C++实现用户分组--学习
第一步实现:ETL的设计分三部分:数据抽取(Data Extraction)、数据的清洗转换(Data Transformation)、数据的加载(Data Loading).
构建一个数据容器类,其中包含转换后的MNIST手写数据。还实现了一个数据处理程序,该数据处理程序将提取并转换数据以供将来的算法实现使用。
#ifndef __DATA_H
#define __DATA_H#include <iostream>
#include <vector>
#include "stdint.h"
#include "stdio.h"// 数据类
class data
{std::vector<uint8_t>* feature_vector; // 特征向量uint8_t label; // 标签int enum_label; // 枚举标签 A->1, B->2, C->3, D->4, E->5, F->6, G->7, H->8, I->9, J->10public:data(); // 构造函数~data(); // 析构函数void set_feature_vector(std::vector<uint8_t> *); // 设置特征向量void append_to_feature_vector(uint8_t); // 向特征向量追加数据void set_label(uint8_t); // 设置标签void set_enum_label(int); // 设置枚举标签int get_feature_vector_size(); // 获取特征向量大小uint8_t get_label(); // 获取标签uint8_t get_enumerated_label(); // 获取枚举标签std::vector<uint8_t>* get_feature_vector(); // 获取特征向量};#endif这段代码定义了一个名为 data 的类,用于处理特征向量和标签。首先,代码使用了头文件保护机制,通过 #ifndef、#define 和 #endif 来防止重复包含头文件 data.hpp。
在 data 类中,有三个私有成员变量:feature_vector 是一个指向 std::vector<uint8_t> 的指针,用于存储特征向量;label 是一个 uint8_t 类型的变量,用于存储标签;enum_label 是一个整数,用于存储枚举标签,注释中说明了不同字符对应的整数值(例如,A 对应 1,B 对应 2,依此类推)。
在公共成员函数部分,data 类提供了一些方法来操作和访问这些成员变量:
void set_feature_vector(std::vector<uint8_t> *):设置特征向量的指针。void append_to_feature_vector(uint8_t):向特征向量中追加一个uint8_t类型的值。void set_label(uint8_t):设置标签。void set_enum_label(int):设置枚举标签。
此外,还有一些方法用于获取成员变量的值:
int get_feature_vector_size():获取特征向量的大小。uint8_t get_label():获取标签。uint8_t get_enumerated_label():获取枚举标签。std::vector<uint8_t>* get_feature_vector():获取特征向量的指针。
这些方法使得 data 类能够灵活地操作和访问特征向量和标签,适用于需要处理大量数据的场景。
#include "data.hpp"data::data(){feature_vector = new std::vector<uint8_t>;
}data::~data()
{delete feature_vector;
}void data::set_feature_vector(std::vector<uint8_t> *vect)
{feature_vector = vect;
}void data::append_to_feature_vector(uint8_t val)
{feature_vector->push_back(val);
}void data::set_label(uint8_t val)
{label = val;
}void data::set_enum_label(int val)
{enum_label = val;
}int data::get_feature_vector_size()
{return feature_vector->size();
}uint8_t data::get_label()
{return label;
}
uint8_t data::get_enumerated_label()
{return enum_label;
}std::vector<uint8_t>* data::get_feature_vector()
{return feature_vector;
}这段代码实现了 data 类的构造函数、析构函数以及多个成员函数。首先,代码包含了头文件 data.hpp,以确保类的声明可用。
构造函数 data::data() 初始化了 feature_vector,为其分配了一个新的 std::vector<uint8_t> 对象。析构函数 data::~data() 则负责释放该内存,防止内存泄漏。
set_feature_vector 方法接受一个指向 std::vector<uint8_t> 的指针,并将其赋值给 feature_vector。append_to_feature_vector 方法向 feature_vector 中追加一个 uint8_t 类型的值。
set_label 和 set_enum_label 方法分别设置 label 和 enum_label 的值。
get_feature_vector_size 方法返回 feature_vector 的大小。get_label 和 get_enumerated_label 方法分别返回 label 和 enum_label 的值。最后,get_feature_vector 方法返回 feature_vector 的指针。
总体来说,这段代码实现了 data 类的基本功能,使其能够管理和操作特征向量和标签。
2.处理数据
#ifndef __DATA_HANDLER_H
#define __DATA_HANDLER_H#include<fstream>
#include "stdint.h"
#include"data.hpp"
#include<vector>
#include<string>
#include<map>
#include<unordered_set>// 数据处理类
class data_handler
{std::vector<data *> *data_array; // 数据数组std::vector<data *> *training_data; // 训练数据std::vector<data *> *testing_data; // 测试数据std::vector<data *> *validation_data; // 验证数据int num_classes; // 类别数量int feature_vector_size; // 特征向量大小std::map<uint8_t, int> class_map; // 类别映射const double TRAIN_SET_PERCENTAGE = 0.75; // 训练集比例const double TEST_SET_PERCENTAGE = 0.20; // 测试集比例const double VALIDATION_SET_PERCENTAGE = 0.05; // 验证集比例public:data_handler(); // 构造函数~data_handler(); // 析构函数void read_feature_vector(std::string path); // 读取特征向量void read_label_vector(std::string path); // 读取标签向量void split_data(); // 分割数据void count_classes(); // 统计类别数量uint32_t convert_to_little_endian(const unsigned char* bytes); // 转换为小端序std::vector<data *> *get_training_data(); // 获取训练数据std::vector<data *> *get_testing_data(); // 获取测试数据std::vector<data *> *get_validation_data(); // 获取验证数据};#endif这个类名为 data_handler,用于处理数据集的读取、分割和分类等操作。以下是对该类的详细解释:
成员变量
-
std::vector<data *> *data_array:- 指向一个
std::vector容器的指针,该容器存储了所有的数据对象的指针。
- 指向一个
-
std::vector<data *> *training_data:- 指向一个
std::vector容器的指针,该容器存储了训练数据集的数据对象的指针。
- 指向一个
-
std::vector<data *> *testing_data:- 指向一个
std::vector容器的指针,该容器存储了测试数据集的数据对象的指针。
- 指向一个
-
std::vector<data *> *validation_data:- 指向一个
std::vector容器的指针,该容器存储了验证数据集的数据对象的指针。
- 指向一个
-
int num_classes:- 存储数据集中类别的数量。
-
int feature_vector_size:- 存储特征向量的大小。
-
std::map<uint8_t, int> class_map:- 一个映射,用于将类别标签(
uint8_t类型)映射到整数值。
- 一个映射,用于将类别标签(
-
const double TRAIN_SET_PERCENTAGE:- 常量,表示训练数据集所占的比例,值为 0.75。
-
const double TEST_SET_PERCENTAGE:- 常量,表示测试数据集所占的比例,值为 0.20。
-
const double VALIDATION_SET_PERCENTAGE:- 常量,表示验证数据集所占的比例,值为 0.05。
构造函数和析构函数
-
data_handler():- 构造函数,用于初始化
data_handler对象。
- 构造函数,用于初始化
-
~data_handler():- 析构函数,用于释放
data_handler对象所占用的资源。
- 析构函数,用于释放
成员函数
-
void read_feature_vector(std::string path):- 从指定路径读取特征向量数据。
-
void read_label_vector(std::string path):- 从指定路径读取标签数据。
-
void split_data():- 将数据集分割为训练集、测试集和验证集。
-
void count_classes():- 统计数据集中各个类别的数量。
-
uint32_t convert_to_little_endian(const unsigned char* bytes):- 将字节数组转换为小端格式的
uint32_t类型。
- 将字节数组转换为小端格式的
-
std::vector<data *> *get_training_data():- 返回指向训练数据集的指针。
-
std::vector<data *> *get_testing_data():- 返回指向测试数据集的指针。
-
std::vector<data *> *get_validation_data():- 返回指向验证数据集的指针。
总结
data_handler 类提供了一系列方法,用于读取数据、分割数据集、统计类别数量以及获取训练集、测试集和验证集。通过这些方法,可以方便地管理和处理数据集,适用于机器学习和数据分析等场景。
相关文章:

C++实现用户分组--学习
第一步实现:ETL的设计分三部分:数据抽取(Data Extraction)、数据的清洗转换(Data Transformation)、数据的加载(Data Loading). 构建一个数据容器类,其中包含转换后的MNIST手写数据。还实现了一个数据处理程序,该数据处理程序将提…...

鸿蒙华为商城APP案例
模拟器运行效果如下: 鸿蒙版APP-华为商城-演示视频...

回首遥望-C++内存对齐的思考
这一章节主要巩固一下学习C/C时内存对齐相关的内容! 文章目录 什么是内存对齐?为什么要有内存对齐?如何进行内存对齐?致谢: 什么是内存对齐? 这里不提及一堆啰嗦概念,就结合实际出发࿰…...

力扣 LeetCode 704. 二分查找(Day1:数组)
解题思路: 二分查找主要分为[ left , right ]左闭右闭和[ left , right )左闭右开两种 此处采取[ left , right ]左闭右闭写法 注意: 1. right的初始化取值 2. while中取等 3. right mid -1 ; class Solution {public int search(int[] nums, i…...

【Mode Management】AUTOSAR架构下唤醒源检测函数EcuM_CheckWakeup详解
目录 前言 正文 1.AUTOSAR标准描述 1.1 EcuM_CheckWakeup用来干什么 1.2 EcuM_CheckWakeup在哪里被调用 1.3 EcuM_CheckWakeup的使用场景 1.3.1 GPT中断检测唤醒源 1.3.2 EcuM轮询GPT检测唤醒源 1.3.3 ICU中断检测唤醒源 1.3.4 其他 2.AUTOSR工具相关配置 3.唤醒源…...

Zabbix基础信息概述
1.Zabbix概述 Zabbix 是一款能够监控各种网络参数以及服务器健康性和完整性的软件。Zabbix 使用灵活的通知机制,允许用户为几乎任何事件配置基于邮件的告警,这样可以快速反馈服务器的问题。基于已存储的数据,Zabbix 提供了出色的报告和数据可…...
SpringBoot配置redis)
SpringBoot(十二)SpringBoot配置redis
接下来我要实现的webscoket即时聊天中需要使用到redis,我先在项目中配置一下redis。 我这里再windows中做测试,关于redis的安装请移步《Redis(三)Windows系统安装redis》 一:在pom.xml中添加依赖 <!-- springboot redis start --><dependency><grou…...
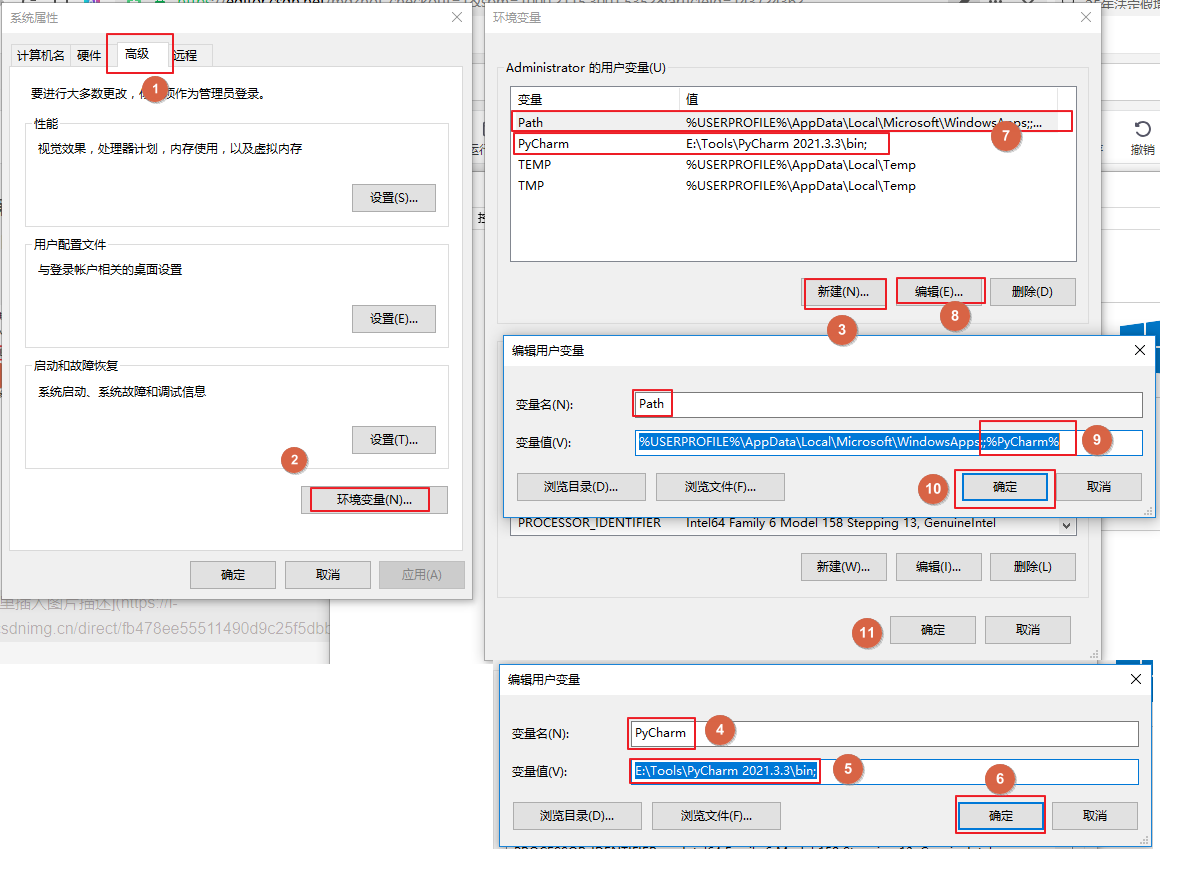
Pycharm安装
Pycharm安装 返回主目录Pycharm安装1. Pycharm下载PyCharm官网下载地址下载安装包 2. Pycharm安装第一步:双击安装包第二步:进入安装程序第三步:选择安装路径第四步:选择安装选项第五步:安装第六步:完成安装…...
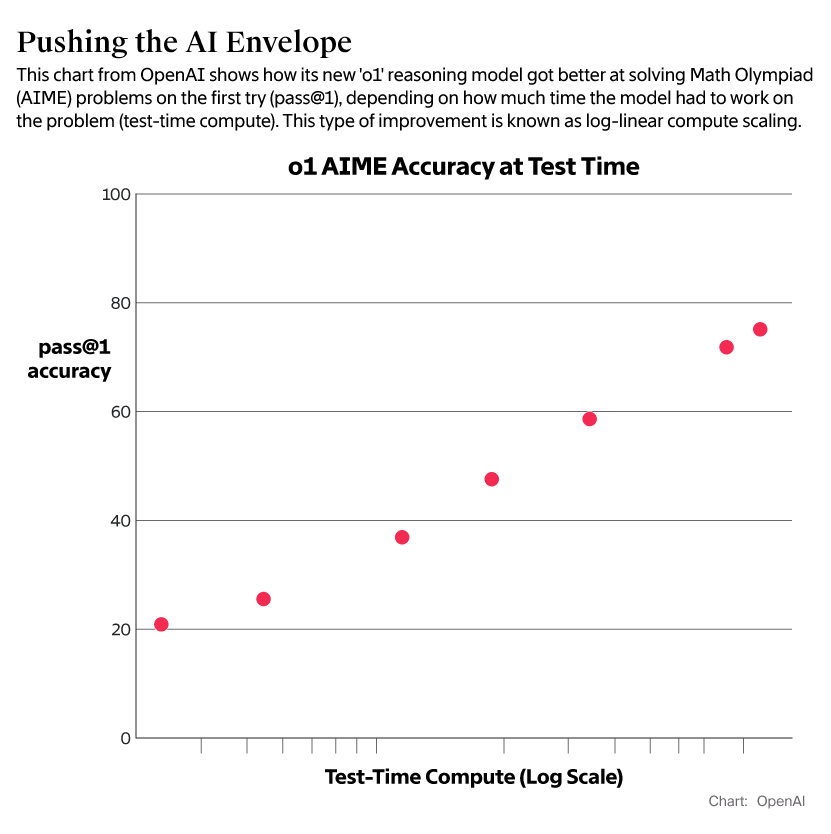
OpenAI大改下代大模型方向,scaling law撞墙?AI社区炸锅了
有研究预计,如果 LLM 保持现在的发展势头,预计在 2028 年左右,已有的数据储量将被全部利用完。届时,基于大数据的大模型的发展将可能放缓甚至陷入停滞。 来自论文《Will we run out of data? Limits of LLM scaling based on hum…...

技术整合与生态构建:Lyft与Mobileye引领自动驾驶新纪元
在科技日新月异的今天,自动驾驶技术正逐渐从科幻电影走进现实生活,成为出行服务领域的一股不可忽视的力量。近日,北美网约车巨头Lyft与自动驾驶技术领先者Mobileye宣布联手合作,共同推动自动驾驶汽车出行服务的广泛商业化进程。此…...

利用huffman树实现对文件A先编码后解码
利用huffman树实现对文件A先编码后解码,范围为ASCII码0-255的值,如何解决特殊符号问题是一个难点,注意应使用unsigned char存储数据,否则ASCII码128-255的值可能会出问题: #define _CRT_SECURE_NO_WARNINGS 1 #includ…...

第三十九章 基于VueCli自定义创建项目
目录 1. 选择创建模式 2. 选择需要的功能 3. 选择历史模式还是哈希模式 4.CSS预处理器 5. 选择ESLint规则 6. 开始创建项目 7. 自定义项目最终结构 1. 选择创建模式 输入创建的项目名,创建项目: 这里选择自定义模式: 2. 选择需要…...

网页web无插件播放器EasyPlayer.js点播播放器遇到视频地址播放不了的现象及措施
在数字媒体时代,视频点播已成为用户获取信息和娱乐的重要方式。EasyPlayer.js作为一款流行的点播播放器,以其强大的功能和易用性受到广泛欢迎。然而,在使用过程中,用户可能会遇到视频地址无法播放的问题,这不仅影响用户…...

LLaMA-Factory学习笔记(1)——采用LORA对大模型进行SFT并采用vLLM部署的全流程
该博客是我根据自己学习过程中的思考与总结来写作的,由于初次学习,可能会有错误或者不足的地方,望批评与指正。 1. 安装 1.1 LLaMA-Factory安装 安装可以参考官方 readme (https://github.com/hiyouga/LLaMA-Factory/blob/main/…...

PHP和Python脚本的性能监测方案
目录 1. 说明 2. PHP脚本性能监测方案 2.1 安装xdebug 2.2 配置xdebug.ini 2.3 命令行与VS Code中使用 - 命令行 - VS Code 2.4 QCacheGrind 浏览 3. Python脚本性能监测方案 3.1 命令行 4. 工具 5.参考 1. 说明 获取我们的脚本程序运行时的指标,对分析…...

C语言实现数据结构之堆
文章目录 堆一. 树概念及结构1. 树的概念2. 树的相关概念3. 树的表示4. 树在实际中的运用(表示文件系统的目录树结构) 二. 二叉树概念及结构1. 概念2. 特殊的二叉树3. 二叉树的性质4. 二叉树的存储结构 三. 二叉树的顺序结构及实现1. 二叉树的顺序结构2.…...

战略共赢 软硬兼备|云途半导体与知从科技达成战略合作
2024年11月5日,江苏云途半导体有限公司(以下简称“云途”或“云途半导体”)与上海知从科技有限公司(以下简称“知从科技”)达成战略合作,共同推动智能汽车领域高端汽车电子应用的开发。 云途半导体与知从科…...

python:用 sklearn 构建 K-Means 聚类模型
pip install scikit-learn 或者 直接用 Anaconda3 sklearn 提供了 preprocessing 数据预处理模块、cluster 聚类模型、manifold.TSNE 数据降维模块。 编写 test_sklearn_3.py 如下 # -*- coding: utf-8 -*- """ 使用 sklearn 构建 K-Means 聚类模型 "&…...
实现方案)
elementUI中2个日期组件实现开始时间、结束时间(禁用日期面板、控制开始时间不能超过结束时间的时分秒)实现方案
没有使用selectableRange 禁用时分秒,是因为他会禁止每天的时分秒。 我们需要解决的是当开始时间、结束时间是同一天时, 开始时间不能超过结束时间。 如果直接清空,用户体验不好。所以用watch监听赋值,当前操作谁,它不…...

Oracle 聚集因子factor clustering
文章目录 聚集因子(Factor clustering)举例说明查询聚集因子聚集因子的优化结论 最近发现突然忘记聚集因子的原理了,故整理记录一下 聚集因子(Factor clustering) 在Oracle中,聚集因子(Clustering Factor)用于衡量数据在表中存储…...

ARM Trace Buffer扩展与调试同步机制详解
1. ARM Trace Buffer扩展与调试状态同步机制解析在嵌入式系统和处理器架构设计中,调试与追踪技术是开发人员不可或缺的工具。ARM架构通过Trace Buffer Extension(TBE)提供了强大的指令级执行流追踪能力,其核心原理是通过专用硬件单…...

CAXA 引出说明
位置同 CAD 里引线。效果示例设置样式默认样式,GB_引出说明(1984)Tip:如果引线样式需求是和标注样式一致,就使用“标注” 这一个样式就可以了。场景例如,标注比例是 1:4;但有个地方需要用文字引…...

ctf show web入门 254
这是一道典型的php对象序列化的题目可以从代码看出,本题需要让$user->isvip为true就可以调用yiponekeygetflag()函数从而获取flag从这可以看出$this->username$u&&$this->password$p时isvip为true,所以我们尝试构造payload为࿱…...

Claude Code 基础配置篇-三层配置体系详解
基础配置篇 —— Rules、Memory、Custom Instructions 三层配置体系详解系列导读: Claude Code 最让新手头疼的问题是"每次写的代码风格都不一样"、“总要重新解释项目架构”。本篇将彻底解决这个问题。通过建立三层配置体系,你可以让 Claude …...
—东方仙盟)
支付即开票·自助开票·阿雪心学·无相无界(12)—东方仙盟
未来之窗架构:支付即开票,构建企业数字化开票新生态未来之窗架构深度融合数电发票创新能力,以支付即开票为核心内核,打通交易、开票、数据流转全链路,为企业提供合规、高效、低成本的一体化开票解决方案。该架构无需依…...

高校教务系统DES加密登录逆向实战:从抓包到Python自动化
1. 这不是“爬个登录”那么简单:为什么一个广东白云学院的登录接口值得花一整天逆向你可能刚看到标题就下意识划走——“又一个学校教务系统?不就是抓个包改个密码字段嘛”,我完全理解。去年帮朋友调试某高校选课脚本时,我也这么想…...

网络技术05-TCP拥塞控制算法——从CUBIC到BBR的性能进化
🚗 一句话总结:TCP拥塞控制就像开车——看到前面堵车就减速(拥塞避免),路通畅了就慢慢加速(慢启动)。CUBIC是"看到堵车就猛踩刹车",BBR是"根据路况预测提前调整"…...

【LeetCode刷题日记】二叉搜索树 的中序遍历 + 前驱指针,一套模板解决530.最小绝对差|501.二叉搜索树中的众数
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

【ChatGPT投资人邮件撰写黄金法则】:20年FA/VC顾问亲授——3类高回复率模板+5个致命话术雷区
更多请点击: https://codechina.net 第一章:ChatGPT投资人邮件撰写的核心认知与底层逻辑 投资人邮件不是信息的简单堆砌,而是认知对齐、信任构建与决策催化三重目标的高度凝练表达。其底层逻辑根植于风险投资行业的决策机制——LP关注资金效…...

零基础玩转AI斗地主:DouZero_For_HappyDouDiZhu快速上手实战指南
零基础玩转AI斗地主:DouZero_For_HappyDouDiZhu快速上手实战指南 【免费下载链接】DouZero_For_HappyDouDiZhu 基于DouZero定制AI实战欢乐斗地主 项目地址: https://gitcode.com/gh_mirrors/do/DouZero_For_HappyDouDiZhu 想要在欢乐斗地主中体验AI智能辅助的…...