postgresql(功能最强大的开源数据库)继承特性和分区实现
PostgreSQL实现了表继承,在多重表继承下,对上亿条不同类别的数据条目进行按型号、按月份双层分区管理,既可在总表查阅所有条目的共有字段,也可在各类型字表查询附加字段,非常高效。
分区是通过继承的方式来实现的,每个分区实际上都是一个独立的表。
1,继承
我们创建两个表来说明继承的特性:创建一个人类表和leader表,全球很多人,但是只有少数人是国家leader人。我们希望能够快速地检索任何国家的leader,继承特性有助于解决这个问题。
创建人类表:
mydb=#create table human(hid int,name varchar(20));创建leader表,继承人类表:
mydb=#create table leader(flag int default 1) inherits(human);通过继承,leader表将继承它父表human的所有列。leader通过一个额外的flag列来表示它为leader。
mydb=# \d human资料表 "public.human"栏位 | 型别 | 修饰词 ------+-----------------------+--------hid | integer | name | character varying(20) | mydb=# \d leader资料表 "public.leader"栏位 | 型别 | 修饰词 ------+-----------------------+--------hid | integer | name | character varying(20) | flag | integer | 缺省 1继承: human查找所有的人
mydb=# select * from human;hid | name -----+--------1 | 小花2 | 小明3 | 小华4 | 小丽5 | 小李7 | 朱元璋8 | 特兰普查找不是领导人的人
mydb=# select * from only human;hid | name -----+------1 | 小花2 | 小明3 | 小华4 | 小丽5 | 小李查找领导人
mydb=# select * from leader;hid | name | flag -----+--------+------7 | 朱元璋 | 18 | 特兰普 | 12,分区
分区在某些情况下可以使得查询性能显著提升。
当查询或更新访问一个分区的大部分行时,可以通过该分区上的一个顺序扫描来取代分散到整个表上的索引和随机访问,这样可以改善性能。
如果需求计划使用划分设计,可以通过增加或移除分区来完成批量载入和删除。 ALTER TABLE NO INHERIT 和 DROP TABLE 都远快于一个批量操作。这些命令也完全避免了由批量 DELETE 造成的 VACUUM 负载。
很少使用的数据可以被迁移到便宜且较慢的存储介质上。
通过继承实现分区:
mydb=# create table login_log(login_id int not null,user_name varchar(20),login_time date);mydb=# create table login_log_201801(check(login_time>=DATE '2018-01-01' and login_time<=DATE '2018-01-31')) inherits(login_log);mydb=# create table login_log_201802(check(login_time>=DATE '2018-02-01' and login_time<=DATE '2018-02-28')) inherits(login_log);mydb=# create table login_log_201803(check(login_time>=DATE '2018-03-01' and login_time<=DATE '2018-03-31')) inherits(login_log);在时间列上建立索引,确保性能:
mydb=# create index idx_login_log_201801_time on login_log_201801(login_time);mydb=# create index idx_login_log_201802_time on login_log_201802(login_time);mydb=# create index idx_login_log_201803_time on login_log_201803(login_time);通过insert into login_log,利用触发器和函数,使得数据根据登陆日期重定向到不同的分区。
函数创建:
CREATE OR REPLACE FUNCTION insert_login_log()RETURNS TRIGGER AS $$BEGINif(new.login_time>=DATE '2018-01-01' and new.login_time<=DATE '2018-01-31') theninsert into login_log_201801 values(new.*);elsif(new.login_time>=DATE '2018-02-01' and new.login_time<=DATE '2018-02-28') theninsert into login_log_201802 values(new.*);elsif(new.login_time>=DATE '2018-03-01' and new.login_time<=DATE '2018-03-31') theninsert into login_log_201803 values(new.*);elseRAISE EXCEPTION 'Date out of range!';end if;RETURN NULL;END;$$LANGUAGE plpgsql;触发器创建:
CREATE TRIGGER insert_log_triggerBEFORE INSERT ON login_logFOR EACH ROW EXECUTE PROCEDURE insert_login_log();数据录入:
insert into login_log values(1,'小明','2018-01-10');insert into login_log values(2,'小明','2018-02-13');insert into login_log values(3,'小明','2018-03-20');insert into login_log values(4,'小丽','2018-01-31');insert into login_log values(5,'小丽','2018-02-20');insert into login_log values(6,'小丽','2018-03-11');查询全部数据:
mydb=# select * from login_log;login_id | user_name | login_time ----------+-----------+------------1 | 小明 | 2018-01-104 | 小丽 | 2018-01-312 | 小明 | 2018-02-135 | 小丽 | 2018-02-203 | 小明 | 2018-03-206 | 小丽 | 2018-03-11查询分区表login_log_201801数据:
mydb=# select * from login_log_201801;login_id | user_name | login_time ----------+-----------+------------1 | 小明 | 2018-01-104 | 小丽 | 2018-01-31查询分区表login_log_201802数据:
mydb=# select * from login_log_201802;login_id | user_name | login_time ----------+-----------+------------2 | 小明 | 2018-02-135 | 小丽 | 2018-02-20查询分区表login_log_201803数据:
mydb=# select * from login_log_201803;login_id | user_name | login_time ----------+-----------+------------3 | 小明 | 2018-03-206 | 小丽 | 2018-03-113,注意点
a、分区表并不能完全的继承父表的所有属性,比如唯一约束、主键、外键。而检查约束与非空约束是可以继承的。
b、修改父表的结构,子表结构同时被修改。
c、reindex、vacuum命令不会影响到子表。
d、不要在父表上定义检查约束,除非你想约束所有分区。
e、不要在父表上创建索引和或唯一约束,因为没有任何意义。应该在每个分区上分别创建。
f、 合理的设计中,父表一般不存入数据,分区过滤时,父表的扫描代价为零。
g、在postgresql 10中,实现了分区的功能,用户可以通过相应语法直接实现分区功能,喜欢的朋友可以研究下。
相关文章:
继承特性和分区实现)
postgresql(功能最强大的开源数据库)继承特性和分区实现
PostgreSQL实现了表继承,在多重表继承下,对上亿条不同类别的数据条目进行按型号、按月份双层分区管理,既可在总表查阅所有条目的共有字段,也可在各类型字表查询附加字段,非常高效。 分区是通过继承的方式来实现的&…...
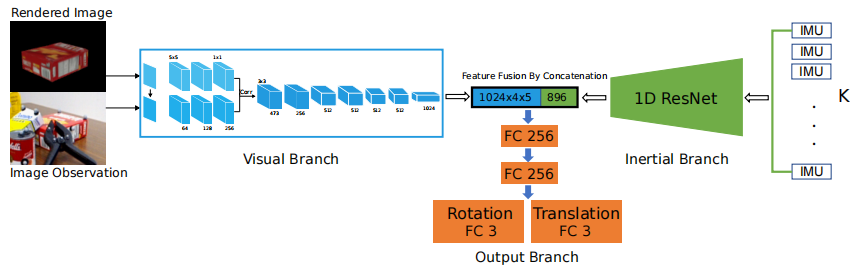
论文笔记(五十六)VIPose: Real-time Visual-Inertial 6D Object Pose Tracking
VIPose: Real-time Visual-Inertial 6D Object Pose Tracking 文章概括摘要I. INTRODACTIONII. 相关工作III. APPROACHA. 姿态跟踪工作流程B. VIPose网络 文章概括 引用: inproceedings{ge2021vipose,title{Vipose: Real-time visual-inertial 6d object pose tra…...

微服务治理详解
文章目录 什么是微服务架构为什么要使用微服务单体架构如何转向微服务架构服务治理服务治理治的是什么服务注册与发现服务熔断降级服务网关服务调用服务负载均衡服务配置中心 微服务解决方案SpringCloud体系EurekaHystrixGatewayOpenFeignRibbonConfig SpringCloud Alibaba体系…...
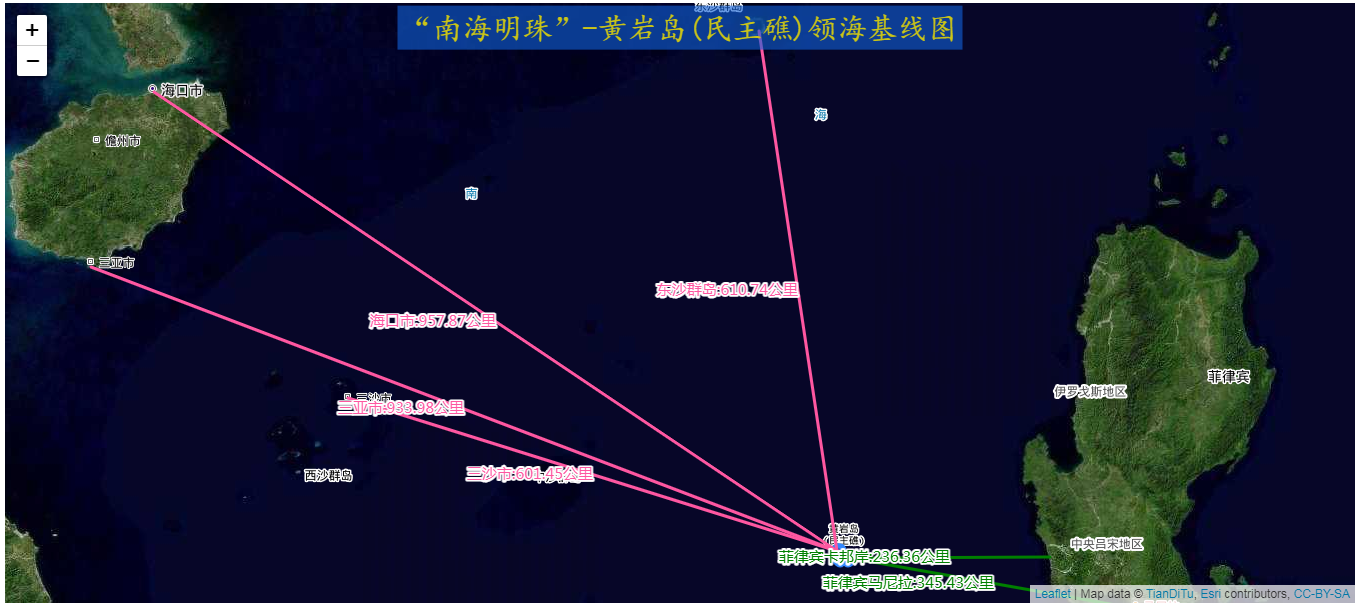
“南海明珠”-黄岩岛(民主礁)领海基线WebGIS绘制实战
目录 前言 一、关于岛屿的基点位置 1、领海基点 二、基点坐标的转换 1、最底层的左边转换 2、单个经纬度坐标点转换 3、完整的转换 三、基于天地图进行WebGIS展示 1、领海基点的可视化 2、重要城市距离计算 四、总结 前言 南海明珠黄岩岛,这座位于南海的…...

Oracle数据库 创建dblink的过程及其用法详解
前言 dblink是Oracle数据库中用于连接不同数据库实例的一种机制。通过dblink,用户可以在一个数据库实例中直接查询或操作另一个数据库实例中的表、视图或存储过程。 dblink的作用主要体现在以下几个方面: 跨数据库操作:允许用户…...

Linux从0——1之shell编程4
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...

pycharm快速更换虚拟环境
目录 1. 选择Conda 虚拟环境2. 创建环境3. 直接选择现有虚拟环境 1. 选择Conda 虚拟环境 2. 创建环境 3. 直接选择现有虚拟环境...

MVVM框架
MVVM由以下三个内容构成: Model:数据模型View:界面ViewModel:作为桥梁负责沟通View和Model 在JQuery时期,如果需要刷新UI,需要先取到对应的 DOM 再更新 UI,这样数据和业务的逻辑就和⻚⾯有强耦合。 在 MVVM 中,UI 是…...

数据仓库在大数据处理中的作用
数据仓库(Data Warehouse,简称DW或DWH)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。以下是对数据仓库及其在大数据处理中作用的详细解释: 一、数据仓库的定义 面向主题&#x…...
)
前端Javascript、Vue、CSS等场景面试题目(二)
前端面试场景题目(一)-CSDN博客 针对您提供的前端场景面试题目,以下是详细的回答: 1. 如何通过 CSS 实现美观的自定义复选框和单选按钮? 方法:使用 CSS 伪元素 ::before 和 ::after,以及隐藏…...
)
鸿蒙学习生态应用开发能力全景图-开发者支持平台(5)
鸿蒙相关平台作用: 开发者社区:开发者技术交流平台,帮助开发者探索开发实践、交流心得经验、获悉业界动态、答疑解惑。 开发者学堂:聚合官方鸿蒙生态课程,课程有慕课、微课、直播课、训练营等多种形式ÿ…...

计算机网络各层设备总结归纳(更新ing)
计算机网络按照OSI(开放式系统互联)模型分为七层,每一层都有其特定的功能和对应的网络设备。以下是各层对应的设备: 1. 物理层(Physical Layer) 设备:中继器(Repeater)、集线器…...

3. Spring Cloud Eureka 服务注册与发现(超详细说明及使用)
3. Spring Cloud Eureka 服务注册与发现(超详细说明及使用) 文章目录 3. Spring Cloud Eureka 服务注册与发现(超详细说明及使用)前言1. Spring Cloud Eureka 的概述1.1 服务治理概述1.2 服务注册与发现 2. 实践:创建单机 Eureka Server 注册中心2.1 需求说明 图解…...
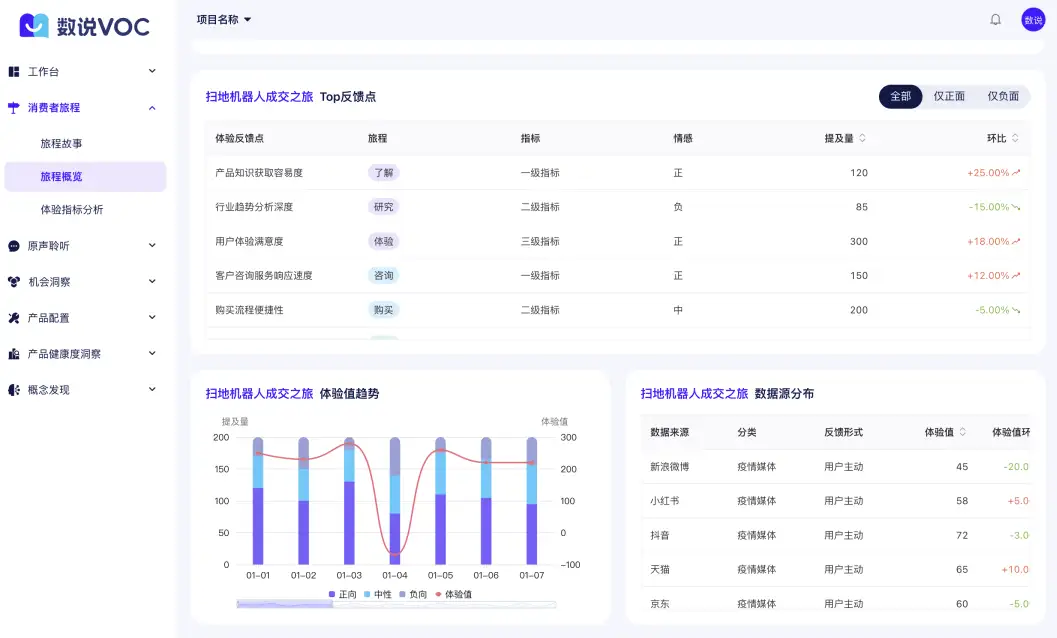
品牌如何利用大数据工具,进行消费者洞察分析?
存量竞争的时代, 消费者聆听是品牌持续增长的关键,借助大数据的消费者数据洞察,可以帮助品牌分析消费者的所思所想及行为特征,获取消费者对产品的需求痛点、使用感受,对品牌的评价口碑等,从而帮助品牌更好地…...

鸿蒙实现 web 传值
前言:安卓和 IOS 加载 H5 的时候,都有传值给到 H5 或者接收 H5 值,鸿蒙也可传值和接收 H5 的内容,以下是鸿蒙传值给 H5 端的具体操作 一: 定义好 H5 和鸿蒙传值的方法名,两端必须保持方法名一致 // xxx.ets import …...
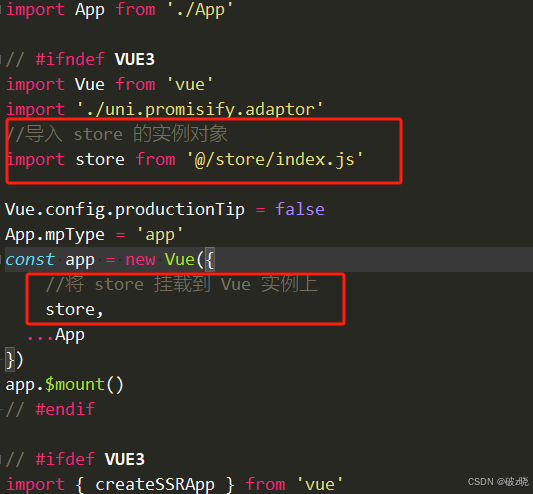
uniapp vuex的使用
实现组件全局(数据)管理的一种机制,可以方便的实现组件之间共享数据,不同于上述三种传递值的方式。 可以把vuex当成一个store仓库,可以集中管理共享的数据,并且存储在vuex中的数据都是响应式的,…...

RabbitMQ实战启程:从原理到部署的全方位探索(上)
文章目录 一、RabbitMQ简介1.1、概述1.2、特性 二、RabbitMQ原理架构三、RabbitMQ应用场景3.1 简单模式3.2 工作模式3.3 发布订阅3.4 路由模式3.5 主题订阅模式 四、同类中间件对比五、RabbitMQ部署5.1 单机部署5.1.1 安装erlang5.1.2 安装rabbitmq 5.2 集群部署(镜…...

【论文复现】轻松利用自适应特征融合实现去雾
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀ 智慧医疗 介绍创新点网络结构特征提取阶段自适应融合阶段图像重建阶段上下文增强模块CEM特征融合模块AFM 结果分析 提示 论文题目࿱…...

【大数据学习 | HBASE高级】hbase-phoenix 与二次索引应用
1. hbase-phoenix的应用 1.1 概述: 上面我们学会了hbase的操作和原理,以及外部集成的mr的计算方式,但是我们在使用hbase的时候,有的时候我们要直接操作hbase做部分数据的查询和插入,这种原生的方式操作在工作过程中还…...

高级java每日一道面试题-2024年11月09日-缓存中间件篇-Redis和Memecache有什么区别?
如果有遗漏,评论区告诉我进行补充 面试官: Redis和Memecache有什么区别? 我回答: 一、基础特性 数据类型支持 Redis: 支持多种数据类型,包括字符串(String)、哈希(Hash)、列表(List)、集合…...

163MusicLyrics:一键获取网易云QQ音乐歌词的专业工具
163MusicLyrics:一键获取网易云QQ音乐歌词的专业工具 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为找不到高质量歌词而烦恼吗?163MusicLy…...

如何用applera1n免费绕过iOS激活锁:完整指南与操作教程
如何用applera1n免费绕过iOS激活锁:完整指南与操作教程 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否购买了一部二手iPhone或iPad,却发现设备被原主人的Apple ID锁定&a…...

从零到一:在个人PC上部署并集成ChatGLM-6B到Unity应用
1. 环境准备与模型下载 在个人PC上部署ChatGLM-6B需要先搞定三件事:硬件检查、软件环境搭建和模型文件获取。我的老款游戏本(i7-9750H RTX2060 6GB显存)实测可以流畅运行,关键在于正确的量化配置。 硬件检查要点: 显存…...

5分钟快速掌握Windows右键菜单终极管理神器ContextMenuManager
5分钟快速掌握Windows右键菜单终极管理神器ContextMenuManager 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是不是经常在右键文件时,面对几十个…...

【技术解析】基于主成分分析与神经网络的航空安全风险建模:从QAR数据预处理到实时预警仿真
1. 航空安全风险建模的技术背景 每次坐飞机时,你可能都好奇过:机长是如何确保飞行安全的?其实背后有一整套数据驱动的安全体系在支撑。QAR(快速存取记录器)就像飞机的"黑匣子",记录了上百项飞行参…...

告别Python依赖!手把手教你用C++复现Librosa的Mel频谱和MFCC特征提取
高性能C音频特征提取实战:从Librosa原理到嵌入式部署优化 在语音识别和音频分析领域,Mel频谱和MFCC特征提取是基础但关键的技术环节。许多开发者习惯使用Python的Librosa库快速实现原型,但当需要部署到生产环境时,Python的解释器性…...

STM32CubeIDE实战指南:从代码编译到一键下载的完整流程解析
1. STM32CubeIDE开发环境概述 对于刚接触STM32开发的工程师来说,选择一款合适的集成开发环境(IDE)至关重要。STM32CubeIDE是ST官方推出的免费开发工具,它集成了代码编辑、编译、调试和下载功能于一体,特别适合新手快速上手。我在实际项目中使…...

如何在Mac上轻松导出微信聊天记录:WeChatExporter完整指南
如何在Mac上轻松导出微信聊天记录:WeChatExporter完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而焦虑?…...

如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案
如何用Sunshine打造个人游戏云:终极自托管游戏串流解决方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想在任何设备上畅玩PC游戏?无论是想…...

猫抓插件:5分钟掌握浏览器资源嗅探的终极武器
猫抓插件:5分钟掌握浏览器资源嗅探的终极武器 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容无处不在的今天,你…...