算法(第一周)
一周周五,总结一下本周的算法学习,从本周开始重新学习许久未见的算法,当然不同于大一时使用的 C 语言以及做过的简单题,现在是每天一题 C++ 和 JavaScript(还在学,目前只写了一题)
题单是代码随想录(JS)和面试 150 题(C++), 括号中是我所用的解题语言。
令我印象最深的不是题目的难度,而是 leecode 的提交方式与我所用过的学校 oj 还有洛谷都不同,它所提交的是核心代码,一开始我都是使用 ai 帮我浓缩成核心代码样式,后面发现其实只需要补充 public 中的函数就可以了…… 我还一直在想 leecode 的输入格式到底是什么样的,话不多说开始总结:
代码随想录
移除链表元素
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:

输入:head = [1,2,6,3,4,5,6], val = 6 输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1 输出:[]
示例 3:
输入:head = [7,7,7,7], val = 7 输出:[]
提示:
- 列表中的节点数目在范围
[0, 104]内 1 <= Node.val <= 500 <= val <= 50
这题是我觉得比较简单的一道题,复习一下链表知识就好
var removeElements = function (head, val) {// 创建一个虚拟头节点const dummy = new ListNode(0);dummy.next = head;let current = dummy; // 从虚拟头节点开始遍历while (current.next !== null) {if (current.next.val === val) {// 跳过当前值等于 val 的节点//跳过了,就再也不存在这个地址,相当于删除这个元素current.next = current.next.next;} else {// 否则,继续移动到下一个节点current = current.next;}}// 返回新的头节点return dummy.next;
};// 定义链表节点的结构
class ListNode {constructor(val = 0, next = null) {this.val = val;this.next = next;}
}
面试 150
多数元素
给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
输入:nums = [3,2,3] 输出:3
示例 2:
输入:nums = [2,2,1,1,1,2,2] 输出:2
提示:
n == nums.length1 <= n <= 5 * 104-109 <= nums[i] <= 109
进阶:尝试设计时间复杂度为 O (n)、空间复杂度为 O (1) 的算法解决此问题。
这题看上去很难,想明白了就很简单,简单来说是要找到出现最多的那个元素,但是要想明白怎么找最省力:我们假设找出一种生物,用一个计数器为 0,当这个生物遇到同类 + 1,遇到其他生物就会 - 1,当 cnt 为 0 时,说明这个生物数量不够,自然就 dead 了,以此类推,如果走到最后这个生物的数量没有为 0,则证明它是最多的一类,如果前面都不存在这种生物,那留在最后的自然而然就是最多的
class Solution {
public:int majorityElement(vector<int>& nums) {int temp;int cnt = 0;for(int i = 0; i < nums.size();i++){if(cnt == 0)temp = nums[i];cnt+= (nums[i] == temp) ? +1 : -1;}return temp;}
};
合并两个有序数组
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3 输出:[1,2,2,3,5,6] 解释:需要合并 [1,2,3] 和 [2,5,6] 。 合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。
示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0 输出:[1] 解释:需要合并 [1] 和 [] 。 合并结果是 [1] 。
示例 3:
输入:nums1 = [0], m = 0, nums2 = [1], n = 1 输出:[1] 解释:需要合并的数组是 [] 和 [1] 。 合并结果是 [1] 。 注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。
提示:
nums1.length == m + nnums2.length == n0 <= m, n <= 2001 <= m + n <= 200-109 <= nums1[i], nums2[j] <= 109
这题也简单,只需要从后往前查找,比较 nums1 和 nums2 的大小,如果 nums1 大于 nums2 就往后放,反之就往前放,如果有多,nums1 未放完的自然都在前面,nums2 潍坊玩的只需要接着仿就行
#include <vector>
using namespace std;class Solution {
public:void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {int i = m - 1; // nums1 的有效元素索引int j = n - 1; // nums2 的有效元素索引int k = m + n - 1; // 合并后数组的最后一个索引// 从数组的最后一位开始查找while (i >= 0 && j >= 0) {if (nums1[i] > nums2[j]) {// 将较大的放到合并数组的末尾nums1[k] = nums1[i];i--;} else {nums1[k] = nums2[j];j--;}k--;}// 将 nums2 剩余的元素复制到 nums1 中while (j >= 0) {nums1[k] = nums2[j];j--;k--;}// nums1 的剩余元素不需要复制,因为它们已经在正确的位置上}
};
罗马数字转整数
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1 。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。
示例 1:
输入: s = "III" 输出: 3
示例 2:
输入: s = "IV" 输出: 4
示例 3:
输入: s = "IX" 输出: 9
示例 4:
输入: s = "LVIII" 输出: 58 解释: L = 50, V= 5, III = 3.
示例 5:
输入: s = "MCMXCIV" 输出: 1994 解释: M = 1000, CM = 900, XC = 90, IV = 4.
提示:
1 <= s.length <= 15s仅含字符('I', 'V', 'X', 'L', 'C', 'D', 'M')- 题目数据保证
s是一个有效的罗马数字,且表示整数在范围[1, 3999]内 - 题目所给测试用例皆符合罗马数字书写规则,不会出现跨位等情况。
- IL 和 IM 这样的例子并不符合题目要求,49 应该写作 XLIX,999 应该写作 CMXCIX 。
- 关于罗马数字的详尽书写规则,可以参考 罗马数字 – 百度百科。
这题需要学习一下关于 unordered_map,这里简单讲一下就是他可以存放名字+value,这样方便查找数字。思路是使用 for 循环遍历,使用 current 存储当前字母的数字,再用 next 去判断是否存在下一数字,只要存在就存入下一个字符的数字,不存在就入 0;然后进行比较,如果当前数字小于下一数字就减去当前数字,否则就加上当前数字,相等也要加上当前数字(IIII 这种情况),最后直接返回就行
class Solution {
public:int romanToInt(string s) {// 罗马数字字符与整数的映射unordered_map<char, int> romanMap = {{'I', 1}, {'V', 5}, {'X', 10}, {'L', 50},{'C', 100}, {'D', 500}, {'M', 1000}};int total = 0;int n = s.length();for (int i = 0; i < n; ++i) {// 获取当前字符和下一个字符的数字int current = romanMap[s[i]];int next = (i + 1 < n) ? romanMap[s[i + 1]] : 0;// 如果当前数字小于下一个数字,执行减法if (current < next) {total -= current;} else {// 否则,执行加法total += current;}}return total;}
};
买卖股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4] 输出:5 解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
示例 2:
输入:prices = [7,6,4,3,1] 输出:0 解释:在这种情况下, 没有交易完成, 所以最大利润为 0。
提示:
1 <= prices.length <= 1050 <= prices[i] <= 104
这题假设第一天是最低买入价格,将最大利润设置成 0(不能为负,不然不是利润),遍历数组,持续更新最低买入价格,要是比这个最低价格高就说明可能会存在最大利润,使用 max 函数比较最大利润(用当前价钱减去最低价格)
class Solution {
public:int maxProfit(vector<int>& prices) {if (prices.empty()) return 0; // 防止空数组访问int minPrice = prices[0]; // 最低买入价格int maxProfit = 0; // 最大利润for (int i = 1; i < prices.size(); i++) {if (prices[i] < minPrice) {minPrice = prices[i]; // 更新最低买入价格} else {maxProfit = max(maxProfit, prices[i] - minPrice); // 计算当前利润}}return maxProfit;
}};
删除有序数组中的重复项
给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。
考虑 nums 的唯一元素的数量为 k ,你需要做以下事情确保你的题解可以被通过:
- 更改数组
nums,使nums的前k个元素包含唯一元素,并按照它们最初在nums中出现的顺序排列。nums的其余元素与nums的大小不重要。 - 返回
k。
判题标准:
系统会用下面的代码来测试你的题解:
int[] nums = [...]; // 输入数组
int[] expectedNums = [...]; // 长度正确的期望答案int k = removeDuplicates(nums); // 调用assert k == expectedNums.length;
for (int i = 0; i < k; i++) {assert nums[i] == expectedNums[i];
}
如果所有断言都通过,那么您的题解将被 通过。
示例 1:
输入:nums = [1,1,2] 输出:2, nums = [1,2,_] 解释:函数应该返回新的长度2,并且原数组 nums 的前两个元素被修改为1,2
。 |
不需要考虑数组中超出新长度后面的元素。
示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4] 输出:5, nums = [0,1,2,3,4] 解释:函数应该返回新的长度5, 并且原数组 nums 的前五个元素被修改为0,1,2,3,4。不需要考虑数组中超出新长度后面的元素。
提示:
1 <= nums.length <= 3 * 104-104 <= nums[i] <= 104nums已按 非严格递增 排列
这题开始时我没想清楚从前开始算,这个比较应该是后一位与前一位比较,如果不相同,就将该元素赋值到一个新数组,再 cnt++,cnt 就是新数组长度(新数组是在原数组基础上添加,如果不相同那么添加的位置与原位置也相同,如果元素相同则删除一个元素,不管怎么样在原数组基础上增删都不会超过原数组长度,而且节省了空间)
class Solution {
public:int removeDuplicates(vector<int>& nums) {if (nums.empty()) return 0; // 如果数组为空,返回 0int count = 1; // count 用来追踪唯一元素的个数for (int i = 1; i < nums.size(); i++) {if (nums[i] != nums[i - 1]) { // 如果当前元素和前一个不同nums[count++] = nums[i]; // 将当前元素移动到不重复部分的末尾}}return count; // 返回不重复元素的个数}
};
移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素。元素的顺序可能发生改变。然后返回 nums 中与 val 不同的元素的数量。
假设 nums 中不等于 val 的元素数量为 k,要通过此题,您需要执行以下操作:
- 更改
nums数组,使nums的前k个元素包含不等于val的元素。nums的其余元素和nums的大小并不重要。 - 返回
k。
用户评测:
评测机将使用以下代码测试您的解决方案:
int[] nums = [...]; // 输入数组
int val = ...; // 要移除的值
int[] expectedNums = [...]; // 长度正确的预期答案。// 它以不等于 val 的值排序。int k = removeElement(nums, val); // 调用你的实现assert k == expectedNums.length;
sort(nums, 0, k); // 排序 nums 的前 k 个元素
for (int i = 0; i < actualLength; i++) {assert nums[i] == expectedNums[i];
}
如果所有的断言都通过,你的解决方案将会 通过。
示例 1:
输入:nums = [3,2,2,3], val = 3 输出:2, nums = [2,2,_,_] 解释:你的函数函数应该返回 k = 2, 并且 nums 中的前两个元素均为 2。 你在返回的 k 个元素之外留下了什么并不重要(因此它们并不计入评测)。
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2 输出:5, nums = [0,1,4,0,3,_,_,_] 解释:你的函数应该返回 k = 5,并且 nums 中的前五个元素为 0,0,1,3,4。 注意这五个元素可以任意顺序返回。 你在返回的 k 个元素之外留下了什么并不重要(因此它们并不计入评测)。
提示:
0 <= nums.length <= 1000 <= nums[i] <= 500 <= val <= 100
与代码随想录题目相同,从 js 改成了 c++
class Solution {
public:int removeElement(vector<int>& nums, int val) {int newLength = 0; // 用于记录新数组的有效长度// 遍历 nums 数组for (int i = 0; i < nums.size(); i++) {if (nums[i] != val) {nums[newLength] = nums[i]; // 将非 val 元素放到前面newLength++; // 更新新数组的长度}}return newLength; // 返回新数组的长度}
};
本周题解就到这里结束,下周见。
相关文章:
算法(第一周)
一周周五,总结一下本周的算法学习,从本周开始重新学习许久未见的算法,当然不同于大一时使用的 C 语言以及做过的简单题,现在是每天一题 C 和 JavaScript(还在学,目前只写了一题) 题单是代码随想…...

Linux服务器进程的控制与进程之间的关系
在 Linux 服务器中,进程控制和进程之间的关系是系统管理的一个重要方面。理解进程的生命周期、控制以及它们之间的父子关系对于系统管理员来说至关重要。以下是关于进程控制、进程之间的关系以及如何管理进程的详细介绍: 1. 进程的概念 进程࿰…...

机器学习Housing数据集
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from sklearn.datasets import fetch_openml 设置Seaborn的美观风格 sns.set(style“whitegrid”) Step 1: 下载 Housing 数据集,并读入计算机 def load_housing_data(): housing …...

随着最新的补丁更新,Windows 再次变得容易受到攻击
SafeBreach专家Alon Leviev发布了一款名为 Windows Downdate的工具,可用于对Windows 10、Windows 11 和 Windows Server 版本进行降级攻击。 这种攻击允许利用已经修补的漏洞,因为操作系统再次容易受到旧错误的影响。 Windows Downdate 是一个开源Pyth…...

【Python】爬虫通过验证码
1、将验证码下载至本地 # 获取验证码界面html url http://www.example.com/a.html resp requests.get(url) soup BeautifulSoup(resp.content.decode(UTF-8), html.parser)#找到验证码图片标签,获取其地址 src soup.select_one(div.captcha-row img)[src]# 验证…...
dc-aichat(一款支持ChatGPT+智谱AI+讯飞星火+书生浦语大模型+Kimi.ai+MoonshotAI+豆包AI等大模型的AIGC源码)
dc-aichat 一款支持ChatGPT智谱AI讯飞星火书生浦语大模型Kimi.aiMoonshotAI豆包AI等大模型的AIGC源码。全网最易部署,响应速度最快的AIGC环境。PHP版调用各种模型接口进行问答和对话,采用Stream流模式通信,一边生成一边输出。前端采用EventS…...

检索增强生成
检索增强生成 检索增强生成简介 检索增强生成(RAG)旨在通过检索和整合外部知识来增强大语言模型生成文本的准确性和丰富性,其是一个集成了外部知识库、信息检索器、大语言模型等多个功能模块的系统。 RAG 利用信息检索、深度学习等多种技术…...

操作系统--进程
2.1.1 进程的概念、组成、特征 进程的概念 进程的组成 进程的特征 总结 2.1.2 进程的状态与转换,进程的组织 创建态、就绪态 运行态 阻塞态 终止态 进程状态的转换 进程的组织 链式方式 索引方式 2.1.3 进程控制 如何实现进程控制? 在下面的例子,将PCB2的是state设为1和和把…...

abap 可配置通用报表字段级日志监控
文章目录 1.功能需求描述1.1 功能1.2 效果展示2.数据库表解释2.1 表介绍3.数据库表及字段3.1.应用日志数据库抬头表:ZLOG_TAB_H3.2.应用日志数据库明细表:ZLOG_TAB_P3.3.应用日志维护字段配置表:ZLOG_TAB_F4.日志封装类5.代码6.调用方式代码7.调用案例程序demo1.功能需求描述 …...

OpenCV视觉分析之目标跟踪(11)计算两个图像之间的最佳变换矩阵函数findTransformECC的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 根据 ECC 标准 78找到两幅图像之间的几何变换(warp)。 该函数根据 ECC 标准 ([78]) 估计最优变换(warpMatri…...

PGMP-串串0203 项目集管理绩效域战略一致性
1.项目集管理绩效域 2.战略一致性 战略一致性包含内容商业论证BC项目集章程项目集路线图环境评估项目集风险管理策略 前期formulation sub-phaseplanning sub-phase组织的战略计划项目集风险管理策略项目集管理计划商业论证BC项目集章程项目集路线图环境评估...

HiveMetastore 的架构简析
HiveMetastore 的架构简析 Hive Metastore 是 Hive 元数据管理的服务。可以把元数据存储在数据库中。对外通过 api 访问。 hive_metastore.thrift 对外提供的 Thrift 接口定义在文件 standalone-metastore/src/main/thrift/hive_metastore.thrift 中。 内容包括用到的结构体…...

【WRF模拟】全过程总结:WPS预处理及WRF运行
【WRF模拟】全过程总结:WPS预处理及WRF运行 1 数据准备1.1 嵌套域设置(Customize domain)-基于QGis中gis4wrf插件1.2 静态地理数据1.2.1 叶面积指数LAI和植被覆盖度Fpar(月尺度)1.2.2 地面反照率(月尺度)1.2.3 土地利用类型+不透水面积1.2.4 数据处理:geotiff→tiff(W…...
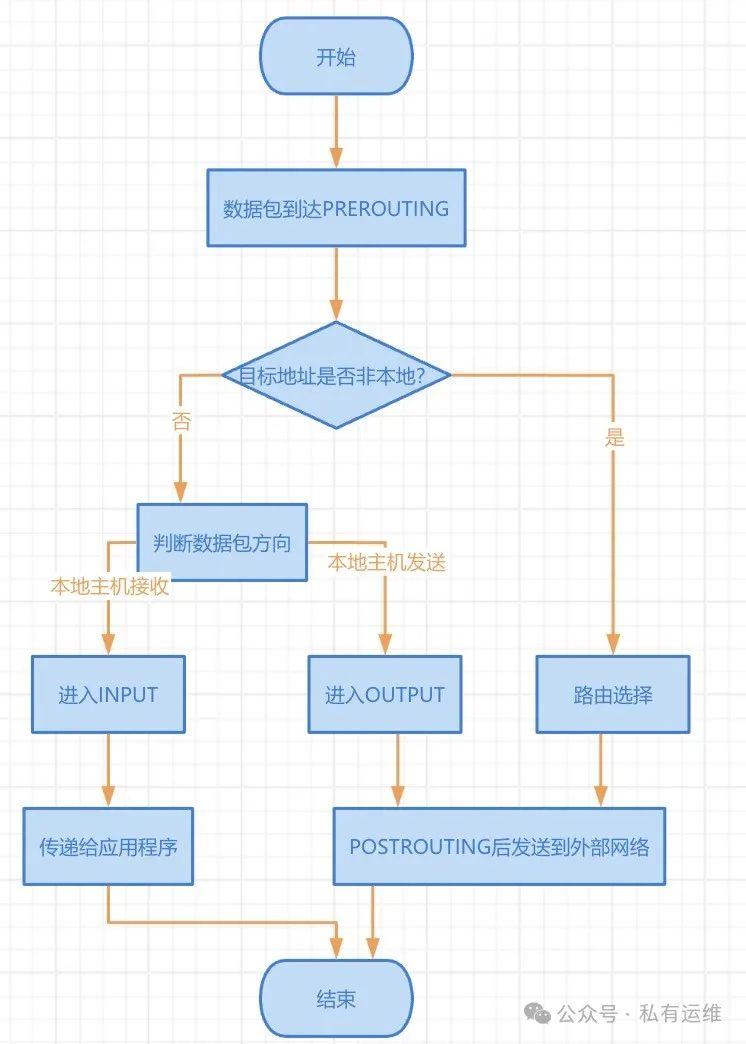
linux基础理解和使用 iptables 防火墙
本文档旨在编写一份详尽的 iptables基础 使用指南,涵盖其核心概念、使用方法以及高级技巧。将结合图表和示例,更好地理解和应用 iptables。 1. 什么是 iptables? iptables 是 Linux 系统自带的包过滤防火墙,它与内核空间的 netf…...
)
【系统架构设计师】2024年下半年真题论文: 论软件维护及其应用(包括参考素材)
更多内容请见: 备考系统架构设计师-专栏介绍和目录 文章目录 真题题目(2024年下半年 试题2)论文素材参考软件维护的类型软件维护的方法软件维护应用案例分析软件维护面临的挑战与应对策略真题题目(2024年下半年 试题2) 请围绕 “论软件维护及其应用” 论题,依次从以下三…...

【数学二】线性代数-矩阵-初等变换、初等矩阵
考试要求 1、理解矩阵的概念,了解单位矩阵、数量矩阵、对角矩阵、三角矩阵、对称矩阵、反对称矩阵和正交矩阵以及它们的性质. 2、掌握矩阵的线性运算、乘法、转置以及它们的运算规律,了解方阵的幂与方阵乘积的行列式的性质. 3、理解逆矩阵的概念,掌握逆矩阵的性质以及矩阵可…...
MinerU容器构建教程
一、介绍 MinerU作为一款智能数据提取工具,其核心功能之一是处理PDF文档和网页内容,将其中的文本、图像、表格、公式等信息提取出来,并转换为易于阅读和编辑的格式(如Markdown)。在这个过程中,MinerU需要利…...

BFS 解决拓扑排序
BFS 解决拓扑排序 1.课程表1.1. 题⽬链接:1.2 题⽬描述:1.3. 解法:1.4 代码 2. 课程表2.1题⽬链接:2.2 题⽬描述:2.3解法:2.4代码 3. ⽕星词典(hard)3.1题⽬链接:3.2 题⽬…...

MySQL 程序设计课程复习大纲
作为一门基础的 MySQL 程序设计课程,期末复习的重点应放在常见的数据库操作、基本查询、数据建模、关系型数据库的规范化设计等方面。以下是针对基础课程的 MySQL 期末复习知识点。 1. MySQL 基础概念与数据库操作 数据库基础 数据库与表的概念数据库管理系统&…...

C++ : STL容器(适配器)之stack、queue剖析
STL容器适配器之stack、queue剖析 一、stack、queue的接口(一)stack 接口说明(二)queue 接口说明 二、stack、queue的模拟实现(一)stack、queue是容器适配器stack、queue底层默认容器--deque1、deque概念及…...

pyecharts-assets终极指南:告别网络依赖,打造本地可视化环境
pyecharts-assets终极指南:告别网络依赖,打造本地可视化环境 【免费下载链接】pyecharts-assets 🗂 All assets in pyecharts 项目地址: https://gitcode.com/gh_mirrors/py/pyecharts-assets 还在为pyecharts图表加载慢而烦恼吗&…...

AI智能体开发新范式:用TDD工程化方法构建可靠LLM应用
1. 项目概述:当AI智能体遇上测试驱动开发最近在GitHub上看到一个挺有意思的项目,叫agent-skill-tdd。光看名字,就能嗅到一股“新老结合”的味道——一边是当下火热的AI智能体(Agent),另一边是软件工程领域经…...

Silk-v3-decoder:打破即时通讯音频格式壁垒的专业解码方案
Silk-v3-decoder:打破即时通讯音频格式壁垒的专业解码方案 【免费下载链接】silk-v3-decoder [Skype Silk Codec SDK]Decode silk v3 audio files (like wechat amr, aud files, qq slk files) and convert to other format (like mp3). Batch conversion support. …...

从赛博朋克到量子有机体,未来主义风格演进全图谱,深度解析MJ 5.2→6.2→NijiV6的渲染范式跃迁
更多请点击: https://intelliparadigm.com 第一章:赛博朋克到量子有机体:未来主义视觉范式的哲学跃迁 当霓虹雨巷中的义体少女凝视全息广告牌,她瞳孔倒映的已不仅是资本编码的欲望图景,而是意识与拓扑量子态耦合的初始…...

AI编码工具集:提升开发效率的智能助手选型与应用指南
1. 项目概述:为什么我们需要一个AI编码工具集?如果你和我一样,每天大部分时间都在和代码打交道,那你肯定对这样的场景不陌生:面对一个复杂的业务逻辑,你卡在某个函数的设计上,反复调试却找不到最…...

Unity 2D游戏开发:用Cinemachine 2D Camera实现平滑镜头跟随,告别手动写代码
Unity 2D游戏开发:用Cinemachine 2D Camera实现平滑镜头跟随,告别手动写代码 在2D游戏开发中,摄像机跟随是最基础却又最容易出问题的功能之一。很多开发者习惯用代码手动控制摄像机的位置更新,却常常陷入边界抖动、跟随延迟不自然…...

AI智能体评估框架Agent Vibes:构建标准化基准测试的实践指南
1. 项目概述与核心价值最近在AI智能体开发圈子里,一个名为“Agent Vibes”的项目引起了我的注意。这个项目名听起来就挺有意思,直译过来是“智能体氛围”或者“智能体感觉”,它本质上是一个开源的、用于构建和评估AI智能体(Agent&…...

Overture开源框架:快速部署生产级大语言模型API服务
1. 项目概述:一个开箱即用的开源AI应用框架最近在折腾AI应用开发的朋友,估计都绕不开一个核心问题:如何快速、稳定地把一个大语言模型(LLM)的能力,封装成一个能对外提供服务的API,并且这个服务还…...

Djot表格制作教程:简单创建专业级数据展示
Djot表格制作教程:简单创建专业级数据展示 【免费下载链接】djot A light markup language 项目地址: https://gitcode.com/gh_mirrors/dj/djot 想要在文档中快速创建美观的表格吗?Djot表格功能让数据展示变得简单高效!Djot作为一款轻…...

GUID partition table, GPT 磁盘分区表
GPT分割表 LBA0 (MBR 兼容区块) 与 MBR 模式相似的,这个兼容区块也分为两个部份,一个就是跟之前 446 bytes 相似的区块,存储了第一阶段的开机管理程式! 而在原本的分割表的纪录区内,这个兼容模式仅放入一个特殊标志的分割,用来表示此磁盘为 GPT 格式之意。而不懂 GPT 分割…...