ThreadLocal的熟悉与使用
目录
- 1.ThreadLocal介绍
- 2.ThreadLocal源码解析
- 2.1 常用方法
- 2.2 结构设计
- 2.3 类图
- 2.4 源码分析
- 2.4.1 set方法分析
- 2.4.2 get方法分析
- 2.4.3 remove方法分析
- 3.ThreadLocal内存泄漏分析
- 3.1 相关概念
- 3.1.1 内存溢出
- 3.1.2 内存泄漏
- 3.1.3 强引用
- 3.1.4 弱引用
- 3.2 内存泄漏是否和key使用的弱引用有关
- 3.2.1 假设key使用强引用
- 3.2.2 假设key使用弱引用
- 3.2.3 内存泄漏的真实原因
- 3.2.4 ThreadLocalMap的key使用弱引用的原因
- 4.ThreadLocal使用场景
1.ThreadLocal介绍
ThreadLocal 是Java JDK中提供的一个类,用于提供线程内部的局部变量,这种变量在多线程下的环境下去访问时能保证各个线程的变量独立于其他线程的变量。也就是说,使用ThreadLocal 可以提供线程内部的局部变量(通过ThreadLocal的set() 和 get() 方法),不同的线程之间不会互相干扰,这种变量在线程的生命周期内起作用,可以减少同一个线程内多个函数或者组件之间一些公共变量传递的复杂度。听起来好像挺复杂的,下面我们使用一个简单的案例来解释一下ThreadLocal的作用。
案例说明: 演示的代码将会使用一个TestData类表示存放在线程里面的数据,然后开启10个线程,在每个线程中设置数据后紧接着获取数据,并且使用Thread.currentThread().getName()标识对应的线程。然后为每个线程设置名称,方便我们观察线程的数据情况。
在不使用ThreadLocal和加锁的情况下:
public class ThreadLocalDemo {public static void main(String[] args) {TestData testData = new TestData();for (int i = 0; i < 10; i++) {Thread thread = new Thread(new Runnable() {@Overridepublic void run() {testData.setData("数据XXX,当前线程是===>"+ Thread.currentThread().getName());System.out.println("当前线程是: "+ Thread.currentThread().getName()+ ",存放的数据是:" + testData.getData());}});thread.setName("线程===>" + i);thread.start();}}static class TestData {private String data;public void setData(String data) {this.data = data;}public String getData() {return data;}}
}
运行上面的代码结果如下:

如上图所示:我们发现有的线程拿到的数据是其他线程的,也就是各个线程之间的数据错乱了,这种情况是一种错误,因为线程之间的数据发生了相互干扰的情况。比如上图中选中的部分,线程1存放的数据被线程4拿到了。正确的情况应该是,线程1存放的数据,应该也是由线程1取。即各个线程之间不应该相互干扰
解决上面线程间错误的问题有两种方法,一是加锁,二是使用ThreadLocal,接下来看加锁的方案,代码如下:
public static void main(String[] args) {TestData testData = new TestData();for (int i = 0; i < 10; i++) {Thread thread = new Thread(new Runnable() {@Overridepublic void run() {// 加锁解决线程间数据错乱的问题synchronized (ThreadLocalDemo.class){testData.setData("数据XXX,当前线程是===>"+ Thread.currentThread().getName());System.out.println("当前线程是: "+ Thread.currentThread().getName()+ ",存放的数据是:" + testData.getData());}}});thread.setName("线程===>" + i);thread.start();}}
在每个线程的run方法中添加一个synchronized锁,在多个线程的情况下,限制每次只能有一个线程存取数据,这样就能解决线程间数据干扰的问题,运行结果如下:

如上图所示,使用加锁的方案后,线程存数据和取数据的线程都是同一个了,不会出现线程1的数据被线程2取到了
然后我们再看下使用ThreadLocal的方式解决线程间数据相互干扰的问题,代码如下:
static class TestData {private ThreadLocal<String> tl = new ThreadLocal<>();public void setData(String data) {tl.set(data);}public String getData() {return tl.get();}}
运行结果如下:

如上图所示,存储数据时使用TreadLocal的set方法,取数据时使用ThreadLocal的get()方法,这样也能解决线程间数据相互干扰的问题,具体原理会在后面源码分析部分解析
看完上面的例子,可能会有小伙伴心中有疑问,既然加锁可以解决线程间数据相互干扰的问题,那么为啥还需要设计出一个ThreadLocal呢?其实这得联系synchronized和ThreadLocal的区别,synchronized是一种同步机制,采用以“时间换空间”的方式,只是提供一份数据,让不同的线程排队使用,它的侧重点在于多个线程之间同步访问资源。而ThreadLocal则是以“空间换时间”,为每一个线程都提供了一份数据的副本,从而实现同时访问而互不干扰,它侧重于多线程中让每个线程之间的数据的相互隔离。在上面的例子中我们强调的是线程数据隔离的问题,使用synchronized不仅消耗性能(加锁会使程序的性能降低),而且加锁更加使用于数据共享的场景,用在此处并不合适,使用TreadLocal可以使程序获得更高的并发性。
通过上面的例子,相信读者已经可以简单的理解ThreadLocal是啥以及它的作用了,接下来我们将从源码分析ThreadLocal,一点点解开其背后的神秘面纱。
2.ThreadLocal源码解析
2.1 常用方法
| 方法 | 描述 |
|---|---|
| ThreadLocal() | 构造方法,创建ThreadLocal对象 |
| public void set(T value) | 设置当前线程绑定的数据 |
| public T get() | 获取当前线程绑定的数据 |
| public void remove() | 移除当前线程绑定的数据 |
2.2 结构设计
这里我们说的ThreadLocal都是JDK 1.8之后的,在JDK1.8中,每个Thread维护一个ThreadLocalMap哈希表,这个Hash表的Key是ThreadLocal本身,value是要存储的数据Object具体的过程如下:
1.每个Thread都有一个Map,名为ThreadLocalMap
2.ThreadLocalMap里面存储了ThreadLocal对象(Key)和线程的数据副本(Value)
3.Thread内部的ThreadLocalMap是由ThreadLocal维护的,由ThreadLocal负责向map获取和设置线程的数据
4.对于不同的线程,每次获取副本数据时,别的线程并不能获取当前线程的副本数据,实现了副本数据的隔离。
ThreadLocal的结构如下所示:

2.3 类图

ThreadLocalMap 是ThreadLocal的内部类,没有实现Map接口,而是使用独立的方式实现了Map的功能,其内部的Entry也是独立实现的。并且继承自弱引用的接口
2.4 源码分析
下面先解释下ThreadLocal中会用到的存储结构,Entry类,代码如下所示:
static class Entry extends WeakReference<ThreadLocal<?>> {/** The value associated with this ThreadLocal. */Object value;Entry(ThreadLocal<?> k, Object v) {super(k);value = v;}}
从Entry的代码中我们可以得知,Entry继承自WeakReference,并且使用ThreadLocal作为key.并且这个key只能是ThreadLocal对象.
补充:在ThreadLocal中会自定义一个ThreadLocalMap以Key、Value的方式保存值,类似于HashMap。我们都知道HashMap会有Hash冲突,而解决HashMap冲突的方法是
链地址法,而ThreadLocalMap解决冲突的方法是线性探测法,该方法一次探测一个地址,直到有空地址可插入,若是整个空间都找不到空余的地址,则产生溢出。比如,假设当前数组的长度为16,如果计算出来的索引为14,而数组中位置为14的地方已经有值了,并且这个值的key和当前待插入数据的key不一样,那么此时就发生了哈希冲突。线性探测法就是说这时候可以通过一个线性的函数,将当前的位置作为输入,经过线性函数运算后得到一个输出,,比如我们确定这个线性函数为y = x + 1,y为计算后的索引值,x为输入的索引值,我们这时候可以将14输入线性函数,得到新的索引为15,取数组中位置为15的位置的值判断,如果还是冲突,则会溢出,这时候可以判断溢出的时候就从位置0继续使用线性探测法查找可以插入数据的位置。
2.4.1 set方法分析
当我们使用ThreadLocal的时候,首先会通过new关键字创建一个ThreadLocal对象,然后调用ThreadLocal的set方法保存我们想要保存的值,set方法执行过程的源码如下:
使用ThreadLocal对象调用set方法存储数据的时候,会首先调用下面的set方法,下面的方法会将当前线程对象和需要保存的数据一起传入内部的set(Thread,value)方法里。
public void set(T value) {// 调用内部的set方法,并且将当前的线程对象和要保存的值传递过去set(Thread.currentThread(), value);if (TRACE_VTHREAD_LOCALS) {dumpStackIfVirtualThread();}}
set(Thread,value)方法会首先去获取下当前线程是否已经关联了ThreadLocalMap,如果已经关联了就直接取出这个Map,调用其set方法保存数据,否则创建一个新的ThreadLocalMap,并保存数据,并且将创建的ThreadLocalMap赋值给当前线程里面的threadLocals变量。
private void set(Thread t, T value) {// 获取和当前线程相关联的ThreadLocalMapThreadLocalMap map = getMap(t);// 如果获取到的ThreadLocalMap不为空,则直接调用ThreadLocalMap的set方法直接赋值// 否则使用当前线程和需要保存的值直接创建ThreadLocalMap对象,需要注意的是,这里不用再// 调用ThreadLocalMap的set方法了,因为值的保存操作会在ThreadLocalMap的构造函数中完成if (map != null) {map.set(this, value);} else {createMap(t, value);}}// 通过线程去拿与其关联的ThreadLocalMap,从下面的代码// 可以看出,ThreadLocalMap被作为了一个成员变量声明到了线程// Thread类中ThreadLocalMap getMap(Thread t) {return t.threadLocals;}// 使用线程和需要保存的数据创建一个ThreadLocalMap对象,// 并将其赋值给当前线程的threadLocals变量void createMap(Thread t, T firstValue) {t.threadLocals = new ThreadLocalMap(this, firstValue);}
当线程中关联的ThreadLocalMap为空时会使用ThreadLocal作为key,需要保存的数据作为Value去新建一个ThreadLocalMap对象,下面是ThreadLocalMap的构造方法。
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {// table 和HashMap中的table类似,这里的INITIAL_CAPACITY是16,必须为2的幂次方,// 原因后面会介绍// 这里主要是初始化table数组,数据的元素类型是Entry的,初始容量是16table = new Entry[INITIAL_CAPACITY];// 和HashMap一样,使用key的HashCode和长度减一做与操作,计算出一个索引值int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);// 将要保存的数据包装成Entry后保存到索引对应的位置table[i] = new Entry(firstKey, firstValue);// 记录当前ThreadLocalMap的大小size = 1;// 设置扩容的阈值setThreshold(INITIAL_CAPACITY);}// 设置阈值,当阈值达到设置长度的2/3时进行扩容操作private void setThreshold(int len) {threshold = len * 2 / 3;}
如果线程中的ThreadLocalMap不为空的情况下,会被取出来调用其set(ThreadLocal<?> key, Object value) 方法保存数据,这个方法的具体解析如下面代码中的注释所示。
private void set(ThreadLocal<?> key, Object value) {Entry[] tab = table;// 记录下table的长度int len = tab.length;// 计算待插入元素在table数组中的索引,使用的是和HashMap类似的,使用key的hash值和// 数组的长度减一做与操作。这里的数组长度需要是2的幂次方int i = key.threadLocalHashCode & (len-1);for (Entry e = tab[i];e != null;e = tab[i = nextIndex(i, len)]) {ThreadLocal<?> k = e.get();// 如果待插入的key已经存在,则直接使用待插入的数据覆盖原来的数据即可if (k == key) {e.value = value;return;}// 如果key为null,但是数据value不为null,则说明之前的ThreadLocal对象已经被回收了if (k == null) {// 使用新的元素替换之前的元素replaceStaleEntry(key, value, i);return;}}// ThreadLocal对应的key不存在并且没有找到旧的元素,则在空元素的位置新建一个Entrytab[i] = new Entry(key, value);// 增加ThreadLocalMap的sizeint sz = ++size;// cleanSomeSlots用于清除e.get == null的元素// 因为这种数据key关联的对象已经被回收,所以Entry(table[index])可以被置为null,// 如果没有清除任何的Entry,并且当前的使用量达到了负载因子所定义的(长度的2/3),// 那么进行再次哈希计算的逻辑(rehash),执行一次全表的扫描清理工作if (!cleanSomeSlots(i, sz) && sz >= threshold)rehash();}// 循环获取数组的下一个索引private static int nextIndex(int i, int len) {return ((i + 1 < len) ? i + 1 : 0);}在上面的代码中我们提到了数组的长度需要是2的幂次方,原因如下:
我们都知道通常情况下如果想要将某个Hash值映射到数组的索引上,通常会使用到取模(%)运算符,因为这可以确保生成的索引在数组的范围类,例如生成数组长度为16,计算的结果会在0到15之间。,那我们在HashMap和ThreadLocalMap中要规定数组的长度必须是2的幂次方呢?那是因为计算数组的索引没有采用传统的取模(%)运算,而使用的是与(&)操作,如下图所示:
使用与操作会比取模操作快很多,但是只有当数组长度为2的幂次方时,hashcode&(数组长度 - 1) 才等价于 hashcode % 数组长度,,其次保证数组长度为2的幂次方也恶意减少冲突的次数,提高查询的效率。例如,若数组长度为2的幂次方,则数组长度减一转为二进制必定是1111…的形式,在和hashcode二进制做与操作时效率会非常高,而且空间不浪费。举个反例,假设数组的长度不是2的幂次方,不妨设为15,则数组的长度减一为14,对应的二进制为1110,在与hashcode做“与操作”时,由于最后一位都是0,这就会导致数组位置索引最后一位为“1”的位置(如0001,0101,1011,1101)永远无法存放元素,浪费空间,并且导致数组可使用的位置比数组长度小很多,发生哈希冲突的几率增大,并且降低了查询效率。
注意:这里的hashcode不是指通过对象的hashCode()方法获取到的值,而是经过一些算法得到的一个哈希值

set方法代码的执行流程
- 根据key的hashcode计算出索引"i",然后查找到"i"位置上的Entry
- 若Entry存在,并且key等于传入的key,那么直接给找到的Entry赋新的value值
- 若Entry存在,但是key为null,则调用replaceStaleEntry()方法更换key为空的Entry
- 若不存在上面的情况,则开启循环检测,直到遇到为null的位置,在这个null位置新建一个Entry,然后插入,同时将ThreadLocalMap的size增加1
- 调用cleanSomeSlots方法,清理Key为null的Entry,最后返回是否清理了Entry的结果,然后再判断ThreadLocalMap的size是否大于等于扩容的阈值,如果达到了,需要执行rehash函数进行全表扫描清理,清理完ThreadLocalMap的size还是大于阈值的3/4的化,那么就需要进行扩容。扩容操作会将数组的长度扩容为之前的两倍
2.4.2 get方法分析
get方法是获取当前线程中保存的值,调用的方式就是使用ThreadLocal的对象调用get方法,ThreadLocal中的get方法如下所示:
public T get() {// 获取当前线程Thread t = Thread.currentThread();// 根据当前线程拿到ThreadLocalMapThreadLocalMap map = getMap(t);if (map != null) {// ThreadLocalMap不为空的情况下,调用ThreadLocalMap的getEntry方法,// 传入当前的ThreadLocal(key),拿到当前ThreadLocal对应的数据并返回给调用者ThreadLocalMap.Entry e = map.getEntry(this);if (e != null) {@SuppressWarnings("unchecked")// 将数据做一个类型转换,然后返回T result = (T)e.value;return result;}}// ThreadMap为空的情况下,会调用setInitialValue方法返回一个值return setInitialValue();}// 拿到线程对应的ThreadLocalMap对象ThreadLocalMap getMap(Thread t) {return t.threadLocals;}// 设置ThreadLocal的初始值private T setInitialValue() {// 通过initialValue方法获取初始值,initialValue是一个可供// 子类重写的方法,子类可以重写initialValue方法提供一个默认// 值,不重写的情况下为null.T value = initialValue();// 获取当前线程Thread t = Thread.currentThread();// 根据当前线程拿到ThreadLocalMapThreadLocalMap map = getMap(t);// 如果ThreadLocalMap不为空,则将通过initialValue获取的值设// 置给ThreadLocalMapif (map != null) {map.set(this, value);} else {// 如果通过当前线程没有获取到ThreadLocalMap,则创建一个ThreadLocalMap并将通过// initialValue方法获取到的值设置给它createMap(t, value);}// 不是重点,不分析,这里是为了解决ThreadLocal引用泄漏的问题的,TerminatingThreadLocal // 提供了一种机制,可以在线程终止时自动清理其绑定的数据。if (this instanceof TerminatingThreadLocal) {TerminatingThreadLocal.register((TerminatingThreadLocal<?>) this);}return value;}// ThreadLocalMap中的getEntry方法,参数:keyprivate Entry getEntry(ThreadLocal<?> key) {// 通过key的threadLocalHashCode计算出数组table中的索引位置int i = key.threadLocalHashCode & (table.length - 1);// 通过计算出的索引值拿到对应的Entry元素Entry e = table[i];// 若拿到的元素不为null,并且元素的key和当前传入的key相同,则证明找到了// 传入的key对应的Entry元素,直接返回if (e != null && e.get() == key)return e;else// 否则可能是在插入数据时有冲突被放到了其他位置了,通过getEntryAfterMiss方法// 继续查找其他位置return getEntryAfterMiss(key, i, e);}// 查找Entry元素,参数key:待查找元素的key,i: 当前元素的索引,索引i对应的元素Entryprivate Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {// 拷贝一份当前的table数组Entry[] tab = table;// 记录当前数组的长度int len = tab.length;// 若是元素Entry不为null,就循环查找,直到找到待查找元素key对应的Entry为止while (e != null) {ThreadLocal<?> k = e.get();// 如果e的key等于待查找的元素的key,证明找到了直接返回就行if (k == key)return e;// 如果e的key为null,则调用expungeStaleEntry方法替换if (k == null)// 清除key为null的EntryexpungeStaleEntry(i);else// 通过线性探测法继续寻找下一个位置,插入值的时候如果有冲突也是通过这个方法// 解决的,所以查询值的时候,如果不在通过key的hashcode值计算出的索引位置// 就可以通过这个函数继续寻找下一个位置。直到找到待查找key对应的数据为止i = nextIndex(i, len);e = tab[i];}// 如果没有找到就返回nullreturn null;}2.4.3 remove方法分析
ThreadLocal的remove方法用于删除当前线程中保存的ThreadLocal对应的Entry,代码如下所示:
public void remove() {// 首先通过当前线程获取到TheadLocalMap,不为null的情况下// 删除当前ThreadLocal保存的Entry;如果为null,表示// 不需要删除ThreadLocalMap m = getMap(Thread.currentThread());if (m != null) {// 调用ThreadLocalMap的remove方法删除保存的Entrym.remove(this);}}// ThreadLocalMap中删除ThreadLocal对应的Entryprivate void remove(ThreadLocal<?> key) {// 拷贝一份table数组Entry[] tab = table;// 记录数组的长度int len = tab.length;// 根据当前的key计算出Entry的索引位置"i"int i = key.threadLocalHashCode & (len-1);// 在数组中遍历查找key对应的entryfor (Entry e = tab[i];e != null;e = tab[i = nextIndex(i, len)]) {// 查找到key对应的entryif (e.get() == key) {// 调用Entry的clear方法清理掉Entry,其实就是将当前的Entry引用置为null// 等待垃圾回收器回收e.clear();// 清除key为null的EntryexpungeStaleEntry(i);return;}}// Entry中的clear方法public void clear() {this.referent = null;}
3.ThreadLocal内存泄漏分析
3.1 相关概念
3.1.1 内存溢出
内存溢出(Memory overflow)是指没有足够的内存提供给申请者使用
3.1.2 内存泄漏
内存泄漏(Memory leak)指的时程序中已经动态分配的堆内存由于某种原因未释放或者是无法释放,造成系统内存的浪费,从而导致程序运行速度减慢升值系统崩溃的严重后果,内存泄漏的堆积最终将会导致内存溢出
3.1.3 强引用
强引用(Strong Reference)就是我们常见的普通对象的引用,比如:Object strongRef = new Object();就是一种强引用,只要某个对象有强引用指向它,垃圾回收器(Garbage Collector) 就不会回收该对象。
3.1.4 弱引用
弱引用(Weak Reference) 是一种特殊的引用类型,用于改善内存管理。弱引用允许垃圾回收器回收被其引用的对象,即使该对象仍然有活动的弱引用存在。它通常用于缓存、引用监听器和防止内存泄漏的场景。
3.2 内存泄漏是否和key使用的弱引用有关
有读者可能会猜测ThreadLocal的内存泄漏可能会和Entry中使用了弱引用的key有关系,其实这个猜测不太准确,下面就从两个方面分析下ThreadLocal内存泄漏的原因
3.2.1 假设key使用强引用
假设ThreadLocalMap中的key使用了强引用,,则此时ThreadLocal的内存图如下所示:

如上图所示,假设在业务代码中使用玩ThreadLocal后,ThreadLocal引用被回收了,但是因为ThreadLocalMap的Entry强引用ThreadLocal,会造成ThreadLocal无法被回收,这时在没有手动删除Entry和CurrentThread的情况下,始终会有强引用链:CurrentThread引用===>CurrentThread===> ThreadLocalMap===>Entry.最终导致Entry无法被回收导致内存泄漏,所以ThreadLocalMap中的key使用了强引用是无法完全避免内存泄漏的
3.2.2 假设key使用弱引用
假设key使用了弱引用,ThreadLocal的内存图如下所示

假设业务代码中使用完ThreadLocal后,然后ThreadLocal被回收了,此时由于ThreadLocalMap只持有ThreadLcoal的弱引用,并且没有任何的强引用指向ThreadLocal实例,所以ThreadLocal实例可以顺利的被垃圾回收器回收,此时就会导致Entry的key为null,这时候如果我们没有手动删除这个Entry以及CurrentThread仍然运行的前提下,也存在强引用链:CurrentThread引用===>CurrentThread===> ThreadLocalMap===>Entry===>Value,而这里的Value不会被回收,但是这块Value永远不会被访问到了,因为key已经被回收了,导致Value内存泄漏,所以ThreadLocalMap中的key使用了弱引用,也有可能导致内存泄漏。
3.2.3 内存泄漏的真实原因
通过上面的两种对key使用强引用和弱引用的方式分析,我们发现ThreadLocal的内存泄漏和ThreadLocalMap的key是否使用弱引用是没有关系的,真正引起内存泄漏的原因主要有两点,第一点是当ThreadLocal被回收后,没有手动删除ThreadLocalMap的Entry,这时只要我们使用完后调用ThreadLocal的remove方法删除对应的Entry就可以避免内存泄漏。第二点是当ThreadLocal被回收后,CurrentThread依然在运行。由于ThreadLocalMap是Thread的一个属性,被当前线程引用,所以它的生命周期和Thread一样长,那么在使用完ThradLocal,如果当前的线程也一起随之结束,那么ThreadLocalMap就可以被垃圾回收器回收,从根源上避免了内存泄漏
结合上面的分析可以知道,ThreadLocal内存泄漏的真实原因是,由于ThreadLocalMap的生命周期和Thread一样长,如果没有手动删除对应的Entry就会导致内存泄漏。
3.2.4 ThreadLocalMap的key使用弱引用的原因
有的读者可能会问,既然ThreadLocalMap的key使用强引用和弱引用都无法避免内存泄漏,那么为啥偏偏选择使用弱引用呢?经过前面的分析我们发现ThreadLocalMap的key无论使用强引用还是弱引用都无法完全避免内存泄漏,如果想要避免内存泄漏,主要有两种方式:
- 使用完ThreadLocal后,调用其remove方法删除对应的Entry
- 使用完ThreadLocal后,当前线程也随之结束
第一种方式相对简单,直接调用ThreadLocal提供的remove方法就行,但是第二种方式就不是那么好控制了,因为如果在使用线程池的场景,第二种方式就会出问题,因为线程池中的线程有复用的情况。那么回到问题,为啥ThreadLocalMap的key偏偏要使用弱引用。其实在ThreadLocal中的get/set/getEntry方法中会对key为null的情况进行判断,如果key为null,则value也会被置为null,这时候使用弱引用就会多一层保障,假设在ThreadLocal,CurrentThread依然运行的情况下,如果忘记调用了ThreadLocal的remove方法,ThreadLocalMap的key由于是弱引用,所以可以被回收,这时候key就为null,然后在下一次ThreadLocalMap调用set、get、getEntry中的任何一个方法都会将key为null的Entry清除掉,从而避免了内存泄漏,这就是为什么ThreadLocalMap的key要使用弱引用的原因。
4.ThreadLocal使用场景
ThreadLocal目前使用最常见的就是Android中Handler机制中的Looper,
@UnsupportedAppUsagestatic final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();// 创建Looper时需要调用Looper的prepare方法private static void prepare(boolean quitAllowed) {if (sThreadLocal.get() != null) {throw new RuntimeException("Only one Looper may be created per thread");}sThreadLocal.set(new Looper(quitAllowed));}
我们都知道Android的Handler机制中,每个线程有一个Looper,并且每个线程的Looper是互相不干扰的,要实现这种功能就得借助ThreadLocal,创建Looper的时候先判断当前创建Looper的线程是否已经有了Looper,没有再创建,有的化就直接使用。
另外还有一种情景就是在服务端开发的时候,读取MySQL的数据库连接对象,如果是多个线程去读取的情况下,每个线程都需要维护一个自己的数据库连接,这样使用完后就释放自己的连接,不会影响到其他线程的数据连接。
相关文章:
ThreadLocal的熟悉与使用
目录 1.ThreadLocal介绍2.ThreadLocal源码解析2.1 常用方法2.2 结构设计2.3 类图2.4 源码分析2.4.1 set方法分析2.4.2 get方法分析2.4.3 remove方法分析 3.ThreadLocal内存泄漏分析3.1 相关概念3.1.1 内存溢出3.1.2 内存泄漏3.1.3 强引用3.1.4 弱引用 3.2 内存泄漏是否和key使用…...
如何使用 Puppeteer 和 Browserless 抓取亚马逊产品数据?
您可以在亚马逊上找到所有有关产品、卖家、评论、评分、特价、新闻等的相关且有价值的信息。无论是卖家进行市场调研还是个人收集数据,使用高质量、便捷且快速的工具将极大地帮助您准确地抓取亚马逊上的各种信息。 为什么抓取亚马逊产品数据很重要? 亚…...

使用Python求解经典“三门问题”,揭示概率的奇妙之处
三门问题(Monty Hall Problem)是经典的概率问题,描述了一位游戏选手在三个门中选择一扇门,其中一扇门后有奖品,其余两扇门后是空的。选手做出选择后,主持人会打开另一扇空门,然后给选手一次更改…...
 . DDL)
数据库基础(6) . DDL
3.2.DDL 数据定义语言 DDL : Data Definition Language 用于创建新的数据库、模式(schema)、表(tables)、视图(views)以及索引(indexes)等。 常见的DDL语句包括SHOW、CREATE、DRO…...

2024 年度分布式电力推进(DEP)系统发展探究
分布式电力推进 (DEP) 的发明是为了尝试和改进现代飞机:我们如何提高飞机的效率?提高它的机动性?缩短它的起飞和着陆距离? DEP 概念有望在提高性能的同时减少燃料消耗,在我们孜孜不倦地努力使航…...

vue通过iframe方式嵌套grafana图表
文章目录 前言一、iframe方式实现xxx.xxx.com拒绝连接登录不跳转Cookie 的SameSite问题解决不显示额外区域(kiosk1) 前言 我们的前端是vue实现的,监控图表是在grafana中的,需要在项目web页面直接显示grafana图表 一、iframe方式实现 xxx.xxx.com拒绝连…...

简单介绍下 Java 中的 @Validated 和 @Valid 注解的区别?
文章目录 Valid:专注单个对象的深度验证适用场景使用示例小结 Validated:聚焦接口分组的批量验证适用场景使用示例小结 主要区别总结如何选择?总结推荐阅读文章 在 Java 开发中,为了确保输入数据符合我们的要求,少不了…...

SpringBoot配置Rabbit中的MessageConverter对象
SpringAMQP默认使用SimpleMessageConverter组件对消息内容进行转换 SimpleMessageConverter: only supports String, byte[] and Serializable payloads仅仅支持String、Byte[]和Serializable对象Jackson2JsonMessageConverter:was expecting (JSON Str…...

C++ 错题本--duplicate symbol问题
顾名思义, duplicate symbol是重复符号的意思! 代码是用来做什么的(问题缘由 & 代码结构) 写排序算法, 提出了一个公共的头文件用来写一些工具方法, 比如打印数组内容. 以便于不同文件代码需要打印数组内容的时候,直接引入相关头文件即可, 但是编译时出现了 duplicate sym…...

Cursor的chat与composer的使用体验分享
经过一段时间的试用,下面对 Composer 与 Chat 的使用差别进行总结: 一、长文本及程序文件处理方面 Composer 在处理长文本时表现较为稳定,可以对长文进行更改而不会出现内容丢失的情况。而 Chat 在更改长的程序文件时,有时会删除…...

【优选算法 — 滑动窗口】最大连续1的个数 将 x 减到0的最小操作数
最大连续1的个数 最大连续1的个数 题目描述 题目解析 给我们一个元素全是0或者1的数组,和一个整数 k ,然后让我们在数组选出最多的 k 个0;这里翻转最多 k 个0的意思,是翻转 0 的个数< k,而不是一定要翻转 k …...

《TCP/IP网络编程》学习笔记 | Chapter 8:域名及网络地址
《TCP/IP网络编程》学习笔记 | Chapter 8:域名及网络地址 《TCP/IP网络编程》学习笔记 | Chapter 8:域名及网络地址域名系统什么是域名?DNS 服务器IP 地址和域名之间的转换使用域名的必要性利用域名获取 IP 地址利用 IP 地址获取域名 基于 Wi…...

FastHTML快速入门:调试模式和 URL中的变量
调试模式 FastHTML基于FastAPI友好的装饰器模式来指定URL,并添加了额外功能: main.py from fasthtml.common import * app, rt fast_app() rt("/") def get():return Titled("FastHTML", P("让我们开始吧!"…...

C++高级编程(8)
八、标准IO库 1.输入输出流类 1)非格式化输入输出 2)put #include <iostream> #include <string> using namespace std; int main() {string str "123456789";for (int i str.length() - 1; i > 0; i--) {cout.put(str[i]); //从最后一个字符开…...

AUTOSAR_EXP_ARAComAPI的7章笔记(2)
☞返回总目录 相关总结:服务发现实现策略总结 7.2 服务发现的实现策略 如前面章节所述,ara::com 期望产品供应商实现服务发现的功能。服务发现功能基本上是在 API 级别通过 FindService、OfferService 和 StopOfferService 方法定义的,协议…...
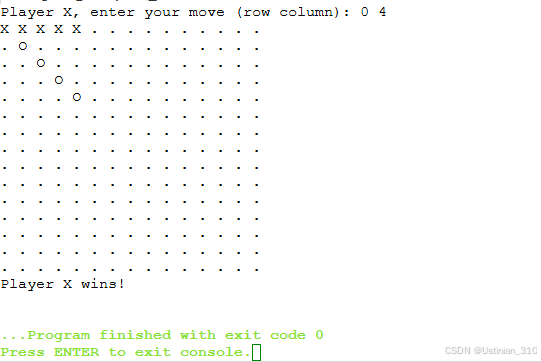
【C++】 C++游戏设计---五子棋小游戏
1. 游戏介绍 一个简单的 C 五子棋小游戏 1.1 游戏规则: 双人轮流输入下入点坐标横竖撇捺先成五子连线者胜同一坐标点不允许重复输入 1.2 初始化与游戏界面 初始化界面 X 输入坐标后 O 输入坐标后 X 先达到胜出条件 2. 源代码 #include <iostream> #i…...

仿RabitMQ 模拟实现消息队列项目开发文档2(个人项目)
项目需求分析 核心概念 现在需要将这个项目梳理清楚了,便于之后的代码实现。项目中具有一个生产消费模型: 其中生产者和消费者的个数是可以灵活改变的,让系统资源更加合理的分配。消息队列的主逻辑和上面的逻辑基本一样,只不过我…...

李佳琦回到巅峰背后,双11成直播电商分水岭
时间倏忽而过,又一年的双11即将宣告结束。 从双11正式开始前的《新所有女生的offer》,到被作为“比价”标杆被其他平台直播间蹭、被与其他渠道品牌比较,再到直播间运营一时手快多发了红包……整个双11周期下来,李佳琦直播间在刷新…...

云计算在教育领域的应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 云计算在教育领域的应用 云计算在教育领域的应用 云计算在教育领域的应用 引言 云计算概述 定义与原理 发展历程 云计算的关键技…...

C语言 | Leetcode C语言题解之第543题二叉树的直径
题目: 题解: typedef struct TreeNode Node;int method (Node* root, int* max) {if (root NULL) return 0;int left method (root->left, max);int right method (root->right, max);*max *max > (left right) ? *max : (left right);…...

程序员连夜带团队跑路,省了23万:这AI太贵,真的用不起了
好的,收到!你说得对,之前的风格可能信息密度太高,有点“极客狂欢”的味道。 今天咱们换个姿势,用唠家常、说人话的方式,把5月11日AI圈最有趣、最魔幻的几件事儿聊明白。保证你在地铁上、蹲坑时,…...

大型机场U型机坪推出等待点运行优化【附案例】
✨ 长期致力于机场、U型机坪区、推出等待点、运行程序优化、启发式算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)单通道U型机坪推出等待点位优化…...
)
给IPC相机调图像,别再瞎调了!一份保姆级的ISP线性模式调试顺序图(附避坑要点)
IPC相机图像调试实战指南:从线性模式到专业级画质优化 刚接触IPC相机图像调试的工程师们,常常会陷入参数迷宫——面对AE、AWB、Gamma、3DNR等数十个模块,该从何处入手?调试顺序的错误可能导致反复返工,甚至影响最终成像…...

如何快速掌握雀魂Mod Plus:解锁全角色皮肤的新手完全指南
如何快速掌握雀魂Mod Plus:解锁全角色皮肤的新手完全指南 【免费下载链接】majsoul_mod_plus 雀魂解锁全角色、皮肤、装扮等,支持全部服务器。 项目地址: https://gitcode.com/gh_mirrors/ma/majsoul_mod_plus 还在为无法获得心仪角色和皮肤而烦恼…...
:核心抽象层 —— 块 、分区 、inode 从原理到实操)
【Linux 指南】文件系统系列(二):核心抽象层 —— 块 、分区 、inode 从原理到实操
上一篇我们吃透了磁盘的底层原理,搞懂了磁盘通过 CHS/LBA 寻址定位扇区,也知道扇区是磁盘硬件的最小读写单位(512 字节)。但随之而来的两个核心问题摆在眼前:一是逐个扇区读写磁盘效率极低,磁头的寻道和旋转…...

硬件工程师实战指南:工业物联网安全、无线充电与TSN网络设计解析
1. 项目概述:一场面向硬件工程师的线上技术盛宴最近在整理行业资料时,翻到了EE Times几年前发布的一个“即将到来的线上技术活动”汇总页面。虽然发布时间是2018年,但里面提到的几个技术主题——工业物联网安全、硬件身份认证、工业以太网演进…...

别再只怪芯片了!拆解一个智能家居产品,看它的EMC静电防护设计到底哪里出了问题
智能家居静电防护失效分析:从产品拆解看EMC设计盲区 最近一位做智能门锁的创业者朋友向我吐槽:他们的旗舰产品在北方冬季频繁出现用户触摸时死机的情况,售后返修率飙升到15%。拆机检测却显示主板芯片完好,问题究竟出在哪里&#…...

eFuse 的核心作用
它触及了设备安全性的核心机制——eFuse。 简而言之:一台已经烧录(blown)了 eFuse 的设备,其安全机制与未烧录 eFuse 的设备有本质区别,你之前在非 eFuse 设备上成功的代码修改(强制 check_key 返回 0)很可能在烧录了 eFuse 的设备上无效。 以下是详细解释: eFuse 的…...
)
用C++‘数1’这道题,带你彻底搞懂整数位分离的循环技巧(附避坑点)
用C‘数1’这道题,带你彻底搞懂整数位分离的循环技巧(附避坑点) 在编程学习的道路上,整数位分离是一个看似简单却暗藏玄机的基础操作。许多初学者在解决"统计数字中1的个数"这类问题时,往往能写出大致正确的…...

解锁智能告警管理:Keep开源AIOps平台从零到生产实战指南
解锁智能告警管理:Keep开源AIOps平台从零到生产实战指南 【免费下载链接】keep The open-source AIOps and alert management platform 项目地址: https://gitcode.com/GitHub_Trending/kee/keep 在当今复杂的云原生环境中,运维团队每天都要面对海…...