R7:糖尿病预测模型优化探索
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、实验目的:
探索本案例是否还有进一步优化的空间
二、实验环境:
- 语言环境:python 3.8
- 编译器:Jupyter notebook
- 深度学习环境:Pytorch
- torch==2.4.0+cu124
- torchvision==0.19.0+cu124
三、数据集标准化处理
对比R6的代码,本案例的改进部分主要是取消了两行代码的注释# 数据集标准化处理
from sklearn.preprocessing import StandardScaler # '高密度脂蛋白胆固醇'字段与糖尿病负相关,故而在 X 中去掉该字段
X = DataFrame.drop(['是否糖尿病','高密度脂蛋白胆固醇'],axis=1)
y = DataFrame['是否糖尿病'] # 数据集标准化处理
sc_X = StandardScaler()
X = sc_X.fit_transform(X) X = torch.tensor(np.array(X), dtype=torch.float32)
y = torch.tensor(np.array(y), dtype=torch.int64) train_X, test_X, train_y, test_y = train_test_split(X, y,test_size=0.2, random_state=1)
train_X.shape, train_y.shape
代码输出结果如下:




对比R6的结果可以看到测试集准确率有了明显的提高,而原因我也有在上一次总结中提及。结果差异大的可能原因分析如下:
数据处理差异
- 特征选择不同
- 在R6中,除了删除
'高密度脂蛋白胆固醇'和'是否糖尿病',还删除了'卡号'。这意味着R6代码使用的特征集比R7少了一个额外的特征。不同的特征集会对模型的学习和预测能力产生影响。'卡号'这个特征本身包含了一些与糖尿病相关的潜在信息(不同卡号对应的人群有不同的糖尿病发病倾向等),那么去掉它会改变模型的行为。
- 在R6中,除了删除
- 标准化处理的有无
- R7代码对数据进行了标准化处理(
sc_X.fit_transform(X)),而R6没有。标准化可以使数据的特征具有相似的尺度,这对于一些基于距离或梯度的算法(如神经网络中的梯度下降)非常重要。如果数据没有标准化,可能会导致某些特征在模型训练过程中对损失函数的影响过大或过小,从而影响模型的收敛速度和性能。例如,在神经网络中,如果某个特征的值域很大,而另一个特征的值域很小,那么在计算梯度时,可能会使模型过度关注值域大的特征,而忽略值域小的特征。
- R7代码对数据进行了标准化处理(
模型训练相关因素
- 初始条件差异
- 模型的初始参数(如神经网络的权重初始化)可能会因为数据的不同而导致不同的训练轨迹。不同的数据分布(由于数据处理的不同)可能会使模型在相同的初始化策略下朝着不同的方向优化。
- 训练动态变化
- 由于数据的改变,模型在训练过程中的梯度更新情况也会不同。R6代码中没有标准化的数据可能会导致梯度在某些方向上变化剧烈,影响模型收敛。而在R7中,标准化后的数据可能使梯度更新更加稳定和合理,导致训练和测试准确率的变化趋势不同。而且,不同的数据特征可能在不同的训练阶段对模型的贡献不同,进而影响模型在每个 epoch 的准确率和损失值。


四、总结
标准化处理对模型训练的具体影响:
-
加快收敛速度
- 原理:在未进行标准化处理时,不同特征的取值范围可能差异巨大。例如,一个特征的取值范围是0 - 1,另一个特征的取值范围是0 - 1000。在基于梯度下降的优化算法中,如随机梯度下降(SGD),损失函数的梯度更新会受到特征尺度的影响。对于取值范围大的特征,其梯度更新步长可能会过大,导致模型难以收敛到最优解;而对于取值范围小的特征,其梯度更新步长可能过小,模型学习这些特征的速度会很慢。标准化将数据变换到均值为0、标准差为1的分布,使得不同特征具有相似的尺度。这样,在梯度更新时,各个特征能够以相对平衡的步长进行学习,从而加快模型收敛速度。
- 示例:假设我们有一个简单的线性回归模型 y = w 1 x 1 + w 2 x 2 + b y = w_1x_1+w_2x_2 + b y=w1x1+w2x2+b,其中 x 1 x_1 x1的取值范围是[0, 1], x 2 x_2 x2的取值范围是[0, 100]。如果不进行标准化,当更新 w 1 w_1 w1和 w 2 w_2 w2的梯度时,由于 x 2 x_2 x2的取值范围大, w 2 w_2 w2的更新步长会比 w 1 w_1 w1大很多。经过标准化后, x 1 x_1 x1和 x 2 x_2 x2的尺度变得相似, w 1 w_1 w1和 w 2 w_2 w2可以以更合理的步长进行更新,模型能够更快地找到合适的权重组合。
-
提高模型精度
- 原理:标准化可以减少数据中异常值和离群点对模型训练的影响。在一些机器学习算法中,如支持向量机(SVM)和神经网络,异常值可能会导致模型过度拟合这些异常数据点,从而降低模型在其他正常数据点上的泛化能力。标准化通过将数据压缩到一个相对稳定的范围内,降低了异常值的影响,使模型能够更好地学习数据的整体分布规律,进而提高模型的精度。
- 示例:考虑一个K - 近邻(K - NN)分类器,它基于数据点之间的距离进行分类。如果存在一个特征有很大的取值范围,并且有一些离群点,那么这些离群点会在距离计算中占据主导地位,导致分类错误。通过标准化,所有特征的取值范围变得相对均匀,离群点的影响被减弱,K - NN分类器能够更准确地根据数据的真实分布进行分类。
-
增强模型稳定性和鲁棒性
- 原理:在模型训练过程中,数据的微小变化可能会导致模型性能的大幅波动。标准化后的数据在一定程度上减少了这种波动,因为它使得数据的分布更加稳定。对于神经网络等复杂模型,这种稳定性尤为重要,因为它们通常具有大量的参数,容易受到数据变化的影响。标准化可以帮助模型在不同的数据集(如训练集和测试集)上保持相对一致的性能,提高模型的鲁棒性。
- 示例:在深度学习中,当使用小批量梯度下降(Mini - Batch Gradient Descent)训练模型时,每个小批量数据的分布可能会有所不同。如果没有标准化,模型可能会因为小批量数据的差异而产生较大的性能波动。而标准化后,小批量数据的分布更加稳定,模型的训练过程更加平稳,对数据变化的敏感度降低,从而增强了模型的鲁棒性。
除了标准化处理,还有下述数据预处理方法:
- 数据清洗
- 缺失值处理
- 删除法:当数据集中的缺失值占比较小,且缺失是完全随机的情况下,可以直接删除含有缺失值的行或列。例如,在一个包含1000条记录的客户信息数据集中,如果只有少数几条记录的“联系电话”字段缺失,且这些缺失看起来是随机发生的,那么可以考虑删除这些记录。
- 插补法:
- 均值/中位数/众数插补:对于数值型特征的缺失值,可以使用该特征的均值、中位数来填充。比如,在一个学生成绩数据集中,如果某个学生的数学成绩缺失,可以用全班数学成绩的均值来填充。对于分类型特征,则可以使用众数填充,例如,在一个调查问卷数据集中,“性别”字段有缺失值,就可以用出现频率最高的性别(众数)来填充。
- 回归插补:通过建立一个回归模型,利用数据集中其他相关特征来预测缺失值。假设在一个房屋价格数据集中,“房屋面积”字段有缺失值,可以建立一个以房屋价格、房间数量等其他特征为自变量,房屋面积为因变量的回归模型,然后利用该模型预测缺失的房屋面积。
- 异常值处理
- 盖帽法:将超出一定范围(如大于某个分位数加上几倍的四分位距,或小于某个分位数减去几倍的四分位距)的异常值替换为该范围的边界值。例如,在一个员工工资数据集中,若发现工资数据有异常高的值,可以将这些异常高的值替换为上四分位数加上1.5倍四分位距的值。
- 删除法:当异常值对模型训练有严重干扰,且其出现是由于数据录入错误等原因时,可以直接删除异常值。例如,在一个体温测量数据集中,如果出现了明显不符合人体正常体温范围(如50℃)的异常值,且确定是测量错误导致的,就可以删除。
- 缺失值处理
- 数据编码
- 独热编码(One - Hot Encoding):主要用于处理分类型数据。对于一个具有 n n n个类别(如颜色有红、绿、蓝三种)的分类变量,会创建 n n n个新的二进制变量(0或1)来表示。例如,对于“颜色”这个分类变量,会创建“红色”、“绿色”、“蓝色”三个新变量,当原始数据为红色时,“红色”变量为1,其他两个为0。这种编码方式可以避免模型将分类变量的类别顺序错误地理解为数值大小关系。
- 标签编码(Label Encoding):将分类变量的类别转换为整数。例如,对于一个包含“低”、“中”、“高”三个类别的变量“风险等级”,可以将“低”编码为0,“中”编码为1,“高”编码为2。不过这种编码方式可能会让模型误解类别之间的顺序关系,所以在一些对类别顺序不敏感的模型(如决策树)中可以使用,而在对顺序敏感的模型(如线性回归)中可能需要谨慎使用。
- 数据变换
- 对数变换:对于一些具有正偏态分布(数据大部分集中在左侧,右侧有较长的尾巴)的数据,如收入数据、人口数据等,可以使用对数变换将其转换为近似正态分布。例如,对一组公司营业收入数据进行对数变换后,数据的分布会更加对称,这样更符合一些模型(如基于正态分布假设的线性回归)的假设,有助于提高模型性能。
- 平方根变换:和对数变换类似,主要用于改善数据的分布形态。当数据的偏态程度不是特别严重时,平方根变换可能是一种有效的方法。例如,对于一些生物实验中的细胞计数数据,其分布可能存在一定的偏态,通过平方根变换可以使其分布更加合理,方便后续模型的训练。
五、模型优化探索
1. 调整模型结构
-
增加更多的层:可以考虑增加
LSTM层的数量。更多的层可能能够捕捉到更复杂的数据模式。例如,可以增加到3层或4层的LSTM,但要注意防止过拟合,可以结合正则化方法。 -
添加Dropout层:在
LSTM层之间或者在全连接层之前添加Dropout层。Dropout在训练过程中随机忽略一些神经元,有助于减少过拟合。比如,可以在每个LSTM层之后添加Dropout层,设置Dropout概率为0.2 - 0.5之间。
class model_lstm(nn.Module):def __init__(self):super(model_lstm, self).__init__()self.lstm0 = nn.LSTM(input_size=13, hidden_size=200, num_layers=1, batch_first=True)self.dropout1 = nn.Dropout(0.2) # 添加Dropout层,概率为0.2self.lstm1 = nn.LSTM(input_size=200, hidden_size=200, num_layers=1, batch_first=True)self.dropout2 = nn.Dropout(0.2) # 添加另一个Dropout层self.fc0 = nn.Linear(200, 2)def forward(self, x):out, hidden1 = self.lstm0(x)out = self.dropout1(out) # 使用Dropoutout, _ = self.lstm1(out, hidden1)out = self.dropout2(out) # 使用Dropoutout = self.fc0(out)return out
2. 优化超参数
- 调整隐藏层大小:当前
LSTM的隐藏层大小是200,可以尝试不同的值,如128、256、300等。通过交叉验证等方法来确定最佳的隐藏层大小,以提高模型的性能。 - 调整学习率:使用不同的学习率策略,如学习率衰减。可以从一个相对较大的学习率开始,随着训练的进行逐渐降低学习率。例如,使用Adam优化器,并设置初始学习率为0.001,然后每几个
epoch按照一定比例(如0.9)降低学习率。
from torch.optim.lr_scheduler import StepLRloss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-3 # 初始学习率增大为1e - 3
opt = torch.optim.Adam(model.parameters(), lr=learn_rate)
scheduler = StepLR(opt, step_size=10, gamma=0.1) # 添加学习率调度器
epochs = 30train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = opt.state_dict()['param_groups'][0]['lr']scheduler.step() # 更新学习率template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr))print("=" * 20, 'Done', "=" * 20)
3. 改进输入数据处理
- 特征工程:进一步分析输入的13个特征,看是否可以通过特征组合、特征变换等方式提高数据的质量。例如,如果某些特征之间存在非线性关系,可以尝试添加一些新的特征来表示这种关系。
- 数据增强(如果适用):如果数据具有一定的可变性,可以考虑数据增强方法。例如,如果数据是时间序列数据,可以通过对数据进行小幅度的时间平移、缩放等操作来增加数据量和多样性。
4. 模型集成
- 使用多个模型进行集成:训练多个不同初始化或者不同超参数的
LSTM模型,然后将它们的预测结果进行集成,如简单平均或者加权平均。这样可以利用不同模型的优势,提高整体的预测准确性。
经过上述调整模型结构、优化超参数后(特征工程效果不明显),效果有所提升,结果输出如下:


5. 改进空间
-
进一步调整模型结构
- 增加更多层或调整层大小:虽然已经添加了一些改进,但可以继续尝试增加
LSTM的层数或者调整隐藏层大小。例如,可以尝试将LSTM的层数增加到3层,同时适当调整每层的隐藏单元数量,如将隐藏单元数量从200增加到256或300等,然后观察模型性能的变化。 - 尝试不同类型的层:可以考虑在模型中添加其他类型的神经网络层,如卷积层(如果数据结构适合)。对于时间序列数据或具有局部相关性的数据,卷积层可以提取数据中的局部特征,与
LSTM层结合可能会提高模型性能。
- 增加更多层或调整层大小:虽然已经添加了一些改进,但可以继续尝试增加
-
优化超参数
- 更精细的学习率调整:目前使用了简单的学习率衰减策略,可以尝试更复杂的学习率调整方法,如余弦退火学习率(Cosine Annealing Learning Rate)。这种方法可以使学习率在训练过程中按照余弦函数的规律变化,在前期可以有较大的学习率快速收敛,后期学习率逐渐减小以更精细地调整模型参数。
- 调整Dropout概率:当前设置的
Dropout概率为0.2,可以尝试不同的值,如0.3、0.4等,观察对模型过拟合情况的影响。不同的Dropout概率可能会改变模型的复杂度和泛化能力。
-
改进特征工程
- 深入分析数据相关性:对新添加的特征进行更深入的分析,检查它们与目标变量的相关性。如果某些新特征与目标变量相关性较低,可以考虑删除或进一步修改这些特征的构建方式。同时,可以探索更多的特征组合和变换方法,以挖掘数据中更有价值的信息。
- 添加领域相关特征(如果可能):根据数据的领域知识,添加更多有意义的特征。例如,如果是医疗数据,可以考虑添加一些与疾病相关的衍生特征,如不同指标之间的比率等。
-
模型集成
- 使用多种模型集成:除了单一的
LSTM模型,可以尝试将其与其他类型的模型(如决策树、支持向量机等)进行集成。例如,可以使用堆叠(Stacking)或混合(Blending)等集成方法,将不同模型的预测结果进行组合,以提高模型的泛化能力和稳定性。 - 训练多个不同初始化的LSTM模型并集成:训练多个不同初始化参数的
LSTM模型,然后通过平均或加权平均等方式将它们的预测结果集成在一起。这种方法可以利用不同初始化模型的多样性,降低模型的方差,提高预测性能。
- 使用多种模型集成:除了单一的
相关文章:
R7:糖尿病预测模型优化探索
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 一、实验目的: 探索本案例是否还有进一步优化的空间 二、实验环境: 语言环境:python 3.8编译器:Jupyter notebo…...

Spring核心:探索IoC容器与依赖注入的奥秘
目录 一、什么是Spring? 二、什么是 Ioc ? 2.1 控制反转的实现方式 2.1.1 依赖注入 2.1.2 依赖查找 2.1.3 优点分析 2.2 理解 Ioc 一、什么是Spring? 我们通常所说的 Spring 指的是 Spring Framework(Spring 框架ÿ…...

15分钟学 Go 实践项目二:打造博客系统
打造博客系统 项目概述 在本项目中,我们将创建一个简单的博客系统,重点实现CRUD(创建、读取、更新、删除)操作和用户管理。这个博客系统将使用户能够发布文章,评论,并管理其个人账户信息。 目标 实现用…...

Follow软件的使用入门教程
开篇 看到很多兄弟还不知道怎么用这个当下爆火的浏览器!在这里简单给需要入门的小伙伴一些建议: 介绍 简单解释一下,RSS 意思是简易信息聚合,用户可以通过 RSS 阅读器或聚合工具自主订阅并浏览各个平台的内容源,不用…...

【IC验证】systemverilog的设计特性
systemverilog的设计特性 一.概述二.面向硬件的过程语句块1.说明2.always_comb2.always_latch3.always_ff 三.关系运算符1.说明2.例子 四.inside判定符1.说明2.例子 五.条件分支语句(1)说明(2)例子(case和unique case的…...

【点击劫持漏洞(附测试代码)】
漏洞描述 点击劫持(Clickjacking)是一种网络攻击技术,攻击者通过将一个恶意的页面或按钮隐藏在合法网站的页面下,诱使用户在不知情的情况下点击隐藏的内容,从而触发攻击者设计的操作。这种攻击通常会导致用户无意中执…...

【AD】3-4 在原理图中放置元件
1.打开原理图库,选中元件点击放置 2.点击工程右键,选择,,进行编译,点击Components,选中鼠标点击拖动即可...

协程2 --- 相关概念
文章目录 协程切换方案协程库的完善程度协程栈方案协程调度实现有栈协程与无栈协程对称协程与非对称协程 协程切换方案 具体使用和解析看栈切换那个博客 使用setjump、longjump c语言提供的方案 可参考:libmill 使用操作系统提供的api:ucontext、fiber …...

Hadoop-005-HDFS分布式文件存储原理
一、HDFS数据如何存储 分布式存储:每个服务器(节点)存储文件的一部分, 本文提到的part只是为方便理解, 指的文件部分数据, 并不是真实存在的概念 #mermaid-svg-qjJMG6r2bzRNcWkF {font-family:"trebuchet ms",verdana,arial,sans-s…...

【多线程入门篇】 创建线程以及线程的属性
大家好呀 我是浪前 今天给大家讲解的是创建线程以及线程的属性 祝愿所有点赞关注的人,身体健康,一夜暴富,升职加薪迎娶白富美!!! 点我领取迎娶白富美大礼包 🍓多线程编程: 前言: 我们为什么不用多进程?…...
)
三十四、Python基础语法(文件操作-上)
一、介绍 文件:可以储存在长期储存设备上的一段数据,在计算机储存的数据都是二进制的形式储存的,我们用软件打开文件不是看见0和1是因为软件会自动将二进制数据进行转换。 二、文件操作 1.打开文件 打开文件:文件是在硬盘中储…...

【大咖云集,院士出席 | ACM独立出版】第四届大数据、人工智能与风险管理国际学术会议 (ICBAR 2024,11月15-17日)--冬季主会场
第四届大数据、人工智能与风险管理国际学术会议 (ICBAR 2024)--冬季主会场 2024 4th International Conference on Big Data, Artificial Intelligence and Risk Management 官方信息 会议官网:www.icbar.net 2024 4th International Conference on Big Data, Art…...

03 Oracle进程秘籍:深度解析Oracle后台进程体系
文章目录 Oracle进程秘籍:深度解析Oracle后台进程体系一、Oracle后台进程概览1.1 DBWn(Database Writer Process)1.2 LGWR(Log Writer Process)1.3 SMON(System Monitor Process)1.4 PMON&#…...
AndroidStudio通过Bundle进行数据传递
作者:CSDN-PleaSure乐事 欢迎大家阅读我的博客 希望大家喜欢 使用环境:AndroidStudio 目录 1.新建活动 2.修改页面布局 代码: 效果: 3.新建类ResultActivity并继承AppCompatActivity 4.新建布局文件activity_result.xml 代…...
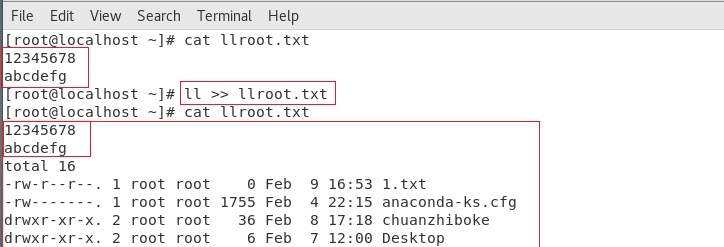
Linux篇(文件管理命令)
目录 一、Linux下文件命名规则 1. 可以使用哪些字符 2. 文件名的长度 3. 文件名的大小写 4. Linux文件扩展名 二、目录创建与删除 1. 目录创建 1.1. mkdir创建目录 1.2. mkdir -p 递归创建目录 1.3. 使用mkdir同时创建多个目录 2. 目录删除(必须是空目录&…...

大数据新视界 -- 大数据大厂之 Impala 性能优化:数据存储分区的艺术与实践(下)(2/30)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

【数据结构】B树
B树(B-Tree)是一种自平衡的多叉搜索树,广泛应用于数据库系统和文件系统中,以便高效地进行数据存储和检索。它的设计目标是减少磁盘I/O操作,使得在大量数据的情况下依然能够进行快速的查找、插入和删除操作。 B树的特点…...

Docker 容器网络模式详解
Docker 容器网络模式详解 1.1 引言 1.1.1 Docker 网络简介 Docker 是一个开源的应用容器引擎,它允许开发者将应用和依赖打包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器采用沙箱机制,彼此…...

吴恩达深度学习笔记:卷积神经网络(Foundations of Convolutional Neural Networks)4.11
目录 第四门课 卷积神经网络(Convolutional Neural Networks)第四周 特殊应用:人脸识别和神经风格转换(Special applications: Face recognition &Neural style transfer)4.11 一维到三维推广(1D and 3…...

小游戏开发,出现了降本增效的技术?
中国经济下行大周期下,要说受影响程度较小的,非游戏行业莫属了。 小游戏的快速增长主要得益于其便捷的使用方式和轻量化的特点。小游戏通常无需下载,即点即玩,适合在碎片时间内进行娱乐,这种特性吸引了大量用户。此外…...

XInputTest:精准测量游戏手柄轮询率与延迟的专业工具
XInputTest:精准测量游戏手柄轮询率与延迟的专业工具 【免费下载链接】XInputTest Xbox 360 Controller (XInput) Polling Rate Checker 项目地址: https://gitcode.com/gh_mirrors/xin/XInputTest 在竞技游戏和模拟飞行等高精度操作场景中,游戏手…...
)
保姆级教程:在RK3568开发板上搞定ES8316声卡驱动(从DTS配置到tinymix调试全流程)
RK3568开发板ES8316声卡驱动全流程实战指南 从零开始的声音之旅 当你第一次拿到RK3568开发板,想要实现音频功能时,ES8316这颗高性能低功耗的音频编解码芯片可能会成为你的首选。但在嵌入式Linux环境下,从硬件连接到软件驱动,再到最…...

别再只读原始值了!MPU6050数据滤波与姿态解算入门:用STM32实现简易角度估算
从原始数据到稳定姿态:MPU6050滤波与解算实战指南 当你第一次成功读取MPU6050的原始数据时,可能会被那些不断跳动的数值弄得手足无措。这些看似杂乱的数据背后,隐藏着设备在三维空间中的运动秘密。本文将带你超越基础的数据读取,探…...

从‘浴盆曲线’到加速测试:拆解企业级SSD如何做到MTBF 200万小时
从‘浴盆曲线’到加速测试:拆解企业级SSD如何做到MTBF 200万小时 当企业技术决策者面对存储方案选型时,一个看似简单的参数常引发激烈讨论:为什么同样容量的企业级SSD价格是消费级的3-5倍?答案藏在MTBF(Mean Time Betw…...
)
别再死记硬背了!用‘榨汁机’和‘张三的饭量’搞定高数函数定义域(附3类题型解法)
用生活化思维破解高数函数定义域:从榨汁机到张三的饭量 第一次翻开高等数学教材时,那些密密麻麻的函数符号让我头晕目眩。直到有一天,我在厨房榨果汁时突然顿悟——原来函数就像一台榨汁机,而定义域不过是张三在不同状态下的饭量。…...

收藏备用!【2025 版】CMD 命令超详细大全,零基础全覆盖
在Windows操作系统中,命令提示符(CMD)是一个强大的工具,允许用户通过输入命令来执行各种操作。无论是系统管理、网络配置,还是文件管理,CMD都能提供高效的解决方案。 一、基本命令 cd:更改目录…...

SegFormer凭什么不用位置编码?深入拆解Mix-FFN与重叠Patch Merging的设计哲学
SegFormer革命性设计:为何抛弃位置编码仍能称霸语义分割? 在视觉Transformer的浪潮中,SegFormer以其独特的设计哲学脱颖而出——它大胆摒弃了传统Transformer中视为标配的位置编码(Positional Encoding),却…...

Phillips SDM01 0940860010091 003149电子控制单元
Phillips SDM01 0940860010091 003149 是一款飞利浦出品的电子控制单元,专用于工业设备或医疗系统的逻辑控制与信号处理。中间:15条产品特点SDM01 采用飞利浦高品质元器件,稳定性好。具备多路数字量输入输出通道,扩展性强。处理速…...

抖音视频批量下载神器:3分钟学会无水印批量下载技巧
抖音视频批量下载神器:3分钟学会无水印批量下载技巧 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...

人工智能,应用层和算法层到底该怎么选?
想做AI,但是应用层和算法层到底有啥区别?”“我非科班,能学算法吗?”“哪个方向薪资更高、更有前景?”其实不止新手,就连一些转行做AI的从业者,初期也会被这两个方向搞懵。毕竟都属于人工智能领…...