【笔记】扩散模型(九):Imagen 理论与实现
论文链接:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
非官方实现:lucidrains/imagen-pytorch
Imagen 是 Google Research 的文生图工作,这个工作并没有沿用 Stable Diffusion 的架构,而是级联了一系列普通的 DDPM 模型。其主要的贡献有以下几个方面:
- 使用比较大的文本模型进行文本嵌入,可以获得比使用 CLIP 更好的文本理解能力;
- 在采样阶段引入了一种动态阈值的方法,可以利用更高的 guidance scale 来生成更真实、细节更丰富的图像(这里的阈值是控制 x \mathbf{x} x 的范围);
- 改良了 UNet,提出 Efficient UNet,使模型更简单、收敛更快、内存消耗更少。
该模型的架构如下图所示,可以看到使用了一个条件生成的 diffusion 模型以及两个超分辨率模型,每个模型都以文本模型的 embedding 作为条件,先生成一个 64 分辨率的图像,然后逐步超分辨率到 1024 大小。
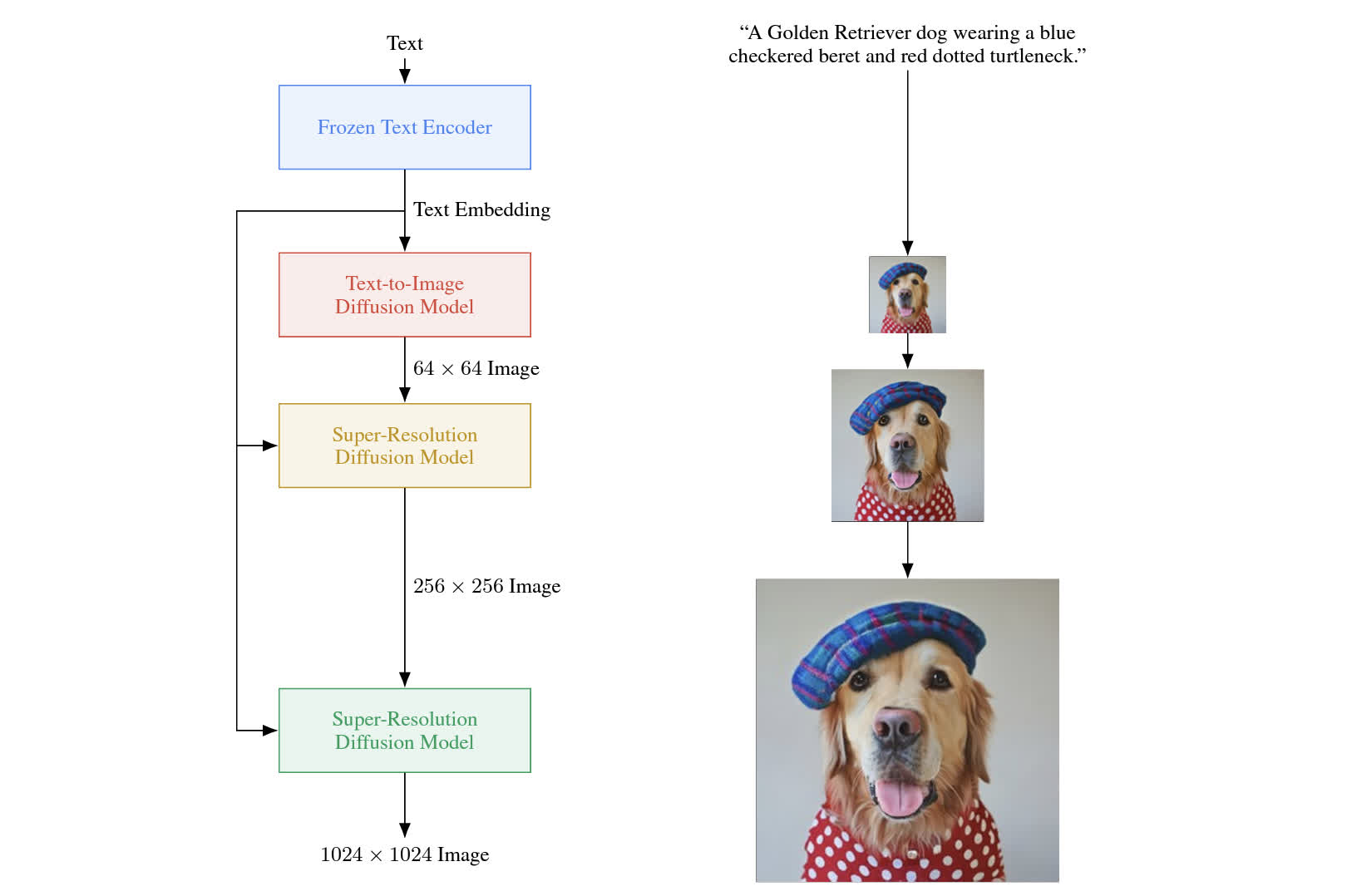
Imagen
预训练文本模型
现在的文生图模型主流使用的文本嵌入方法是使用 CLIP 文本编码器,在直观上感觉是比较合理的,因为 CLIP 的文本特征和图像特征共享同一个空间,用来控制图像的生成过程是比较合理的。不过 CLIP 的缺点是对文本的表达能力比较有限,处理复杂文本比较困难。
这里选择的不是使用 CLIP,而是使用规模比较大、且在大规模文本语料上训练的文本模型,具体来说使用的模型有 BERT、T5 和 CLIP。经过实验(具体结果可以看原论文 Figure 4 的 a 和 b,以及 Figure A.5),主要有以下发现:
- 缩放文本编码器对提升生成质量的作用很明显;
- 相比增大 UNet 的尺寸,增大文本编码器的尺寸更重要;
- 相比于 CLIP,人类更偏好 T5-XXL 的结果。
高 Guidance Scale 的改善
提高 classifier-free guidance 的 guidance scale 可以提升文本-图像的匹配程度,但是会破坏图像的质量。这个现象是因为高 guidance scale 会导致训练阶段和测试阶段出现 mismatch。具体来说,在训练时,所有的 x \mathbf{x} x 都分布在 [ − 1 , 1 ] [-1,1] [−1,1] 的范围里,然而当使用比较大的 guidance scale 时,得到的 x \mathbf{x} x 会超出这个范围。这样会导致 x \mathbf{x} x 落在已经学习过的范围以外,为了解决这个问题,作者研究了静态阈值(static thresholding)和动态阈值(dynamic thresholding)两种方案,具体算法如下图所示:

静态阈值
这种方法就是在预测噪声后,先计算出 x 0 \mathbf{x}_0 x0,然后将其取值范围直接裁剪到 [ − 1 , 1 ] [-1,1] [−1,1] 之间,然后再进行去噪。这种方法已经很多方法都使用了,例如 openai/guided-diffusion 中的这段代码就是为了进行这种处理:
def process_xstart(x):if denoised_fn is not None:x = denoised_fn(x)if clip_denoised:return x.clamp(-1, 1) # 裁剪到 [-1,1]return xif self.model_mean_type == ModelMeanType.EPSILON:pred_xstart = process_xstart(self._predict_xstart_from_eps(x_t=x, t=t, eps=model_output) # 得到 x_0)
model_mean, _, _ = self.q_posterior_mean_variance(x_start=pred_xstart, x_t=x, t=t
)
动态阈值
这个方法不是很好理解,我们可以从一个例子出发,我们平时进行 classifier-free guidance 时使用的 guidance scale 通常都是 7.5,那么一个原本分布在 [ − 1 , 1 ] [-1,1] [−1,1] 之间的变量乘以这个系数之后就会变到 [ − 7.5 , 7.5 ] [-7.5,7.5] [−7.5,7.5] 的范围内。如果某处的几个数分别是 { 0.2 , 0.4 , 0.6 , 0.8 } \{0.2, 0.4, 0.6, 0.8\} {0.2,0.4,0.6,0.8},乘以 7.5 后就变成了 { 1.5 , 3.0 , 4.5 , 6.0 } \{1.5,3.0,4.5,6.0\} {1.5,3.0,4.5,6.0}。如果此时直接将这些数裁剪到 [ − 1 , 1 ] [-1,1] [−1,1],那么所有的数都会变成 1,原本这些数之间是有比较大的差别的,裁剪后都变成了相同的数,这样很明显是不合理的,动态阈值就是为了寻找一个比较合理的裁剪范围。
这里的做法是寻找一个 x 0 \mathbf{x}_0 x0 的 p-分位数 s s s,也就是找到大多数的数字落在什么范围内,然后先裁剪到 [ − s , s ] [-s,s] [−s,s] 范围内,再全部除以 s s s 以缩放到 [ − 1 , 1 ] [-1,1] [−1,1] 的范围内。实验发现这种方法能比较好地改善图像的质量,这部分的代码如下所示(摘自非官方实现):
if pred_objective == 'noise':x_start = noise_scheduler.predict_start_from_noise(x, t=t, noise=pred)
elif pred_objective == 'x_start':x_start = pred
elif pred_objective == 'v':x_start = noise_scheduler.predict_start_from_v(x, t=t, v=pred)if dynamic_threshold: # 动态阈值# 找到 p-分位数s = torch.quantile(rearrange(x_start, 'b ... -> b (...)').abs(),self.dynamic_thresholding_percentile,dim = -1)s.clamp_(min=1.)s = right_pad_dims_to(x_start, s)# 进行归一化x_start = x_start.clamp(-s, s) / s
else: # 静态阈值,直接截断x_start.clamp_(-1., 1.)
mean_and_variance = noise_scheduler.q_posterior(x_start=x_start, x_t=x, t=t, t_next=t_next)
级联扩散模型
为了生成高分辨率图像,模型级联了三个扩散模型,一个用来生成低分辨率图像,两个用来将低分辨率图像逐步超分到高分辨率。在训练阶段,作者发现使用带有噪声条件增强的超分模型可以生成更高质量的模型。具体来说,每次生成噪声时,还从 [ 0 , 1 ] [0,1] [0,1] 范围内随机采样一个 aug level,然后基于这个 level 进行增强。在预测噪声时,不仅输入带噪声的图像、低分辨率图像、时间步,还输入一个 aug level。在推理阶段,使用一系列 aug level 进行增强,然后分别进行推理,从中选取一个最佳样本,这样可以提升采样效果。具体的算法如下所示:

总结
除了上述的一些贡献,Imagen 还做了一些工程上的改进,例如使用了不同的 text condition 注入方式,以及对基础的 UNet 模型进行了改进,提出了 Efficient UNet 模型等。相比同期的其他方法,Imagen 应该是为数不多可以直接生成 1024 分辨率图像的 diffusion 模型,虽然和主流的 Stable Diffusion 架构不同,但其中的一些改进思路还是值得学习一下的。
本文原文以 CC BY-NC-SA 4.0 许可协议发布于 笔记|扩散模型(九):Imagen 理论与实现,转载请注明出处。
相关文章:
【笔记】扩散模型(九):Imagen 理论与实现
论文链接:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding 非官方实现:lucidrains/imagen-pytorch Imagen 是 Google Research 的文生图工作,这个工作并没有沿用 Stable Diffusion 的架构,而是级…...

05 SQL炼金术:深入探索与实战优化
文章目录 SQL炼金术:深入探索与实战优化一、SQL解析与执行计划1.1 获取执行计划1.2 解读执行计划 二、统计信息与执行上下文2.1 收集统计信息2.2 执行上下文 三、SQL优化工具与实战3.1 SQL Profile3.2 Hint3.3 Plan Baselines3.4 实战优化示例 SQL炼金术:…...

Linux用lvm格式挂载磁盘
Linux用lvm格式挂载磁盘 本次目标是将磁盘/dev/sdd以lvm格式挂载到/backup目录作为备份盘来用 1、查看当前磁盘 [rootquentin ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 300G 0 disk ├─sda1 8:1 0 1G…...

Xshell,Shell的相关介绍与Linux中的权限问题
目录 XShell的介绍 Shell的运行原理 Linux当中的权限问题 Linux权限的概念 Linux权限管理 文件访问者的分类(人) 文件类型和访问权限(事物属性) 文件权限值的表示方法 文件访问权限的相关设置方法 如何改变文件的访问权限…...

考研要求掌握的C语言(选择排序)
选择排序的特点 每次进行一趟排序后,就确定一个数据的最终位置 选择排序的原理 就是假设你是最小(最大数据)的下标,然后和其他进行比较,若发现还有比你还小(或还大)的数据,就更新…...

达梦8数据库适配ORACLE的8个参数
目录 1、概述 1.1 概述 1.2 实验环境 2、参数简介 3、实验部分 3.1 参数BLANK_PAD_MODE 3.2 参数COMPATIBLE_MODE 3.3 参数ORDER_BY_NULLS_FLAG 3.4 参数DATETIME_FMT_MODE 3.5 参数PL_SQLCODE_COMPATIBLE 3.6 参数CALC_AS_DECIMAL 3.7 参数ENABLE_PL_SYNONYM 3.8…...

CSS实现文字渐变效果
效果图: 代码: h1 {font-size: 100px;color:linear-gradient(gold,deeppink);background-image:linear-gradient( -gold, deeppink); /*春意盎然*///背景被裁剪成文字的前景色。background-clip:text;/*兼容内核版本较低的浏览器*/-webkit-background-c…...

3. Redis的通用命令介绍
Redis作为一个高效的键值对存储系统,不仅支持多种数据结构,还提供了丰富的通用命令,这些命令适用于各种场景。本文将详细介绍Redis的常用通用命令,并结合具体应用场景,帮助你理解这些命令的功能与使用时机。 1. 键(key…...

[spark面试]spark与mapreduce的区别---在DAG方面
1、spark中的task是以线程实现的,而mapreduce中是以进程实现的。 进程的频繁启动和停止会增加资源的消耗。 2、spark中支持DAG,而mapreduce不支持DAG DAG的使用:为什么支持DAG会更加高效 1)、在DAG图中,会将一个job…...

tomcat启动失败和缓存清理办法
tomcat只在学校接触过并且是在window xp和win7的电脑上配置过(中途升级过电脑系统),只记得在windows系统上可以将其设置成服务管理。但我已毕业10多年了,学的知识早就不知道丢哪里了。这次为了修改一个07,08年的项目&a…...
【软件测试】需求的概念和常见模型(瀑布、螺旋、增量、迭代)
1. 什么是需求 在企业中,经常会听到:用户需求和软件需求 用户需求:没用经过合理的评估,通常就是一句话(开发一个五彩斑斓的黑)软件需求:开发人员和测试人员执行工作的依据 1.2 软件需求 在工…...

Python爬虫如何处理验证码与登录
Python爬虫如何处理验证码与登录 Python 爬虫在抓取需要登录的网站数据时,通常会遇到两个主要问题:登录验证和验证码处理。这些机制是网站用来防止自动化程序过度抓取数据的主要手段。本文将详细讲解如何使用 Python 处理登录与验证码,以便进…...

QT添加资源文件
QT添加资源文件 1.概述 这篇文章介绍为QT项目添加资源文件,例如项目中使用到的图片、音视频文件等等 2.添加资源文件 拷贝资源文件到项目中 在项目mainwindow.app文件上右键选择show in Finder 打开项目所在目录。 将图片文件夹复制到该目录中 创建资源文件结…...

负载均衡式在线oj项目开发文档(个人项目)
项目目标 需要使用的技术栈: 这个项目共分成三个模块第一个模块为公共的模块,用于解决字符串处理,文件操作,网络连接等等的问题。 第二个模块是一个编译运行的模块,这个模块的主要功能就是将用户的代码收集上来之后要…...
)
Python小白学习教程从入门到入坑------第二十六课 单例模式(语法进阶)
在这个节课的开始,我们先回顾一下面向对象课程中学的构造函数__init__() 目录 一、__init__() 和 __new__() 1.1 __init__() 1.2 __new__() 二、单例模式 2.1 特点 2.2 通过classmethod实现单例模式 2.3 通过装饰器实现单例模式 2.3 通过重写__new__() 实现…...

革命性AI搜索引擎!ChatGPT最新功能发布,无广告更智能!
文章目录 零、前言一、ChatGPT最新AI搜索引擎功能操作指导实战1:搜索新闻实战2:搜索天气实战3:搜索体育消息 二、感受 零、前言 大人,时代变了。 最强 AI 助力下的无广告搜索引擎终于问世。我们期待已久的这一刻终于到来了,从今天起,ChatGPT…...

windows C#-使用异常
在 C# 中,程序中的运行时错误通过使用一种称为“异常”的机制在程序中传播。 异常由遇到错误的代码引发,由能够更正错误的代码捕捉。 异常可由 .NET 运行时或由程序中的代码引发。 一旦引发了一个异常,此异常会在调用堆栈中传播,直…...

玩的花,云产品也能拼团了!!!
说起拼单大家都不陌生,电商一贯的营销手段,不过确实可以给消费者省下一笔钱。双11到了,腾讯云产品也玩起了拼团,这明显是对开发人员和各企业的福利。 对于有云产品需求的个人或企业,这次绝对是难得的一次薅羊毛机会。…...

HTML+CSS基础【快速上手】
目录 一、HTML展示 1、HTML基础结构 2、认识元素属性 (1)元素属性理解 (2)实例 3、自结束标签和注释 (1)自结束标签 (2)注释 4、语义化标签 (1)语义…...

mysql分布式锁
大家好,今天我们来看下如何使用本地MySql实现一把分布式锁,以及Mysql实现分布式锁的原理是怎么样的 MySql实现分布式锁有三种方式 1:基于行锁实现分布式锁 k1.png 实现原理 首先我们的表lock要提前存好相对应的lockName,这时候…...

Go语言静态站点生成器Zeuxis:极简架构与高性能构建实践
1. 项目概述:一个轻量级、高性能的静态站点生成器最近在折腾个人博客和文档站点,发现市面上的静态站点生成器虽然多,但要么配置复杂、学习曲线陡峭,要么过于臃肿,启动和构建速度慢得让人抓狂。直到我遇到了bnomei/zeux…...

TPU柔性材料3D打印GoPro车载支架:从减震原理到实战拍摄全指南
1. 项目概述与设计思路我一直对第一人称视角(FPV)拍摄很着迷,尤其是那种能贴着地面、模拟小车视角疾驰的画面,动态感和沉浸感是手持拍摄无法比拟的。市面上的运动相机车载支架要么是硬连接,颠簸起来画面抖动得厉害&…...

AI Agent架构深度解析:从核心原理到工程实践
1. 项目概述:一次关于AI Agent的深度技术探险最近在GitHub上看到一个名为“tvytlx/ai-agent-deep-dive”的项目,光看标题就让人眼前一亮。这显然不是一个简单的“Hello World”式教程,而是一次对AI Agent(智能体)技术的…...

开源AI代码助手实践:从数据到部署的全链路解析
1. 项目概述:从“copaw-code”看AI代码助手的开源实践最近在GitHub上看到一个挺有意思的项目,叫“QSEEKING/copaw-code”。光看这个名字,可能有点摸不着头脑。“copaw”这个词,听起来像是“co-pilot”(副驾驶ÿ…...

碳排放混合时间窗集装箱运输调度【附算法】
✨ 长期致力于集装箱运输VRP、混合时间窗、碳排放、多目标优化、NSGA-Ⅱ、蚁群算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)经济性与紧急性双目…...

Cursor与Figma通过MCP协议实现AI辅助设计与开发同步
1. 项目概述:当代码编辑器与设计工具“开口说话”最近在开发者社区里,一个名为“cursor-talk-to-figma-mcp”的项目引起了我的注意。这个由开发者“hamadoun1760”开源的仓库,名字直译过来就是“Cursor与Figma对话的MCP”。乍一看,…...

基于RP2040的客制化宏键盘:从硬件设计到KMK固件开发全攻略
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫clawdpad,作者是kudretyilmazz。乍一看这个名字,可能有点摸不着头脑,但如果你对机械键盘、客制化输入设备或者桌面自动化感兴趣,那这个项目绝对值得你花时间…...

Cursor编辑器状态快照插件开发:一键保存与恢复工作区
1. 项目概述:一个专为开发者设计的“后悔药”如果你是一名重度使用 Cursor 编辑器的开发者,那么你一定经历过这样的场景:在沉浸式编码时,为了快速定位或修改,你可能会频繁地使用CtrlClick跳转到函数定义,或…...

ComfyUI ControlNet Aux 终极指南:30+种预处理器让AI图像生成更精准
ComfyUI ControlNet Aux 终极指南:30种预处理器让AI图像生成更精准 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux 想让您的AI图像生成具备真实…...

云端生信分析:从零部署RStudio Server避坑指南
1. 为什么需要云端RStudio Server? 做生物信息分析的朋友们肯定深有体会,单细胞测序、转录组这些数据动辄几十GB,用自己电脑跑分析简直是折磨。我去年处理一个肝癌单细胞项目时,光是读取数据就卡了半小时,更别说后续的…...