【高中生讲机器学习】25. AdaBoost 算法详解+推导来啦!
创建时间:2024-11-08
首发时间:2024-11-13
最后编辑时间:2024-11-13
作者:Geeker_LStar
你好呀~这里是 Geeker_LStar 的人工智能学习专栏,很高兴遇见你~
我是 Geeker_LStar,一名高一学生,热爱计算机和数学,我们一起加油~!
⭐(●’◡’●) ⭐
hi!!! 上一篇开了个坑,大概介绍了一下集成学习。这篇我们来讲集成学习之 Boosting 中很经典的一个算法——AdaBoost!
AdaBoost 是 Boosting 的代表之一,so 它具有 Boosting 算法的各种共性,so 可以先大概了解一下 Boosting 再看 AdaBoost 噢!
启动!
文章目录
- 主要思想
- 正向解释:数学叙述
- 逆向解释:前向分布算法
- 前向分步算法
- AdaBoost 特例
- 总结
主要思想
在上一篇中我们说过,Boosting 算法用那些过于简单的、欠拟合的学习器(模型)作为基学习器,以串行的方式对这些基学习器进行组合,以获得性能更好的模型。Boosting 算法旨在解决基学习器高偏差的问题。
这里放一张图来复习一下 Boosting,尤其是它的 “串行”:
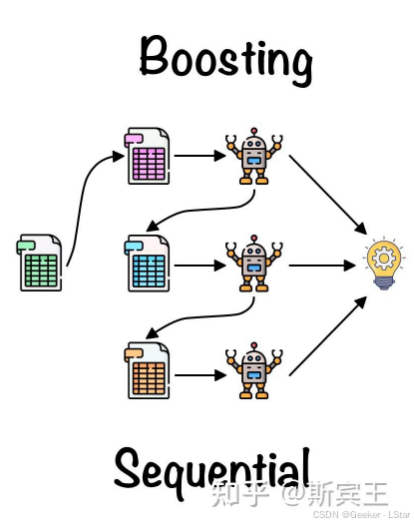
remember,在 Boosting 中,每个基学习器都是在前一个基学习器的基础上生成的,这个基准会贯穿整篇文章(或者说关于 Boosting 的所有文章)。
嗯,从 Boosting 的主要思想出发,很自然地就有以下这两个问题:
第一,选择什么模型作为弱学习器?
第二,怎样组合这些弱学习器?
第二个问题又可以引出更多的问题:每个弱学习器拥有一样的权重吗?每个弱学习器学习的数据是相同的吗?组合到什么时候算结束呢?…
上面这些都是 AdaBoost,或者说 Boosting 家族的算法的核心问题。Boosting 家族为什么有不同的算法呢?因为这些问题可以有很多种答案。
可以说,Boosting 家族的每一种算法都给出了对以上问题的不同回答,搞懂了这几个问题,对应的算法也就搞明白啦!
嗯!那我们就从 adaboost 开始吧嘿嘿嘿。(eeea 原谅我真的懒得每次都把 A 和 B 大写(((
首先,对于第一个问题,adaboost 选择决策树桩作为基学习器,决策树桩就是只有一个根节点和两个子节点的决策树,这在决策树那篇当中我讲过。
为什么这么选呢?因为决策树桩简单,它一定是个高偏差的模型,这非常符合 boosting 的口味。boosting 就是要选择那些欠拟合的学习器作为基学习器。
接下来是第二个问题,或者说是一系列问题——怎样组合这些基学习器?
在这里先给个概括:adaboost 算法串行生成每个基学习器,相同的样本在每个基学习器上有不同的权重,每个基学习器本身也有不同的权重,这些权重都是可量化的。
可以细化为以下三点:
-
关于串行:后一个基学习器是在前一个基学习器的基础上生成的。
-
关于样本权重:在前一个基学习器上产生较高损失的样本会被后一个基学习器赋予更高的权重;换言之,后一个基学习器会更关注在前一个基学习器上产生较高损失的样本。
-
关于基学习器权重:在最终的基学习器组合中,每个基学习器拥有不同的权重。性能越好(表现为损失函数越小)的基学习器会获得更高的权重。
这些都是很直观的想法,adaboost 之所以好用,或许就是因为它把这些很直观的想法们结合在了一起。
adaboost 既可以用于分类(二分类 & 多分类),也可以用于回归。后面我将以分类问题为例叙述 adaboost 的各种操作,然后提一下如果是回归问题,在各个步骤上应该做什么样的修改。
(其实也就损失函数会有差别啦,别的地方的差别都很小。
我们先来看 adaboost 算法的数学表述,其中包含了更多细节。
正向解释:数学叙述
这一部分中,我们以二分类为例,展示 adaboost 算法的数学表示。
首先还是来规定一些 notation。
我们有一个包含 N N N 个样本的二分类数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T = \{(x_1, y_1), (x_2, y_2), ...,(x_N, y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)},其中 y i ∈ { + 1 , − 1 } y_i \in \{+1, -1\} yi∈{+1,−1}。
在这个数据集的基础上,我们会训练 M M M 个基学习器 m 1 , m 2 , . . . , m M m_1, m_2, ..., m_M m1,m2,...,mM,每个基学习器的权重记作 α 1 , α 2 , . . . , α M \alpha_1, \alpha_2, ..., \alpha_M α1,α2,...,αM,数据集中第 n n n 个样本 x i x_i xi 在第 m m m 个基学习器上的权重记作 w m , n w_{m,n} wm,n.
emmm 感觉把这些符号写在一起有点让人头大()。
okay,现在我们从第一轮,或者说第一个基学习器开始。
在第一轮中,所有的样本拥有相同的权重,即:
w 1 , n = 1 N , n = 1 , 2 , . . . , N w_{1, n} = \frac 1 N, \ n=1, 2, ..., N w1,n=N1, n=1,2,...,N
根据目前的数据,我们找到最优基学习器 G 1 ( x ) G_1(x) G1(x)。
最优基学习器怎么找呢?当然是最小化损失函数啦,如下:
G 1 ( x ) = arg min G ∑ i = 1 N w 1 , i I ( y i ≠ G ( x i ) ) G_1(x)=\argmin_G\sum_{i=1}^N w_{1, i} I(y_i \neq G(x_i)) G1(x)=Gargmini=1∑Nw1,iI(yi=G(xi))
其中 w 1 , i w_{1,i} w1,i 为第 i i i 个样本 x i x_i xi 在第 1 个基学习器上的权重, I I I 是指示函数,当括号内条件成立,即 y i ≠ G ( x i ) y_i \neq G(x_i) yi=G(xi) 时,指示函数值为 1,否则为 0。
也就是说,当基学习器预测的标签和真实标签不同时,损失为它的权重,否则为 0.
注意,因为这里我们使用的是分类损失中的 0-1 损失(这里多了个加权),同时我们默认的基学习器(决策树桩)是一个非参数模型,所以这个损失函数没有办法写成参数的形式,也就是说,我们不能通过数值优化算法来求解这个损失函数。
在实际实现中,adaboost(决策树桩)会尝试所有可能的分裂特征,并选出让损失函数最小的那个,没有显式的数值优化过程。
嗯,在这里补充一下,当问题是回归问题,我们要找的模型是一个可参数化的回归模型(比如线性回归 y = β T x y=\beta^Tx y=βTx)的时候的情况。
这个时候,前面的权重不变,但是后面就不再是指示函数了。如果我们采用平方损失作为损失函数,后面的部分就变成:
( y i − G ( x i ) ) 2 \bigg(y_i-G(x_i)\bigg)^2 (yi−G(xi))2
那么,整个式子就变成:
G 1 ∗ ( x ) = arg min G ∑ i = 1 N w 1 , i ( y i − G ( x i ) ) 2 = arg min β ∑ i = 1 N w 1 , i ( y i − β T x i ) 2 G_1^*(x)=\argmin_G\sum_{i=1}^N w_{1, i} \bigg(y_i-G(x_i)\bigg)^2 \\ =\argmin_\beta\sum_{i=1}^N w_{1, i} \bigg(y_i-\beta^Tx_i\bigg)^2 G1∗(x)=Gargmini=1∑Nw1,i(yi−G(xi))2=βargmini=1∑Nw1,i(yi−βTxi)2
这种情况下,我们就可以显式地使用数值优化算法求解啦!
en!! 现在我们可以大致理解这个 “权重” 是怎么起作用的了——对于每个样本,如果它被分类错误了,产生的损失是它的权重。这就迫使模型更关注那些权重大的样本,争取把它们都分类正确,以获得更小的损失。
用一张图来解释:
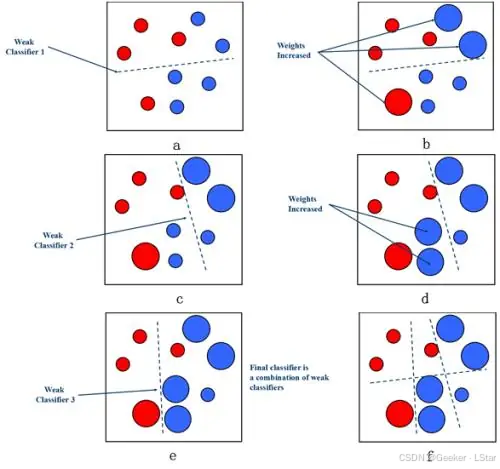
图中,被第一个基学习器分类错误的样本在第二个基学习器那里获得了更高的权重,第二个基学习器会更注重把它们分类正确,以此类推。
嗯,现在假设我们找到了最优基学习器(决策树桩) G 1 ( x ) G_1(x) G1(x)。接下来,我们要用它对样本进行分类,并计算分类错误率。
错误率的计算和损失的计算是一样的,换句话说,我们找到的损失最小的基学习器也就是错误率最小的基学习器,在这个语境下两者是等价的。
第一个基学习器的错误率 e 1 e_1 e1 为:
e 1 = ∑ i = 1 N w 1 , i I ( y i ≠ G ( x i ) ) e_1 = \sum_{i=1}^N w_{1,i} I(y_i\neq G(x_i)) e1=i=1∑Nw1,iI(yi=G(xi))
然后,根据这个错误率,我们计算第一个模型的权重。
前面说过,adaboost 很聪明,它会给那些错误率低的模型赋予更高的权重。这种量化是通过对数函数定义的,公式如下。
α 1 = 1 2 log 1 − e 1 e 1 \alpha_1= \frac{1}{2} \log \frac{1-e_1}{e_1} α1=21loge11−e1
我们直接来看图像吧,这是 α \alpha α 和 e e e 的关系图,横轴代表 e , 0 < e < 1 e,\ 0 < e < 1 e, 0<e<1,纵轴代表 α \alpha α。
可以看到,函数是单调递减的, e e e 越小,相应的 α \alpha α 就越大。
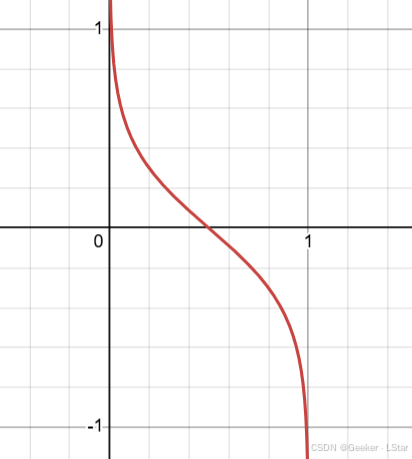
嗯不过我们这里要注意一件事。即,在通常情况下,弱学习器的错误率都会小于 0.5,也就是说弱学习器的性能再怎么差也会比随即猜测好。在这个前提下,弱学习器的权重总是大于 0 的,这一点也可以从图上看出来(当 e > 0.5 e>0.5 e>0.5 时, α > 0 \alpha>0 α>0)。
emm 那么,如果真的出现了某个弱学习器的性能比随即猜测差的情况呢(虽然几乎不会出现)?
well,那这个弱学习器的权重就会变成负值了。也就是说,这个弱学习器在整个模型中的
这也很好理解,如果弱学习器的准确率小于 0.5,那我们只要和它反着来(也就是权重为负数),就可以获得大于 0.5 的准确率了。
举个不恰当的例子,这就像你 “借鉴” 其他同学的作业(咳咳),如果有个同学很不靠谱,错的题总是比对的多,那这个时候,没有被这位同学选择的那些选项反而有可能是正确选项。换言之,这位同学可能不太能告诉你什么是正确答案,但是可以帮助你避开一些错误答案(((咳咳为什么我会对借鉴作业这么了解(bushi
嗯,现在我们已经获得了第一个模型的权重 α 1 \alpha_1 α1,模型权重这块处理完了,接下来要处理样本权重了。
前面说过,如果某个样本被上一个弱学习器分类错误,adaboost 会加大它在下一个弱学习器中的权重;相反地,如果某个样本被上一个弱学习器分类正确,adaboost 会减小它在下一个弱学习器中的权重。
在实际实现中,样本权重的更新和模型权重是密切相关的,我们还是来看式子,这个式子表示了所有样本在第二个基学习器上的权重。
w 2 , i = w 1 , i Z ( w 1 ) exp ( − α 1 y i G 1 ( x i ) ) w_{2,i}=\frac{w_{1,i}}{Z(w_1)}\exp(-\alpha_1y_iG_1(x_i)) w2,i=Z(w1)w1,iexp(−α1yiG1(xi))
well 乍一看这个式子有点复杂诶,没事我们分开来看,分别看当基学习器预测正确和预测错误的时候,样本权重的变化。
首先是基学习器预测正确的时候,此时 y i y_i yi 和 G 1 ( x i ) G_1(x_i) G1(xi) 同号,即 y i G 1 ( x i ) = 1 y_iG_1(x_i)=1 yiG1(xi)=1,那么我们有:
w 2 , i = w 1 , i Z ( w 1 ) exp ( − α 1 y i G 1 ( x i ) ) = w 1 , i Z ( w 1 ) exp ( − α ) w_{2,i}=\frac{w_{1,i}}{Z(w_1)}\exp(-\alpha_1y_iG_1(x_i))=\frac{w_{1,i}}{Z(w_1)}\exp(-\alpha) w2,i=Z(w1)w1,iexp(−α1yiG1(xi))=Z(w1)w1,iexp(−α)
前面说过,通常而言 α \alpha α 的值为正,那么 − α -\alpha −α 的值为负。此时 exp ( − α ) \exp(-\alpha) exp(−α) 的值小于 1,即 w 2 , i = w 1 , i exp ( − α ) < w 1 , i w_{2,i}=w_{1,i}\exp(-\alpha)<w_{1,i} w2,i=w1,iexp(−α)<w1,i,也就是说这个样本的权重变小了。
(先不用管 Z ( w 1 ) Z(w_1) Z(w1) 是什么,后面会说到)
相应的,当基学习器预测错误的时候,此时 y i y_i yi 和 G 1 ( x i ) G_1(x_i) G1(xi) 异号,即 y i G 1 ( x i ) = − 1 y_iG_1(x_i)=-1 yiG1(xi)=−1,我们有:
w 2 , i = w 1 , i Z ( w 1 ) exp ( − α 1 y i G 1 ( x i ) ) = w 1 , i Z ( w 1 ) exp ( α ) w_{2,i}=\frac{w_{1,i}}{Z(w_1)}\exp(-\alpha_1y_iG_1(x_i))=\frac{w_{1,i}}{Z(w_1)}\exp(\alpha) w2,i=Z(w1)w1,iexp(−α1yiG1(xi))=Z(w1)w1,iexp(α)
我们有 exp ( α ) > 1 \exp(\alpha)>1 exp(α)>1,即 w 2 , i = w 1 , i exp ( α ) > w 1 , i w_{2,i}=w_{1,i}\exp(\alpha)>w_{1,i} w2,i=w1,iexp(α)>w1,i,样本的权重变大了。
o 对了,这里还有一个点就是, α \alpha α 越大,或者说,基学习器的性能越好,被它分类错误的样本在下一轮中获得权重(增量)就会越大。这也非常符合直觉——那些被很好的模型分类错误的点通常比那些性能一般的模型分类错误的点需要更多的关注,因为它们更难被分类正确(就像通常而言,学霸错的题是更难的题一样)。所以,在同样是被分类错误的情况下,如果这个点是被一个性能很好的模型分类错误的,它的权重增加量会比它被一个一般的模型分类错误的时候的权重增加量更多。
嗯,现在我们来看一下 Z ( w 1 ) Z(w_1) Z(w1)。它只是用于归一化的配分函数,对样本权重间的大小关系没有影响,我们在最大熵那一篇中见到过它。在这里 Z ( w 1 ) Z(w_1) Z(w1) 的表达式如下:
Z ( w 1 ) = ∑ i = 1 N w 1 , i exp ( − α 1 y i G 1 ( x i ) ) Z(w_1)=\sum_{i=1}^Nw_{1,i}\exp(-\alpha_1y_iG_1(x_i)) Z(w1)=i=1∑Nw1,iexp(−α1yiG1(xi))
nice!! 现在我们得到了样本在第二个基学习器上的权重 w 2 , i w_{2, i} w2,i,可以按照相同的流程往下做啦!我就不一轮一轮写了,这里给出一个流程概括。
首先,在经过第 m − 1 m-1 m−1 个基学习器后,第 i i i 个样本 x i x_i xi 的权重可以用 w w , i w_{w, i} ww,i 表示,这代表了 x i x_i xi 在第 m m m 个基学习器上的权重。
根据现有数据及权重,我们最小化如下损失函数,得到最优基学习器 G m ( x ) G_m(x) Gm(x):
G m ( x ) = arg min G ∑ i = 1 N w m , i I ( y i ≠ G ( x i ) ) G_m(x)=\argmin_G\sum_{i=1}^N w_{m, i} I(y_i \neq G(x_i)) Gm(x)=Gargmini=1∑Nwm,iI(yi=G(xi))
计算 G m ( x ) G_m(x) Gm(x) 的错误率 e m e_m em:
e m = ∑ i = 1 N w m , i I ( y i ≠ G ( x i ) ) e_m = \sum_{i=1}^N w_{m,i} I(y_i\neq G(x_i)) em=i=1∑Nwm,iI(yi=G(xi))
根据错误率计算 G m ( x ) G_m(x) Gm(x) 的权重 α m \alpha_m αm:
α m = 1 2 log 1 − e m e m \alpha_m= \frac{1}{2} \log \frac{1-e_m}{e_m} αm=21logem1−em
得到 α m \alpha_m αm 后,更新每个样本点的权重:
w m + 1 , i = w m , i Z ( w m ) exp ( − α m y i G m ( x i ) ) w_{m+1,i}=\frac{w_{m,i}}{Z(w_m)}\exp(-\alpha_my_iG_m(x_i)) wm+1,i=Z(wm)wm,iexp(−αmyiGm(xi))
最终,我们得到了 M M M 个基学习器的线性组合,也就是我们最终需要的强学习器 G ( x ) G(x) G(x)!
G ( x ) = ∑ m = 1 M α m G m ( x ) G(x)=\sum_{m=1}^M \alpha_mG_m(x) G(x)=m=1∑MαmGm(x)
好耶!!
嗯!那么这部分就到这里吧,我觉得你现在应该对 AdaBoost 算法有一个比较全面的了解啦!
接下来,我们来看一些更有趣的东西…
逆向解释:前向分布算法
上一个部分中,我们正向梳理了一遍 adaboost 算法的流程和数学表示。一切看上去都很合理也很简洁。(点头)
诶但是你有没有好奇,这么合理的东西是怎么来的?举个例子,为什么 α m \alpha_m αm 一定等于 1 2 log 1 − e m e m \frac{1}{2} \log \frac{1-e_m}{e_m} 21logem1−em?因为它单调递增吗?但满足单调递增性质的函数也不止它一个吧。
在上上一篇中,我们最终推出来,逻辑回归算法是最大熵模型的一个特例,当我们选择某个特定的特征函数的时候,最大熵算法等价于逻辑回归算法。
这篇文章和那篇文章,在这个点上,简直太像了!
没错,我们后面马上就会说到,adaboost 算法也是一个算法的特例,这个算法就是——前向分布算法!(emmm 诶其实这部分的小标题是不是已经暴露了这件事情()
(o对了那篇文章在这里:23. 最大熵模型详解+推导来啦!解决 why sigmoid!
我们先来看看前向分布算法吧。
前向分步算法
前向分步算法,说的更具体一点,前向分步加法算法,可以看作一种分步优化算法。用一句话概括就是,它把一个【需要一次性完成的】复杂优化问题拆解成了很多个【可以分步完成的】简单优化问题;它分步完成这些简单优化问题,并用最终的结果近似原始的复杂优化问题。
emmm 似乎没有什么很好的例子,so 我们直接来看数学表述吧()不过也并没有很复杂啦。
还是一样的数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T = \{(x_1, y_1), (x_2, y_2), ...,(x_N, y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)}.
考虑如下所示的加法模型,它其实是一个模型,但是由很多个不同的模型(基学习器)构成:
f ( x ) = ∑ m = 1 M β m b ( x , γ m ) f(x)=\sum_{m=1}^M\beta_mb(x,\gamma_m) f(x)=m=1∑Mβmb(x,γm)
展开来写就是:
f ( x ) = β 1 b ( x , γ 1 ) + β 2 b ( x , γ 2 ) + . . . + β M b ( x , γ M ) f(x)=\beta_1b(x,\gamma_1)+\beta_2b(x,\gamma_2)+...+\beta_Mb(x, \gamma_M) f(x)=β1b(x,γ1)+β2b(x,γ2)+...+βMb(x,γM)
解释一下参数, β m \beta_m βm 代表第 m m m 个模型的权重, x x x 代表输入数据, γ m \gamma_m γm 代表第 m m m 个模型的参数。
注意o, b b b 不一定是线性模型, γ m \gamma_m γm 决定了它是什么模型(实际上,它可以是任何模型,在 adaboost 中,它通常是决策树桩)。
注意我们现在写的是对于某个特定的 x x x 的 f ( x ) f(x) f(x),在真实的数据集中还需要加一个 ∑ i = 1 N \sum_{i=1}^N ∑i=1N 来遍历整个数据集。
嗯,我们现在的任务就是找到最优参数 β = { β 1 , β 2 , . . . , β M } \beta=\{\beta_1, \beta_2, ..., \beta_M\} β={β1,β2,...,βM} 和 γ = { γ 1 , γ 2 , . . . , γ M } \gamma=\{\gamma_1, \gamma_2, ..., \gamma_M\} γ={γ1,γ2,...,γM},这是一个多元优化问题。它的损失函数长成下面这个样子,
Loss = ∑ i = 1 N L ( y i , ∑ m = 1 M β m b ( x i , γ m ) ) \text{Loss}=\sum_{i=1}^N\mathcal{L}\bigg(y_i, \sum_{m=1}^{M}\beta_mb(x_i, \gamma_m)\bigg) Loss=i=1∑NL(yi,m=1∑Mβmb(xi,γm))
其中 y i y_i yi 是 x i x_i xi 对应的正确标签,其它参数已经解释过了。
我们的目的就是最小化这个损失函数。
em…这怎么办?或者说,这能怎么办???这个问题太复杂了。
我们需要一些让它变简单的方法。
前向分步算法给出了一种思路——既然不能一次求出所有的,那我一次求一个,再把所有次的加起来,总可以了吧?
好耶!我们来试试这种方法。
首先我们需要设置 f ( 0 ) f(0) f(0),显然开始的时候什么都没有,所以 f ( 0 ) = 0 f(0)=0 f(0)=0。
then 还是从第一次开始,往后推。
第一个模型的权重为 β 1 \beta_1 β1,参数为 γ 1 \gamma_1 γ1,我们的损失函数是:
Loss = ∑ i = 1 N L ( y i , f 0 ( x i ) + β 1 b ( x i , γ 1 ) ) \text{Loss}=\sum_{i=1}^N\mathcal{L}\bigg(y_i, f_0(x_i)+\beta_1b(x_i, \gamma_1)\bigg) Loss=i=1∑NL(yi,f0(xi)+β1b(xi,γ1))
嗯,可以看到,我们在最开始的什么也没有的模型 f ( 0 ) f(0) f(0) 的基础上添加了一个模型 β 1 b ( x i , γ 1 ) \beta_1b(x_i, \gamma_1) β1b(xi,γ1)。
然后,我们把参数 β 1 \beta_1 β1 和 γ 1 \gamma_1 γ1 解出来,如下。em 因为在这里我们没有规定具体的损失函数,所以没法写具体的求解过程。
(提前剧透一下,改变这个损失函数,我们能够得到前向分步算法不同的特例,本篇的主角 adaboost 就是其一…啊不过这就是下一个话题了())
β 1 , γ 1 = arg min β , γ ∑ i = 1 N L ( y i , f 0 ( x i ) + β b ( x i , γ ) ) \beta_1, \gamma_1=\argmin_{\beta, \gamma}\sum_{i=1}^N\mathcal{L}\bigg(y_i, f_0(x_i)+\beta b(x_i, \gamma)\bigg) β1,γ1=β,γargmini=1∑NL(yi,f0(xi)+βb(xi,γ))
豪德,现在我们更新 f ( x ) f(x) f(x): f 1 ( x ) = f 0 ( x ) + β 1 b ( x i , γ 1 ) f_1(x)=f_0(x)+\beta_1b(x_i, \gamma_1) f1(x)=f0(x)+β1b(xi,γ1)。说白了就是,我们把新求解得到的模型加到最开始的什么也没有的模型上。(remember? “加法模型”。
then,我们再往下写一轮,然后你估计就明白啦!
现在我们已经得到 f 1 ( x ) f_1(x) f1(x) 了,接着我们要求解参数 β 2 , γ 2 \beta_2, \gamma_2 β2,γ2.
这次,我们的损失函数是:
Loss = ∑ i = 1 N L ( y i , f 1 ( x i ) + β 2 b ( x i , γ 2 ) ) \text{Loss}=\sum_{i=1}^N\mathcal{L}\bigg(y_i, f_1(x_i)+\beta_2b(x_i, \gamma_2)\bigg) Loss=i=1∑NL(yi,f1(xi)+β2b(xi,γ2))
和最开始的是一个道理,我们想要把新的模型加到已有的模型上,形成一个新的整体,并且最小化这个整体的损失函数。
eeaaa 加法模型顾名思义就是这样嘛,挨个加起来。
(有点 resnet 那味了,不过还不够 “正宗”,下一篇讲提升树会有更重的 resnet 味哈哈哈哈哈哈)
emm,然后,我们把这个求解得到的参数写一下:
β 2 , γ 2 = arg min β , γ ∑ i = 1 N L ( y i , f 1 ( x i ) + β b ( x i , γ ) ) \beta_2, \gamma_2=\argmin_{\beta, \gamma}\sum_{i=1}^N\mathcal{L}\bigg(y_i, f_1(x_i)+\beta b(x_i, \gamma)\bigg) β2,γ2=β,γargmini=1∑NL(yi,f1(xi)+βb(xi,γ))
嘿,我感觉你应该已经完全明白了!’
那么,对于第 m m m 个模型,它的参数 β m , γ m \beta_m, \gamma_m βm,γm 就可以写成:
β m , γ m = arg min β , γ ∑ i = 1 N L ( y i , f m − 1 ( x ) + β b ( x i , γ ) ) \beta_m, \gamma_m=\argmin_{\beta, \gamma}\sum_{i=1}^N\mathcal{L}\bigg(y_i, f_{m-1}(x)+\beta b(x_i, \gamma)\bigg) βm,γm=β,γargmini=1∑NL(yi,fm−1(x)+βb(xi,γ))
其实本质上就是每次在已有模型的基础上再添加一个模型,形成新的整体,并让这个整体的损失函数最小,以求出新加的模型的参数。
最终,在我们累加完了所有 M M M 个模型之后,我们就得到了最终的 f ( x ) f(x) f(x),这个结果可以用于近似 “一次性优化”,也就是求解 ∑ i = 1 N L ( y i , ∑ m = 1 M β m b ( x i , γ m ) ) \sum_{i=1}^N\mathcal{L}\bigg(y_i, \sum_{m=1}^{M}\beta_mb(x_i, \gamma_m)\bigg) ∑i=1NL(yi,∑m=1Mβmb(xi,γm)) 得到的结果,同时它大大减少了计算量。
在这里放一下我突然冒出来的想法:前向分步算法就像是把一个 1 ∗ n 1*n 1∗n 的行向量拆了再拼,拼成一个 n ∗ 1 n*1 n∗1 的列向量,其中每一行代表一个优化问题,每一列代表一对参数。(eeemmm 这是个很奇怪的说法,如果你感觉很绕,不用管它,希望我过一段时间之后再看这篇文章的时候能够想起来我现在是怎么想的(((但我又觉得其实这是个非常好的比喻)🤯
好耶!!这些就是前向分步算法的介绍啦!我感觉铺垫已经很充分了其实,接下来我们来看看,为什么说 adaboost 是前向分步算法的特例?从前向分步算法是怎么推出 adaboost 中的各个参数和它们的值的?
AdaBoost 特例
呃嗷嗷嗷(什么奇怪的拟声词/。。),在这一部分里,我们来回答上一部分末尾提出的问题——既然说 adaboost 是前向分步算法的特例,那它是怎么从前向分步算法推导出来的呢?
还是先放结论:当前向分步算法的损失函数为指数损失函数时,就是 adaboost 算法。
下面我们来一步步说明这件事情!
首先先说一下指数损失函数,公式如下:
L = exp ( − y i f ( x ) ) \mathcal{L}=\exp(-y_if(x)) L=exp(−yif(x))
其中 y i y_i yi 是正确的标签(1 或 -1), f ( x ) f(x) f(x) 是模型的输出。
现在我们假设,经过 m − 1 m-1 m−1 轮前向迭代,我们已经得到了 f m − 1 ( x ) f_{m-1}(x) fm−1(x),展开如下:
f m − 1 ( x ) = α 1 G 1 ( x ) + α 2 G 2 ( x ) + . . . + α m − 1 G m − 1 ( x ) f_{m-1}(x)=\alpha_1G_1(x)+\alpha_2G_2(x)+...+\alpha_{m-1}G_{m-1}(x) fm−1(x)=α1G1(x)+α2G2(x)+...+αm−1Gm−1(x)
按照前向分步模型的一般流程,我们现在要添加第 m m m 个模型了,它可以表示为:
α m G m ( x ) \alpha_mG_m(x) αmGm(x)
注意这里的表示和前向分步算法介绍那块的表述稍有不同,介绍那里我们写的是 β m b ( x , γ m ) \beta_mb(x,\gamma_m) βmb(x,γm),其中 γ m \gamma_m γm 为参数。
但是因为 adaboost 中的基学习器(决策树桩)是个非参数模型,所以我们在这里直接写成 G m ( x ) G_m(x) Gm(x),省略了参数部分,后面求解的时候也没有显式的数值优化求解参数的过程。
(emm 其实类似的我在上面已经说过一遍了,在那里我补充了回归问题的情况,在这里也是一样的,就不再展开叙述了。如果你忘记了或者感觉不太明白,可以回到上面看一看~)
那么,把这个新模型(基学习器)加到已有的模型 f m − 1 f_{m-1} fm−1 上,按照前向分步算法,我们得到了这一轮的优化问题:
α m , G m ( x ) = arg min α , G ∑ i = 1 N L ( y i , f m − 1 ( x ) + α G ( x ) ) \alpha_m, G_m(x)=\argmin_{\alpha, G}\sum_{i=1}^N\mathcal{L}\bigg(y_i, f_{m-1}(x)+\alpha G(x)\bigg) αm,Gm(x)=α,Gargmini=1∑NL(yi,fm−1(x)+αG(x))
嗯,我们规定函数 L \mathcal{L} L 为指数损失函数,那么这一轮的优化问题就是:
α m , G m ( x ) = arg min α , G ∑ i = 1 N exp [ − y i ( f m − 1 ( x ) + α G ( x ) ) ] \alpha_m, G_m(x)=\argmin_{\alpha, G}\sum_{i=1}^N\exp\bigg[-y_i\bigg(f_{m-1}(x)+\alpha G(x)\bigg)\bigg] αm,Gm(x)=α,Gargmini=1∑Nexp[−yi(fm−1(x)+αG(x))]
现在我们来对它做一些小小的变形…
a 其实非常简单(),我们按照 exp \exp exp 的计算方式把这个式子拆开:
α m , G m ( x ) = arg min α , G ∑ i = 1 N exp [ ( − y i f m − 1 ( x i ) ) + ( − y i α G ( x i ) ) ] = arg min α , G ∑ i = 1 N [ exp ( − y i f m − 1 ( x i ) ) exp ( − y i α G ( x i ) ) ] \alpha_m, G_m(x)=\argmin_{\alpha, G}\sum_{i=1}^N\exp\bigg[\bigg(-y_i f_{m-1}(x_i)\bigg)+\bigg(-y_i\alpha G(x_i)\bigg)\bigg]\\ =\argmin_{\alpha, G}\sum_{i=1}^N\bigg[\exp\bigg(-y_i f_{m-1}(x_i)\bigg)\exp\bigg(-y_i\alpha G(x_i)\bigg)\bigg] αm,Gm(x)=α,Gargmini=1∑Nexp[(−yifm−1(xi))+(−yiαG(xi))]=α,Gargmini=1∑N[exp(−yifm−1(xi))exp(−yiαG(xi))]
很简单的指数的运算法则。
接下来,我们把前面那个很长的 exp \exp exp 用 w m , i w_{m,i} wm,i 表示,即:
w ‾ m , i = exp ( − y i f m − 1 ( x i ) ) \overline{w}_{m,i}=\exp\bigg(-y_i f_{m-1}(x_i)\bigg) wm,i=exp(−yifm−1(xi))
我们发现, w m , i w_{m,i} wm,i 和整个优化问题无关,因为它已经是定值了。式子可以重写为:
arg min α , G ∑ i = 1 N w ‾ m , i exp ( − y i α G ( x i ) ) \argmin_{\alpha, G}\sum_{i=1}^N \overline{w}_{m,i}\exp\bigg(-y_i\alpha G(x_i)\bigg) α,Gargmini=1∑Nwm,iexp(−yiαG(xi))
不错,现在 exp \exp exp 里少了很多干扰项,只剩下我们要求的 α \alpha α 和 G ( x ) G(x) G(x) 了。
我们在这里停一下。
首先,我们看看 w ‾ m , i \overline{w}_{m,i} wm,i 的表达式,它等于 exp ( − y i α m − 1 G m − 1 ( x i ) ) \exp\bigg(-y_i\alpha_{m-1}G_{m-1}(x_i)\bigg) exp(−yiαm−1Gm−1(xi)).
你会发现,诶这怎么感觉和 adaboost 里的 w m , i w_{m,i} wm,i 没什么关系呀?
先别着急,往后看,样本权重这块的重点是它的更新公式,而不是它自己长什么样子。
(另外,注意,这里的 w ‾ \overline{w} w 上面有个短横线,注意区分o~)
继续继续,我们来最小化这个式子…
最小化这个式子是一件相对容易的事情,因为 α \alpha α 和 G ( x ) G(x) G(x) 之间没有关系,所以我们可以分别求解它们。
我们得到,使得整个式子最小的 G ( x ) G(x) G(x) 如下:
G m ( x ) = arg min G ∑ i = 1 N w ‾ m , i I ( y i ≠ G ( x i ) ) G_m(x)=\argmin_G\sum_{i=1}^N \overline{w}_{m, i} I(y_i \neq G(x_i)) Gm(x)=Gargmini=1∑Nwm,iI(yi=G(xi))
它就是让加权分类损失最小的模型。注意在求解 G ( x ) G(x) G(x) 的时候,我们不用考虑 α \alpha α,它对于求解而言只是一个常数。
其中 w m , i w_{m, i} wm,i 就是我们之前从 exp \exp exp 中提出去的那部分。
还是再强调一下,你可能会对这个结论的得出感觉有点困惑——怎么直接就得出模型了?都没有一个求解的过程吗?
well,这又回到了决策树桩是个非参数化模型这件事了,对于非参数化模型,我们没有一个显式的求解过程。如果你对这块依然感到困惑,我在这简单补充一个用平方损失作为损失函数的例子(此时得到的模型用于回归问题),这个或许会更好理解一点。
【注意,这部分可能有点 distract,可以跳过不看,或者最后再回来看】
当前向分步算法的损失函数为平方损失时,拟合的模型为回归模型的时候,即:
α m , G m ( x ) = arg min α , G ∑ i = 1 N ( y i − f m − 1 ( x i ) − α G ( x i ) ) 2 \alpha_m, G_m(x)=\argmin_{\alpha, G}\sum_{i=1}^N\bigg(y_i-f_{m-1}(x_i)-\alpha G(x_i)\bigg)^2 αm,Gm(x)=α,Gargmini=1∑N(yi−fm−1(xi)−αG(xi))2
嗯…在这个式子中,我们就可以通过梯度下降等数值优化方法来求最优权重 α \alpha α 和最优模型 G G G 了。
关于这个部分更详细的叙述…其实会在下一篇!!! 到时候再说吧!这里就不剧透太多了嘿嘿。
【插入部分结束,回到正题】
嗯,现在我们已经得到了 G m ( x ) G_m(x) Gm(x),接下来求解 α m \alpha_m αm。
arg min α , G ∑ i = 1 N w ‾ m , i exp ( − y i α G ( x i ) ) \argmin_{\alpha, G}\sum_{i=1}^N \overline{w}_{m,i}\exp\bigg(-y_i\alpha G(x_i)\bigg) α,Gargmini=1∑Nwm,iexp(−yiαG(xi))
我们可以把整个式子分成两部分: y i = G m ( x i ) y_i=G_m(x_i) yi=Gm(xi) 的部分和 y i ≠ G m ( x i ) y_i \neq G_m(x_i) yi=Gm(xi) 的部分。
展开写成:
∑ i = 1 N w ‾ m , i exp ( − y i α G ( x i ) ) = ∑ y i = G m ( x i ) w ‾ m , i e − α + ∑ y i ≠ G m ( x i ) w ‾ m , i e α \sum_{i=1}^N \overline{w}_{m,i}\exp\bigg(-y_i\alpha G(x_i)\bigg)=\sum_{y_i=G_m(x_i)}\overline{w}_{m,i}e^{-\alpha}+\sum_{y_i \neq G_m(x_i)}\overline{w}_{m,i}e^{\alpha} i=1∑Nwm,iexp(−yiαG(xi))=yi=Gm(xi)∑wm,ie−α+yi=Gm(xi)∑wm,ieα
上面的变形中,我们把 exp \exp exp 写成了 e e e,根据计算结果 1 或 -1 省略掉了 y i = G m ( x i ) y_i=G_m(x_i) yi=Gm(xi),符号被保留在了 α \alpha α 上。
我们再做一个恒等变形,因为所有的 e α e^\alpha eα 和 e − α e^{-\alpha} e−α 相对 ∑ \sum ∑ 而言都是常数(它们都不包含 i i i),我们可以直接把它们提出来;同时,写在 ∑ \sum ∑ 下面的 y i = G m ( x i ) , y i ≠ G m ( x i ) y_i=G_m(x_i), y_i \neq G_m(x_i) yi=Gm(xi),yi=Gm(xi) 也可以变成指示函数的形式,因为指示函数只有在条件成立时为 1,所以两者是等价的。具体公式如下:
above = e − α ∑ y i = G m ( x i ) w ‾ m , i + e α ∑ y i ≠ G m ( x i ) w ‾ m , i = e − α ∑ i = 1 N w ‾ m , i I ( y i = G ( x i ) ) + e α ∑ i = 1 N w ‾ m , i I ( y i ≠ G ( x i ) ) = e − α ( ∑ i = 1 N w ‾ m , i − ∑ i = 1 N w ‾ m , i I ( y i ≠ G ( x i ) ) ) + e α ∑ i = 1 N w ‾ m , i I ( y i ≠ G ( x i ) ) \text{above}=e^{-\alpha}\sum_{y_i=G_m(x_i)}\overline{w}_{m,i}+e^{\alpha}\sum_{y_i \neq G_m(x_i)}\overline{w}_{m,i}\\ =e^{-\alpha}\sum_{i=1}^N\overline{w}_{m,i}I(y_i=G(x_i))+e^{\alpha}\sum_{i=1}^N\overline{w}_{m,i}I(y_i \neq G(x_i))\\ =e^{-\alpha}\bigg(\sum_{i=1}^N\overline{w}_{m,i}-\sum_{i=1}^N\overline{w}_{m,i}I(y_i \neq G(x_i))\bigg)+e^{\alpha}\sum_{i=1}^N\overline{w}_{m,i}I(y_i \neq G(x_i))\\ above=e−αyi=Gm(xi)∑wm,i+eαyi=Gm(xi)∑wm,i=e−αi=1∑Nwm,iI(yi=G(xi))+eαi=1∑Nwm,iI(yi=G(xi))=e−α(i=1∑Nwm,i−i=1∑Nwm,iI(yi=G(xi)))+eαi=1∑Nwm,iI(yi=G(xi))
注意现在 G m ( x i ) G_m(x_i) Gm(xi) 已经是已知的了。接下来对 α \alpha α 求解偏导,所有 ∑ \sum ∑ 都可以看作常数(系数)。
emm 是不是感觉这个系数好像有点太长了()我们不如先用 A , B A, B A,B 代替,即原式变为:
e − α A + e α B e^{-\alpha}A+e^{\alpha}B e−αA+eαB
其中:
A = ∑ i = 1 N w ‾ m , i − ∑ i = 1 N w ‾ m , i I ( y i ≠ G ( x i ) ) , B = ∑ i = 1 N w ‾ m , i I ( y i ≠ G ( x i ) ) A=\sum_{i=1}^N\overline{w}_{m,i}-\sum_{i=1}^N\overline{w}_{m,i}I(y_i \neq G(x_i)),\ B=\sum_{i=1}^N\overline{w}_{m,i}I(y_i \neq G(x_i)) A=i=1∑Nwm,i−i=1∑Nwm,iI(yi=G(xi)), B=i=1∑Nwm,iI(yi=G(xi))
这下看着顺眼多了,求解偏导得到:
∂ ( e − α A + e α B ) ∂ α = − A e − α + B e α \frac{\partial(e^{-\alpha}A+e^{\alpha}B)}{\partial{\alpha}}=-Ae^{-\alpha}+Be^\alpha ∂α∂(e−αA+eαB)=−Ae−α+Beα
我们让这个偏导等于 0:
− A e − α + B e α = 0 → A e − α = B e α → A B = e α e − α = e 2 α -Ae^{-\alpha}+Be^\alpha=0 \\ \to Ae^{-\alpha}=Be^\alpha \\ \to \frac A B=\frac{e^\alpha}{e^{-\alpha}}=e^{2\alpha} −Ae−α+Beα=0→Ae−α=Beα→BA=e−αeα=e2α
我们最终要求的是 α \alpha α 的值,所以对两边同时以 e e e 为底取对数:
log A B = 2 α → α = 1 2 log A B \log\frac A B=2\alpha \\ \to \alpha=\frac 1 2 \log \frac A B logBA=2α→α=21logBA
嗯!! 这就是令原式偏导数为 0 得到的 α \alpha α 值!也就是最优的 α \alpha α 值啦!!(是不是还蛮简单的嘿嘿嘿)
我们把 A , B A, B A,B 带进去,得到:
α = 1 2 log ∑ i = 1 N w ‾ m , i − ∑ i = 1 N w ‾ m , i I ( y i ≠ G ( x i ) ) ∑ i = 1 N w ‾ m , i I ( y i ≠ G ( x i ) ) \alpha=\frac 1 2 \log \frac{\sum_{i=1}^N\overline{w}_{m,i}-\sum_{i=1}^N\overline{w}_{m,i}I(y_i \neq G(x_i))}{\sum_{i=1}^N\overline{w}_{m,i}I(y_i \neq G(x_i))} α=21log∑i=1Nwm,iI(yi=G(xi))∑i=1Nwm,i−∑i=1Nwm,iI(yi=G(xi))
eeeenn 快要结束了但还差一点()
我们把 log \log log 里的公式上下同除 ∑ i = 1 N \sum_{i=1}^N ∑i=1N,相当于做个归一化,很显然这不改变式子最终的值,即:
above = 1 2 log ∑ i = 1 N w ‾ m , i − ∑ i = 1 N w ‾ m , i I ( y i ≠ G ( x i ) ) ∑ i = 1 N w ‾ m , i ∑ i = 1 N w ‾ m , i I ( y i ≠ G ( x i ) ) ∑ i = 1 N w ‾ m , i = 1 2 log 1 − ∑ i = 1 N w ‾ m , i I ( y i ≠ G ( x i ) ) ∑ i = 1 N w ‾ m , i ∑ i = 1 N w ‾ m , i I ( y i ≠ G ( x i ) ) ∑ i = 1 N w ‾ m , i \text{above}=\frac 1 2 \log \frac{\frac{\sum_{i=1}^N\overline{w}_{m,i}-\sum_{i=1}^N\overline{w}_{m,i}I(y_i \neq G(x_i))}{\sum_{i=1}^N\overline{w}_{m,i}}}{\frac{\sum_{i=1}^N\overline{w}_{m,i}I(y_i \neq G(x_i))}{\sum_{i=1}^N\overline{w}_{m,i}}}\\ =\frac 1 2 \log \frac{1-\frac{\sum_{i=1}^N\overline{w}_{m,i}I(y_i \neq G(x_i))}{\sum_{i=1}^N\overline{w}_{m,i}}}{\frac{\sum_{i=1}^N\overline{w}_{m,i}I(y_i \neq G(x_i))}{\sum_{i=1}^N\overline{w}_{m,i}}} above=21log∑i=1Nwm,i∑i=1Nwm,iI(yi=G(xi))∑i=1Nwm,i∑i=1Nwm,i−∑i=1Nwm,iI(yi=G(xi))=21log∑i=1Nwm,i∑i=1Nwm,iI(yi=G(xi))1−∑i=1Nwm,i∑i=1Nwm,iI(yi=G(xi))
嗯,,,这个式子有点复杂,我们换个元:
e m = ∑ i = 1 N w ‾ m , i I ( y i ≠ G m ( x i ) ) ∑ i = 1 N w ‾ m , i = ∑ i = 1 N w m , i I ( y i ≠ G m ( x i ) ) e_m=\frac{\sum_{i=1}^N\overline{w}_{m,i}I(y_i\neq G_m(x_i))}{\sum_{i=1}^N\overline{w}_{m,i}}\\ =\sum_{i=1}^Nw_{m,i}I(y_i\neq G_m(x_i)) em=∑i=1Nwm,i∑i=1Nwm,iI(yi=Gm(xi))=i=1∑Nwm,iI(yi=Gm(xi))
e m e_m em 就等于原来的分数的分母和分子减号后面的部分。
这样的话,我们的权重 a m a_m am 就可以改写成:
a m = 1 2 log 1 − e m e m a_m = \frac 1 2 \log \frac{1-e_m}{e_m} am=21logem1−em
嘿!看到了吗?这和我们前面正向叙述那里写的一模一样!
好啊…总算是推出来了!!! 现在 e m e_m em 和 a m a_m am 我们都有啦!还剩下一个 w m , i w_{m,i} wm,i…
不过现在它就很好处理了。
回忆一下,前向分步算法的模型更新公式是什么来着?前面说过,每次都会把新求出来的模型加到前面已经得到的所有模型上,即:
f m ( x ) = f m − 1 ( x ) + α m G m ( x ) f_m(x)=f_{m-1}(x)+\alpha_mG_m(x) fm(x)=fm−1(x)+αmGm(x)
其中 α m \alpha_m αm 和 G m ( x ) G_m(x) Gm(x) 我们已经求出来了,和 adaboost 中是一样的形式。
我们之前,在一个有点远又不太远的地方得到了 w ‾ m , i = exp ( − y i f m − 1 ( x i ) ) \overline{w}_{m,i}=\exp(-y_i f_{m-1}(x_i)) wm,i=exp(−yifm−1(xi)),根据指数的运算法则,我们有:
exp ( f m ( x ) ) = exp ( f m − 1 ( x ) ) ∗ exp ( α m G m ( x ) ) → exp ( − y i f m ( x ) ) = exp ( − y i f m − 1 ( x ) ) ∗ exp ( − y i α m G m ( x ) ) → w ‾ m + 1 , i = w ‾ m , i exp ( − y i α m G m ( x ) ) \exp{(f_m(x))}=\exp{(f_{m-1}(x))}*\exp{(\alpha_mG_m(x))} \\ \to\exp{(-y_if_m(x))}=\exp{(-y_if_{m-1}(x))}*\exp{(-y_i\alpha_mG_m(x))} \\ \to \overline{w}_{m+1,i}=\overline{w}_{m,i}\exp{(-y_i\alpha_mG_m(x))} exp(fm(x))=exp(fm−1(x))∗exp(αmGm(x))→exp(−yifm(x))=exp(−yifm−1(x))∗exp(−yiαmGm(x))→wm+1,i=wm,iexp(−yiαmGm(x))
嘿!!! 这和 adaboost 算法中的样本权重更新公式几乎一样诶!
或者说,这和 adaboost 算法中的样本权重更新公式相差一个归一化,so 只要在两边同时归一化就可以了,两者是等价的!
这样的话,我们已经从前向分步算法推导出了 adaboost 中的 w m , a m , e m w_m, a_m,e_m wm,am,em 啦!
嗯!!现在我们已经完整地从前向分步算法推导出 adaboost 算法啦!完结撒花!!
总结
最后,我们来总结一下 adaboost 算法吧!
adaboost 算法属于 boosting 家族,通过加权组合多个弱学习器的方式进行决策,注重解决弱学习器高偏差的问题。
adaboost 在寻找新的基学习器时,会提高那些被上一个基学习器分类错误的样本的权重,迫使新的基学习器更关注这些样本。
在组合基学习器时,adaboost 会赋予那些性能较好的基学习器更高的权重。
adaboost 算法可以从前向分步算法推导得出,它是前向分步算法的损失函数为指数损失函数时的特殊情况。
嗯!! 核心内容就这些!!q(≧▽≦q)
放一张蛮不错的图作为结尾吧!
嘿嘿,那这一篇就到这里啦~~下一篇再见!下一篇我估计会讲梯度提升树 GBDT!!
这篇文章详解了 AdaBoost 算法,并从前向分步算法的角度给出了推导,希望对你有所帮助!⭐
欢迎三连!!一起加油!🎇
——Geeker_LStar
相关文章:
【高中生讲机器学习】25. AdaBoost 算法详解+推导来啦!
创建时间:2024-11-08 首发时间:2024-11-13 最后编辑时间:2024-11-13 作者:Geeker_LStar 你好呀~这里是 Geeker_LStar 的人工智能学习专栏,很高兴遇见你~ 我是 Geeker_LStar,一名高一学生,热爱计…...

第三十七章 Vue之编程式导航及跳转传参
目录 一、编程式导航跳转方式 1.1. path 路径跳转 1.1.1. 使用方式 1.1.2. 完整代码 1.1.2.1. main.js 1.1.2.2. App.vue 1.1.2.3. index.js 1.1.2.4. Home.vue 1.1.2.5. Search.vue 1.2. name 命名路由跳转 1.2.1. 使用方式 1.2.2. 完整代码 1.2.2.1. main.js 1…...

vue 版本升级
Vue 3.4 升级了组件产值方式 v-model ,果断升级玩玩,记录一下升级过程 我的原Vue版本是3.2.13 升级到目前最新3.5.12 1. npm add vuelatest 2. npm add -g vue/clilatest 安装完成后记得查看是否有如下警告 这个警告是说eslint-plugin-vue package…...

探索Copier:Python项目模板的革命者
文章目录 **探索Copier:Python项目模板的革命者**1. 背景介绍:为何Copier成为新宠?2. Copier是什么?3. 如何安装Copier?4. 简单库函数使用方法4.1 创建模板4.2 从Git URL创建项目4.3 使用快捷方式4.4 动态替换文本4.5 …...

云原生后端深度解析
云原生后端 云原生后端是指专门为云计算环境设计的软件架构和服务。它强调了应用程序的设计、开发、部署和运维的方式,以充分利用云平台提供的弹性、可伸缩性和自动化能力。云原生技术主要包括容器化、微服务、不可变基础设施、声明式APIs等核心概念。下面是对这些…...

本地 SSL 证书生成神器,自己创建SSL
本地 SSL 证书生成神器,自己创建SSL 在本地环境中配置HTTPS一直以来是开发者的痛点,手动创建SSL证书、配置信任存储不仅繁琐,还容易出错。今天给大家介绍一个开源神器——mkcert!它能让你快速生成本地受信任的SSL/TLS证书,轻松打造安全的HTTPS开发环境,成为许多开发者的首…...

HCIP-快速生成树RSTP
一、RSTP是什么 STP(Spanning Tree Protocol )是生成树协议的英文缩写。该协议可应用于环路网络,通过一定的算法实现路径冗余,同时将环路网络修剪成无环路的树型网络,从而避免报文在环路网络中的增生和无限循环。 RS…...

企业级RAG(检索增强生成)系统构建研究
— 摘要 检索增强生成(Retrieval-Augmented Generation,RAG)技术已经成为企业在知识管理、信息检索和智能问答等应用中的重要手段。本文将从RAG系统的现状、方法论、实践案例、成本分析、实施挑战及应对策略等方面,探讨企业如何…...

MATLAB基础应用精讲-【数模应用】Google Caffeine算法
目录 前言 算法原理 Caffeine算法的背景和优势 什么是Caffeine算法 Caffeine算法的工作原理 常见的缓存数据淘汰算法 FIFO LRU LFU W-TinyLFU Caffeine W-TinyLFU 实现 元素驱逐 元素访问 Caffeine 的四种缓存添加策略 1. 手动加载 2. 自动加载 3. 手动异步加载…...

第十九届中国国际中小企业博览会将在粤开展
11月15日-18日,第十九届中国国际中小企业博览会(简称“中博会”)将在广州广交会展馆举办,共设8个展厅,展位总数约2800个,将举办超过30场系列配套活动,35个国家(地区)和国…...

云计算在智能交通系统中的应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 云计算在智能交通系统中的应用 云计算在智能交通系统中的应用 云计算在智能交通系统中的应用 引言 云计算概述 定义与原理 发展历…...

b4tman / docker-squid 可快速安装运行的、容器型代理服务器 + podman
使用容器部署,省时省力。 使用镜像,目前的最大麻烦就是之前各大镜像源纷纷关闭,需要自己找到合适的、安全的镜像源。 幸好 docker-squid 推广在 ghcr.io,目前下载没有障碍。 注:ghcr.io 是 GitHub Container Registry …...

脉冲神经网络(Spiking Neural Network,SNN)学习(1)
目录 一、神经网络 1、神经元 2、激活函数 (1)常见的激活函数:Sigmoid函数 (2)常见的激活函数:ReLU(Rectified Linear Unit)函数 (3)常见的激活函数&…...

【疑难杂症】电脑休眠后无法开机,进入 steamVR 时电脑突然黑屏关机
问题描述 1.电脑休眠后无法启动,只能拔电源再启动 2.进入 steamVR 时,电脑突然断电黑屏关机(无蓝屏,无任何报错) 3.在进行渲染时,如R23等,电脑突然黑屏关机 4.进入 VRChat 时,准备进…...

HTML文件中引入jQuery的库文件
方法一: 1. 首先,在官方网站(https://jquery.com/)上下载最新版本的jQuery库文件,通常是一个名为jquery-x.x.x.min.js的文件。 2. 将下载的jquery-x.x.x.min.js文件保存到你的项目目录中的一个合适的文件夹中,比如将它保存在你的项…...

IntelliJ IDEA超详细下载安装教程(附安装包)
目录 IDEA的简单介绍一、下载IDEA二、安装IDEA三、启动IDEA并使用1.配置IDEA2.输出:"Hello World!" IDEA的简单介绍 IDEA 全称IntelliJ IDEA,是由 JetBrains 开发的一款广泛使用的集成开发环境(IDE)&#x…...

MySQL技巧之跨服务器数据查询:基础篇-更新语句如何写
MySQL技巧之跨服务器数据查询:基础篇-更新语句如何写 上一篇已经描述:借用微软的SQL Server ODBC 即可实现MySQL跨服务器间的数据查询。 而且还介绍了如何获得一个在MS SQL Server 可以连接指定实例的MySQL数据库的连接名: MY_ODBC_MYSQL 以及用同样的…...

期权懂|期权新手入门教学:期权合约有哪些要素?
期权小懂每日分享期权知识,帮助期权新手及时有效地掌握即市趋势与新资讯! 期权新手入门教学:期权合约有哪些要素? 期权合约:是指约定买方有权在将来某一时间以特定价格买入或卖出约定标的物的标准化或非标准化合约。期…...

腾讯云nginx SSL证书配置
本章教程,记录在使用腾讯云域名nginx证书配置SSL配置过程。 一、nginx配置 域名和证书,替换成自己的即可。证书文件可以自定义路径位置。服务器安全组或者防火墙需要开放80和443端口。 server {#SSL 默认访问端口号为 443listen 443 ssl; #请填写绑定证书的域名server_name c…...

重新认识HTTPS
一. 什么是 HTTPS HTTP 由于是明文传输,所谓的明文,就是说客户端与服务端通信的信息都是肉眼可见的,随意使用一个抓包工具都可以截获通信的内容。 所以安全上存在以下三个风险: 窃听风险,比如通信链路上可以获取通信…...

你的Linux启动慢?可能是UEFI这七个阶段在“摸鱼”!性能调优实战指南
Linux启动慢?UEFI七阶段性能调优实战指南当你的Linux系统启动速度像蜗牛爬行时,问题可能隐藏在UEFI启动的七个关键阶段中。本文将带你深入UEFI启动流程的每个环节,揭示可能导致延迟的"摸鱼"行为,并提供针对性的优化方案…...

3步快速上手SSDD:合成孔径雷达舰船检测终极指南
3步快速上手SSDD:合成孔径雷达舰船检测终极指南 【免费下载链接】Official-SSDD SAR Ship Detection Dataset (SSDD): Official Release and Comprehensive Data Analysis 项目地址: https://gitcode.com/gh_mirrors/of/Official-SSDD SSDD(SAR S…...
)
Flutter+React Native如何真正实现Lovable?跨端情感一致性开发规范(仅限内部团队流通版)
更多请点击: https://codechina.net 第一章:Lovable移动端应用开发 Lovable 是一套面向现代移动开发的轻量级跨平台框架,专为构建高响应、低资源占用且具备原生体验的应用而设计。它采用声明式 UI 编程模型,底层通过桥接机制与 i…...

孩子学英语怎么选择
需要一点点建议哦...

Linux-安装cmatrix
linux-安装cmatrix (黑客帝国矩阵效果) su root #切换身份到root不受权限控制 cd /usr/src #进入源码下载位置,准备下载安装包利用xftp 共享传送文件进入home找到文件,cp 文件 /usr/src解压,进…...

HTML应用指南:利用GET请求获取智己汽车门店位置信息
智己汽车作为高端智能电动汽车品牌,深度融合先锋设计美学、纯电驱动技术、高阶智能驾驶与全场景出行服务,依托L7、LS7、LS6、L6等产品矩阵,打造兼具科技感与驾控乐趣的高端出行体验。在营销推广层面,智己摒弃传统4S店模式…...

鸿蒙electron跨端框架PC简序实战:把轻任务、优先级和截止时间塞进一张桌面清单
前言 欢迎加入鸿蒙PC开发者社区,共同打造开发者工具生态:鸿蒙PC开发者社区 :https://harmonypc.csdn.net/ 开源地址:https://AtomGit.com/lqjmac/ele-shixu?source_modulesearch_project 写 简序 时,我没有把它当成…...

STM32F4电池电量监测实战:用HAL库和ADC DMA,从硬件分压到软件滤波全流程解析
STM32F4电池电量监测实战:从硬件设计到软件滤波的工程化实现 在物联网设备和便携式电子产品的开发中,精确监测电池电量是一个看似简单却暗藏玄机的关键技术点。许多开发者都曾遇到过这样的困境:实验室测试时电量显示精准稳定,一旦…...

Python之streamjam包语法、参数和实际应用案例
Python StreamJam 包完整使用指南 一、StreamJam 包核心概述 StreamJam 是 Python 中一款轻量级、高性能的流式数据处理工具包,专为实时数据流、增量数据处理、管道式数据转换、异步/同步流处理设计,核心定位是替代复杂的大数据框架(如Spark、…...

基于RK平台的智慧出行方案:从芯片选型到车规级开发的实战指南
1. 项目概述:当“智慧出行”遇上“RK平台”最近几年,如果你关注汽车电子或者物联网领域,一定对“智慧出行”这个词不陌生。它早已不是科幻电影里的概念,而是真真切切地走进了我们的生活,从智能座舱里流畅的语音交互、多…...