深入探索:Scrapy深度爬取策略与实践
标题:深入探索:Scrapy深度爬取策略与实践
引言
在数据驱动的时代,深度爬取成为了获取丰富信息的重要手段。Scrapy,作为一个强大的Python爬虫框架,提供了多种工具和设置来帮助我们实现深度爬取。本文将详细介绍如何在Scrapy中设置并发请求的数量,并提供实际的代码示例,以指导如何进行深度爬取。
1. 理解深度爬取
深度爬取指的是从一个或多个起始页面开始,递归地抓取链接到的页面,以获取更深层次的数据。在Scrapy中,这通常涉及到管理多个请求和响应,以及处理页面间的链接。
2. 设置并发请求
Scrapy中有几个重要的设置项可以帮助我们控制并发请求的数量,以达到优化爬取效率的目的。
a. CONCURRENT_REQUESTS
这是控制Scrapy同时处理的最大并发请求数的设置项。默认值是16,但可以根据需要进行调整。
# settings.py
CONCURRENT_REQUESTS = 32
这将设置Scrapy同时处理的最大并发请求数为32。
b. CONCURRENT_REQUESTS_PER_DOMAIN 和 CONCURRENT_REQUESTS_PER_IP
这两个设置项分别控制每个域名和每个IP的最大并发请求数。默认值通常为8和0(不限制)。
# settings.py
CONCURRENT_REQUESTS_PER_DOMAIN = 8
CONCURRENT_REQUESTS_PER_IP = 8
这些设置有助于避免对单一资源的过度请求,减少被封禁的风险。
3. 实现深度爬取的策略
a. 递归爬取
递归爬取是深度爬取中常用的策略。以下是一个简单的Scrapy爬虫示例,它从一个起始页面开始,递归地抓取所有链接到的页面。
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Ruleclass DepthCrawlSpider(CrawlSpider):name = 'depth_crawl'allowed_domains = ['example.com']start_urls = ['http://example.com/start']rules = (Rule(LinkExtractor(), callback='parse_page', follow=True),)def parse_page(self, response):# 提取数据的逻辑pass
在这个示例中,LinkExtractor用于提取页面中的所有链接,并且follow=True参数确保了链接被跟踪并递归爬取。
b. 管理请求深度
有时,我们可能需要限制爬取的深度。可以通过在Request对象中使用meta参数来传递额外的信息,例如请求的深度。
def parse_page(self, response):depth = response.meta.get('depth', 0)if depth < 3: # 限制最大深度为3for link in get_links(response):yield scrapy.Request(url=link, callback=self.parse_page, meta={'depth': depth+1})# 提取数据的逻辑
这段代码展示了如何使用meta参数来控制请求的深度。
4. 处理中间数据
在深度爬取中,中间数据的处理非常重要。Scrapy的Item Pipeline可以用来清洗和存储中间数据。
class MyPipeline(object):def process_item(self, item, spider):# 处理和存储数据的逻辑return item
在settings.py中启用这个Pipeline:
ITEM_PIPELINES = {'myproject.pipelines.MyPipeline': 300,
}
5. 结论
通过合理配置Scrapy的并发请求和使用递归爬取策略,我们可以有效地进行深度爬取。同时,管理请求深度和处理中间数据是确保爬取效率和数据质量的关键。希望本文提供的信息能帮助你在Scrapy项目中实现更有效的深度爬取。
相关文章:

深入探索:Scrapy深度爬取策略与实践
标题:深入探索:Scrapy深度爬取策略与实践 引言 在数据驱动的时代,深度爬取成为了获取丰富信息的重要手段。Scrapy,作为一个强大的Python爬虫框架,提供了多种工具和设置来帮助我们实现深度爬取。本文将详细介绍如何在…...

《生成式 AI》课程 第3講:訓練不了人工智慧嗎?你可以訓練你自己
资料来自李宏毅老师《生成式 AI》课程,如有侵权请通知下线 Introduction to Generative AI 2024 Spring 摘要 这一系列的作业是为 2024 年春季的《生成式 AI》课程设计的,共包含十个作业。每个作业都对应一个具体的主题,例如真假难辨的世界…...

如何编译 Cesium 源码
如何编译 Cesium 源码 Cesium 是一个开源的 JavaScript 库,用于构建 3D 地球和地图应用程序。它提供了一套强大的 API 和工具,使开发者能够创建丰富的地理空间应用。本文将指导您如何从 GitHub 下载 Cesium 源码,并在本地进行编译。 TilesB…...

前端开发设计模式——责任链模式
目录 一、定义和特点 1. 定义 2. 特点 二、实现方式 定义抽象处理者(Handler)类 创建具体处理者(ConcreteHandler)类 构建责任链 以下是一个用 JavaScript 实现的示例: 三、应用场景 1. 表单验证 2. 请求处…...

JavaWeb--MySQL
1. MySQL概述 首先来了解一下什么是数据库。 数据库:英文为 DataBase,简称DB,它是存储和管理数据的仓库。 像我们日常访问的电商网站京东,企业内部的管理系统OA、ERP、CRM这类的系统,以及大家每天都会刷的头条、抖音…...

Python | Leetcode Python题解之第564题数组嵌套
题目: 题解: class Solution:def arrayNesting(self, nums: List[int]) -> int:ans, n 0, len(nums)for i in range(n):cnt 0while nums[i] < n:num nums[i]nums[i] ni numcnt 1ans max(ans, cnt)return ans...
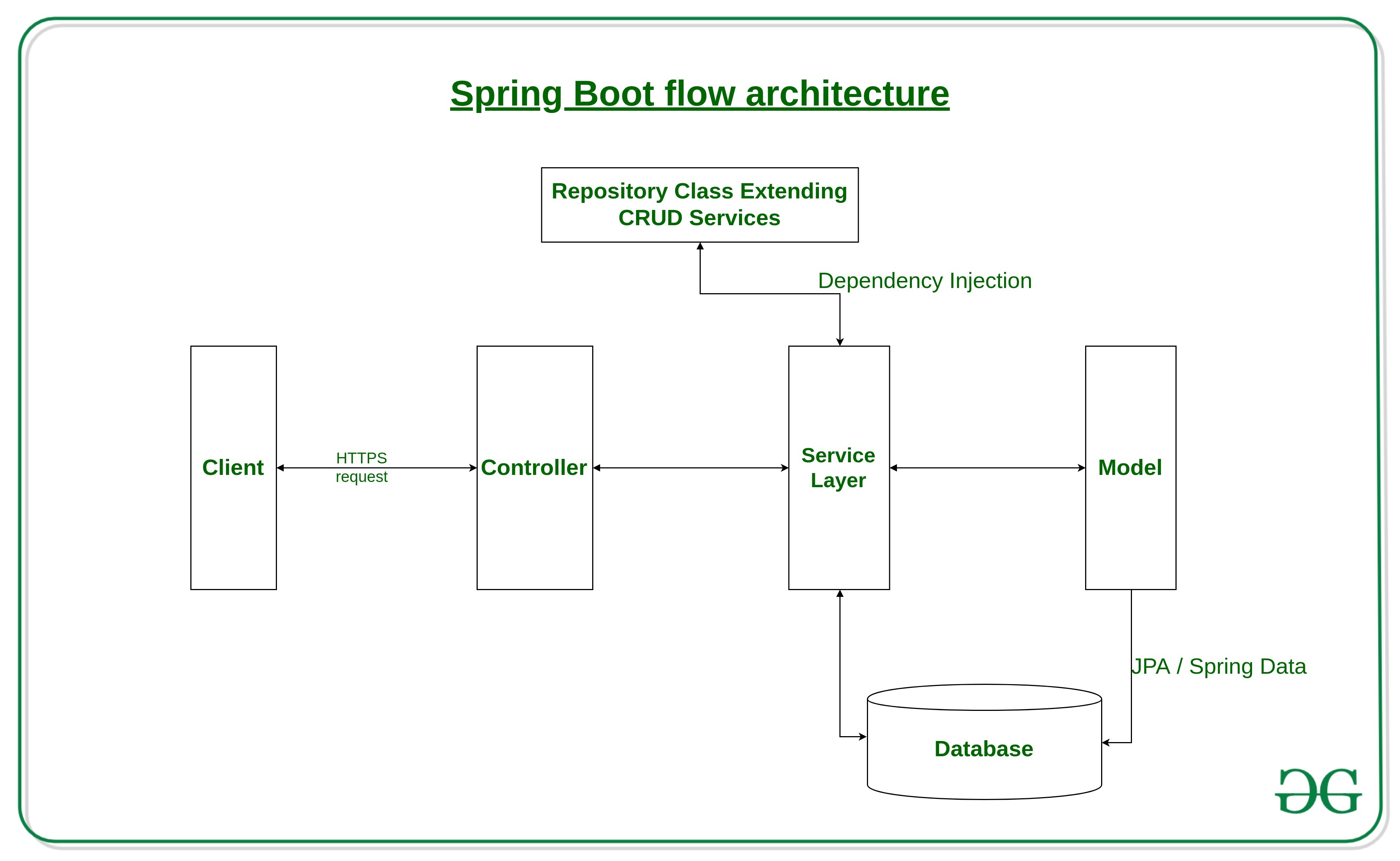
Spring Boot教程之Spring Boot简介
Spring Boot 简介 接下来一段时间,我会持续发布并完成Spring Boot教程 Spring 被广泛用于创建可扩展的应用程序。对于 Web 应用程序,Spring 提供了 Spring MVC,它是 Spring 的一个广泛使用的模块,用于创建可扩展的 Web 应用程序。…...

Qwen2-VL:发票数据提取、视频聊天和使用 PDF 的多模态 RAG 的实践指南
概述 随着人工智能技术的迅猛发展,多模态模型在各类应用场景中展现出强大的潜力和广泛的适用性。Qwen2-VL 作为最新一代的多模态大模型,融合了视觉与语言处理能力,旨在提升复杂任务的执行效率和准确性。本指南聚焦于 Qwen2-VL 在三个关键领域…...

【安全科普】NUMA防火墙诞生记
一、我为啥姓“NUMA” 随着网络流量和数据包处理需求的指数增长,曾经的我面对“高性能、高吞吐、低延迟”的要求,逐渐变得心有余而力不足。 多CPU技术应运而生,SMP(对称多处理)和NUMA(非一致性内存访问&a…...

机器学习day2-特征工程
四.特征工程 1.概念 一般使用pandas来进行数据清洗和数据处理、使用sklearn来进行特征工程 将任意数据(文本或图像等)转换为数字特征,对特征进行相关的处理 步骤:1.特征提取;2.无量纲化(预处理…...

Python数据分析NumPy和pandas(三十五、时间序列数据基础)
时间序列数据是许多不同领域的结构化数据的重要形式,例如金融、经济、生态学、神经科学和物理学。在许多时间点重复记录的任何内容都会形成一个时间序列。许多时间序列是固定频率的,也就是说,数据点根据某些规则定期出现,例如每 1…...
常见错误及排查)
Python 小高考篇(6)常见错误及排查
目录 TypeError拼接字符串和数字错误示范正确示范 数字、字符串当成函数错误示范 给函数传入未被定义过的参数错误示范 传入的参数个数不正确错误示范 字符串相乘错误示范正确示范 量取整数的长度错误示范正确示范 格式化字符串时占位符个数不正确错误示范 给复数比较大小错误示…...

k8s上部署redis高可用集群
介绍: Redis Cluster通过分片(sharding)来实现数据的分布式存储,每个master节点都负责一部分数据槽(slot)。 当一个master节点出现故障时,Redis Cluster能够自动将故障节点的数据槽转移到其他健…...

C++的类和对象
在C中,类(class)和对象(object)是面向对象编程(OOP)的核心概念。以下是它们的详细介绍: 1. 类(Class) 定义: 类是用来定义一个新的数据类型&…...

自动驾驶系列—深入解析自动驾驶车联网技术及其应用场景
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...

机器学习(1)
一、机器学习 机器学习(Machine Learning, ML)是人工智能(Artificial Intelligence, AI)的一个分支,它致力于开发能够从数据中学习并改进性能的算法和模型。机器学习的核心思想是通过数据和经验自动优化算法ÿ…...

深入理解 Redis跳跃表 Skip List 原理|图解查询、插入
1. 简介 跳跃表 ( skip list ) 是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。 在 Redis 中,跳跃表是有序集合键的底层实现之一,那么这篇文章我们就来讲讲跳跃表的实现原理。 2. …...
)
Halcon HImage 与 Qt QImage 的相互转换(修订版)
很久以前,我写过一遍文章来介绍 HImage 和 QImage 之间的转换方法。(https://blog.csdn.net/liyuanbhu/article/details/91356988) 这个代码其实是有些问题的。因为我们知道 QImage 中的图像数据不一定是连续的,尤其是图像的宽度…...

【Golang】——Gin 框架中的模板渲染详解
Gin 框架支持动态网页开发,能够通过模板渲染结合数据生成动态页面。在这篇文章中,我们将一步步学习如何在 Gin 框架中配置模板、渲染动态数据,并结合静态资源文件创建一个功能完整的动态网站。 文章目录 1. 什么是模板渲染?1.1 概…...
CSS:导航栏三角箭头
用CSS实现导航流程图的样式。可根据自己的需求进行修改,代码精略的写了一下。 注:场景一和场景二在分辨率比较低的情况下会有一个1px的缝隙不太优雅,自行处理。有个方法是直接在每个外面包一个DIV,用动态样式设置底色。 场景一、…...

基于RAG的智能客服系统实战:从架构设计到生产环境优化
最近在做一个智能客服系统的升级项目,之前用规则引擎维护起来太痛苦了,纯用大模型又贵又不准。经过一番折腾,最终用RAG(检索增强生成)技术搞定了,效果提升非常明显。今天就来分享一下从架构设计到上线优化的…...

Chatbot Arena排行榜单实战指南:从数据采集到模型优化
Chatbot Arena排行榜单实战指南:从数据采集到模型优化 在构建和优化自己的对话AI时,我们常常面临一个核心问题:如何客观、全面地评估它的性能?闭门造车式的测试往往带有主观偏见,而Chatbot Arena这类公开的排行榜单&a…...

NaViL-9B效果展示:电商主图自动提取卖点文案+竞品对比分析
NaViL-9B效果展示:电商主图自动提取卖点文案竞品对比分析 1. 多模态大模型惊艳登场 想象一下,当你上传一张商品图片,AI不仅能准确识别图片内容,还能自动生成吸引人的卖点文案——这就是NaViL-9B带来的革命性体验。作为原生多模态…...

告别鉴权内耗,让每一位Java开发者都能轻松上手
写Java的这些年,无论是初入职场的新手,还是深耕多年的老兵,谁没在「鉴权」上栽过跟头? 熬夜啃Spring Security的复杂配置,对着一堆过滤器链抓耳挠腮;用Shiro做前后端分离项目,为了适配Token模式…...

生成式AI欺诈来袭,什么样的IP数据接口才能筑起防线?
某电商平台的风控系统发出预警:一个“新用户”正在批量下单高价商品,收货地址遍布全国,支付方式各不相同。但奇怪的是,这些订单的浏览行为、停留时间、点击轨迹几乎完全一致——这不是真人,而是生成式AI模拟的虚假用户…...

3步终结告警疲劳:Keep平台的智能告警管理实践
3步终结告警疲劳:Keep平台的智能告警管理实践 【免费下载链接】keep The open-source alerts management and automation platform 项目地址: https://gitcode.com/GitHub_Trending/kee/keep 智能告警管理已成为现代运维体系的核心能力。根据Gartner最新报告…...

如何零配置搭建专业级视觉交互系统:MediaPipe TouchDesigner完全指南
如何零配置搭建专业级视觉交互系统:MediaPipe TouchDesigner完全指南 【免费下载链接】mediapipe-touchdesigner GPU Accelerated MediaPipe Plugin for TouchDesigner 项目地址: https://gitcode.com/gh_mirrors/me/mediapipe-touchdesigner 想要在TouchDes…...

QQ机器人开发零基础入门:LuckyLilliaBot插件完全指南
QQ机器人开发零基础入门:LuckyLilliaBot插件完全指南 【免费下载链接】LuckyLilliaBot NTQQ的OneBot API插件 项目地址: https://gitcode.com/gh_mirrors/li/LuckyLilliaBot 在即时通讯机器人开发领域,如何快速实现QQ平台的自动化交互?…...

3分钟告别机械键盘连击:精准修复打字困扰的Windows神器
3分钟告别机械键盘连击:精准修复打字困扰的Windows神器 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 机械键盘连击问题让无…...

实战指南:深入Terraria源码的5个核心模块与架构解析
实战指南:深入Terraria源码的5个核心模块与架构解析 【免费下载链接】Terraria-Source-Code 项目地址: https://gitcode.com/gh_mirrors/te/Terraria-Source-Code 你是否曾好奇一款2D沙盒游戏如何实现复杂的物理系统、网络同步和游戏逻辑?Terrar…...