机器学习基础02_特征工程
目录
一、概念
二、API
三、DictVectorize字典列表特征提取
四、CountVectorize文本特征提取
五、TF-IDF文本1特征词的重要程度特征提取
六、无量纲化预处理
1、MinMaxScaler 归一化
2、StandardScaler 标准化
七、特征降维
1、特征选择
VarianceThreshold 底方差过滤降维
根据相关系数的特征选择
一、概念
一般是使用pandas来进行数据清洗和数据处理、使用sklearn来对特征进行相关的处理。
特征工程是将任意数据(如文本或图像)转换为可用于机器学习的数字特征,比如:字典特征提取(特征离散化)、文本特征提取、图像特征提取。
步骤:
-
特征提取, 如果不是像dataframe那样的数据,要进行特征提取,比如字典特征提取,文本特征提取
-
无量纲化(预处理)
-
归一化
-
标准化
-
-
降维
-
底方差过滤特征选择
-
主成分分析-PCA降维
-
二、API
实例化转换器对象,转换器类有很多,都是Transformer的子类,常用的子类有:
DictVectorizer 字典特征提取
CountVectorizer 文本特征提取
TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
MinMaxScaler 归一化
StandardScaler 标准化
VarianceThreshold 底方差过滤降维
PCA 主成分分析降维
三、DictVectorize字典列表特征提取
- 创建转换器对象:
sklearn.feature_extraction.DictVectorizer(sparse=True)
参数
sparse=True返回类型为csr_matrix的稀疏矩阵
sparse=False表示返回的是数组,数组可以调用.toarray()方法将稀疏矩阵转换为数组
- 转换器对象:
转换器对象调用fit_transform(data)函数,参数data为一维字典数组或一维字典列表,返回转化后的矩阵或数组
转换器对象get_feature_names_out()方法获取特征名
a)提取为稀疏矩阵对应的数组
# DictVectorizer 字典列表特征提取
# 01 提取为稀疏矩阵对应的数组
from sklearn.feature_extraction import DictVectorizer
import pandas as pddata = [{'city':'成都', 'age':30, 'temperature':200}, {'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
# 创建DictVectorizer对象 字典转变为向量的工具器
transfer = DictVectorizer(sparse=False)# 返回的是数组
data_new = transfer.fit_transform(data)# 类型为numpy.ndarray
print('data_new:\n', data_new)
print('特征名字:\n', transfer.get_feature_names_out())# 返回特征名字pd.DataFrame(data=data_new, columns=transfer.get_feature_names_out())

b)提取为稀疏矩阵(三元组)
# 02 提取为稀疏矩阵(三元组)
from sklearn.feature_extraction import DictVectorizer
data = [{'city':'成都', 'age':30, 'temperature':200},{'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
transfer = DictVectorizer(sparse=True)# sparse=True表示返回的是稀疏矩阵
data_new = transfer.fit_transform(data)
# data_new的类型为<class 'scipy.sparse._csr.csr_matrix'>
print("data_new:\n", data_new) # 三元组
#得到特征
print("特征名字:\n", transfer.get_feature_names_out())
print(data_new.toarray()) # 三元组(稀疏矩阵)转换为数组 
其中, 稀疏矩阵对象调用toarray()函数, 得到类型为ndarray的二维稀疏矩阵。
关于稀疏矩阵和三元组
稀疏矩阵是指一个矩阵中大部分元素为零,只有少数元素是非零的矩阵。 在数学和计算机科学中,当一个矩阵的非零元素数量远小于总的元素数量,且非零元素分布没有明显的规律时,这样的矩阵就被认为是稀疏矩阵。
三元组表就是一种稀疏矩阵类型数据,存储非零元素的行索引、列索引和值:
(行,列) 数据
(0,0) 10
(0,1) 20
(2,0) 90
(2,20) 8
(8,0) 70
表示除了列出的有值, 其余全是0。
四、CountVectorize文本特征提取
sklearn.feature_extraction.text.CountVectorizer
构造函数关键字参数stop_words,值为list,表示词的黑名单(不提取的词)。
fit_transform函数的返回值为稀疏矩阵。
a)英文文本特征提取
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pddata=["stu is well, stu is great", "You like stu"]
# 创建一个词频提取对象 提取文本特征向量
transfer = CountVectorizer(stop_words=['you','is'])# you和is这两个词会被过滤掉
data_new = transfer.fit_transform(data)# 进行提取,得到稀疏矩阵
print(data_new)pd.DataFrame(data=data_new.toarray(),index=["第一个句子","第二个句子"],columns=transfer.get_feature_names_out())
b)中文文本特征提取
jieba库安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba
# CountVectorizer 中文文本特征提取
from sklearn.feature_extraction.text import CountVectorizer
import jieba# data = ' '.join(data)
# print(data)
# 传入的文本(未断词的字符串)用jieba分词工具转化为数据容器,在把数据容器中的元素用空格连接成字符串
def my_cut(text):return ' '.join(jieba.cut(text))data = ["教育学会会长期间,坚定支持民办教育事业!", "扶持民办,学校发展事业","事业做出重大贡献!"]transfer = CountVectorizer(stop_words=[])
# 提取词频,得到稀疏矩阵
data_new = transfer.fit_transform([my_cut(dt) for dt in data])
print(data_new)
print(transfer.get_feature_names_out())pd.DataFrame(data=data_new.toarray(),columns=transfer.get_feature_names_out())
五、TF-IDF文本1特征词的重要程度特征提取
词频(Term Frequency, TF), 表示一个词在当前篇文章中的重要性,是对词数的归一化。
TF = 某词出现次数/总词数
逆文档频率(Inverse Document Frequency, IDF), 反映了词在整个文档集合中的稀有程度。
IDF = lg[(文档总数+1)/(包含该词的文档数+1)] + 1
重要程度 TF-TDF = TF*TDF
# TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
import jieba
import pandas as pddef my_cut(text):return ' '.join(jieba.cut(text))
data = ["教育学会会长期间,坚定支持民办教育事业!", "扶持民办,学校发展事业","事业做出重大贡献!"]
data = [my_cut(i) for i in data]
# print(data)
transfer = TfidfVectorizer(stop_words=[])
data_new = transfer.fit_transform(data)
# print(data_new.toarray())
pd.DataFrame(data=data_new.toarray(),columns=transfer.get_feature_names_out())
六、无量纲化预处理
无量纲数据即没有单位的数据,无量纲化包括“归一化”和“标准化”。
1、MinMaxScaler 归一化
通过对原始数据进行变换把数据映射到指定区间(默认为0-1)。
x_scaled = (x - x_min)/(x_max - x_min)
这里的 𝑥min 和 𝑥max 分别是每种特征中的最小值和最大值,而 𝑥是当前特征值,𝑥scaled 是归一化后的特征值。
若要缩放到其他区间,可以使用公式:x_scaled'=x_scaled*(max-min)+min
from sklearn.preprocessing import MinMaxScaler
import pandas as pdscaler = MinMaxScaler(feature_range=(0, 1))
data = pd.read_excel('../src/minmaxscaler.xlsx')
# print(data.values)
data_new = scaler.fit_transform(data)
print(data_new)最大值和最小值容易受到异常点影响,所以鲁棒性较差。所以常使用标准化的无量纲化。
2、StandardScaler 标准化
最常见的标准化方法是Z-score标准化,也称为零均值标准化。它通过对每个特征的值减去其均值,再除以其标准差,将数据转换为均值为0,标准差为1的分布。
μ = x.mean()
σ = x.std()
z_score = (x - μ) / σ
z是转换后的数值,x是原始数据的值,μ是该特征的均值,σ是该特征的标准差。
from sklearn.preprocessing import StandardScaler
import numpy as npscaler = StandardScaler()
np.random.seed(6)
data = np.random.randint(0,100,size=(4,4))# 随机生成4行4列的数据
# scaler.fit(data) # 计算出均值和标准差 只调用一次
# scaler.transform(data) # 转化数据
data_standard = scaler.fit_transform(data) # 后续调用transform方法print(data)
print(data_standard) 
关于fit()、fit_transform()、transform()
1. fit:
- 这个方法用来计算数据的统计信息,比如均值和标准差(在`StandardScaler`的情况下)。这些统计信息随后会被用于数据的标准化。
- 应仅在训练集上使用`fit`方法。
2. fit_transform:
- 这个方法相当于先调用`fit`再调用`transform`,但是它在内部执行得更高效。
- 它同样应当仅在训练集上使用,它会计算训练集的统计信息并立即应用到该训练集上。
3. transform:
- 这个方法使用已经通过`fit`方法计算出的统计信息来转换数据。
- 它可以应用于任何数据集,包括训练集、验证集或测试集,但是应用时使用的统计信息必须来自于训练集。
在使用`StandardScaler`时,`fit`方法会根据训练数据集计算均值和标准差,然后将这些值保存在`StandardScaler`对象中。当你在另一个数据集上使用`transform`方法时,`StandardScaler`对象会根据之前计算的均值和标准差来转换数据。
一旦`scaler`对象在`X_train`上被`fit`,它就已经知道了如何将数据标准化。总的来说,我们常常是先使用fit_transform(x_train)然后再调用transform(x_text)。
七、特征降维
降维即去掉一些特征,或者转化多个特征为少个特征,以减少数据集的维度,同时尽可能保留数据的重要信息。
在高维空间中处理数据可能非常耗时且计算密集。降维可以简化模型,降低训练时间和资源需求。高维数据可能包含许多无关或冗余特征,这些特征可能引入噪声并导致过拟合。降维可以帮助去除这些不必要的特征。
1、特征选择
VarianceThreshold 底方差过滤降维
Filter(过滤式): 主要探究特征本身特点, 特征与特征、特征与目标值之间关联。
- 方差选择法: 低方差特征过滤
如果一个特征的方差很小,说明这个特征的值在样本中几乎相同或变化不大,包含的信息量很少,模型很难通过该特征区分不同的对象,比如区分甜瓜子和咸瓜子还是蒜香瓜子,如果有一个特征是长度,这个特征相差不大可以去掉。
1. 计算方差:对于每个特征,计算其在训练集中的方差(每个样本值与均值之差的平方,在求平均)。
2. 设定阈值:选择一个方差阈值,任何低于这个阈值的特征都将被视为低方差特征。
3. 过滤特征:移除所有方差低于设定阈值的特征。
# 低方差过滤
from sklearn.feature_selection import VarianceThreshold
transfer = VarianceThreshold(threshold=0.5)# 方差阈值
data = [[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]]
data_new = transfer.fit_transform(data)print(data_new)根据相关系数的特征选择
正相关性(Positive Correlation)是指两个变量之间的一种统计关系,其中一个变量的增加通常伴随着另一个变量的增加,反之亦然。在正相关的关系中,两个变量的变化趋势是同向的。当我们说两个变量正相关时,意味着:
- 如果第一个变量增加,第二个变量也有很大的概率会增加。
- 同样,如果第一个变量减少,第二个变量也很可能会减少。
在数学上,正相关性通常用正值的相关系数来表示,这个值介于0和1之间。当相关系数等于1时,表示两个变量之间存在完美的正相关关系,即一个变量的值可以完全由另一个变量的值预测。
负相关性(Negative Correlation)与正相关性刚好相反,但是也说明相关,比如运动频率和BMI体重指数程负相关。
不相关指两者的相关性很小,一个变量变化不会引起另外的变量变化,只是没有线性关系。
# 皮尔逊相关系数
from scipy.stats import pearsonr
import pandas as pddata = pd.read_csv('../src/factor_returns.csv')
data = data.iloc[:, 1:-2]
print(data)
# 计算某两个变量之间的相关系数
r = pearsonr(data["pe_ratio"], data["pb_ratio"])
print(r)
print(r.statistic)# 皮尔逊相关系数[-1,1] -0.004389322779936271
print(r.pvalue)# 零假设 统计上评估两个变量之间的相关性,越小越相关 0.8327205496590723
注:开发中一般不使用求相关系数的方法,一般使用主成分分析,因为主成分分析过程中就包括了求相关系数。
相关文章:
机器学习基础02_特征工程
目录 一、概念 二、API 三、DictVectorize字典列表特征提取 四、CountVectorize文本特征提取 五、TF-IDF文本1特征词的重要程度特征提取 六、无量纲化预处理 1、MinMaxScaler 归一化 2、StandardScaler 标准化 七、特征降维 1、特征选择 VarianceThreshold 底方差…...

CSS Modules中的 :global
最近写需求遇到如下代码,我们来分析一番: .medicine-bot {:global(.cosd-site-vcard-card) {margin-top: -3px;}:global(.cosd-site-vcard-title-text) {font-size: var(--cos-text-headline-sm);}:global(.cosd-site-vcard-button) {background-color: …...

linux病毒编写+vim shell编程
学习视频来自B站UP主泷羽sec,如涉及侵权马上删除文章 感谢泷羽sec 团队的教学 请一定遵循《网络空间安全法》!!! Linux目录介绍 /bin 二进制可执行文件(kali里面是工具一些文件)/etc 系统的管理和配置文…...

WinDefender Weaker
PPL Windows Vista / Server 2008引入 了受保护进程的概念,其目的不是保护您的数据或凭据。其最初目标是保护媒体内容并符合DRM (数字版权管理)要求。Microsoft开发了此机制,以便您的媒体播放器可以读取例如蓝光,同时…...
)
智能工厂的设计软件 为了监管控一体化的全能Supervisor 的监督学习 之 序5 架构for认知系统 总述 (架构全图)
本文提要 本文讨论的“智能工厂的设计软件” for认知系统的架构全图 ,这有别于前面所说的“智能工厂的设计软件”的“全景图”。两者在内容和侧重点上有所不同,但它们共同构成了对智能工厂设计软件的全面描述。 全景图是对智能工厂设计软件的整体概览&…...

vmware集群 vSAN HCL 数据库
HCL数据库升级 https://partnerweb.vmware.com/service/vsan/all.json VSAN版本目录升级 https://vcsa.vmware.com/ph/api/v1/results?deploymentId2d02e861-7e93-4954-9a73-b08692a330d1&collectorIdVsanCloudHealth.6_5&objectId0c3e9009-ba5d-4e5f6-bae8-f25ec5…...

人工智能引发直播革命:AI 技术塑造无人直播全新体验
在数字化浪潮席卷全球的今天,人工智能(AI)技术以其无与伦比的速度和广度,正深刻地改变着各行各业的面貌。其中,直播行业作为新媒体时代的宠儿,也迎来了由AI技术引领的颠覆性变革。这场由人工智能引发的直播…...

数据研发基础 | 什么是流批一体
流批一体的概念是可能出现在大厂的面试题中的,虽然就算大厂实习也没机会实操这样的高级操作,学一点概念,面试多少是能说上一两句的。大致就是希望一套代码能同时在批处理和流处理中运行(同时做离线计算和实时计算)。下…...

《Python网络安全项目实战》项目6 编写密码工具程序
《Python网络安全项目实战》项目6 编写密码工具程序 项目6 编写密码工具程序任务6.1 猜数字游戏任务描述任务分析任务实施6.1.1 编写基本的猜数字程序6.1.3 测试并修改程序6.1.4 给程序增加注释 任务拓展任务实施6.2.1 生成随机密码6.2.4 菜单功能 相关知识1. 密码字典2. 密码字…...

现代C++HTTP框架cinatra
文章目录 cinatra简介主要特点 快速上手编译器版本要求使用指南快速示例 项目地址 cinatra简介 cinatra是一个基于C20协程的高性能HTTP框架,它的目标是提供一个快速开发的C HTTP框架解决方案 它不仅支持HTTP/1.1和1.0,还支持SSL和WebSocket,…...
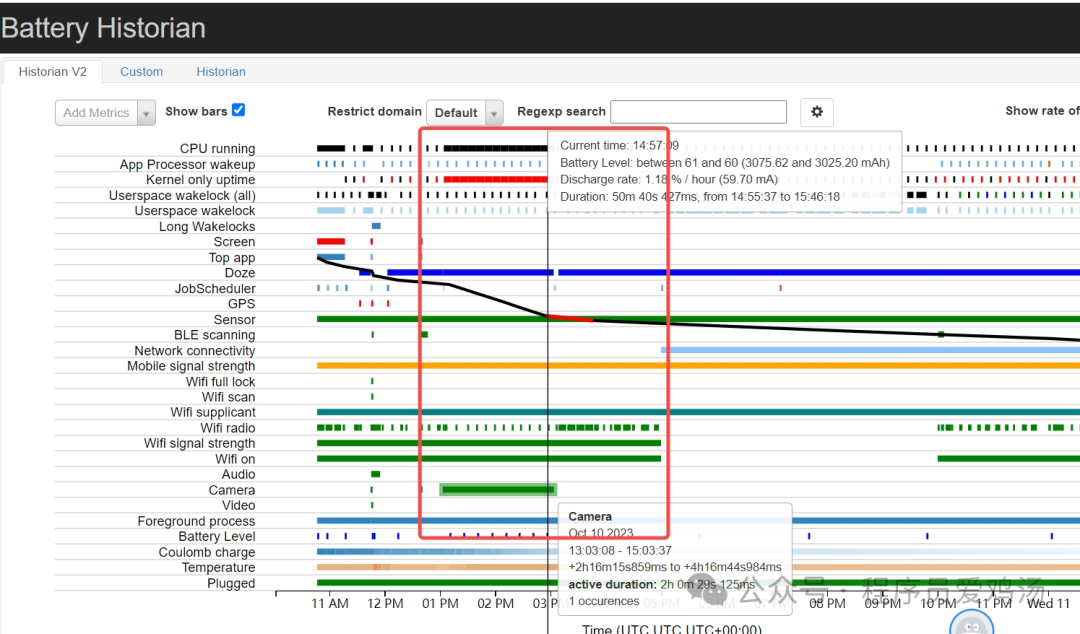
【功耗现象】com.gorgeous.lite后台Camera 使用2小时平均电流200mA耗电量400mAh现象
现象 轻颜相机(com.gorgeous.lite)后台Camera 使用2小时平均电流200mA(BugReport提供的电流参考数据),耗电量400mAh 即耗电占比(200mA*2h)/(12.83h*52.68mA )400mAh/623mAh62% CameraOct 10 202321:03:08 - 23:03:372h16m15s859ms to 4h16m44s984msactive duration: 2h 0m 29…...

06.VSCODE:备战大项目,CMake专项配置
娇小灵活的简捷配置不过是年轻人谈情说爱的玩具,帝国大厦的构建,终归要交给CMake去母仪天下。一个没有使用 CMake 的 C 项目,就像未来世界里的一台相声表演,有了德纲却无谦,观众笑着遗憾。—— 语出《双城记》作者&…...

还是小时候味道的麻辣片
麻辣片的诞生,源于人们对辣味的热爱和对丰富口感的追求。它将辣椒的火辣、香料的浓郁和豆制品的醇厚完美结合在一起,创造出了一种令人回味无穷的美食体验。无论是在学校的小卖部、街头的小吃摊,还是超市的货架上,麻辣片都以其鲜艳…...

GaussDB部署架构
GaussDB部署架构 云数据库GaussDB管理平台(TPOPS)基于B/S架构开发,由Web、管控Service、管控Agent三部分组成,软件结构如图1所示。 图1 各节点部署架构 Web:作为用户接入子系统,用于将用户在Web下发的操作…...
遥测数据采集工具Grafana Alloy
介绍 Alloy是Grafana产品公司旗下的一款新主推遥测数据采集工具,Grafana Alloy也是一个开源OpenTelemetry收集器,具有内置 Prometheus管道并支持指标、日志、跟踪和配置文件。Alloy支持为OTEL、Prometheus、Pyroscope、Loki等服务提供许多指标、日志、跟…...
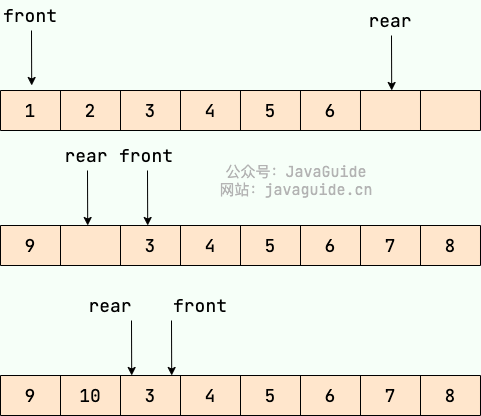
线性数据结构
数组 数组(Array) 是一种很常见的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。 我们直接可以利用元素的索引(index)可以计算出该元素对应的存储地址。 数组…...

【ArcGIS微课1000例】0127:计算城市之间的距离
本文讲述,在ArcGIS中,计算城市(以地级城市为例)之间的距离,效果如下图所示: 一、数据准备 加载配套实验数据包中的地级市和行政区划矢量数据(订阅专栏后,从私信查收数据),如下图所示: 二、计算距离 1. 计算邻近表 ArcGIS提供了计算点和另外点之间距离的工具:分析…...

【算法】二分
1. 找到有序区间中 x 最左边的数字的位置 static int getL(int a[], int l, int r, int x) {while (l < r) {int mid l r >> 1;if (x < a[mid]) {r mid;} else {l mid 1;}}if (a[l] ! x) return -1;return l;} 2. 找到有序区间中 x 最右边的数字的位置 stati…...

ARM CCA机密计算安全模型之简介
安全之安全(security)博客目录导读 目录 1、引言 2、问题陈述 3、CCA 安全保证 3.1 对领域所有者的安全保证 3.2 对host环境的安全保证 Arm 机密计算架构(CCA)安全模型(SM)定义了 CCA 隔离架构的安全要求和基本安全属性。这…...

蓝桥杯-洛谷刷题-day3(C++)
目录 1.忽略回车的字符串输入 i.getline() ii.逐个字符的识别再输入 2.获取绝对值abs() 3.做题时的误区 4.多个变量的某一个到达判断条件 i.max() 5.[NOIP2016 提高组] 玩具谜题 i.代码 6.逻辑上的圆圈 i.有限个数n的数组 7.数组的定义 i.动态数组 1.忽略回车的字符串输…...

通过taotoken审计日志追溯api调用详情与安全分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken审计日志追溯API调用详情与安全分析 对于将大模型API集成到业务流程中的团队而言,API调用的可见性与可控性…...

Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程
Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾因为Adobe Creative Cloud高昂的订阅…...

ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题
ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI动画创作中,ComfyUI的Vi…...

移动端大语言模型本地部署:从模型轻量化到推理引擎实战
1. 项目概述:当GPT遇见移动端,一个开源项目的诞生最近在GitHub上闲逛,发现了一个挺有意思的项目,叫Taewan-P/gpt_mobile。光看名字,你大概就能猜到它的核心:把类似GPT这样的大语言模型(LLM&…...

AXI交叉开关IP核:SoC内部高并发数据传输的核心枢纽设计与实战
1. 项目概述:一个高效、可配置的片上总线交叉开关在复杂的数字系统设计,尤其是片上系统(SoC)领域,多个主设备(如CPU、DMA控制器)需要同时访问多个从设备(如内存、外设控制器…...

Ruby专属LLM应用框架ruby_llm:从基础集成到生产部署实战
1. 项目概述:一个为Ruby语言量身打造的LLM应用框架如果你是一名Ruby开发者,最近被各种大语言模型(LLM)的应用搞得心痒痒,但看着满世界的Python库和框架感到无从下手,那么crmne/ruby_llm这个项目可能就是你在…...

基于Kubernetes Lease构建分布式部署锁:解决CI/CD环境下的资源竞争
1. 项目概述:从“clawfight”看一场被遗忘的社区技术博弈看到“2019-02-18/clawfight”这个标题,很多人的第一反应可能是困惑。它不像一个标准的软件项目名,没有清晰的版本号,也没有指明具体的技术栈。但恰恰是这种看似随意的命名…...

n8n-claw:在自动化工作流中实现零代码网页抓取
1. 项目概述与核心价值最近在折腾自动化工作流,发现了一个挺有意思的项目,叫freddy-schuetz/n8n-claw。乍一看名字,你可能会有点懵,“n8n”我知道,是那个开源的自动化工具,但这个“claw”是啥?爪…...

ComfyUI ControlNet Aux 终极指南:30+种预处理器让AI图像生成更精准
ComfyUI ControlNet Aux 终极指南:30种预处理器让AI图像生成更精准 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux 想让您的AI图像生成具备真实…...

Hermes Agent 连接 Taotoken 自定义供应商,完成环境变量配置
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 连接 Taotoken 自定义供应商,完成环境变量配置 基础教程类,指导用户在使用 Hermes Agent 时&…...