LLMs之Code:Qwen2.5-Coder的简介、安装和使用方法、案例应用之详细攻略
LLMs之Code:Qwen2.5-Coder的简介、安装和使用方法、案例应用之详细攻略
导读:这篇论文介绍了Qwen2.5-Coder系列模型,这是一个针对代码生成的强大开源大型语言模型。
>> 背景痛点:现有代码大型语言模型的不足:虽然现有开源代码LLM(如StarCoder, CodeLlama, DeepSeek-Coder, CodeQwen1.5, CodeStral)在编码评估中表现出色,但与最新的闭源模型(Claude-3.5-Sonnet, GPT-4o)相比仍存在差距。 这些模型在代码生成、补全、推理和修复等方面表现不够优秀。
>> 具体的解决方案:论文提出了Qwen2.5-Coder系列模型,包含六个不同规模的模型 (0.5B/1.5B/3B/7B/14B/32B)。该系列模型基于Qwen2.5架构,并进行了以下改进:
● 大规模预训练数据:使用超过5.5 T的token的代码特定预训练数据集,该数据集包含多种类型的数据,包括源代码数据、文本-代码关联数据、合成数据、数学数据和文本数据。数据清洗过程使用了多阶段的过滤方法,并结合了弱模型分类器和评分器。预训练过程包含文件级别和仓库级别两个阶段,以确保全面覆盖。
● 精心设计的指令微调数据集:为了将模型转化为代码助手,论文构建了一个高质量的指令微调数据集,包含各种代码相关问题和解决方案,数据来源包括真实世界应用和代码LLM生成的合成数据。 该数据集的构建使用了多种技术,例如:多语言编程代码识别、从GitHub合成指令数据、多语言代码指令数据生成(多Agent协作框架)、指令数据检查列表评分和多语言沙箱代码验证。
● 数据混合策略:为了平衡编码能力和通用语言理解能力,论文对代码、数学和文本数据进行了仔细的混合,最终比例为70%代码、20%文本和10%数学数据。
● 去污染:为了避免测试集泄漏导致结果膨胀,对预训练和后训练数据集进行了去污染处理,移除了HumanEval、MBPP、GSM8K和MATH等关键数据集。
>> 核心思路步骤:Qwen2.5-Coder的训练过程分为三个阶段:
● 阶段一:文件级别预训练:使用最大长度为8192个token的序列进行预训练,目标包括下一个token预测和Fill-in-the-Middle (FIM)。
● 阶段二:仓库级别预训练:将上下文长度扩展到32768个token,并使用YARN机制支持高达131072个token的序列,目标同样包括下一个token预测和仓库级别的FIM。
● 阶段三:指令微调:使用精心设计的指令微调数据集,采用粗到细的微调策略,并结合了监督微调和直接偏好优化 (DPO),其中DPO利用了多语言代码沙箱和LLM作为评判者。
>> 优势:Qwen2.5-Coder系列模型在代码生成任务上取得了显著的成果,在多个基准测试中达到了最先进的水平,甚至在某些任务上超越了更大的模型。
● 强大的代码生成能力:在多个代码相关基准测试中取得了最先进的性能,包括代码生成、补全、推理和修复。在相同模型规模下,其性能优于更大的模型。
● 多语言支持:在多种编程语言上表现出色,平衡了不同语言的性能。
● 强大的数学和通用语言能力:在数学推理和通用自然语言理解方面也表现良好。
● 长上下文能力:支持高达128K token的输入长度。
● 开源:采用许可的开源许可证,方便开发者使用。
>> 结论和观点:
● 大规模高质量的数据和精心设计的训练策略对于构建强大的代码LLM至关重要。
● 规模化(大规模数据和模型)是构建强大代码LLM的关键。 该模型的开源发布将促进代码智能研究的发展,并支持开发者在实际应用中更广泛地采用。
目录
相关文章
《Qwen2.5-Coder Technical Report》翻译与解读
Qwen2.5-Coder的简介
1、Qwen2.5-Coder 特点
2、模型列表
3、特殊 token 及其对应的 token id
4、模型评估
5、训练策略
Qwen2.5-Coder的安装和使用方法
1、安装
2、使用方法
(1)、与 Qwen2.5-Coder-32B-Instruct (指令模型) 进行对话
(2)、使用 Qwen2.5-Coder-32B (基础模型) 进行代码补全(code completion)任务
(3)、采用YaRN 技术处理长文本 (超过 32,768 tokens):
(4)、文件级代码补全 ("fill-in-the-middle")
(5)、仓库级代码补全
3、部署
(1)、使用 vLLM 部署 Qwen2.5-Coder
离线批量推理
多 GPU 分布式服务
(2)、基于Gradio界面以获得更好的体验
Qwen2.5-Coder的案例应用
1、基础用法
相关文章
《Qwen2.5-Coder Technical Report》翻译与解读
| 地址 | 论文地址:https://arxiv.org/abs/2409.12186 |
| 时间 | 2024年9月18日 |
| 作者 | 阿里巴巴-通义千问团队 |
| 摘要 | 在本报告中,我们将介绍Qwen2.5-Coder系列,这是对其前身CodeQwen1.5的重大升级。该系列包括六个型号:qwen2.5 -编码器-(0.5B/1.5B/3B/7B/14B/32B)。作为一个特定于代码的模型,Qwen2.5- coder建立在Qwen2.5架构之上,并在超过5.5万亿个token的庞大语料库上继续进行预训练。通过细致的数据清理、可扩展的合成数据生成和平衡的数据混合,Qwen2.5-Coder展示了令人印象深刻的代码生成能力,同时保留了通用和数学技能。这些模型已经在广泛的代码相关任务上进行了评估,在超过10个基准测试中实现了最先进的(SOTA)性能,包括代码生成、完成、推理和修复,始终优于相同模型大小的更大模型。我们相信Qwen2.5-Coder系列的发布将推动代码智能的研究,并且凭借其宽松的许可,支持开发人员在实际应用中更广泛地采用。 |
Qwen2.5-Coder的简介
2024年11月,发布Qwen2.5-Coder 是阿里云Qwen团队开发的Qwen2.5大型语言模型系列的代码版本。它是一个强大的、多样化的、实用的开源代码大型语言模型 (Open CodeLLM)。此前被称为 CodeQwen1.5。
GitHub地址:GitHub - QwenLM/Qwen2.5-Coder: Qwen2.5-Coder is the code version of Qwen2.5, the large language model series developed by Qwen team, Alibaba Cloud.
1、Qwen2.5-Coder 特点
>> 强大 (Powerful):Qwen2.5-Coder-32B-Instruct 成为当前最先进的开源代码模型,其编码能力可与 GPT-4o 相媲美。它展现出强大且全面的编码能力,同时具备良好的通用和数学能力。
>> 多样 (Diverse):在之前开源的 1.5B/7B 两个尺寸的基础上,此次发布增加了四个模型尺寸,包括 0.5B/3B/14B/32B。目前,Qwen2.5-Coder 涵盖了六个主流模型尺寸,以满足不同开发者的需求。
>> 实用 (Practical):该项目探索了 Qwen2.5-Coder 在代码助手和 Artifacts 两种场景中的实用性,并提供了一些示例,展示了 Qwen2.5-Coder 在现实世界场景中的潜在应用。
>> 长上下文理解和生成:支持 128K tokens 的上下文长度。
>> 支持多种编程语言:支持 92 种编程语言 (具体语言列表见原文)。并保留了基础模型的数学和通用能力优势。
['ada', 'agda', 'alloy', 'antlr', 'applescript', 'assembly', 'augeas', 'awk', 'batchfile', 'bluespec', 'c', 'c#', 'c++', 'clojure', 'cmake', 'coffeescript', 'common-lisp', 'css', 'cuda', 'dart', 'dockerfile', 'elixir', 'elm', 'emacs-lisp', 'erlang', 'f#', 'fortran', 'glsl', 'go', 'groovy', 'haskell', 'html', 'idris', 'isabelle', 'java', 'java-server-pages', 'javascript', 'json', 'julia', 'jupyter-notebook', 'kotlin', 'lean', 'literate-agda', 'literate-coffeescript', 'literate-haskell', 'lua', 'makefile', 'maple', 'markdown', 'mathematica', 'matlab', 'objectc++', 'ocaml', 'pascal', 'perl', 'php', 'powershell', 'prolog', 'protocol-buffer', 'python', 'r', 'racket', 'restructuredtext', 'rmarkdown', 'ruby', 'rust', 'sas', 'scala', 'scheme', 'shell', 'smalltalk', 'solidity', 'sparql', 'sql', 'stan', 'standard-ml', 'stata', 'swift', 'systemverilog', 'tcl', 'tcsh', 'tex', 'thrift', 'typescript', 'verilog', 'vhdl', 'visual-basic', 'vue', 'xslt', 'yacc', 'yaml', 'zig']
2、模型列表
| model name | type | length | Download |
|---|---|---|---|
| Qwen2.5-Coder-0.5B | base | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-1.5B | base | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-3B | base | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-7B | base | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-14B | base | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-32B | base | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-0.5B-instruct | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-1.5B-instruct | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-3B-instruct | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-7B-instruct | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-14B-instruct | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-32B-instruct | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-0.5B-Instruct-AWQ | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-0.5B-Instruct-GGUF | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-0.5B-Instruct-GPTQ-Int4 | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-0.5B-Instruct-GPTQ-Int8 | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-1.5B-Instruct-AWQ | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-1.5B-Instruct-GGUF | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-1.5B-Instruct-GPTQ-Int4 | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-1.5B-Instruct-GPTQ-Int8 | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-3B-Instruct-AWQ | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-3B-Instruct-GGUF | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-3B-Instruct-GPTQ-Int4 | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-3B-Instruct-GPTQ-Int8 | instruct | 32k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-7B-Instruct-AWQ | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-7B-Instruct-GGUF | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-7B-Instruct-GPTQ-Int4 | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-7B-Instruct-GPTQ-Int8 | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-14B-Instruct-AWQ | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-14B-Instruct-GGUF | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-14B-Instruct-GPTQ-Int4 | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-14B-Instruct-GPTQ-Int8 | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-32B-Instruct-AWQ | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-32B-Instruct-GGUF | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-32B-Instruct-GPTQ-Int4 | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
| Qwen2.5-Coder-32B-Instruct-GPTQ-Int8 | instruct | 128k | 🤗 Hugging Face • 🤖 ModelScope |
3、特殊 token 及其对应的 token id
为了与 Qwen2.5 保持一致,我们更新了特殊 token 及其对应的 token id。新的特殊 token 如下:
{"<|fim_prefix|>": 151659, "<|fim_middle|>": 151660, "<|fim_suffix|>": 151661, "<|fim_pad|>": 151662, "<|repo_name|>": 151663, "<|file_sep|>": 151664, "<|im_start|>": 151644, "<|im_end|>": 151645
}4、模型评估

5、训练策略

图2:Qwen2.5-Coder的三阶段训练流水线。
Qwen2.5-Coder的安装和使用方法
1、安装
需要 Python 3.9 或更高版本以及 transformers>4.37.0 (因为 transformers 从 4.37.0 版本开始集成 Qwen2 代码)。可以使用以下命令安装所需的包
pip install -r requirements.txt2、使用方法
使用方法:主要通过 transformers 库进行调用。 使用方法根据任务类型不同而有所区别,
Qwen2.5-Coder-[0.5-32]B-Instrcut是用于聊天的指令模型;
Qwen2.5-Coder-[0.5-32]B是一个通常用于完成的基础模型,可以作为微调的更好起点。
(1)、与 Qwen2.5-Coder-32B-Instruct (指令模型) 进行对话
使用 AutoModelForCausalLM 和 AutoTokenizer 加载模型和分词器,并使用 apply_chat_template 函数将消息转换为模型可理解的格式,然后使用 generate 方法进行对话。 max_new_tokens 参数控制响应的最大长度。 代码示例见原文。
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "Qwen/Qwen2.5-Coder-32B-Instruct"model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)prompt = "write a quick sort algorithm."
messages = [{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)generated_ids = model.generate(**model_inputs,max_new_tokens=512
)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]函数apply_chat_template()用于将消息转换为模型可以理解的格式。add_generation_prompt参数用于添加生成提示,该<|im_start|>assistant\n提示引用输入。值得注意的是,我们按照以前的惯例将 ChatML 模板应用于聊天模型。max_new_tokens参数用于设置响应的最大长度。函数tokenizer.batch_decode()用于解码响应。就输入而言,上述消息是一个示例,用于展示如何格式化对话历史记录和系统提示。您可以以相同的方式使用其他大小的指示模型。
(2)、使用 Qwen2.5-Coder-32B (基础模型) 进行代码补全(code completion)任务
加载模型和分词器,使用 generate 方法进行代码补全。 max_new_tokens 参数控制输出的最大长度。 代码示例见原文。
from transformers import AutoTokenizer, AutoModelForCausalLMdevice = "cuda" # the device to load the model onto# Now you do not need to add "trust_remote_code=True"
TOKENIZER = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-Coder-32B")
MODEL = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-Coder-32B", device_map="auto").eval()# tokenize the input into tokens
input_text = "#write a quick sort algorithm"
model_inputs = TOKENIZER([input_text], return_tensors="pt").to(device)# Use `max_new_tokens` to control the maximum output length.
generated_ids = MODEL.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=False)[0]
# The generated_ids include prompt_ids, so we only need to decode the tokens after prompt_ids.
output_text = TOKENIZER.decode(generated_ids[len(model_inputs.input_ids[0]):], skip_special_tokens=True)print(f"Prompt: {input_text}\n\nGenerated text: {output_text}")(3)、采用YaRN 技术处理长文本 (超过 32,768 tokens):
使用 YaRN 技术来处理超过 32,768 tokens 的长输入。 需要在 config.json 文件中添加相应的配置。
{...,"rope_scaling": {"factor": 4.0,"original_max_position_embeddings": 32768,"type": "yarn"}
}(4)、文件级代码补全 ("fill-in-the-middle")
使用 <|fim_prefix|>, <|fim_suffix|>, 和 <|fim_middle|> 这三个特殊标记来表示代码结构的不同部分。 代码示例见原文。
代码插入任务也称为“填补中间”挑战,要求以填补给定代码上下文中空白的方式插入代码段。对于符合最佳实践的方法,我们建议遵守论文“有效训练语言模型以填补中间”[ arxiv ]中概述的格式指南。这涉及使用三个专门的标记<fim_prefix>、<fim_suffix>和<fim_middle>来表示代码结构的各个段。提示的结构应如下:
prompt = '<|fim_prefix|>' + prefix_code + '<|fim_suffix|>' + suffix_code + '<|fim_middle|>'from transformers import AutoTokenizer, AutoModelForCausalLM
# load model
device = "cuda" # the device to load the model ontoTOKENIZER = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-Coder-32B")
MODEL = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-Coder-32B", device_map="auto").eval()input_text = """<|fim_prefix|>def quicksort(arr):if len(arr) <= 1:return arrpivot = arr[len(arr) // 2]<|fim_suffix|>middle = [x for x in arr if x == pivot]right = [x for x in arr if x > pivot]return quicksort(left) + middle + quicksort(right)<|fim_middle|>"""model_inputs = TOKENIZER([input_text], return_tensors="pt").to(device)# Use `max_new_tokens` to control the maximum output length.
generated_ids = MODEL.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=False)[0]
# The generated_ids include prompt_ids, we only need to decode the tokens after prompt_ids.
output_text = TOKENIZER.decode(generated_ids[len(model_inputs.input_ids[0]):], skip_special_tokens=True)print(f"Prompt: {input_text}\n\nGenerated text: {output_text}")(5)、仓库级代码补全
使用 <|repo_name|> 和 <|file_sep|> 这两个特殊标记来表示仓库结构。 代码示例见原文。
重要提示:Qwen2.5-Coder-[0.5-32]B-Instrcut 是用于聊天的指令模型;Qwen2.5-Coder-[0.5-32]B 是基础模型,通常用于代码补全,并且是微调的更好起点。 模型更新了特殊标记及其对应的标记 ID,以保持与 Qwen2.5 的一致性。新的特殊标记及其 ID 见原文。
input_text = f'''<|repo_name|>{repo_name}
<|file_sep|>{file_path1}
{file_content1}
<|file_sep|>{file_path2}
{file_content2}'''from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" # the device to load the model onto# Now you do not need to add "trust_remote_code=True"
TOKENIZER = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-Coder-32B")
MODEL = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-Coder-32B", device_map="auto").eval()# tokenize the input into tokens
input_text = """<|repo_name|>library-system
<|file_sep|>library.py
class Book:def __init__(self, title, author, isbn, copies):self.title = titleself.author = authorself.isbn = isbnself.copies = copiesdef __str__(self):return f"Title: {self.title}, Author: {self.author}, ISBN: {self.isbn}, Copies: {self.copies}"class Library:def __init__(self):self.books = []def add_book(self, title, author, isbn, copies):book = Book(title, author, isbn, copies)self.books.append(book)def find_book(self, isbn):for book in self.books:if book.isbn == isbn:return bookreturn Nonedef list_books(self):return self.books<|file_sep|>student.py
class Student:def __init__(self, name, id):self.name = nameself.id = idself.borrowed_books = []def borrow_book(self, book, library):if book and book.copies > 0:self.borrowed_books.append(book)book.copies -= 1return Truereturn Falsedef return_book(self, book, library):if book in self.borrowed_books:self.borrowed_books.remove(book)book.copies += 1return Truereturn False<|file_sep|>main.py
from library import Library
from student import Studentdef main():# Set up the library with some bookslibrary = Library()library.add_book("The Great Gatsby", "F. Scott Fitzgerald", "1234567890", 3)library.add_book("To Kill a Mockingbird", "Harper Lee", "1234567891", 2)# Set up a studentstudent = Student("Alice", "S1")# Student borrows a book
"""
model_inputs = TOKENIZER([input_text], return_tensors="pt").to(device)# Use `max_new_tokens` to control the maximum output length.
generated_ids = MODEL.generate(model_inputs.input_ids, max_new_tokens=1024, do_sample=False)[0]
# The generated_ids include prompt_ids, so we only need to decode the tokens after prompt_ids.
output_text = TOKENIZER.decode(generated_ids[len(model_inputs.input_ids[0]):], skip_special_tokens=True)print(f"Prompt: \n{input_text}\n\nGenerated text: \n{output_text}")预期输出如下:
Generated text:book = library.find_book("1234567890")if student.borrow_book(book, library):print(f"{student.name} borrowed {book.title}")else:print(f"{student.name} could not borrow {book.title}")# Student returns a bookif student.return_book(book, library):print(f"{student.name} returned {book.title}")else:print(f"{student.name} could not return {book.title}")# List all books in the libraryprint("All books in the library:")for book in library.list_books():print(book)if __name__ == "__main__":
main()
3、部署
(1)、使用 vLLM 部署 Qwen2.5-Coder
离线批量推理
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# Initialize the tokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-Coder-32B")# Pass the default decoding hyperparameters of Qwen1.5-32B-Chat
# max_tokens is for the maximum length for generation.
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, repetition_penalty=1.05, max_tokens=1024)# Input the model name or path. Can be GPTQ or AWQ models.
llm = LLM(model="Qwen/Qwen2.5-Coder-32B")# Prepare your prompts
prompt = "#write a quick sort algorithm.\ndef quick_sort("# generate outputs
outputs = llm.generate([prompt], sampling_params)# Print the outputs.
for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")多 GPU 分布式服务
为了扩大服务吞吐量,分布式服务可以帮助您利用更多 GPU 设备。使用超长序列进行推理时,可能会导致 GPU 内存不足。在这里,我们演示如何通过传入参数来运行具有张量并行性的 Qwen2.5-Coder-32B tensor_parallel_size。
llm = LLM(model="Qwen/Qwen2.5-Coder-32B", tensor_parallel_size=8)(2)、基于Gradio界面以获得更好的体验
# 切换到聊天机器人演示目录
cd demo/chatbot/
# Linux和Windows用户以及搭载Intel处理器的macOS用户运行以下命令
python app.py # 搭载Apple Silicon的macOS用户运行以下命令,不支持Intel,性能可能比RTX 4090慢20倍
PYTORCH_ENABLE_MPS_FALLBACK=1 python app.py# 切换到提供Gradio界面的工件模式演示目录
cd demo/artifacts/
# 运行应用
python app.py# 可根据需求指定--server_port, --share, --server_name等参数Qwen2.5-Coder的案例应用
1、基础用法
>> 代码助手:作为代码助手,可以根据提示生成代码,进行代码补全,以及处理长文本和文件级的代码补全任务。
>> Artifacts:项目探索了在Artifacts场景下的应用,但具体细节未在提供的文本中详细说明。
>> Gradio 接口:提供了 Gradio 接口,方便用户使用 (包含聊天模式和 Artifacts 模式)。 运行方法见原文。
>> vLLM 部署:支持使用 vLLM 进行部署,包括离线批量推理和多 GPU 分布式服务。 示例代码见原文。
>> 模型下载:模型可以在 Hugging Face 和 ModelScope 上下载。 不同尺寸和类型的模型 (base, instruct, 以及不同量化方式的模型) 均可下载,具体见原文表格。
相关文章:
LLMs之Code:Qwen2.5-Coder的简介、安装和使用方法、案例应用之详细攻略
LLMs之Code:Qwen2.5-Coder的简介、安装和使用方法、案例应用之详细攻略 导读:这篇论文介绍了Qwen2.5-Coder系列模型,这是一个针对代码生成的强大开源大型语言模型。 >> 背景痛点:现有代码大型语言模型的不足:虽然…...

pytest结合allure做接口自动化
这是一个采用pytest框架,结合allure完成接口自动化测试的项目,最后采用allure生成直观美观的测试报告,由于添加了allure的特性,使得测试报告覆盖的内容更全面和阅读起来更方便。 1. 使用pytest构建测试框架,首先配置好…...
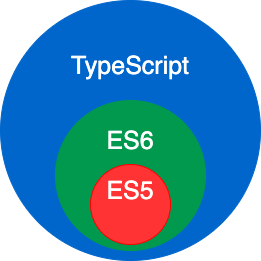
TypeScript简介:TypeScript是JavaScript的一个超集
官方描述:TypeScript 是 JavaScript 的一个超集 GitHub官网:https://github.com/Microsoft/TypeScript TypeScript is a superset of JavaScript that compiles to clean JavaScript output. TypeScript 是 JavaScript 的一个超集,支持 EC…...

【循环测试试题2】小X与三次方
题目描述 卡卡西要过 10 岁生日啦!今年,她特别想要一份与众不同的礼物,那就是一条能在阳光下发出五光十色耀眼光芒的水晶项链。她把这个想法告诉了妈妈。妈妈对卡卡西神秘的一笑,透露道:“邻居芭比阿姨家有个后花园。…...

【Python · PyTorch】卷积神经网络(基础概念)
【Python PyTorch】卷积神经网络 CNN(基础概念) 0. 生物学相似性1. 概念1.1 定义1.2 优势1.2.1 权重共享1.2.2 局部连接1.2.3 层次结构 1.3 结构1.4 数据预处理1.4.1 标签编码① One-Hot编码 / 独热编码② Word Embedding / 词嵌入 1.4.2 归一化① Min-…...

深入描述dts和dtsi的区别
QA:dts和dtsi的区别 在嵌入式 Linux 系统中,DTS(Device Tree Source)和 DTSI(Device Tree Source Include)是描述硬件设备树的文件格式。它们本质上是同一种语法的文件,但在使用上有一定区别。…...

京准时钟:一种北斗卫星校时器的结构设计
京准时钟:一种北斗卫星校时器的结构设计 京准时钟:一种北斗卫星校时器的结构设计 1、有关时间的一些基本概念: 时间与频率之间互为倒数关系,两者密不可分,时间标准的基础是频率标准,由晶体振荡器决定时间…...

【WiFi】ubuntu20.4 WiFi6 无线抓包环境搭建及使用
环境说明 笔记本电脑,无线网卡AX200,安装ubuntu20.04 安装无线网卡工具aircrack-ng sudo apt-get install aircrack-ng 安装wireshark sudo add-apt-repository ppa:wireshark-dev/stable sudo apt update sudo apt -y install wireshark sudo apt -…...

《Java核心技术 卷I》用户界面AWT事件继承层次
AWT事件继承层次 EventObject类有一个子类AWTEvent,它是所有AWT事件类的父类。 Swing组件会生成更多其他事件对象,都直接拓展自EventObject而不是AWTEvent。 AWT将事件分为底层(low-level)事件和语义事件。 语义事件:表示用户的动作事件&…...

蓝牙 HFP 协议详解及 Android 实现
文章目录 前言一、什么是蓝牙 HFP 协议?HFP 的核心功能HFP 的核心功能HFP 在 Android 中的典型应用场景 二、HFP 协议的工作流程HFP 的连接流程 三、HFP 在 Android 的实现1. 检查蓝牙适配器状态2. 发现并检测支持 HFP 的设备3. 获取 BluetoothHeadset 服务4. 连接设…...

sqli-labs靶场17-20关(每日四关)持续更新!!!
Less-17 打开靶场,发现页面比之前多了一行字 翻译过来就是,密码重置,大家肯定会想到,自己平时在日常生活中怎么密码重置,肯定是输入自己的用户名,输入旧密码,输入新密码就可以了,但…...

动态规划-完全背包问题——518.零钱兑换II
1.题目解析 建议先看 322.零钱兑换可以 更加轻松的理解本题 题目来源 518.零钱兑换——力扣 测试用例 2.算法原理 1.状态表示 本题要求返回所有情况,所以dp值就代表所有的方法数,即 dp[i][j]:在[1,i]个硬币中选择不同面值的硬币,…...

[模板总结] - 单向链表LinkedList操作
题目汇总 Leetcode 21, 82, 160, 206, 237, 268 Leetcode 21. 合并两个有序链表 归并排序的思路,创建一个哨兵节点从两个链表中按大小插入即可。 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(…...

fastadmin多个表crud连表操作步骤
1、crud命令 php think crud -t xq_user_credential -u 1 -c credential -i voucher_type,nickname,user_id,voucher_url,status,time --forcetrue2、修改控制器controller文件 <?phpnamespace app\admin\controller;use app\common\controller\Backend;/*** 凭证信息…...

山西省网络建设与运维第十八届职业院校技能大赛(样题)
集团计划把部分业务由原有的 X86 架构服务器 上迁移到 ARM 架构服务器上,同时根据目前的部分业务需求进行了部分 调整和优化。 一、 X86 架构计算机安装与管理 1、PC1系统为 ubuntu-desktop-amd64 系统,登录用户为 xiao,密码为 Key-1122。在对…...

服务端高并发分布式结构进阶之路
序言 在技术求知的旅途中,鉴于多数读者缺乏在中大型系统实践中的亲身体验,难以从宏观角度把握某些概念,因此,本文特选取“电子商务应用”作为实例,详细阐述从百级至千万级并发场景下服务端架构的逐步演变历程。同时&am…...

分布式微服务项目,同一个controller不同方法间的转发导致cookie丢失,报错null pointer异常
源码: /***添加商品进入购物车*/ GetMapping("/addToCart") public String addToCart(RequestParam("num") Integer num, RequestParam("skuId") Long skuId, RedirectAttributes redirectAttributes) {System.out.println("nu…...

STM32 ADC --- 任意单通道采样
STM32 ADC — 单通道采样 文章目录 STM32 ADC --- 单通道采样cubeMX配置代码修改:应用 使用cubeMX生成HAL工程 需求:有多个通道需要进行ADC采样,实现每次采样只采样一个通道,且可以随时采样不同通道的功能。 cubeMX配置 这里我们…...

vscode中执行git合并操作需要输入合并commit信息,打开的nano小型文本编辑器说明-
1.前提: VScode中的git组件执行任何合并动作的时候需要提交远程合并的commit信息,然后编辑器自动打开的是nano文本编辑器 2.nano编辑器说明: 1.保存文件:按 Ctrl O,然后按 Enter 来保存文件。 2.退出编辑器…...

蓝桥杯每日真题 - 第7天
题目:(爬山) 题目描述(X届 C&C B组X题) 解题思路: 前缀和构造:为了高效地计算子数组的和,我们可以先构造前缀和数组 a,其中 a[i] 表示从第 1 个元素到第 i 个元素的…...

空洞骑士模组管理器Scarab:2024年最全面的安装与管理指南
空洞骑士模组管理器Scarab:2024年最全面的安装与管理指南 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为空洞骑士模组安装的复杂流程而烦恼吗?…...

3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍
3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过这样的情况࿱…...

前端工程化实战:基于 Kelivo 模板的配置即代码与自动化工作流
1. 项目概述与核心价值最近在整理个人开发环境时,发现一个挺有意思的项目,叫Chevey339/kelivo。乍一看这个仓库名,可能有点摸不着头脑,但点进去之后,你会发现它是一个围绕特定开发工具或框架进行深度定制、优化和功能增…...

开源办公套件自动化部署与集成实战:基于OpenOffice的服务化解决方案
1. 项目概述:为什么我们需要一个“开源”的办公套件?如果你在GitHub上搜索过办公软件相关的仓库,大概率会看到过longyangxi/OpenOffice这个项目。乍一看,你可能会以为这是一个Apache OpenOffice的镜像或者某个分支。但点进去仔细研…...

Unity区域加载系统:实现开放世界无缝加载与内存优化
1. 项目概述:一个高效、可扩展的Unity区域加载系统 最近在做一个开放世界风格的项目,场景大了之后,加载卡顿和内存管理就成了老大难问题。传统的Unity场景加载,要么一股脑全塞进内存,要么就得自己写一堆脚本来手动控制…...

如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南
如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经历过手机丢失、微信重装后珍贵聊天…...

从零打造开源机械爪:低成本机器人抓取方案全解析
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“OpenClawTuto”。光看这个名字,你可能会有点摸不着头脑,它不像“XX管理系统”或者“XX深度学习框架”那样一目了然。但作为一个在开源社区和自动化领域摸爬滚打了十来年的老手…...

终极网络资源下载神器:面向内容创作者的5步实战指南
终极网络资源下载神器:面向内容创作者的5步实战指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否曾为保…...

Linux光标主题管理工具x-cursor-help:从原理到实战
1. 项目概述:一个被低估的鼠标光标辅助工具如果你在Linux桌面环境下工作,尤其是使用像GNOME、KDE Plasma这类现代化的桌面环境,你可能会遇到一个不大不小但很恼人的问题:鼠标光标主题的安装和管理。从网上下载了一个漂亮的.tar.gz…...

Node.js代理池实战:proxy-agents库核心原理与高级应用
1. 项目概述与核心价值最近在折腾一些需要处理大量网络请求的自动化脚本,比如数据采集、API测试或者模拟用户操作,一个绕不开的痛点就是IP被封。单个IP频繁请求,对方服务器很容易就把你拉黑了。这时候,代理池就成了刚需。市面上成…...