贝式计算的 AI4S 观察:使用机器学习对世界进行感知与推演,最大魅力在于横向扩展的有效性
「传统研究方法高度依赖于科研人员自身的特征和问题定义能力,通常采用小数据,在泛化能力和拓展能力上存疑。而 AI 研究方法则需要引入大规模、高质量数据,并采用机器学习进行特征抽取,这使得产生的科研结果在真实世界的问题中非常有效」。
OpenBayes贝式计算创始人王臣汉在 COSCon’24 的 AI for Science 论坛中,以「AI 驱动的科研新范式:⼈⼯智能对统计⽅法的全⾯升级」为题,分享了其面向 AI4S 发展的观点。HyperAI超神经在不违原意的基础上,对其分享内容进行了整理汇总,以下是精彩实录。
机器学习是统计学的有效应用
OpenBayes贝式计算是国内领先的人工智能服务商,在赋能国内一流高校及研究机构的过程中,我们观察到,在科研领域,尤其是理工科研究中,AI 技术和方法的应用规模正在大幅上升。今天,我想和大家分享的是,AI、机器学习为何能够成为科研领域与工业研究领域的全新范式。
机器学习理论于上世纪 90 年代便已经建立,尽管经历了多年的迭代发展,但从该领域目前的 backbone 来看,机器学习仍然没有脱离传统统计学的范畴,这也是 AI 为人所诟病的重要原因之一,即统计系统缺乏可解释性。
相信大家对于我们公司的名字并不陌生——OpenBayes贝式计算,除了人们熟知的利用贝叶斯公式来完成自动化系统的复杂运算外,我们也认为机器学习就是统计学中的贝叶斯学派。

其中,监督学习在工业应用和科研领域更加可靠。尤其是在科研领域,更加依赖于被标注的、结构化的数据,通过对这些数据集进行多种模型结构式的建模,来解析具体的科研问题。在这个过程中,我认为科研的本质是通过统计、解析研究人员收集的研究样本,从而反应真实世界中的问题。

规模数据 X 模型结构 = AI 科研成绩 - 传统研究
不久前,AlphaFold 摘冠诺贝尔化学奖,引发大家的广泛讨论。其实 AlphaFold 近几年一直在迭代升级,超越人类极限,实现了对人类蛋白质组的相对准确的预测。AlphaFold 1 始于 2018 年,在第 13 届 CASP (Critical Assessment of protein Structure Prediction) 中,准确地从 43 种蛋白质中预测出了 25 种蛋白质的结构。而同组比赛中获得第二名的参赛者仅准确预测出了 3 种。
到 2020 年,Google DeepMind 将其升级为 AlphaFold 2,在蛋白质结构预测方面的准确率能够达到 94%-98%,对制药领域起到了参考性意义,甚至对冷冻电镜等观测手段能够实现 85%-90% 以上的替代。同时,当人类掌握了蛋白质结构的奥秘,那么在抗体和生物制药的研究上,也就掌握了最为有效的即时性工具。相信这也是 AlphaFold 能够荣获诺贝尔奖的重要原因。
除了 AlphaFold 的案例外,我还想介绍一下与贝式计算合作的国内知名研究者,北京大学人工智能研究院施柏鑫教授团队发表的论文「EventPS: Real-Time Photometric Stereo Using an Event Camera」,已经入选 CVPR 2024 最佳论文。

该研究入选 CVPR 2024 最佳论文
该研究通过事件触发与表⾯法线建立关联的「零化向量」信息,利⽤最优化与深度学习分别实现了光度立体表⾯法线估计的求解,配合⾃研的⾼速转台所搭建的数据采集系统,和经过 GPU 优化的算法,实现了超过 30 帧每秒的实时表⾯法线重建。
- 论文地址:
https://openaccess.thecvf.com/content/CVPR2024/papers/Yu_EventPS_Real-Time_Photometric_Stereo_Using_an_Event_Camera_CVPR_2024_paper.pdf
总结来看,基于二维信息的三维信息模型重建一直是学术领域的研究重点之一,因为无论是从宏观还是微观的角度,人类都有对真实世界的理解需求。而 AlphaFold 便是将一维的化学、生物信息在空间中进行重构,EventPS 是通过事件相机来还原物体的三维轮廓。
上述介绍的两个案例展示了机器学习方法推动前沿研究多带来的价值,针对于此,借助贝式对科研群体的观察,我总结出了一个简单的公式:规模数据 X 模型结构 = AI 科研成绩 - 传统研究。
具体而言,在科研过程中,将规模化的数据应用于有效的模型结构上,能够起到「乘积」的作用,能在任何一个工业领域的落地研究课题上大幅超越传统方法,这便是 AI 驱动的科研能够在近两年内实现了 2-5 倍增长的重要原因。
而我们提出的公式之所以是乘积而非加法,核心原因在于单独依靠某一个参数的增长,其所得到的效果都不是很明显。如果保持模型结构不变而一味地增加数据量,则可能会产生边际效应,导致性能提升困难;同样地,当数据规模一定时,模型参数也并非越大越好。
如下图所示,如果使用线性函数对一组数据进行二分类任务,可以看到一元的线性函数有效性很有限;如果我们上升为二元函数,能够看到,虽然有部分样本错误,但整体实现了泛化;进而,如果在数据不变的情况下,继续提供更高维的函数或更大参数规模的模型来拟合数据集,所得结果的拟合度和预测准确度是非常高的,但同时也会导致过拟合问题,使得模型丧失在该数据集之外的泛化能力。
所以,数据规模并不是越大越好,模型复杂度也不是越高越好。

近年来,业界激烈探讨的 Scaling Law 也提到,只有当数据规模和参数规模都同等增大时,模型 loss 函数的下限,也就是其预测的失误率将会下探到一个较低水平,这个水平是较小规模的数据和较小参数规模的模型无法实现的。

监督式学习推动科学研究创新升级
聚焦到科研领域,通常还是使用监督式学习的方法来推动科学研究。
监督式学习的本质是抽样调查,通过科研人员手中的数据集和样本来尝试解决真实世界的问题。当数据集规模与模型规模、复杂度同时扩大时,本质上是学习样本变得更大了,研究人员得以在更大规模想样本中抽取更多特征。这便是机器学习的优势所在,即将定义特征与抽取特征的工作从研究者手中解放出来。

其更高层次的价值在于,当数据集中的特征过于复杂时,人脑很难抽取其中的主要特征、并分配相应的权重,但机器学习能够自动化提取特征,能够很好的解决大规模样本的特征提取,而越大规模的样本和模型结构越能拟合真实世界的问题。
不妨大胆推断,当机器学习变得更加成熟后,科研人员的主要工作就变成了定义问题、提升并提纯手中的数据集规模,以及选定合适的机器学习模型。这也将带来一个划时代的创新,工业研究、理工科研究能够像工厂制作产品一样以流水线的形式进行生产。
使用机器学习对世界进行认知/感知与推演
贝式计算相信,随着 AI 在科研领域的落地和新范式的不断推广,人类正面临一个类似于寒武纪时代的大爆发,几乎每一个工业、理工科研领域的前沿都会被推进。
我们认为,机器学习对科研领域的促进将体现在两个方面,其一是使⽤机器学习对世界进⾏认知/感知,其二是使⽤机器学习对世界进⾏推演。
其中,在感知侧最大的推动来自于机器学习方法对世界进行超采样。
人类感知世界主要依赖眼耳口鼻等感官,在计算机领域可以理解为使用传感器和大规模数据记录来对世界进行采样,而当人们拥有更大规模的数据集后,使用机器学习的方法就可以对采样的精度和规模进行成比例的扩增,这也是使用机器学习认知世界的本质。

换言之,机器学习加强了对世界的感知,从而帮助人们对世界的本质展开研究。
举例来看,中科院、上海交通大学等高校、研究机构,已经开始利用机器学习处理质谱和光谱数据,例如使用机器学习对光谱进行建模,从而提高地底矿物发现的准确率。

此外,在使用机器学习对世界规律进行推演方面,我想分享的是时序数据的研究范式。
时序数据就是在时间序列上对事物的发展进行量化的定义,最常见的就是股市数据、降雨量、气温变化等等,都是时序数据。在 AI 领域,大语言模型的本质就是将人类语言或知识使用文本方式进行表达的同时,将文本的序列当做一种时序数据来进行理解,预测前述输入文字所带来的下一个 token 出现的概率。
总结来看,时序数据能够表达事物的前沿发展运行规律,那么,我们自然可以使用机器学习来拟合大量的数据,进而根据前序输入的数据来推演后续输出的数据。
举例来看,在气象领域,中国、美国、法国等国家的各类科研院所都在积极地将机器学习模型应用到各维度的预测中,目前的气象预测不仅扩摸扩大、预测时间延长,而且精度也在不断提高。
可以看到,从认知到推演,这是机器学习在科研领域最有可能批量产出科研结果的两个方向。
传统研究方法 vs. AI 研究方法
在此,我将传统研究方法与 AI 的研究方法进行了对比。

传统研究方法高度依赖于科研人员自身特征和问题定义能力,只采用「小数据」。而一旦数据量较小,研究成果在工业领域或更广泛的人类社会中进行拓展应用时就会存疑。
当科研领域引入 AI 时,首先需要引入大规模的数据,人们使用机器学习模型进行相关特征的抽取,正如刚刚所讲,只要使用规模性的数据和有效的模型结构,就能带来科研领域的突破性进展。通常而言,如此产生的科研结果在真实社会的真实问题应用中仍然有效,这也恰恰是 AI 推动科研的最大魅力,即横向扩展中的有效性。
OpenBayes贝式计算打造集群软件
最后为大家介绍一下 OpenBayes贝式计算,我们是国内相对领先的人工智能服务商,在集群构架、编译器和模型结构领域拥有丰富的创新成果与产品。目前 OpenBayes 的模型构件系统已经被超过百家企业和研究机构所采用,进行私有部署。同时,我们的线上公开服务注册用户已经超过 17 万,其中大多数是终端工程师及科研领域的学者,重点用户覆盖了国内的双一流 985、211 高校的工科和工业研究机构,例如清华大学、北京大学、天津大学、上海交大等等。
我们面向 AI for Science 提供的工具集能够端到端覆盖人工智能模型研发的全生命周期,将全球的开源数据集和大量 AI、HPC 领域的教程,同时还预置了开源和私有模型,将科研领域的要素整合到一个集群软件中,这也是我们公司的主要产品——OpenBayes。我们将其部署在 NVIDIA 及其他国产芯片的计算集群中,为科研人员和团队提供开箱可用的服务,帮助科研人员在模型构建、模型推理、工业软件计算等方面实现一站式衔接。
整个套件能够能够将模型训练成本降低到常规 AI 构建此水准模型成本的 8.25%,例如,过去需要数千万集群才能完成的计算,基于 OpenBayes 的软件成本能够降低至数十万。
也正是基于对 AI for Science 领域的深度赋能,我们观察到,目前在科研领域,仍然有大量 AI 仍未触达、有待开垦的领域,我们也相信,科研领域的寒武纪时代即将到来,几乎所有的工业研究、理工科研究都将落地 AI 范式及方法。
相关文章:
贝式计算的 AI4S 观察:使用机器学习对世界进行感知与推演,最大魅力在于横向扩展的有效性
「传统研究方法高度依赖于科研人员自身的特征和问题定义能力,通常采用小数据,在泛化能力和拓展能力上存疑。而 AI 研究方法则需要引入大规模、高质量数据,并采用机器学习进行特征抽取,这使得产生的科研结果在真实世界的问题中非常…...
容器化技术入门:Docker详解
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 容器化技术入门:Docker详解 容器化技术入门:Docker详解 容器化技术入门:Docker详解 引言 Doc…...
框架的药房管理系统)
基于SSM(Spring + Spring MVC + MyBatis)框架的药房管理系统
基于SSM(Spring Spring MVC MyBatis)框架的药房管理系统 项目概述 功能需求 用户管理:管理员可以添加、删除、修改和查询用户信息。药品管理:支持对药品信息的增删改查操作,包括药品名称、价格、库存量等。供应商…...

在服务器里安装2个conda
1、安装新的conda 下载地址:Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 本文选择:Anaconda3-2023.03-1-Linux-x86_64.sh 安装:Ubuntu安装Anaconda详细步骤(Ubuntu22.04.1ÿ…...

web安全漏洞之ssrf入门
web安全漏洞之ssrf入门 1.什么是ssrf SSRF(Server Side Request Forgery,服务端请求伪造)是一种通过构造数据进而伪造成服务端发起请求的漏洞。因为请求是由服务器内部发起,所以一般情况下SSRF漏洞的目标往往是无法从外网访问的内系统。 SSRF漏洞形成的原理多是服务…...

《NoSQL 基础知识总结》
在当今的数据存储和管理领域,NoSQL 数据库正逐渐崭露头角,成为许多应用场景下的有力选择。今天,我们就来一起深入了解一下 NoSQL 的基础知识吧。 一、什么是 NoSQL? NoSQL,即 “Not Only SQL”,它是一种不…...

高校宿舍信息管理系统小程序
作者主页:编程千纸鹤 作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参…...

2.索引:MySQL 索引分类
MySQL中的索引是提高数据查询速度的重要工具,就像一本书的目录,可以帮助我们快速定位到所需的内容。选择适合的索引类型对数据库设计和性能优化至关重要。本文将详细介绍MySQL中常见的索引类型,并重点讲解聚集索引和二级索引的概念及应用。 1…...

sklearn红酒数据集分类器的构建和评估
实验目的: 1. 掌握sklearn科学数据包中决策树和神经网络分类器的构建 2. 掌握对不同分类器进行综合评估 实验数据: 红酒数据集 红酒数据集利用红酒的化学特征来描述三种不同类型的葡萄酒。 实验内容与要求: 解压文件得到wine数据。利用pa…...

【IC验证面试常问-4】
IC验证面试常问-4 1.11 struct和union的异同1.13 rose 和posedge 的区别?1.14 semaphore的用处是什么?1.15 类中的静态方法使用注意事项有哪些?1.16 initial和final的区别? s t o p , stop, stop,finish的区别1.17 logic,wire和re…...

【数据集】【YOLO】【目标检测】交通事故识别数据集 8939 张,YOLO道路事故目标检测实战训练教程!
数据集介绍 【数据集】道路事故识别数据集 8939 张,目标检测,包含YOLO/VOC格式标注。数据集中包含2种分类:{0: accident, 1: non-accident}。数据集来自国内外图片网站和视频截图。检测范围道路事故检测、监控视角检测、无人机视角检测、等&…...
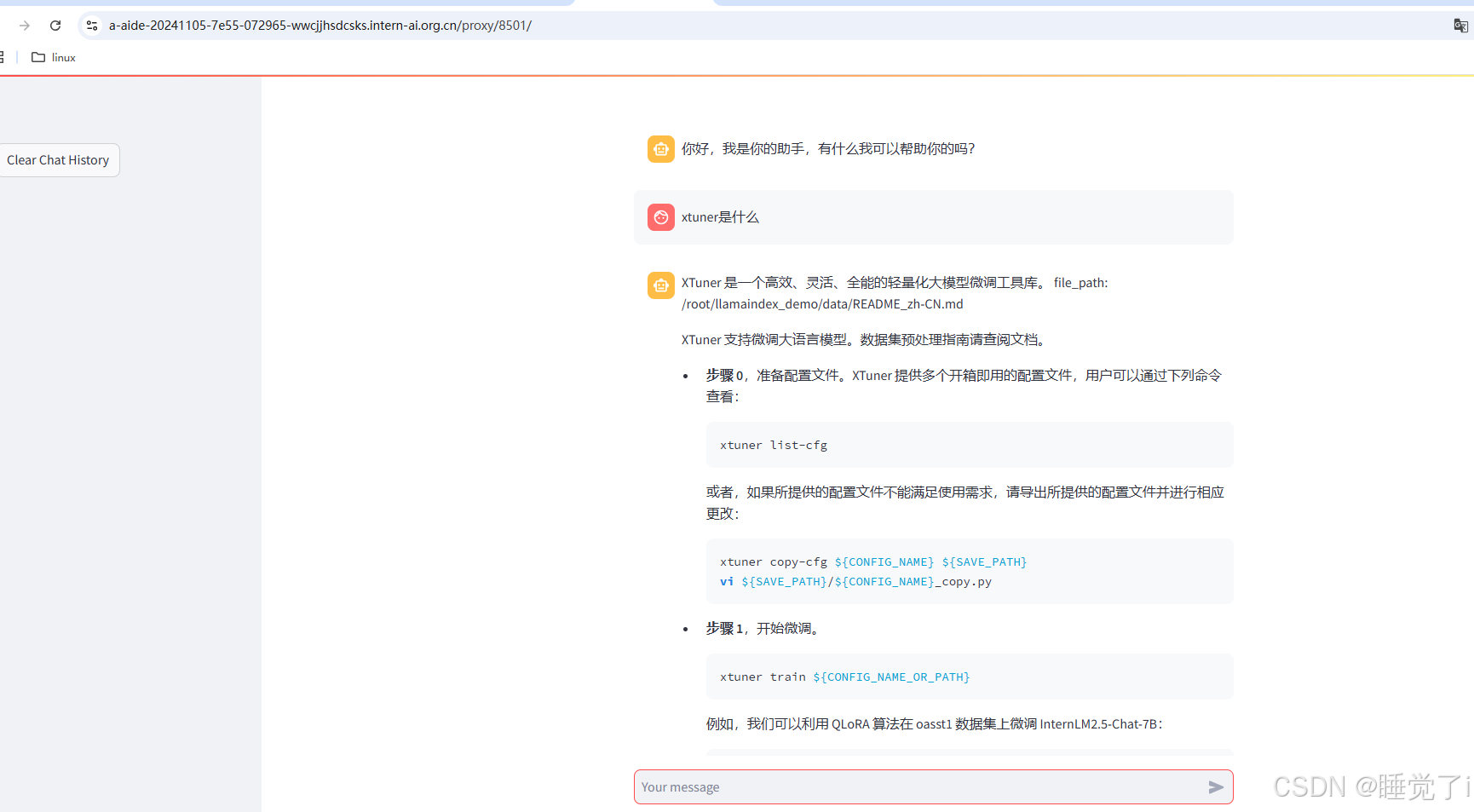
书生浦语第四期基础岛L1G4000-InternLM + LlamaIndex RAG 实践
文章目录 一、任务要求11.首先创建虚拟环境2. 安装依赖3. 下载 Sentence Transformer 模型4.下载 NLTK 相关资源5. 是否使用 LlamaIndex 前后对比6. LlamaIndex web7. LlamaIndex本地部署InternLM实践 一、任务要求1 任务要求1(必做,参考readme_api.md&…...

基于ViT的无监督工业异常检测模型汇总
基于ViT的无监督工业异常检测模型汇总 论文1:VT-ADL: A Vision Transformer Network for Image Anomaly Detection and Localization(2021)1.1 主要思想1.2 系统框架 论文2:Inpainting Transformer for Anomaly Detection…...

数据库管理-第258期 23ai:Oracle Data Redaction(20241104)
数据库管理258期 2024-11-04 数据库管理-第258期 23ai:Oracle Data Redaction(20241104)1 简介2 应用场景与有点3 多租户环境4 特性与能力4.1 全数据编校4.2 部分编校4.3 正则表达式编校4.4 随机编校4.5 空值编校4.6 无编校4.7 不同数据类型上…...

运放进阶篇-多种波形可调信号发生器-产生方波-三角波-正弦波
引言:前几节我们已经说到硬件相关基础的电路,以及对于运放也讲到了初步的理解,特别是比较器的部分,但是放大器的部分我们对此并没有阐述,在这里通过实例进行理论结合实践的学习。而运放真正的核心,其实就是…...

CSS中的变量应用——:root,Sass变量,JavaScript中使用Sass变量
:root—— 原生CSS 自定义属性(变量) 在 SCSS 文件中定义 CSS 自定义属性。然后通过 JavaScript 读取这些属性。 // variables.scss :root { --login-bg-color: #293146;--left-menu-max-width: 200px;--left-menu-min-width: 64px;--left-menu-bg-…...

WPF+MVVM案例实战与特效(二十八)- 自定义WPF ComboBox样式:打造个性化下拉菜单
文章目录 1. 引言案例效果3. ComboBox 基础4. 自定义 ComboBox 样式4.1 定义 ComboBox 样式4.2 定义 ComboBoxItem 样式4.3 定义 ToggleButton 样式4.4 定义 Popup 样式5. 示例代码6. 结论1. 引言 在WPF应用程序中,ComboBox控件是一个常用的输入控件,用于从多个选项中选择一…...

速盾:怎么使用cdn加速?
CDN(Content Delivery Network)即内容分发网络,是一种通过在网络各处部署节点来缓存和传输网络内容的技术。通过使用CDN加速,可以提高网站的访问速度、减轻服务器负载、提供更好的用户体验。 使用CDN加速的步骤如下: …...

C++ 优先算法 —— 三数之和(双指针)
目录 题目:三数之和 1. 题目解析 2. 算法原理 ①. 暴力枚举 ②. 双指针算法 不漏的处理: 去重处理: 固定一个数 a 的优化: 3. 代码实现 Ⅰ. 暴力枚举(会超时 O(N)) Ⅱ.…...

YOLOv7-0.1部分代码阅读笔记-yolo.py
yolo.py models\yolo.py 目录 yolo.py 1.所需的库和模块 2.class Detect(nn.Module): 3.class IDetect(nn.Module): 4.class IAuxDetect(nn.Module): 5.class IBin(nn.Module): 6.class Model(nn.Module): 7.def parse_model(d, ch): 8.if __name__ __main__…...

zen-rails-security-checklist测试策略:安全测试用例与自动化扫描
zen-rails-security-checklist测试策略:安全测试用例与自动化扫描 【免费下载链接】zen-rails-security-checklist Checklist of security precautions for Ruby on Rails applications. 项目地址: https://gitcode.com/gh_mirrors/ze/zen-rails-security-checkli…...
的作用分析)
射频链路中 Coupler(耦合器)的作用分析
射频链路中 Coupler(耦合器)工程解析报告 ——原理、系统作用、工程实现及 Bi‑Directional Coupler 全解 1. Coupler 在射频链路里“到底起什么作用”(工程结论) Coupler 的本质作用只有一句话: 在**“不显著影响主射频链路”的前提下,抽取一小部分、方向可控的射频能量…...

基于STM32F401与TM8211的I2S音频播放系统:从WAV解析到硬件驱动全解析
1. 硬件选型与系统架构设计 第一次接触音频项目时,我被各种专业术语搞得晕头转向。后来发现,用"音乐快递员"的比喻就能轻松理解整个系统:STM32F401是快递分拣中心,I2S是运送音乐包裹的高速公路,TM8211则是把…...

揭秘哔咔漫画下载器:打造高效离线漫画图书馆的完全指南
揭秘哔咔漫画下载器:打造高效离线漫画图书馆的完全指南 【免费下载链接】picacomic-downloader 哔咔漫画 picacomic pica漫画 bika漫画 PicACG 多线程下载器,带图形界面 带收藏夹,已打包exe 下载速度飞快 项目地址: https://gitcode.com/gh…...

ECU软件刷写核心:拆解UDS的34/36/37服务,如何像拷贝文件一样传输数据?
ECU软件刷写核心:拆解UDS的34/36/37服务,如何像拷贝文件一样传输数据? 想象一下,你需要将一部高清电影从电脑传输到手机——这个过程需要稳定的连接、合理的分块大小和可靠的数据校验。在汽车电子领域,ECU软件刷写同样…...

数据笔记:LargeST——如何构建与评估一个面向未来的大规模交通预测基准数据集
1. 为什么我们需要LargeST这样的交通预测基准数据集 交通预测是智慧城市建设的核心技术之一,但长期以来这个领域面临一个尴尬局面:算法模型越来越复杂,却缺乏足够规模和质量的数据来验证其真实效果。这就像给赛车手一辆玩具车来测试性能——模…...

构建本地化个人助理系统:事件驱动架构与模块化设计实践
1. 项目概述:一个高度可定制的个人助理系统最近在GitHub上看到一个挺有意思的项目,叫“Personal-Assistant”,作者是idk-man69。光看名字,你可能会觉得这又是一个类似Siri或Google Assistant的语音助手,但点进去仔细研…...

告别ET1100?聊聊AX58100这颗高性价比EtherCAT从站芯片的升级体验
告别ET1100?AX58100高性价比EtherCAT从站芯片的工业升级实战 当工业设备制造商面临从传统控制架构向实时以太网迁移时,EtherCAT从站芯片的选型往往成为关键转折点。十年前,ET1100凭借其稳定的性能和相对友好的开发门槛,成为许多工…...

Ruby中文分词利器Rurima:纯Ruby实现的高性能分词引擎详解
1. 项目概述:一个为Ruby打造的现代中文分词引擎在Ruby社区里,处理中文文本一直是个有点“硌脚”的活儿。如果你做过中文搜索、内容分析或者简单的词频统计,肯定遇到过这个经典难题:怎么把一串连续的中文字符,准确地切割…...

如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南
如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 您是否梦想过在任何设备上畅玩PC游戏&#x…...