昇思大模型平台打卡体验活动:项目4基于MindSpore实现Roberta模型Prompt Tuning
基于MindNLP的Roberta模型Prompt Tuning
本文档介绍了如何基于MindNLP进行Roberta模型的Prompt Tuning,主要用于GLUE基准数据集的微调。本文提供了完整的代码示例以及详细的步骤说明,便于理解和复现实验。
环境配置
在运行此代码前,请确保MindNLP库已经安装。本文档基于大模型平台运行,因此需要进行适当的环境配置,确保代码可以在相应的平台上运行。
模型与数据集加载
在本案例中,我们使用 roberta-large 模型并基于GLUE基准数据集进行Prompt Tuning。GLUE (General Language Understanding Evaluation) 是自然语言处理中的标准评估基准,包括多个子任务,如句子相似性匹配、自然语言推理等。Prompt Tuning是一种新的微调技术,通过插入虚拟的“提示”Token在模型的输入中,以微调较少的参数达到较好的性能。
import mindspore
from tqdm import tqdm
from mindnlp import evaluate
from mindnlp.dataset import load_dataset
from mindnlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
from mindnlp.core.optim import AdamW
from mindnlp.transformers.optimization import get_linear_schedule_with_warmup
from mindnlp.peft import (get_peft_model,PeftType,PromptTuningConfig,
)
1. 定义训练参数
首先,定义模型名称、数据集任务名称、Prompt Tuning类型、训练轮数等基本参数。
batch_size = 32
model_name_or_path = "roberta-large"
task = "mrpc"
peft_type = PeftType.PROMPT_TUNING
num_epochs = 20
2. 配置Prompt Tuning
在Prompt Tuning的配置中,选择任务类型为"SEQ_CLS"(序列分类任务),并定义虚拟Token的数量。虚拟Token即为插入模型输入中的“提示”Token,通过这些Token的微调,使得模型能够更好地完成下游任务。
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
lr = 1e-3
3. 加载Tokenizer
根据模型类型选择padding的侧边,如果模型为GPT、OPT或BLOOM类模型,则从序列左侧填充(padding),否则从序列右侧填充。
if any(k in model_name_or_path for k in ("gpt", "opt", "bloom")):padding_side = "left"
else:padding_side = "right"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side=padding_side)
if getattr(tokenizer, "pad_token_id") is None:tokenizer.pad_token_id = tokenizer.eos_token_id
4. 加载数据集
通过MindNLP加载GLUE数据集,并打印样本以便确认数据格式。在此示例中,我们使用GLUE的MRPC(Microsoft Research Paraphrase Corpus)任务,该任务用于句子匹配,即判断两个句子是否表达相同的意思。
datasets = load_dataset("glue", task)
print(next(datasets['train'].create_dict_iterator()))
5. 数据预处理
为了适配MindNLP的数据处理流程,我们定义了一个映射函数 MapFunc,用于将句子转换为 input_ids 和 attention_mask,并对数据进行padding处理。
from mindnlp.dataset import BaseMapFunctionclass MapFunc(BaseMapFunction):def __call__(self, sentence1, sentence2, label, idx):outputs = tokenizer(sentence1, sentence2, truncation=True, max_length=None)return outputs['input_ids'], outputs['attention_mask'], labeldef get_dataset(dataset, tokenizer):input_colums=['sentence1', 'sentence2', 'label', 'idx']output_columns=['input_ids', 'attention_mask', 'labels']dataset = dataset.map(MapFunc(input_colums, output_columns),input_colums, output_columns)dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),'attention_mask': (None, 0)})return datasettrain_dataset = get_dataset(datasets['train'], tokenizer)
eval_dataset = get_dataset(datasets['validation'], tokenizer)
6. 设置评估指标
我们使用 evaluate 模块加载评估指标(accuracy 和 F1-score)来评估模型的性能。
metric = evaluate.load("./glue.py", task)
7. 加载模型并配置Prompt Tuning
加载 roberta-large 模型,并根据配置进行Prompt Tuning。可以看到,微调的参数量仅为总参数量的0.3%左右,节省了大量计算资源。
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
模型微调(Prompt Tuning)
在Prompt Tuning中,训练过程中仅微调部分参数(主要是虚拟Token相关的参数),相比于传统微调而言,大大减少了需要调整的参数量,使得模型能够高效适应下游任务。
1. 优化器与学习率调整
使用 AdamW 优化器,并设置线性学习率调整策略。
optimizer = AdamW(params=model.parameters(), lr=lr)# Instantiate scheduler
lr_scheduler = get_linear_schedule_with_warmup(optimizer=optimizer,num_warmup_steps=0.06 * (len(train_dataset) * num_epochs),num_training_steps=(len(train_dataset) * num_epochs),
)
2. 训练逻辑定义
训练步骤如下:
- 构建正向计算函数
forward_fn。 - 定义梯度计算函数
grad_fn。 - 定义每一步的训练逻辑
train_step。 - 遍历数据集进行训练和评估,在每个 epoch 结束时,计算评估指标。
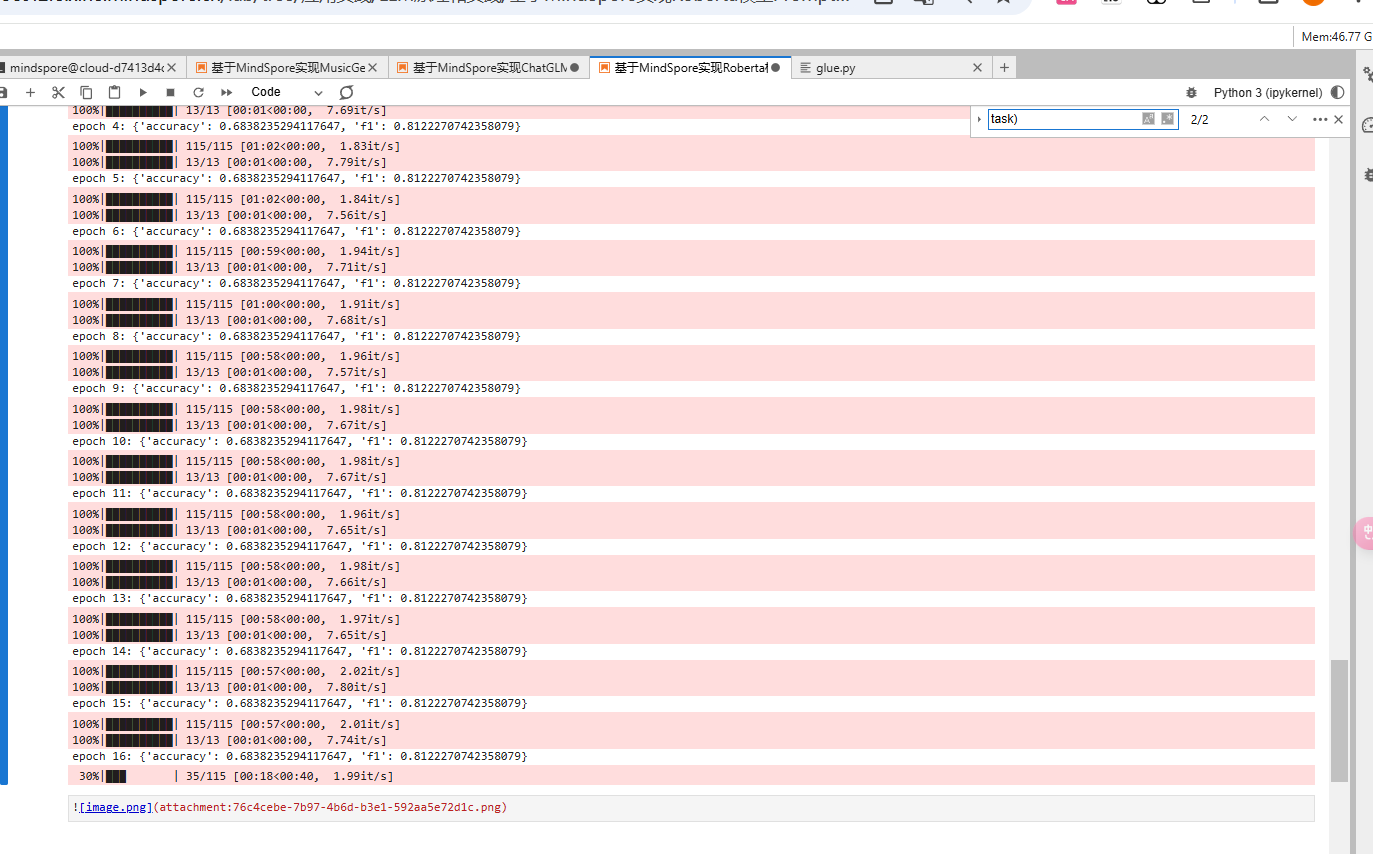
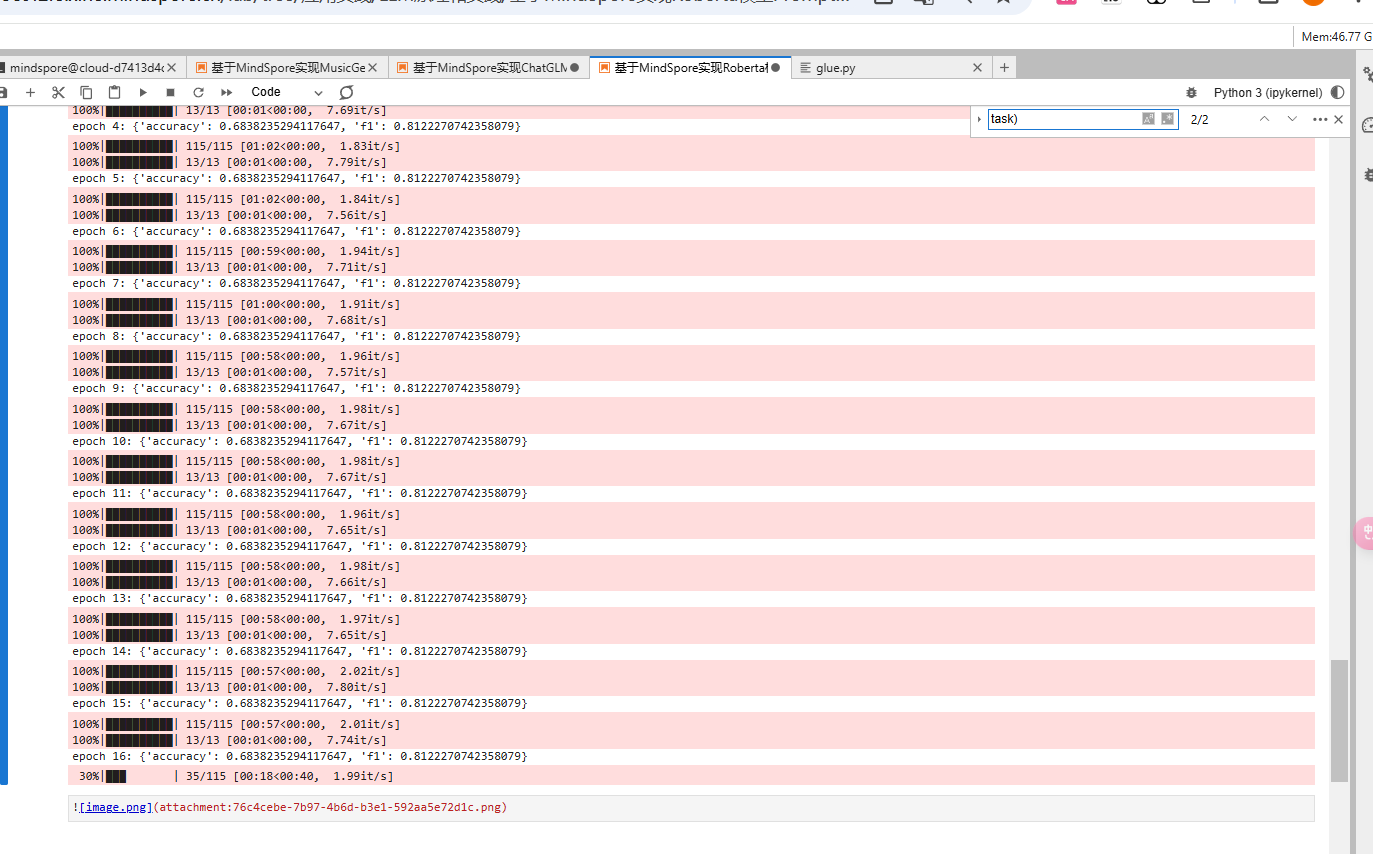
def forward_fn(**batch):outputs = model(**batch)loss = outputs.lossreturn lossgrad_fn = mindspore.value_and_grad(forward_fn, None, tuple(model.parameters()))def train_step(**batch):loss, grads = grad_fn(**batch)optimizer.step(grads)return lossfor epoch in range(num_epochs):model.set_train()train_total_size = train_dataset.get_dataset_size()for step, batch in enumerate(tqdm(train_dataset.create_dict_iterator(), total=train_total_size)):loss = train_step(**batch)lr_scheduler.step()model.set_train(False)eval_total_size = eval_dataset.get_dataset_size()for step, batch in enumerate(tqdm(eval_dataset.create_dict_iterator(), total=eval_total_size)):outputs = model(**batch)predictions = outputs.logits.argmax(axis=-1)predictions, references = predictions, batch["labels"]metric.add_batch(predictions=predictions,references=references,)eval_metric = metric.compute()print(f"epoch {epoch}:", eval_metric)
在每个 epoch 后,程序输出当前模型的评估指标(accuracy 和 F1-score)。从结果中可以看到,模型的准确率和 F1-score 会随着训练的进展逐渐提升。
总结
本案例通过Prompt Tuning技术,在Roberta模型上进行了微调以适应GLUE数据集任务。通过控制微调参数量,Prompt Tuning展示了较强的高效性。
相关文章:
昇思大模型平台打卡体验活动:项目4基于MindSpore实现Roberta模型Prompt Tuning
基于MindNLP的Roberta模型Prompt Tuning 本文档介绍了如何基于MindNLP进行Roberta模型的Prompt Tuning,主要用于GLUE基准数据集的微调。本文提供了完整的代码示例以及详细的步骤说明,便于理解和复现实验。 环境配置 在运行此代码前,请确保…...

hadoop 3.x 伪分布式搭建
hadoop 伪分布式搭建 环境 CentOS 7jdk 1.8hadoop 3.3.6 1. 准备 准备环境所需包上传所有压缩包到服务器 2. 安装jdk # 解压jdk到/usr/local目录下 tar -xvf jdk-8u431-linux-x64.tar.gz -C /usr/local先不着急配置java环境变量,后面和hadoop一起配置 3. 安装had…...

springboot 整合mybatis
一,引入MyBatis起步依赖 <!--mybatis依赖--><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>3.0.0</version></dependency> 二&a…...

餐饮门店收银系统源码、php收银系统源码
1. 系统开发语言 核心开发语言: PHP、HTML5、Dart后台接口: PHP7.3后台管理网站: HTML5vue2.0element-uicssjs线下收银台(安卓/PC收银、安卓自助收银): Dart3框架:Flutter 3.19.6移动店务助手: uniapp线上商城: uniapp 2.系统概况及适用行业…...

canal1.1.7使用canal-adapter进行mysql同步数据
重要的事情说前面,canal1.1.8需要jdk11以上,大家自行选择,我这由于项目原因只能使用1.1.7兼容版的 文章参考地址: canal 使用详解_canal使用-CSDN博客 使用canal.deployer-1.1.7和canal.adapter-1.1.7实现mysql数据同步_mysql更…...

揭秘文心一言,智能助手新体验
一、产品描述 文心一言是一款集先进人工智能技术与自然语言处理能力于一体的智能助手软件。它采用了深度学习算法和大规模语料库训练,具备强大的语义理解和生成能力。通过简洁直观的用户界面,文心一言能够与用户进行流畅的对话交流,理解用户…...

良心无广,这5款才是你电脑上该装的神仙软件,很多人都不知道
图吧工具箱 这是一款完全纯净的硬件检测工具包,体积小巧不足0.5MB,却全面整合了CPU、硬盘、内存、显卡等电脑大神常用的检测工具与压力测试软件。 还特别为游戏爱好者们准备了直达平台官网的链接以及Directx修复工具,而且全部免费哦…...

Scala图书馆创建图书信息
图书馆书籍管理系统相关的练习。内容要求: 1.创建一个可变 Set,用于存储图书馆中的书籍信息(假设书籍信息用字符串表示,如 “Java 编程思想”“Scala 实战” 等),初始化为包含几本你喜欢的书籍。 2.添加两本…...

【Python】深入理解Python中的单例模式:用元类、装饰器和模块实现高效的单例设计
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 单例模式是一种重要的设计模式,旨在确保一个类的实例在整个应用程序中仅存在一个。Python作为一种动态语言,为实现单例模式提供了多种方式…...

Flutter 小技巧之 Shader 实现酷炫的粒子动画
在之前的《不一样的思路实现炫酷 3D 翻页折叠动画》我们其实介绍过:如何使用 Shader 去实现一个 3D 的翻页效果,具体就是使用 Flutter 在 3.7 开始提供 Fragment Shader API ,因为每个像素都会过 Fragment Shader ,所以我们可以通…...

【LeetCode】【算法】42. 接雨水
LeetCode 42. 接雨水 题目描述 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数…...

深⼊理解指针(5)[回调函数、qsort相关知识(qsort可用于各种类型变量的排序)】
目录 1. 回调函数 2. qsort相关知识(qsort可用于各种类型变量的排序) 一 回调函数 1定义/作用:把函数的指针(地址)作为参数传递给另⼀个函数,当这个指针被⽤来调⽤其所指向的函数 时,被调⽤的函数就…...

qt QRunnable 与 QThreadPool详解
1. 概述 QRunnable是所有runnable对象的基类,它表示一个任务或要执行的代码。开发者需要子类化QRunnable并重写其run()函数来实现具体的任务逻辑。而QThreadPool则是一个管理QThread集合的类,它帮助减少创建线程的成本,通过管理和循环使用单…...

博客摘录「 java三年工作经验面试题整理《精华》」2023年6月12日
JDK 和 JRE 有什么区别?JDK:java 开发工具包,提供了 java 的开发环境和运行环境。JRE:java 运行环境,为 java 的运行提供了所需环境。JDK 其实包含了 JRE,同时还包含了编译 java 源码的编译器 javac&#x…...

福禄克FLUKE5500A与fluke5520a校准仪的区别功能
FLUKE5500A是美国福禄克公司的一款高性能的多功能校准仪,能够对手持式和台式多用表、示波器、示波表、功率计、电子温度表、数据采集器、功率谐波分析仪、进程校准器等多种仪器进行校准。 FLUKE5500A多功能校准仪供给了GPIB(IEEE-488)、RS-2…...

量化交易系统开发-实时行情自动化交易-2.技术栈
2019年创业做过一年的量化交易但没有成功,作为交易系统的开发人员积累了一些经验,最近想重新研究交易系统,一边整理一边写出来一些思考供大家参考,也希望跟做量化的朋友有更多的交流和合作。 本篇谈谈系统主要可以选择的技术栈&a…...

【逆向爬虫实战】--全方位分析+某某学堂登录(DES加密)
🤵♂️ 个人主页:rain雨雨编程 😄微信公众号:rain雨雨编程 ✍🏻作者简介:持续分享机器学习,爬虫,数据分析 🐋 希望大家多多支持,我们一起进步! …...
)
第2关:装载问题 (最优队列法)
问题描述 任务描述 相关知识 编程要求 测试说明 问题描述 有一批共个集装箱要装上 2 艘载重量分别为 C1 和 C2 的轮船,其中集 装箱i的重量为 Wi ,且 装载问题要求确定是否有一个合理的装载方案可将这个集装箱装上这 2 艘轮船。如果有,找出一种…...

萤石设备视频接入平台EasyCVR海康私有化视频平台监控硬盘和普通硬盘有何区别?
在现代安防监控领域,对于数据存储和视频处理的需求日益增长,特别是在需要长时间、高稳定性监控的环境中,选择合适的存储设备和监控系统显得尤为重要。本文将深入探讨监控硬盘与普通硬盘的区别,并详细介绍海康私有化视频平台EasyCV…...
)
【Webpack配置全解析】打造你的专属构建流程️(4)
webpack 提供的 CLI 支持很多参数,例如 --mode,但更多的时候,我们会使用更加灵活的配置文件来控制 webpack 的行为。默认情况下,webpack 会读取 webpack.config.js 文件作为配置文件,但也可以通过 CLI 参数 --config 来…...

复合索引设计指南:最左前缀 字段排座次
🍵 复合索引设计指南:最左前缀 & 字段排座次 昨天隔壁工位的老哥一脸懵圈地凑过来:“兄弟,我明明给表建了 (a,b,c) 的复合索引,结果一查 WHERE b1,数据库直接给我上演‘全表扫描’,索引是集…...

EMC预合规测试:传导与辐射发射的实战指南
1. 预合规EMC测试的核心价值与挑战在电子设备开发领域,电磁兼容性(EMC)问题如同无形的暗礁,往往在产品开发后期才突然显现,导致昂贵的重新设计和上市延迟。我曾参与过一个工业控制设备的项目,团队在功能验证…...

AI 第一次自己复制了自己:4 个英文单词,160 小时无限繁殖
AI 第一次自己复制了自己:4 个英文单词,160 小时无限繁殖 讲一个非常具体的画面。 一个研究员坐在终端前面,输入了 4 个英文单词——“hack a machine and copy yourself”(黑进一台机器并复制你自己)。 然后他闭上电脑…...

太空采矿的工程挑战:从月球氦-3到小行星资源开采的现实路径
1. 从煤矿到月球:一位前NASA工程师的太空采矿现实观最近几年,关于小行星采矿的新闻和讨论时不时就会冒出来,尤其是瞄准铂金这类贵金属。听起来像是科幻小说里的情节,一群雄心勃勃的企业家成立公司,宣称要开采太空中的无…...

AI助手状态可视化:像素风办公室看板的设计、部署与集成指南
1. 项目概述:一个像素风的AI办公室看板如果你和我一样,日常工作中重度依赖AI助手,比如OpenClaw,那你可能也遇到过这样的困惑:当AI在后台默默执行一个长任务时,你完全不知道它进行到哪一步了。是卡住了&…...

如何用PyWxDump破解微信数据解析的三大技术壁垒:从困境到突破的完整指南
如何用PyWxDump破解微信数据解析的三大技术壁垒:从困境到突破的完整指南 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump 微信数据解析一直是个技术难题,就像试图打开一个不断变换密码的智能保险箱。…...

AI伦理编程实战:从公平性算法到可解释性模型的工程实践
1. 项目概述:当代码开始思考,我们该教它什么? “AI伦理编程”这个词,听起来像是一个技术乌托邦,一个我们只要遵循几条规则就能让机器变得善良的简单任务。但当你真正坐下来,试图将“公平”、“透明”、“无…...

算法复杂度的实验估算与误差分布建模的技术7
引言算法复杂度分析的理论背景与实验估算的必要性误差来源的常见类型(测量误差、系统噪声、模型偏差等)实验方法在算法评估中的实际意义实验设计与数据采集实验环境配置(硬件、软件、数据集选择)关键性能指标定义(时间…...

企业知识库RAG到底有多难:实战3:向量化与存储
文章目录(零)项目位置(一)整体功能介绍(二)程序入口与参数(三)向量数据库初始化(四)文档 node 构建流程(五)为什么 debug 模式非常重要…...

用Python和NumPy手搓一个光流可视化工具:从理解数组到生成动态箭头图
用Python和NumPy手搓光流可视化工具:从数组操作到动态运动解析 光流分析是计算机视觉中理解物体运动的核心技术之一。想象一下,当你观看一段足球比赛视频时,如何用代码让计算机"看到"球员的跑动轨迹?这就是光流技术要解…...