SelfAttention在Ascend上的实现
1 SelfAttention是什么?
Self-Attention(自注意力)机制是深度学习领域的一种重要技术,尤其在自然语言处理(NLP)任务中得到广泛应用。它是 Transformer 架构的核心组成部分之一,由 Vaswani 等人在 2017 年提出的论文《Attention is All You Need》中首次介绍。Self-Attention 机制使模型能够在处理序列数据时关注到输入序列的不同部分,从而更好地捕捉上下文关系。
以下介绍来自于知友晚安汤姆布利多的博客,写的非常好,通俗易懂,这里直接引用了。
从零实现Transformer
注意力机制简介
其实注意力机制并不是一个新鲜概念,而且这一概念也不仅仅局限于深度学习领域。以我们人类为例,当我们在通过面相判断一个人的性别时,那么我们人眼的注意力可能就主要放在这个人的脸上,看鼻子、眼睛、耳朵等。当我们通过肢体动作判断运动员所从事的运动时,可能又会关注这个人手脚的肢体动作,而不关注这个人的长相。这一现象在神经网络中也存在(神经网络和人类的感知机理完全不同,仅作类比),如下图图2所示:

上图中,热力图的颜色越深表示网络对这一区域的关注程度越高。可以看到,边牧面部和前胸区域的颜色较深,但是地面、背景的树等的颜色较浅,这说明神经网络可以学到“不同区域的对于当前任务的重要性不同”。
注:热力图(saliency map)的画法多种多样,无固定范式,如有兴趣请自行Google。
值得注意的是,上图所示的热力图是训练完成之后我们采取一些专门为了注意力可视化而设计的方法得到的,比如计算模型输出对于图像输入的每个原始像素点的梯度,然后认为梯度越大的点模型的关注度越高。但是,我们在模型训练的时候却并不一定要求模型直接学习到模型输出和输入之间的注意力,比如CNN中,我们仅仅只是通过反向传播的方式来更新卷积核的权重,但是并没有任何和注意力直接有关的约束。而Transformer,则是直接以注意力机制为主要构成模块的主干网络。
再举一个例子,假如我们想把“早上好!”这句中文翻译成对应的英文“Good Morning!”。我们现在把“早上好!”作为模型输入,“Good Morning!”作为模型输出,那么模型在尝试着拟合输入输出关系的时候,应当可以关注到对于输出的某一部分,输入的不同部分的重要性是不一样的。
具体来讲,“Good”和“好”的关联性最强,和“早上”以及“!”的关联性较弱;“Morning”和“早上”的关联性最强,和“好”以及“!”的关联性较弱;“!”和“!”的关联性最强,和“早上”以及“好”的关联性较弱。如下图所示,其中线条的颜色的颜色深浅表示相连的输入输出字符之间的关联性,颜色越深表示关联性越大。这一“关联性”,其实就是注意力的体现。

好了,说了这么多。那么我们来看Transformer中的注意力机制的实现方式吧!
很形象。。。
Transformer中用的注意力机制包括Query ( Q),Key ( K)和Value ( V )三个组成部分(学习过数据库的同学对这三个名词应该比较熟悉)。可以这样理解,V 是我们手头已经有的所有资料,可以作为一个知识库;Q 是我们待查询的东西,我们希望把V 中和 Q有关的信息都找出来;而 K是 V 这个知识库的钥匙 ,V中每个位置的信息对应于一个 K。对于V 中的每个位置的信息而言,如果 Q和对应钥匙 的匹配程度越高,那么就可以从该条信息中找到和 Q更多的内容。
举个例子,我们现在希望给四不像找妈妈。以四不像作为 Q ,以[鹿 ,牛 ,羊 ,驴,青蛙 ]同时作为V 和K ,然后发现四不像和鹿的相似度为1/3、和牛的相似度为1/6,和羊、驴的相似度均为1/4,和青蛙的相似度为0,那么最终的查询结果就是1/3鹿+1/6牛+1/4羊+1/4驴+0青蛙。
从上面的描述可以看出,计算注意力的流程可以分解为以下两个步骤:
- 计算 Q和 K 的相似度
- 根据计算得到的相似度,取出 V 每条信息中和 Q 有关的内容
Transformer中注意力的计算方法也可以大致分为上面两步。
我们以下面的例子为例。计算过程的简要图如下图所示(美观起见,保留至两位小数),详细分析附后。


1.1 计算Q和K的相似度
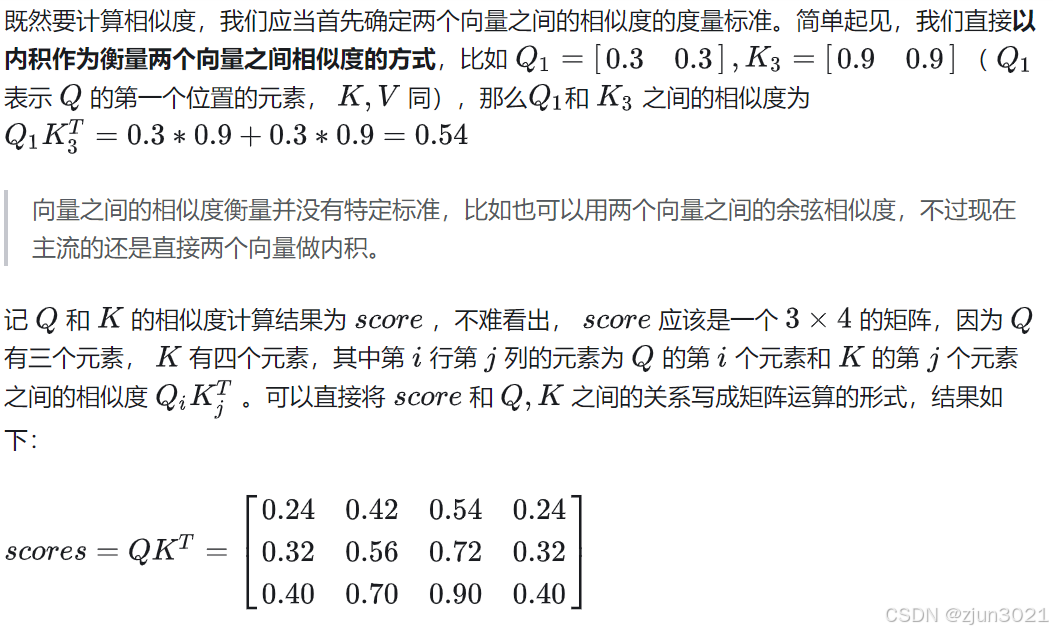
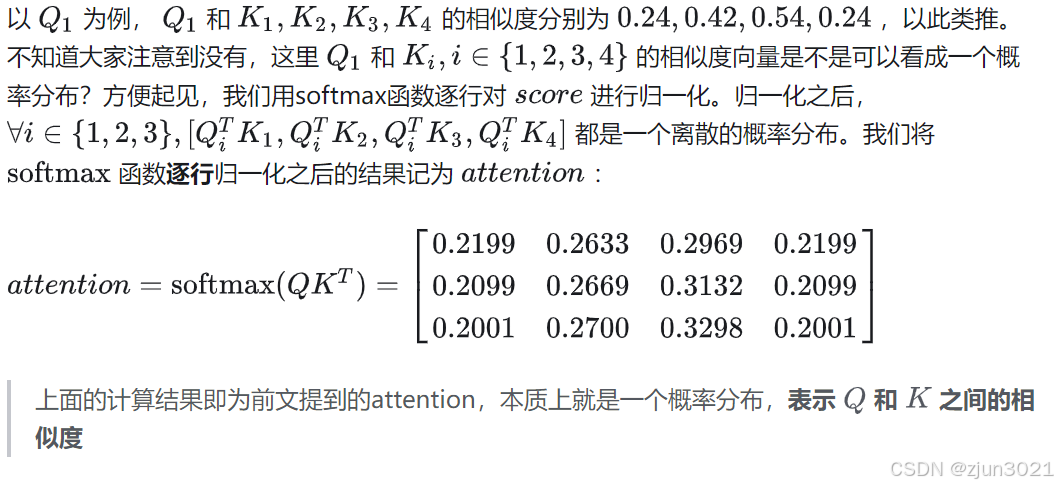
1.2 取出V中每条信息中和Q有关的内容

1.3 注意力机制解释


多头注意力机制的伪代码如下:
q_len, k_len, v_len = ...
batch_size, hdim = ...
head_dim = ...
assert hdim % head_dim = 0
assert k_len == v_len
num_head = hdim // head_dim
q = tensor(batch_size, q_len, hdim)
k = tensor(batch_size, k_len, hdim)
v = tensor(batch_size, v_len, hdim)def multi_head_split(x):# x: (batch_size, len, hdim)b, l, hdim = x.size()x = x.reshape(b, l, num_head, head_dim).transpose(1, 2) # (b, num_head, l, dim)return xdef multi_head_merge(x, b):# x: (batch_ize, num_head, len, head_dim)b, num_head, l, head_dim = x.size()x = x.transpose(1, 2).reshape(b, l, num_head * head_dim) #(batch_size, l, hdim)return xq, k, v = map(multi_head_split, [q, k, v])
output = MultiHeadAttention(q, k, v) # 该函数的具体实现后文给出
output = multi_head_merge(output, batch_size)
多头注意力机制目前已经是Transformer的标配,通常每个注意力头的维度为64,注意力头的个数为输入维度除以64。
在Transformer原文中,作者并没有对多头注意力机制的motivation做过多的阐述,后来也有研究发现多头并不一定比单头好,参考论文<<Are sixteen heads really better than one?>>[1],不过目前基本都是默认用的多头注意力。
1.4 Scaled Dot-Product Attention

2 SelfAttention概念总结
2.1 自注意力机制的基本概念
Query (Q):查询向量,代表了模型需要关注的部分。
Key (K):键向量,代表了输入序列中各个位置的信息。
Value (V):值向量,包含了实际的信息内容。
自注意力机制的工作流程包括以下几个步骤:
- 线性变换:首先将输入数据通过三个不同的线性变换(即三个权重矩阵)得到 Query、Key 和 Value 向量。
- 计算注意力分数:将 Query 向量与所有 Key 向量进行点积操作,并将结果除以 Key 向量的维度开根号,以获得未归一化的注意力得分(有时称为注意力分数)。
- Softmax 归一化:对注意力得分应用 Softmax 函数,将其转换为概率分布。
- 加权求和:将 Value 向量与经过 Softmax 归一化的注意力得分相乘,得到加权后的值向量,然后对这些加权后的值向量求和,得到最终的输出。
2.2 特点
- 并行计算:自注意力机制可以并行处理序列中的所有位置,这使得模型能够更快地训练。
- 长距离依赖:自注意力机制能够有效捕捉输入序列中的长距离依赖关系。
- 适应性强:自注意力机制可以根据输入数据的不同自动调整其关注的焦点,提高了模型的灵活性。
2.3 多头注意力
在实践中,经常会使用多头注意力(Multi-Head Attention)机制来增强模型的表现力。多头注意力允许模型在同一位置学会关注不同的信息,通过将输入数据分成多个不同的头部(head),每个头部独立进行自注意力计算,最后将所有头部的结果合并起来作为最终的输出。
2.4 与Paged Attention的关系
Self-Attention 和 Paged Attention 都是为了处理序列数据而设计的机制,但它们解决的问题略有不同。Self-Attention 更关注于如何在序列内部建立联系,而 Paged Attention 主要解决的是如何处理超长序列的问题。在某些情况下,Paged Attention 可能会结合 Self-Attention 来实现更高效的长序列处理.
3. Ascend上的Self-Attention实现
SelfAttention在ascend上实现是通过atb算子实现的,如下:
SelfAttentionOperation-atb/infer_op_params.h-Ascend Transformer Boost加速库接口-CANN商用版8.0.RC2.2开发文档-昇腾社区
参考
https://proceedings.neurips.cc/paper_files/paper/2019/file/2c601ad9d2ff9bc8b282670cdd54f69f-Paper.pdf
相关文章:
SelfAttention在Ascend上的实现
1 SelfAttention是什么? Self-Attention(自注意力)机制是深度学习领域的一种重要技术,尤其在自然语言处理(NLP)任务中得到广泛应用。它是 Transformer 架构的核心组成部分之一,由 Vaswani 等人…...

C#设计模式
文章目录 项目地址一、开放封闭原则1.1 不好的版本1.2 将BankProcess的实现改为接口1.3 修改BankStuff类和IBankClient类二、依赖倒置原则2.1 高层不应该依赖于低层模块2.1.1 不好的例子2.1.2 修改:将各个国家的歌曲抽象2.2 抽象不应该依于细节2.2.1 不同的人开不同的车(接口…...

仪表板展示|DataEase看中国:历年双十一电商销售数据分析
背景介绍 2024年“双十一”购物季正在火热进行中。自2009年首次推出至今,“双十一”已经成为中国乃至全球最大的购物狂欢节,并且延伸到了全球范围内的电子商务平台。随着人们消费水平的提升以及电子商务的普及,线上销售模式也逐渐呈现多元化…...

急着骂华为?我劝你别急
文 | AUTO芯球 作者 | 雷慢 赛力斯这下怒了! 要对那些华为黑、问界黑出手了, 就在这几天,赛力斯起诉了一批蓄意抹黑、散步虚假信息的人。 起因是什么,听我慢慢说, 今年7月,佛山一辆问界M7发生交通事故…...
虚拟机linux7.9下安装mysql
1.MySQL官网下载安装包: MySQL :: Download MySQL Community Server https://cdn.mysql.com/archives/mysql-5.7/mysql-5.7.39-linux-glibc2.12-x86_64.tar.gz 2.解压文件: #tar xvzf mysql-5.7.39-linux-glibc2.12-x86_64.tar.gz 3.移动文件&#…...

【Linux】一篇文章轻松搞懂基本指令
本篇所有展示代码均是在超级用户的权限下进行的,如果不是超级用户并且一些命令执行的和我的不太一样,那么可以试着在对应命令前暂且加上sudo,我们在下一篇会讲权限问题,到时候再转换为普通用户。 本篇展示的内容是基于CentOs进行…...

深入浅出理解Spring和SpringBoot,剖析自动配置源码
文章目录 1.Spring2.SpringBoot3.小结 1.摘要 本文旨在带大家理解Spring框架和SpringBoot框架最为核心的部分,自Spring和SpringBoot问世以来,给Web开发掀起了巨大的浪潮,极大的缩短项目开发周期,下面将带大家分析Spring和SpringBo…...
)
Spring配置文件初始化加载(一)
1.枚举 public enum TestEnum {type_01("01", "zeroTest01ServiceImpl"),type_02("02", "zeroTest02ServiceImpl"),type_03("03", "zeroTest03ServiceImpl");private String type;private String pathClass; } …...

正则表达式 - 简介
正则表达式 - 简介 正则表达式(Regular Expression,简称Regex)是一种用于处理字符串的强大工具,它允许用户通过特定的模式(pattern)来搜索、匹配、查找和替换文本中的数据。正则表达式广泛应用于文本编辑器…...

【电机控制器】STC8H1K芯片——ADC电压采集
【电机控制器】STC8H1K芯片——ADC电压采集 文章目录 [TOC](文章目录) 前言一、ADC1.ADC初始化1.ADC_CONTR2.ADCCFG3.ADCTIM4.代码 2.ADC读取1.ADC_RES、ADC_RESL2.代码 3.VREF电压读取——MCU工作电压1.MCU工作电压计算公式2.代码 4.ADC被转换通道的输入电压读取1.ADC被转换通…...

图像格式中的 stride 和 pix stide
最近发现media codec 解码后 yuv 的拷贝时间很大,进一步分析后发现底层会一个像素一个像素拷贝,非常花时间。用过调整解码后图像的Stride(步幅)后直接进行内存块拷贝,可以大幅缩短拷贝时间 在YUV图像格式中,…...

传统POE供电P1摄像头实现
首先,我们来了解一下什么是poe供电?poe供电是一种通过网络线(通常为网线)传输电能的技术。这种技术可以省去马达、插头等传统供电设备,以及不需要另外的电源延长线,从而实现方便的供电。 那么,…...

云计算基础:AWS入门指南
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 云计算基础:AWS入门指南 云计算基础:AWS入门指南 云计算基础:AWS入门指南 引言 AWS概述 什么…...

pytorch torch.tile用法
指定各维度分别重复多少次 tile 是 PyTorch 中用于重复张量的函数。它可以沿指定的维度重复张量的元素。以下是一个示例代码,展示 tile 的用法: import torch# 创建一个张量 weight_hh torch.tensor([[1, 2], [3, 4]])# 假设批量大小为3 bs 3# 使用 …...

实战项目:通过自我学习让AI学习五子棋 - 1 - 项目定义
项目介绍 五子棋是一种博弈游戏。在棋盘上黑子和白子交替落子,先于在任何方向上将至少五个棋子连在一起的一方获胜。在我们这个项目中我们尝试使用自学习的方法训练出一套走五子棋的算法。 这个项目本身并无特别大的实用价值。我们的目的在于: 尝试自…...

统信UOS开发环境支持Electron
全面支持Electron开发环境,同时还提供了丰富的开发工具和开发资源,进一步提升工作效率。 文章目录 一、环境部署1. Electron应用开发介绍2. Electron开发环境安装安装Node.js和npm安装electron环境配置二、代码示例Electron开发案例三、常见问题一、环境部署 1. Electron应用…...

2024.11.09【BUG报错】| Fastuniq “Error in Reading pair-end FASTQ sequence!”解决方案
解决 Fastuniq 中“Error in Reading pair-end FASTQ sequence!”报错的指南 在使用 Fastuniq 进行高通量测序数据分析时,用户可能会遇到“Error in Reading pair-end FASTQ sequence!”的错误提示。这通常表明在读取配对的 FASTQ 序列时出现了问题。以下是一些可能…...
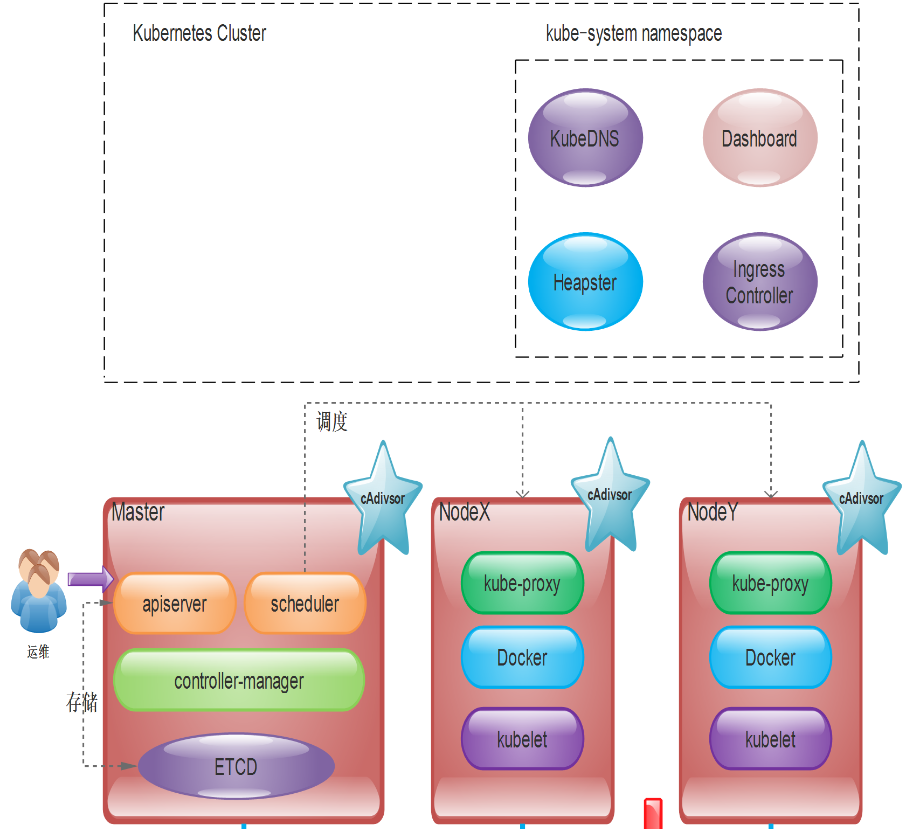
k8s组件原理
文章目录 1、kubernetes控制平面组件1、kube-apiserver2、etcd3、controller-manager4、schedule 2、node组件1、kubelet2、container runtime3、kube-proxy 3、附加组件1、kubedns2、dashboard 4、创建pod的原理 1、kubernetes控制平面组件 1、kube-apiserver 是公开kubernete…...

0基础跟德姆(dom)一起学AI 深度学习02-Pytorch基本使用
1 基本介绍 (1)什么是Pytorch? PyTorch是一个开源机器学习和深度学习框架。PyTorch 允许您使用 Python 代码操作和处理数据并编写深度学习算法,能够在强大的GPU加速基础上实现张量和动态神经网络。 PyTorch是一个基于 Python 的科学计算包…...

九州未来再度入选2024边缘计算TOP100
随着数智化转型的浪潮不断高涨,边缘计算作为推动各行业智能化升级的重要基石,正在成为支持万物智能化的关键点。近日,德本咨询(DBC)联合《互联网周刊》(CIW)与中国社会科学院信息化研究中心(CIS),共同发布《2024边缘计算TOP100》榜…...

Python自动化资源管理工具closeclaw:智能清理闲置窗口与进程
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫closeclaw,作者是krishpranav。乍一看这个仓库名,你可能会有点摸不着头脑——“关闭爪子”?这到底是干嘛的?点进去研究了一番,发现这是一个用…...

Elsevier审稿追踪插件:告别焦虑等待,让投稿管理变轻松
Elsevier审稿追踪插件:告别焦虑等待,让投稿管理变轻松 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 你是否曾为Elsevier期刊投稿后的漫长等待而焦虑?每天反复刷新页面查看审稿进…...

影像技术实战05:视频上传后无法在线播放?MP4 封装、编码兼容与 FastStart 修复方案
影像技术实战05:视频上传后无法在线播放?MP4 封装、编码兼容与 FastStart 修复方案 一、问题场景:视频明明是 MP4,为什么网页还是播不了? 在很多视频系统里,用户上传视频后,后台保存文件&#x…...

龙虾之父月耗 6030 亿 API token 花 130 万美元+,Token 成 AI 新生产资料?
【导语:龙虾之父 Peter Steinberger 一个月 API token 花费超 130 万美元,引发网友热议。他正探索 Token 不再重要时如何构建软件,Token 也逐渐成为新的生产资料。】高额 Token 花费引争议龙虾之父 Peter Steinberger 一个月 API token 花费高…...

基于Go与Croc构建Telegram文件传输机器人:原理、部署与优化
1. 项目概述:一个基于Go的轻量级文件传输机器人 如果你经常需要在不同的设备、服务器或者聊天群组之间快速分享文件,并且对安全性、速度和便捷性有一定要求,那么你很可能已经厌倦了那些需要注册账号、上传到第三方服务器、或者操作繁琐的命令…...

基于本地大模型的字幕翻译:LM Studio集成方案与实战优化
1. 项目概述:当本地大模型遇上字幕翻译最近在折腾本地大模型应用时,发现了一个挺有意思的场景:字幕翻译。很多朋友喜欢看海外影视剧或学习资料,但苦于没有高质量的中文字幕。在线翻译工具要么有字数限制,要么担心隐私泄…...

Yolov5算法界面 PyQt5 +.exe文件部署 yolo双击运行 yolo打包识别
介绍 Yolov5是一种基于深度学习的目标检测算法,PyQt5是一个Python编写的GUI框架,用于创建交互式界面。在部署和运行Yolov5模型时,结合PyQt5可以方便地创建一个用户友好的界面,并将代码打包为.exe文件以供其他人使用。 下面是一个简…...

观察 Taotoken 用量看板如何帮助团队清晰掌握 API 调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察 Taotoken 用量看板如何帮助团队清晰掌握 API 调用成本 对于依赖大模型 API 进行开发的项目团队而言,成本控制与预…...

用PCA给高维数据‘瘦身’:从鸢尾花数据集到人脸图像,实战对比降维效果与可视化技巧
用PCA给高维数据‘瘦身’:从鸢尾花数据集到人脸图像,实战对比降维效果与可视化技巧 当面对成百上千维的数据时,我们常会陷入"维度灾难"的困境——计算资源吃紧、模型训练缓慢,更糟的是噪声干扰导致分析结果失真。主成分…...

荣品RV1126 SDK编译避坑指南:从环境配置到分区调整,手把手解决常见编译错误
RV1126 SDK编译实战:从环境搭建到分区优化的全流程解决方案 1. 开发环境配置与初始化 RV1126开发环境的搭建是整个开发流程的第一步,也是后续所有工作的基础。一个稳定、高效的开发环境能够显著提升开发效率,减少不必要的错误。 首先需要确保…...