深入理解 Kafka:分布式消息队列的强大力量
一、引言
在现代分布式系统中,消息队列扮演着至关重要的角色,而 Kafka 作为其中的佼佼者,以其高吞吐量、可扩展性和持久性等特点被广泛应用。无论是处理海量的日志数据、实时的用户交互信息,还是复杂的微服务间通信,Kafka 都展现出了卓越的性能。
二、Kafka 的基本架构
(一)整体架构图

(二)主要组件
- Producer(生产者)
生产者负责向 Kafka 集群发布消息。它可以将消息发送到指定的主题(Topic)。生产者在发送消息时,可以选择同步或异步的方式。例如,一个日志收集系统中的生产者,会将各个服务器产生的日志数据发送到 Kafka 的特定日志主题中。 - Broker(代理)
Broker 是 Kafka 集群中的服务器节点。它负责存储和管理消息。一个 Kafka 集群可以由多个 Broker 组成,它们共同存储所有的主题数据。每个 Broker 可以处理多个主题的分区(Partition)。例如,在一个大规模的消息处理系统中,可能有多个 Broker 来处理海量的消息流量。 - Consumer(消费者)
消费者从 Kafka 集群中读取消息并进行处理。消费者可以以组(Consumer Group)的形式存在,同一组内的消费者共同消费一个主题中的消息,不同组之间互不影响。例如,在一个电商系统中,订单处理服务和物流通知服务可以作为不同的消费者组来消费订单相关的主题消息。 - Zookeeper(分布式协调服务)
Zookeeper 在 Kafka 中用于管理和协调集群中的 Broker。它负责维护集群的配置信息、选举领导者等。例如,当有新的 Broker 加入或现有 Broker 故障时,Zookeeper 协调集群进行相应的调整。
三、Kafka 的工作流程
(一)消息发布流程
- 生产者创建消息,并指定要发送到的主题。
- 生产者根据配置的分区策略(如基于键的哈希、轮询等)确定消息要发送到的分区。如果没有指定分区策略,Kafka 会默认使用某种策略。
- 生产者将消息发送到对应的 Broker 上的分区。
- Broker 接收到消息后,将其写入本地磁盘的日志文件中,并更新相应的索引信息。
以下是消息发布的伪代码示例:
# 生产者配置
producer_config = {'bootstrap_servers': 'kafka_broker_1:9092,kafka_broker_2:9092','key_serializer': lambda k: str(k).encode('utf-8'),'value_serializer': lambda v: json.dumps(v).encode('utf-8')
}# 创建生产者实例
producer = KafkaProducer(**producer_config)# 要发送的消息
message = {'data': 'This is a sample message','timestamp': datetime.now().strftime('%Y-%m-%%H:%M:%S')
}# 发送消息到指定主题
topic ='my_topic'
producer.send(topic, key='message_key', value=message)
producer.flush()(二)消息消费流程
- 消费者向 Kafka 集群发送订阅请求,指定要消费的主题和消费者组。
- Kafka 根据消费者组和分区分配策略(如范围分配、轮询分配等)为消费者分配分区。
- 消费者从分配到的分区中读取消息。它可以根据需要设置偏移量(Offset)来控制从哪里开始读取消息。消费者读取消息后进行相应的业务逻辑处理。
- 消费者定期向 Kafka 提交偏移量,以便在故障恢复等情况下能够从正确的位置继续消费。
以下是消息消费的伪代码示例:
# 消费者配置
consumer_config = {'bootstrap_servers': 'kafka_broker_1:9092,kafka_broker_2:9092','group_id': 'consumer_group_1','key_deserializer': lambda k: k.decode('utf-8'),'value_deserializer': lambda v: json.loads(v.decode('utf-8'))
}# 创建消费者实例
consumer = KafkaConsumer(**consumer_config)# 订阅主题
topic ='my_topic'
consumer.subscribe([topic])# 循环读取消息并处理
for message in consumer:print(f"Received message: {message.value} from partition {message.partition}")# 在这里进行业务逻辑处理,比如存储消息到数据库、触发其他服务等四、Kafka 的优势
- 高吞吐量:Kafka 能够处理大量的消息,每秒可以处理数百万条消息,这得益于其高效的存储和网络传输机制。
- 可扩展性:可以轻松地增加 Broker 节点来扩展集群的存储和处理能力,以适应不断增长的业务需求。
- 持久性:消息被持久化存储在磁盘上,保证了数据的可靠性,即使在系统故障或重启后也不会丢失消息。
- 分布式特性:通过多个 Broker 和分区的分布式架构,实现了负载均衡和容错能力。
五、总结
Kafka 作为一款强大的分布式消息队列系统,在现代分布式应用中有着广泛的应用。通过了解其架构、工作流程以及优势,我们可以更好地利用它来构建高效、可靠的消息处理系统,满足不同业务场景下的需求,无论是大数据处理、实时流处理还是微服务架构中的通信等领域,Kafka 都将继续发挥重要的作用。
相关文章:
深入理解 Kafka:分布式消息队列的强大力量
一、引言 在现代分布式系统中,消息队列扮演着至关重要的角色,而 Kafka 作为其中的佼佼者,以其高吞吐量、可扩展性和持久性等特点被广泛应用。无论是处理海量的日志数据、实时的用户交互信息,还是复杂的微服务间通信,Ka…...
LabVIEW 离心泵机组故障诊断系统
开发了一套基于LabVIEW图形化编程语言设计的离心泵机组故障诊断系统。系统利用先进的数据采集技术和故障诊断方法,通过远程在线监测与分析,有效提升了离心泵的预测性维护能力,保证了石油化工生产的连续性和安全性。 项目背景及意义 离心泵作…...

GEE土地分类——土地分类的原始remap转化原始的土地分类名称
简介 GEE土地分类——土地分类的原始remap转化原始的土地分类名称 函数 first(image2) Selects the value of the first value for each matched pair of bands in image1 and image2. If either image1 or image2 has only 1 band, then it is used against all the bands…...

一些关于云电脑与虚拟化东西
前言 好久没有更新了,在进行自我校准。 云计算是什么? 云计算是一种模型,它使得用户能够随时随地、方便地、按需访问共享的可配置计算资源池(例如,网络、服务器、存储、应用程序和服务),这些资…...

Java实现图片转pdf
该方法可以选择多个图片是否合并为一个pdf输出,也可以选择图片为横向或者纵向输出,也可以选择pdf页面为A3或者A4 第一步 <dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version…...

【iOS】使用AFNetworking进行网络请求
文章目录 前言AFNetworkingAFNetworking 的核心组件AKNetworking库的常用方法使用AKNetworking进行网络请求的步骤和代码示例 总结 前言 在暑假写天气预报项目时,我们已经接触到网络请求,当时我们是使用URLSession类,即Foundation框架中用于管…...

ThingsBoard规则链节点:RPC Call Reply节点详解
引言 1. RPC Call Reply 节点简介 2. 节点配置 2.1 基本配置示例 3. 使用场景 3.1 设备控制 3.2 状态查询 3.3 命令执行 4. 实际项目中的应用 4.1 项目背景 4.2 项目需求 4.3 实现步骤 5. 总结 引言 ThingsBoard 是一个开源的物联网平台,提供了设备管理…...
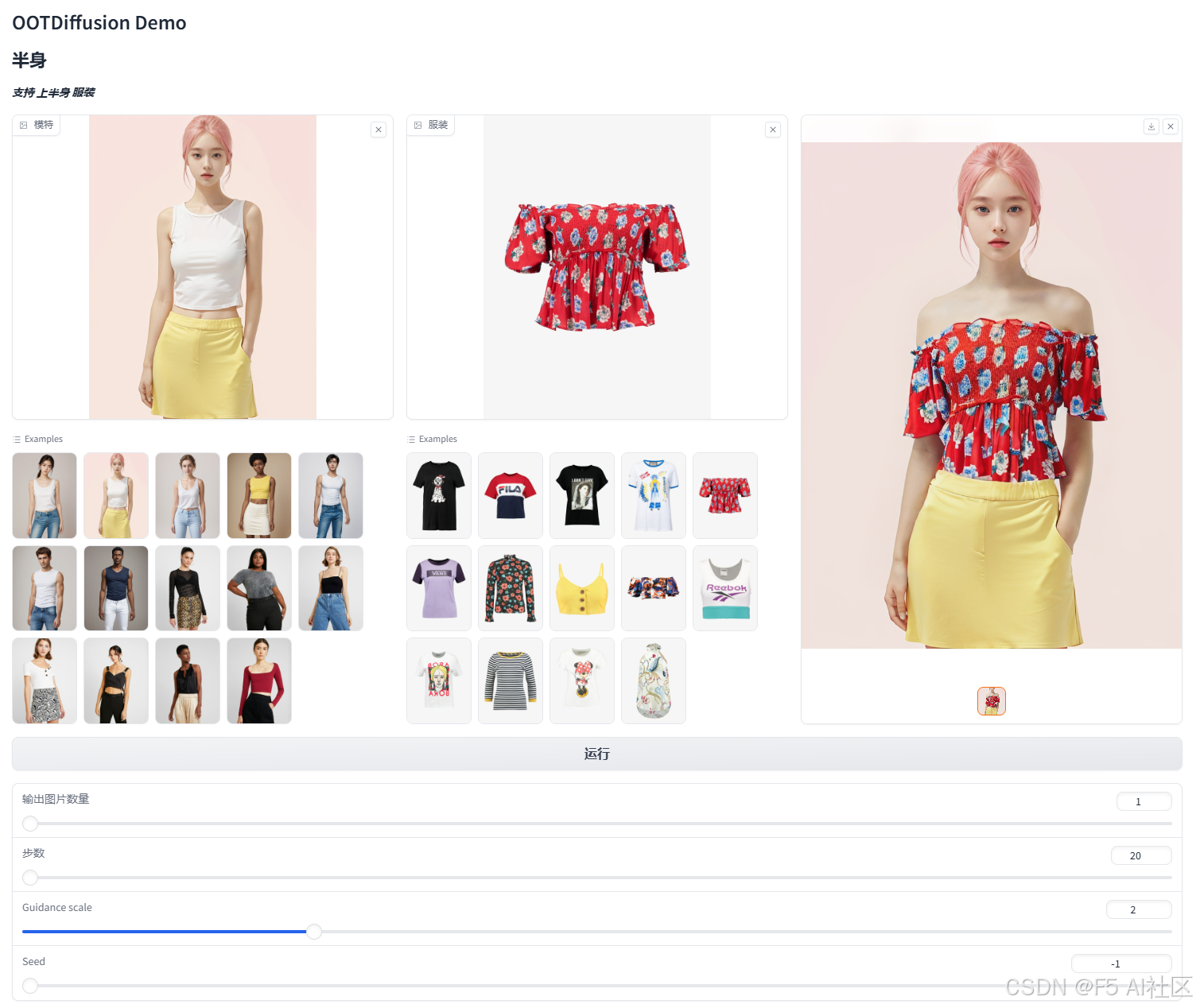
【AI换装整合包及教程】OOTDiffusion:以AI技术引领的时尚换装革命
在当今数字化快速发展的时代,人工智能(AI)技术正以前所未有的速度改变着我们的生活。从智能家居到自动驾驶,从在线教育到虚拟现实,AI的应用范围正在不断扩展。而在时尚领域,一款名为OOTDiffusion࿰…...

排序算法详细总结
算法 定义:算法是解决特定问题的明确步骤集合。算法的效率通常用时间复杂度和空间复杂度来衡量。 排序算法 定义:排序算法是计算机科学中用于对元素序列进行排序的一系列算法。排序算法在各种应用中都非常常见,从简单的数据处理到复杂的数…...

uniapp MD5加密
安装: npm install js-md5 -D 引入: import Md5 from js-md5 需求加密一个对象, login_form: {openId: 123456789,phone: ,scenario: 656677,phoneSessionKey: ,openIdSessionKey: ,timeStamp: , }, //10位时间戳(秒)…...

提升视觉回归测试体验:Cypress 插件推荐
项目介绍 在现代前端开发中,视觉回归测试是确保用户界面在不同版本之间保持一致性的关键步骤。然而,传统的视觉回归测试工具往往复杂且难以使用。为了解决这一问题,我们推荐一款专为 Cypress 设计的插件:Cypress Plugin Visual Re…...

fastbootd模式刷android固件的方法
1. fastbootd追根溯源 Google在Android 10上正式引入了动态分区机制来提升OTA的可扩展性。动态分区使能后:andorid系统可以在开机阶段动态地进行分区创建、分区销毁、分区大小调整等操作,下游厂商只需要规划好super分区的总大小,其内部的各个…...

基于C#实现Windows后台窗口操作与图像处理技术分析
在Windows编程中,操作后台窗口是一项复杂而有用的技术。它可以用来自动化用户界面测试、应用程序机器人等场景。本文将深入探讨如何在C#中绑定后台窗口、获取后台窗口界面图片,以及在图片中寻找指定图标并获取坐标。本技术文章结合最先进的资料与实践经验…...
戴尔电脑 Bios 如何进入?Dell Bios 进入 Bios 快捷键是什么?
BIOS(基本输入输出系统)是计算机启动时运行的第一个程序,它负责初始化硬件并加载操作系统。对于戴尔电脑用户来说,有时可能需要进入 BIOS 进行一些特定的设置调整,比如更改启动顺序、调整性能选项或解决硬件兼容性问题…...

数据结构之二叉树——堆 详解(含代码实现)
1.堆 如果有一个关键码的集合 K { , , , … ,},把它的所有元素按完全二叉树的顺序存储方式存储 在一个一维数组中,则称为小堆( 或大堆 ) 。将根节点最大的堆叫做最大堆或大根堆,根节点最小的…...
推荐一款面向增材制造的高效设计平台:nTopology
nTopology是一款面向增材制造的高效设计平台,平台预置了大量增材制造常用的设计工具包,工程师通过调用若干个预置工具包、或自主开发定制的工具包,建立一个工作流,实现复杂几何结构的参数化设计。nTopology集合了的强大几何建模和…...

SQL,力扣题目1767,寻找没有被执行的任务对【递归】
一、力扣链接 LeetCode_1767 二、题目描述 表:Tasks ------------------------- | Column Name | Type | ------------------------- | task_id | int | | subtasks_count | int | ------------------------- task_id 具有唯一值的列。 ta…...

JavaScript数据类型- Symbol 详解
文章目录 前言1.唯一性2. 描述3. 作为对象属性键4. 全局注册6. 不可变性7. 隐式转换 前言 Symbol是ES6新增内容,代表创建后独一无二且不可变的数据类型,它主要是为了解决可能出现的全局变量冲突的问题 在JavaScript发展的过程中,其中的ES6带…...

WordPress网站添加嵌入B站视频,自适应屏幕大小,取消自动播放
结合bv号 改成以下嵌入式代码(自适应屏幕大小,取消自动播放) <iframe style"width: 100%; aspect-ratio: 16/9;" src"//player.bilibili.com/player.html?isOutsidetrue&bvidBV13CSVYREpr&p1&autoplay0" scrolling…...

11.6 校内模拟赛总结
打的很顺的一场 复盘 7:40 开题,看到题目名很interesting T1 看起来很典,中位数显然考虑二分,然后就是最大子段和;T2 构造?一看数据范围这么小,感觉不是很难做;T3 神秘数据结构;T…...

8051仿真器OMF转SIG格式的实战指南
1. Signum 8051 仿真器符号转换器使用指南在嵌入式开发领域,Signum Systems 的 8051 仿真器是一个常用的调试工具。很多开发者在使用 Vision 开发环境时,经常遇到需要将链接器生成的绝对目标模块(OMF)转换为仿真器专用格式的需求。本文将详细介绍这个转换…...

量子纠错码与硬件定制逻辑门的优化实现
1. 量子纠错码与硬件定制逻辑门概述量子纠错码(QECC)是容错量子计算的核心组件,其核心思想是通过编码将量子信息分布在多个物理量子比特上,利用稳定子(stabilizer)测量来检测和纠正错误。在众多QECC中&…...

终极指南:如何用ESP32-A2DP库快速构建蓝牙音频设备
终极指南:如何用ESP32-A2DP库快速构建蓝牙音频设备 【免费下载链接】ESP32-A2DP A Simple ESP32 Bluetooth A2DP Library (to implement a Music Receiver or Sender) that supports Arduino, PlatformIO and Espressif IDF 项目地址: https://gitcode.com/gh_mir…...

React Starter Kit 团队协作:如何建立统一的开发规范
React Starter Kit 团队协作:如何建立统一的开发规范 【免费下载链接】react-starter-kit Start your first React App. By using React, Redux, and React-Router. 项目地址: https://gitcode.com/gh_mirrors/reac/react-starter-kit React Starter Kit 是一…...

【入门+总结】万字复盘黑马点评|从业务到 Redis 实战,面试直接背
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

Bazzite:专为游戏玩家打造的Linux操作系统深度解析
Bazzite:专为游戏玩家打造的Linux操作系统深度解析 【免费下载链接】bazzite Bazzite makes gaming and everyday use smoother and simpler across desktop PCs, handhelds, tablets, and home theater PCs. 项目地址: https://gitcode.com/gh_mirrors/ba/bazzit…...

从开题到定稿,okbiye AI 写作如何解决毕业论文 90% 的核心痛点
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 作为一名踩过论文无数坑的过来人,我深知毕业季被毕业论文支配的恐惧:对着 Word 空白页无从下笔,开题报告…...

Python机器学习模型部署实战:从训练到生产环境
Python机器学习模型部署实战:从训练到生产环境 引言 作为从Python转向Rust的后端开发者,我深刻体会到机器学习模型部署的重要性。一个优秀的模型如果不能成功部署到生产环境,其价值将大打折扣。本文将从实战角度出发,详细介绍Pyth…...

嵌入式开发框架ASF架构解析与设计实践:从硬件抽象到模块化应用
1. 项目概述:为什么我们需要深入理解ASF?如果你是一位长期在嵌入式领域,特别是基于Atmel(现在叫Microchip)AVR和SAM系列MCU进行开发的工程师,你大概率听说过或者直接使用过Atmel Software Framework&#x…...

5分钟快速获取微信数据库密钥:Sharp-dumpkey完整指南
5分钟快速获取微信数据库密钥:Sharp-dumpkey完整指南 【免费下载链接】Sharp-dumpkey 基于C#实现的获取微信数据库密钥的小工具 项目地址: https://gitcode.com/gh_mirrors/sh/Sharp-dumpkey 当你的微信聊天记录被加密锁定,无法备份或迁移时&…...