云岚到家 秒杀抢购
目录
秒杀抢购业务特点
常用技术方案
抢券
抢券界面
进行抢券
我的优惠券列表
活动查询
系统设计
活动查询分析
活动查询界面显示了哪些数据?
面向高并发如何提高活动查询性能?
如何保证缓存一致性?
数据流
Redis数据结构设计
如何保证活动状态自动改变
如何实现活动状态的自动改变?
定时预热程序
明确需求
活动查询接口
实时性问题
peek()是中间操作方法,它的主要功能是对流中的每个元素执行一个操作(可以是获取、修改或打印等),而不影响流的整体处理流程。这意味着即使使用了peek(),流也可以继续进行后续的映射、过滤或其他操作。但是他一定要在终端操作前执行(collect(), forEach(), reduce()等),如果没执行终端操作,则peek不执行。
更新活动状态,活动预热总结:
抢券
解决超卖问题
系统需求
什么是超卖问题
悲观锁与乐观锁
Redis分布式锁方案
Redis原子操作方案
Redis原子操作方案
Redis+Lua实现
redis中使用EVAL 命令执行Lua脚本。
下边是使用RedisTemplate执行Lua脚本的方法:
抢券整体方案
抢券方案分析
数据流
Redis数据结构
小结
库存同步
抢券接口开发
抢券service方法
抢券结果同步
Redis到MySQL同步方案分析
如何使用线程池?
Redisson分布式锁
问题分析
Redisson实现分布式锁
看门狗机制
数据同步组件
理解数据同步组件原理
抢券结果同步开发
编写扣减库存方法
秒杀抢购业务特点
时间限制: 秒杀抢购活动通常在特定的时间段内进行,例如1小时或更短的时间。在这个时间段内,消费者可以购买特定商品或服务,通常是限量销售。
限量销售: 秒杀抢购商品通常数量有限,销售数量是提前确定的。一旦库存售罄,抢购活动就结束,未能购买的消费者需要等待下一次活动。
价格优惠: 秒杀抢购商品通常以折扣价格销售,价格较平时低廉。这种价格优势是吸引消费者参与抢购的重要因素。
高并发和服务器压力: 抢购开始时大量用户会同时访问在线商城,导致网站服务器承受巨大压力。因此,网站的服务器和网络基础设施需要具备高并发处理能力,以应对瞬时大量的用户请求。
技术要求高: 秒杀抢购业务对技术要求非常高,包括网站性能优化、数据库优化、缓存技术、负载均衡等方面的技术应用。
常用技术方案
实现秒杀抢购业务会用到哪些技术呢?可以参考行业上一些成熟的解决方案。
缓存方案
使用缓存技术(如Redis)来存储热点数据,例如商品信息和库存数量。这样可以减轻数据库的压力,提高读取数据的速度。
异步处理方案
当用户成功秒杀后,将抢购信息发送到队列,然后由消费者多线程异步处理订单,减轻系统的实时压力,使用Redis、RabbitMQ等技术都可以实现队列。
防止超卖方案
超卖是最终下单购买数量大于库存数量,比如:库存100个用户最终购买了101个,多出这一个就是超卖了,在秒杀抢购业务中这也是需要解决的问题,可以使用分布式锁、Redis等技术都可以防止超卖。
限流与防刷方案
使用限流算法(如令牌桶、漏桶算法)来控制请求的并发数,防止服务器被过多请求压垮。可以在服务端使用限流技术,比如:sentinel、nginx、验证码等技术。
数据库优化方案
对数据库进行优化,包括索引的设计、SQL语句的优化、数据库连接池的使用等,以提高数据库的查询和更新速度。
数据库分库分表方案
在数据库层面进行分库分表,将数据分散存储在不同的数据库实例或表中,提高数据库的读写性能。
负载均衡
使用负载均衡技术,例如Nginx、Spring Cloud Gateway等,将请求分发到多个服务器上,增加系统的处理能力。
CDN加速
CDN(Content DeliveryNetwork)即内容分发网络,CDN用于加速静态资源的访问,将内容分发到CDN节点就近为客户提供服务。
安全性处理
确保系统的安全性,防止SQL注入、XSS攻击(跨站脚本攻击)等,同时在后端实现防刷、验证码等安全措施,保护系统免受恶意攻击。
抢券
抢券界面
用户进入抢券界面如下图。
“疯抢中”界面展示进行中还未到结束的优惠券活动,按照开始时间升序排列,不进行分页。
“即将开始”界面是展示1个月内待发放的优惠券活动,按照开始时间升序排列,不进行分页。

进行抢券
优惠券到达发放时间后,用户点击“立即领取”进行抢券。

我的优惠券列表
用户抢券成功在我的优惠券列表查看。
用户进入【我的】-【优惠券】查看已抢到的优惠券,按抢券时间降序显示当前用户抢到的优惠券。
本查询为滚动查询,向上拖屏幕查询下一屏,一屏显示10条。
对优惠券的三个状态说明如下:
未使用:未过有效期的优惠券。
优惠券的有效期:从领取优惠券的时间加上优惠券的使用期限(“使用期限”在优惠券活动管理界面进行设置)。
已使用:已经在订单中使用的优惠券。
已过期:未使用且已过有效期的优惠券,已过期的优惠券将无法使用。
查询没有进行分页查询,就是普通查询,按照时间顺序查询,然后传入最后一个id,这样可以加快查询速度。

@GetMapping("/my")@ApiOperation("我的优惠券列表")@ApiImplicitParams({@ApiImplicitParam(name = "lastId", value = "上一次查询最后一张优惠券id", required = false, dataTypeClass = Long.class),@ApiImplicitParam(name = "status", value = "优惠券状态,1:未使用,2:已使用,3:已过期", required = true, dataTypeClass = Long.class)})public List<CouponInfoResDTO> queryMyCouponForPage(@RequestParam(value = "lastId", required = false) Long lastId,@RequestParam(value = "status", required = true) Integer status) {return couponService.queryForList(lastId, UserContext.currentUserId(), status);}public List<CouponInfoResDTO> queryForList(Long lastId, Long userId, Integer status) {// 1.校验if (status > 3 || status < 1) {throw new BadRequestException("请求状态不存在");}// 2.查询准备LambdaQueryWrapper<Coupon> lambdaQueryWrapper = new LambdaQueryWrapper<>();// 查询条件lambdaQueryWrapper.eq(Coupon::getStatus, status).eq(Coupon::getUserId, userId).lt(ObjectUtils.isNotNull(lastId), Coupon::getId, lastId);// 查询字段lambdaQueryWrapper.select(Coupon::getId);// 排序lambdaQueryWrapper.orderByDesc(Coupon::getId);// 查询条数限制lambdaQueryWrapper.last(" limit 10 ");// 3.查询数据(数据中只含id)List<Coupon> couponsOnlyId = baseMapper.selectList(lambdaQueryWrapper);//判空if (CollUtils.isEmpty(couponsOnlyId)) {return new ArrayList<>();}// 4.获取数据且数据转换// 优惠id列表List<Long> ids = couponsOnlyId.stream().map(Coupon::getId).collect(Collectors.toList());// 获取优惠券数据List<Coupon> coupons = baseMapper.selectBatchIds(ids);// 数据转换return BeanUtils.copyToList(coupons, CouponInfoResDTO.class);}活动查询
系统设计
活动查询分析
下边根据需求分析对抢券界面的活动查询功能进行分析与设计,如下图:

活动查询界面显示了哪些数据?
活动信息:
包括两个部分数据:
-
进行中还未到结束的优惠券活动。
-
1个月内待开始的优惠券活动。
信息内容包括:
优惠券活动名称
优惠券满减或折扣信息
活动的起止时间
是否抢光(根据库存剩余量判断)
活动的状态。
面向高并发如何提高活动查询性能?
此部分信息来源于优惠券活动表,由于抢券页面面向C端用户且请求并发量大,如何在高并发下提高活动查询的性能呢?
如果直接查询数据库无法满足需求并且对数据库造成巨大的压力从而影响其它功能使用数据库,我们可以使用缓存,将优惠券活动信息存入缓存,比如Redis,从Redis查询避免查询数据库。

如何保证缓存一致性?
通过定时预热程序保证缓存一致性,抢券页面列出的活动信息属于热点信息,对于热点信息通过定时预热防止缓存击穿,定时预热程序通过定时任务定时执行,定时将活动信息存入Redis。

数据流
根据以上分析设计数据流如下:

活动管理:运营人员进行优惠券活动管理,对活动表进行增删改查操作。
活动状态更新任务:根据活动的开始和结束时间更新活动状态。
活动预热任务:定时查询活动表信息存入Redis
抢券查询:从Redis查询活动预热信息。
Redis数据结构设计
活动预热任务定时查询活动表信息存入Redis,下边设计活动信息的缓存结构:
根据需求可知在抢券查询界面需要的数据全部来源于活动表,因为要预热的活动信息内容有限,我们可以将要预热的活动信息转为json串存入redis,活动查询程序读取json串也方便进行解析。
活动信息缓存结构设计如下:
redis结构:String类型
key: "ACTIVITY:LIST"
value: 符合条件的优惠券活动列表JSON数据。
过期时间:永不过期
缓存一致性方案:通过预热程序保证缓存一致性
如何保证活动状态自动改变
在活动查询界面如何保证活动状态实时改变,当到达活动开始时间活动状态变为“进行中”,在“疯抢中”界面显示,当活动结束在“疯抢中”界面将无法查询到。
关于活动状态的改变,在“优惠券活动管理实战”中完成了通过定时任务自动更新活动的状态,实现了如下需求:
1)对待生效的活动更新为进行中
到达发放开始时间状态改为“进行中”。
2)对待生效及进行中的活动更新为已失效
到达发放结束时间状态改为“已失效”

@Override
public void updateStatus() {LocalDateTime now = DateUtils.now();// 1.更新已经进行中的状态lambdaUpdate().set(Activity::getStatus, ActivityStatusEnum.DISTRIBUTING.getStatus())//更新活动状态为进行中.eq(Activity::getStatus, NO_DISTRIBUTE.getStatus())//检索待生效的活动.le(Activity::getDistributeStartTime, now)//活动开始时间小于等于当前时间.gt(Activity::getDistributeEndTime,now)//活动结束时间大于当前时间.update();// 2.更新已经结束的lambdaUpdate().set(Activity::getStatus, LOSE_EFFICACY.getStatus())//更新活动状态为已失效.in(Activity::getStatus, Arrays.asList(DISTRIBUTING.getStatus(), NO_DISTRIBUTE.getStatus()))//检索待生效及进行中的活动.lt(Activity::getDistributeEndTime, now)//活动结束时间小于当前时间.update();
}
但是这样存在一个问题 因为是定时任务不能做到每秒都那么准确那怎么办呢?
通过上边的定时任务无法实现状态的实时改变,每分钟执行一次状态变更理论上存在最多1分钟的状态变更延迟
如何实现在页面到达活动开始时间立即变更活动状态?
-
在前端进行控制,根据活动开始时间进行倒计时,达到开始时间将活动移到进行中界面。
-
请求后端查询数据,根据当前时间和活动开始、活动结束时间判断活动的状态。
当活动开始时间小于等于当前时间并且结束时间大于当前时间说明活动已经开始并且还没有结束,活动状态为进行中。
当活动结束时间小于当前时间说明活动结束,活动状态为失效。
如何实现活动状态的自动改变?
-
通过定时任务每几分钟更新活动状态
对于待生效的活动,当活动开始时间小于等于当前时间并且结束时间大于当前时间,将活动状态更新为进行中。
对于待生效和进行中的活动,当活动结束时间小于当前时间,将活动状态更新为失效。
如何实现状态变化的实时性,当到达活动开始时间状态立即变化:
两种方法结合:
-
前端请求后端接口查询活动信息,后端根据活动时间(开始、结束时间)及当前时间得到活动当前准确的状态,并将状态返回给前端。
-
前端进行控制,根据活动开始时间进行倒计时,达到开始时间将活动移到进行中界面。
定时预热程序
明确需求
根据需求预热的活动信息包括两个部分:(尽管这里状态可能不对,但是一个月之内的活动我们都都歘出来了,最后后面我们在查询的时候跟根据当前时间再重新判断一下活动状态)
进行中还未到结束的优惠券活动。
1个月内待开始的优惠券活动。

in 后面 是arrays,aslist(),为了防止缓存穿透,没有数据就缓存空数据,存入优惠卷的时候 同时也要写入库存。这里的泛型都是object,你put进去的值也是object类型

可以通过定时预热程序中将优惠券活动的库存同步到Redis,同步规则如下:
-
对于待生效的活动更新库存。
-
对于已生效的活动如果库存已经同步则不再同步,只更新没有同步库存的活动。
做第二点的原因是为了避免时间差问题,活动状态更改为进行中了但是库存还没有同步到Redis。
public void preHeat() {LocalDateTime now = DateUtils.now();// 获取未来一个月内的待开始和已经开始的活动List<Activity> list = lambdaQuery().lt(Activity::getDistributeStartTime, now.plusDays(30)).in(Activity::getStatus, Arrays.asList(NO_DISTRIBUTE.getStatus(), DISTRIBUTING.getStatus())).orderByAsc(Activity::getDistributeStartTime).list();// 防止缓存穿透if (CollUtils.isEmpty(list)){list = new ArrayList<>();}// 类型转换List<SeizeCouponInfoResDTO> seizeCouponInfoResDTOS = BeanUtils.copyToList(list, SeizeCouponInfoResDTO.class);String jsonStr = JsonUtils.toJsonStr(seizeCouponInfoResDTOS);// 写入缓存redisTemplate.opsForValue().set(ACTIVITY_CACHE_LIST, jsonStr);// 存入库存// 待生效活动的存入库存list.stream().filter(v-> NO_DISTRIBUTE.getStatus() == getStatus(v.getDistributeStartTime(),v.getDistributeEndTime(),v.getStatus())).forEach(o->{redisTemplate.opsForHash().put(String.format(COUPON_RESOURCE_STOCK, o.getId() % 10),o.getId(),o.getStockNum());});// 进行中的活动存入库存list.stream().filter(v-> DISTRIBUTING.getStatus() == getStatus(v.getDistributeStartTime(),v.getDistributeEndTime(),v.getStatus())).forEach(o->{redisTemplate.opsForHash().putIfAbsent(String.format(COUPON_RESOURCE_STOCK, o.getId() % 10),o.getId(),o.getStockNum());});}活动查询接口

界面有两个tab,疯抢中和即将开始,前端传入后端一个参数标记是查询进行中的活动还是即将开始的活动。
后端需要给前端返回以下数据:

实时性问题
这些信息在预热的活动信息缓存中都存在,但是有两个字段不够实时:活动状态,优惠券剩余数量。
活动状态:通过定时任务更新活动状态,写入活动表,定时预热程序读出活动信息存储到Redis,由于是通过定时任务更新活动状态、定时预热程序更新活动信息缓存,最终从redis取出的活动状态于实际的活动状态存在延迟,导致实际活动的状态与页面显示的状态不一致。
示例:活动开始时间为8点钟,当前时间已过了8点钟,查看抢券页面活动状态仍然显示“即将开始”。
优惠券剩余数量:在抢券模块会操作此字段,这里暂不考虑此字段。
如何解决活动状态延迟问题?
当点击查询某个状态的活动时,请求后端查询数据,从redis中取出来数据,根据当前时间和活动开始、活动结束时间判断活动的状态。然后变更状态返回。
当活动开始时间小于等于当前时间并且结束时间大于当前时间说明活动已经开始并且还没有结束,活动状态为进行中。
当活动结束时间小于当前时间说明活动结束,活动状态为失效。

@GetMapping("/list")@ApiOperation("用户端抢券列表分页接口")@ApiImplicitParams({@ApiImplicitParam(name = "tabType", value = "页面tab类型,1:疯抢中,2:即将开始", required = true, dataTypeClass = Integer.class)})public List<SeizeCouponInfoResDTO> queryForPage(@RequestParam(value = "tabType",required = true) Integer tabType) {return null;}public interface IActivityService extends IService<Activity> {/*** 用户端抢券列表分页查询活动信息** @param tabType 页面类型* @return*/
List<SeizeCouponInfoResDTO> queryForListFromCache(Integer tabType);@Override
public List<SeizeCouponInfoResDTO> queryForListFromCache(Integer tabType) {//从redis查询活动信息Object seizeCouponInfoStr = redisTemplate.opsForValue().get(ACTIVITY_CACHE_LIST);if (ObjectUtils.isNull(seizeCouponInfoStr)) {return CollUtils.emptyList();}//将json转为ListList<SeizeCouponInfoResDTO> seizeCouponInfoResDTOS = JsonUtils.toList(seizeCouponInfoStr.toString(), SeizeCouponInfoResDTO.class);//根据tabType确定要查询的状态int queryStatus = tabType == TabTypeConstants.SEIZING ? DISTRIBUTING.getStatus() : NO_DISTRIBUTE.getStatus();//过滤数据,并设置剩余数量、实际状态List<SeizeCouponInfoResDTO> collect = seizeCouponInfoResDTOS.stream().filter(item -> queryStatus == getStatus(item.getDistributeStartTime(), item.getDistributeEndTime(), item.getStatus())).peek(item -> {//剩余数量item.setRemainNum(item.getStockNum());//状态item.setStatus(queryStatus);}).collect(Collectors.toList());return collect;
}/*** 获取状态,* 用于xxl或其他定时任务在高性能要求下无法做到实时状态** @return*/
private int getStatus(LocalDateTime distributeStartTime, LocalDateTime distributeEndTime, Integer status) {if (NO_DISTRIBUTE.equals(status) &&distributeStartTime.isBefore(DateUtils.now()) &&distributeEndTime.isAfter(DateUtils.now())) {//待生效状态,实际活动已开始return DISTRIBUTING.getStatus();}else if(NO_DISTRIBUTE.equals(status) &&distributeEndTime.isBefore(DateUtils.now())){//待生效状态,实际活动已结束return LOSE_EFFICACY.getStatus();}else if (DISTRIBUTING.equals(status) &&distributeEndTime.isBefore(DateUtils.now())) {//进行中状态,实际活动已结束return LOSE_EFFICACY.getStatus();}return status;
}peek()是中间操作方法,它的主要功能是对流中的每个元素执行一个操作(可以是获取、修改或打印等),而不影响流的整体处理流程。这意味着即使使用了peek(),流也可以继续进行后续的映射、过滤或其他操作。但是他一定要在终端操作前执行(collect(), forEach(), reduce()等),如果没执行终端操作,则peek不执行。
更新活动状态,活动预热总结:
我们通过定时任务更新活动的状态,定时任务事前把一个月以内的所有待开始以及进行中的活动保存到redis中,这里存在一个问题就是活动的状态存在一定的延迟。所以我们在查询的时候把redis中的数据取出来,根据当前时间在进行判断一次,然后啊过滤出符合条件的数据返回给前端。前端也可进行倒计时。到时间了 把活动添加进去即可。
通过定时任务更新活动状态,如何解决活动状态实时更新的问题?
-
前端请求后端接口查询活动信息
-
后端接口从redis查询活动信息,并根据活动开始和结束时间判断活动的最新状态
-
最后将活动信息及最新状态返回给前端。
抢券
解决超卖问题
系统需求
在抢券模块中需要实现下边两个需求:
1、提升高并发吞吐量
抢券类似抢购、秒杀等业务场景具有时效性的特点,提前规定好用户在什么时间可以抢购,用户访问集中,这样就会给系统造成高并发,抢券模块在设计时要以提升系统在高并发下的吞吐量为目标,吞吐量表示单位时间内系统处理的总请求数量,吞吐量高意味着系统处理能力强。
衡量系统吞吐量的常用指标有哪些?
QPS(Queries Per Second):
每秒查询数(Queries Per Second),它表示系统在每秒内能够处理的查询或请求的数量,是衡量一个系统处理请求的性能和吞吐量的指标。
计算公式:总请求数/时间窗口大小
示例:
在10秒内处理1万个请求,QPS为1000。每个请求处理的时间越短,QPS越大。
假设:一个网站有10万用户,有2万日活跃用户,并发量是4000,每个用户每秒平均发起2个请求,那么总请求数就是 2*4000,那么QPS就是 8000,如果单机支持2000的qps理论上需要4台服务器。
qps指标是需要根据服务器硬件性能、及具体的业务场景去测试,比如:门户查询数据如果直接走Nginx静态服务器则QPS可以达到上万,如果请求查询Tomcat,并且通过数据库去查询数据库返回,此时QPS会远低于查询Nginx静态服务器的QPS值,如果不走数据库,而是从Redis查询数其QPS也会大大提升。
TPS(Transactions Per Second):
表示系统每秒完成的事务数,与QPS不同,TPS更关注系统的事务处理能力,而不仅仅是单纯的查询或请求,一次事务通常会包括多个请求。在高度事务性的系统中,如在线交易系统、支付系统等,TPS是一个关键指标,用于衡量系统的处理能力。
TPS指标通常会涉及业务处理及数据库存储,在测试时也需要根据服务器硬件性能、及具体的业务场景去测试,拿下单举例:单机支持几十到几百的TPS指标属于正常。
在开发中,对以上性能指标的优化,可通过CDN、缓存、异步处理、数据库优化、多线程、集群、负载均衡等技术去提高系统的吞吐量。当然,再优化也不要忘记系统保护,通过限流技术根据系统的性能指标进行限流保护。
2、解决超卖问题
抢购、秒杀等业务场景还需要解决超卖问题,超卖是最终下单购买数量大于库存数量,比如:库存有100个,用户最终购买了101个,多出这一个就是超卖了,结合抢券业务即用户最终抢到的优惠券总数大于优惠券库存数。
下边先分析超卖问题的解决方案。
什么是超卖问题
超卖是最终下单购买数量大于库存数量,比如:库存100个用户最终购买成功了101个,多出这一个就是超卖了,结合抢券业务,用户最终抢到的优惠券总数大于优惠券库存数就出现了超卖问题。
导致超卖问题的原因是什么呢?
下边举例说明超卖问题并分析导致超卖问题的原因。
下图是两个线程更新数据库的库存字段。
线程1:先查询库存为1,判断是否大于0,如果大于则库存减1,最后更新数据库库存字段。
线程2:先查询库存为1,判断是否大于0,如果大于则库存减1,最后更新数据库库存字段。
线程1和线程2查询到的库存都是1,两个线程分别减1得到剩余库存数0,由于线程2并不是基于线程1扣减库存后的值进行扣减,线程2更新库存覆盖了线程1更新的库存值。
上边的例子就出现了超卖的问题。
造成超卖问题的原因是在高并发场景下对库存这个共享资源进行操作存在线程不安全所导致

悲观锁与乐观锁
提到解决线程安全问题大家想到了锁,下边复习下关于锁的基本概念。
jvm提供了很多锁,比如:synchronized、reentrantLock、CAS等,它们都可以解决线程安全问题,synchronized、reentrantLock可以实现悲观锁,CAS可以实现乐观锁
悲观锁
悲观锁是一种悲观思想,总认为会有其它线程修改数据,为了保证线程安全所以在操作前总是先加锁,操作完成后释放锁,其它线程只有当锁释放后才可以获取锁继续操作数据。synchronized和ReentrantLock都可以实现悲观锁。

使用悲观锁后原来的多线程并发执行改为了顺序(同步)执行,当线程2去执行时查询到库存发现为0,不满足条件更新库存失败。
乐观锁
乐观锁则是一种乐观思想,认为不会有太多线程去并发修改数据,所以谁都可以去执行代码。
Java提供的CAS机制可以实现乐观锁,CAS即Compare And Swap 比较并交换,在修改数据前先比较版本号,如果数据的版本号没有变化说明数据没有修改,此时再去更改数据。
示例如下:
库存数据对应一个版本,库存每次变化则版本号跟着变化,如下

线程1修改库存前拿到库存及对应的版本号:1和100。
线程1判断库存如果大于0则将库存减1,准备更新库存。
更新库存时要校验当前库存的版本是否和自己之前拿到的一致,如果版本号为1说明自己在执行的这过程没有其它线程去修改过库存,此时将库存更新为99并将库存加1为2。
线程2执行和线程1一样的逻辑,线程2去更新库存时发现库存的版本号为2与自己之前拿到的不一致,更新库存失败。
结论
悲观锁和乐观锁都是一种解决共享资源的线程安全问题的方法,悲观锁是在读数据时就加锁,如果读比较多则加锁频繁影响性能,相比而言乐观锁性能比悲观锁要好。
数据库行锁控制方案
数据库的行级锁可以实现悲观锁也可以实现乐观锁
1.实现悲观锁(排他锁)
执行select … for update 实现加锁,select … for update 会锁住符合条件的行的数据,如下语句会锁一行的数据


2.实现乐观锁
数据库的行级锁也可以实现乐观锁,通用的做法是在表中添加一个version版本字段,在更新时对比版本号,更新成功将版本号加1,SQL为:
![]()
针对扣减库存业务扣减库存SQL:
![]()
多线程执行上边的SQL,假如线程1先执行会添加排他锁,当事务没有结束前其它线程去更新同一条记录会被阻塞,等到线程1更新结束其它线程才可以更新库存。

当执行update后返回影响的记录行数为1表示更新成功即扣减库存成功,返回0表示没有更新记录行,即扣减库存失败。
结论
悲观锁在查询时就开始加锁,如果读比较多则加锁频繁影响性能,相比而言乐观锁性能比悲观锁要好。
对于并发不高的场景可以使用数据乐观锁去控制扣减库存,由于抢购业务并发较高且对性能要求也高,如果使用数据库行锁去控制,并发高就会对数据造成压力,如果进行限流控制并发数又无法满足性能要求,所以对于抢购业务使用数据库行锁进行控制是不适合的。
Redis分布式锁方案
数据库乐观锁不适用高并发场景,我们将库存数据放在Redis,并且通过JVM锁去控制扣减库存?
上边介绍的synchronized、reentrantLock、CAS只控制了JVM本身的线程争抢同一个锁,无法控制多个JVM之间争抢同一个锁。
如下图,有两个JVM进程,每个JVM进程都有一个Lock01锁,这两个JVM进程中的线程1仍然会同时去修改库存:
线程1:先查询库存为1,判断是否大于0,如果大于则库存减1,最后更新Redis库存数据。
线程2:先查询库存为1,判断是否大于0,如果大于则库存减1,最后更新Redis库存数据。
此时就会出现修改库存数据的线程不安全问题。

所以,如果是单机环境下,使用JVM的锁在内存加锁可以解决资源并发访问的线程安全问题。
微服务架构的项目在部署时每个微服务会部署多个实例(JVM),每个实例就是一个JVM,如果要控制多个JVM之间争抢资源需要用到分布式锁,分布式锁是由一个统一的服务提供分布式锁服务,比如:使用redis、数据库都可以实现分布式锁,下边介绍分布式锁控制争抢资源的方法。
如下图:每个JVM中的线程去争抢同一个分布式锁,在扣减库存前先获取分布式锁,拿到锁再扣减库存,执行完释放锁之后其它JVM的线程才可以获取锁继续扣减库存,如下图:

上边的方案将库存放在Redis中避免与数据库交互,很大的提高的了执行效率,在分布式场景下使用分布式锁是一种常用的控制共享资源的方案。
分布式锁需要搭建独立的分布式锁服务(例如Redis、Zookeeper等),每次操作需要远程与分布式锁服务交互获取锁、释放锁(这也是一种网络开销),还有没有性能更高的方案呢?
Redis原子操作方案
上边使用分布式锁的方案每次操作需要远程与分布式锁服务交互获取锁、释放锁,有没有优化的方法避免申请锁与释放锁的交互呢?
在分布式锁方案中是在java程序扣减库存最后更新redis库存的值,能否使用redis的decr命令去扣减库存呢?


Redis Decr 命令将 key 中储存的数字值减一,并且具有原子性,Redis中所有命令都具有原子性。
原子性表示该命令在执行过程中是不被中断的,也就实现了多线程去执行decr命令扣减库存是顺序执行的,假如库存原来是100,扣减到0结束,多线程并发执行decr命令不会出现扣减次数超过100次,如下图:

基于这个思想可以对分布式锁方案优化如下:

此方案中没有使用分布式锁,而是基于Redis命令具有原子性的特点实现。
本项目使用Redis原子操作控制超卖问题。
Redis原子操作方案
在Redis原子操作方案中扣减库存使用decr命令实现,decr命令具有原子性,如果在扣减库存操作中有多个操作 ,那么整体还是原子性吗?如下图:

扣减库存逻辑如下:
1、首先查询库存
2、判断库存大小,如果大于0则扣减库存,否则 直接返回
3、记录抢券成功的记录,用于判断用户不能重复抢券的依据。
4、记录抢券同步的记录,用于后续的异步处理,将抢券结果保存到数据库。
如果上述四步整体不具有原子性仍然没有办法控制超卖问题,所以必须保证1、2、3步逻辑放在一起整体具有原子性。
如何保证多个Redis命令具有原子性呢?
通过 MULTI 事务命令实现
对于redis单个命令都是原子操作,现在要求扣减库存、写入抢券成功队列及写入同步队列保证原子性,多个redis命令如何保证原子性呢?
通过 MULTI 事务命令实现
下边的命令执行流程如下:
执行MULTI 标记首先标记一个事务块开始。
然后将要执行的命令加入队列。
将“HSET key1 field1 value2 field2 value2” 命令放入队列中,表示向key1中写入两个hashkey。
将“INCR key2”命令放入队列中,表示对key2自增1。
运行EXEC命令按顺序执行,整体保证原子性。

Pipeline与MULTI 的区别
pipline也可实现批量执行多个 redis命令,pipline与multi的区别是:
pipeline 是把多个redis指令一起发出去,redis并没有保证这些命令的执行是原子的;multi实现的是将多个命令作为事务块去执行,保证整个操作的原子性。
如果仅是执行多个命令不保证原子性那么使用pipeline 的性能要比multi要高,但是针对本项目要保证多个命令实现原子性的需求那么pipeline 不符合要求。
Redis+Lua实现
Lua 是一种强大、高效、轻量级、可嵌入的脚本语言,Lua体积小、启动速度快,从而适合嵌入在别的程序里,Lua可以用于web开发、游戏开发、嵌入式开发等领域。
参考:http://www.lua.org/docs.html,或者去百度搜索Lua中文教程。
对于Lua脚本语法非常容易理解,先不用系统的去学习,先把本项目使用的Lua脚本读懂即可,实际工作中用到时再参考本项目的脚本去写即可,不会的再查Lua 的语法。
先看一个例子,对上边的例子编写Lua脚本,如下:(这段命令是在redis中写的)
local ret = redis.call('hset', KEYS[1], ARGV[1], ARGV[2], ARGV[3], ARGV[4]);
redis.call('incr', KEYS[2]);
return ret..'';说明:
KEYS:表示在脚本中所用到的那些 Redis 键(key),这些键名参数可以在 Lua 中通过全局变量 KEYS 数组,KEYS[1]表示第一个key,KEYS[2]表示第2个key,依次类推。
ARGV:表示在脚本中所用到的参数,在 Lua 中通过全局变量 ARGV 数组访问,访问的形式和 KEYS 变量类似( ARGV[1] 、 ARGV[2] ,诸如此类),ARGV[1]表示第一个参数,ARGV[2]表示第二个参数,依次类推。
如何执行上边的Lua脚本呢?
redis中使用EVAL 命令执行Lua脚本。
EVAL是redis的命令本身具有原子性,整个脚本的执行具有原子性。
EVAL script numkeys key [key ...] arg [arg ...] -
script: 是一段 Lua 5.1 脚本程序。
-
numkeys: 用于指定键名参数的个数。
-
key [key ...]: 从 EVAL 的第三个参数开始算起,表示在脚本中所用到的那些 Redis 键(key),这些键名参数可以在 Lua 中通过全局变量 KEYS 数组,用 1 为基址的形式访问( KEYS[1] , KEYS[2] ,以此类推)。
-
arg [arg ...]: 附加参数,在 Lua 中通过全局变量 ARGV 数组访问,访问的形式和 KEYS 变量类似( ARGV[1] 、 ARGV[2] ,诸如此类)。
eval "local ret = redis.call('hset', KEYS[1], ARGV[1], ARGV[2], ARGV[3], ARGV[4]);
redis.call('incr', KEYS[2]);
return ret..'';" 2 test_key01 test_key02 field1 aa field2 bb说明:
eval后边的script参数即脚本程序,将上边的Lua脚本使用双引号括起来。
numkeys:为2表示2个key
之后传入key的名称(多key中间用空格分隔):test_key01 test_key02
key后边再传入ARGV 参数(多ARGV 中间用空格分隔):field1 aa field2 bb
测试结果如下所示:

返回2表示向hash中写入2个key
下边是使用RedisTemplate执行Lua脚本的方法:
这个T是返回值类型
<T> T execute(RedisScript<T> script, List<K> keys, Object... args)通过第一个参数类型指定要执行的Lua脚本,RedisScript的实现类是DefaultRedisScript,下边查阅DefaultRedisScript的源代码。

本项目使用第二种方法,在RedisLuaConfiguration中定义DefaultRedisScript bean
@Bean("seizeCouponScript")public DefaultRedisScript<Integer> seizeCouponScript() {DefaultRedisScript<Integer> redisScript = new DefaultRedisScript<>();//resource目录下的scripts文件下的seizeCouponScript.lua文件redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("scripts/seizeCouponScript.lua")));redisScript.setResultType(Integer.class);return redisScript;}lua脚本位置

百度的时候说是 回去不到数据返回的是nil?????
但是测试的时候 如果 判断是否是nil 就会出错(待解决,暂定为没有数据返回false)
-- 抢券lua实现
-- key: 抢券同步队列,资源库存,抢券成功列表
-- argv:活动id,用户id--优惠券是否已经抢过
-- -1: 限领一张
-- -2: 已抢光
-- -3: 写入抢券成功队列失败,返回给用户为:抢券失败
-- -4: 已抢光
-- -5: 写入抢券同步队列失败,返回给用户为:抢券失败
local couponNum = redis.call("HGET", KEYS[3], ARGV[2])
-- hget 获取不到数据返回false而不是nil
if couponNum ~= false and tonumber(couponNum) >= 1
thenreturn "-1";
end
-- --库存是否充足校验
local stockNum = redis.call("HGET",KEYS[2], ARGV[1])
if stockNum == false or tonumber(stockNum) < 1
thenreturn "-2";
end
--抢券列表
local listNum = redis.call("HSET",KEYS[3], ARGV[2], 1)
if listNum == false or tonumber(listNum) < 1
thenreturn "-3";
end--减库存
stockNum = redis.call("HINCRBY",KEYS[2], ARGV[1], -1)
if tonumber(stockNum) < 0
thenreturn "-4"
end
-- 抢单结果写入同步队列
local result = redis.call("HSETNX", KEYS[1], ARGV[2],ARGV[1])
if result > 0
thenreturn ARGV[1] ..""
end
return "-5"测试
只需要按顺序制定好他的key和参数即可
@Test
void test_seizeCouponScriptLua() {//argv:抢券活动idlong activityId = 1706183021040336896L;// argv: 用户idLong userId = 1694250327664218113L;int index = (int) (activityId % 10);//key: 抢券同步队列,资源库存,抢券成功列表// 同步队列redisKeyString couponSeizeSyncRedisKey = RedisSyncQueueUtils.getQueueRedisKey(COUPON_SEIZE_SYNC_QUEUE_NAME, index);// 资源库存redisKeyString resourceStockRedisKey = String.format(COUPON_RESOURCE_STOCK, index);// 抢券成功列表String couponSeizeListRedisKey = String.format(COUPON_SEIZE_LIST,activityId, index);// 抢券Object execute = redisTemplate.execute(seizeCouponScript, Arrays.asList(couponSeizeSyncRedisKey, resourceStockRedisKey, couponSeizeListRedisKey),activityId, userId);log.debug("seize coupon result : {}", execute);
}使用Lua脚本注意点
Lua脚本在redis集群上执行需要注意什么?
在redis集群下执行redis命令会根据key求哈希,确定具体的槽位(slot),然后将命令路由到负责该槽位的 Redis 节点上。
执行一次Lua脚本会涉及到多个key,在redis集群下执行lua脚本要求多个key必须最终落到同一个节点,否则调用Lua脚本会报错:ERR eval/evalsha command keys must be in same slot。
如何保证多个key落地到一个redis节点呢?
只要保证多个key的哈希值一致即可保证多个key落到一个redis节点上,这个如何实现呢?
解决方法:一次执行Lua脚本的所有key中使用大括号‘{}’且保证大括号中的内容相同,此时会根据大括号中的内容求哈希,因为内容相同所以求得的哈希数据相同所以就落在了同一个Redis节点。
测试如下:
在key名称后边添加{},大括号中写一个固定的值。


抢券整体方案
抢券方案分析
抢券的架构设计思想同抢券查询,将库存保存在Redis,避免抢券操作请求数据库,通过异步任务将Redis中的抢券结果同步到数据库。
抢券的交互流程如下:

说明如下:
1、由预热程序将待生效库存同步到redis(活动开始将不允许更改库存)
2、活动开始后,抢券程序请求Redis扣减库存,扣减库存成功向抢券成功队列和抢券同步队列写入记录
Redis中两个队列的作用如下:
抢券成功队列:为了校验用户是否抢过该优惠券。
抢券同步队列:将抢券结果同步到数据库
3、通过定时任务程序根据Redis中同步队列记录的用户抢券结果信息将数据同步到MySQL,具体操作如下:
向优惠券表插入用户抢券记录。
更新优惠券活动表的库存。
写入数据库完成后删除Redis中同步队列的相应记录,删除后表示同步完成,如果同步过程失败将保留Redis同步队列的相应记录。
数据流
根据交互流程分析数据流如下:

Redis数据结构
活动信息
缓存结构:String类型:
key: "ACTIVITY:LIST"
value: 符合条件的优惠券活动列表JSON数据。
过期时间:永不过期
缓存一致性方案:通过预热程序保证缓存一致性
优惠券活动库存
缓存结构:Hash
RedisKey:COUPON:RESOURCE:STOCK:{活动id%10}
{活动id%10}表示根据活动id除以10求余,通过这种方法将key分散到不同的redis服务器上,通过“活动id%10”表达式可知优惠券活动库存hash最多有10个。
HashKey:活动id
HashValue: 库存
过期时间:永不过期
缓存一致性方案:通过预热程序保证缓存一致性

抢券成功队列
缓存结构:Hash
RedisKey:COUPON:SEIZE:LIST:活动id_{活动id%10}
HashKey:用户id
HashValue:1
过期时间:永不过期

抢券同步队列
缓存结构:Hash
RedisKey:QUEUE:COUPON:SEIZE:SYNC:{活动id%10}
HashKey:用户id
HashValue:活动id
过期时间:永不过期

小结
抢券是怎么做的?或方案是什么?
抢券业务的Redis数据结构用的什么?具体说说
秒杀系统中如何进行流量削峰?
在秒杀系统中进行流量削峰是非常重要的,因为瞬时的高流量可能会导致系统崩溃或性能下降。以下是一些常见的流量削峰策略:
-
限流措施:通过控制请求的发放速率,可以有效地平滑流量,避免瞬时的高并发。
-
队列缓冲: 使用消息队列来缓冲请求,将瞬时的高并发请求进行缓存和排队。秒杀系统可以异步地从队列中取出请求进行处理,以平滑处理流量。
-
分批处理:将瞬时的高并发请求分批处理。不需要一次性处理所有请求,可以将请求按照一定的规模分批处理,以减轻数据库和系统的压力。
-
负载均衡:采用多节点部署,通过负载均衡器将流量分发到不同的服务器上。
-
熔断策略: 实现熔断机制,当系统达到一定的负载阈值时,暂时停止接受新的请求,防止系统崩溃。等到系统恢复后再重新开启。
-
缓存预热:在秒杀开始之前,提前将秒杀商品的信息加载到缓存中,减轻数据库的压力。
-
验证码和身份验证:引入验证码和身份验证机制,防止机器人或恶意请求,减少无效请求对系统的冲击。
-
数据库优化:对于秒杀系统,数据库通常是瓶颈之一。通过优化数据库结构、建立索引、使用缓存等手段来提高数据库的读写性能。
库存同步
根据整体方案分析,用户抢券要在Redis扣减库存,所以需要提前将优惠券活动的库存同步到Redis。
可以通过定时预热程序中将优惠券活动的库存同步到Redis,同步规则如下:
-
对于待生效的活动更新库存。
-
对于已生效的活动如果库存已经同步则不再同步,只更新没有同步库存的活动。
做第二点的原因是为了避免时间差问题,活动状态更改为进行中了但是库存还没有同步到Redis。
当用户抢券成功,Redis中的库存有了变化,如何将最新库存由Redis同步MySQL呢?
根据整体方案分析,在抢券结果同步程序中根据抢券结果修改数据库中的库存

预热程序中同步库存
@Override
public void preHeat() {....// 将待生效的活动库存写入redislist.stream().filter(v->getStatus(v.getDistributeStartTime(),v.getDistributeEndTime(),v.getStatus())==1).forEach(v->{redisTemplate.opsForHash().put(String.format(COUPON_RESOURCE_STOCK, v.getId() % 10), v.getId(), v.getTotalNum());});// 对于已生效的活动库存没有同步时再进行同步list.stream().filter(v->getStatus(v.getDistributeStartTime(),v.getDistributeEndTime(),v.getStatus())==2).forEach(v->{redisTemplate.opsForHash().putIfAbsent(String.format(COUPON_RESOURCE_STOCK, v.getId() % 10), v.getId(), v.getTotalNum());});
}对于待生效的活动库存使用put方法,可以对已设置的记录进行更改。
对已生效的活动库存使用putIfAbsent实现,当key不存在时才执行设置操作。
String.format(COUPON_RESOURCE_STOCK, v.getId() % 10) 用来拼装 key,库存的redis key为:
COUPON:RESOURCE:STOCK:{活动id%10}。
抢券接口开发
请求哪些参数?
抢券需要明确两个元素: 哪个用户抢的是哪个活动的优惠券。
用户的身份信息在token中由前端传入服务端。
所以,本接口需要传入服务端的参数是活动ID。
传入参数:活动ID。
响应结果:无,通过状态码判断。
@Overridepublic void seizeCoupon(SeizeCouponReqDTO seizeCouponReqDTO) {// 1.校验活动开始时间或结束// 首先从缓存查询活动// 2.抢券准备
// key: 抢券同步队列,资源库存,抢券列表
// argv:抢券id,用户id// 3.执行lua脚本进行抢券结果// 4.处理lua脚本结果,失败的抛出异常,成功的正常返回}如何校验活动是否有效?
1、从缓存中查询指定活动的信息
抢券接口避免与数据库交互。
2、根据活动时间校验活动是否未开始或者已经结束,这两类活动不允许抢券
定义从缓存查询指定活动信息的方法
findFirst().orElse()
@Override
public ActivityInfoResDTO getActivityInfoByIdFromCache(Long id) {// 1.从缓存中获取活动信息Object activityList = redisTemplate.opsForValue().get(ACTIVITY_CACHE_LIST);if (ObjectUtils.isNull(activityList)) {return null;}// 2.过滤指定活动信息List<ActivityInfoResDTO> list = JsonUtils.toList(activityList.toString(), ActivityInfoResDTO.class);if (CollUtils.isEmpty(list)) {return null;}// 3.过滤指定活动return list.stream().filter(activityInfoResDTO -> activityInfoResDTO.getId().equals(id)).findFirst().orElse(null);
}抢券service方法
@Overridepublic void seizeCoupon(SeizeCouponReqDTO seizeCouponReqDTO) {// 1.校验活动开始时间或结束// 抢券时间ActivityInfoResDTO activity = activityService.getActivityInfoByIdFromCache(seizeCouponReqDTO.getId());LocalDateTime now = DateUtils.now();if (activity == null ||activity.getDistributeStartTime().isAfter(now)) {throw new CommonException(SEIZE_COUPON_FAILD, "活动未开始");}if (activity.getDistributeEndTime().isBefore(now)) {throw new CommonException(SEIZE_COUPON_FAILD, "活动已结束");}// 2.抢券准备
// key: 抢券同步队列,资源库存,抢券列表
// argv:抢券id,用户idint index = (int) (seizeCouponReqDTO.getId() % 10);// 同步队列redisKeyString couponSeizeSyncRedisKey = RedisSyncQueueUtils.getQueueRedisKey(COUPON_SEIZE_SYNC_QUEUE_NAME, index);// 资源库存redisKeyString resourceStockRedisKey = String.format(COUPON_RESOURCE_STOCK, index);// 抢券列表String couponSeizeListRedisKey = String.format(COUPON_SEIZE_LIST, activity.getId(), index);log.debug("seize coupon keys -> couponSeizeListRedisKey->{},resourceStockRedisKey->{},couponSeizeListRedisKey->{},seizeCouponReqDTO.getId()->{},UserContext.currentUserId():{}",couponSeizeListRedisKey, resourceStockRedisKey, couponSeizeListRedisKey, seizeCouponReqDTO.getId(), UserContext.currentUserId());// 3.抢券结果Object execute = redisTemplate.execute(seizeCouponScript, Arrays.asList(couponSeizeSyncRedisKey, resourceStockRedisKey, couponSeizeListRedisKey),seizeCouponReqDTO.getId(), UserContext.currentUserId());log.debug("seize coupon result : {}", execute);// 4.处理lua脚本结果if (execute == null) {throw new CommonException(SEIZE_COUPON_FAILD, "抢券失败");}long result = NumberUtils.parseLong(execute.toString());if (result > 0) {return;}if (result == -1) {throw new CommonException(SEIZE_COUPON_FAILD, "限领一张");}if (result == -2 || result == -4) {throw new CommonException(SEIZE_COUPON_FAILD, "已抢光!");}throw new CommonException(SEIZE_COUPON_FAILD, "抢券失败");}抢券结果同步
Redis到MySQL同步方案分析
如何将Redis中的抢券结果同步到MySQL的优惠券表(coupon)呢?
基本思路: 遍历Redis中的抢券结果同步队列,拿到一个元素就向数据库的优惠券表插入记录,插入完成后删除Redis中的这条记录。

我们可以一次从Hash表中拿一批数据,每个元素包括了用户id和活动id,根据这两个参数插入coupon表。
从下图可以看出,只要拿到用户id和活动id即可向优惠券表插入一条记录。

基本思路清楚,现在需要考虑:系统有多个活动,如何提高同步程序的处理性能呢?
假如同步队列的key为:QUEUE:COUPON:SEIZE:SYNC:{活动id % 10},这说明最多有10个同步列表。
我们可以用多线程,每个线程处理一个同步队列。

由定时任务去调度,每隔1分钟由多线程对同步队列中的数据进行处理。
如何使用线程池?
根据我们需求,假如同步队列个数为10我们需要定义一个最多有10个活跃线程的线程池,满负荷工作下每个线程处理一个同步队列,当满负荷工作时如果再有新的任务线程池拒绝任务。
定义一个线程池需要以下参数:
-
corePoolSize(核心线程数): 核心线程一直存活的线程池中,即使它们是空闲的也会被保留在池中。在执行新任务时,如果线程池中的线程数小于
corePoolSize,将会创建一个新的线程来执行任务。 -
maximumPoolSize(最大线程数): 池中允许的最大线程数。如果队列满了,并且活动线程数小于
maximumPoolSize,则会创建新的线程来处理任务。 -
keepAliveTime(线程空闲时间): 当线程池中的线程数量超过
corePoolSize时,多余的空闲线程的存活时间如果超过这个时间会被终止,直到线程数量不超过corePoolSize。这样可以确保在低负载时最小化资源消耗。 -
unit(时间单位):
keepAliveTime的时间单位,可以是TimeUnit.SECONDS、TimeUnit.MINUTES等。 -
workQueue(阻塞队列): 用于保存等待执行的任务的阻塞队列。
常用的阻塞队列:
LinkedBlockingQueue:链表结构,无界队列。
ArrayBlockingQueue:数组结构,有界队列。
SynchronousQueue:容量为1,在没有线程去消费时不会保存任务。
线程池的拒绝策略(RejectedExecutionHandler)定义了当线程池无法执行新任务时应该采取的策略。当线程池中的工作队列已满,并且线程池中的线程数已达到最大值时,新任务的处理方式由拒绝策略来确定。
如下:
- ThreadPoolExecutor.AbortPolicy 是默认的饱和策略。当任务添加到线程池中被拒绝时,会抛出 RejectedExecutionException 异常。
- ThreadPoolExecutor.CallerRunsPolicy 当任务被拒绝时,会使用调用线程池的线程来执行被拒绝的任务。
- ThreadPoolExecutor.DiscardPolicy 当任务被拒绝时,会默默地丢弃被拒绝的任务,不会抛出异常也不会执行被拒绝的任务。
- ThreadPoolExecutor.DiscardOldestPolicy 当任务被拒绝时,会丢弃队列中最老的一个任务,并尝试重新提交被拒绝的任务。

@Configuration
public class ThreadPoolConfiguration {@Bean("syncThreadPool")public ThreadPoolExecutor synchronizeThreadPool(RedisSyncProperties redisSyncProperties) {// 定义线程池参数int corePoolSize = 1; // 核心线程数int maxPoolSize = redisSyncProperties.getQueueNum(); // 最大线程数long keepAliveTime = 120; // 线程空闲时间TimeUnit unit = TimeUnit.SECONDS; // 时间单位// 指定拒绝策略为 DiscardPolicy RejectedExecutionHandler rejectedHandler = new ThreadPoolExecutor.DiscardPolicy();// 任务队列,使用SynchronousQueue容量为1,在没有线程去消费时不会保存任务ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maxPoolSize, keepAliveTime, unit,new SynchronousQueue<>(),rejectedHandler);return executor;}
}下边测试线程池:
分两轮向线程池提交任务,每轮提交10个任务。
任务要实现runnable (无返回值)或者 callable(有返回值)
@SpringBootTest
@Slf4j
public class SyncThreadPoolTest {public class RunnableSimple implements Runnable{//任务序号private int index;public RunnableSimple(int index){this.index = index;}@Overridepublic void run() {//执行任务log.info("{}执行任务:{}",Thread.currentThread().getId(),index);try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}}@Resource(name="syncThreadPool")private ThreadPoolExecutor threadPoolExecutor;@Testpublic void test_threadPool() throws InterruptedException {for (int i = 0; i < 10; i++) {threadPoolExecutor.execute(new RunnableSimple(i));}
// Thread.sleep(3000);延迟三秒,线程池的线程执行任务后空闲下来for (int i = 10; i < 20; i++) {threadPoolExecutor.execute(new RunnableSimple(i));}//主线程休眠一定的时间防止程序结束Thread.sleep(9999999);}}如果注释Thread.sleep(3000);,由于线程池最大线程数是10,提交10个任务后线程还没有空闲再提交新任务会被拒绝。
如果放开Thread.sleep(3000);,20个任务都会执行完成。
如何从Redis 批量取数据?
使用线程池处理的任务的代码完成测试,下边需要解决的是每个任务如何从Hash中拿一批数据呢?
我们使用redisTemplate.opsForHash().scan(H key, ScanOptions options)方法,scan方法通过游标的方式实现从hash中批量获取数据。这个游标返回的是键值对。这个游标中的泛型,是string和object 是为了让其更加通用,当然key你也可以定义其他类型,但是一定要类型对应。所以为了通用一般定义为string和object
@SpringBootTest
@Slf4j
public class SyncThreadPoolTest {public class RunnableSimple implements Runnable{private int index;public RunnableSimple(int index){this.index = index;}@Overridepublic void run() {//执行任务log.info("{}执行任务:{}",Thread.currentThread().getId(),index);//获取数据String queue = String.format("QUEUE:COUPON:SEIZE:SYNC:{%s}",index);log.info("开始获取{}队列的数据",queue);getData(queue);}
}
/*** 从同步队列拿数据* @param queue 队列名称*/public void getData(String queue) {Cursor<Map.Entry<String, Object>> cursor = null;// 通过scan从redis hash数据中批量获取数据,获取完数据需要手动关闭游标ScanOptions scanOptions = ScanOptions.scanOptions().count(10).build();try {// sscan获取数据cursor = redisTemplate.opsForHash().scan(queue, scanOptions);// 遍历数据转换成SyncMessage列表List<SyncMessage<Object>> collect = cursor.stream().map(entry -> SyncMessage.builder().key(entry.getKey().toString()).value(entry.getValue()).build()).collect(Collectors.toList());log.info("{}获取{}数据{}条", Thread.currentThread().getId(),queue,collect.size());collect.stream().forEach(System.out::println);}catch (Exception e){log.error("同步处理异常,e:", e);throw new RuntimeException(e);} finally {// 关闭游标if (cursor != null) {cursor.close();}}}}游标使用完之后要关闭

小结
1、使用线程池从多个同步队列中查询数据,每个线程处理一个同步队列。
注意:同步队列的个数可以灵活配置,但不宜过多,因为同步队列个数为最大线程数,通常配置10到20即可。
2、使用redisTemplate.opsForHash().scan(H key, ScanOptions options)方法从hash表获取数据。
这里需要注意游标的使用,一定要在finally 中关闭游标。
Redisson分布式锁
问题分析
多线程在执行任务时,如果多个线程从同一个Redis Hash中获取数据就会出现重复处理数据的问题。
下边的情况出现这个问题:
定时任务每隔1分钟调用线程池处理一个数据同步任务,假如同步队列1的数据非常多,一轮结束后线程1还在处理同步队列1的数据,此时当第二轮开始又会从同步队列1开始分配线程去处理,将会找一个空闲线程去处理同步队列1的数据,此时将会有多个线程处理一个同步队列的数据。

这个问题如何解决呢?
在前边我们介绍超卖方案时提到了使用锁去控制共享资源访问,对于分布式系统我们使用分布式锁去控制。
如下图:每个同步队列使用一把锁进行控制,当线程1还没有处理完时锁不进行释放,这样线程2就无法获取同步队列1的锁,解决了多个线程处理同一个队列的问题。
Redisson实现分布式锁
实现分布式锁的方案有很多:Redis、数据库、Zookeeper等,我们使用Redis实现分布式锁,使用Redis实现分布式锁可以使用的它的setNx命令,也可以使用Redisson工具去实现,本项目使用Redission去实现,关于setNx的知识可以参考视频(https://www.bilibili.com/video/BV1j8411N7Bm?p=181)自学。
Redisson 是一个用于 Java 开发的 Redis 客户端和分布式锁框架,它不仅可以实现分布式锁,还可以实现分布式集合(如 List、Set、Map 等)和分布式对象(如 AtomicInteger、AtomicLong、CountDownLatch 等),简单理解就是将JVM中内存存储的List、Set、AtomicInteger这些对象使用Redis去存储和管理。
使用Redisson的基本用法如下:
// 创建Redisson客户端
RedissonClient redissonClient = Redisson.create();
// 获取名为myLock的分布式锁实例,通过此实例进行加锁、解锁
RLock lock = redissonClient.getLock("myLock");try {// 尝试获取锁,最多等待3秒,持锁时间为5秒boolean isLockAcquired = lock.tryLock(3, 5, TimeUnit.SECONDS);if (isLockAcquired) {// 获取锁成功,执行业务逻辑} else {// 获取锁失败,处理相应逻辑}
} catch (InterruptedException e) {// 处理中断异常
} finally {// 释放锁lock.unlock();
}
说明:
lock.tryLock方法是一种非阻塞获取锁的方式,没有获取锁可以直接返回,而lock.lock()是一种阻塞获取锁的方法,多个线程通过lock()方法获取锁,只有一个线程获取到锁,其它线程将阻塞等待。
通常lock.tryLock方法使用的更广泛。
使用tryLock方法获取锁时传3个参数:
-
waitTime:尝试获取锁的最大等待时间,在这个时间范围内会不断地尝试获取锁,如果在
waitTime时间内未能获取到锁,则返回false。waitTime默认为-1,表示获取锁失败后立刻返回不重试。 -
leaseTime:表示持锁的时间,即锁的自动释放时间。在获取锁成功后,锁会在
leaseTime时间后自动释放。如果在持锁的时间内未手动释放锁,锁也会在leaseTime时间后自动释放。 -
TimeUnit:表示时间单位,可以是秒、毫秒等。
tryLock方法返回值:
true:获取到了锁
false:未获取到锁
下边我们进行测试
注意释放锁
lock.tryLock代码放在try中,在finally 中释放锁。
下边进行测试:
我们实现一个队列只有一个线程去处理数据,锁的粒度为队列,每个锁与队列对应,我们定义锁名称为"Lock:"加队列名称。
public class RunnableSimple2 implements Runnable {//任务序号private int index;public RunnableSimple2(int index) {this.index = index;}@Overridepublic void run() {// 指定锁名称,每个队列只有一个线程去处理,锁粒度为队列,锁名称在队列名称前加Lock:String lockName = String.format("Lock:QUEUE:COUPON:SEIZE:SYNC:{%s}",index);//队列名称String queue = String.format("QUEUE:COUPON:SEIZE:SYNC:{%s}",index);RLock lock = redissonClient.getLock(lockName);try {// 2.尝试获取锁,参数:waitTime、leaseTime、时间单位boolean isLock = lock.tryLock(3, 10, TimeUnit.SECONDS);if (isLock) {//执行任务log.info("{}执行任务:{}",Thread.currentThread().getId(),index);log.info("{}开始获取{}队列的数据",Thread.currentThread().getId(),queue);getDate(queue);//模拟执行任务的时长Thread.sleep(3000);}else{log.info("!!!!!!{}获取{}队列的锁失败",Thread.currentThread().getId(),queue);}} catch (Exception e) {e.printStackTrace();} finally {// 4.释放锁if (lock != null && lock.isLocked()) {lock.unlock();}}}
}
看门狗机制
什么是Redisson看门狗
学习了Redisson的基本使用现在有一个问题:
当设置了leaseTime的时间为10秒,结果任务执行了20秒,会出现什么问题?
由于锁的自动释放时间为10秒,当到达到10秒即使任务还没有结束锁将自动释放,此时就会有新线程获取该锁去执行任务,设置分布式锁的本意是当前只有一个线程去执行,出现这个问题会导致多个线程共同去执行任务,可能在并发处理上存在问题。
当执行任务的时间可以控制在一个范围就可以指定leaseTime锁自动释放时间,如果执行任务的时间不容易通过leaseTime去设置,此时可以使用Redisson的看门狗机制避免在任务没有完成时自动释放锁的问题发生。
Redisson的"看门狗机制"(Watchdog)是一种用于监测和维护锁的超时时间的机制,它可以确保在任务没有完成时对锁的过期时间进行自动续期,以避免任务没有完成时锁自动释放的问题。
开启看门狗后针对当前锁创建一个线程执行延迟任务,默认每隔10秒将锁的过期时间重新续期为30秒。
看门狗线程会首先判断锁是否存在,如果不存在将不再续期,当程序执行unlock()方法释放锁时会将该锁的对应的延迟任务取消,此时看门狗线程结束任务。
注意:任务结束一定要执行unlock()方法释放锁,否则看门狗线程一直进行续期,导致锁无法释放。
测试看门狗

下边进行测试:
修改tryLock的方法,leaseTime参数传入-1,开启看门狗。
数据同步组件
针对Redis到MySQL数据同步的需求本项目开发数据同步组件,使用组件可以提高开发效率,数据同步组件的代码在jzo2o-framework下的jzo2o-redis工程,下边我们先学会使用同步组件,再去理解它的工作原理。
我们的目标是要将抢券同步队列的数据同步到数据库,我们手动向抢券同步队列添加一些数据方便进行测试:
抢券同步队列的key为用户id,value是活动id。

如何使用同步组件呢?非常简单,只需要两步:
第一步我们定义处理器:
同步组件会自动从上图的Hash结构中读取数据,处理器负责接收到数据后写入数据库。
第二步启动同步任务:
调用组件syncManager接口的start方法即启动。
-
编写数据同步处理器
数据同步处理需要实现SyncProcessHandler接口。
处理器的实例会放在spring容器,bean的名称的命名规则如下:
从队列名称中截取一部分:
队列名称:QUEUE:COUPON:SEIZE:SYNC:{8},把开头部分(QUEUE:)和序号部分(:{8})去掉。
截取后为:COUPON:SEIZE:SYNC
处理器定义如下:
package com.jzo2o.market.handler;import com.jzo2o.common.utils.NumberUtils;
import com.jzo2o.redis.handler.SyncProcessHandler;
import com.jzo2o.redis.model.SyncMessage;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;import java.util.List;import static com.jzo2o.market.constants.RedisConstants.RedisKey.COUPON_SEIZE_SYNC_QUEUE_NAME;/*** 抢单成功同步任务*/
@Component(COUPON_SEIZE_SYNC_QUEUE_NAME)
@Slf4j
public class SeizeCouponSyncProcessHandler implements SyncProcessHandler<Object> {@Overridepublic void batchProcess(List<SyncMessage<Object>> multiData) {throw new RuntimeException("不支持批量处理");}/*** signleData key activityId, value 抢单用户id* @param singleData*/@Override@Transactional(rollbackFor = Exception.class)public void singleProcess(SyncMessage<Object> singleData) {log.info("获取要同步的数据: {}",singleData);//用户idlong userId = NumberUtils.parseLong(singleData.getKey());//活动idlong activityId = NumberUtils.parseLong(singleData.getValue().toString());log.info("userId={},activity={}",userId,activityId);//todo: 向优惠券表插入数据//todo:扣减数据库表中的库存}
}启动同步任务
数据同步任务仍然由xxl-job调度,下边先编写任务调度方法然后在xxl-job调度中心进行配置。
在定时任务方法中调用组件提供的syncManager接口的start方法:
在XxlJobHandler 中注入syncManager接口的bean:
@Component
public class XxlJobHandler {@Resourceprivate SyncManager syncManager;...syncManager接口提供两个start方法如下,阅读start方法的注释:
package com.jzo2o.redis.sync;import java.util.concurrent.Executor;/*** 同步程序管理器*/
public interface SyncManager {/*** 开始同步,使用默认线程池* @param queueName 同步队列名称* @param storageType 数据存储类型,1:redis hash数据结构,2:redis list数据结构,3:redis zSet结构* @param mode 单条执行 2批量执行*/void start(String queueName, int storageType, int mode);/*** 开始同步,可以使用自定义线程池,如果不设置使用默认线程池* @param queueName 同步队列名称* @param storageType 数据存储类型,1:redis hash数据结构,2:redis list数据结构,3:redis zSet结构* @param mode 1 单条执行 2批量执行* @param dataSyncExecutor 数据同步线程池*/void start(String queueName, int storageType, int mode, Executor dataSyncExecutor);}如果使用组件默认线程池调用第一个start方法启动任务,如果使用自定义的线程池调用第二个start方法。
queueName 同步队列名称参数:是将同步队列名称裁剪后的名称。
storageType 数据存储类型参数:选择hash数据结构
mode :选择单条执行,目前针对hash结构数据的同步只支持单条同步
dataSyncExecutor :线程池
首先在XxlJobHandler中注入自定义的线程池
@Resource(name="syncThreadPool")
private ThreadPoolExecutor threadPoolExecutor;编写定时任务方法:
/*** 抢券同步队列* 10秒一次*/
@XxlJob("seizeCouponSyncJob")
public void seizeCouponSyncJob() {syncManager.start(COUPON_SEIZE_SYNC_QUEUE_NAME, RedisSyncQueueConstants.STORAGE_TYPE_HASH, RedisSyncQueueConstants.MODE_SINGLE,threadPoolExecutor);
}理解数据同步组件原理
SyncManager 接口
数据同步组件在jzo2o-framework的jzo2o-redis工程中定义,提供以下SyncManager 接口供使用。
SyncManager 接口提供两个方法:如果使用组件默认线程池调用第一个start方法启动任务,如果使用自定义的线程池调用第二个start方法,项目使用第二个start方法。
package com.jzo2o.redis.sync;import java.util.concurrent.Executor;/*** 同步程序管理器*/
public interface SyncManager {/*** 开始同步,使用默认线程池* @param queueName 同步队列名称* @param storageType 数据存储类型,1:redis hash数据结构,2:redis list数据结构,3:redis zSet结构* @param mode 单条执行 2批量执行*/void start(String queueName, int storageType, int mode);/*** 开始同步,可以使用自定义线程池,如果不设置使用默认线程池* @param queueName 同步队列名称* @param storageType 数据存储类型,1:redis hash数据结构,2:redis list数据结构,3:redis zSet结构* @param mode 1 单条执行 2批量执行* @param dataSyncExecutor 数据同步线程池*/void start(String queueName, int storageType, int mode, Executor dataSyncExecutor);}组件提供SyncManager 接口的实现类SyncManagerImpl如下:
如果线程池为空,则默认走默认的线程池。如果有自定义的线程池,那么走自定义的线程池。
@Override
public void start(String queueName, int storageType, int mode) {this.start(queueName, storageType, mode, DEFAULT_SYNC_EXECUTOR);
}@Override
public void start(String queueName, int storageType, int mode, final Executor dataSyncExecutor) {//根据队列的数量循环,将每个队列的数据同步任务提交到线程池for (int index = 0; index < redisSyncProperties.getQueueNum(); index++) {try {if (dataSyncExecutor == null) {//使用默认线程池//使用getSyncThread方法获取任务对象DEFAULT_SYNC_EXECUTOR.execute(getSyncThread(queueName, index, storageType, mode));} else {//使用自定义线程池dataSyncExecutor.execute(getSyncThread(queueName, index, storageType, mode));}} catch (Exception e) {log.error("同步数据处理异常,e:", e);}}
}/*** 获取线程对象** @param queueName 队列名称* @param index 队列序号* @param storageType 存储结构 1:redis hash数据结构,2:redis list数据结构,3:redis zSet结构* @param mode 1 单条处理,2 批量处理* @return*/
private SyncThread getSyncThread(String queueName, int index, Integer storageType, int mode) {switch (storageType) {//目前组件支付同步Redis Hash结构的数据case STORAGE_TYPE_HASH:return new HashSyncThread(redissonClient, queueName, index, redisTemplate, redisSyncProperties.getPerCount(), mode);case STORAGE_TYPE_LIST:return null;case STORAGE_TYPE_ZSET:return null;}return null;
}
不管这个线程池.execute() 里面的内容长什么样子,他一定实现了runable或者callable接口
 往下面点一定会看到
往下面点一定会看到

执行里面的run方法
 然后调用getdate获取到数据
然后调用getdate获取到数据

获取到数据后有个process方法

获取我们定义的bean的处理器,最后执行里面的singleProcess
 最后我们只需要这个bean里面写具体的方法就好
最后我们只需要这个bean里面写具体的方法就好

整个数据处理的序列图如下:

抢券结果同步开发
编写扣减库存方法
项目使用数据同步组件完成数据从Redis的Hash结构同步到MySQL中。
关于数据同步组件的使用前边已经讲解,下边我们需要完善数据同步处理器即可将抢券同步队列的数据同步到MySQL。
数据同步处理器拿到抢券结果做两件事:
-
插入优惠券表
-
扣减库存
首先编写扣减库存
public interface IActivityService extends IService<Activity> {/*** 扣减库存* @param id 活动id* 如果扣减库存失败抛出异常*/
public void deductStock(Long id);
...@Service
public class ActivityServiceImpl extends ServiceImpl<ActivityMapper, Activity> implements IActivityService {/*** 扣减库存* @param id 活动id* 如果扣减库存失败抛出异常*/
public void deductStock(Long id){boolean update = lambdaUpdate().setSql("stock_num = stock_num-1").eq(Activity::getId, id).gt(Activity::getStockNum, 0).update();if(!update){throw new CommonException("扣减优惠券库存失败,活动id:"+id);}
}
...完善数据同步处理器
package com.jzo2o.market.handler;import com.jzo2o.api.customer.CommonUserApi;
import com.jzo2o.api.customer.dto.response.CommonUserResDTO;
import com.jzo2o.common.utils.DateUtils;
import com.jzo2o.common.utils.IdUtils;
import com.jzo2o.common.utils.NumberUtils;
import com.jzo2o.market.enums.CouponStatusEnum;
import com.jzo2o.market.model.domain.Activity;
import com.jzo2o.market.model.domain.Coupon;
import com.jzo2o.market.service.IActivityService;
import com.jzo2o.market.service.ICouponService;
import com.jzo2o.redis.handler.SyncProcessHandler;
import com.jzo2o.redis.model.SyncMessage;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;import javax.annotation.Resource;
import java.util.List;import static com.jzo2o.market.constants.RedisConstants.RedisKey.COUPON_SEIZE_SYNC_QUEUE_NAME;/*** 抢单成功同步任务*/
@Component(COUPON_SEIZE_SYNC_QUEUE_NAME)
@Slf4j
public class SeizeCouponSyncProcessHandler implements SyncProcessHandler<Object> {@Resourceprivate IActivityService activityService;@Resourceprivate ICouponService couponService;@Resourceprivate CommonUserApi commonUserApi;@Overridepublic void batchProcess(List<SyncMessage<Object>> multiData) {throw new RuntimeException("不支持批量处理");}/*** signleData key activityId, value 抢单用户id* @param singleData*/@Override@Transactional(rollbackFor = Exception.class)public void singleProcess(SyncMessage<Object> singleData) {log.info("获取要同步抢券结果数据: {}",singleData);//用户idlong userId = NumberUtils.parseLong(singleData.getKey());//活动idlong activityId = NumberUtils.parseLong(singleData.getValue().toString());log.info("userId={},activity={}",userId,activityId);// 1.获取活动Activity activity = activityService.getById(activityId);if (activity == null) {return;}CommonUserResDTO commonUserResDTO = commonUserApi.findById(userId);if(commonUserResDTO == null){return;}// 2.新增优惠券Coupon coupon = new Coupon();coupon.setId(IdUtils.getSnowflakeNextId());coupon.setActivityId(activityId);coupon.setUserId(userId);coupon.setUserName(commonUserResDTO.getNickname());coupon.setUserPhone(commonUserResDTO.getPhone());coupon.setName(activity.getName());coupon.setType(activity.getType());coupon.setDiscountAmount(activity.getDiscountAmount());coupon.setDiscountRate(activity.getDiscountRate());coupon.setAmountCondition(activity.getAmountCondition());coupon.setValidityTime(DateUtils.now().plusDays(activity.getValidityDays()));coupon.setStatus(CouponStatusEnum.NO_USE.getStatus());couponService.save(coupon);//扣减库存activityService.deductStock(activityId);}
}相关文章:
云岚到家 秒杀抢购
目录 秒杀抢购业务特点 常用技术方案 抢券 抢券界面 进行抢券 我的优惠券列表 活动查询 系统设计 活动查询分析 活动查询界面显示了哪些数据? 面向高并发如何提高活动查询性能? 如何保证缓存一致性? 数据流 Redis数据结构设计 如…...

【WPF】Prism库学习(一)
Prism介绍 1. Prism框架概述: Prism是一个用于构建松耦合、可维护和可测试的XAML应用程序的框架。它支持WPF、.NET MAUI、Uno Platform和Xamarin Forms等多个平台。对于每个平台,Prism都有单独的发布版本,并且它们在不同的时间线上独立开发。…...
)
0 -vscode搭建python环境教程参考(windows)
引用一篇非常详细的vscode搭建python环境教程 链接:vscode安装以及配置Python基本环境 以下是VSCode和PyCharm的对比 个人更建议使用VSCode Visual Studio Code (VSCode) Visual Studio Code 是由微软开发的一款免费、开源的轻量级代码编辑器。它支持多种编程语…...

Uniapp 引入 Android aar 包 和 Android 离线打包
需求: 原生安卓 apk 要求嵌入到 uniapp 中,并通过 uniapp 前端调起 app 的相关组件。 下面手把手教你,从 apk 到 aar,以及打包冲突到如何运行,期间我所遇到的问题都会 一 一 进行说明,相关版本以我文章内为…...
10款高效音频剪辑工具,让声音编辑更上一层楼。
音频剪辑在音频,视频,广告制作,游戏开发,广播等领域中都有广泛的应用。通过音频剪辑,创作者可以通将不同的音频片段进行剪切、拼接、混音等操作,创作出风格各异的音乐作品。如果你也正在为音频创作而努力的…...
)
Javascript——设计模式(一)
Javascript常见设计模式-CSDN博客 设计模式专栏内容总结-CSDN博客 C#编程思想——设计模式-CSDN博客 设计模式概述及其作用 设计模式(Design Pattern)是一套被反复使用、多数人知晓的、经过分类编目的代码设计经验的总结。使用设计模式的主要目的是为…...

Hybird和WebView
在移动端Hybrid开发模式下,iOS和Android应用都可以通过一种共享代码的方式,利用Web技术(HTML、CSS、JavaScript)和原生应用的功能进行开发。这种方式的主要优点是减少了开发成本,因为大部分代码可以共享,同…...

c++实现中缀表达式 转换为后缀表达式
使用栈来计算后缀表达式的值: 9(3 - 1)*310/2; 后缀表达式:所有的符号都是在运算数字的后面出现: 9 3 1 – 3 * 10 2 / 规则: 中缀表达式转后缀表达式: 1.从左到右遍历中缀表达式的每个数字和符号,若是数字就打印同时入栈数…...
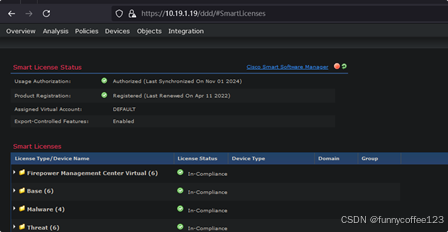
Cisco FMC重置SmartLicense到Evaluatin mode步骤
1 科普: what is FMC full name is Firepower Management Center, 是思科FirePower防火墙的统一管理平台. 能管理ASA不? no,只能管理FTD模式的墙。这里的FTD包括物理机firepower系列运行的FTD,以及FTDv(虚拟化版本&a…...

多表查询综合归纳
目录 1. 多表关系 1.1 一对多(多对一) 1.2 多对多 1.3 一对一 2. 多表查询概述 2.1 熟悉表 2.2 笛卡尔积 2.3 消除笛卡尔积 2.4 多表查询分类 3. 内连接 3.1 隐式内连接 3.2 显式内连接 4. 外连接 4.1 左外连接 4.2 右外连接 5. 自连接 …...

【5.线性表-链式表示-王道课后算法题】
王道数据结构-第二章-链式表示算法题 1.在带头结点的单链表L中,删除所有值为x的结点,并释放其空间,假设值为x的结点不唯一,试编写算法以实现上述操作。2. 试编写在带头结点的单链表L中删除一个最小值结点的高效算法(假设该结点唯一…...

存储过程及练习
1.存储过程 📖什么是存储过程? 存储过程和函数是事先经过编译并存储在数据库中的一段sql语句集合,调用存储过程函数可以简 化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的 效率…...

【在Linux世界中追寻伟大的One Piece】多路转接epoll
目录 1 -> I/O多路转接之poll 1.1 -> poll函数接口 1.2 -> poll的优点 1.3 -> poll的缺点 1.4 -> poll示例 1.4.1 -> 使用poll监控标准输入 2 -> I/O多路转接之epoll 2.1 -> 初识epoll 2.2 -> epoll的相关系统调用 2.2.1 -> epoll_cre…...

设计模式-参考的雷丰阳老师直播课
一般开发中使用的模式为模版模式策略模式组合,模版用来定义骨架,策略用来实现细节。 模版模式 策略模式 与模版模式特别像,模版模式会定义好步骤定义好框架,策略模式定义小细节 入口类 使用模版模式策略模式开发支付 以上使用…...

Python +Pyqt5 简单视频爬取学习(一)
文章目录 前言 一、演示 二、查找网页视频流的索引文件 三、分析视频流的url和视频流索引文件的差异性 四、判断视频数据是否需要转化为ts 五、判断视频是否被加密,如若被加密,需要先解密 六、合并所有的ts视频,以MP4模式输出完整视频 总结 前…...

Python Requests模块全面教程
Python Requests模块全面教程 在现代软件开发中,网络请求是一个不可或缺的部分。无论是获取网页数据、调用API接口,还是进行数据交互,都会涉及到HTTP请求。Python的Requests模块是一个非常强大的库,能够让我们轻松地发送HTTP请求…...

PyQt入门指南六十 与Python其他库的集成方法
PyQt是一个强大的GUI库,它可以与Python的其他库无缝集成,以实现更复杂的功能。以下是一些常见的集成方法和示例: 1. NumPy NumPy是Python中用于科学计算的基础库。您可以在PyQt应用程序中使用NumPy来处理数据和进行数值计算。 import sys …...

Android15之解决:Dex checksum does not match for dex:framework.jar问题(二百三十九)
简介: CSDN博客专家、《Android系统多媒体进阶实战》一书作者 新书发布:《Android系统多媒体进阶实战》🚀 优质专栏: Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏: 多媒体系统工程师系列【…...
)
车企自动驾驶功能策略 --- 硬件预埋(卷传感器配置)
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明自己,无利益不试图说服别人,是精神上的节…...

【已为网站上传证书,却显示不安全】
已为网站上传证书,却显示不安全 错误显示解决办法分析原因 错误显示 此站点有一个由受信任的颁发机构颁发的有效证书但是网站的某些部分不安全 解决办法 删除浏览器所有历史记录, 如果是Edge浏览器显示不安全,那就删除Edge浏览器的所有历史记录; 如果是Google Chrome浏览器显…...

智能硬件行业现状与未来趋势:技术、市场与盈利三重门解析
1. 项目概述:为什么现在要聊智能硬件?最近几年,身边的朋友、客户,甚至家里的长辈,都在问我同一个问题:“现在做智能硬件还有机会吗?” 这个问题背后,其实反映了一个普遍的行业焦虑&a…...

灰度发布与流量切换
Skeyevss FAQ:灰度发布与流量切换 试用安装包下载 | SMS | 在线演示 项目地址:https://github.com/openskeye/go-vss 1. 目标 新版本 先小流量验证,指标正常再全量;出问题 快速回滚。对 SIP 类系统,还要考虑 会话粘…...
)
JDK 17 + Hadoop 3.3.5 + Spark 3.3.2 集群搭建保姆级避坑指南(CentOS 8.5 + VMware)
JDK 17 Hadoop 3.3.5 Spark 3.3.2 集群搭建实战避坑手册 当你第一次尝试在本地环境搭建大数据集群时,是否曾被各种兼容性问题、配置错误和莫名其妙的报错折磨得焦头烂额?本文将带你完整走一遍从零开始搭建基于JDK 17、Hadoop 3.3.5和Spark 3.3.2的集群…...

TDengine数据迁移与备份实战:使用taosdump将2.x数据安全升级到3.0
TDengine 2.x到3.0数据迁移完全指南:从备份策略到避坑实践 时序数据库的版本升级往往伴随着数据迁移的挑战。当企业决定将TDengine从2.x升级到3.0时,如何确保数据安全迁移成为技术团队面临的首要问题。本文将深入解析使用taosdump工具进行数据迁移的全流…...

3大核心功能解密:如何用CSL编辑器告别引用格式噩梦
3大核心功能解密:如何用CSL编辑器告别引用格式噩梦 【免费下载链接】csl-editor cslEditorLib - A HTML 5 library for searching and editing CSL styles 项目地址: https://gitcode.com/gh_mirrors/csl/csl-editor 还在为论文引用格式而烦恼吗?…...

细胞的“近距离对话大师”——Notch信号通路
在我们身体里,细胞并非孤立存在,它们通过信号通路精准沟通,其中Notch信号通路堪称细胞间的“近距离对话大师”,从果蝇到人类都高度保守,不靠远距离信号扩散,仅靠相邻细胞“面对面接触”,就能掌控…...

MAA明日方舟助手:5步配置实现游戏日常全自动化
MAA明日方舟助手:5步配置实现游戏日常全自动化 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitcode.co…...

LeetCode热题100-从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。 示例 1: 输入: preorder [3,9,20,15,7], inorder [9,3,15,20,7] 输出: [3,9,20,null,null,15,7] 思…...

解决QGIS自定义投影难题:手把手教你添加中科院资源环境数据的Krasovsky_1940_Albers投影
QGIS自定义投影实战:精准处理Krasovsky_1940_Albers科研数据 第一次打开中科院资源环境数据中心下载的栅格数据时,那个扭曲变形的中国地图让我愣了几秒——这显然不是常见的WGS84或CGCS2000坐标系。右下角状态栏显示着一个陌生的名字:Krasovs…...

黑苹果配置复杂化挑战:OCAT跨平台管理工具的智能化解决方案
黑苹果配置复杂化挑战:OCAT跨平台管理工具的智能化解决方案 【免费下载链接】OCAuxiliaryTools Cross-platform GUI management tools for OpenCore(OCAT) 项目地址: https://gitcode.com/gh_mirrors/oc/OCAuxiliaryTools 面对日益复杂…...