大模型基础BERT——Transformers的双向编码器表示
大模型基础BERT——Transformers的双向编码器表示
整体概况
BERT:用于语言理解的深度双向Transform的预训练
论文题目:BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
Bidirectional Encoder Representations from Transformers.
概括:这篇文章在摘要部分说明了其参考的主要的文章就是ELBO和GPT的相关工作。
-
BERT 模型只需一个额外的输出层即可进行微调,从而为各种任务(例如问答和语言推理)创建最先进的模型,而无需对特定于任务的架构进行大量修改
-
和论文的标题要对应起来
预训练最早我们使用的是词嵌入来做模型的预训练的任务的,当然后面GPT系列的文章。 -
做预训练任务的时候主要有两种方式例如ELBO基于特征的方式,和BERT基于微调的方式。(GPT)感觉就像是迁移学习
-
受完形填空任务启发,通过使用“掩码语言模型”(MLM)预训练目标来实现前面提到的单向性约束(Taylor,1953)。
词嵌入wordembing(word2vec)
在进一步学习自然语言处理之前,因为自己之前主要研究的是cv的方向,因此对自然语言处理缺乏足够的知识去学习。在学习双向编码器之前需要先学习一些NLP的基础知识。

在自然语言处理中: 词是意义的基本单元。顾名思义, 词向量是用于表示单词意义的向量, 并且还可以被认为是单词的特征向量或表示。 将单词映射到实向量的技术称为词嵌入。 近年来,词嵌入逐渐成为自然语言处理的基础知识
在NLP领域构建词向量的过程中,我们如果使用独热编码的方式来进行词向量的构建是一个不好的方式。
-
独热向量很容易构建,但它们通常不是一个好的选择。一个主要原因是独热向量不能准确表达不同词之间的相似度,比如我们经常使用的“余弦相似度”
-
由于任意两个不同词的独热向量之间的余弦相似度为0,所以独热向量不能编码词之间的相似性。
x ⊤ y ∥ x ∥ ∥ y ∥ ∈ [ − 1 , 1 ] . \frac{\mathbf{x}^{\top} \mathbf{y}}{\|\mathbf{x}\|\|\mathbf{y}\|} \in[-1,1] . ∥x∥∥y∥x⊤y∈[−1,1].
我们通过词嵌入的技术可以将onehot编码下的高维稀疏向量,转化为低维且连续的向量。
然后我们这一部分学习的就是常用的词嵌入算法 ——word2vec的技术。通过特定的词嵌入算法,如word2vec、fasttext、Glove等训练一个通用的嵌入矩阵

word2vec工具是为了解决上述问题而提出的。它将每个词映射到一个固定长度的向量,这些向量能更好地表达不同词之间的相似性和类比关系
嵌入矩阵的行,是语料库中词语的个数,矩阵的列是表示词语的维度

5000个单词每个单词都使用128维度的向量来进行表示。

主要包括了两个部分组成。训练依赖于条件概率
- 跳元模型(skip-gram)
- 连续词袋(CBOW)
跳元模型(Skip-Gram)
跳元模型假设一个词可以用来在文本序列中生成其周围的单词。以文本序列“the”“man”“loves”“his”“son”为例。假设中心词选择“loves”,并将上下文窗口设置为2。
给定中心词“loves”,跳元模型考虑生成上下文词“the”“man”“him”“son”的条件概率:

P("the","man","his","son" | "loves"). \text { P("the","man","his","son" | "loves"). } P("the","man","his","son" | "loves").
假设上下文词是在给定中心词的情况下独立生成的(即条件独立性)。在这种情况下,上述条件概率可以重写为:
P ( "the" | "loves") ⋅ P ( "man" | "loves") ⋅ P ( "his" | "loves" ) ⋅ P ( "son" | "loves") P(\text { "the" | "loves") } \cdot P(\text { "man" | "loves") } \cdot P(\text { "his" | "loves" }) \cdot P(\text { "son" | "loves") } P( "the" | "loves") ⋅P( "man" | "loves") ⋅P( "his" | "loves" )⋅P( "son" | "loves")
也就是要设置好窗口的长度。设置好窗口的长度后,需要根据目标词,预测窗口内的上下文词:

在这里我们抛开公式来解释一下这一个跳元模型的建模的思想是什么?
也就是:Skip-gram在迭代时。
- 调整词向量使目标词的词向量与其上下文的词向量尽可能的接近。
- 使目标词的词向量与非上下文词的词向量尽可能的远离。

这里我们的建模的思想就是给定一个词向量,我们希望这样建模也就是:上下文词的词向量相似与非上下文词的词向量不相似。那么我们的词向量就能捕获词语之间的语义关系。
之后我们需要提出的问题就是,如何判断两个词向量是否相似呢?这里就是给定两个词向量,我们与Transform中一样使用点积来判断两个词向量之间的相似性。
A ⋅ B = a 1 b 1 + a 2 b 2 + … + a n b n A = ( a 1 , a 2 , … , a n ) B = ( b 1 , b 2 , … , b n ) \begin{array}{l} A \cdot B=a 1 b 1+a 2 b 2+\ldots+a n b n \\ A=(a 1, a 2, \ldots, a n) \\ B=(b 1, b 2, \ldots, b n) \end{array} A⋅B=a1b1+a2b2+…+anbnA=(a1,a2,…,an)B=(b1,b2,…,bn)
向量的点积:衡量了两个向量在同一方向上的强度点积越大:两个向量越相似,它们对应的词语的语义就越接近。

跳元网络结构
Skip-Gram网络模型是一个神经网络。它主要是包括了
- in_embedding和out_embedding两个嵌入层组成。
- 向该神经网络输入一个目标词之后。
- 模型会返回一个词表大小的分布情况。
词汇表中的每个词是目标词的上下文的可能性

词表中的词,与目标词有两种关系上下文词:正样本,标记为1非上下文词:负样本,标记为0
给定中心词w(词典中的索引lc),生成任何上下文词w。(词典中的索引lo)的条件概率可以通过对向量点积的softmax操作来建模:
P ( w o ∣ w c ) = exp ( u o ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v c ) P\left(w_{o} \mid w_{c}\right)=\frac{\exp \left(\mathbf{u}_{o}^{\top} \mathbf{v}_{c}\right)}{\sum_{i \in \mathcal{V}} \exp \left(\mathbf{u}_{i}^{\top} \mathbf{v}_{c}\right)} P(wo∣wc)=∑i∈Vexp(ui⊤vc)exp(uo⊤vc)

整体的模型得到的词表概率分布的公式如下所示:
∏ t = 1 T ∏ − m ≤ j ≤ m , j ≠ 0 P ( w ( t + j ) ∣ w ( t ) ) \prod_{t=1}^{T} \prod_{-m \leq j \leq m, j \neq 0} P\left(w^{(t+j)} \mid w^{(t)}\right) t=1∏T−m≤j≤m,j=0∏P(w(t+j)∣w(t))
网络训练
跳元模型参数是词表中每个词的中心词向量和上下文词向量。在训练中,我们通过最大化似然函数(即极大似然估计)来学习模型参数。这相当于最小化以下损失函数:
指定窗口长度为m,同时词向量的长度为T
− ∑ t = 1 T ∑ − m ≤ j ≤ m , log P ( w ( t + j ) ∣ w ( t ) ) -\sum_{t=1}^{T} \sum_{-m \leq j \leq m,} \log P\left(w^{(t+j)} \mid w^{(t)}\right) −t=1∑T−m≤j≤m,∑logP(w(t+j)∣w(t))
这里就可以使用随机梯度下降来最小化损失函数的值。
连续词袋(CBOW)模型
CBOW连续词袋模型 Continuous Bag of Words与刚刚说过的跳元模型相比是一个相反的过程了。

假设将我们的窗口长度设置为2以后,就有如下的推导关系了。

连续词袋模型假设中心词是基于其在文本序列中的周围上下文词生成的。例如,在文本序列“the”“man”“loves”“his”“son”中,在“loves”为中心词且上下文窗口为2的情况下,连续词袋模型考虑基于上下文词“the”“man”“him”“son”

P ( "loves" | "the","man","his","son"). P(\text { "loves" | "the","man","his","son"). } P( "loves" | "the","man","his","son").
CBOW的网络结构
我们按照这个顺序继续向下推导直到整个句子推导结束的时候在停止。
CBOW模型同样也是一个神经网络模型,该神经网络会接收上下文词语将上下文词语转换为最有可能得目标词。

我们将这个网络模型在进一步的进行细化进行解释。我们将其中每一个部分的蓝色部分单独的拿出来其中蓝色的部分就是我们的嵌入矩阵,也就是之前提到的N x V的部分。 其输出的结果就是一个词向量。
然后:由于某个词的上下文中,包括了多个词语这些词语会同时输入至embeddings层每个词语都会被转换为一个词向量。
embeddings层的输出结果:是一个将语义信息平均的向量V
v = ( v 1 + v 2 + v 3 + v 4 ) / 4 v=(v 1+v 2+v 3+v 4) / 4 v=(v1+v2+v3+v4)/4


最后一步我们将所有词向量得到的平均值输入到最后的线性层中,通过最后的激活函数就可以得到需要预测的词了。整个过程就可以如下所示。概率最大的词就是我们的输出结果了。

按照和上面同样的思想我们就可以采用如下的方式来进行数学上的建模操作。
P ( w c ∣ w o 1 , … , w o 2 m ) = exp ( 1 2 m u c ⊤ ( v o 1 + … , + v o 2 m ) ) ∑ i ∈ V exp ( 1 2 m u i ⊤ ( v o 1 + … , + v o 2 m ) ) P\left(w_{c} \mid w_{o_{1}}, \ldots, w_{o_{2 m}}\right)=\frac{\exp \left(\frac{1}{2 m} \mathbf{u}_{c}^{\top}\left(\mathbf{v}_{o_{1}}+\ldots,+\mathbf{v}_{o_{2 m}}\right)\right)}{\sum_{i \in \mathcal{V}} \exp \left(\frac{1}{2 m} \mathbf{u}_{i}^{\top}\left(\mathbf{v}_{o_{1}}+\ldots,+\mathbf{v}_{o_{2 m}}\right)\right)} P(wc∣wo1,…,wo2m)=∑i∈Vexp(2m1ui⊤(vo1+…,+vo2m))exp(2m1uc⊤(vo1+…,+vo2m))

P ( w c ∣ W o ) = exp ( u c ⊤ v ‾ o ) ∑ i ∈ V exp ( u i ⊤ v ‾ o ) . P\left(w_{c} \mid \mathcal{W}_{o}\right)=\frac{\exp \left(\mathbf{u}_{c}^{\top} \overline{\mathbf{v}}_{o}\right)}{\sum_{i \in \mathcal{V}} \exp \left(\mathbf{u}_{i}^{\top} \overline{\mathbf{v}}_{o}\right)} . P(wc∣Wo)=∑i∈Vexp(ui⊤vo)exp(uc⊤vo).
BERT的由来
BERT的由来本质上来自于NLP领域迁移学习的思考。使用预训练好的模型来抽取词、句子的特征 例如word2vec
最后我们就可以将整个的建模过程表示如下了:
∏ t = 1 T P ( w ( t ) ∣ w ( t − m ) , … , w ( t − 1 ) , w ( t + 1 ) , … , w ( t + m ) ) \prod_{t=1}^{T} P\left(w^{(t)} \mid w^{(t-m)}, \ldots, w^{(t-1)}, w^{(t+1)}, \ldots, w^{(t+m)}\right) t=1∏TP(w(t)∣w(t−m),…,w(t−1),w(t+1),…,w(t+m))
然而对于我们的一个新的任务来说需要构建新的网络来抓取新任务需要的信息Word2vec忽略了时序信息,语言模型只看了一个方向。

在CV方向上迁移学习有广泛的应用这里我自己举一个例子:例如在许多的网络中我们的backbone都使用的是预训练好的restnet50的权重,并且在网络训练的过程中会冻结这部分权重不需要在调整或者进行新的训练了。
同样NLP是否可以:基于微调的NLP模型预训练的模型抽取了足够多的信息新的任务只需要增加一个简单的输出层。
它就是一个只要Transform编码器的部分—只保留编码器的部分。它是第一个在NLP领域做的很大的网络,并且使用了很大的一个数据集,可以看作是大模型的一个前置的基础了
基础架构
BERT: 主要使用的是Transform的编码器的部分。也就是左半部分所以整个完整的结构理解起来还是挺容易的。
这里提到了是Transform的双向编码器的表示方式:也就是在自注意力机制中,每个词元都与其他所有词元计算注意力分数,这意味着每个词元在编码时都能获取到整个序列的信息。这种机制允许模型在编码时同时考虑前文和后文的信息,从而实现双向处理。
但是我们的Transform的Decode部分通常是单项的部分了,主要的原因是:在自然语言处理中,解码器通常用于生成文本,例如在机器翻译、文本摘要或问答系统中生成回答。在这些任务中,解码器需要根据已经生成的文本来预测下一个词元,而不能利用未来的信息。

我们的编码器部分主要包括了三个部分组成,其中BERT base是堆叠了12个编码器,而BERT large部分主要是堆叠了24个编码器部分。
- 输入部分
- 注意力机制部分
- 前馈神经网络的部分
BERT和Transform的主要的区别在什么地方呢?
- Transform是由6个encode部分堆叠起来构成编码端,6个decode部分构成了解码端。

- 在编码方式上存在不同之处,Transform主要使用的是位置编码也就是正余弦的三角函数编码,而BERT采用的是
Input=token emb+ segment emb+ position emb

在我们的Transform的结构中,例如机器翻译的任务我们的句子要从source(原句子)经过encode的部分到target,在将得到的targets输入到decode部分中进行解码。同步的输出翻译的句子
这里的改进主要的就是想:如何通过新的编码的方式只使用encode完成

上面解释了我们的BERT是一个预训练的任务,也就是要实现通用的功能呀
论文中也提到了BERT主要包括了两个步骤预训练和微调

如何做预训练
BERT的预训练主要包括了两个部分,主要是MLM+NSP :掩码语言模型+ 判断两个句子之间的关系。
BERT在预训练的时候使用的是大量的无标记的预料来进行的。(考虑通过无监督来去做。)
MLM:
在这里要考虑到两种无监督的目标函数。AR模型和AE模型
- AR:auto regressive,自回归模型;只能考虑单侧的信息,典型的就是GPT。

自回归模型(Autoregressive Model,简称AR模型)是时间序列分析中的一种常用模型,它假设一个时间序列的未来值可以通过其过去值的线性组合来预测。自回归模型基于这样的假设:一个变量的当前值可以作为其过去值的函数来预测。
- AE:auto encoding,自编码模型;从损坏的输入数据中预测重建原始数据。可以使用上下文的信息,Bert就是使用的AE

预训练任务一:MLM
带掩码的语言模型(Masked Language Model, MLM)是一种特殊的预训练任务,它通过随机地将输入文本中的一些词元替换为特殊的掩码标记(如mask),然后让模型预测这些被掩码的词元 。
受完形填空任务启发,通过使用“掩码语言模型”(MLM)预训练目标来实现前面提到的单向性约束(Taylor,1953)其实也就是说在做完型填空的时候不能只看一侧而应该关注左右两边的信息。
这种训练方式使得模型能够学习到词汇之间的语义关系和上下文依赖。在BERT等模型中,这种掩码策略通常包括将80%的词汇被替换为MASK,10%被替换为随机词汇,剩余10%保持不变 。这样的随机替换策略既保证了模型能够学习到足够的上下文信息,又避免了模型过度依赖MASK标记而忽略真实的词汇信息 。

预训练任务二:下一句子预测NSP
NSP:
NSP的样本如下:
- 从训练语料库中取出两个连续的段落作为正样本
- 从不同的文档中随机创建一对段落作为负样本
也就是预测:预测一个句子对中两个句子是不是相邻的这一个任务了。
也就是让我们的训练样本中:50%概率选择相邻句子对:50%概率选择随机句子对:将对应的输出放到一个全连接层来预测。
最后需要解释的就是我们输入的token序列对是如何进行的它包含的两个字符[CLS]和[SEP]的两个部分。
- 每个序列的标记始终是一个特殊的分类标记([CLS])
- 句子对被打包成一个序列。 我们以两种方式区分句子。 首先,我们用一个特殊的标记([SEP])将它们分开。

下面的这个图就是我们嵌入层的一个关系图也就是之前提到的编码方式。

-
Input:作为词嵌入层的一个输入属于是这里的[CLS]是用于NSP任务的一个标志词[SEP]用来将两个句子断开。
-
第二部分的Segment Embeddings层这里将我们的第一个句子的编码EA设置为0,第二个部分的编码设置为1即可
-
第三部分是位置编码的部分:这里是随机初始化让我们的模型自己学习出来
微调
更多的情况下我们不会去预训练一个BERT的模型而是使用大公司给我们预训练模型并在此基础上进行微调的操作。
也就是如何更好的将我们的BERT应用到下游的任务中去。
这里的微调就是:
- 在相同领域 上继续训练LM (Domain transfer)
- 在任务相关的小数据上继续训练LM(Tasktransfer)
相关文章:
大模型基础BERT——Transformers的双向编码器表示
大模型基础BERT——Transformers的双向编码器表示 整体概况 BERT:用于语言理解的深度双向Transform的预训练 论文题目:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding Bidirectional Encoder Representations from…...
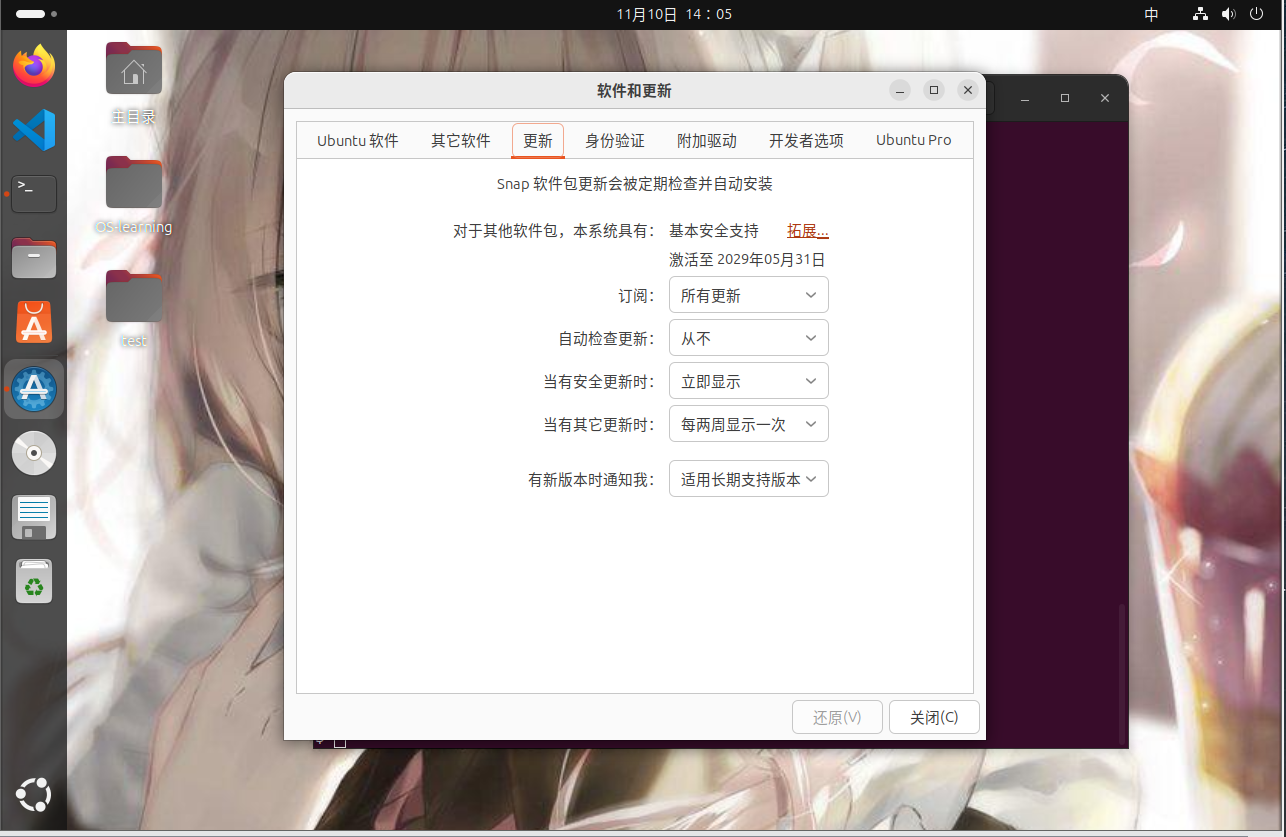
怎么禁止Ubuntu自动更新升级
怎么禁止Ubuntu自动更新升级 笔者在做MIT 6.S081的时候发现他给我的qemu自动更新了又卡住了,故关闭了自动更新 文章目录 怎么禁止Ubuntu自动更新升级一、图形化修改二、基于命令行修改配置文件的方法 一、图形化修改 1.打开设置->软件和更新->更新 2.选择自…...

【SpringBoot】20 同步调用、异步调用、异步回调
Git仓库 https://gitee.com/Lin_DH/system 介绍 同步调用:指程序在执行时,调用方需要等待函数调用返回结果后,才能继续执行下一步操作,是一种阻塞式调用。 异步调用:指程序在执行时,调用方在调用函数后立…...

【Excel】数据透视表分析方法大全
数据透视表的最常用的功能是分类汇总,其实它还有很强大的数据分析功能。在数据透视表右键菜单的值显示方式中,可以看到有14个很实用的分析选项。 1、总计的百分比 作用:透视表中每一个数字(包括汇总行、总计行)占右…...

深度学习在边缘检测中的应用及代码分析
摘要: 本文深入探讨了深度学习在边缘检测领域的应用。首先介绍了边缘检测的基本概念和传统方法的局限性,然后详细阐述了基于深度学习的边缘检测模型,包括其网络结构、训练方法和优势。文中分析了不同的深度学习架构在边缘检测中的性能表现&am…...

k8s 1.28.2 集群部署 docker registry 接入 MinIO 存储
文章目录 [toc]docker registry 部署生成 htpasswd 文件生成 secret 文件 生成 registry 配置文件创建 service创建 statefulset创建 ingress验证 docker registry docker registry 监控docker registry ui docker registry dockerfile docker registry 配置文件 S3 storage dr…...

常用的生物医药专利查询数据库及网站(很全!)
生物医药专利信息检索是药物研发前期不可或缺的一步,通过对国内外生物医药专利网站信息查询,可详细了解其专利技术,进而有效降低药物研发过程中的风险。 目前主要使用的生物医药专利查询网站分为两大类,一个是免费生物医药专利查询…...

「QT」几何数据类 之 QPolygon 多边形类
✨博客主页何曾参静谧的博客📌文章专栏「QT」QT5程序设计📚全部专栏「VS」Visual Studio「C/C」C/C程序设计「UG/NX」BlockUI集合「Win」Windows程序设计「DSA」数据结构与算法「UG/NX」NX二次开发「QT」QT5程序设计「File」数据文件格式「PK」Parasolid…...

写给初学者的React Native 全栈开发实战班
React Native 全栈开发实战班 亲爱的同学们: 很高兴在这里与大家相聚!我是你们的讲师,将带领大家一起踏上 React Native 移动开发的学习之旅。 为什么选择 React Native? 在这个移动互联网时代,App 开发工程师已经…...

工作和学习遇到的技术问题
写在前面 记录工作和学习遇到的技术问题,以求再次遇到可以快速解决。 1:Ubuntu TSL换源报错:Err:1 http://mirrors.aliyun.com/ubuntu focal InRelease 执行如下操作(已经操作的则忽略),首先在文件/etc/apt/sources…...

如何解决JAVA程序通过obloader并发导数导致系统夯住的问题 | OceanBase 运维实践
案例背景 某保险机构客户的数据中台,自系统上线后不久,会定期的用 obload 工具从上游业务系统导入数据至OceanBase数据库。但,不久便遇到了应用服务器的 Memory 与 CPU 资源占用持续攀升,最终导致系统夯住而不可用的异常。 memo…...

Git零基础到入门
一、开始工作区 clone: 克隆一个仓库到新的目录。 git clone https://github.com/username/repository.git init: 创建一个新的空 Git 仓库或重新初始化现有的仓库,新建git项目。 //创建项目两种方式 //一、本地项目自己创建项目,先创建好工作文件夹,通…...

HTTP 1.0、HTTP 1.1 和 HTTP 2.0 区别
HTTP 1.0、HTTP 1.1 和 HTTP 2.0 是超文本传输协议(HTTP)不同版本的规范,各自进行了多项更新和改进: 1. HTTP/1.0 单一请求-响应:每次请求都需要建立一个新的 TCP 连接,完成后立即断开。无状态连接&#…...

解决 ElSelect 数据量大导致加载速度慢
遇到一个性能相关的问题,使用 Element Plus 的 <ElSelect> 组件在数据量很大时,加载速度变慢。 下面简单分析下原因,并提供了一些解决方法。 1. 问题分析 1、大量 DOM 节点渲染 问题:当数据量非常大时,每一个…...

在 CentOS 系统中,您可以使用多种工具来查看网络速度和流量
在 CentOS 系统中,您可以使用多种工具来查看网络速度和流量 在 CentOS 系统中,您可以使用多种工具来查看网络速度和流量1. 使用 iftop安装 iftop使用 iftop 2. 使用 nload安装 nload使用 nload 3. 使用 vnstat安装 vnstat初始化 vnstat查看流量 4. 使用 …...

分布式----Ceph部署
目录 一、存储基础 1.1 单机存储设备 1.2 单机存储的问题 1.3 商业存储解决方案 1.4 分布式存储(软件定义的存储 SDS) 1.5 分布式存储的类型 二、Ceph 简介 三、Ceph 优势 四、Ceph 架构 五、Ceph 核心组件 #Pool中数据保存方式支持两种类型&…...
使用 PyTorch 实现 AlexNet 进行 MNIST 图像分类
AlexNet 是一种经典的深度学习模型,它在 2012 年的 ImageNet 图像分类比赛中大放异彩,彻底改变了计算机视觉领域的格局。AlexNet 的核心创新包括使用深度卷积神经网络(CNN)来处理图像,并采用了多个先进的技术如 ReLU 激…...

Python爬虫项目 | 一、网易云音乐热歌榜歌曲
文章目录 1.文章概要1.1 实现方法1.2 实现代码1.3 最终效果 2.具体讲解2.1 使用的Python库2.2 代码说明2.2.1 创建目录保存文件2.2.2 爬取网易云音乐热歌榜单歌曲 2.3 过程展示 3 总结 1.文章概要 学习Python爬虫知识,实现简单的一个小案例,网易云音乐热…...

【Linux】HTTP协议和HTTPS加密
文章目录 HTTP1、概念2、认识URL3、协议格式、请求方法和状态码4、HTTP请求和响应报头5、Cookie和Session HTTPS1、对称和非对称加密2、对称非对称加密安全分析3、证书 HTTP 1、概念 我们在应用层定制协议时,不建议直接发送结构体对象,因为在不同的环境…...

Linux编辑/etc/fstab文件不当,不使用快照;进入救援模式
目录 红帽镜像9救援模式 现象 解决 第一步:修改启动参数以进入救援模式 第二步:进入救援模式、获取root权限、编辑/etc/fstab文件 第三步:编辑好后在重启 下面是ai给的模板 红帽镜像9救援模式 编辑/etc/fstab不当时 17 /dev/nvme0n3p1…...

Steam Deck Tools 终极指南:让 Windows 掌机体验焕然一新
Steam Deck Tools 终极指南:让 Windows 掌机体验焕然一新 【免费下载链接】steam-deck-tools (Windows) Steam Deck Tools - Fan, Overlay, Power Control and Steam Controller for Windows 项目地址: https://gitcode.com/gh_mirrors/st/steam-deck-tools …...

3分钟快速上手Inter字体:免费开源字体如何提升你的数字产品体验
3分钟快速上手Inter字体:免费开源字体如何提升你的数字产品体验 【免费下载链接】inter The Inter font family 项目地址: https://gitcode.com/gh_mirrors/in/inter Inter字体是一款专为屏幕显示设计的开源无衬线字体,凭借其出色的可读性和多语言…...

LeetCode 前K个高频元素题解
LeetCode 前K个高频元素题解 题目描述 给定一个数组,找到前 k 个高频元素。 示例: 输入:nums [1,1,1,2,2,3], k 2输出:[1,2] 解题思路 方法:堆 思路: 使用哈希表统计每个元素出现的次数。使用最小堆维护前…...

FanControl:Windows平台终极风扇控制解决方案
FanControl:Windows平台终极风扇控制解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanCont…...

FPGA与Jetson异构计算:破解机器视觉高带宽实时处理难题
1. 项目概述:当FPGA遇上Jetson,一台为视觉而生的“小钢炮”在机器视觉和工业检测这个行当里干了十几年,我经手过不少号称“高性能”的嵌入式系统。它们要么是体积硕大、功耗惊人的工控机,要么是接口单一、扩展性堪忧的嵌入式板卡。…...

AMD游戏本ChinaJoy三连发:从3D V-Cache到性价比旗舰的全面解析
1. 项目概述:ChinaJoy 2023上的AMD游戏本盛宴每年ChinaJoy不仅是游戏玩家的狂欢,更是硬件厂商展示肌肉的舞台。今年,这个舞台的主角无疑是AMD。当大家还在讨论移动端处理器核心数大战时,AMD直接甩出了“缓存为王”的王炸ÿ…...

企业级应用如何通过taotoken统一管理多个大模型api调用与成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken统一管理多个大模型API调用与成本 对于需要集成多种大语言模型的企业技术团队而言,直接对接…...

2026年DRAM价格暴涨194%深度分析:AI服务器跨界抢芯,苹果为何丧失议价特权?
一、194%涨幅:1978年以来最大单年涨幅 2026年DRAM价格全年涨幅预计达到194%——这是什么概念?比2017年比特币挖矿带动的内存涨价(+88%)还高出两倍,更是2023年AI爆发初期涨幅(+47%)的4倍以上。 涨价的核心驱动力不是"挖矿",而是AI服务器对内存的海量需求。 …...

Input Leap跨设备键盘鼠标共享3步配置指南
Input Leap跨设备键盘鼠标共享3步配置指南 【免费下载链接】input-leap Open-source KVM software 项目地址: https://gitcode.com/gh_mirrors/in/input-leap Input Leap是一款功能强大的开源KVM软件,能够帮助用户在不同操作系统和设备之间实现键盘鼠标的完美…...

终极指南:5步掌握UnityPackage Extractor高效提取Unity资源包
终极指南:5步掌握UnityPackage Extractor高效提取Unity资源包 【免费下载链接】unitypackage_extractor Extract a .unitypackage, with or without Python 项目地址: https://gitcode.com/gh_mirrors/un/unitypackage_extractor UnityPackage Extractor是一…...