【 LLM论文日更|检索增强:大型语言模型是强大的零样本检索器 】
- 论文:https://aclanthology.org/2024.findings-acl.943.pdf
- 代码:GitHub - taoshen58/LameR
- 机构:悉尼科技大学 & 微软 & 阿姆斯特丹大学 & 马里兰大学
- 领域:retrieval & llm
- 发表:ACL2024

研究背景
- 研究问题:这篇文章要解决的问题是如何在零样本场景下利用大型语言模型(LLM)进行大规模检索。具体来说,作者提出了一种简单的方法,称为“大型语言模型作为检索器”(LameR),通过将查询与其潜在答案候选结合,提升零样本检索的性能。
- 研究难点:该问题的研究难点包括:自监督检索器的性能较弱,导致整个流程瓶颈;直接将LLM与自监督检索器结合会产生大量无关或域外的答案,降低查询增强的效果。
- 相关工作:该问题的研究相关工作有:Yu等人提出的生成-读取管道;Dai等人提出的少样本密集检索方法;Dua等人提出的领域适应数据增强方法;Gao等人提出的基于假设文档嵌入(HyDE)的零样本密集检索方法;Jeronymo等人利用微调排序器过滤LLM生成数据的少样本方法;Saad-Falcon等人设计的两阶段LLM管道;Wang等人利用少样本查询-文档示例生成新查询的方法。
研究方法
这篇论文提出了“大型语言模型作为检索器”(LameR)用于解决零样本大规模检索问题。具体来说,
- 非参数词典检索:首先,作者采用BM25方法进行大规模检索。BM25的核心思想是根据查询词和文档之间的词汇频率和逆文档频率对文档进行排序。其相关性评分公式如下:

- 其中,t表示查询词中的词典词,TF(t,d)表示t在文档d中的词频,IDF(t)表示词t的逆文档频率,N是集合中的文档总数,n(t)是包含词t的文档数,len(d)是文档d的长度,avgdl是集合中文档的平均长度。
- 候选答案生成:其次,作者提出了一种新的提示模式,称为候选答案生成,用于大规模检索中的查询增强。具体步骤如下:
-
通过检索器获取查询q的前M个候选答案Cq。
-
将这些候选答案与查询q结合,构成提示p(t,q,Cq),然后调用LLM生成答案Aq
-

-
-
- 生成多个答案以防止“词汇不匹配”问题。

- 答案增强的大规模检索:最后,作者使用生成的答案AqAq来增强查询qq,生成新的查询qˉ,并进行大规模检索。具体步骤如下:
-
将每个生成的答案aqaq与原查询qq连接,形成增强查询qˉqˉ。
-
公式如下:
-

实验设计
- 数据集和指标:作者使用了MS-MARCO和TREC深度学习2019/2020测试集(分别记为DL19和DL20)以及BEIR基准中的六个低资源任务数据集。评估指标包括MAP、nDCG@10和Recall@1000(R@1k)。
- 实验设置:默认使用gpt-3.5-turbo作为LLM进行答案生成,候选答案数量M设为10,生成的答案数量N设为5。查询和文档被截断为128个令牌。
- 基线和竞争者:主要基线包括不使用标注查询-文档对的检索方法(即零样本设置),如BM25和Contriever。竞争者包括HyDE和少样本相关判断的Q2DBM25方法。此外,还包括一些全监督检索模型,如DPR和ANCE。
结果与分析
-
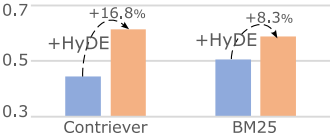
DL19和DL20测试集:在TREC深度学习2019和2020测试集中,LameR在零样本设置下显著优于其强竞争者HyDE。与少样本相关判断方法和全监督检索模型相比,LameR在大多数检索评估指标上也表现最佳。


-
BEIR基准:在BEIR基准的六个低资源任务数据集中,LameR在四个数据集上表现最佳。特别是在TREC-COVID和TREC-NEWS两个TREC检索数据集上,验证了LameR在网络信息检索任务中的优越性。

-
开源LLMs:将开源LLMs(如LLaMA-2-chat-7B和-13B)集成到LameR框架中,LameR在DL19数据集上的表现优于HyDE配置和传统方法,展示了LameR与各种LLM骨干的适应性和效率。
-
更强LLM的探索:进一步验证了更强LLM(如GPT-4)对LameR的提升效果,GPT-4在DL20数据集上的表现显著优于其他竞争者,甚至在全相关判断下也表现最佳。
总体结论
本文提出了一种基于LLM和简单BM25算法的检索方法,无需依赖可学习的检索模型。通过将查询与其潜在答案候选结合,LameR在零样本大规模检索中表现出色,显著优于现有的零样本检索方法。未来的工作将探索使用较小的LLM进行查询增强,以进一步提高效率。
论文评价
优点与创新
- 零样本检索方法:提出了一种简单的方法,将大型语言模型(LLM)应用于零样本场景下的大规模检索,称为“大型语言模型作为检索器”(LameR)。
- 候选答案注入提示:在提示LLM生成答案时,将查询的候选答案注入到提示中,使LLM能够区分和模仿这些候选答案,并通过内部知识总结或重写新的答案。
- 非参数词典检索:利用非参数词典方法(如BM25)作为检索模块,捕捉查询-文档重叠,使检索过程对LLM透明,规避了自监督检索器的性能瓶颈。
- 基准数据集上的优异表现:在多个基准数据集上进行了评估,结果表明LameR在大多数数据集上实现了最佳的检索质量,甚至超过了基于上下文标签演示的LLM检索器和在全量数据集上微调的基线检索器。
- 开源LLM的适应性:展示了将开源LLMs(如LLaMA-2-7B和-13B)集成到LameR框架中的有效性,证明了LameR与各种LLM骨干的适应性和效率。
- 更强大的LLM的优势:进一步验证了使用更强大的LLM(如GPT-4)可以带来更多的改进,显著提高了检索方法的性能。
不足与反思
- 指令敏感性:与其他基于提示的LLM应用一样,LameR对不同LLM的指令也很敏感,这可能需要大量的人工努力来编写提示。
- 计算开销:尽管LameR的两阶段检索过程非常快,依赖于LLM生成答案的计算开销仍然存在。未来的工作将探索专门针对较小LLM进行查询增强,以减少计算开销。
关键问题及回答
问题1:LameR方法如何在零样本场景下利用大型语言模型(LLM)进行大规模检索?
LameR方法通过将查询与其潜在答案候选结合,提升零样本检索的性能。具体步骤如下:
- 非参数词典检索:首先,使用BM25方法进行大规模检索,而不是训练深度神经网络。BM25根据查询和文档之间的词频和逆文档频率对文档进行排序。
- 候选答案生成:在提示LLM时,将查询的候选答案也加入提示中。这些候选答案是通过对查询进行普通检索得到的。然后,构造提示并使用LLM生成答案。
- 答案增强的大规模检索:使用生成的答案增强原始查询,并进行大规模检索。最终使用增强后的查询进行检索。
这种方法避免了直接将LLM与自监督检索器结合产生的问题,提升了检索质量和性能。
问题2:LameR方法在实验中如何验证其有效性?
LameR方法在多个数据集和评价指标上进行了验证,具体包括:
- DL19和DL20测试集:在TREC深度学习2019和2020测试集中,LameR在零样本设置下表现最佳,显著优于其强竞争者HyDE。与少样本相关判断方法和全监督相关判断方法相比,LameR在大多数检索评估指标上也表现最佳。
- BEIR基准:在BEIR基准的六个低资源任务数据集中,LameR在四个数据集上表现最佳。特别地,在两个TREC检索数据集(TREC-COVID和TREC-NEWS)上,LameR表现出色,验证了其在Web信息检索任务中的有效性。
- 开源LLMs:将开源LLMs(如LLaMA-2-chat-7B和-13B)集成到LameR框架中,LameR在DL19数据集上的表现优于HyDE配置和传统的DPR和Contriever-FT方法,展示了LameR与各种LLM骨干的适应性和效率。
- 更强LLM的探索:进一步验证了更强的LLM(如GPT-4)是否会带来更大的改进。在DL20数据集上应用GPT-4后,LameR的性能显著提高,甚至在全相关判断下也击败了所有竞争者。
问题3:LameR方法在实验中有哪些发现和改进空间?
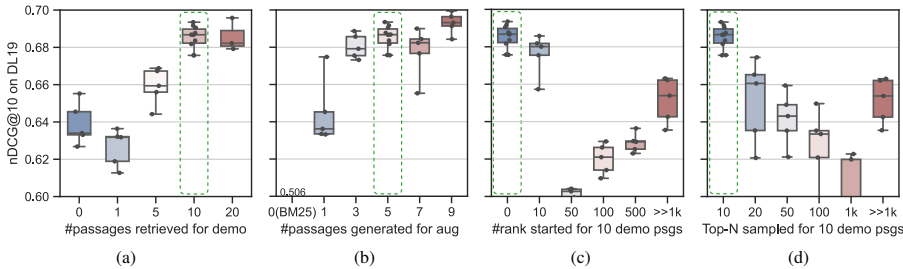
- 候选答案数量的影响:实验发现,增加检索到的候选答案数量(M)会一致提高答案增强大规模检索的性能,但当M超过10时,提升变得边际。因此,选择M=10以平衡性能和效率。
- 生成的答案数量的影响:生成的答案数量(N)越多,检索性能越好,但当N>5时,性能波动并趋于饱和。因此,选择N=5作为默认值。
- 检索方法的比较:LameR在使用BM25进行检索时,表现出高效的检索性能和较低的延迟,优于使用密集检索器(如Contriever)的方法。
- 未来改进方向:未来的工作将探索使用较小的LLM进行查询增强,以进一步提高效率,并解决提示敏感性问题,减少人工编写提示的工作量。
相关文章:
【 LLM论文日更|检索增强:大型语言模型是强大的零样本检索器 】
论文:https://aclanthology.org/2024.findings-acl.943.pdf代码:GitHub - taoshen58/LameR机构:悉尼科技大学 & 微软 & 阿姆斯特丹大学 & 马里兰大学领域:retrieval & llm发表:ACL2024 研究背景 研究…...

【基于轻量型架构的WEB开发】课程 作业3 Spring框架
一. 单选题(共12题,48分) 1. (单选题)以下有关Spring框架优点的说法不正确的是( )。 A. Spring就大大降低了组件之间的耦合性。 B. Spring是一种侵入式框架 C. 在Spring中,可以直接通过Spring配置文件管理…...

14.最长公共前缀-力扣(LeetCode)
题目: 解题思路: 解决本题的关键点是确定扫描的方式,大体上有两种方式:横向扫描和纵向扫描。 1、横向扫描:首先比较第一个字符串和第二个字符串,记录二者的公共前缀,然后用当前公共前缀与下一个…...

客户案例|智能进化:通过大模型重塑企业智能客服体验
01 概 述 随着人工智能技术的快速发展,客户对服务体验的期待和需求不断升级。在此背景下,大模型技术的崛起,为智能客服领域带来了创造性的变革。 在上篇文章《在后LLM时代,关于新一代智能体的思考》中有提到,智能客服…...

Flink Job更新和恢复
Checkpoints 的主要目的是为意外失败的作业提供恢复机制。 Savepoints的设计更侧重于可移植性和操作灵活性,尤其是在 job 变更方面。Savepoint 的用例是针对计划中的、手动的运维。例如,可能是更新你的 Flink 版本,更改你的作业图等等。 fli…...

读多写少业务中,MySQL如何优化数据查询方案?
小熊学Java站点:https://www.javaxiaobear.cn 编程资料合集:https://pqgmzk7qbdv.feishu.cn/base/QXq2bY5OQaZiDksJfZMc30w5nNb?from=from_copylink 看一看当面试官提及“在读多写少的网络环境下,MySQL 如何优化数据查询方案”时,你要从哪些角度出发回答问题??? 案例…...

Bugku CTF_Web——点login咋没反应
Bugku CTF_Web——点login咋没反应 进入靶场 随便输个试试 看来确实点login没反应 抓包看看 也没有什么信息 看了下源码 给了点提示 一个admin.css try ?12713传参试试 拿到一个php代码 <?php error_reporting(0); $KEYctf.bugku.com; include_once("flag.php&q…...

attention 注意力机制 学习笔记-GPT2
注意力机制 这可能是比较核心的地方了。 gpt2 是一个decoder-only模型,也就是仅仅使用decoder层而没有encoder层。 decoder层中使用了masked-attention 来进行注意力计算。在看代码之前,先了解attention-forward的相关背景知识。 在普通的self-atten…...

什么是HTTP,什么是HTTPS?HTTP和HTTPS都有哪些区别?
什么是 HTTP? HTTP(Hypertext Transfer Protocol,超文本传输协议)是一种应用层协议,用于在互联网上进行数据通信。它定义了客户端(通常是浏览器)和服务器之间的请求和响应格式。HTTP 是无状态的…...

SkyWalking-安装
SkyWalking-简单介绍 是一个开源的分布式追踪系统,用于检测、诊断和优化分布式系统的功能。 支持 ElasticSearch、H2、MySQL、PostgreSql 等数据库 基于 ElasticSearch 的情况 ElasticSearch(ES) 安装 1、下载并解压 https://www.elastic…...

RabbitMQ运维
1. 单机多节点 1.1 搭建RabbitMQ ①安装RabbitMQ 略 ②确认RabbitMQ运⾏没问题 #查看RabbitMQ状态 rabbitmqctl status 节点名称: 端口号: 25672:Erlang分布式节点通信的默认端⼝, Erlang是RabbitMQ的底层通信协议.15672: Web管理界⾯的默认端⼝, 通过这个端⼝可以访问R…...

Go语言并发精髓:深入理解和运用go语句
Go语言并发精髓:深入理解和运用go语句 在Go语言的世界里,go语句是实现并发的核心,它简洁而强大,允许程序以前所未有的方式运行多个任务。本文将深入探讨go语句及其执行规则,揭示Go语言并发编程的内在机制,并提供实际案例帮助读者掌握其用法。 1. go语句的基本概念(Wha…...

基于STM32的智能家居系统:MQTT、AT指令、TCP\HTTP、IIC技术
一、项目概述 随着智能家居技术的不断发展,越来越多的家庭开始使用智能设备来提升生活质量和居住安全性。智能家居系统不仅提供了便利的生活方式,还能有效地监测家庭环境,保障家庭安全。本项目以设计一种基于STM32单片机的智能家居系统为目标…...

分糖果(相等分配)
题目:有n种不同口味的糖果,第i种糖果的数量为a[i],现在需要把糖果分给m个人。分给每个人糖果的数量必须是相等的,并且每个人只能选择一种糖果。也就是说,可以把一种糖果分给多个人,但是一个人的糖果不能有多…...

docker构建jdk11
# 建立一个新的镜像文件,配置模板:新建立的镜像是以centos为基础模板 # 因为jdk必须运行在操作系统之上 FROM centos:7.9.2009# 作者名 MAINTAINER yuanhang# 创建一个新目录来存储jdk文件 RUN mkdir /usr/local/java#将jdk压缩文件复制到镜像中&#…...

唐帕科技校园语音报警系统:通过关键词识别,阻止校园霸凌事件
校园霸凌问题已成为全球教育领域的严峻挑战,给受害者带来了身心上的长期创伤。然而,随着科技的发展,尤其是人工智能和语音识别技术的不断进步,我们开始看到创新性解决方案的出现。校园语音报警系统便是其中一种利用技术手段保护学…...

酒店行业数据仓库
重要名词: PMS:酒店管理系统CRS:中央预定系统客户:可以分为会员、散客(自行到店入住)、协议(与酒店长期合作,内部价)、中介预定:可以分为线上预定、线下预定…...

A029-基于Spring Boot的物流管理系统的设计与实现
🙊作者简介:在校研究生,拥有计算机专业的研究生开发团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 赠送计算机毕业设计600…...

Python Day5 进阶语法(列表表达式/三元/断言/with-as/异常捕获/字符串方法/lambda函数
Python 列表推导式是什么 列表推导式是 Python 语言特有的一种语法结构,也可以看成是 Python 中一种独特的数据处理方式, 它在 Python 中用于 转换 和 过滤 数据。 其语法格式如下所示,其中 [if 条件表达式] 可省略。 [表达式 for 迭代变量…...

一文了解Android的核心系统服务
在 Android 系统中,核心系统服务(Core System Services)是应用和系统功能正常运行的基石。它们负责提供系统级的资源和操作支持,包含了从启动设备、管理进程到提供应用基础组件的方方面面。以下是 Android 中一些重要的核心系统服…...

协议转换网关与数据采集网关的区别与差异
摘要在工业自动化、物联网、智能建筑等领域中,“协议转换”和“数据采集网关”是两个常被提及但容易混淆的概念。它们虽有关联,却扮演着不同的角色。理解其核心差异对于构建高效、可靠的数据通信系统至关重要。1.核心定义:本质差异1.1协议转换…...

Jellyfin Android TV客户端:打造家庭影院的终极大屏解决方案
Jellyfin Android TV客户端:打造家庭影院的终极大屏解决方案 【免费下载链接】jellyfin-androidtv Android TV Client for Jellyfin 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-androidtv Jellyfin Android TV客户端是一款专为智能电视和流媒体设…...
)
RWKV vs Llama2:在论文审稿任务上,我们为什么第一版选了它?(附长上下文模型选型避坑指南)
RWKV与Llama2在论文审稿任务中的技术选型思考 当面对论文审稿这一知识密集型任务时,模型选型往往成为项目成败的关键。2023年第三季度,我们在构建首个论文审稿GPT系统时,曾在RWKV与Llama2之间面临艰难抉择。本文将深入剖析两种架构的核心差异…...

3分钟完成智能图像分层:Layerdivider一键PSD生成终极指南
3分钟完成智能图像分层:Layerdivider一键PSD生成终极指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾面对一张精美的插画&#x…...

AssetRipper:3步解锁Unity游戏资源逆向提取的终极免费方案
AssetRipper:3步解锁Unity游戏资源逆向提取的终极免费方案 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper 在Unity游戏开发…...

VoiceFixer终极指南:三分钟让模糊录音变清晰的免费语音修复神器
VoiceFixer终极指南:三分钟让模糊录音变清晰的免费语音修复神器 【免费下载链接】voicefixer General Speech Restoration 项目地址: https://gitcode.com/gh_mirrors/vo/voicefixer 你是否曾经因为一段珍贵的录音模糊不清而遗憾?也许是重要的会议…...

低代码平台表单设计器 unione form editor 布局组件 — 折叠面板
低代码平台表单设计器 unione-form-editor 布局组件 —— 折叠面板 在企业级表单越来越长、内容越来越多的今天,如何让表单保持简洁、可收起、可展开、层级清晰,成为提升填写体验的关键。继栅格、卡片、标签、段落布局之后,今天为大家介绍 折…...

别再死记硬背了!用C++邻接矩阵手搓Dijkstra算法,我连路径打印都给你讲明白了
从零实现Dijkstra算法:邻接矩阵实战与路径回溯详解 在计算机科学的世界里,寻找两点之间最短路径的问题就像现代都市中的导航系统——我们需要在错综复杂的道路网络中找到最优解。Dijkstra算法作为解决单源最短路径问题的经典方法,其重要性不…...

被AI冲击的App,反成了Agent的命门
2026年最流行的一个判断:AI Agent要吃掉一切图形界面,对话即服务,App即将消亡。 这个判断的依据并非没有道理。Agent确实在接管"发现"和"调度"——用户不再需要主动打开某个App,而是告诉Agent"帮我订一…...

AD导出Gerber文件时,单位选英寸格式选2:5?一文讲透这些‘祖传’设置背后的原因
为什么PCB工程师至今仍在使用英寸和2:5格式导出Gerber文件? 在PCB设计领域,有一个看似奇怪却普遍存在的现象:即使全球绝大多数国家采用公制单位,工程师们在导出Gerber文件时却坚持使用英制单位(英寸)&#…...