flink 内存配置(一):设置Flink进程内存
flink 内存配置(一):设置Flink进程内存
flink 内存配置(二):设置TaskManager内存
flink 内存配置(三):设置JobManager内存
flink 内存配置(四):内存调优和问题处理
flink 内存配置(五):网络缓存调优
Apache Flink通过严格控制各个组件的内存使用,在JVM之上提供了高效的工作负载。虽然Flink社区努力为所有配置提供合理的默认值,但由于用户部署在Flink上的应用范围很广,这并不总是可行的。为了给用户提供最大的生产价值,Flink支持对集群内的内存分配进行高层和细粒度的调优。
下面进一步描述的内存配置适用于1.10版本之后的TaskManager进程和1.11版本之后的JobManager进程。
1. 配置 Total Memory
Flink JVM进程的总进程内存(Total Process Memory)由Flink应用程序消耗的内存(Flink总内存即Total Flink Memory)和运行该进程的JVM消耗的内存组成。Flink总内存消耗包括JVM堆和非堆(直接内存或本地内存)内存的使用。如下图:

在Flink中设置内存最简单的方法是配置以下两个选项中的一个:
| Component | Option for TaskManager | Option for JobManager |
| Total Flink memory | taskmanager.memory.flink.size | jobmanager.memory.flink.size |
| Total process memory | taskmanager.memory.process.size | jobmanager.memory.process.size |
其余的内存组件将根据默认值或额外配置的选项自动调整。请参阅后面章节如何设置TaskManager和JobManager内存的其他组件。
对于本来就需要声明给Flink占用多少内存的standalone deployments部署方式来说,配置Flink总内存更合适。Flink总内存分为JVM堆内存和堆外内存。原因在于:总进程内存无关紧要,因为它也不会受控于yarn或k8s。
而对于容器化部署方式(yarn或k8s)来说,配置Flink JVM进程的总进程内存是更合适,他的大小对应于容器(container)的大小。
设置内存的另一种方法是配置Flink总内存里的各个具体组件的内存大小。具体配置见 flink 内存配置(二)和flink 内存配置(三).
上面一共说了3种配置方法:1是配置Total process memory;2是配置Total Flink memory;3是具体配置 Total Flink memory里各个组件的具体内存大小。即如下,必须显式的配置以上三种里的一种,不然flink就会启动失败。当然也不建议同时配置Total process memory和Total Flink memory,容易引发内存配置的冲突,而导致启动失败,配置其他内存组件也需要谨慎,因为它可能产生进一步的配置冲突。
| for TaskManager: | for JobManager: |
| taskmanager.memory.flink.size | jobmanager.memory.flink.size |
| taskmanager.memory.process.size | jobmanager.memory.process.size |
| taskmanager.memory.task.heap.size and taskmanager.memory.managed.size | jobmanager.memory.heap.size |
2. JVM参数
flink提供了以下jvm参数配置:
| JVM Arguments | Value for TaskManager | Value for JobManager |
| -Xmx and -Xms | Framework + Task Heap Memory | JVM Heap Memory (*) |
| -XX:MaxDirectMemorySize (always added only for TaskManager, see note for JobManager) | Framework + Task Off-heap (**) + Network Memory | Off-heap Memory (**),(***) |
| -XX:MaxMetaspaceSize | JVM Metaspace | JVM Metaspace |
说明:
(*)请记住,根据所使用的GC算法,您可能无法使用全部堆内存。有些GC算法会为自己分配一定数量的堆内存。这将导致堆监控指标返回不同的最大值。
(**)请注意,用户代码中的本地非直接内存使用也可以作为堆外内存的一部分。
(***)只有设置了相应的 jobmanager.memory.enable-jvm-direct-memory-limit 选项,才会为 JobManager 进程添加 JVM 直接内存限制。
3. 有比例限制的组件
本节将介绍一些选项的配置细节,这些选项可以是其他内存大小的一部分比值(即乘以fraction参数),同时受到 最小 - 最大范围 的限制,例如:
- JVM Overhead 可以是总进程内存的一部分。
- Network Memory可以是 Flink 总内存的一部分(仅适用于 TaskManager)。
这些组件的大小必须在最大值和最小值之间,否则Flink启动将失败。最大值和最小值有默认值,或者可以通过相应的配置选项显式设置。例如,如果你只设置以下内存选项:
- total Process memory = 1000MB,
- JVM Overhead min = 64MB,
- JVM Overhead max = 128MB,
- JVM Overhead fraction = 0.1
然后JVM Overhead值就是 1000MB x 0.1 = 100MB, 在64-128MB范围之间。
注意,如果你配置相同的最大值和最小值,它会有效地固定大小为该值。
如果不显式配置组件内存,Flink会根据总内存计算出内存大小。计算值由相应的min/max选项限制。例如,如果只设置了以下内存选项:
- total Process memory = 1000MB,
- JVM Overhead min = 128MB,
- JVM Overhead max = 256MB,
- JVM Overhead fraction = 0.1
那么 JVM Overhead 将是128MB,因为由fraction比例得出的大小是100MB,小于最小值。
如果总内存及其其他组成部分的大小已经定义,那么这个比例也可能被忽略。在这种情况下,JVM Overhead就是总内存的剩余部分。派生值仍然必须在其最小/最大范围内,否则配置将失败。例如,假设只设置了以下内存选项。
- total Process memory = 1000MB,
- task heap = 100MB, (similar example can be for JVM Heap in the JobManager)
- JVM Overhead min = 64MB,
- JVM Overhead max = 256MB,
- JVM Overhead fraction = 0.1
进程总内存的所有其他组件都有默认值,包括默认 Managed Memory 分数(或 JobManager 中的 Off-heap Memory)。那么JVM Overhead 不是这个部分(1000MB x 0.1 = 100MB),而是整个进程内存的剩余部分,这些部分要么在64-256MB范围内,要么失败。
参考网址:
https://nightlies.apache.org/flink/flink-docs-release-1.20/docs/deployment/memory/mem_setup/
相关文章:
flink 内存配置(一):设置Flink进程内存
flink 内存配置(一):设置Flink进程内存 flink 内存配置(二):设置TaskManager内存 flink 内存配置(三):设置JobManager内存 flink 内存配置(四)…...

贪心算法习题其三【力扣】【算法学习day.20】
前言 ###我做这类文档一个重要的目的还是给正在学习的大家提供方向(例如想要掌握基础用法,该刷哪些题?)我的解析也不会做的非常详细,只会提供思路和一些关键点,力扣上的大佬们的题解质量是非常非常高滴&am…...

速盾:高防cdn针对网站的好处有哪些?
高防CDN(Content Delivery Network)是一种网络分发技术,它能够提供可靠的网站高防护服务,有效地解决了网站遭受DDoS攻击、恶意流量等网络安全问题。高防CDN的应用已经变得越来越广泛,对于网站的好处也变得越发明显。 …...
和接口(interface)有什么异同?)
【Java SE语法】抽象类(abstract class)和接口(interface)有什么异同?
目录 1. 抽象类与接口的基本概念 1.1 抽象类 1.2 接口 2. 抽象类与接口的异同 2.1 相同点 2.2 不同点 3. 拓展知识:多态与设计模式 3.1 多态 3.2 设计模式 4. 结论 在软件工程中,设计模式和代码结构的选择对于构建可维护、可扩展的系统至关重要…...

京准同步:GPS北斗卫星授时服务器发展趋势介绍
京准同步:GPS北斗卫星授时服务器发展趋势介绍 京准同步:GPS北斗卫星授时服务器发展趋势介绍 GPS北斗卫星授时服务器的发展趋势紧密围绕着不断提升的时间同步精度、可靠性、安全性,以及适应广泛应用场景的需求展开,以下是卫星授时…...
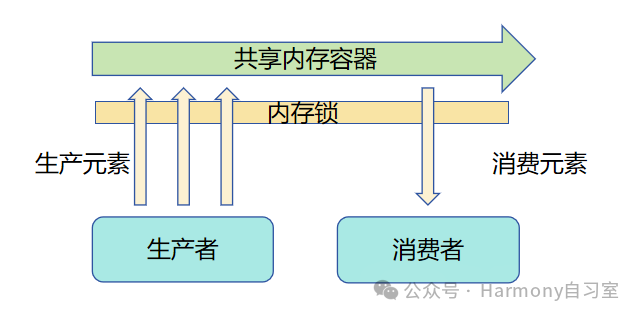
鸿蒙多线程开发——并发模型对比(Actor与内存共享)
1、概 述 并发是指在同一时间段内,能够处理多个任务的能力。为了提升应用的响应速度与帧率,以及防止耗时任务对主线程的干扰,HarmonyOS系统提供了异步并发和多线程并发两种处理策略。 异步并发:指异步代码在执行到一定程度后会被…...

【计算机网络】章节 知识点总结
一、计算机网络概述 1. 计算机网络向用户提供的两个最重要的功能:连通性、共享 2. 因特网发展的三个阶段: 第一阶段:从单个网络 ARPANET 向互联网发展的过程。1983 年 TCP/IP 协议成为 ARPANET 上的标准协议。第二阶段:建成三级…...

开箱即用!265种windows渗透工具合集--灵兔宝盒
【渗透工具箱】灵兔宝盒-Rabbit_Treasure_Box_V1.0.1 介绍 Rabbit_Treasure_Box_V1.0.1是一款Windows渗透工具箱,集成Dawn Launcher管理,便捷备份更新。内含脚本工具及在线安全工具,覆盖信息收集、漏洞利用、逆向破解、蓝队防御等多领域&am…...

怎么在哔哩哔哩保存完整视频
哔哩哔哩(B站)作为一个集视频分享、弹幕互动于一体的平台,吸引了大量用户。许多人希望能够将自己喜欢的完整视频保存到本地,以便离线观看或分享。直接下载视频的功能并不总是可用,因此,本文将介绍几种在哔哩哔哩上保存完整视频的方…...

CPU算法分析LiteAIServer视频智能分析平台视频智能分析:抖动、过亮与过暗检测技术
随着科技的飞速发展,视频监控系统在各个领域的应用日益广泛。然而,视频质量的好坏直接影响到监控系统的效能,尤其是在复杂多变的光照条件下和高速数据传输中,视频画面常常出现抖动、过亮或过暗等问题,导致监控视频难以…...

fastGPT调用stable diffusion生成图片,本地模型使用ollama
ps:192.168.1.100换成你的ip 一、开器stable diffusion的api访问 Git上copy的项目,在启动web-ui.bat/sh时加上--api的启动参数. /web-ui.bat --api我这里使用的stabble-diffusion-docker构建的默认就开启了 http://192.168.1.100:7860/docs 二…...

【jmeter】jmeter的线程组功能的详细介绍
初衷 之前在公司做的性能测试基本上都是关于数据库的,针对接口的性能测试还是比较少一点。考虑到后边大模型问答产品的推广,公司方面也要求对相关接口进行压测,也趁着这个机会,对jmeter进行深入研究,进一步加强自己性…...

高边坡安全监测系统的工作原理和应用领域
高边坡安全监测系统的工作原理主要依赖于各种先进的传感器设备,这些传感器能够实时地捕捉和记录边坡的位移、应力、裂缝、倾斜和沉降等多种关键数据。这些数据的采集是通过高精度的监测设备进行的,确保了数据的准确性和可靠性。采集到的数据随后通过高效…...

Java:多态的调用
1.什么是多态 允许不同类的对象对同一消息做不同的响应。即同一消息可以根据发送对象的不同而采用多种不同的行为方式。(发送消息就是函数调用)。多态使用了一种动态绑定(dynamic binding)技术,指在执行期间判断所引用…...

A day a tweet(seventeen)——Visualize Convolution Neural Network!
a.形象化地CNNs visually explained! . .CNN(Convolution Neural Network) 卷积神经网络 a.不可思议的,难以置信的 v.使形象化CNN explainer is an incredible interactive tool to visualize the internal workings of a CNN. n.解释器;讲解员 …...

卡达掐发展史
自行车是一种简单而又伟大的交通工具。自从19世纪诞生以来,它不仅改变了人们的出行方式,也深刻地影响了我们的生活方式、城市布局以及健康观念。作为一种绿色、经济的出行工具,自行车至今仍在全球范围内被广泛使用。本文将从自行车的历史、结…...

UI界面设计入门:打造卓越用户体验
互联网的迅猛发展催生了众多相关职业,其中UI界面设计师成为互联网行业的关键角色之一。UI界面设计无处不在,影响着网站、应用程序以及其他数字平台上的按钮、菜单布局、色彩搭配和字体排版等。UI设计不仅仅是字体、色彩和导航栏的组合,它的意…...

【Linux:tcp三次握手和四次挥手】
目录 三次握手: 两次握手 丢包问题与乱序问题 四次挥手 为什么客户端需要等待超时时间? TCP报文中含有SYN、ACK、FIN等标识,把这些标识设置1就是开启这些标识,设置为0就是关掉这些标识 三次握手: 在客户端发送tc…...

大数据Informatica面试题及参考答案
目录 什么是 Informatica?它主要解决什么问题? 什么是 Informatica PowerCenter? Informatica PowerCenter 的主要组成部分有哪些? 解释 Informatica PowerCenter 的主要组件。 Informatica PowerCenter 与 DataStage 有何区别? 解释 Informatica 中的源 (Source) 和…...
--- 论文实战)
Gradient Boosting Regressor(GBDT)--- 论文实战
一、前言 在《机器学习论文复现实战---linear regression》中通过Pearson 相关性分析,去除了2个高相关性特征 "PN" 和 "AN" ,数据维度变为890*25。(数据集地址) 这里我们不做任何前期处理,直接就将数据放入 GBDT 模型中进行训练了。 二、模型训练过程…...

对服务器网络参数具体相关概念
你问到了 高并发系统真正的“全链路瓶颈” 问题,非常关键! 要真正理解“一个请求从用户到服务器再返回”到底经历了什么、哪里可能卡住,确实不能只看 CPU —— 网卡、网络带宽、协议开销、包大小、运营商、甚至流量套餐,都会影响整…...

抖音批量下载开源工具:3个核心模块打造高效无水印下载工作流
抖音批量下载开源工具:3个核心模块打造高效无水印下载工作流 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback…...

AArch64调试异常机制与自托管调试实践
1. AArch64调试异常机制概述在AArch64架构中,调试异常是处理器响应调试事件的核心机制。当程序执行过程中遇到预设的调试条件时,处理器会暂停正常执行流,转而进入异常处理流程。这种机制使得开发者能够在不引入额外硬件调试器的情况下&#x…...

仿真流程专题——基于Workbench的随机振动工程实践与3σ准则应用
1. 随机振动分析入门:从理论到工程实践 第一次接触随机振动分析时,我和大多数工程师一样感到困惑——这种"不确定"的载荷到底该怎么分析?经过多个项目的实战,我发现用生活中的例子最容易理解:想象你在颠簸的…...

普通工程师堆起来的人海战术,作用其实很有限
普通工程师堆起来的人海战术,作用其实很有限。为什么这么说?因为芯片项目需要的是那些不可堆积的优势。什么叫不可堆积?就是你招10个普通工程师,也顶不上一个顶尖架构师的价值。架构设计能力、关键IP的积累、底层算法的创新——这些东西不是靠加班加点就能搞出来的…...
)
Langchain的学习(一)
目录 一,实操 编码 Runnable Runnable 是什么 核心方法(所有 Runnable 都有) 最关键能力:用 | 组合(LCEL) 常用内置 Runnable 总结 二,聊天模型-核心能力 定义模型 init_chat_model 本地部署 调用工具 定义工具-Tool version1 schema: version2(基于…...

实测 DeepSeek-V4 接入 Hermes:一句话爬取几十个网页,真的丝滑!
你好,我是郭震OpenClaw龙虾使用有一段时间了,体感很好,即便使用本地模型,如Qwen3.5:9B这样的模型,养虾Token自由,回复也比较丝滑。如下所示,轻松生成HTML风格的文件结构树:也能轻松生…...

STM32F4/F7上跑AI手写识别:从CUBEMX配置到串口通信的完整避坑指南
STM32F4/F7实战AI手写识别:从模型部署到数据处理的工程化解决方案 在嵌入式设备上部署神经网络进行手写识别,正逐渐从实验室走向工业现场。STM32F4/F7系列凭借其平衡的性能与功耗,成为边缘AI应用的理想选择。本文将深入探讨从模型准备到实际部…...

保姆级教程:解决PyTorchViz安装报错,手把手教你用AlexNet模型可视化
PyTorch模型可视化实战:从安装报错到AlexNet结构解析全指南 在深度学习模型开发过程中,可视化工具如同开发者的"第二双眼睛"。PyTorchViz作为PyTorch生态中轻量级但功能强大的可视化工具,能直观展示模型的计算图结构,帮…...

WebPlotDigitizer技术架构深度解析:计算机视觉驱动的图表数据提取引擎
WebPlotDigitizer技术架构深度解析:计算机视觉驱动的图表数据提取引擎 【免费下载链接】WebPlotDigitizer Computer vision assisted tool to extract numerical data from plot images. 项目地址: https://gitcode.com/gh_mirrors/we/WebPlotDigitizer 在科…...