快排和归并
目录
前言
快速排序
相遇位置一定比key小的原理(大):
避免效率降低方法(快排优化)
三数取中(选key优化)
小区间优化
hoare版本快排
挖坑法快排
前后指针快排
非递归快排
归并排序
非递归归并
总结:编辑
前言
本篇讲解上一篇没有讲解的快速排序和归并排序;
上篇排序:常见排序算法-CSDN博客
本期专栏:算法_海盗猫鸥的博客-CSDN博客
个人主页:海盗猫鸥-CSDN博客

这两种排序思想较为复杂,和堆排序、希尔排序,都为效率较高的排序算法;且快排和归并都分为递归和非递归两种实现方法。
快速排序

hoare方法原理解析:升序
图中循环开始时L指向比较区间的最左,R指向比较区间的最右位置
1. 假设确定最左的数为key值
2. 则R--寻找小于key的值;L++寻找大于key的值;找到后交换R和L所指向位置的值
3. 如此循环下去,直到R等于L,循环结束,将key值和相遇位置(一定小于key)的值进行交换,并将key指向相遇位置
4.完成一次循环之后,小于key的值都在此时key位置的左边,大于key的值都在key位置右边
5.将此时的key位置作为分界点,分为左右俩区间进行递归
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
void QuickSort(int* arr, int left, int right)
{if (left >= right){return;}//以key为基准int keyi = left;int begin = left;int end = right;while (begin < end){//先找小,后找大,能保证begin和end相遇位置的数据一定小于keyi位置的数据//右边找小while (begin < end && arr[end] >= arr[keyi]){end--;}//左边找大while (begin < end && arr[begin] <= arr[keyi]){begin++;}Swap(&arr[begin], &arr[end]);}//Swap(&arr[keyi], &arr[begin]);keyi = begin;QuickSort(arr, left, keyi - 1);QuickSort(arr, keyi + 1, right);
}相遇位置一定比key小的原理(大):
升序:
left做key,保证R先走,就能保证相遇位置一定小于key(相对的,right做key时,就要让L先走,保证相遇位置比key大)
降序排列时则相反
因为在上一次交换中,L与R交换值,L所指向的位置就一定已经是小于key的值了,此时到下一个循环,R先再往前走L还没有动,所以当R遇到L时就一定是上一轮交换过来的,小于key的值,所以相遇位置一定小于key;
反之如果先让L先走,那么相遇位置就一定是上一轮交换完成后,大于key的值所在的位置,也就是上一轮R所在位置,一定大于key值

当前版本的快排,当数据本身就有序时,快排的时间复杂度将会退化为N^2;
并且有栈溢出的风险,递归深度太深将导致栈溢出,因为函数栈帧空间较小
当每次的key越接近中间位置时,快排的时间复杂度约为O(N*logN):;
避免效率降低方法(快排优化)
三数取中(选key优化)
想办法使key的值更接近中间,
使用随机值赋值key(可以避免效率降低到O(N^2),但随机性任然较大);
三数取中
将排序区间的left,right和位于最中间的数比较;取大小居中的那个数作为key值;但为保证后续排序逻辑不变,要将key值和最左left位置上的值进行交换
小区间优化
假设每次key都比较接近中间位置,那么每次区间分割都可以大致看为二分,则其递归的形式就形似二叉树,效率最高;但当数据个数较少时,使用递归来排序是不太合适的
所以当区间数据个数较少时,我们可以直接使用插入排序
hoare版本快排
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}//三数取中
int GetMidi(int* arr, int left, int right)
{//返回三个数中值最小的下标int midi = (left + right) / 2;if (arr[left] > arr[midi]){if (arr[midi] > arr[right])return midi;else if (arr[left] > arr[right])return right;elsereturn left;}else//arr[left] < arr[midi]{if (arr[midi] < arr[right])return midi;else if (arr[left] < arr[right])return right;elsereturn left;}}//hoare
O(N*logN)
void QuickSort(int* arr, int left, int right)
{if (left >= right){return;}//小区间优化,不再采取递归的方式if ((right - left + 1) < 10){//传递区间的起始地址arr + leftInsertSort(arr + left, right - left + 1);}else{//以key为基准//固定以left为key时,当数组倒序时,将导致时间复杂度退化为O(N^2);//int keyi = left;//三数取中int midi = GetMidi(arr, left, right);Swap(&arr[left], &arr[midi]);//将要作为key的值交换到最左边int keyi = left;int begin = left;int end = right;while (begin < end){//先找小,后找大,能保证begin和end相遇位置的数据一定小于keyi位置的数据//右边找小while (begin < end && arr[end] >= arr[keyi]){end--;}//左边找大while (begin < end && arr[begin] <= arr[keyi]){begin++;}Swap(&arr[begin], &arr[end]);}//Swap(&arr[keyi], &arr[begin]);keyi = begin;QuickSort(arr, left, keyi - 1);QuickSort(arr, keyi + 1, right);}
}挖坑法快排

原理解析:(升序)
1. 将最左位置视为初始坑位,并将其值赋值给key存储起来,L指向最左边(此时L所指就是坑位),R指向最右位置;
2. R开始从右往左找小于key的值,找到后,将这个位置的值赋值给坑位,并将这个位置视为新的坑位;
3. 接着L从左往右找大于key的值,找到后,将这个位置的值赋值给坑位,并将这个位置视为新的坑位。
4. 直到L和R相遇(同时指向坑位),将key值赋值给坑位。此时小于key的值就都在坑位前,大于key‘的值都在坑位后
5. 以最后的坑位为分界,左右区间递归
void QuickSort(int* arr, int left, int right)
{if (left >= right){return;}//将第一个数据视为坑;int keni = left;int key = arr[keni];int begin = left;int end = right;while (begin < end){//找到小于key的值,填到坑中while (begin < end && arr[end] > key){end--;}arr[keni] = arr[end];keni = end;while (begin < end && arr[begin] < key){begin++;}arr[keni] = arr[begin];keni = begin;}//相遇后,将key值赋给坑的位置arr[keni] = key;QuickSort(arr, left, keni - 1);QuickSort(arr, keni + 1, right);
}
前后指针快排

原理解析(升序):
1. 以最左为key值,prev从排序区间的第一个位置开始,cur=prev+1开始
2. 当cur所指位置值小于key值时,prev++后将prev位置和cur位置的数据交换位置,然后cur++继续寻找下一个符合条件的数据;
3. cur所指位置值大于key时,直接cur++即可;不论cur所指是否满足交换条件,cur始终都要++;
(实际就是让大于key的值都放在prev和cur所指的区间之间,并将这些值通过交换一步步送到数组的右边);
4. 直到cur超出数组范围,此时prev所指的位置,左边就全是小于key的值,右边就全是大于key的值;
5. 交换prev位置和key位置的数据,将key重新指向prev,本次循环结束
6. 然后以新key位置为分界,左右区间递归
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
void QuickSort(int* arr, int left, int right)
{if (left >= right)return;//小区间优化if ((right - left + 1) < 10){//传递区间的起始地址arr + leftInsertSort(arr + left, right - left + 1);}else{//三数取中(此优化后,逻辑会改变,原理分析处为没有三数取中优化的解析)int midi = GetMidi(arr, left, right);Swap(&arr[left], &arr[midi]);//将要作为key的值交换到最左边int keyi = left;int prev = left, cur = left + 1;//prev和cur中间都为大于key的值while (cur <= right){if (arr[cur] < arr[keyi] && ++prev)Swap(&arr[prev], &arr[cur]);cur++;}Swap(&arr[keyi], &arr[prev]);keyi = prev;QuickSort(arr, left, keyi - 1);QuickSort(arr, keyi + 1, right);}
}
非递归快排
使用栈来模拟递归的区间分解模式;
1. 循环每走一次相当于之前的一次递归;
2. 取栈顶区间,单趟排序,然后右左子区间入栈(栈后进先出)

代码:
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
//非递归快排
//使用栈模拟递归分区逻辑(DFS深度优先)
//使用队列模拟(BFS广度优先)
void QuickSortNonR(int* arr, int left, int right)
{//创建栈,存入右左区间ST st;STInit(&st);STPush(&st,right);STPush(&st, left);//一次循环就是相当于一次递归while (!STEmpty(&st)){//取区间//栈先进后出,先出的为区间左边界int begin = STTop(&st);STPop(&st);int end = STTop(&st);STPop(&st);//排序(前后指针法)int keyi = begin;int prev = begin, cur = begin + 1;//prev和cur中间都为大于key的值while (cur <= end){if (arr[cur] < arr[keyi] && ++prev)Swap(&arr[prev], &arr[cur]);cur++;}Swap(&arr[keyi], &arr[prev]);keyi = prev;//存储右左区间if (keyi + 1 < end)//keyi + 1 < end说明还有两个数以上{STPush(&st, end);STPush(&st, keyi + 1);}if (begin < keyi - 1){STPush(&st, keyi - 1);STPush(&st, begin);}}
}快速排序的特性总结:
- 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序,上述几种在实际使用中效率差别不大
- 时间复杂度:O(N*logN)
- 空间复杂度:O(logN)(递归损耗)
- 稳定性:不稳定
归并排序

原理解析(升序):
1. 将数组从中间分为左右两个区间,
2. 如果左右区间不有序,就继续分解左右数组,直到左右区间中都只存在一个数时,左右区间就一定有序(一个单独的数据一定有序)
3. 那么如果左右区间有序,就分别从左右区间的第一个数开始比较,将左右区间中的数按照升序插入到临时数组中,完成后,临时数组中就是一个顺序结构

上文动图只显示了合并的思想,分解的思想过程是由递归过程来实现的
代码:
void _MergeSort(int* arr, int* tmp, int begin, int end)
{if (begin == end)return;//将区间从中间分为左右区间int midi = (begin + end) / 2;int begin1 = begin;int end1 = midi;int begin2 = midi + 1;int end2 = end;//[left,midi][midi+1,right]_MergeSort(arr, tmp, begin1, end1);_MergeSort(arr, tmp, begin2, end2);int i = begin;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2])//小的先插入tmp{tmp[i++] = arr[begin1++];}else{tmp[i++] = arr[begin2++];}}//将没有完成插入的一边全部插入到tmpwhile (begin1 <= end1){tmp[i++] = arr[begin1++];}while (begin2 <= end2){tmp[i++] = arr[begin2++];}//排序结果memcpy(arr+ begin, tmp + begin, sizeof(int) * (end - begin + 1));
}//归并排序
void MergeSort(int* arr, int n)
{//假设左右区间都为有序//取左右区间小的那个数插入新数组int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail!");return;}//排序核心_MergeSort(arr, tmp, 0, n - 1);free(tmp);tmp = NULL;
}注意:区间划分问题
在进行左右分区时,不能使用[left,midi-1][midi,right]来分区
由于midi是整形相除的结果,所以存在数据丢失的情况,若一个以区间[2,3]为例,midi=2;
则此时再按照midi分区,右区间仍然为[2,3],程序将陷入无限递归从而崩溃,而如果按照[left,midi][midi+1,right]来区分区间,则右区间为[3,3],满足递归条件就返回了,不会导致程序出错

非递归归并
思路:
使用循环直接模拟归并合并的过程
理想数组思路图解(数据个数等于gap)

越界问题解析:

参考代码:
//归并排序非递归
void MergeSortNonR(int* arr, int n)
{//循环模拟int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail!");return;}//两组begin,end分别表示归并的左右两组int begin1, end1;int begin2, end2;int gap = 1;while (gap < n){for (int i = 0; i < n; i += gap * 2){//i为每次比较的左右两组,最左边的起始位置begin1 = i;end1 = i + gap - 1;begin2 = i + gap;end2 = i + 2 * gap - 1;int j = i;//printf("[%d,%d][%d,%d]", begin1, end1, begin2, end2);if (begin2 >= n)break;if (end2 >= n)end2 = n - 1;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] <= arr[begin2])//=保证稳定性tmp[j++] = arr[begin1++];elsetmp[j++] = arr[begin2++];}//printf(" ");while (begin1 <= end1)tmp[j++] = arr[begin1++];while (begin2 <= end2)tmp[j++] = arr[begin2++];//每归并一组左右区间,就拷贝一次memcpy(arr + i, tmp + i, sizeof(int) * (end2 - i + 1));}//memcpy(arr, tmp, sizeof(int) * (n - 1));gap *= 2;//printf("\n");}free(tmp);tmp = NULL;
}
归并排序的特性总结:
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)(额外开辟空间)
- 稳定性:稳定
总结:

排序的介绍到这里就完结啦~
欢迎大家继续关注我的博客~

相关文章:
快排和归并
目录 前言 快速排序 相遇位置一定比key小的原理(大): 避免效率降低方法(快排优化) 三数取中(选key优化) 小区间优化 hoare版本快排 挖坑法快排 前后指针快排 非递归快排 归并排序 非递…...

VUE+SPRINGBOOT实现邮箱注册、重置密码、登录功能
随着互联网的发展,网站用户的管理、触达、消息通知成为一个网站设计是否合理的重要标志。目前主流互联网公司都支持手机验证码注册、登录。但是手机短信作为服务端网站是需要付出运营商通信成本的,而邮箱的注册、登录、重置密码,无疑成为了这…...

Vue 项目打包后环境变量丢失问题(清除缓存),区分.env和.env.*文件
Vue 项目打包后环境变量丢失问题(清除缓存),区分.env和.env.*文件 问题背景 今天在导报项目的时候遇到一个问题问题:在开发环境中一切正常,但在打包后的生产环境中,某些环境变量(如 VUE_APP_B…...

创建vue+electron项目流程
一个vue3和electron最基本的环境搭建步骤如下:// 安装 vite vue3 vite-plugin-vue-setup-extend less normalize.css mitt pinia vue-router npm create vuelatest npm i vite-plugin-vue-setup-extend -D npm i less -D npm i normalize.css -S ࿰…...

3. 用Ruby on Rails创建一个在线商城
哎呀,你这是想要我写一篇超长篇的Ruby on Rails教程啊!好吧,既然你这么热情,那我就勉为其难地给你来一篇生动有趣、充满比喻夸张讽刺修辞手法的教程吧! 1. 准备工作 1.1. 安装Ruby和Rails 1.1.1 安装Ruby 下载Ruby…...

jmeter常用配置元件介绍总结之配置元件
系列文章目录 1.windows、linux安装jmeter及设置中文显示 2.jmeter常用配置元件介绍总结之安装插件 3.jmeter常用配置元件介绍总结之线程组 4.jmeter常用配置元件介绍总结之函数助手 5.jmeter常用配置元件介绍总结之取样器 6.jmeter常用配置元件介绍总结之jsr223执行pytho…...

SpringBoot获取请求参数
spring boot获取请求参数 文章目录 spring boot获取请求参数一、简单参数二、实体参数三、数组集合参数四、日期参数五、Json参数六、路径参数 开头概述 在Spring Boot框架中,处理HTTP请求并获取请求参数是开发Web应用程序中的一项基本任务。无论是简单的GET请求还是…...

【数据结构】树——顺序存储二叉树
写在前面 在学习数据结构前,我们早就听说大名鼎鼎的树,例如什么什么手撕红黑树大佬呀,那这篇笔记不才就深入浅出的介绍二叉树。 文章目录 写在前面一、树的概念及结构1.1、数的相关概念1.2、数的表示1.3 树在实际中的运用(表示文…...

Android中perform和handle方法的区别——以handleLaunchActivity与performLaunchActivity为例
在Android系统中,perform和handle方法经常出现在关键流程中,分别承担不同的职责。这种命名约定反映了框架设计中的分层思想,帮助开发者区分任务的调度与实现。本文通过handleLaunchActivity和performLaunchActivity这两个典型方法的源码分析&…...

聊聊依赖性测试
在软件测试中,我们常常面临一个挑战:多个模块之间高度耦合,任何一个模块的异常都可能导致整个系统崩溃。如何确保这些模块之间的协作无缝衔接?这就需要依赖性测试的助力! 什么是依赖性测试?它与功能测试、…...
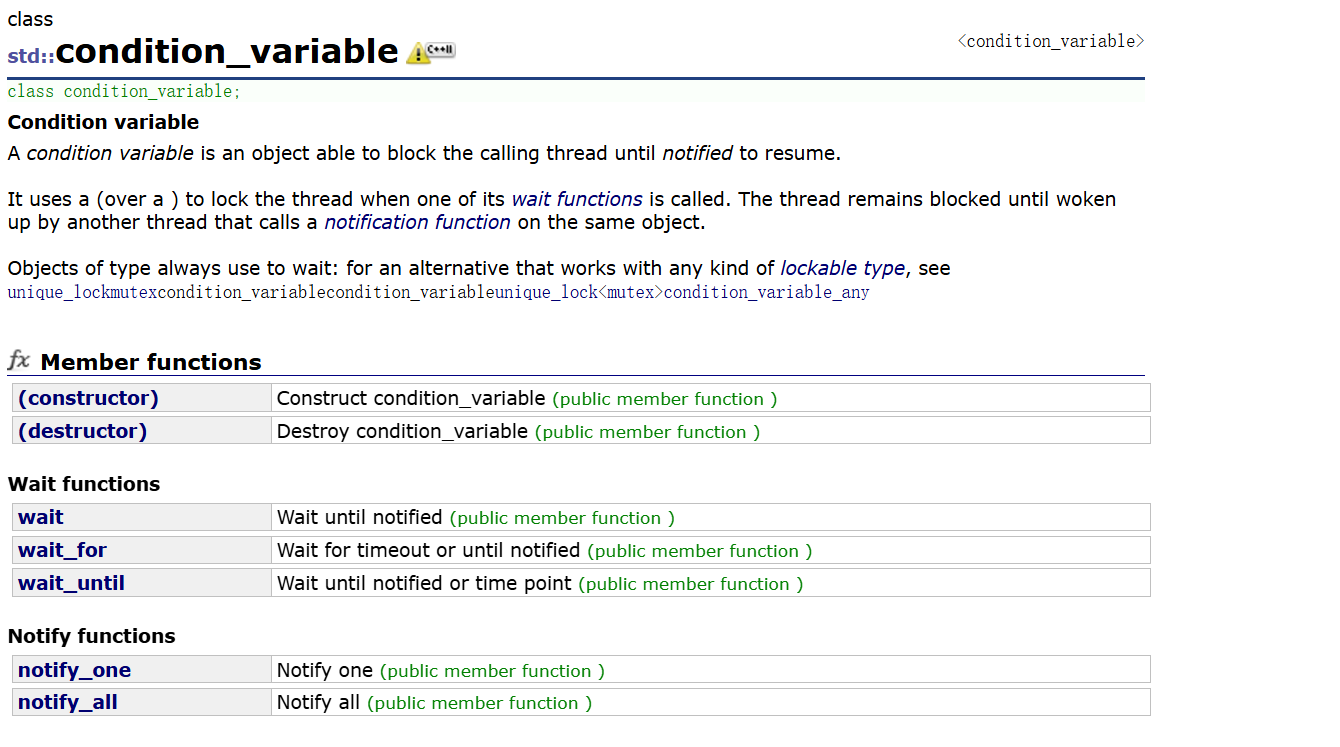
C++11————线程库
thread 类的简单介绍 在 c11 之前,涉及到多线程问题,都是和平台相关的,比如 windows 和 linux 下各自有自己的接口,这使得代码的可移植性比较差。在 c11 中引入了线程库,使得 c在编程时不需要依赖第三方库了 函数名 …...

Java 动态代理初步
动态代理初步 package ReflectExercise;import ReflectExercise.pojo.BigStar; import ReflectExercise.pojo.ProxyUtil; import ReflectExercise.pojo.Star;/*** 动态代理* 无侵入的给方法增强功能*/ public class ReflectExercise {public static void main(String[] args) {…...

应用系统开发(10) 钢轨缺陷的检测系统
涡流检测系统框图 其中信号发生器为一定频率的正弦信号作为激励信号,这个激励信号同时输入给交流电桥中的两个检测线圈,将两个线圈输出的电压差值作为差分信号引出至差分放大电路进行放大,经过放大后信号变为低频的缺陷信号叠加在高频载波上…...

理解 \r、\n、\r\n 和 \n\r:换行符的区别和用法
\r(回车,Carriage Return): ASCII 码 13,对应的控制字符是 CR,将光标回到当前行的行首(而不会换到下一行),之后的输出会把之前的输出覆盖。\n(换行,Line Feed)…...

【jvm】StringTable为什么要调整
目录 1. 永久代内存限制与回收效率2. 堆内存的优势3. JDK版本的演进4. 实际应用的考虑 1. 永久代内存限制与回收效率 1.内存限制:在JDK 6及之前的版本中,StringTable位于永久代(PermGen space)中。然而,永久代的内存空…...

AI 驱动低代码平台:开创智能化用户体验新纪元
一、引言 人工智能技术如汹涌浪潮般迅猛发展,在各个行业掀起了颠覆性的变革风暴。于软件开发领域而言,AI 辅助编程与低代码平台的完美结合已然成为关键趋势,极大地提高了开发效率。然而,低代码平台的使命绝非仅仅局限于简化开发流…...

谈一谈QThread::CurrentThread和this->thread
QThread::CurrentThread是指的当前函数调用者者所在的线程 this->thread是指的当前对象所在的线程(对象创建出来的时候所在的线程) Qt文档说明 CurrentThread返回一个指向管理当前执行线程的QThread的指针 thread返回对象所在的线程 这两个函数所…...

ThriveX 博客管理系统前后端项目部署教程
前端 前端项目地址:https://github.com/LiuYuYang01/ThriveX-Blog 控制端项目地址:https://github.com/LiuYuYang01/ThriveX-Admin Vercel 首先以 Vercel 进行部署,两种方式部署都是一样的,我们以前端项目进行演示 首先我们先…...

STM32单片机设计防儿童人员误锁/滞留车内警报系统
目录 目录 前言 一、本设计主要实现哪些很“开门”功能? 二、电路设计原理图 1.电路图采用Altium Designer进行设计: 2.实物展示图片 三、程序源代码设计 四、获取资料内容 前言 近年来在车辆逐渐普及的情况下,由于家长的疏忽,将…...

可认证数据资产合约标准协议(CMIDA-1)意见征集
标准背景 数据资产具备多维度的属性,涵盖行业特性、状态信息、资产类型、存储格式等。数据资产在不同流通主体之间可理解、可流通、可追溯、可信任的重要前提之一是存在统一的标准,缺失统一的标准,数据混乱冲突、一数多源、多样多类等问题将…...

独立开发者如何用AI验证创业点子:15分钟完成市场分析与风险评估
1. 项目概述:一个为独立开发者打造的AI创业点子验证伙伴如果你和我一样,是个喜欢自己动手鼓捣点东西的独立开发者,那你肯定也经历过这个阶段:脑子里冒出一个自认为绝妙的点子,兴奋地花上几周甚至几个月把它做出来&…...

KMS_VL_ALL_AIO:基于微软官方协议的系统激活工具技术解析
KMS_VL_ALL_AIO:基于微软官方协议的系统激活工具技术解析 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO KMS_VL_ALL_AIO是一款基于微软KMS(密钥管理服务)协议…...

PyCharm直连Spark集群:一站式配置与避坑指南
1. 为什么需要PyCharm直连Spark集群? 作为数据工程师,我经常需要在本地开发Spark应用,然后部署到远程集群执行。传统方式是本地写完代码后,手动上传到服务器再用spark-submit提交,这个过程既繁琐又容易出错。直到发现P…...

《OpenClaw语义采集:让机器第一次真正读懂网页》
传统网页采集的本质困境从未被真正打破,所有基于结构匹配的工具都逃不过网站改版的宿命。开发者耗费数小时精心编写的规则,可能在一次前端更新后彻底失效,而数据清洗的工作量往往占据整个流程的七成以上。OpenClaw的出现彻底重构了这一范式,它将采集的核心从"定位元素…...
)
保姆级教程:手把手教你搞定Automation Studio 4.7.2.98安装与90天试用授权(含官方第三方学习资源指北)
从零开始掌握Automation Studio 4.7:完整安装指南与学习资源全景图 第一次打开Automation Studio时,那个闪烁的授权提示框就像一堵高墙。作为工业自动化领域的重要工具,这款由贝加莱(现属ABB集团)开发的集成开发环境&a…...

新手教程使用Python和Taotoken快速调用大模型API完成第一个对话
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手教程:使用Python和Taotoken快速调用大模型API完成第一个对话 对于刚接触大模型API的开发者而言,第一步…...

实测Taotoken聚合API的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken聚合API的延迟与稳定性表现 作为一名需要频繁调用大模型API的开发者,选择一个稳定、响应迅速的服务平台至…...

从接入到观测 Taotoken 为开发者提供的全链路体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从接入到观测 Taotoken 为开发者提供的全链路体验 对于开发者而言,将大模型能力集成到自己的应用或项目中,…...

HDLbits实战解析:Verification模块的Simulation测试技巧
1. 从零开始理解Verification模块的仿真测试 刚开始接触数字电路设计时,很多人会陷入一个误区——认为只要把模块代码写出来就万事大吉了。直到我第一次在HDLbits上遇到Verification模块的题目,才真正明白仿真测试的重要性。仿真就像给电路设计装上"…...

如何永久保存微信聊天记录:5分钟掌握完整数据备份方案
如何永久保存微信聊天记录:5分钟掌握完整数据备份方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...