如何用分布式数据库解决慢查询问题
当使用MySQL时,我们不可避免地会遇到许多与慢查询相关的问题。
为了解决这些慢SQL的问题,我们通常需要投入大量的精力去研究执行计划、考虑合适的索引策略、精心改写SQL语句,甚至可能需要调整程序逻辑。然而,针对特定SQL的优化往往既复杂又具有挑战性,而且存在许多原因,即使经过多次尝试和优化,也可能无法取得显著的效果。
慢查询产生的典型场景
下面是2个典型的慢查询场景,大家在日常写SQL和优化SQL的过程中应该会有感受:
场景一:大表
这是MySQL的经典问题。MySQL早期有单表数据量不能超过2000W的说法,虽然有点夸张,不过对于MyQL中千万级,乃至过亿的表,哪怕对这种表的查询建了索引,索引的B+树也会很深,查询速度确实很受影响,从而形成慢SQL。
一些有经验的开发会考虑给这张表加分区,通过合理拆分,来降低每个分区对应B+树索引的深度,从而提升执行性能。但MySQL毕竟是一个单机库,各个分区共享的还是一份硬件资源;而如果想突破单机的限制,就要考虑做分库,而那又是一个更复杂的问题,涉及到整个数据库用法和结构的大调整。
场景二:多表连接。这也是让很多研发头痛的问题,类似下面这类SQL:
select ...
from t1 --100行
left join t2 --100000行
on t1.c1=t2.c1
left join t3 --100行
on t1.c1=t3.c1
left join t4 --100行
on t1.c1=t4.c1
order by t1.c1 limit 1000;
在这个例子中, 4 张表做连接 T1、T2、T3、T4,其中 T2 是大表,其它都是小表,如果严格按照连接次序来做,T1 跟 T2 连接,再跟 T3、T4 连接,最大的表T2就过早进行了合并,导致结果集特别大,整个SQL开销相对较高。
如果要优化慢查询的话,就要改写SQL,把T2挪到最后来连接,这样整个SQL的代价就会小很多了,但很多时候这是跟我们业务开发的逻辑是违背的。很多场景下,修改SQL都是非常麻烦的一件事。
其实自适应调整表连接顺序应该是数据库能做到的,这步一般被称为“SQL改写”,但因为MySQL当前的优化器更多是基于规则的模型,所以通常情况是做不到这点的。
为什么MySQL的大SQL能力比较差?
因为MySQL社区主要还是将MySQL定位为一个纯粹OLTP(Online Transaction Processing,联机交易处理)型的开源数据库。这个定位使得MySQL的迭代发版,侧重于提升单核性能、加强事务处理能力等,而对于大数据量、复杂查询类的偏OLAP(Online Analytical Processing,联机事务处理)场景,MySQL发展缓慢。
举个例子:在MySQL 8.0.14前,MySQL是没有并行执行能力的。也就是说MySQL对每条SQL最多只能使用CPU的一个核来处理。而并行执行可以将一个 SQL 查询任务分成多个子任务,并允许这些子任务在多个处理器上同时运行,以提高整个查询任务的执行效率。对于上文的慢查询场景一而言,并行执行就可以极快加速这种场景的查询效率。虽然MySQL自8.0.14版本开始支持并行执行,但目前仅在select count(*)等有限场景下生效,且必须手动配置参数。因此目前MySQL还不支持大部分场景的并行执行,从根本上解决复杂查询的问题。
用分布式数据库解决慢查询问题
针对这些挑战,OceanBase作为一款原生分布式的HTAP(Hybrid Transactional/Analytical Processing)数据库,对大规模查询场景的处理上进行了重点的优化。如果您也在寻求解决慢SQL查询的方案,不妨尝试一下用分布式数据库OceanBase从根本上来解决这个问题。
OceanBase在大查询场景的主要技术点有:
1、并行执行
OceanBase有非常成熟的并行执行能力,可以对普通查询、DDL、DML操作都进行并行执行,并且可以自动/手动灵活选取并行度。这可以使得开发者通过少量CPU的代价,简单、直接的使原本运行较慢的SQL性能快上几倍,对于大SQL问题有立竿见影的解决效果。
可以通过下面两个参数来开启并设置自动并行:
#开启并行
set global parallel_degree_policy = AUTO;
#设置基表最大扫描时间,单位为ms,默认为1000ms;您可以视情况调大或调小这个值,这里把这个参数改为100ms,即基表扫描时间超过100ms,则开启并行执行。
set global parallel_min_scan_time_threshold = 100;
2、分库分表
如同前文MySQL的场景一中所提到的,解决大数据量表查询性能问题的一个解法是分库分表,但MySQL分库分表有很高的改造成本。而OceanBase是一款原生的分布式数据库,OceanBase中的分区是一个独立的存储、高可用、事务的单位,这意味着OceanBase同一张表的不同分区可以分布在不同的服务器上,从而利用多机性能大大加快大表查询速度。同时OB的原生分布式能力,也可以使应用程序像使用一个单机数据库一样使用分布式的OB,没有业务改造成本。
3、多表连接次序优化
对于前文的场景二,业务上是比较难判断怎么调整表连接的顺序更好的,而OceanBase 实现了一套完备的连接枚举算法,整体优化逻辑是基于代价的,可以灵活调整内连接和外连接的次序,可以调整外连接、反连接、半连接,甚至还可以改变一个外连接的连接类型,把它变成内连接或反连接等,可以做到场景自动优化。像场景二的例子,在OB中自然就会优化成,t1跟t3连接,再跟t4连接,最后再跟t2连接,从而使得SQL执行性能快了近百倍。很多在MySQL中需要反复改写、调优的SQL,在OB中自然跑出来就是最优的执行计划。
4、子查询场景优化
子查询也是很常见的性能问题,并且不同于多表连接,子查询通常比较难改写,往往会造成执行很慢。OceanBase 查询改写模块,实现了丰富的子查询优化策略,只要不是嵌套非常深的子查询,都可以把它变成连接,变成连接后,就成了连接枚举的问题,可以采取不同的连接算法去优化它。
5、大表聚合场景优化
大表聚合也是一个经典的场景,比如我们要汇总一年的营业额数据,就有可能用到下面的SQL:
SELECT year(sold_date) AS yearDate, code, name, SUM(value0) as total_value FROM t where sold_date>='2023-01-01' and sold_date<'2023-12-31' GROUP BY year(sold_date), code, name;
针对这种场景,OB有一种优化能力称作预聚合,就是把大表的数据拆成多份,每个线程分别做分组聚合,然后线程交换数据继续聚合,全部聚合完后再做一次汇总。比如把示例中t表分为100组,每组按year(sold_date), code, name分别聚合,再最后汇总。
预聚合配合并行执行,往往可以取得几倍的性能提升。但这种优化并不一定是好效果的,假如一共10亿条数据,不同的year(sold_date), code, name租户就有5亿种,那么区分度就太低了,预聚合甚至是一个反优化。
OceanBase 面对大表聚合场景,是让执行引擎变得更聪明,不在优化器层面去做决策,而是交给执行层,执行根据计算过程中的实际情况,去决定做不做预聚合优化。
当前OceanBase 对各种场景基本都支持了这个优化,包括分组、去重、窗口函数,都可以灵活判断是否做预聚合。
6、TP 与 AP隔离,避免互相影响
对于数据库来说,相比于单条复杂大查询,让大量的 DML 和短查询尽快返回更有意义。为了避免一条大查询阻塞大量简单请求而导致系统吞吐量暴跌,避开分库分表的查询性能局限,当大查询和短请求同时争抢 CPU 时,OceanBase 会限制大查询的 CPU 使用。当一个线程执行的 SQL 查询耗时太长,这条查询就会被判定为大查询,一旦判定为大查询,就会进入大查询队列,然后执行大查询的线程会等在一个 Pthread Condition 上,为其它的租户工作线程让出 CPU 资源。
通过这些技术能力,可以使得原本在MySQL中执行时间超过1s的慢SQL,在OceanBase中获得显著的性能提升。
如果大家希望体验分布式数据库OceanBase在复查查询的性能,可以在OceanBase官网开通365天的免费试用。1核4G的OceanBase租户实例就可以体验查询性能,如果还需要体验OceanBase的其他特性,也可以申请企业版的集群实例。产品中有相关的新手教程引导,也请注意通过上文中的方法打开并行执行。
相关文章:

如何用分布式数据库解决慢查询问题
当使用MySQL时,我们不可避免地会遇到许多与慢查询相关的问题。 为了解决这些慢SQL的问题,我们通常需要投入大量的精力去研究执行计划、考虑合适的索引策略、精心改写SQL语句,甚至可能需要调整程序逻辑。然而,针对特定SQL的优化往…...
)
vscode文件重定向输入输出(竞赛向)
VS Code 中文件重定向输入输出 在使用 VS Code 调试或运行 C 程序时,可以使用文件重定向来方便地从文件读取输入并将输出写入文件,而不是修改代码中的 ifstream 和 ofstream。 方法一:在终端中使用文件重定向 假设你的 C 程序文件为 main.…...

[Linux]IO多路转接(上)
1. IO 多路转接之select 1.1 select概述 select 是系统提供的一个多路转接接口,其核心工作在于等待。它能够让程序同时监视多个文件描述符上的事件是否就绪,只有当被监视的多个文件描述符中有一个或多个事件就绪时,select 才会成功返回&…...

基于Java的药店管理系统
药店管理系统 一:基本介绍开发环境管理员功能模块图系统功能部分数据库表设计 二:部分系统页面展示登录界面管理员管理进货信息界面管理员管理药品信息界面管理员管理员工界面管理员管理供应商信息界面管理员管理销售信息界面员工对信息进行管理员工对销…...

LaTeX之四:如何兼容中文(上手中文简历和中文论文)、在win/mac上安装新字体。
改成中文版 如果你已经修改了.cls文件和主文档,但编译后的PDF仍然显示英文版本,可能有以下几个原因: 编译器问题:确保你使用的是XeLaTeX或LuaLaTeX进行编译,因为它们对Unicode和中文支持更好。你可以在你的LaTeX编辑器…...

Unity自动LOD工具AutoLOD Mesh Decimator的使用
最近在研究大批量物体生成,由于我们没有专业美术,在模型减面工作上没有人手,所以准备用插件来实现LOD功能,所以找到了AutoLOD Mesh Decimator这个插件。 1,导入插件后,我们拿个实验的僵尸狗来做实验。 空…...

Flutter:使用Future发送网络请求
pubspec.yaml配置http的SDK cupertino_icons: ^1.0.8 http: ^1.2.2请求数据的格式转换 // Map 转 json final chat {name: 张三,message: 吃饭了吗, }; final chatJson json.encode(chat); print(chatJson);// json转Map final newChat json.decode(chatJson); print(newCha…...

4000字浅谈Java网络编程
什么是网络编程? 可以让设备中的程序与网络上的其他设备中的程序进行数据交互的技术(实现网络通信)。 基本的通信架构 基本的通信架构有两种形式:CS架构(Client客户端/Server服务端)、BS架构(…...

立体工业相机提升工业自动化中的立体深度感知
深度感知对仓库机器人应用至关重要,尤其是在自主导航、物品拾取与放置、库存管理等方面。 通过将深度感知与各种类型的3D数据(如体积数据、点云、纹理等)相结合,仓库机器人可以在错综复杂环境中实现自主导航,物品检测…...

大模型基础BERT——Transformers的双向编码器表示
大模型基础BERT——Transformers的双向编码器表示 整体概况 BERT:用于语言理解的深度双向Transform的预训练 论文题目:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Bidirectional Encoder Representations from…...
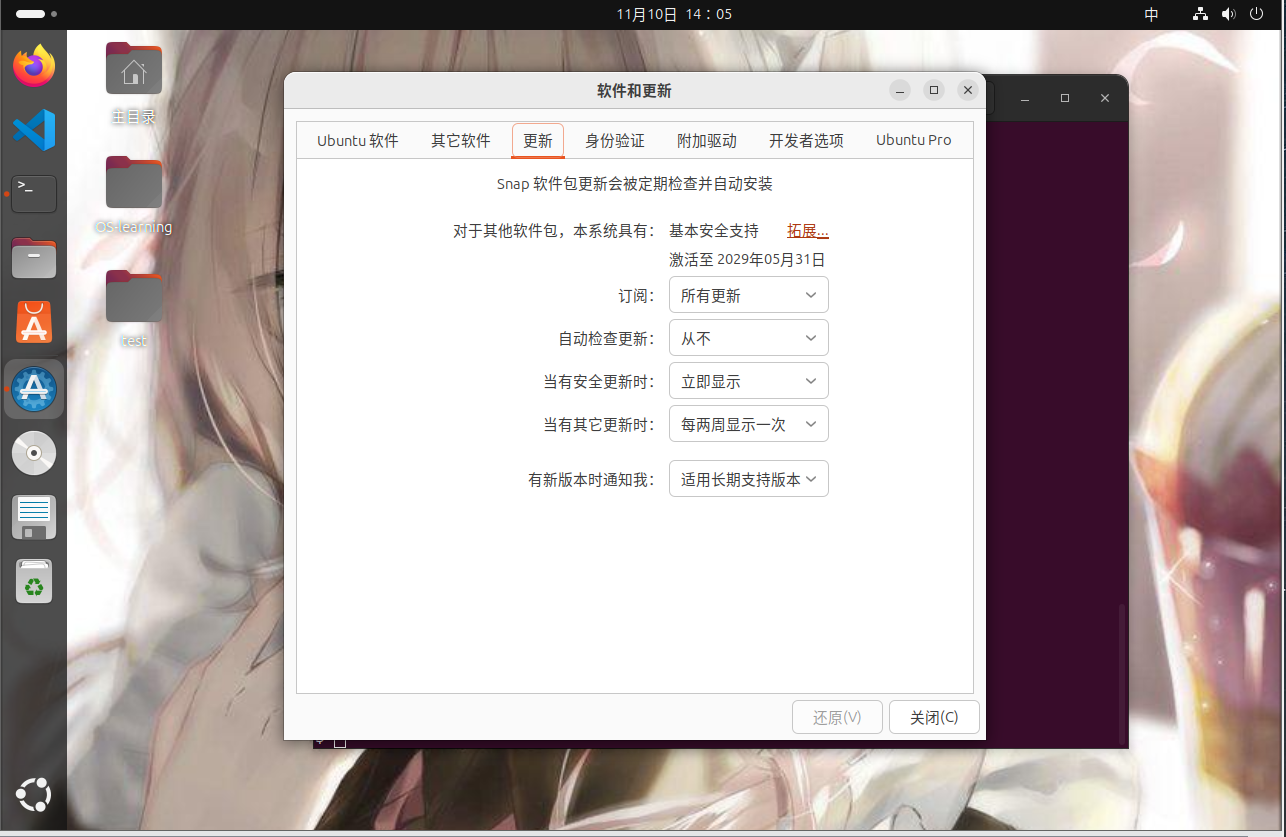
怎么禁止Ubuntu自动更新升级
怎么禁止Ubuntu自动更新升级 笔者在做MIT 6.S081的时候发现他给我的qemu自动更新了又卡住了,故关闭了自动更新 文章目录 怎么禁止Ubuntu自动更新升级一、图形化修改二、基于命令行修改配置文件的方法 一、图形化修改 1.打开设置->软件和更新->更新 2.选择自…...

【SpringBoot】20 同步调用、异步调用、异步回调
Git仓库 https://gitee.com/Lin_DH/system 介绍 同步调用:指程序在执行时,调用方需要等待函数调用返回结果后,才能继续执行下一步操作,是一种阻塞式调用。 异步调用:指程序在执行时,调用方在调用函数后立…...

【Excel】数据透视表分析方法大全
数据透视表的最常用的功能是分类汇总,其实它还有很强大的数据分析功能。在数据透视表右键菜单的值显示方式中,可以看到有14个很实用的分析选项。 1、总计的百分比 作用:透视表中每一个数字(包括汇总行、总计行)占右…...

深度学习在边缘检测中的应用及代码分析
摘要: 本文深入探讨了深度学习在边缘检测领域的应用。首先介绍了边缘检测的基本概念和传统方法的局限性,然后详细阐述了基于深度学习的边缘检测模型,包括其网络结构、训练方法和优势。文中分析了不同的深度学习架构在边缘检测中的性能表现&am…...

k8s 1.28.2 集群部署 docker registry 接入 MinIO 存储
文章目录 [toc]docker registry 部署生成 htpasswd 文件生成 secret 文件 生成 registry 配置文件创建 service创建 statefulset创建 ingress验证 docker registry docker registry 监控docker registry ui docker registry dockerfile docker registry 配置文件 S3 storage dr…...

常用的生物医药专利查询数据库及网站(很全!)
生物医药专利信息检索是药物研发前期不可或缺的一步,通过对国内外生物医药专利网站信息查询,可详细了解其专利技术,进而有效降低药物研发过程中的风险。 目前主要使用的生物医药专利查询网站分为两大类,一个是免费生物医药专利查询…...

「QT」几何数据类 之 QPolygon 多边形类
✨博客主页何曾参静谧的博客📌文章专栏「QT」QT5程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasolid…...

写给初学者的React Native 全栈开发实战班
React Native 全栈开发实战班 亲爱的同学们: 很高兴在这里与大家相聚!我是你们的讲师,将带领大家一起踏上 React Native 移动开发的学习之旅。 为什么选择 React Native? 在这个移动互联网时代,App 开发工程师已经…...

工作和学习遇到的技术问题
写在前面 记录工作和学习遇到的技术问题,以求再次遇到可以快速解决。 1:Ubuntu TSL换源报错:Err:1 http://mirrors.aliyun.com/ubuntu focal InRelease 执行如下操作(已经操作的则忽略),首先在文件/etc/apt/sources…...

如何解决JAVA程序通过obloader并发导数导致系统夯住的问题 | OceanBase 运维实践
案例背景 某保险机构客户的数据中台,自系统上线后不久,会定期的用 obload 工具从上游业务系统导入数据至OceanBase数据库。但,不久便遇到了应用服务器的 Memory 与 CPU 资源占用持续攀升,最终导致系统夯住而不可用的异常。 memo…...

从高斯-克吕格到UTM:在QGIS里搞定国内卫星影像与地形图的坐标匹配
从高斯-克吕格到UTM:在QGIS里搞定国内卫星影像与地形图的坐标匹配 当你在QGIS中加载了从不同来源获取的卫星影像和地形图时,是否遇到过这样的困扰:明明应该是同一区域的数据,却在软件中显示得南辕北辙?这种"影像对…...

华为鸿蒙与欧拉操作系统:全场景战略下的技术架构与生态构建
1. 从“备胎”到“主干”:华为操作系统的战略突围之路 最近科技圈里关于华为的消息,大家讨论得最多的,除了孟晚舟女士的归国,可能就是华为在软件领域接连放出的几个“大招”了。作为一名在ICT行业摸爬滚打了十几年的老兵ÿ…...

Linux内核平台设备深度盘点:从原理到实战的全面解析
1. 项目概述:一次对Linux内核“家底”的深度盘点在Linux内核开发的日常工作中,无论是为一块新的开发板适配驱动,还是排查一个诡异的硬件初始化问题,我们常常会面临一个基础却又关键的问题:当前系统里到底有哪些“平台设…...

终极指南:掌握WinPmem Windows内存取证采集核心技术
终极指南:掌握WinPmem Windows内存取证采集核心技术 【免费下载链接】WinPmem The multi-platform memory acquisition tool. 项目地址: https://gitcode.com/gh_mirrors/wi/WinPmem WinPmem作为Windows平台物理内存采集的标杆工具,为安全分析师和…...
了!用Celery的Canvas原语(Group/Chain/Chord)构建复杂异步工作流)
别再只会用delay()了!用Celery的Canvas原语(Group/Chain/Chord)构建复杂异步工作流
别再只会用delay()了!用Celery的Canvas原语构建复杂异步工作流 在异步任务处理领域,Celery早已成为Python生态中的标配工具。但令人惊讶的是,大多数开发者仅仅停留在task.delay()的基础用法上,就像只学会了加减法却从未接触过微积…...

抖音批量下载工具终极指南:从零开始实现高效无水印下载
抖音批量下载工具终极指南:从零开始实现高效无水印下载 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback supp…...

3分钟上手Windhawk:像安装App一样轻松定制Windows系统
3分钟上手Windhawk:像安装App一样轻松定制Windows系统 【免费下载链接】windhawk The customization marketplace for Windows programs: https://windhawk.net/ 项目地址: https://gitcode.com/gh_mirrors/wi/windhawk 你是否厌倦了Windows系统一成不变的界…...

Embulk高级用法指南:如何实现高效并行处理与数据分片
Embulk高级用法指南:如何实现高效并行处理与数据分片 【免费下载链接】embulk Embulk: Pluggable Bulk Data Loader. 项目地址: https://gitcode.com/gh_mirrors/em/embulk Embulk是一个强大的可插拔批量数据加载器,专为高效处理大规模数据迁移而…...
)
别再死记硬背了!手把手教你玩转COMSOL Desktop的窗口布局与自定义(附效率翻倍技巧)
别再死记硬背了!手把手教你玩转COMSOL Desktop的窗口布局与自定义(附效率翻倍技巧) 作为一名经常与多物理场仿真打交道的工程师,你是否曾因频繁切换窗口而打断思路?或是花费大量时间在菜单栏中寻找某个隐藏功能&#…...

麒麟KylinOS 2303系统管理员必备:用模板为新用户批量配置统一电源策略
麒麟KylinOS 2303系统管理员实战:批量配置用户电源策略的模板化方案 在企业办公环境或学校机房中,麒麟KylinOS系统管理员经常面临统一管理多台电脑电源策略的需求。传统逐台配置的方式效率低下,而通过/etc/skel/用户模板目录的机制࿰…...