Python学习从0到1 day27 第三阶段 Spark ③ 数据计算 Ⅱ
目录
一、Filter方法
功能
语法
代码
总结
filter算子
二、distinct方法
功能
语法
代码
总结
distinct算子
三、SortBy方法
功能
语法
代码
总结
sortBy算子
四、数据计算练习
需求:
解答
总结
去重函数:
过滤函数:
转换函数:
排序函数:
于是我驻足,享受无法复刻的一些瞬间
—— 24.11.9
一、Filter方法
功能
过滤想要的数据进行保留
语法
基于filter中我们传入的函数,决定rdd对象中哪个保留哪个丢弃
代码
from pyspark import SparkConf,SparkContext# 设置spark中的python解释器对象
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
# 对RDD的数据进行过滤,保留奇数,去除偶数# 方法1:
def Retain(data):if data % 2 == 1:return Trueelse:return False# 对RDD数据进行过滤,留下奇数
rdd1 = rdd.filter(Retain)
print(rdd1.collect())# 方法2:
rdd2 = rdd.filter(lambda num:num % 2 == 1)
print(rdd2.collect())
总结
filter算子
接受一个处理函数,可用lambda匿名函数快速编写
函数对RDD数据逐个处理,得到True的保留到返回值的RDD中
二、distinct方法
功能
对RDD数据进行去重,返回新RDD
语法
rdd.distinct() # 无需传参代码
from pyspark import SparkConf,SparkContext# 设置spark中的python解释器对象
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize([1,3,3,4,4,4,7,8,9,9])
rdd = rdd.distinct()
print(rdd.collect())
总结
distinct算子
完成对Rdd内数据的去重操作
三、SortBy方法
功能
对RDD数据进行排序,基于指定的排序依据
语法
rdd.sortBy()
rdd.sortBy(func, ascending = False, numPartitions = 1)
# func:(T) - > U: 告知按照rdd中的哪个数据进行排序,比如 lambda x:x[1] 表示按照rdd中的第二列元素进行排序
# ascending: True升序 False 降序
# numPartitions: 用多少分区排序代码
from pyspark import SparkConf,SparkContext# 设置spark中的python解释器对象
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 读取数据文件
rdd = sc.textFile("D:/2LFE\Desktop\WordCount.txt")
# 取出全部单词
word_rdd = rdd.flatMap(lambda x:x.split(" "))
print(word_rdd.collect())# 将所有单词都转换成二元元组,单词为key,value设置为1
word_with_one_rdd = word_rdd.map(lambda word:(word,1))
# 分组并求和
result_rdd = word_with_one_rdd.reduceByKey(lambda a,b:a+b)
# 对结果进行排序
result_rdd = result_rdd.sortBy(lambda x:x[1],ascending = False,numPartitions = 1)
# 打印并输出结果
print(result_rdd.collect())
总结
sortBy算子
接收一个处理函数,可用lambda快速编写
函数表示用来决定排序的依据
可以控制升序或降序
全局排序需要设置分区数为1
四、数据计算练习
需求:
复制以上内容到文件中,使用Spark读取文件进行计算:
① 各个城市销售额排名,从大到小
② 全部城市,有哪些商品类别在售卖
③ 北京市有哪些商品类别在售卖
解答
from pyspark import SparkConf,SparkContext
import json# 设置spark中的python解释器对象
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 读取文件得到RDD
file_rdd = sc.textFile("E:\python.learning\pyspark\sortBy.txt")# 取出一个个JSON字符串
json_str_rdd = file_rdd.flatMap(lambda x:x.split("|"))# 将一个JSON字符串转换为字典 json模块
dict_rdd = json_str_rdd.map(lambda x:json.loads(x))# 取出城市和销售额数据:(城市,销售额)
city_with_money_rdd = dict_rdd.map(lambda x:(x['areaName'],int(x['money'])))# 按销售额对结果进行聚合然后根据销售额降序排序
city_result_rdd = city_with_money_rdd.reduceByKey(lambda x,y:x+y)
res1 = city_result_rdd.sortBy(lambda x:x[1],ascending = False,numPartitions = 1)
print("需求1结果:" , res1.collect())# 需求2 对全部商品进行去重
category_rdd = dict_rdd.map(lambda x: x['category']).distinct()
print("需求2结果:",category_rdd.collect())# 需求3 过滤北京市的数据
BJ_data_rdd = dict_rdd.filter(lambda x:x['areaName'] == '北京')
print("需求3结果:",BJ_data_rdd.collect())# 需求4 对北京市的商品类别进行商品类别去重
res2 = BJ_data_rdd.map(lambda x:x['category']).distinct()
print("需求4结果:",res2.collect())
总结
去重函数:
在 PySpark 框架下,distinct函数用于返回一个新的 RDD,其中包含原始 RDD 中的不同元素。
过滤函数:
filter函数用于从弹性分布式数据集(RDD)中筛选出满足特定条件的元素,返回一个新的 RDD 只包含满足条件的元素。
转换函数:
在 PySpark 中,map函数是对弹性分布式数据集(RDD)进行转换操作的一种重要方法。map函数对 RDD 中的每个元素应用一个函数,返回一个新的 RDD,其中包含应用函数后的结果。
排序函数:
sortBy 函数用于对RDD 中的元素进行排序,它接受一个函数或者一个字段名作为参数,根据这个参数来确定排序的依据。
相关文章:
Python学习从0到1 day27 第三阶段 Spark ③ 数据计算 Ⅱ
目录 一、Filter方法 功能 语法 代码 总结 filter算子 二、distinct方法 功能 语法 代码 总结 distinct算子 三、SortBy方法 功能 语法 代码 总结 sortBy算子 四、数据计算练习 需求: 解答 总结 去重函数: 过滤函数: 转换函数: 排…...

腾讯混元3D模型Hunyuan3D-1.0部署与推理优化指南
腾讯混元3D模型Hunyuan3D-1.0部署与推理优化指南 摘要: 本文将详细介绍如何部署腾讯混元3D模型Hunyuan3D-1.0,并针对不同硬件配置提供优化的推理方案。我们将探讨如何在有限的GPU内存下,通过调整配置来优化模型的推理性能。 1. 项目概览 腾…...

基于 PyTorch 从零手搓一个GPT Transformer 对话大模型
一、从零手实现 GPT Transformer 模型架构 近年来,大模型的发展势头迅猛,成为了人工智能领域的研究热点。大模型以其强大的语言理解和生成能力,在自然语言处理、机器翻译、文本生成等多个领域取得了显著的成果。但这些都离不开其背后的核心架…...
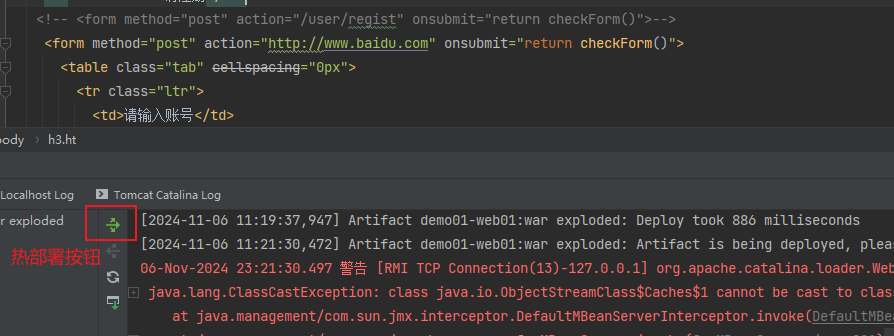
IDEA构建JavaWeb项目,并通过Tomcat成功运行
目录 一、Tomcat简介 二、Tomcat安装步骤 1.选择分支下载 2.点击下载zip安装包 3.解压到没有中文、空格和特殊字符的目录下 4.双击bin目录下的startup.bat脚本启动Tomcat 5.浏览器访问Tomcat 6.关闭Tomcat服务器 三、Tomcat目录介绍 四、WEB项目的标准结构 五、WEB…...
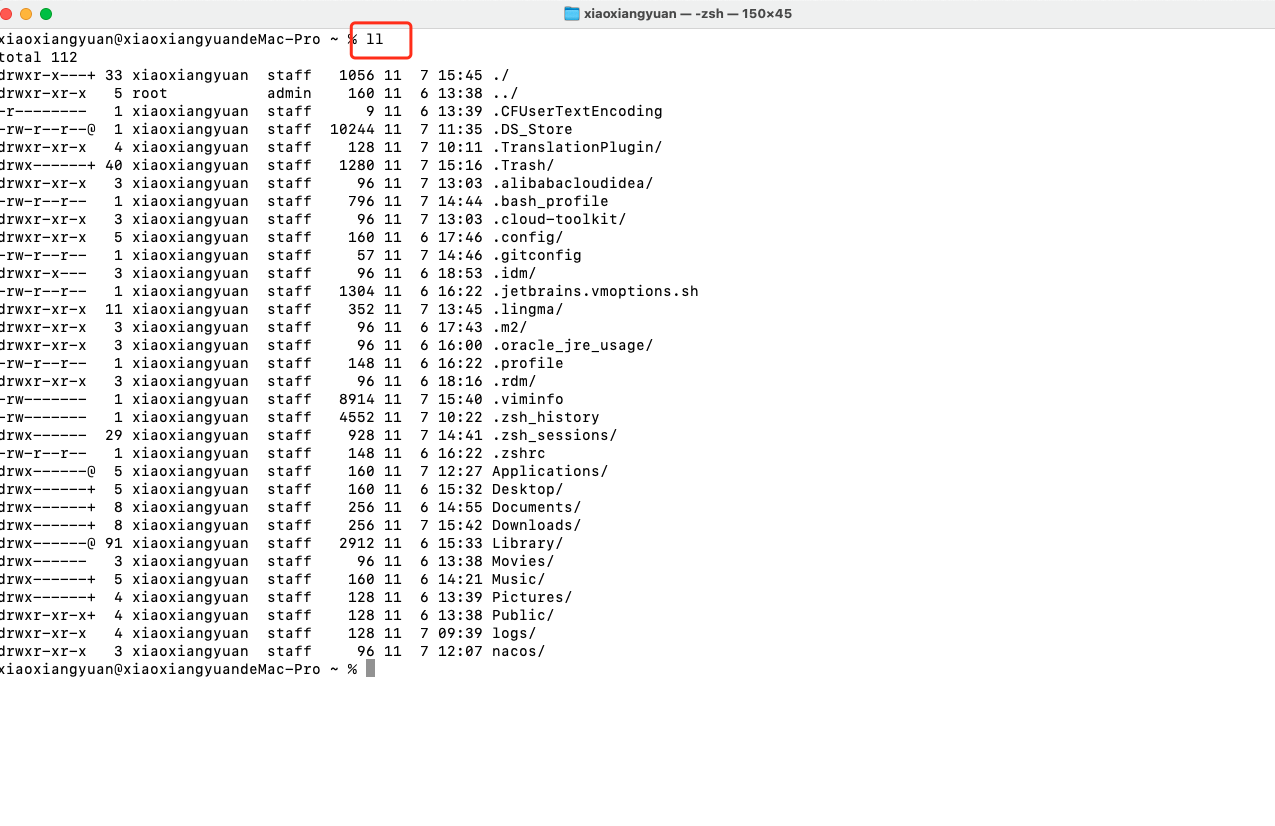
Mac解决 zsh: command not found: ll
Mac解决 zsh: command not found: ll 文章目录 Mac解决 zsh: command not found: ll解决方法 解决方法 1.打开bash_profile 配置文件vim ~/.bash_profile2.在文件中添加配置:alias llls -alF键盘按下 I 键进入编辑模式3. alias llls -alF添加完配置后,按…...
库打包工具 rollup
库打包工具 rollup 摘要 **概念:**rollup是一个模块化的打包工具 注:实际应用中,rollup更多是一个库打包工具 与Webpack的区别: 文件处理: rollup 更多专注于 JS 代码,并针对 ES Module 进行打包webpa…...

unplugin-vue-components 库作用
一、基本概念与用途 1. 自动导入 Vue 组件 unplugin - vue - components是一个用于 Vue 项目的插件,主要功能是自动导入组件,从而减少在 Vue 组件中手动导入其他组件的繁琐过程。 在大型 Vue 项目中,往往会有许多自定义组件或者第三方组件…...

LinkedList和单双链表。
java中提供了双向链表的动态数据结构 --- LinkedList,它同时也实现了List接口,可以当作普通的列表来使用。也可以自定义实现链表。 单向链表:一个节点本节点数据下个节点地址 给定两个有序链表的头指针head1和head2,打印两个链表…...
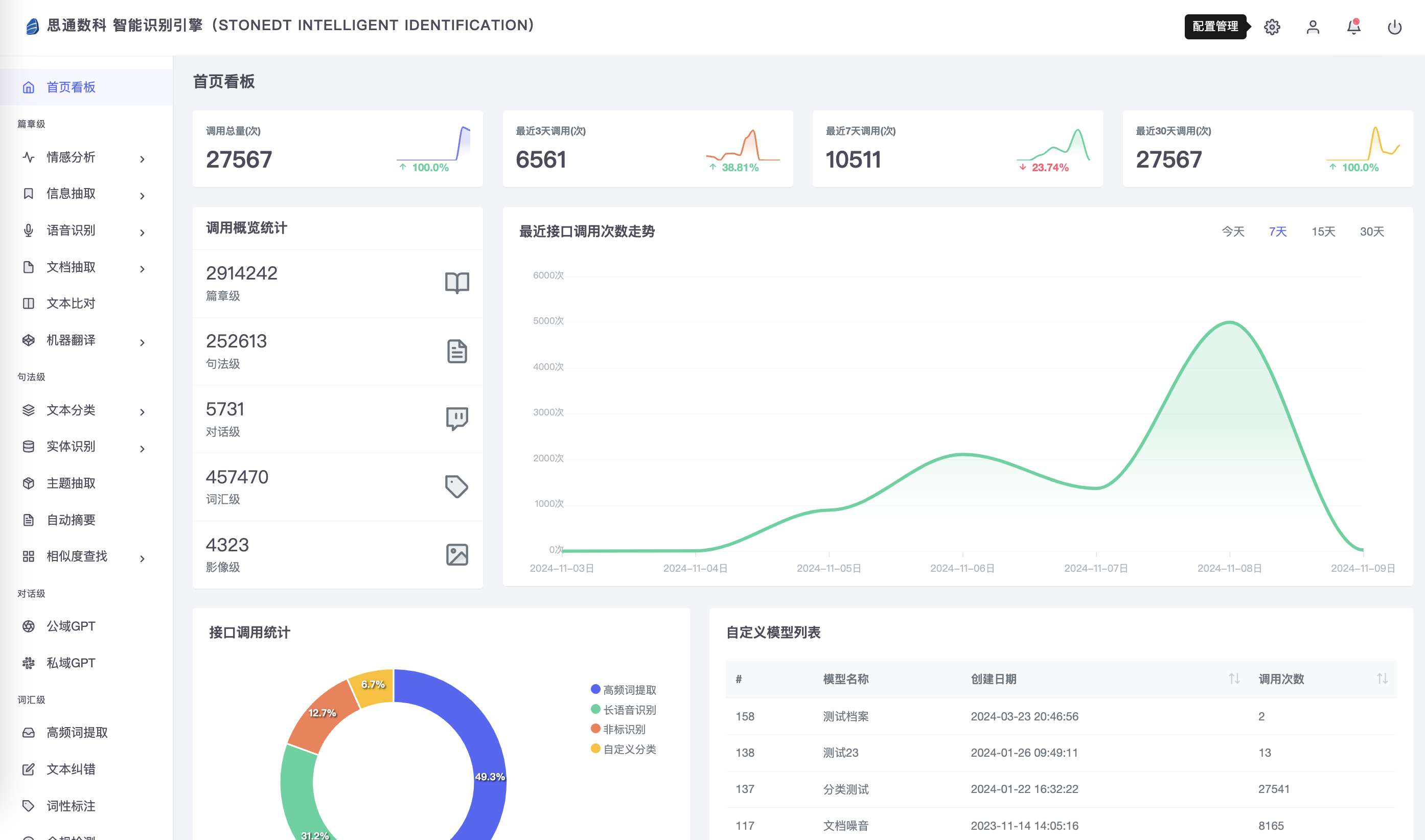
AI与OCR:数字档案馆图像扫描与文字识别技术实现与项目案例
文末有免费工具可在线体验,或者网络搜索关键词“思通开源AI能力平台” 一、扫描与图像预处理 技术实现过程 在纸质档案的数字化过程中,首先需要使用高精度扫描仪对纸质文档进行扫描,生成高清的数字图像。这一步骤是整个OCR流程的基础…...

Spring boot 读模块项目升级为spring cloud 项目步骤以及问题
1.结构说明 bean 模块 ,public 模块, client 模块, erp模块,system 主模块。 2.环境说明以及pom 原本环境 新环境 mysql 5.7 -------------- mysql 8.0 maven 3.9.6 jdk 8 -----------…...

时序数据库之influxdb和倒排索引以及LSM-TREE
一、时序数据库的特点 1、时序数据库用作打点,用来做监控使用,属于写多读少的场景,而且由于时间不可逆,几乎不可能出现更新的操作。而且监控数据一般只会查询最近几分钟数据,冷热数据查询频率非常明显。因此非常贴合ES…...

如何避免消息的重复消费问题?(消息消费时的幂等性)
如何避免消息的重复消费问题 1、 消息的幂等性1.1、概念1.2、产生业务场景 2、全局唯一IDRedis解决消息幂等性问题2.1、application.yml配置文件2.2、生产者发送消息2.3、消费者接收消息2.4、pom.xml引入依赖2.5、RabbitConfig配置类2.6、启动类2.7、订单对象2.8、测试 1、 消息…...

【Java SE】类与对象
现实世界中,随处可见的一个事物实体就是对象,而类就是同一类事物(或对象)的统称,由一个类构造对象的过程称为创建这个类的一个实例(instance),即: 类(class&…...

基于springboot的公益服务平台的设计与实现
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于springboot的公益服务平台的设计与实…...
 什么是Servlet容器?)
Tomcat(6) 什么是Servlet容器?
Servlet容器是Java EE技术中的一个关键组件,它负责管理和执行Servlet。Servlet容器提供了运行时环境,使得Servlet能够接收和响应来自客户端的HTTP请求。以下是Servlet容器的详细解释,以及一些相关的代码示例。 Servlet容器的主要功能 加载和…...

用js去除变量里的html标签
要用 JavaScript 去除字符串中的 HTML 标签,你可以使用正则表达式。以下是一个简单的示例代码: function removeHTMLTags(str) {return str.replace(/<[^>]*>/g, ); }// 示例 var str <p>This is <b>bold</b> text with <…...

Vue3+element-plus摘要
1.如果自己电脑vue版本是vue2版本,下面将详细介绍如何在vue2版本基础上继续安装 vue3版本且不会影响vue2版本的使用 1-1 在c盘或者别的盘建一个文件夹vue3 1-2 在这个文件夹里使用WINR 打开终端 输入命令 npm install vue/cli 安装完即可 1-3 然后进入此文件夹中的n…...
Android Studio 将项目打包成apk文件
第一步:选择Build -> Generate Signed APK 会出现: 我们选择 Create new… 然后选择你要存放密钥的地方 点击ok之后,则选择好了文件,并生成了jks文件了。 点击ok之后, 会出现: 选择release…...

贪心算法day2(最长递增子序列)
目录 1.最长递增子序列 方法一:动态规划 方法二:贪心二分查找 1.最长递增子序列 链接:. - 力扣(LeetCode) 方法一:动态规划 思路:我们定义dp[i]为最长递增子序列,那么dp[j]就是…...

arcgis pro 学习笔记
二维三维集合在一起,与arcgis不同 一、首次使用,几个基本设置 1.选项——常规里面设置自动保存时间 2.新建工程文件,会自动加载地图,可以在选项里面设置为无,以提高启动效率。 3.设置缓存位置,可勾选每次…...

告别电脑“飞机起飞“噪音:FanControl风扇控制终极指南
告别电脑"飞机起飞"噪音:FanControl风扇控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tr…...

Steam创意工坊模组下载终极指南:轻松获取1000+游戏模组的完整解决方案
Steam创意工坊模组下载终极指南:轻松获取1000游戏模组的完整解决方案 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为无法下载Steam创意工坊模组而烦恼吗&…...

基本面分析建模——用Excel构建财务筛选系统
价值投资就像相亲——你得设定条件,才能筛选出合适的对象。ROE是"赚钱能力",净利润增长率是"成长潜力",资产负债率是"家底厚不厚"。财报就像企业的"体检报告",而Excel就是你的"红娘系统"。记住,股东的钱生钱能力,才是…...

【knife4j】接口分组配置;登录拦截器放行;登录拦截器配置token;给全局异常处理类添加注解;解决上传文件不显示文件域;参数扁平化;@Parameter
Parameter Parameter 是用来为 API 接口参数添加元数据(描述信息)的注解,这些信息最终会生成到 OpenAPI 规范的文档中,供 Knife4j/Swagger UI 等工具展示 简单来说:它让 API 的使用者能清楚地知道每个参数的含义、是…...

LibreCAD符号库创建终极指南:快速构建您的专业CAD图库
LibreCAD符号库创建终极指南:快速构建您的专业CAD图库 【免费下载链接】LibreCAD LibreCAD is a cross-platform 2D CAD program. It can read DXF and write DXF/PDF/SVG files, with basic support for DWG reading. It supports point/line/circle/ellipse/parab…...

三自由度机械臂运动学建模与求解:从DH参数到算法验证
1. 三自由度机械臂运动学基础 刚接触机械臂控制时,我最头疼的就是运动学建模这部分。三自由度机械臂虽然结构简单,但要把它的运动规律用数学语言描述清楚,需要建立完整的理论框架。运动学主要研究机械臂末端执行器的位置、速度和加速度与各关…...

别再用docker tag了!深入理解Containerd生态:crictl、ctr与nerdctl到底该怎么选?
深入解析Containerd生态:crictl、ctr与nerdctl的镜像管理实战指南 在容器技术快速发展的今天,越来越多的开发者正从Docker生态转向Containerd这一更轻量、更符合Kubernetes标准的运行时环境。但当我们真正开始使用Containerd时,往往会遇到一个…...

构建自主可控安全自动化平台:从开源情报到自动化响应实践
1. 项目概述:从开源代码到安全实践的桥梁最近在梳理一些开源安全项目时,我注意到了mattijsmoens/openclaw-sovereign-shield这个仓库。单从名字看,“Sovereign Shield”(主权之盾)就透着一股强烈的防御和自主掌控的意味…...

87456238
8637452...

从指标到版图:基于Cadence与gmid方法的两级运放实战设计
1. 两级运放设计入门:从指标到晶体管的思维转换 第一次接触两级运放设计时,我盯着性能指标表发呆了半小时。AV≥10M、CL10pf、SR10V/us这些数字就像天书,直到导师扔给我一本《模拟集成电路设计艺术》和一份Cadence使用手册。现在回想起来&…...