【pyspark学习从入门到精通14】MLlib_1
目录
包的概览
加载和转换数据
在前文中,我们学习了如何为建模准备数据。在本文中,我们将实际使用这些知识,使用 PySpark 的 MLlib 包构建一个分类模型。
MLlib 代表机器学习库。尽管 MLlib 现在处于维护模式,即它不再积极开发(并且很可能会在未来被弃用),但至少覆盖库的一些特性是有必要的。此外,MLlib 目前是唯一支持流式训练模型的库。
在这一部分中,你将学习如何执行以下操作:
- 使用 MLlib 为建模准备数据
- 执行统计测试
- 使用逻辑回归预测婴儿的生存机会
- 选择最可预测的特征并训练一个随机森林模型
包的概览
在高层次上,MLlib 提供了三个核心的机器学习功能:
- 数据准备:特征提取、转换、选择、分类特征的哈希以及一些自然语言处理方法
- 机器学习算法:实现了一些流行和先进的回归、分类和聚类算法
- 实用工具:描述性统计、卡方测试、线性代数(稀疏和密集矩阵和向量)以及模型评估方法等统计方法
正如你看到的,可用功能的范围允许你执行几乎所有基本的数据科学任务。
我们将构建两个分类模型:线性回归和随机森林。我们将使用我们从 http://www.cdc.gov/nchs/data_access/vitalstatsonline.htm 下载的 2014 年和 2015 年美国出生数据的一部分;在总共 300 个变量中,我们选择了 85 个特征来构建我们的模型。此外,在总共近 799 万条记录中,我们选择了一个平衡的样本,共有 45,429 条记录:22,080 条报告婴儿死亡的记录和 23,349 条婴儿存活的记录。
加载和转换数据
尽管 MLlib 设计时以 RDD 和 DStreams 为重点,为了便于转换数据,我们将读取数据并将其转换为 DataFrame。
我们首先指定数据集的模式。
这是代码:
import pyspark.sql.types as typ
labels = [('INFANT_ALIVE_AT_REPORT', typ.StringType()),('BIRTH_YEAR', typ.IntegerType()),('BIRTH_MONTH', typ.IntegerType()),('BIRTH_PLACE', typ.StringType()),('MOTHER_AGE_YEARS', typ.IntegerType()),('MOTHER_RACE_6CODE', typ.StringType()),('MOTHER_EDUCATION', typ.StringType()),('FATHER_COMBINED_AGE', typ.IntegerType()),('FATHER_EDUCATION', typ.StringType()),('MONTH_PRECARE_RECODE', typ.StringType()),...('INFANT_BREASTFED', typ.StringType())
]
schema = typ.StructType([typ.StructField(e[0], e[1], False) for e in labels])接下来,我们加载数据。.read.csv(...) 方法可以读取未压缩或(像我们的情况)GZipped 逗号分隔值。将 header 参数设置为 True 表示第一行包含标题,我们使用 schema 指定正确的数据类型:
births = spark.read.csv('births_train.csv.gz', header=True, schema=schema)我们的数据集中有许多以字符串形式表示的特征。这些大多是我们需要以某种方式转换为数字形式的分类变量。
我们将首先指定我们的重新编码字典:
recode_dictionary = {'YNU': {'Y': 1,'N': 0,'U': 0}
}我们这一章的目标是预测 'INFANT_ALIVE_AT_REPORT' 是否为 1 或 0。因此,我们将丢弃所有与婴儿相关的特征,并将仅基于与其母亲、父亲和出生地相关的特征来尝试预测婴儿的生存机会:
selected_features = ['INFANT_ALIVE_AT_REPORT', 'BIRTH_PLACE', 'MOTHER_AGE_YEARS', 'FATHER_COMBINED_AGE', 'CIG_BEFORE', 'CIG_1_TRI', 'CIG_2_TRI', 'CIG_3_TRI', 'MOTHER_HEIGHT_IN', 'MOTHER_PRE_WEIGHT', 'MOTHER_DELIVERY_WEIGHT', 'MOTHER_WEIGHT_GAIN', 'DIABETES_PRE', 'DIABETES_GEST', 'HYP_TENS_PRE', 'HYP_TENS_GEST', 'PREV_BIRTH_PRETERM'
]
births_trimmed = births.select(selected_features)在我们的数据集中,有许多特征具有是/否/未知的值;我们只会将“是”编码为 1;其他所有值将被设置为 0。
母亲的吸烟数量编码也有一个小问题:0 表示母亲在怀孕前或怀孕期间没有吸烟,1-97 表示实际吸烟的香烟数量,98 表示 98 或更多,而 99 标识未知;我们将假设未知为 0 并相应地重新编码。
接下来,我们将指定我们的重新编码方法:
import pyspark.sql.functions as func
def recode(col, key):return recode_dictionary[key][col]
def correct_cig(feat):return func \.when(func.col(feat) != 99, func.col(feat))\.otherwise(0)
rec_integer = func.udf(recode, typ.IntegerType())重新编码方法查找 recode_dictionary 中的正确键(给定键)并返回更正后的值。correct_cig 方法检查特征 feat 的值是否不等于 99,并(在那种情况下)返回特征的值;如果值等于 99,我们得到 0,否则。
我们不能直接在 DataFrame 上使用重新编码函数;它需要被转换为 Spark 能理解的 UDF。rec_integer 就是这样一个函数:通过传递我们指定的 recode 函数并指定返回值数据类型,然后我们就可以使用它来编码我们的是/否/未知特征。
那么,让我们开始吧。首先,我们将更正与吸烟数量相关的特征:
births_transformed = births_trimmed \.withColumn('CIG_BEFORE', correct_cig('CIG_BEFORE'))\.withColumn('CIG_1_TRI', correct_cig('CIG_1_TRI'))\.withColumn('CIG_2_TRI', correct_cig('CIG_2_TRI'))\.withColumn('CIG_3_TRI', correct_cig('CIG_3_TRI')).withColumn(...) 方法将列名作为其第一个参数,转换作为第二个参数。在前面的案例中,我们没有创建新列,而是重用了相同的列。
现在,我们将专注于更正是/否/未知特征。首先,我们将找出这些特征,如下所示:
cols = [(col.name, col.dataType) for col in births_trimmed.schema]
YNU_cols = []
for i, s in enumerate(cols):if s[1] == typ.StringType():dis = births.select(s[0]) \.distinct() \.rdd \.map(lambda row: row[0]) \.collect() if 'Y' in dis:YNU_cols.append(s[0])首先,我们创建了一个包含列名和相应数据类型的元组列表(cols)。接下来,我们遍历所有这些并计算所有字符串列的不同值;如果返回的列表中有 'Y',我们将列名添加到 YNU_cols 列表中。
DataFrame 可以批量转换特征,同时选择特征。为了说明这个想法,考虑以下示例:
births.select(['INFANT_NICU_ADMISSION', rec_integer('INFANT_NICU_ADMISSION', func.lit('YNU')) \.alias('INFANT_NICU_ADMISSION_RECODE')]).take(5)这是我们得到的返回结果:
我们选择 'INFANT_NICU_ADMISSION' 列,并将特征名称传递给 rec_integer 方法。我们还重命名新转换的列为 'INFANT_NICU_ADMISSION_RECODE'。这样,我们还将确认我们的 UDF 是否按预期工作。
所以,为了一次性转换所有的 YNU_cols,我们将创建这样的转换列表,如下所示:
exprs_YNU = [rec_integer(x, func.lit('YNU')).alias(x) if x in YNU_cols else x for x in births_transformed.columns
]
births_transformed = births_transformed.select(exprs_YNU)让我们检查一下我们是否正确得到了它:
births_transformed.select(YNU_cols[-5:]).show(5)这是我们得到的:
看起来一切都按照我们的预期工作,那么让我们更好地了解我们的数据。
相关文章:
【pyspark学习从入门到精通14】MLlib_1
目录 包的概览 加载和转换数据 在前文中,我们学习了如何为建模准备数据。在本文中,我们将实际使用这些知识,使用 PySpark 的 MLlib 包构建一个分类模型。 MLlib 代表机器学习库。尽管 MLlib 现在处于维护模式,即它不再积极开发…...

C++全局构造和初始化
片段摘自程序员的自我修养—链接、装载与库.pdf 11.4 程序在进入main之前,需要对全局对象进行构造初始化。 glibc全局对象进行构造初始化 gibc启动程序时会经过.init段,退出程序时会经过.finit段。这两个段中的代码最终拼接成_init()和_finit(),这两个…...

安全见闻-泷羽sec课程笔记
编程语言 C语言:一种通用的、面向过程的编程语言,广泛应用于系统软件和嵌入式开发。 C:在C语言基础上发展而来,支持面向对象编程,常用于尊戏开发、高性能计算等领域。 Java:一种广泛使用的面问对象编程语言,具有跨平台…...

游戏引擎学习第17天
视频参考:https://www.bilibili.com/video/BV1LPUpYJEXE/ 回顾上一天的内容 1. 整体目标: 处理键盘输入:将键盘输入的处理逻辑从平台特定的代码中分离出来,放入更独立的函数中以便管理。优化消息循环:确保消息循环能够有效处理 …...
)
【FFmpeg】FFmpeg 内存结构 ③ ( AVPacket 函数简介 | av_packet_ref 函数 | av_packet_clone 函数 )
文章目录 一、av_packet_ref 函数1、函数原型2、函数源码分析3、函数使用代码示例 二、av_packet_clone 函数1、函数原型2、函数源码分析 FFmpeg 4.0 版本源码地址 : GitHub : https://github.com/FFmpeg/FFmpeg/tree/release/4.0GitCode : https://gitcode.com/gh_mirrors/ff…...

【学习笔记】量化概述
Quantize量化概念与技术细节 题外话,在七八年前,一些关于表征的研究,会去做表征的压缩,比如二进制嵌入这种事情,其实做得很简单,无非是找个阈值,然后将浮点数划归为零一值,现在的Qu…...
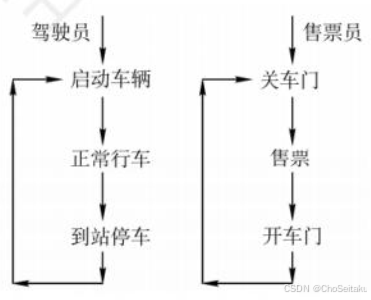
同步互斥相关习题10道 附详解
PV操作 2016 某系统允许最多10个进程同时读文件F,当同时读文件F的进程不满10个时,欲读该文件的其他文件可立即读,当已有10个进程在读文件F时读,其他欲读文件F的进程必须等待,直至有进程读完后退出方可去读 在实现管…...
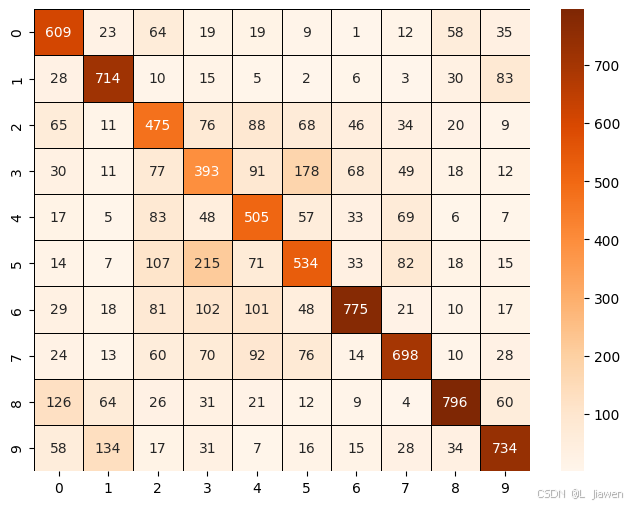
【Python · PyTorch】卷积神经网络 CNN(LeNet-5网络)
【Python PyTorch】卷积神经网络 CNN(LeNet-5网络) 1. LeNet-5网络※ LeNet-5网络结构 2. 读取数据2.1 Torchvision读取数据2.2 MNIST & FashionMNIST 下载解包读取数据 2. Mnist※ 训练 LeNet5 预测分类 3. EMnist※ 训练 LeNet5 预测分类 4. Fash…...

Git 拉取指定分支创建项目
一 背景 因为项目过大,只需要部分分支的代码即可。 二 实现 方法一:使用 --single-branch 参数 git clone 支持只拉取指定分支,而不是整个库的所有分支: git clone --branch <branch_name> --single-branch <reposi…...
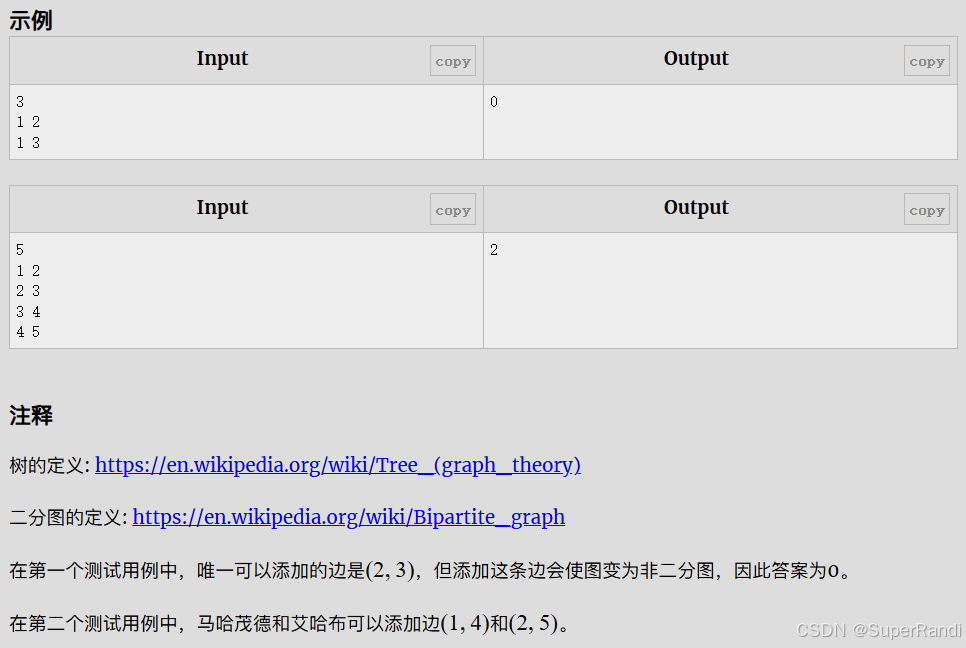
CF862B Mahmoud and Ehab and the bipartiteness(二分图的性质)
思路:一个二分图是由两个集合组成的,同一个集合中的节点间不能连边,所以一个二分图最多有cnt[1]*cnt[2]条边,题目给出一个树的n-1条边,要我们添加最多的边数使他成为二分图,添加的边数就是cnt[1]*cnt[2]-n1…...

React Native 全栈开发实战班 :数据管理与状态之React Hooks 基础
在 React Native 应用中,数据管理与状态管理是构建复杂用户界面的关键。React 提供了多种工具和模式来处理数据流和状态管理,包括 React Hooks、Context API 以及第三方状态管理库(如 Redux)。本章节将详细介绍 React Hooks 的基础…...

传奇996_22——自动挂机
登录钩子函数中执行 callscript(actor, "../QuestDiary/主界面基础按钮/主界面基础按钮QM", "基础按钮QM")基础按钮QM执行了已下代码 #IF Equal <$CLIENTFLAG> 1 #ACT goto PC端面板加载#IF Equal <$CLIENTFLAG> 2 #ACT goto 移动端面板加载…...

faiss 提供了多种索引类型
faiss 多种索引类型 在 faiss 中,IndexFlatL2 是一个简单的基于 L2 距离(欧几里得距离)进行索引的索引类型,但实际上,faiss 提供了多种索引类型,支持不同的度量方式和性能优化,您可以根据需求选…...

比rsync更强大的文件同步工具rclone
背景 多个复制,拷贝,同步文件场景,最大规模的是每次几千万规模的小文件需要从云上对象存储中拉取到本地。其他的诸如定期数据备份,单次性数据备份。 rsync是单线程的,开源的mrsync是多线程的,但适用范围没…...

《业务流程--穿越从概念到实践的丛林》读后感一:什么是业务流程
1.1 流程和业务流程概念辨析 业务流程建模标准(BPMN)对于业务流程的定义:一个业务流程由为了配合一个组织性或技术环境而一系列活动组成。这些活动共同实现一个业务目标。 业务流程再造最有名的倡导者托马斯.H.达文波特对于流程和业务流程的定义:流程是一组结构化且可度量的…...

解决docker mysql命令行无法输入中文
docker启动时,设置支持中文 docker run --name mysql-container -e MYSQL_ROOT_PASSWORDroot -d mysql:5.7 --character-set-serverutf8mb4 --collation-serverutf8mb4_unicode_ci --default-time-zone8:00 进入docker时,指定LANG即可 docker exec -it …...
基于Java Springboot城市公交运营管理系统
一、作品包含 源码数据库设计文档万字PPT全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA/eclipse 数据…...

Lc70--319.两个数组的交集(二分查找)---Java版
1.题目描述 2.思路 用集合求交集,因为集合里面的元素要满足不重复、无序、唯一。使得集合在去重、查找和集合操作(如交集、并集、差集等)中非常高效和方便。 3.代码实现 class Solution {public int[] intersection(int[] nums1, int[] nu…...

亿咖通科技应邀出席微软汽车行业智享会,分享ECARX AutoGPT全新实践
11月14日,全球出行科技企业亿咖通科技(纳斯达克股票代码:ECX)应邀于广州参加由微软举行的汽车行业智享会,揭晓了亿咖通科技对“AI定义汽车”时代的洞察与技术布局,分享了亿咖通科技汽车垂直领域大模型ECARX…...

Python教程:运算符重载
在Python中,运算符重载是通过定义特殊方法(也称为魔术方法)来实现的,这些特殊方法允许类的实例像内置类型那样使用运算符。 Python提供了一系列这样的特殊方法,用于重载各种运算符。 以下是一些常见的运算符重载特殊…...

技术债务的职场政治:谁该为历史遗留问题买单
在软件测试从业者的日常工作中,技术债务是一个绕不开的话题。它像一颗隐藏在代码深处的定时炸弹,随时可能在项目推进的某个节点爆发,引发一系列连锁反应。而当技术债务问题浮出水面时,一场关于“谁该为历史遗留问题买单”的职场政…...

动手写一个 JVM 调优学习项目:6 个真实场景带你掌握性能优化
动手写一个 JVM 调优学习项目:6 个真实场景带你掌握性能优化 项目地址: https://gitee.com/jiucenglou/jvm-tuning-lab 技术栈: Java 8 Maven 适合人群: Java 开发者、性能调优初学者、面试准备者 🤔 为什么写这个项目? 在实际开发和面试中…...

视频字幕提取神器:如何让AI帮你自动转录硬字幕?
视频字幕提取神器:如何让AI帮你自动转录硬字幕? 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测、字…...

实测MPU6050低功耗电流:从Sleep到Cycle模式,不同唤醒频率下功耗到底差多少?
MPU6050低功耗模式实测:从微安级电流到唤醒策略的硬件优化指南 当你的智能手环在手腕上安静沉睡时,MPU6050这颗运动传感器正在以微安级的电流维持着生命体征——这不是魔法,而是现代嵌入式设计中精妙的低功耗艺术。作为硬件工程师,…...

FanControl完整指南:3步掌握Windows风扇控制,告别噪音烦恼
FanControl完整指南:3步掌握Windows风扇控制,告别噪音烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/Git…...

windows系统安装wsl安装opencode教程
使用 AI 助手(OpenCode)在 WSL2 中高效安全工作教程 背景 在 AI 极大发展的现在,AI 可以帮助我们完成很多工作。那么怎么让 AI 帮我们高效、安全地工作呢?以下是教程。 同时,大模型在 Windows 里面直接执行脚本时错…...
用C++实现信奥题 P8563 Magenta Potion)
打卡信奥刷题(3245)用C++实现信奥题 P8563 Magenta Potion
P8563 Magenta Potion 题目描述 给定一个长为 nnn 的整数序列 aaa,其中所有数的绝对值均大于等于 222。有 qqq 次操作,格式如下: 1 i k\texttt{1 i k}1 i k,表示将 aia_iai 修改为 kkk。保证 $k $ 的绝对值大于等于 222。 2 l r…...
)
从USB3.2到PCIe 5.0:我的高速串行链路阻抗匹配踩坑实录(附Sigrity仿真文件)
从USB3.2到PCIe 5.0:我的高速串行链路阻抗匹配踩坑实录 去年负责一款数据中心加速卡的设计时,我遇到了职业生涯中最棘手的高速信号完整性问题。这块板卡需要同时支持PCIe 5.0 x16和四个USB3.2 Gen2x2接口,当第一批工程样机回来进行信号测试时…...

告别龟速!实测字节跳动Rust镜像源rsproxy.cn,安装rust和cargo快到飞起
Rust开发者福音:字节跳动镜像源rsproxy.cn全实测与避坑指南 上周深夜两点,我盯着终端里以KB/s为单位缓慢爬升的Rust安装进度条,第5次按下了CtrlC。作为一门以"零成本抽象"著称的语言,Rust的安装体验却让国内开发者付出了…...

XMly-Downloader-Qt5:跨平台喜马拉雅音频下载解决方案的技术重构与实现深度解析
XMly-Downloader-Qt5:跨平台喜马拉雅音频下载解决方案的技术重构与实现深度解析 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-…...