论文笔记 SuDORMRF:EFFICIENT NETWORKS FOR UNIVERSAL AUDIO SOURCE SEPARATION
SUDORMRF: EFFICIENT NETWORKS FOR UNIVERSAL AUDIO SOURCE SEPARATION
人的精神寄托可以是音乐,可以是书籍,可以是运动,可以是工作,可以是山川湖海,唯独不可以是人。
Depthwise Separable Convolution 深度分离卷积(前置知识)
相比于常规卷积,可以减少参数和计算量。分为两步:
- Depthwise Convolution (DW) 深度卷积:每个卷积核只处理一个输入通道(卷积核深度均为1)。因此输入特征的通道数不变。
- Pointwise Convolution (PW) 逐点卷积:卷积核尺寸为 1 × 1 1 \times 1 1×1,输入特征的尺寸不变。
我们以input feature map shape为 [ 12 , 12 , 3 ] ∈ R H × W × C [12,12,3] \in R^{H \times W \times C} [12,12,3]∈RH×W×C,卷积核shape为 [ 5 , 5 , 3 ] ∈ R k h × k w × C [5,5,3] \in R^{k_h \times k_w \times C} [5,5,3]∈Rkh×kw×C, stride = 1, padding = 0,卷积核数量为256(输出通道数为256),output feature map shape为 [ 8 , 8 , 256 ] [8,8,256] [8,8,256]的情况为例。
- 常规卷积中,卷积核的参数量: C in × C out × k h × k w C_\text{in} \times C_\text{out} \times k_\text{h} \times k_\text{w} Cin×Cout×kh×kw
计算量(FlOPs): C in × C out × k h × k w × O h × O w C_\text{in} \times C_\text{out} \times k_\text{h} \times k_\text{w} \times O_\text{h} \times O_\text{w} Cin×Cout×kh×kw×Oh×Ow
其中 O h × O w O_\text{h} \times O_\text{w} Oh×Ow为output feature map的高 × \times ×宽, k h × k w k_\text{h} \times k_\text{w} kh×kw为卷积核对应尺寸。(对于PW,DW而言,计算公式稍有变化)
- 采用常规卷积:
- 参数量: 3 × 256 × 5 × 5 = 19200 3 \times 256 \times 5 \times 5 = 19200 3×256×5×5=19200
- FLOPs: 3 × 256 × 5 × 5 × 8 × 8 = 1228800 3 \times 256 \times 5 \times 5 \times 8 \times 8 = 1228800 3×256×5×5×8×8=1228800
- 采用Depthwise Separable Convolution:
将 [ 5 , 5 , 3 ] × 256 [5,5,3] \times 256 [5,5,3]×256的卷积层拆分为两个卷积层,先后经过两层卷积以完成同样的维度转换效果:- DW: [ 5 , 5 , 1 ] × 3 [5,5,1] \times 3 [5,5,1]×3
- PW: [ 1 , 1 , 3 ] × 256 [1,1,3] \times 256 [1,1,3]×256
- 参数量:DW: 1 × 3 × 5 × 5 1 \times 3 \times 5 \times 5 1×3×5×5(这里不是 C in C_\text{in} Cin,因为每个卷积核只负责一个通道,即卷积核深度为1);PW: 3 × 256 × 1 × 1 3 \times 256 \times 1 \times 1 3×256×1×1。总计为:843
- FLOPs: 1 × 3 × 5 × 5 × 8 × 8 + 3 × 256 × 1 × 1 × 8 × 8 = 53952 1 \times 3 \times 5 \times 5 \times 8 \times 8 + 3 \times 256 \times 1 \times 1 \times 8 \times 8 = 53952 1×3×5×5×8×8+3×256×1×1×8×8=53952。(分两步卷积,先DW后PW)
2.Methodology
Overall Architecture
整体算法流程如下:

定义输入输出尺寸
x ∈ R T \mathbf{x}\in\mathbb{R}^T x∈RT为混合音频信号, E \mathcal{E} E为Encoder,对输入 x \mathbf{x} x处理得到特征向量: v x = E ( x ) ∈ R C ε × L \mathbf{v}_{\mathbf{x}}=\mathcal{E}\left(\mathbf{x}\right)\in\mathbb{R}^{C_{\mathbf{\varepsilon}}\times L} vx=E(x)∈RCε×L。将 v x \mathbf{v}_{\mathbf{x}} vx送入Separation Module S S S当中得到 m ^ i ∈ R C ε × L \hat{\mathbf{m}}_i\in\mathbb{R}^{C_{\mathcal{\varepsilon}}\times L} m^i∈RCε×L为第 i i i个音源的mask, i = 1 , 2 , ⋯ , N i = 1,2,\cdots,N i=1,2,⋯,N。假设共有 N N N个音源产生的音频信号 s 1 , s 2 , ⋯ , s N ∈ R T \mathbf{s}_1,\mathbf{s}_2,\cdots,\mathbf{s}_N \in \mathbb{R}^T s1,s2,⋯,sN∈RT共同组成 x \mathbf{x} x。将 v x \mathbf{v}_{\mathbf{x}} vx与 m i ^ \hat{\mathbf{m}_i} mi^逐项相乘得到第 i i i音源的特征向量 v i ^ \hat{\mathbf{v}_i} vi^:
v i ^ = v x ⊙ m i ^ \hat{\mathbf{v}_i} = \mathbf{v}_{\mathbf{x}} \odot \hat{\mathbf{m}_i} vi^=vx⊙mi^
再经过解码器 D \mathcal{D} D得到 s ^ i = D ( v i ^ ) \hat{\mathbf{s}}_i = \mathcal{D}(\hat{\mathbf{v}_i}) s^i=D(vi^)
-
定义1: Conv1D C , K , S : R C i n × L i n → R C × L \text{Conv1D}_{C, K, S}: \mathbb{R} ^{C_{in}\times L_{in}}\to \mathbb{R} ^{C\times L} Conv1DC,K,S:RCin×Lin→RC×L。表示一维常规卷积。将输入shape从 R C i n × L i n \mathbb{R} ^{C_{in}\times L_{in}} RCin×Lin转为 R C × L \mathbb{R} ^{C\times L} RC×L。其中 C C C为output channel, S S S为stride, K K K为kernel size,L为尺度(时间)。
-
定义2: ConvTr1D C , K , S : R C i n × L i n → R C × L \text{ConvTr1D}_{C, K, S}: \mathbb{R} ^{C_{in}\times L_{in}}\to \mathbb{R} ^{C\times L} ConvTr1DC,K,S:RCin×Lin→RC×L。转置卷积。需要注意的一点是,转置卷积的运算过程,相当于原卷积核对input求梯度(具体过程参看参考链接)。
-
定义3: DWConv1D C , K , S : R C i n × L i n → R C × L \text{DWConv1D}_{C, K, S}: \mathbb{R} ^{C_{in}\times L_{in}}\to \mathbb{R} ^{C\times L} DWConv1DC,K,S:RCin×Lin→RC×L。一维Depthwise Convolution深度卷积。
本质是将原始卷积层拆分成 G = C in G = C_\text{in} G=Cin 个Conv1D: F ^ i = [ Conv1D C G , K , S ] i \hat{\mathcal{F}} _i= [\text{Conv1D} _{C_G, K, S}] _i F^i=[Conv1DCG,K,S]i,其中 i ∈ { 1 , ⋯ , G } , C G = [ C / G ] i\in \{ 1, \cdots , G\},C_G = [C / G] i∈{1,⋯,G},CG=[C/G]。每一个卷积核 F ^ \hat{\mathcal{F}} F^对输出贡献 C G C_G CG个通道。最终将 { F ^ i ∣ i = 1 , 2 , ⋯ , G } \{\hat{\mathcal{F}}_i | i = 1,2,\cdots,G \} {F^i∣i=1,2,⋯,G}的输出结果按通道拼接:
D W C o n v 1 D C , K , S ( x ) = C o n c a t ( { F i ( x i ) , ∀ i } ) , (2) \mathrm{DWConv}1\mathrm{D}_{C,K,S}\left(\mathbf{x}\right)=\mathrm{Concat}\left(\left\{\mathcal{F}_i\left(\mathbf{x}_i\right), \forall i\right\}\right),\tag2 DWConv1DC,K,S(x)=Concat({Fi(xi),∀i}),(2)
Concat ( ⋅ ) \text{Concat}(\cdot) Concat(⋅)表示拼接。
2.1 Encoder
Encoder用 E \mathcal{E} E表示,包含一个一维卷积,kernel size为 K E K_{\mathcal{E}} KE, stride为 K E / 2 K_{\mathcal{E}}/2 KE/2,使用公式表示Encoder的具体操作如下:
v x = E ( x ) = R e L U ( C o n v 1 D C E , K E , K E / 2 ( x ) ) ∈ R C E × L (3) \mathbf{v}_{\mathbf{x}}=\mathcal{E}\left(\mathbf{x}\right)=\mathrm{ReLU}\left(\mathrm{Conv}1\mathrm{D}_{C_{\mathcal{E}},K_{\mathcal{E}},K_{\mathcal{E}/2}}\left(\mathbf{x}\right)\right)\in\mathbb{R}^{C_{\mathcal{E}}\times L} \tag3 vx=E(x)=ReLU(Conv1DCE,KE,KE/2(x))∈RCE×L(3)
其中ReLU为逐项激活, C E C_{\mathcal{E}} CE为Encoder的输出通道数。
2.2 分离模块
分离模块 S S S将 v x \mathbf{v}_x vx做以下处理
-
使用LN和Pointwise Conv将 v x \mathbf{v}_x vx映射到新的通道空间当中:
y 0 = C o n v 1 D C , 1 , 1 ( L N ( v x ) ) ∈ R C × L (4) \mathbf{y}_0=\mathrm{Conv}1\mathrm{D}_{C,1,1}\left(\mathrm{LN}\left(\mathbf{v}_\mathbf{x}\right)\right)\in\mathbb{R}^{C\times L} \tag4 y0=Conv1DC,1,1(LN(vx))∈RC×L(4)LN ( v x ) \text{LN}(\mathbf{v_x}) LN(vx)为layer-norm layer。
-
使用多个BU-convolutional blocks(U-ConvBlocks)拼接在一起。其中第 i i i个Block的输出作为第 i + 1 i+1 i+1个Block的输入。U-ConvBlock的具体细节参考Sec2.2.1,类似TDA-Net和U-Net,利用了多尺度信息,Block输入输出尺度一致。
-
使用最后的Block输出 y B T ∈ R L × C \mathbf{y}_B^T\in\mathbb{R}^{L\times C} yBT∈RL×C,针对每一个音源设置一个Conv1D层,以得到对应音源的中间特征向量 z i \mathbf{z}_i zi(比如有N个音源,则对应N个Conv1D,随后使用 z i \mathbf{z}_i zi获得 m i ^ \hat{\mathbf{m}_i} mi^):
z i = Conv 1 D C , C E , 1 ( y B T ) T ∈ R C E × L (5) \mathbf{z}_i=\text{Conv}1\text{D}_{C,C_{\mathcal{E}},1}\left(\mathbf{y}_B^T\right)^T\in\mathbb{R}^{C_{\mathcal{E}}\times L} \tag5 zi=Conv1DC,CE,1(yBT)T∈RCE×L(5)
其中 y B T \mathbf{y}_B^T yBT表示 y B \mathbf{y}_B yB的转置。 -
使用 z i \mathbf{z}_i zi 求解 m i ^ \hat{\mathbf{m}_i} mi^:
m ^ i = v e c − 1 ( exp ( v e c ( z i ) ) ∑ j = 1 N exp ( v e c ( z j ) ) ) ∈ R C E × L (6) \hat{\mathbf{m}}_i=\mathrm{vec}^{-1}\left(\frac{\exp\left(\mathrm{vec}\left(\mathbf{z}_\mathrm{i}\right)\right)}{\sum_{j=1}^N\exp\left(\mathrm{vec}\left(\mathbf{z}_j\right)\right)}\right)\in\mathbb{R}^{C_{\mathcal{E}}\times L} \tag6 m^i=vec−1(∑j=1Nexp(vec(zj))exp(vec(zi)))∈RCE×L(6)
其中 m ^ i ∈ [ 0 , 1 ] C E × L \hat{\mathbf{m}}_{i} \in [0,1]^{C_{\mathcal{E}}\times L} m^i∈[0,1]CE×L。 vec ( ⋅ ) : R K × N → R K ⋅ N \left ( \cdot \right ) : \mathbb{R} ^{K\times N}\to \mathbb{R} ^{K\cdot N} (⋅):RK×N→RK⋅N,表示向量化。 v e c − 1 ( ⋅ ) : R K ⋅ N → \mathrm{vec}^{- 1}\left ( \cdot \right ) : \mathbb{R} ^{K\cdot N}\to vec−1(⋅):RK⋅N→ R K × N \mathbb{R}^{K\times N} RK×N表示反向量化。可以发现,对于所有mask的同一位置,求和为1:
∑ i N m i ^ ( x , y ) = 1 \sum\limits_i^N {\hat{\mathbf{m_{i}}}_{ (x,y)}} = 1 i∑Nmi^(x,y)=1
其中 ( x , y ) (x,y) (x,y)表示mask的某个元素的坐标。
- 利用 m ^ i \hat{\mathbf{m}}_i m^i以及特征向量 v x \mathbf{v}_x vx得到每个音源的特征向量 v ^ i \hat{\mathbf{v}}_i v^i:
v ^ i = v x ⊙ m ^ i ∈ R C E × L (7) \hat{\mathbf{v}}_i=\mathbf{v}_\mathbf{x} \odot \hat{\mathbf{m}}_i\in\mathbb{R}^{C_{\mathcal{E}}\times L} \tag7 v^i=vx⊙m^i∈RCE×L(7)
2.2.1 U-ConvBlock
U-ConvBlock整体架构与算法流程如下图所示:


整体而言与U-Net类似,但与TDA-Net更相似,也是连续的下采样,上采样。
-
定义4: P R e L U C : R C × L → R C × L \mathrm{PReLU}_C:\mathbb{R}^{C\times L}\to\mathbb{R}^{C\times L} PReLUC:RC×L→RC×L。(parametric
rectified linear unit):
P R e L U C ( y ) i , j = max ( 0 , y i , j ) + a i ⋅ min ( 0 , y i , j ) (8) \mathrm{PReLU}_C\left(\mathbf{y}\right)_{i,j}=\max\left(0,\mathbf{y}_{i,j}\right)+\mathbf{a}_i \cdot \min\left(0,\mathbf{y}_{i,j}\right) \tag8 PReLUC(y)i,j=max(0,yi,j)+ai⋅min(0,yi,j)(8)
a i \mathbf{a}_i ai为可学习的参数, y \mathbf{y} y为输入。 -
定义5: I M : R C × L → R C × M ⋅ L \mathcal{I}_M:\mathbb{R}^{C\times L}\to\mathbb{R}^{C\times M\cdot L} IM:RC×L→RC×M⋅L。上采样操作,最邻近插值, M M M为缩放系数。
2.3 Decoder
D \mathcal{D} D表示Decoder,将 v ^ i \hat{\mathbf{v}}_i v^i转换到时域空间当中,以得到最终的音频分离结果:
s ^ i = D i ( v ^ i ) = ConvTr 1 D C E , K E , K E / 2 ( v ^ i ) \hat{\mathbf{s}}_i=\mathcal{D}_i\left(\hat{\mathbf{v}}_i\right)=\text{ConvTr}1\text{D}_{C_{\mathcal{E}},K_{\mathcal{E}},K_{\mathcal{E}/2}}\left(\hat{\mathbf{v}}_i\right) s^i=Di(v^i)=ConvTr1DCE,KE,KE/2(v^i)
参考链接
- 【PyTorch】卷积层、池化层梯度计算 https://blog.csdn.net/weixin_44246009/article/details/119379516
- 卷积神经网络-转置卷积 https://blog.csdn.net/weixin_38498942/article/details/106824520
相关文章:
论文笔记 SuDORMRF:EFFICIENT NETWORKS FOR UNIVERSAL AUDIO SOURCE SEPARATION
SUDORMRF: EFFICIENT NETWORKS FOR UNIVERSAL AUDIO SOURCE SEPARATION 人的精神寄托可以是音乐,可以是书籍,可以是运动,可以是工作,可以是山川湖海,唯独不可以是人。 Depthwise Separable Convolution 深度分离卷积&a…...

机器学习系列----KNN分类
目录 前言 一.KNN算法的基本原理 二.KNN分类的实现 三.总结 前言 在机器学习领域,K近邻算法(K-Nearest Neighbors, KNN)是一种非常直观且常用的分类算法。它是一种基于实例的学习方法,也被称为懒学习(Lazy Learnin…...

贪心算法day 06
1.最长回文串 链接:. - 力扣(LeetCode) 思路:计算每个字符个数如果是偶数个那么肯定可以组成回文串,如果是奇数个就会有一个无法组成回文串,但是在最中间还是可以有一个不是成队的字符这个字符就从多的奇…...

HTML之列表学习记录
练习题: 图所示为一个问卷调查网页,请制作出来。要求:大标题用h1标签;小题目用h3标签;前两个问题使用有序列表;最后一个问题使用无序列表。 代码: <!DOCTYPE html> <html> <he…...

Redo与Undo的区别:数据库事务的恢复与撤销机制
在数据库中,redo 和 undo 是两个非常重要的概念,它们主要用于事务管理和恢复机制,确保数据的一致性和完整性。 下面分别解释这两个概念: Redo(重做) 定义:redo 操作记录了事务对数据库所做的所…...

【话题讨论】AI赋能电商:创新应用与销售效率的双轮驱动
目录 引言 一、AI技术在电商中的创新应用 1.1 购物推荐 1.2 会员分类 1.3 商品定价 1.4 用户体验 总结 二、AI技术提高电商平台销售效率 2.1 订单处理 2.2 物流配送 2.3 产品流转效率 2.4 库存管理和订单管理效率 2.5 实际案例分析 三、挑战和未来发展趋势 3.1…...

重构开发之道,Blackbox.AI为技术注入智能新动力
本文目录 一、引言二、Blackbox.AI实战体验2.1 基于网页界面生成前端代码进行应用开发2.2 与AI助手实现实时智能对话2.3 重塑大型文件交互方式2.4 链接Github仓库进行对话编程 三、总结 一、引言 在生产力工具加速进化的浪潮中,Blackbox.AI开始崭露头角,…...

机器学习在医疗健康领域的应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 机器学习在医疗健康领域的应用 机器学习在医疗健康领域的应用 机器学习在医疗健康领域的应用 引言 机器学习概述 定义与原理 发展…...

M芯片Mac构建Dockerfile - 注意事项
由于MacBook的M芯片架构与intel不同,交叉构建Linux服务器docker镜像,需要以下步骤完成: 编写好Dockerfile在命令行中,执行构建命令: docker buildx build --platform linux/amd64 -t ${image_name}:${tag} ....

系统架构设计师论文
软考官网:中国计算机技术职业资格网 (ruankao.org.cn) 2019年 2019年下半年试题二:论软件系统架构评估及其应用...

速盾:CDN 和高防有什么区别?
在网络安全和性能优化领域,CDN(Content Delivery Network,内容分发网络)和高防服务是两个重要的概念,它们在功能、原理和应用场景方面存在诸多区别。 一、CDN (一)基本原理与功能 内容加速分发…...

goframe开发一个企业网站 rabbitmq队例15
RabbitMQ消息队列封装 在目录internal/pkg/rabbitmq/rabbitmq.go # 消息队列配置 mq:# 消息队列类型: rocketmq 或 rabbitmqtype: "rabbitmq"# 是否启用消息队列enabled: truerocketmq:nameServer: "127.0.0.1:9876"producerGroup: "myProducerGrou…...

设计模式-七个基本原则之一-迪米特法则 + 案例
迪米特法则:(LoD) 面向对象七个基本原则之一 只与直接的朋友通信:对象应只与自己直接关联的对象通信,例如:方法参数、返回值、创建的对象。避免“链式调用”:尽量避免通过多个对象链进行调用。例如,a.getB().getC().do…...

【数学二】线性代数-二次型
考试要求 1、了解二次型的概念, 会用矩阵形式表示二次型,了解合同变换与合同矩阵的概念. 2、了解二次型的秩的概念,了解二次型的标准形、规范形等概念,了解惯性定理,会用正交变换和配方法化二次型为标准形。 3、理解正定二次型、正定矩阵的概念,并掌握其判别法. 二次型…...

320页PDF | 集团IT蓝图总体规划报告-德勤(限免下载)
一、前言 这份报告是集团IT蓝图总体规划报告-德勤。在报告中详细阐述了德勤为某集团制定的全面IT蓝图总体规划,包括了集团信息化目标蓝图、IT应用规划、数据规划、IT集成架构、IT基础设施规划以及IT治理体系规划等关键领域,旨在为集团未来的信息化发展提…...
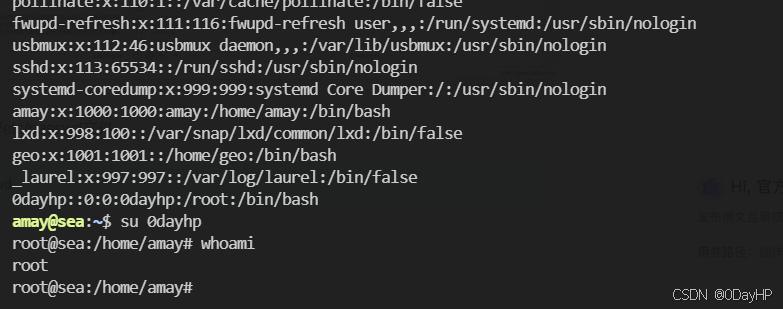
HTB:Sea[WriteUP]
目录 连接至HTB服务器并启动靶机 使用nmap对靶机TCP端口进行开放扫描 使用curl访问靶机80端口 使用ffuf对靶机进行了一顿FUZZ 尝试在Github上搜索版权拥有者 除了LICENSE还FUZZ出了version文件尝试访问 尝试直接在Github搜索该符合该版本的EXP 横向移动 使用john对该哈…...

Java 网络编程(一)—— UDP数据报套接字编程
概念 在网络编程中主要的对象有两个:客户端和服务器。客户端是提供请求的,归用户使用,发送的请求会被服务器接收,服务器根据请求做出响应,然后再将响应的数据包返回给客户端。 作为程序员,我们主要关心应…...

ECharts图表图例8
用eclipse软件制作动态单仪表图 用java知识点 代码截图:...

Redis中的线程模型
Redis 的单线程模型详解 Redis 的“单线程”模型主要指的是其 主线程,这个主线程负责从客户端接收请求、解析命令、处理数据和返回响应。为了深入了解 Redis 单线程的具体工作流程,我们可以将其分为以下几个步骤: 接收客户端请求 Redis 的主线…...

[产品管理-77]:技术人需要了解的常见概念:科学、技术、技能、产品、市场、商业模式、运营
目录 一、概念定义 科学 技术 技能 产品 市场 商业模式 运营 二、上述概念在产品创新中的作用 一、概念定义 对于技术人来说,了解并掌握科学、技术、技能、产品、市场、商业模式、运营等常见概念的定义至关重要。以下是这些概念的详细解释: 科…...

线性回归实战指南:从建模直觉到生产部署
1. 线性回归:不是公式堆砌,而是建模思维的起点 你打开一份销售数据表,发现广告投入每增加1万元,销售额平均涨了8.3万元;你翻看房屋成交记录,发现面积每多10平方米,总价大概多出65万元࿱…...

诸侯割据:不是只有坏处——有些阶段,它是“必要的恶”
在主流的管理话语里,“诸侯割据”几乎是个贬义词。它让人联想到山头主义、资源内耗、总部失控。但有没有一种可能:它在某些阶段、某些条件下,恰恰是企业活下去、长起来的“必要代价”? 一、先看好处:诸侯式架构的“四…...

萨科微宋仕强“华强北山寨手机”研究
萨科微宋仕强“华强北山寨手机”研究(十六),手机的灰色产业链。华强北每个手机柜台背后都有灰色供应链支撑。如香港手机比华强北便宜,就通过各种渠道从香港走私过来。沙头角的中英街两边分属于香港和深圳,香港一侧的走…...

如何快速搭建个人游戏串流服务器:Sunshine跨平台游戏流媒体完整指南
如何快速搭建个人游戏串流服务器:Sunshine跨平台游戏流媒体完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上畅玩PC游戏?Sunshine游…...
)
5G通信实战:手把手教你用Vivado LDPC IP核配置编码参数(附避坑指南)
5G通信实战:FPGA开发中的LDPC编解码参数配置全解析 在5G通信系统的开发过程中,LDPC(低密度奇偶校验)码作为物理层的关键技术之一,其实现质量直接影响着系统的传输性能和可靠性。对于使用Xilinx FPGA进行5G基带开发的工…...

G-Helper完整指南:轻量级华硕笔记本控制工具终极教程
G-Helper完整指南:轻量级华硕笔记本控制工具终极教程 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exp…...
 全解析|≤68kg 单个包装件部分模拟运输测试标准)
ISTA 2A-2011 (2022) 全解析|≤68kg 单个包装件部分模拟运输测试标准
前言ISTA 2A-2011 (2022) 属于 ISTA 2 系列部分模拟性能测试,专门针对重量不大于 68kg(150lb)的单个运输包装件设计,是中小型产品包装最常用的入门级运输验证标准。该标准通过温湿度、堆码压力、振动、冲击等测试模块,…...
解码器,但是没有安装)
ubuntu 播放器 播放此文件需要H.264(high profile)解码器,但是没有安装
解决方法: sudo apt install gstreamer1.0-plugins-bad gstreamer1.0-libav...

DazToBlender:3D创作工作流的无缝桥梁
DazToBlender:3D创作工作流的无缝桥梁 【免费下载链接】DazToBlender Daz to Blender Bridge 项目地址: https://gitcode.com/gh_mirrors/da/DazToBlender 在3D数字创作的世界里,艺术家们常常面临一个现实困境:如何在不同的专业软件之…...

QQ音乐格式转换终极指南:如何3步将.qmc文件转为MP3/FLAC
QQ音乐格式转换终极指南:如何3步将.qmc文件转为MP3/FLAC 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾在QQ音乐下载了心爱的歌曲,却发现它…...