查询引擎的演变之旅 | OceanBase原理解读
在关系型数据库中,查询调度器与计划执行器,有着与查询优化器同样重要的地位,随着计算机硬件技术的飞速进步,这两大模块的重要性日益凸显,成为提升数据库性能的关键所在。接下来,本文将由来自 OceanBase 的技术专家,和我们一同回顾并探讨,执行器技术发展历程中的那些重要变化。
在关系数据库中,当大家提到SQL查询,自然而然的想到查询优化器,毋庸置疑,这是关系数据计算中非常重要并且复杂的一个模块,它决定了查询关系以哪种方式执行能够得到一个最优的结果。但是在关系计算的过程中,还有两个同等重要的模块,那就是查询调度器和计划执行器。
在关系数据库发展的早期,受制于计算机IO能力的约束,计算在查询整体的耗时占比并不明显,这个时候调度器和执行器的作用被弱化,一个查询的好坏更主要取决于优化器对执行计划的选择好坏。但是在今天,随着计算机硬件的发展,调度器和执行器也逐渐彰显了它们的重要地位,这里我们重点介绍下数据库执行器发展过程中的一些演变。
绕不开的火山
Volcano Model是一种经典的基于行的流式迭代模型(Row-BasedStreaming Iterator Model),在我们熟知的主流关系数据库中都采用了这种模型,例如Oracle,SQL Server, MySQL等。
在Volcano模型中,所有的代数运算符(operator)都被看成是一个迭代器,它们都提供一组简单的接口:open()—next()—close(),查询计划树由一个个这样的关系运算符组成,每一次的next()调用,运算符就返回一行(Row),每一个运算符的next()都有自己的流控逻辑,数据通过运算符自上而下的next()嵌套调用而被动的进行拉取。

上图展示了Spark1.0的查询迭代器模型(OceanBase0.5中采用了相同的结构),这是一个最简单的火山模型例子,拉取数据的控制命令从最上层的Aggregate运算符依次传递到执行树的最下层,而数据流动的方向正好相反。
火山模型中每一个运算符都将下层的输入看成是一张表,next()接口的一次调用就获取表中的一行数据,这样设计的优点是:
- 每个运算符之间的代数计算是相互独立的,并且运算符可以伴随查询关系的变化出现在查询计划树的任意位置,这使得运算符的算法实现变得简单并且富有拓展性。
- 数据以row的形式在运算符之间流动,只要没有sort之类破坏流水性的运算出现,每个运算符仅需要很少的buffer资源就可以很好的运行起来,非常的节省内存资源。
但是这种运算符的嵌套模型也有它的缺点:
- 火山模型的流控是一种被动拉取数据的过程,每行数据流向每一个运算符都需要额外的流控操作,所以数据在操作符之间的流动带来了很多冗余的流控指令。
- 运算符之间的next()调用带来了很深的虚函数嵌套,编译器无法对虚函数进行inline优化,每一次虚函数的调用都需要查找虚函数表,同时也带来了更多的分支指令,复杂的虚函数嵌套对CPU的分支预测非常不友好,很容易因为预测失败而导致CPU流水线变得混乱。这些因素都会导致CPU执行效率低下。
通常,一个查询的直接开销主要取决于两个因素:第一个因素就是跨存储和计算操作符之间的数据传输开销,另一个因素就是数据运算所花费的时间。
火山模型最早于1990年Goetz Graefe在Volcano, an Extensible and Parallel Query Evaluation System这篇论文中提出,在90年代早期,计算机的内存资源十分昂贵,相对于CPU的执行效率,IO效率要差得多,因此运算符和存储之间的IO交换是影响查询效率的主要因素(IO墙效应),火山模型将更多的内存资源用于IO的缓存设计而没有优化CPU的执行效率是在当时的硬件基础上很自然的权衡。
随着硬件的发展,计算机的内存容量变得越来越大,更多的数据可以直接存储在内存中,而单核CPU的运算能力并没有显著提升,这个时候CPU对执行效率的影响就变得更加重要,因此越来越多对CPU执行效率的优化被提出。
操作符融和
优化操作符的执行效率最简单有效的方法就是减少执行过程中操作符的函数调用。由于ProjectOp和FilterOp在计划树中最为常见的两个操作符,因此在OceanBase1.0中,我们将这两种操作符融合在其它特定的代数操作符中,这大大减少了计划树中的运算符的个数以及运算符之间的next()嵌套调用,同时,PorjectOp和FilterOp变成每个操作符内部的一种能力,这也增强了代码局部性能力,优化了CPU的分支预测能力。

上图展示了select count(*) from store_sales where ss_item_sk=1000;这条查询在OceanBase1.0的执行计划,操作符从原来的4个变成了2个,而FilterOp和SelectOp成为了操作符中的一个局部运算。
RowSet迭代
在火山模型的基础上另一种简单有效的优化方式就是RowSet机制,简而言之就是每一次数据流的传递不再是单行的形式,而是若干的row组成的集合,这使得运算更多的停留在next()内部,而不是在函数调用间频繁的切换,从而保证代码局部性和减少函数间调用次数。
RowSet机制将数据在各个环节的流向变成了一个局部范围的循环操作,这迎合了现代编译器技术和CPU动态指令预测技术对简单循环指令的极致优化,同时RowSet的构造可以通过CPU的SIMD指令进行加速,这也比单行数据在内存中的拷贝更加高效,这使得一些结果集比较大的查询执行效率能够明显提升。
推送模型
推送模型最早在一些流媒体计算中被使用,随着大数据时代的来临,在一些基于内存设计的OLAP数据库也被大量使用起来,例如HyPer、LegoBase等。

上图展示了拉取模型和推送模型两种不同的控制流和数据流方向,从图中我们可以看出拉取模型的控制流程更符合查询执行的直观印象,上层运算符按需的向下层运算符获取数据并执行,这本质是一层层的函数嵌套调用。而推送引擎刚好相反,通过将上层的计算下推到数据产生的操作符中,由数据的最终生产者驱动上层运算符对数据进行消费。
为了更直观的比较拉取模型和推送模型对代码结构的影响,我们将图1中提到的简单查询各个运算符中next()接口的实现展开成伪代码,如下图所示:

通过上图的对比很容易可以看出,相比于拉取模型,推送模型改变了数据迭代过程中的嵌套调用关系,大大简化了查询过程中的指令跳转流程,从而使得推送模型有更好的代码局部性,优化了CPU执行效率。但是推送模型实现也更为复杂,Hyper系统通过设计模式中的Visitor模式来实现了计算推送引擎,基本思想是每个operator提供了两个接口:produce()用来生产数据,consume()接口用来消费数据,和拉取模型不同的是,consume()并不像next()那样需要关心流控逻辑,而只用关心operator本身的关系代数逻辑,流控逻辑被produce()接管。
这里有个问题是对于一些本身和流控相关的operator很难用这种模型实现,或者说反而执行效率不如拉取模型的高,例如limit、merge join、nested loop join等操作,其关系代数运算本身就和流控相关,查阅了Hyper相关论文,作者并没有详细解释怎么去解决这个问题,我的猜测是Hyper处理的场景是OLAP为主,在该场景下,流控operator出现概率是较少的,不用特别去关注它们的执行效率,并且在一些极端场景中可以将这些运算在其它算子中做特殊处理。
拉取&推送模型融合
对于一个通用的关系数据库可能不得不考虑推送模型中这些缺点,因为在OLTP场景下,merge join、nested loop join这类操作出现的频率可能远远高于hash join操作,所以在通用数据库的执行引擎中融合使用拉取模型和推送模型是一个较好的选择:在一些比较耗时的物化操作中(例如Hash Join中的hash table构建,Aggregate操作等),通过next()接口调用向下层传递一个callback函数,将耗时的阻塞运算通过callback下压到下一个阻塞操作符中,当下层运算符生产好数据后,再依次调用callback list中的回调函数。
而对于limit、merge join、nested loop join这类运算则不会通过callback下压,这种实现方式还有一个好处就是,原有的火山模型并不需要大改,同时也能发挥出推送模型的一些优势,这也是一个比较自然的权衡选择。
编译执行
拉取模型和推送模型影响的是执行流程的代码布局,但只要是解释执行,就无法避免运算符之间的虚函数调用。随着计算机硬件的发展,内存变得越来越大,这意味着越来越多的数据可以直接cache在内存中,而访问磁盘的频率被大幅度的降低,这个时候“IO墙”的效应被削弱,而由于解释执行无法感知CPU寄存器,高频的内存访问,使CPU和内存之间形成了“内存墙”效应,为了解决这个问题,越来越多的内存数据库开始使用编译执行来优化自己的查询效率,例如HyPer、MemSQL、Hekaton、Impala、Spark Tungsten等。
相比于解释执行,编译执行具有以下优点:
1. inline虚函数调用:在火山模型中,处理一行数据最少需要调用一次next()。这些函数的调用是由编译器通过虚函数调度实现(vtable),而编译执行的过程中没有函数调用,并且大量裁剪了解释执行中的流控指令,这使得CPU执行会更加高效。
2.内存和CPU寄存器中的临时数据:在火山模型中,运算符在传递行数据的时候,都需要将行数据存储在一个内存buffer中,每一次执行至少需要访问一次内存,而编译执行没有数据的迭代过程,临时数据被直接存放在CPU寄存器中(当然前提是寄存器的数量足够多),而直接访问寄存器的效率要比访问内存高一个数量级。
3. 循环展开(Loop unrolling)和SIMD:当运行简单的循环时,现代编译器和CPU是令人难以置信的高效。编译器会自动展开简单的循环,甚至在每个CPU指令中产生SIMD指令来处理多个元组。CPU的特性,比如管道(pipelining)、预取(prefetching)以及指令重排序(instruction reordering)使得运行简单的循环非常地高效。然而编译器和CPU对复杂函数调用的优化极少,而火山模型具有非常复杂的流控调用。
在OceanBase2.0中,我们利用LLVM对执行引擎中的表达式运算和PL也进行了编译执行的优化。这里主要介绍下OceanBase的表达式编译执行:

在编译阶段,主要有三个步骤:
1. IR代码生成,对于表达式(c1+c2)*c1+(c1+c2)*3,我们假设所有的类型都为bigint,通过分析表达式语义树,使用LLVM codegen的API生成IR代码如图(a)。

2. 代码优化,我们可以看到,c1+c2表达式做了两次计算,而这个表达式是可以作为公共表达式进行抽取的,经过LLVM 优化后,IR代码如图(b), 只进行了一次c1+c2的计算,总的执行命令也得到减少。另外,使用表达式解释执行时,所有的中间结果都需要在内存中物化;而编译后的代码可以将中间结果保存在CPU的寄存器中,直接用于下一步的计算,大大的提升了执行效率。LLVM还提供了很多类似的优化,我们都可以直接使用,从而大大提升表达式的计算速度。
3. 即时编译, 通过LLVM中ORC(On-RequestCompilation) JIT对优化IR代码进行即时编译,生成可执行机器码,并获取该函数指针。
结果对比
我们使用TPC-H lineitem表1G数据(约600w行),对不同数据库在同样的测试环境进行了性能测试对比,执行SQL:
SELECT SUM(CASE WHEN l_partkey IN(1,2,3,7) THEN l_linenumber + l_partkey +10 ELSE l_linenumber + l_partkey +5 END) AS result
FROM lineitem;
从上图的结果可以看出,在大数据量的情况下,编译执行相比于解释执行有明显的优势,当数据量变得更大的时候,这种优势会更加明显。但编译执行也有它本身的缺点:
- 单纯的将Volcano模型编译成代码块可能会带来函数inline后代码成倍增长,反而使得执行效率很难提升。因此单纯的拉取模型并不适合编译执行,拉取和推送结合是一个很好的选择。对于编译执行感兴趣的同学强烈推荐阅读Hyper作者Thomas Neumann的一篇论文Efficiently CompilingEfficient Query Plans for Modern Hardware,在这篇论文中作者详述了一些复杂operator的优化技巧,以及如何写编译执行代码能够使执行效率最大化。
- 编译执行的binary code生成非常耗时,往往是10+ms级别的时间开销,对于OLAP型数据库而言,编译消耗的时间并不算太坏,因为查询主要时间消耗来自于数据的计算,而对于OLTP型数据库,在一些高频的小数据查询中,这样的编译耗时是无法容忍的,OceanBase的解决方案是通过Plan Cache机制将编译的结果缓存并复用,消除同一个查询的编译次数。
写在最后
软件技术的发展总是和硬件技术的发展紧密结合在一起的,迎合硬件技术的发展而改变软件技术栈的相应策略能够使得设计的系统获得更大的受益。虽然OceanBase不是一个单纯的内存数据库,但是通过合理的分区方式,我们可以将用户访问较热的数据cache在内存中,使其近似于一个分布式的纯内存数据库,因此针对于内存数据库设计的这些优化思想也同样适合OceanBase的架构模型。
现在,OceanBase正在基于这些学术上的新思想做更多工程化的实践,比如更加普及的编译执行,计算下推,分布式并行执行等技术.同时我们也在关注列式存储格式对数据库执行引擎技术的影响,探索将列存计算引擎的一些优势融入到OceanBase的方法,强化OceanBase在分析型计算场景的执行能力,突出其HTAP数据库的定位。
相关文章:
查询引擎的演变之旅 | OceanBase原理解读
在关系型数据库中,查询调度器与计划执行器,有着与查询优化器同样重要的地位,随着计算机硬件技术的飞速进步,这两大模块的重要性日益凸显,成为提升数据库性能的关键所在。接下来,本文将由来自 OceanBase 的技…...
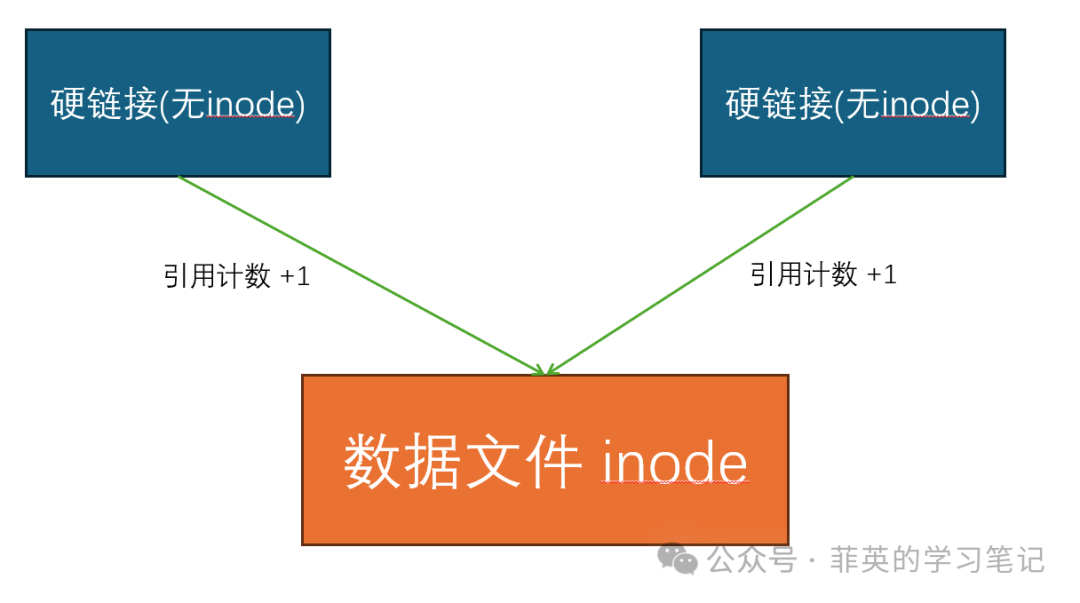
轻松理解操作系统 - Linux 软硬链接是什么?
Linux 由于其开源、比较稳定等特点统治了服务端领域。也因此,学习Linux 系统相关知识在后端开发等岗位中变得越来越重要,甚至可以说是必不可少的。 因为它的广泛应用,所以在程序员的日常工作和面试中,它都是经常出现的。它的开源特…...
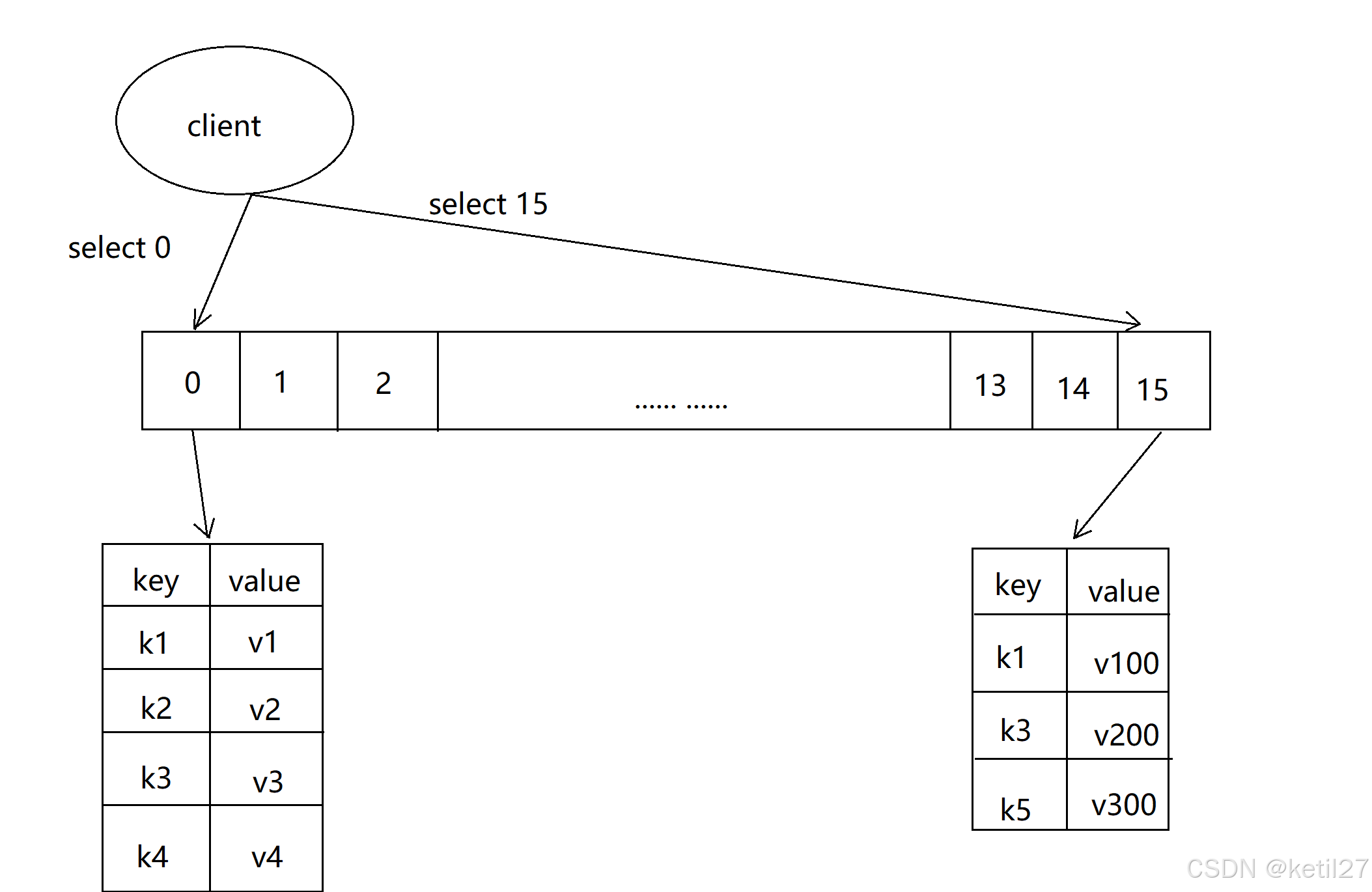
Redis - 数据库管理
Redis 提供了⼏个⾯向Redis数据库的操作,分别是dbsize、select、flushdb、flushall命令, 本机将通过具体的使⽤常⻅介绍这些命令。 一、切换数据库 select dbIndex 许多关系型数据库,例如MySQL⽀持在⼀个实例下有多个数据库存在的&#…...
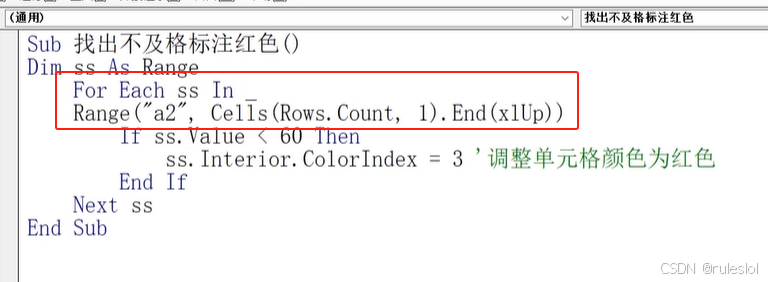
VBA02-初识宏——EXCEL录像机
一、录制宏 录制宏其实就是将一系列操作结果录制下来,并命名存储。这些操作可以是关于数据的处理、格式的设置、函数的运用等,相当于在编程语言(如VB)中定义的一个子程序。 在录制宏时,软件会记录用户执行的一系列操…...

Unity网络开发基础(part5.网络协议)
目录 前言 网络协议概述 OSI模型 OSI模型的规则 第一部分 物理层 数据链路层 网络层 传输层 第二部分 编辑 应用层 表示层 会话层 每层的职能 TCP/IP协议 TCP/IP协议的规则 TCP/IP协议每层的职能 TCP/IP协议中的重要协议 TCP协议 三次握手 四次挥手 U…...

forEach可以遍历不可枚举属性吗
首先第一个问题,forEach能不能遍历对象的属性 const obj { a: 1, b: 2, c: 3 }; obj.forEach((item) > console.log(item))运行这段代码我们发现发生了一个错误 这说明forEach是不可以遍历对象的属性的 在js中,forEach 方法用于遍历数组或类数组对象(如 NodeL…...
Docsify文档编辑器:Windows系统下个人博客的快速搭建与发布公网可访问
文章目录 前言1. 本地部署Docsify2. 使用Docsify搭建个人博客3. 安装Cpolar内网穿透工具4. 配置公网地址5. 配置固定公网地址 前言 本文主要介绍如何在Windows环境本地部署 Docsify 这款以 markdown 为中心的文档编辑器,并即时生成您的文档博客网站,结合…...
索引基础篇
前言 通过本篇博客的学习,我希望大家可以了解到 “索引” 是为了提高数据的查询效率。 索引的介绍 索引是为了提高查询数据效率的数据结构 索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着…...

多进程与多线程分不清?
多进程对应的是fork函数,而多线程对应的是thread函数。 fork 与 thread 的区别: fork开辟新进程,使用了新的资源空间,父子进程对变量的修改互不影响。由于每个进程都是独立的个体,进程间无法直接进行通信。 thread开辟…...

【零基础学习CAPL】——XML工程创建与使用详解
🙋♂️【零基础学习CAPL】系列💁♂️点击跳转 ——————————————————————————————————–—— 从0开始学习CANoe使用 从0开始学习车载测试 相信时间的力量 星光不负赶路者,时光不负有心人。 文章目录 1.概述2.XML和CAPL/.NET之间的区别…...

市场营销应该怎么学?
别一听市场营销就觉得是那些大公司玩的高深莫测的游戏,其实它就在你我身边,无处不在,影响着咱们生活的方方面面。 记得去年双十一,你是不是被各种优惠券、预售、秒杀整得头晕眼花,最后还是忍不住剁了手? …...

作为一个前端开发者 以什么步骤学习后端技术
作为一个前端开发者,学习后端技术可以按照以下步骤进行: 明确学习目标 确定方向:明确自己想学习的后端技术栈(如Node.js、Python、Java等)。 设定目标:短期目标(如完成一个简单的后端项目&…...

大数据新视界 -- 大数据大厂之经典案例解析:广告公司 Impala 优化的成功之道(下)(10/30)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...
yolov8涨点系列之Concat模块改进
文章目录 Concat模块修改步骤(1) BiFPN_Concat3模块编辑(2)在__init_.pyconv.py中声明(3)在task.py中声明yolov8引入BiFPN_Concat3模块yolov8.yamlyolov8.yaml引入C2f_up模块 在YOLOv8中, concat模块主要用于将多个特征图连接在一起。其具体…...

JavaAPI(1)
Java的API(1) 一、Math的API 是一个帮助我们进行数学计算的工具类私有化构造方法,所有的方法都是静态的(可以直接通过类名.调用) 平方根:Math.sqrt()立方根:Math.cbrt() 示例: p…...
【大模型】通过Crew AI 公司的崛起之路学习 AI Agents 的用法
AI 技术的迅猛发展正以前所未有的速度重塑商业格局,而 AI Agents,作为新一代的智能自动化工具,正逐步成为创新型公司的核心力量。在本文中,我们将探讨如何利用 AI Agents 构建一家 AI 驱动的公司,并详细了解 Crew AI 创…...
Python接口自动化测试实战
🍅 点击文末小卡片 ,免费获取软件测试全套资料,资料在手,涨薪更快 接口自动化测试是指通过编写程序来模拟用户的行为,对接口进行自动化测试。Python是一种流行的编程语言,它在接口自动化测试中得到了广泛…...

前端Web用户 token 持久化
用户 token 持久化 业务背景:Token的有效期会持续一段时间,在这段时间内没有必要重复请求token,但是pinia本身是基于内存的管理方式,刷新浏览器Token会丢失,为了避免丢失需要配置持久化进行缓存 基础思路:…...
【测试工具篇一】全网最强保姆级教程抓包工具Fiddler(2)
本文接上篇Fiddler介绍,开始讲fiddler如何使用之前,给大家讲讲http以及web方面的小知识,方便大家后面更好得理解fiddler使用。 目录 一、软件体系结构---B/S与C/S架构 B/S架构 C/S架构 二、HTTP基础知识 什么是http请求和响应? http协…...
ONLYOFFICE 文档8.2更新评测:PDF 协作编辑、性能优化及更多新功能体验
文章目录 🍀引言🍀ONLYOFFICE 产品简介🍀功能与特点🍀体验与测评ONLYOFFICE 8.2🍀邀请用户使用🍀 ONLYOFFICE 项目介绍🍀总结 🍀引言 在日常办公软件的选择中,WPS 和微软…...

告别Mac与Windows传文件烦恼:一招教你将APFS格式的移动硬盘永久改成ExFAT通用格式
跨平台文件共享终极方案:APFS与ExFAT格式深度解析与转换指南 当你在Mac上插入新买的移动硬盘准备备份重要设计稿时,系统默认将其格式化为APFS;三天后客户紧急需要修改方案,你带着硬盘赶到Windows电脑前——却发现根本无法读取内容…...

RISC-V RTOS任务栈与上下文切换:寄存器保存策略与栈初始化详解
1. 项目概述与核心问题上一篇文章我们聊了RISC-V内核单片机移植RTOS时,任务切换的“开关”——中断与异常机制是如何工作的。今天,我们顺着这个思路,深入到最核心的“现场保护”环节:当一个任务被切换出去时,它的“工作…...

【限时解密】Perplexity未公开的历史资料检索协议v2.3:仅开放给前500名深度用户的私有搜索语法手册
更多请点击: https://codechina.net 第一章:Perplexity历史资料搜索的起源与协议演进脉络 Perplexity 作为面向知识密集型任务的下一代搜索代理,并非起源于传统搜索引擎架构,而是植根于大语言模型(LLM)推理…...
)
用STM32F103C8T6驱动总线舵机:手把手教你实现机械臂逆运动学(附完整代码)
STM32F103C8T6驱动总线舵机实现机械臂逆运动学全流程解析 第一次尝试用STM32控制机械臂时,看着六个关节不知如何协调运动,直到理解了逆运动学原理才豁然开朗。本文将带你从零实现一个基于STM32F103C8T6的四自由度机械臂控制系统,重点解决如何…...

HTTPS单向认证、双向认证、抓包原理与反抓包策略详解
HTTPS单向认证、双向认证、抓包原理与反抓包策略详解 一、HTTPS单向认证 HTTPS单向认证是只要求站点部署 SSL证书,客户端会去验证服务器的身份,而服务器不会去验证客户端的身份。这种认证方式相对简单,但可以提供一定的 安全性。任何用户都可…...

时间序列预测损失函数全解析:从MSE到分位数损失的选择指南
1. 项目概述:为什么时间序列预测的损失函数值得深究?做时间序列预测,无论是金融市场的股价波动、电商平台的销量起伏,还是工业设备的传感器读数,我们最终都要面对一个核心问题:如何衡量模型预测得好不好&am…...

RISC-V双芯架构在智慧燃气报警器中的系统级设计与工程实践
1. 项目概述:当RISC-V芯遇上智慧燃气最近在深圳的智慧燃气发展论坛上,我注意到一家叫微五科技的芯片设计公司,他们带来了一套挺有意思的解决方案。核心不是别的,正是当下在嵌入式领域越来越火的RISC-V架构。他们这次重点展示的&am…...

HLS行为差异测试:挑战与LLM驱动的解决方案
1. 高层次综合(HLS)行为差异测试的挑战与机遇在AI计算和边缘计算快速发展的今天,FPGA因其可重构性和并行计算能力,成为硬件加速的重要选择。高层次综合(High-Level Synthesis, HLS)技术允许开发者使用C/C等高级语言编写算法,然后自动转换为硬…...

AUTOSAR Ea模块深度剖析:从原理到实战的EEPROM抽象层配置与优化
1. 项目概述:为什么我们需要深入理解Ea模块?在AUTOSAR的软件架构里,NVRAM管理器(NvM)负责非易失性数据的抽象管理,而Ea(EEPROM Abstraction,EEPROM抽象)模块,…...

RTOS如何通过确定性调度与内存管理增强嵌入式系统安全可靠性
1. 项目概述:为什么我们需要关注实时操作系统的安全与可靠?在嵌入式、工业控制、汽车电子乃至航空航天这些领域里,系统一旦“死机”或“反应迟钝”,后果往往不是重启一下那么简单。轻则产线停摆、设备损坏,重则可能危及…...