Scrapy爬取heima论坛所有页面内容并保存到数据库中
前期准备:
Scrapy入门_win10安装scrapy-CSDN博客
新建 Scrapy项目
scrapy startproject mySpider03 # 项目名为mySpider03
进入到spiders目录
cd mySpider03/mySpider03/spiders
创建爬虫
scrapy genspider heima bbs.itheima.com # 爬虫名为heima ,爬取域为bbs.itheima.com
制作爬虫
items.py:
import scrapyclass heimaItem(scrapy.Item):title = scrapy.Field()url = scrapy.Field()heima.py:
import scrapy
from scrapy.selector import Selector
from mySpider03.items import heimaItemclass HeimaSpider(scrapy.Spider):name = 'heima'allowed_domains = ['bbs.itheima.com']start_urls = ['http://bbs.itheima.com/forum-425-1.html']def parse(self, response):print('response.url: ', response.url)selector = Selector(response)node_list = selector.xpath("//th[@class='new forumtit'] | //th[@class='common forumtit']")for node in node_list:# 文章标题title = node.xpath('./a[1]/text()')[0].extract()# 文章链接url = node.xpath('./a[1]/@href')[0].extract()# 创建heimaItem类item = heimaItem()item['title'] = titleitem['url'] = urlyield item
pipelines.py:
from itemadapter import ItemAdapter
from pymongo import MongoClientclass heimaPipeline:def open_spider(self, spider):# MongoDB 连接设置 self.MONGO_URI = 'mongodb://localhost:27017/' self.DB_NAME = 'heima' # 数据库名称 self.COLLECTION_NAME = 'heimaNews' # 集合名称self.client = MongoClient(self.MONGO_URI)self.db = self.client[self.DB_NAME]self.collection = self.db[self.COLLECTION_NAME]# 如果集合中已有数据,清空集合self.collection.delete_many({})print('爬取开始')def process_item(self, item, spider):title = item['title']url = item['url']# 将item转换为字典item_dict = {'title': title,'url': url,}# 插入数据self.collection.insert_one(item_dict)return item def close_spider(self, spider):print('爬取结束,显示数据库中所有元素')cursor = self.collection.find()for document in cursor:print(document)self.client.close()
settings.py,解开ITEM_PIPELINES的注释,并修改其内容:
ITEM_PIPELINES = {
'mySpider03.pipelines.heimaPipeline': 300,
}
创建run.py:
from scrapy import cmdlinecmdline.execute("scrapy crawl heima -s LOG_ENABLED=False".split())# cd mySpider03/mySpider03/spiders运行run.py文件,即可实现爬取第一页'http://bbs.itheima.com/forum-425-1.html'内容并保存到数据库中的功能。
结果如下图:
爬取到了50条数据。


爬取所有页面
方法一:通过获取下一页url地址的方法爬取所有页面。
在heima.py的parse方法结尾加上以下内容:
# 获取下一页的链接
if '下一页' in response.text:
next_url = selector.xpath("//a[@class='nxt']/@href").extract()[0]
yield scrapy.Request(next_url, callback=self.parse)
即heima.py:
import scrapy
from scrapy.selector import Selector
from mySpider03.items import heimaItemclass HeimaSpider(scrapy.Spider):name = 'heima'allowed_domains = ['bbs.itheima.com']start_urls = ['http://bbs.itheima.com/forum-425-1.html']def parse(self, response):print('response.url: ', response.url)selector = Selector(response)node_list = selector.xpath("//th[@class='new forumtit'] | //th[@class='common forumtit']")for node in node_list:# 文章标题title = node.xpath('./a[1]/text()')[0].extract()# 文章链接url = node.xpath('./a[1]/@href')[0].extract()# 创建heimaItem类item = heimaItem()item['title'] = titleitem['url'] = urlyield item# 获取下一页的链接if '下一页' in response.text:next_url = selector.xpath("//a[@class='nxt']/@href").extract()[0]yield scrapy.Request(next_url, callback=self.parse)爬取结果:
爬取到了70页,一共3466条数据。
# 在cmd中输入以下命令,查看数据库中的数据:
> mongosh # 启动mongoDB
> show dbs # 查看所有数据库
> use heima # 使用heima数据库
> db.stats() # 查看当前数据库的信息
> db.heimaNews.find() # 查看heimaNews集合中的所有文档


方法二:使用crawlspider提取url链接
新建crawlspider类的爬虫
scrapy genspider -t crawl heimaCrawl bbs.itheima.com
# 爬虫名为heimaCrawl ,爬取域为bbs.itheima.com
2.1在rules中通过xpath提取链接
修改heimaCrawl.py文件:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from mySpider03.items import heimaItemclass HeimacrawlSpider(CrawlSpider):name = 'heimaCrawl'allowed_domains = ['bbs.itheima.com']start_urls = ['http://bbs.itheima.com/forum-425-1.html']rules = (Rule(LinkExtractor(restrict_xpaths=r'//a[@class="nxt"]'), callback='parse_item', follow=True),)# 处理起始页面内容,如果不重写该方法,则只爬取满足rules规则的链接,不会爬取起始页面内容def parse_start_url(self, response):# 调用 parse_item 处理起始页面return self.parse_item(response)def parse_item(self, response):print('CrawlSpider的response.url: ', response.url)node_list = response.xpath("//th[@class='new forumtit'] | //th[@class='common forumtit']")for node in node_list:# 文章标题title = node.xpath('./a[1]/text()')[0].extract()# 文章链接url = node.xpath('./a[1]/@href')[0].extract()# 创建heimaItem类item = heimaItem()item['title'] = titleitem['url'] = urlyield item修改run.py:
# heimaCrawl
cmdline.execute("scrapy crawl heimaCrawl -s LOG_ENABLED=False".split())
爬取结果:
爬取到全部70页,一共3466条数据。

2.2在rules中通过正则表达式提取链接
修改heimaCrawl.py文件:
rules = (
Rule(LinkExtractor(allow=r'forum-425-\d+\.html'), callback='parse_item', follow=True),
)
结果:
一共爬取到3516条数据。

相关文章:
Scrapy爬取heima论坛所有页面内容并保存到数据库中
前期准备: Scrapy入门_win10安装scrapy-CSDN博客 新建 Scrapy项目 scrapy startproject mySpider03 # 项目名为mySpider03 进入到spiders目录 cd mySpider03/mySpider03/spiders 创建爬虫 scrapy genspider heima bbs.itheima.com # 爬虫名为heima &#…...

Kafka参数了解
Kafka配置参数完整说明 1. 基础配置 参数名说明推荐值参考值broker.idbroker的唯一标识符每个节点唯一的整数1delete.topic.enable是否允许删除topictruetruelistenersbroker监听地址SASL_PLAINTEXT://host:9092SASL_PLAINTEXT://172.24.77.15:9092advertised.listeners对外发…...

sql专题 之 where和join on
文章目录 前言where介绍使用过滤结果集关联两个表 连接外连接内连接自然连接 使用inner join和直接使用where关联两个表的区别总结 前言 从数据库查询数据时,一张表不足以查询到我们想要的数据,更多的时候我们需要联表查询。 联表查询我们一般会使用连接…...

day12:版本控制器
版本控制 使用到的命令: ls -al查看当前目录下的文件及文件夹mkdir新建目录rm -rf递归强制删除文件夹 一、安装配置 1、下载地址 Git 2、初始配置 #用户名 git config --global user.name "自定义用户名" #邮箱(公司的联系方式--追责&…...

第四十一章 Vue之初识VueX
目录 一、引言 1.1. vuex的概念 1.2. vuex使用场景 1.3. 优势 二、创建演示项目 2.1. 构建项目步骤 2.2. 项目最终生成结构 2.3. 创建项目文件 2.3.1. App.vue 2.3.2. Son1.vue 2.3.3. Son2.vue 三、创建一个空仓库 3.1. 安装vuex 3.2. 新建仓库 3.3. 挂载仓库…...
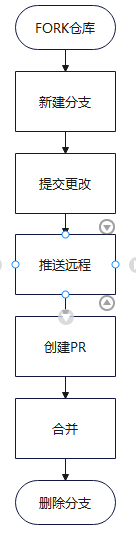
GIT的基本使用与进阶
GIT的简单入门 一.什么是git? Git 是一个开源的分布式版本控制系统,用于跟踪文件更改、管理代码版本以及协作开发。它主要由 Linus Torvalds 于 2005 年创建,最初是为 Linux 内核开发而设计的。如今,Git 已经成为现代软件开发中…...

【Linux系统】—— 基本指令(二)
【Linux系统】—— 基本指令(二) 1 「alias」命令1.1 「ll」命令1.2 「alias」命令 2 「rmdir」指令与「rm」指令2.1 「rmdir」2.2 「rm」2.2.1 「rm」 删除普通文件2.2.2 「rm」 删除目录2.2.3 『 * 』 通配符 3 「man」 指令4 「cp」 指令4.1 拷贝普通…...

MFC工控项目实例三十实现一个简单的流程
启动按钮夹紧 密闭,时间0到平衡 进气,时间1到进气关,时间2到平衡关 检测,时间3到平衡 排气,时间4到夹紧开、密闭开、排气关。 相关代码 void CSEAL_PRESSUREDlg::OnTimer_2(UINT nIDEvent_2) {// if (nIDEvent_21 &am…...

【Android、IOS、Flutter、鸿蒙、ReactNative 】文本点击事件
Android Studio 版本 Android Java TextView 实现 点击事件 参考 import androidx.appcompat.app.AppCompatActivity; import android.os.Bundle; import android.util.Log; import android.view.View; import android.widget.TextView; import android.widget.Toast;public c…...

json转excel,读取json文件写入到excel中【rust语言】
一、rust代码 将json文件写入到 excel中。(保持json :key原始顺序) use indexmap::IndexMap; use serde::Deserialize; use serde_json::{Value, from_str}; use std::error::Error; use std::io::{self, Write}; use std::path::{Path}; u…...

Java面试要点06 - static关键字、静态属性与静态方法
本文目录 一、引言二、静态属性(Static Fields)三、静态方法(Static Methods)四、静态代码块(Static Blocks)五、静态内部类(Static Nested Classes)六、静态导入(Static…...

动态规划-背包问题——416.分割等和子集
1.题目解析 题目来源 416.分割等和子集——力扣 测试用例 2.算法原理 1.状态表示 这里背包问题基本上和母题的思路大相径庭,母题请见 [模板]01.背包 ,这里的状态表示与装满背包的情况类似,第二个下标就是当选择的物品体积直接等于j时是否可…...

Pr:视频过渡快速参考(合集 · 2025版)
Adobe Premiere Pro 自带七组约四十多个视频过渡 Video Transitions效果,包含不同风格和用途,可在两个剪辑之间创造平滑、自然的转场,用来丰富时间、地点或情绪的变化。恰当地应用过渡可让观众更好地理解故事或人物。 提示: 点击下…...

网络安全---安全见闻2
网络安全—安全见闻 拓宽视野不仅能够丰富我们的知识体系,也是自我提升和深造学习的重要途径!!! 设备漏洞问题 操作系统漏洞 渗透测试视角:硬件设备上的操作系统可能存在各种漏洞,攻击者可以利用这些漏洞…...

解决因为TortoiseSVN未安装cmmand line client tools组件,导致idea无法使用svn更新、提交代码
一.错误信息 1.更新代码时:SVN: 更新错误 找不到要更新的版本管理目录。 2.提交代码:检测不到任何更新(实际上有代码修改)。 3.Cannot run program "svn"。 二.原因分析 在电脑上新安装的的客户端TortoiseSVN、ide…...

Ubuntu 20.04安装CUDA 11.0、cuDNN 8.0.5
不知道咋弄的ubuntu20.04电脑的cuda驱动丢了,无奈需装PyTorch环境,只有CUDA11.0以上版本才支持Ubuntu20.04,所以安装了CUDA11.0、cuDNN8.0.5 为防止频繁在浏览器检索对应的贴子,今天记录一下。 一. 驱动安装 为防止驱动安装后没…...

鸿蒙 APP 发布上架
证书创建与打包: https://developer.huawei.com/consumer/cn/doc/app/agc-help-releaseharmony-0000001933963166 不同环境多渠道打包: //todo 备案相关 一、除了发布应用商店以外,还有3个渠道,都适合小规模内测。 【1】开放式测试:发给指定白名单用户 【2】发布企业内…...

【C++笔记】C++三大特性之继承
【C笔记】C三大特性之继承 🔥个人主页:大白的编程日记 🔥专栏:C笔记 文章目录 【C笔记】C三大特性之继承前言一.继承的概念及定义1.1 继承的概念1.2继承的定义1.3继承基类成员访问方式的变化1.4继承类模板 二.基类和派生类间的转…...

如何在CentOS 7上搭建SMB服务
如何在CentOS 7上搭建SMB服务 因项目测试需求,需要自行搭建SMB服务,**SMB(Server Message Block)**协议是一种常用的文件共享方式,它可以让不同操作系统之间共享文件、打印机等资源。本文将带你一步步搭建一个简单的S…...

linux详解,基本网络枚举
基本网络枚举 一、基本网络工具 ifconfig ifconfig是一个用于配置和显示网络接口信息的命令行工具。它可以显示网络接口的P地址、子网掩码、MC地址等信息,还可以用于启动、停止或配置网络接口。 ip ip也是用于查看和管理网络接口的命令。 它提供了比ifconfig更…...

通过Taotoken CLI工具一键配置团队所有成员的开发环境
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置团队所有成员的开发环境 当团队开始使用多个大模型进行开发时,为每位成员逐一配置API密钥…...
)
从“能用”到“好用”:手把手教你用Grafana打造高颜值监控Dashboard(调试实战)
从“能用”到“好用”:手把手教你用Grafana打造高颜值监控Dashboard(调试实战) 在数据驱动的时代,监控Dashboard不仅是技术工具,更是团队沟通的语言。一个优秀的Grafana面板应当像精心设计的用户界面——数据清晰呈现&…...

【C#】 HTTP 请求通讯实现指南
在现代软件开发中,HTTP 协议是应用程序与外部服务交互的核心桥梁。C# 作为 .NET 生态的主力语言,提供了丰富而成熟的 HTTP 通讯能力。本文将系统介绍 C# 中实现 HTTP 请求的技术选型、核心概念、常见场景及最佳实践,帮助开发者构建稳定、高效…...
打破语言壁垒:Translumo屏幕实时翻译工具的终极使用指南
打破语言壁垒:Translumo屏幕实时翻译工具的终极使用指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否…...

DPlayer:5个理由让你选择这款HTML5弹幕视频播放器
DPlayer:5个理由让你选择这款HTML5弹幕视频播放器 【免费下载链接】DPlayer :lollipop: Wow, such a lovely HTML5 danmaku video player 项目地址: https://gitcode.com/gh_mirrors/dp/DPlayer 还在为网页视频播放体验发愁吗?DPlayer用它的优雅设…...

临近毕业答辩,有哪些真正好用的答辩PPT 生成软件能救急?
毕业答辩进入倒计时,论文刚定稿,却要熬夜做 PPT、理逻辑、排版式,一不小心就熬到凌晨,还容易出现内容跑偏、格式混乱、重点不突出等问题。其实,选对 AI PPT 生成工具,能帮你10 分钟搞定答辩 PPT,…...

3个技巧让NoFences重塑你的Windows桌面工作流
3个技巧让NoFences重塑你的Windows桌面工作流 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 每天打开电脑,面对满屏杂乱的图标和文件,是不是感觉工作…...
)
用NE5532和LM1875T手搓一个9V供电的双工对讲机(附完整电路图与Multisim仿真文件)
用NE5532和LM1875T打造9V供电的双工对讲机:从电路设计到实物调试全指南 周末整理零件箱时翻出几片NE5532和LM1875T,突然想起学生时代用这些经典芯片做的第一个对讲机项目。那种通过自己设计的电路实现实时对话的成就感,至今记忆犹新。本文将…...

全平台日常使用的国外应用
人机协作,AI模型:Deepseek 仅供参考。 应用名应用介绍应用入口LocalSend局域网内跨平台文件传输工具,无服务器、无广告、端到端加密。https://localsend.org/download(页面中央有“iOS”和“Android”下载按钮)LANDr…...

3分钟快速上手:ComfyUI-Manager终极节点管理指南
3分钟快速上手:ComfyUI-Manager终极节点管理指南 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various custom nod…...