Debezium日常分享系列之:异步 Debezium 嵌入式引擎
Debezium日常分享系列之:异步 Debezium 嵌入式引擎
- 动机
- 目标
- 非目标
- 保留Kafka Connect模型
- 计划的更改
- 线程池
- 并行运行源任务
- 存储偏移量
- 并发处理CDC事件
- 禁用CDC事件的完全排序
- 自定义记录处理器
- 并行处理记录的选项
- 存储偏移量
- 引擎状态和生命周期
- 防止资源泄漏
- 异常处理
- 退出任务轮询循环
- 引擎关闭
- 辅助接口和对象
- 其他未来可靠的更改
- 测试
动机
- Debezium有两种基本类型。一种类型是Kafka Connect的源连接器。另一种是独立的引擎,可以嵌入到用户应用程序中,或者包装在Debezium server,中,这是一个独立的应用程序。在第一种情况下,连接器的生命周期和连接器任务的执行由Kafka Connect管理,而在后一种情况下,任务的生命周期完全由Debezium引擎本身管理,并且Debezium项目完全控制引擎内部任务的执行方式。DebeziumEngine接口的当前实现EmebeddedEngine以串行方式执行所有步骤。这包括执行事件转换和事件序列化。事件序列化不是由EmebddedEngine直接提供的,而是由其扩展ConvertingEngine提供的,它作为event processing的一部分实现。
- 此外,当前的EmebddedEngine实现不支持执行多个源任务,即使源连接器支持,比如SQL Server连接器。只执行第一个任务,无论连接器配置提供了多少个任务。
- 在大数据集和多核服务器时代,使用单个线程处理来自数据库的所有CDC事件是一个明显的限制因素。提供一个新的DebeziumEngine接口的实现,可以并行运行一些任务,可以显著提高性能。新的实现和相关的更改还应该针对良好的测试覆盖率和测试新实现以及任何其他未来实现的易用性。
目标
- 提供一个新的实现,允许在给定的连接器中运行多个任务,如果连接器提供多个任务。
- 在专用线程中运行可能耗时的代码(例如事件转换或序列化)。
- 可选择禁用消息的完全排序,以进一步提速。
- 准备好未来的更改和新功能,包括切换到Kafka Streams、通过REST调用将源任务委托给外部工作节点(特别是为了能够在Kubernetes集群中的多个Pod上水平扩展连接器负载)、与Debezium k8s操作员和UI更好地集成,以及将Debezium引擎作为Quarkus扩展提供。
- 另一个高级目标是调整当前的Debezium测试套件,以使用DebeziumEngine接口而不是硬编码的EmebddedEngine实现。这样可以轻松切换到任何其他DebeziumEngine的实现,从而使新的实现能够轻松地与当前的测试套件进行测试。
非目标
- 改变DebeziumEngine接口。
- 对Debezium引擎进行任何其他更改。
- 在连接器内部实现任何并行化(例如在多个线程中跟踪数据库CDC更改)。
- 移除对Kafka Connect API的依赖。
- 添加对在一个Debezium引擎中运行多个连接器的支持(参见)。
- 添加对运行接收器连接器的支持。
保留Kafka Connect模型
由于Debezium引擎的主要目标是能够在Kafka之外执行Debezium,可能会觉得为什么不利用这个机会摆脱Kafka的依赖。原因很简单:这将是一个过于复杂的更改,不仅影响到Debezium引擎。例如,删除WorkerConfig将需要删除OffsetBackingStore,这将需要删除OffsetStorageReader等等,这将导致Debezium核心和连接器的重大变化。因此,这应该作为一个单独的任务来完成,需要一个专门的DDD来描述所有的更改,并提出Kafka Connect接口和类的替代方案。
计划的更改
线程池
- 并发处理的实现将基于Java Executors框架。由于Debezium目前基于Java 11,该项目引入的新并发特性,即虚拟线程和结构化并发,目前无法使用。然而,预计将来将切换到虚拟线程,一旦Debezium基于Java 21或更高版本。ThreadPoolExecutor将用于创建和管理线程池。ThreadPoolExecutor将由工厂方法Executors.newFixedThreadPool(int nThreads)创建。将有两个线程池,一个用于并行运行任务,另一个用于处理CDC事件流水线。在本文档的上下文中,CDC事件流水线指的是记录转换的链,最终还包括记录序列化和由用户提供的消费者进行处理。任务线程池中的工作线程数量将与任务数量相同。CDC事件流水线的工作线程数量将通过配置由用户指定,或者使用默认值。默认值将为底层机器的核心数,因为运行任务不是CPU密集型的操作。
并行运行源任务
- Kafka Connect SourceTask的生命周期将被分成一个独立的任务。这些任务将在由Executors.newSingleThreadExecutor()创建的专用线程中执行。如果出现RetriableException,任务将被重新启动。在其他情况下,所有其他任务将被优雅地停止,并且引擎将因任务异常而失败。
存储偏移量
- 并行运行任务对于存储偏移量似乎不是一个问题。任务与连接器/数据库的分区之间存在1:1的映射关系(例如,在SQL Server的情况下,每个数据库都是一个单独的分区,并且为每个数据库创建一个任务),因此每个任务应该在偏移哈希映射中读取或写入自己的键。因此,从多个任务读取偏移量不应引入任何并发问题,并且对于写入,OffsetStorageWriter被明确标记为线程安全。
并发处理CDC事件
- 当前的DebeziumEngine API部分将事件处理委托给用户提供的ChangeConsumer实现。更具体地说,事件以批处理的方式作为列表传递给ChangeConsumer.handleBatch(),这在许多情况下都是更有效的方式,因为事件通常提交给另一个系统时,批处理更高效。但是,这导致我们无法构建完整的事件处理流水线,这个流水线将在专用线程中运行。
- 在将事件批量传递给ChangeConsumer之前,会对记录应用用户定义的单条消息转换。在ConvertingEngineBuilder的情况下,事件还将被序列化为SourceRecords,然后传递给ChangeConsumer。这两个任务将在上述的ThreadPoolExecutor中并行运行。在将批处理传递给ChangeConsumer之前,将等待批处理中所有记录的任务完成。
- 实现还应尝试优化ConvertingEngineBuilder的记录序列化/反序列化。当前,记录在传递给ChangeConsumer之前被序列化为SourceRecords,然后在ChangeConsumer调用RecordCommitter时再次反序列化。在将记录处理委托给用户提供的ChangeConsumer的情况下,似乎没有简单的方法可以避免这个序列化/反序列化过程,而不破坏现有的API。下面概述了一个可能的解决方案,尽管有点复杂。
- 另一方面,如果记录的处理由用户提供的Consumer完成,我们可以通过存储原始记录来轻松避免反序列化步骤。记录将被传递给转换链,序列化,传递给提供的消费者,如果成功,则将原始(存储的)记录传递给RecordCommitter,无需再次反序列化。
禁用CDC事件的完全排序
- 从性能上来说,可以通过跳过消息排序并按照它们准备好的顺序传递消息来进一步提高速度。这在消息顺序不重要的场景下是有意义的(例如,在底层数据库仅接收插入操作的场景),或者是在接收端应用程序通过消费CDC事件进行排序的情况下。
- 虽然并不经常使用,但DebeziumEngine还提供了其他处理更改记录的方法。用户可以提供一个仅处理记录的Consumer函数,而不是实现ChangeConsumer。在这种情况下,我们可以为处理CDC记录创建一个完整的流水线,而且我们不需要以批处理的方式将记录传递给用户的实现。这允许我们单独处理每条消息,如果处理一条记录需要更长时间(例如,由于记录的大小),其他记录不需要被阻塞。这将导致消息的总顺序被打破。然而,如上所述,在某些特定的场景中,这可能是有意义且可取的。
- 新的实现应该提供一个选项来禁用记录的完全排序。这只允许在用户不通过ChangeConsumer提供记录处理的情况下使用。当用户不通过ChangeConsumer提供记录处理,并且启用了记录的总排序(这将是默认情况),用于处理CDC记录的流水线将在单独的线程中运行,但实现必须确保记录的总排序将被保留。
自定义记录处理器
- 当用户希望对记录进行更复杂的处理时,仅提供简单的事件消费者是不够的,用户必须实现ChangeConsumer。然而,正如前面提到的,这种方法的一个缺点是每个记录在处理后必须反序列化回来才能提交。一个可能的解决方案是完全将记录处理的控制权交给用户,包括应用转换链和序列化记录。当然,这意味着向用户实现公开一些DebeziumEngine内部对象-即转换链、序列化器和用于可能的并行处理的执行器服务。ChangeConsumer的这种泛化可以如下所示:
/*** Generalization of {@link DebeziumEngine.ChangeConsumer}, giving complete control over the records processing.* Processor is initialized with all the required engine internals, like chain of transformations, to be able to implement whole record processing chain.* Implementations can provide e.g. serial or parallel processing of the change records.*/@Incubatingpublic interface RecordProcessor<R> {/*** Initialize the processor with object created and managed by {@link DebeziumEngine}, which are needed for records processing.** @param recordService {@link ExecutorService} which allows to run processing of individual records in parallel* @param transformations chain of transformations to be applied on every individual record* @param serializer converter converting {@link SourceRecord} into desired format* @param committer implementation of {@link DebeziumEngine.RecordCommitter} responsible for committing individual records as well as batches*/void initialize(final ExecutorService recordService, final Transformations transformations, final Function<SourceRecord, R> serializer,final RecordCommitter committer);/*** Processes a batch of records provided by the source connector.* Implementations are assumed to use {@link DebeziumEngine.RecordCommitter} to appropriately commit individual records and the batch itself.** @param records List of {@link SourceRecord} provided by the source connector to be processed.* @throws InterruptedException*/void processRecords(final List<SourceRecord> records) throws InterruptedException;}
在当前的实现中,该接口仅在内部使用,但如果社区将来需要完全控制记录处理,则可以稍后通过 SPI 公开实现。
并行处理记录的选项
总结起来,以下是提供给用户的并行处理选项:
- 对于每条记录并行运行转换链,等待整个批处理转换完成,然后将批处理传递给用户提供的ChangeConsumer。如果用户将ChangeConsumer提供给Builder,并且引擎没有提供转换器,则选择此选项。
- 并行运行转换链,并对每条记录进行序列化,等待整个批处理转换完成,然后将批处理传递给用户提供的ChangeConsumer。如果用户将ChangeConsumer提供给Builder,并且引擎提供了转换器,则选择此选项。
- 并行运行记录的转换链。等待结果并按照原始批处理中的顺序一个接一个地将转换后的批处理应用于用户提供的Consumer。如果用户将Consumer提供给Builder,并且引擎没有提供转换器,则选择此选项。
- 并行运行记录的转换链和序列化。等待结果并按照原始批处理中的顺序一个接一个地将转换后的批处理应用于用户提供的Consumer。如果用户将Consumer提供给Builder,并且引擎提供了转换器,则选择此选项。
- 并行运行记录的转换链,并由用户提供的Consumer进行消费。如果用户将Consumer提供给Builder,引擎没有提供转换器,并且将选项CONSUME_RECORDS_ASYNC设置为true,则选择此选项。
- 并行运行记录的转换链、序列化和由用户提供的Consumer进行消费。如果用户将Consumer提供给Builder,引擎提供了转换器,并且将选项CONSUME_RECORDS_ASYNC设置为true,则选择此选项。
存储偏移量
- 与任务的并行执行不同,在记录的并行处理中,提交正确的偏移量非常重要,以避免错过任何事件。假设我们有一个事件链,由源连接器以记录R1->R2->R3的形式实现,我们并行处理它们。如果调度程序先选择处理R2和R3的线程,并且处理R1的线程需要等待,那么可能会发生例如R3的处理作为第一个完成,R3的偏移量被提交的情况。如果此时关闭引擎,则下次启动引擎将从R3开始,并且R1(以及可能的R2)将被引擎忽略。这将破坏Debezium提供的至少一次保证。因此,我们需要始终只提交其所有前置记录已经处理并已提交的记录的偏移量。
- 可能的记录处理流程在上一段中列出。前两个选项很简单-事件的处理委托给了用户提供的ChangeConsumer,因此记录的提交也由它处理,正确的提交顺序不是引擎的责任。当用户提供的Consumer按顺序运行时,下两个选项也很简单- Consumer按顺序在转换后的批处理上运行,并且记录在按顺序由Consumer消耗时逐个提交。
- 剩下的两个选项并行运行整个链。在这些情况下,记录提交不能成为链的一部分,否则我们可能会像上面描述的那样丢失记录。引擎必须等待第一个事件的处理管道被执行,然后提交记录。然后,它必须等待第二个记录被处理等等,直到整个事件批处理被处理。这将确保至少一次交付。另一方面,这可能会增加引擎重新启动后重复记录的数量,但是如果需要异步记录处理,则用户必须接受这个缺点。
引擎状态和生命周期
引擎的状态将由AtomicReference<State> state变量描述。状态枚举将包含以下元素:
- CREATING-正在启动引擎,这主要意味着引擎对象正在创建或已经创建,但尚未调用run()方法。
- INITIALIZING-在run()方法的开头切换到此状态,初始化连接器时处于此状态,并在启动连接器本身和调用DebeziumEngine.ConnectorCallback.connectorStarted()回调时处于此状态。
- CREATING_TASKS-成功启动连接器后切换到此状态,正在创建和初始化任务的配置。
- STARTING_TASKS-任务正在启动,每个任务在单独的线程中执行;保持在此阶段,直到任务启动、任务启动失败或
TASK_MANAGEMENT_TIMEOUT_MS选项指定的时间已过。 - POLLING_TASKS-任务轮询已经开始;这是生成数据的主要阶段,引擎会在此阶段保持,直到开始关闭或抛出异常。
- STOPPING-引擎正在停止,因为调用了引擎的close()方法或抛出了异常;在此阶段存储偏移量,停止处理记录的ExecutorService、任务和连接器。
- STOPPED-引擎已经停止;最终状态,不能从此状态进一步移动,任何在此状态下对引擎对象的调用都应该失败。
可能的状态转换:
- CREATING -> INITIALIZING
- INITIALIZING -> CREATING_TASKS
- CREATING_TASKS -> STARTING_TASKS
- STARTING_TASKS -> POLLING_TASKS
- (CREATING | INITIALIZING | CREATING_TASKS | STARTING_TASKS | POLLING_TASKS) -> STOPPING
- STOPPING -> STOPPED
防止资源泄漏
- 需要特别注意的引擎阶段是任务启动阶段。在此阶段,正在创建数据库连接,如果发生意外情况或在启动任务时关闭引擎,可能会导致各种资源泄漏,例如未关闭的复制槽。为了防止这种情况发生,不可以通过调用引擎的close()方法将其从STARTING_TASKS状态转换为STOPPING状态。此外,STARTING_TASKS必须完全完成。即使其中一个线程无法启动其运行的任务,主线程(引擎线程)也必须等待所有其他任务完成(无论成功与否)后,才能进入STOPPING状态。通常情况下,STARTING_TASKS -> STOPPING的转换是可能的,但只能在从启动任务的方法中抛出异常的情况下,并且只能在所有启动任务的线程都完成之前发生。
异常处理
- 可重试的异常会在其发生的位置进行处理,相关操作将重试直到 ERRORS_MAX_RETRIES 尝试用尽。与现有的 EmebeddedEngine 实现相反,在此时任务不会重新启动(TODO:重新思考,为什么当前实现中任务会重新启动?)。之后,异常会向上传播到堆栈。任何未被捕获以进行重试的异常都会进一步传播。所有异常都应该在引擎 run() 方法的 catch 块中处理。一旦遇到任何异常,引擎应该进入 STOPPING 状态并开始关闭引擎。
退出任务轮询循环
任务在以下情况下退出轮询循环:
- 将引擎状态更改为除了 POLLING_TASKS 之外的任何其他状态(唯一可能性是更改为 STOPPING 状态)
- 从任务的 poll() 方法中抛出异常或在处理记录的批处理过程中抛出异常
- 通过关闭正在处理记录的 ExecutorService 间接关闭引擎时,如果提交另一条记录进行处理,将会抛出异常(然而,这不应该发生,因为线程应该事先注意到引擎状态已经改变 - 在处理下一批之前)
一旦当前批次被处理,退出任务轮询循环应该在合理的快速时间内发生。当调用引擎的关闭方法时,正在运行记录处理的 ExecutorService 会被优雅地关闭。这意味着当前正在处理的记录将等待处理完成,但不会接受任何其他新的记录进行处理,即使它们已经被调度。主线程最多等待 POLLING_SHUTDOWN_TIMEOUT_MS 毫秒来等待 ExecutorService 关闭(即处理提交的记录),然后 ExecutorService 将被立即关闭。因此,可以通过将 POLLING_SHUTDOWN_TIMEOUT_MS 设置为零来实现立即关闭而不等待记录被处理。为立即关闭添加专用方法需要添加一个新的公共方法,该方法不是 DebeziumEngine API 的一部分,目前似乎没有这样的需求,因为可以将 POLLING_SHUTDOWN_TIMEOUT_MS 设置为合理的较小值。如果有用户需求,可以在将来添加该方法。
引擎关闭
- 在引擎关闭期间,如果引擎至少达到 STARTING_TASKS 状态,所有任务都应停止。在调用任务关闭之前,会调用并等待用于处理 CDC 记录的 ExecutorService 的关闭。每个任务在调用其关闭之前还应提交一个偏移量,并且引擎会等待任务停止。用户可以设置 TASK_MANAGEMENT_TIMEOUT_MS 选项(也用于任务启动)来调整等待任务关闭的时间。一旦所有任务关闭完成,连接器将停止。无论先前的引擎状态如何,连接器都应该停止。引擎达到 STOPPED 状态,不应再有其他操作。如果用户想要重新启动引擎,必须重新创建引擎对象。
辅助接口和对象
- 为了减少需要传递给各种引擎方法和对象的参数数量,创建几个辅助对象是方便的,即连接器和任务上下文。上下文应持有对长期存在的对象的引用,通常是在创建引擎、连接器或任务时创建的,例如OffsetStorageReader或OffsetStorageWriter。辅助的DebeziumSourceConnector和DebeziumSourceTask将持有这些上下文。由于我们长期希望将Debezium引擎与Kafka Connect API解耦,这可能是朝着这个方向迈出的第一步,这些对象可以作为Kafka Connect对象的替代品。正如在开始时提到的,我们不能直接用我们的实现替换这些对象。因此,这些对象还将分别包含对Kafka Connect连接器和任务对象的引用,并在需要时提供Connect对象。
- 这些接口是高度实验性的,可能会在未来进行更改或完全删除。主要目的是探索逐步从Kafka Connect对象中移除的方向是否可行。
- 建议的辅助接口如下:
@Incubating
public interface DebeziumSourceConnector {/*** Returns the {@link DebeziumSourceConnectorContext} for this DebeziumSourceConnector.* @return the DebeziumSourceConnectorContext for this connector*/DebeziumSourceConnectorContext context();/*** Initialize the connector with its {@link DebeziumSourceConnectorContext} context.* @param context {@link DebeziumSourceConnectorContext} containing references to auxiliary objects.*/void initialize(DebeziumSourceConnectorContext context);
}
@Incubating
public interface DebeziumSourceConnectorContext {/*** Returns the {@link OffsetStorageReader} for this DebeziumConnectorContext.* @return the OffsetStorageReader for this connector.*/OffsetStorageReader offsetStorageReader();/*** Returns the {@link OffsetStorageWriter} for this DebeziumConnectorContext.* @return the OffsetStorageWriter for this connector.*/OffsetStorageWriter offsetStorageWriter();
}
@Incubating
public interface DebeziumSourceTask {/*** Returns the {@link DebeziumSourceTaskContext} for this DebeziumSourceTask.* @return the DebeziumSourceTaskContext for this task*/DebeziumSourceTaskContext context();
}
@Incubating
public interface DebeziumSourceTaskContext {/*** Gets the configuration with which the task has been started.*/Map<String, String> config();/*** Gets the {@link OffsetStorageReader} for this SourceTask.*/OffsetStorageReader offsetStorageReader();/*** Gets the {@link OffsetStorageWriter} for this SourceTask.*/OffsetStorageWriter offsetStorageWriter();/*** Gets the {@link OffsetCommitPolicy} for this task.*/OffsetCommitPolicy offsetCommitPolicy();/*** Gets the {@link Clock} which should be used with {@link OffsetCommitPolicy} for this task.*/Clock clock();/*** Gets the transformations which the task should apply to source events before passing them to the consumer.*/Transformations transformations();
}
其他未来可靠的更改
- 切换到虚拟线程应该很简单,只需要切换到适当的ExecutorService即可,例如使用Executors.newVirtualThreadPerTaskExecutor()而不是Executors.newFixedThreadPool()。切换到结构化并发应该几乎和切换到虚拟线程一样容易。
- 将SourceTasks分成自包含的任务,并在不同的线程中并行运行它们,应该为通过gRPC在不同的机器上执行它们提供坚实的基础。主要问题是如何交换在远程机器上运行任务所需的对象,而所需的对象可能很复杂,甚至事先不知道(例如,用户提供的ChangeConsumer),因此可能很难甚至不可能为其提供protobuf表示。版本3中的Protobuf提供了对映射的支持,可以轻松地将所有配置选项传递给远程机器。因此,目前最简单的方法似乎是在此引擎中提供几种可以运行的模式之一,其中之一是“task-executor”,它将推迟初始化和启动,并将通过gRPC完成,一旦它从引擎获取任务配置。在这种情况下,引擎只充当运行任务的其他节点的协调器。这将需要较小的重构,主要是引擎的run()方法的实现,但考虑到实施这一点可能需要单独的领域驱动设计,目前似乎是可以接受的。概念验证应该作为实施的一部分或作为后续任务进行。
- 到目前为止,对Debezium operator或UI没有特别的要求。然而,将功能分离成细粒度的函数应该可以使将任何引擎功能暴露给外部服务变得平滑和容易。
- 根据Quarkus扩展指南,即使在当前实现中,EmbeddedEngine应该适用于Quarkus扩展。新的实现应该也能够与Quarkus无缝集成。类似于gRPC,概念验证应该作为后续任务进行。
测试
- 测试套件将改为仅使用DebeziumEngine API。大多数使用DebeziumEngine的测试都继承自AbstractConnectorTest,其中创建了一个DebeziumEngine实例。AbstractConnectorTest将包含一个受保护的方法,负责创建DebeziumEngine。当切换到新的DebeziumEngine实现时,只需要调整这个单一方法即可完成切换。这也允许在需要的情况下在特定的测试中更改引擎实现。
- 将来,如果有这种需要,测试套件可以通过将DebeziumEngine实现作为参数进行参数化。这将允许我们对多个引擎实现运行测试套件。然而,在不久的将来,我们不期望会有这种需要,所以目前在AbstractConnectorTest中的一个专用方法应该足够了。
- 由于现有的测试套件基于EmbeddedEngine实现,该实现提供比DebeziumEngine接口更丰富的API,在整个测试套件中无法完全使用DebeziumEngine API。在大多数情况下可以使用DebeziumEngine API或者引入一些辅助方法,除了一种情况 - EmbeddedEngine#runWithTask()。它公开了用于测试的引擎Kafka Connect SourceTask。如果我们去掉这个方法,将会丢失一些重要的测试。为了保留测试引擎源任务的能力,同时不破坏DebeziumEngine的封装,将引入一个新的接口TestingDebeziumEngine。它将属于debezium-embedded模块的测试包。接口应该只包含一个方法:runWithTask(Consumer<SourceTask> consumer):
public interface TestingDebeziumEngine<T> extends DebeziumEngine<T> {/*** Run consumer function with engine task, e.g. in case of Kafka with {@link SourceTask}.* Effectively expose engine internal task for testing.*/void runWithTask(Consumer<SourceTask> consumer);
}
- 将来,如果从测试的角度来看公开任何其他DebeziumEngine内部或添加方便的测试方法是有益的,我们可能会向此接口添加更多方法。然而,这类方法的数量应该尽可能少,并且只有在非常充分的理由下才应该添加方法,因为如果实现需要使用Debezium测试套件进行测试,接口将强制DebeziumEngine实现也实现所有这些方法。
- 由于此项工作的主要驱动因素是性能,因此此项工作的重要部分将是为DebeziumEngine开发性能测试。应该有两种类型的测试 - JMH基准测试和更健壮的端到端性能测试。 JMH基准测试可以模仿debezium-microbenchmark-oracle的JMH测试,可能使用SimpleSourceConnector或其某些修改。端到端性能测试应该包括从至少一个数据库(可能是PostgreSQL)流式传输数据,并将数据流式传输到“/dev/null”消费者以最小化接收方消费者的影响。数据可能是由在Debezium-performance下开发的工具生成的。
相关文章:

Debezium日常分享系列之:异步 Debezium 嵌入式引擎
Debezium日常分享系列之:异步 Debezium 嵌入式引擎 动机目标非目标保留Kafka Connect模型计划的更改线程池并行运行源任务存储偏移量并发处理CDC事件禁用CDC事件的完全排序自定义记录处理器并行处理记录的选项存储偏移量引擎状态和生命周期防止资源泄漏异常处理退出…...

leetcode206. Reverse Linked List
Given the head of a singly linked list, reverse the list, and return the reversed list. 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 输入:head [1,2,3,4,5] 输出:[5,4,3,2,1] 思路一:双指针 class Solu…...

【MATLAB源码-第291期】基于matlab的AMI编码解码系统仿真,输出各个节点波形。
操作环境: MATLAB 2022a 1、算法描述 AMI(Alternate Mark Inversion,交替极性反转)是一种广泛使用的编码方法,尤其是在通信系统中,用于传输二进制数据。AMI编码的特点是在传输过程中,对于0信…...

springboot苍穹外卖实战:十一:复盘总结
近期在整理草稿区,故放出此贴。 server模块需要导入对common模块的依赖 <dependency><groupId>org.example</groupId><artifactId>sky-common</artifactId><version>1.0-SNAPSHOT</version></dependency>我现在有个…...

基于Python的药房管理系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

chat2db数据库图形化工具
数据库图形化工具 DataGrip:由 JetBrains 公司开发,是开发者中广为人知的数据库管理工具,功能强大且支持多种数据库。DBeaver:一款开源的数据库管理工具,虽然相对 DataGrip 知名度稍低,但在开发者社区中也…...
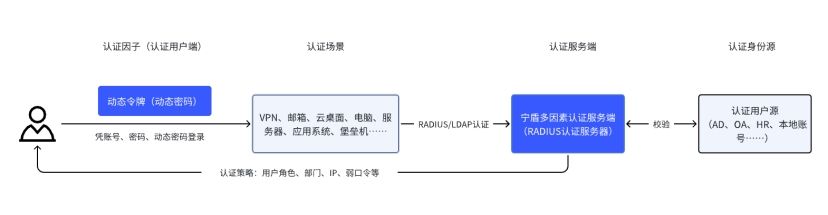
弱口令整改方案:借助双因子认证加强账号密码安全
弱口令整改方案可借助宁盾 2FA双因子身份认证来解决。双因子认证(也称双因素身份认证)是一种安全认证机制,通过结合两个及以上不同的身份验证因子,提高企业用户在办公、研发、生产、运维场景下的的账号密码安全性。它可以有效防止…...

动态代理的优势是什么?
在数据采集的世界里,效率和稳定性是衡量代理IP服务优劣的关键指标。动态代理,作为一种高效的网络工具,正逐渐成为企业和开发者的首选。今天,我们就来聊聊动态代理的优势,以及它如何成为数据采集的高效之选。 动态代理…...
微调用于文本续写任务)
将大型语言模型(如GPT-4)微调用于文本续写任务
要将大型语言模型(如GPT-4)微调用于文本续写任务,构造高质量的训练数据至关重要。以下是如何构造训练数据的详细步骤: 1. 数据收集: 多样性: 收集多种类型的文本,包括小说、新闻、论文、博客等…...

引入了JUnit框架 却报错找不到:java.lang.ClassNotFoundException
完整报错如下: Internal Error occurred. org.junit.platform.commons.JUnitException: TestEngine with ID junit-jupiter failed to discover tests at org.junit.platform.launcher.core.EngineDiscoveryOrchestrator.discoverEngineRoot(EngineDiscoveryOrc…...

深度学习:tensor的定义与维度
tensor的定义与维度 Tensor的定义与维度 Tensor是一个多维数组,用于在一般化的n维空间中表示数据和操作。在深度学习框架中,如TensorFlow或PyTorch,Tensor是基础数据结构,用来存储输入、输出、权重等信息。下面是Tensor不同维度…...

基于Python的膳食健康系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

FFmpeg 4.3 音视频-多路H265监控录放C++开发十三:将AVFrame转换成AVPacket。视频编码原理.编码相关api
前提: 从前面的学习我们知道 AVFrame中是最原始的 视频数据,这一节开始我们需要将这个最原始的视频数据 压缩成 AVPacket数据, 我们前面,将YUV数据或者 RGBA 数据装进入了 AVFrame里面,并且在SDL中显示。 也就是说&…...
)
算法——移除元素(leetcode27)
对于移除元素这道题来讲,我首先想到的还是双指针,根据题目要求我们需要在给定的一组数组中找出与目标值不同的元素数量并且将与目标值不同的元素全部移至数组左边右边则不需关注数组元素的大小,我们利用两个指针一个指向数组首部位置(左指针&…...

『OpenCV-Python』安装以及图像的读取、显示、保存
点赞 + 关注 + 收藏 = 学会了 OpenCV 是一个开源的计算机视觉库,广泛应用于图像处理、机器学习和实时计算机视觉应用。比如图像和视频的滤镜和降噪、物体检测、人脸识别、证件号识别、车牌识别等应用。当然,也有其他工具可以对这些领域做支持,但本专栏是介绍 OpenCV 的,所…...

python开发桌面应用(跨平台) 全流程
前言 之前开发一些软件,亚马逊商品分析相关软件,但是基本上是通过程序猿控制台命令启动,同时在启动之前,还要进行程序依赖包,这对于非开发人员而言,简直是一种灾难, 为了让软件对于小白更加易用, 打算将其封装成应用程序(跨平台), 下面带大家一起完成python开发桌面应用的三步…...

el-table-column prop值根据数组获取
方法一: 可以给el-table-column添加一个属性:formatter,代码如下: 这里是因为多个列都需要同样的计算,所以使用column.property获取属性,不然可以直接row.属性 方法二: 直接在template scope …...

MySQL_聚合函数分组查询
上篇复习: 设计数据库时的三大范式1.第一范式,一行数据中每一列不可再分 关系型数据库必须要满足第一范式,设计表的时候,如果每一列都可以用SQL规定的数据类型描述,就天然满足第一范式. 2.第二范式,在第一…...

PPT 制作神器!Markdown 轻松变幻灯片!
做过幻灯片的朋友们都知道,PPT 的制作常常是费时费力的工作。尤其是需要不断调整布局和设计的时候。 而现在,GitHub 上有一款开源免费的 PPT 制作工具 moffee,能够极大地简化这一过程。你只需通过简单的 Markdown 编写内容,即可快…...

一七八、Node.js PM2使用介绍
PM2 是一个强大的生产级 Node.js 进程管理器,提供了自动重启、负载均衡和进程监控等功能。适用于开发和生产环境,简化了 Node.js 应用程序的管理和维护。 PM2 安装 1. 使用 npm 安装 PM2 npm i -g pm2latest-g:全局安装。latest:…...

构建高可维护、可扩展机器学习系统:从工程化挑战到实战指南
1. 项目概述:为什么机器学习系统的“工程化”如此之难? 在过去的几年里,我参与并主导了多个从零到一的机器学习项目,从最初的算法原型验证,到最终服务于千万级用户的生产系统。一个深刻的体会是: 让一个模…...

DIV+CSS使用技巧
HTML head<title>测试</title><meta charset"utf-8"/><meta http-equivexpires content0 /><meta http-equivCache-Control contentno-cache />CSS CSS变量使用: css标识符:-- sass标识符:$ less标识符:变量只…...
)
别再只会用cp了!用dd命令给硬盘做‘全身体检’和‘克隆手术’(附实战命令)
别再只会用cp了!用dd命令给硬盘做‘全身体检’和‘克隆手术’(附实战命令)在Linux系统管理中,文件复制是最基础的操作之一。大多数用户习惯使用cp命令完成日常的文件复制任务,但当面对磁盘级操作时,cp就显得…...
)
交通顶刊TR Part C 2026年6月论文导读(下)
一期刊简介Transportation Research Part C (TR-C): Emerging Technologies 是交通领域顶刊,由 Elsevier 出版,中科院与 JCR 均为 1 区,近年影响因子约8–9.6。该期刊以交通系统为核心,聚焦 AI、大数据、运筹学等新兴技术对交通规…...

深度学习篇---cuSPARSELt
cuSPARSELt 是 NVIDIA CUDA 生态中一个专门为结构化稀疏矩阵设计的 GPU 加速数学库。它和我们常说的 cuSPARSE 是同门师兄弟,但各有绝活。如果说 cuSPARSE 是什么都能处理的“通用军刀”,那 cuSPARSELt 就是为深度学习这类特定任务量身定制的“手术刀”。…...

告别笔记本续航焦虑:手把手教你用NVMe电源管理给SSD“降频省电”
告别笔记本续航焦虑:手把手教你用NVMe电源管理给SSD“降频省电”每次带着笔记本出差,最担心的就是电量撑不过一场会议。你可能已经关闭了背光键盘、调低了屏幕亮度,甚至忍痛停用了独显,但续航依然捉襟见肘。其实,有一个…...

Gofile极速下载器:Python多线程并发下载的完整实现指南
Gofile极速下载器:Python多线程并发下载的完整实现指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader Gofile作为流行的文件共享平台,其官方下载机…...

在自动化客服系统中集成多模型 API 以提升响应稳定性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化客服系统中集成多模型 API 以提升响应稳定性 对于构建自动化客服系统的团队而言,服务的连续性与稳定性是核心诉…...

智能体通信的序列化标准探索:JSON、ProtoBuf与自定义格式的效率之争
智能体通信的「快递员之战」:JSON、ProtoBuf与自定义格式的效率深度探索 关键词 智能体通信、序列化/反序列化、JSON、Protocol Buffers、自定义二进制格式、传输效率、编码效率、跨语言兼容 摘要 在人工智能多智能体系统(Multi-Agent System, MAS)、大语言模型(LLM)驱…...

JMeter并发与持续性压测:从瞬时吞吐到系统韧性的工程实践
1. 为什么“并发持续”不是简单叠加,而是压测成败的分水岭 很多人第一次做接口性能测试时,会下意识把JMeter当成“高级curl”——写个HTTP请求,加个线程组,跑50个用户,看响应时间飘不飘。结果报告一出来,平…...