CacheLib 原理说明
CacheLib 介绍
CacheLib 是 facebook 开源的一个用于访问和管理缓存数据的 C++ 库。它是一个线程安全的 API,使开发人员能够构建和自定义可扩展的并发缓存。
主要功能:
- 实现了针对 DRAM 和 NVM 的混合缓存,可以将从 DRAM 驱逐的缓存数据持久化到 NVM,存于 NVM 上的缓存数据在被查找命中时会写到DRAM缓存,这些对用户都是透明的。
- 支持缓存数据的持久化,使进程在重新启动后依然可以保持原有缓存数据不丢失。
- 缓存可变大小的对象。
- 提供零拷贝的并发访问。
- 提供丰富的缓存算法,如 LRU、分段 LRU、FIFO、2Q 和 TTL。
- 使用硬 RSS 内存限制以避免 OOM。
- 智能和自动调整缓存以动态更改工作负载。
下面挑选在上述功能中挑选几个重要的着重说明一下。
CacheLib 混合缓存
CacheLib 通过混合缓存功能支持使用多种硬件介质。为了使这对用户透明,提供了统一的 CacheAllocator API 封装,让用户对具体的硬盘读写无感知。CacheLib 支持 SSD 作为混合缓存的 NVM 介质。Navy 是基于 SSD 优化的缓存引擎。为了与 Navy 交互,CacheAllocator 针对 NVM 的操作包装为NvmCache。CacheAllocator 将 Navy的查找、插入和删除的功能完全交给 NvmCache 来实现,并保证其是线程安全的。 NvmCache 实现处理 Item 与 NVM 之间的转换的功能。CacheAllocator 中没有全局键级锁来保证 DRAM 和 NVM 之间的同步,因此 NvmCache 采用乐观并发控制原语来保证数据的正确性。
前置知识:
CacheLib 支持的缓存特性
CacheTrait 是 MMType、AccessType 和 AccessTypeLock 的组合。
MMType:内存管理类型,它控制缓存项的生命周期(add/remove/evict/recordAccess),类型包括 MMLru、MM2Q、MMTinyLFU。
AccessType:访问控制类型,它控制缓存项的访问方式(find/insert/remove),类型包括 ChainedHashTable。
AccessTypeLock:是支持多个锁定原语的访问容器的锁类型,类型包括 SharedMutexBuckets、SpinBuckets。
RefcountWithFlags
记录缓存项的引用计数和标识符
|--------18 bits----------|--3 bits---|------11 bits------| ┌─────────────────────────┬───────────┬───────────────────┐ │ Access Ref │ Admin Ref │ Flags │ └─────────────────────────┴───────────┴───────────────────┘Access Ref:记录缓存项的引用计数
Admin Ref:记录谁有权限管理缓存项,如 kLinked(MMContainer)、kAccessible(AccessContainer)、kMoving。
Flags:指示缓存项当前的状态,如 kIsChainedItem、kHasChainedItem、kNvmClean、kNvmEvicted、 kUnevictable_NOOP。
混合缓存初始化
在创建 Cache 实例时都是通过 CacheAllocator 来实例化,这里分为两种方式,一种是不支持缓存持久化的启动方式,另一种是支持缓存持久化的启动方式。支持持久化的方式比不支持持优化的方式会多一个入参 SharedMemNewT 或 SharedMemAttachT。
SharedMemNewT 会使 Cache 多一个 shmManager,利用 posix shm 来做缓存的持久化,一般会生成两个文件:metadata 和NvmCacheState,具体可以参考 ShmManager.h 和NvmCacheState.h。metadata 会存储内存相关的元信息包括 shm_info、shm_cache、shm_hash_table 和 shm_chained_alloc_hash_table;NvmCacheState 会存储 NVM 的状态信息,因为 NVM 的元信息已经在缓存文件中记录,不需要在额外持久化。
SharedMemAttachT 会在启动时尝试 attach 之前持久化的元数据,如果成功可以继续使用存在的缓存,如果失败会抛出异常,所以一般的用法如下:
try {cache = std::make_unique<Cache>(Cache::SharedMemAttach, config);} catch (const std::exception& ex) {cache.reset();std::cout << "Couldn't attach to cache: " << ex.what() << std::endl;cache = std::make_unique<Cache>(Cache::SharedMemNew, config);default_pool = global_cache->addPool("default", 1024*1024*1024);}
Item 分配和淘汰
缓存在写入 CacheLib 时,会先写入 DRAM 中分配内存并将数据写入,写入后交由 MMContainer(缓存管理容器)进行管理。
insertInMMContainer(*(handle.getInternal()));
当 Item 满足淘汰策略要被淘汰时,有两种途径:一是直接从 CacheLib 中淘汰掉;二是从内存中淘汰掉进入 NVM。
因为 NVM 为了保证时刻都有着良好的性能,支持定制 Admission Policy,比如突然有过多的 kv 写入时可以按百分比拒绝掉部分 kv 写入请求。这样可以起到保护 NVM 的作用,同时在 CacheLib 淘汰的 key 就会直接被淘汰,不会写入 NVM。
当不满足阈值条件时,Item 就会被写入 NVM,如果 NVM 空间被占满同样也会触发淘汰机制。
这个 allocation 过程也就是insert的核心逻辑,对应 insert 还有一个实现是 insertOrReplace,insert 在写入时会因为有重复 key 导致写入失败,insertOrReplace 则会直接替换原先存在的 key,具体的实现就是在 check 后和写入前,将 NVM 做标记删除,具体可以参考createDeleteTombStone 函数。到此也引出一个逻辑就是,NVM 中的数据都是标记删除,并不会直接清空这部分数据,而是后续通过调用 removeAsync 完成异步删除。

混合缓存查找
在查找 key 时首先在内存中进行查找,为此 CacheLib 专门设计了下面这个函数,在找到 key 后会判断 key 是否过期,过期会标记为过期,并返回未找到。
auto handle = findFastImpl(key, mode);
如果内存中不存在,会尝试从 NVM 中查找,find 有同步的也有异步的实现,但 NVM 一般都异步的 find,性能会更好。
NVM 的 find 设计稍微有些复杂,首先为了避免磁盘的繁重搜索,加入了 enableFastNegativeLookups 功能,可以预先判断 Item 在内存中是不是肯定不存在。如果不确定存不存在,再进行 NVM 上的查找,其实这里就是一个 bloom 过滤器。
因为内存和磁盘的交互时间会比较长,从内存中驱逐到磁盘的过程(写 NVM )就会相对比较长,所以为此设计了异步查找功能,通过 GetContext 来追踪整个查找过程,最后使用回调函数来通知通知用户查找完成。
在查找过程中有可能会有多个 find 并发请求,CacheAllocator 为了性能考虑,并没有使用真正意义的锁,而是利用乐观所机制来保证 DARM 和 NVM 中数据的一致性。NvmCache 是通过维护一个 PutTokens 结构来实现的,每个正在写入 NVM 的 key 都有一个属于自己的 putToken,只有在 putToken 有效的情况下才能执行 NVM 的写入,以此来控制 key 的可见性。
举个例子,当线程1有一个 find 请求要查找 key1,此时有可能线程2正在执行 key1 的 NVM 写入,key1 会持有一个有效的 putToken,当线程1执行 find 时,key1 就会被 LRU 等规则激活,就不需要被内存淘汰,也不再需要写入 NVM,所以会将 key1 的 putToken 置为无效,线程2的写入操作发现 putToken 无效则不再继续写操作,这样可以保证从 DRAM 到 NVM 查找的顺序一致性。这里的 putToken 只有在写入 NVM 时才会生成,在 find 和 eviction 等操作时会被置为无效,并没有很复杂的状态变更。
在 NVM 查找完成后,Item 并不是直接返回给用户,而是先写入到 DRAM,同 allocation 逻辑,此时通过 nvmClean(true) flag 标识 DRAM 和 NVM 中该 kv 是一致的,如果 Item 再次被淘汰,则不需要再次写入 NVM,因为 NVM 已经存在该 key。如果 key 所对应的 value 被修改,nvmClean 会被置为 false,标识为不一致。NVM 中这部分不一致的会被后台异步线程清理掉。

Navy实现原理
Navy 是基于 SSD 优化的缓存引擎。Navy 的特点:
- 高效缓存 SSD 上的数十亿个小对象 (<1KB) 和数百万个大对象 (1KB - 16MB)。
- 高效的点查找
- 低 DRAM 开销
由于 Navy 是为缓存而设计的,因此在实现上选择牺牲数据的持久性。由于 Navy 是写密型的,NVM 写入寿命就成为一个关注点,Navy 也针对写入寿命进行了优化。
Navy整理架构
Navy 为用户提供了一个异步 API。Navy 使用 Small Item Engine 对小对象进行优化,使用 Large Item Engine 对大对象进行优化。每个引擎的设计都考虑了所需的DRAM开销,而不会影响读取效率。在下面,做了块设备的抽象,两个引擎都在块设备抽象之上运行。

Engine
Navy 针对 Item 的大小分别实现了 Small Item Engine 和 Large Item Engine,对应的具体实现分别是 BigHash 和 BlockCache,可以通过 Item 的大小控制 Item 是存储到 Small Item Engine 还是 Large Item Engine,在查询时会优先查询 Large Item Engine,如果不存在,再去查询 Small Item Engine。一般 Small Item Engine 都是存储 1K 以内的数据,大数量的缓存一般都是使用 Large Item Engine,Small Item Engine 也是可以通过配置禁用的。如果因为异常终止了还会进行重试。

BigHash 主要用于小对象,暂不做过多介绍。
BlockCache
Large Item Engine 的具体实现就是 BlockCache,下面是 BlockCache 的具体结构:

主要读写逻辑
-
根据 ssd 配置 deviceMaxWriteSize 和 blockCacheRegionSize(默认16MB)将 Device 分为多个 Region,并存入 CleanList。
-
写入流程:
选择一个 Region,如果 Region 还未填满,则向该 Region 追加 Entry,如果当前 Region 已满,会向 CleanList 获取一个 Region。若 CleanList 为空,需要等待 eviction 和 gc 来释放 Region,最后更新 IndexMap。
-
查询流程:
根据 key 找到 RegionId 和 offset,再通过 RegionId 和 offset 定位到 Entry,解析读取数据。
-
删除流程:
只从 IndexMap 中删除,Entry 本身会被标记删除,等待 gc 异步处理。
-
淘汰流程:
根据淘汰策略进行淘汰,策略有 FIFO、LRU、LRU2Q,淘汰是以 Region 为单位进行淘汰,如果觉得粒度太大,可以配置 reinsertion 根据命中率或频率进行重插入来保留。
Job调度
这里的 job 包含4类;
JobType::Read:对于对应于 Navy 读取作业(查找);
JobType::Write:对应于 Navy 写入作业,新的插入和删除都是以插入形式实现的;
JobType::Reclaim:执行内部淘汰操作;
JobType::Flush:执行任何内部异步缓冲写入;
Job是严格按顺序提交,保证写入和查询的顺序一致性,避免对同一个 key 同时执行多个操作。再遇到并发请求时,还是依赖NvmCache的乐观锁机制保证 DRAM 和 NVM 的数据一致性。
JobScheduler 提供两个线程池,一个负责读,另一个负责写。Job 会根据类型分配到两个线程池其中之一。并且在根据 key 分配到指定的线程上,每个线程都维护着一个 JobQueue,一般都是先入先出的,但是 JobType::Reclaim 和 JobType::Flush 会有更高的优先级,会优先执行。
为了使用线程池提高性能还要维持顺序一致性,引入了一个分片排序机制,首先通过配置参数可以指定分片的数量,一般为数百万个,提交的 Job 会根据 key hash 到不同的分片内,同一个 key 只会在一个分片内,保证对同一个 key 处理的顺序性,分配请求会从第一个分片开始遍历,一般一次只取一个 Job,如果连续的 Job 是不同的 key 没有冲突,可以一次取多个提交到线程池线程的 JobQueue 中,遍历到结尾处再次循环遍历,不断的完成 Job。
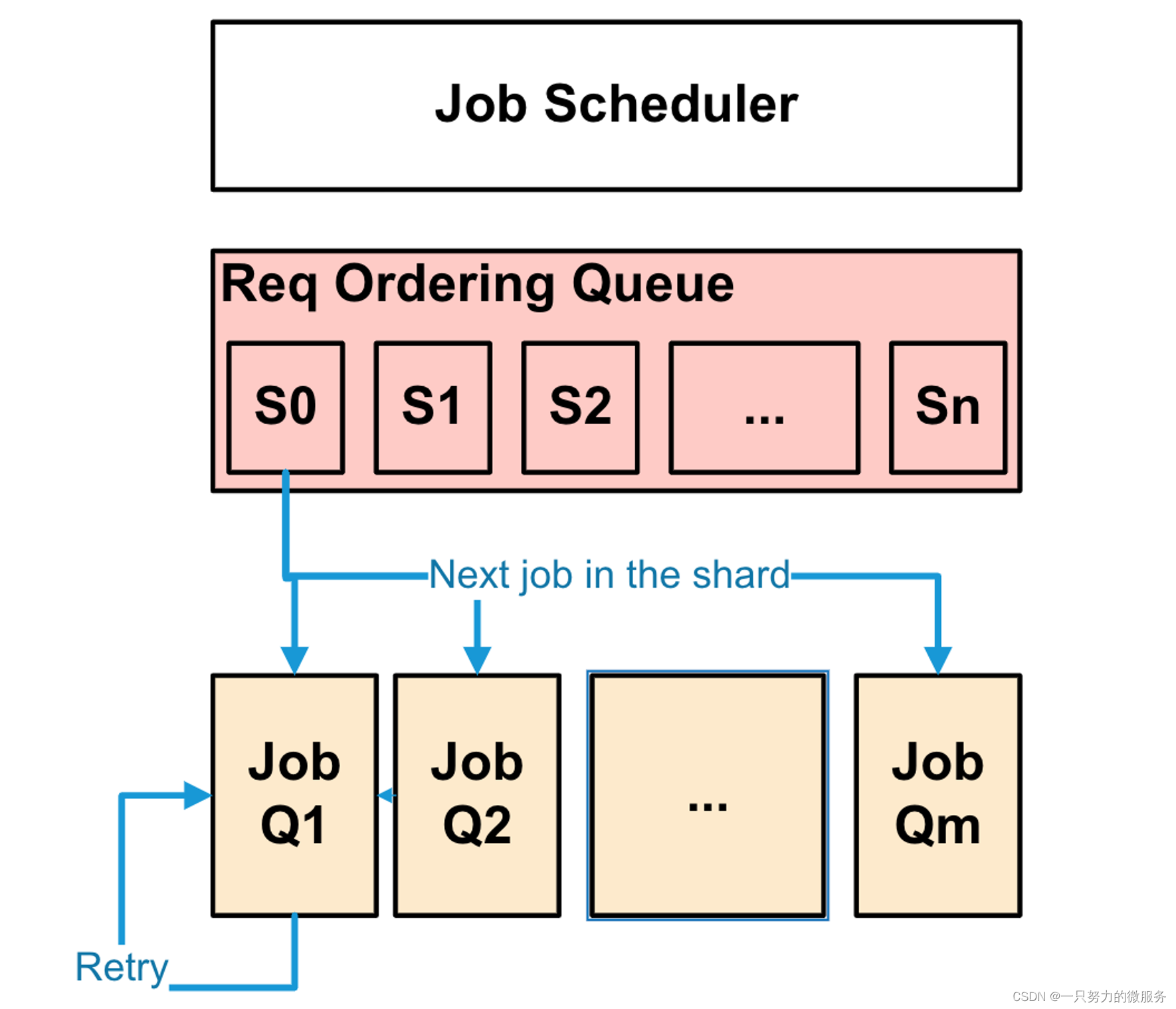
以上就是对 CacheLib 混合缓存原理的介绍。
相关文章:
CacheLib 原理说明
CacheLib 介绍 CacheLib 是 facebook 开源的一个用于访问和管理缓存数据的 C 库。它是一个线程安全的 API,使开发人员能够构建和自定义可扩展的并发缓存。 主要功能: 实现了针对 DRAM 和 NVM 的混合缓存,可以将从 DRAM 驱逐的缓存数据持久…...
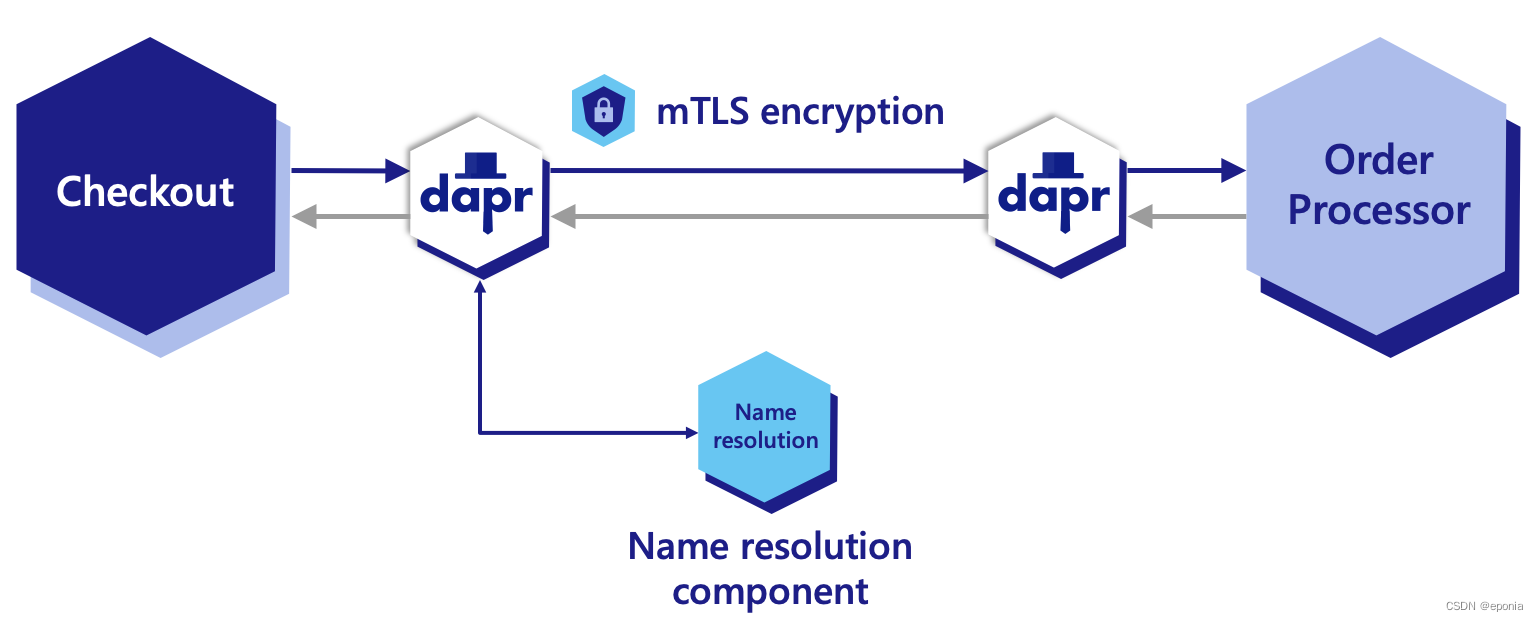
【dapr】服务调用(Service Invokation) - app id的解析
逻辑图解 上图来自Dapr官网教程,其中Checkout是一个服务,负责生成订单号, Order Processor是另一个服务,负责处理订单。Checkout服务需要调用Order Processor的API, 让Order Processor获取到其生成的订单号并进行处理。…...
Odoo丨5步轻松实现在Odoo中打开企微会话框
Odoo丨5步轻松实现在Odoo中打开企微会话框 在Odoo中开启企微会话框 企业微信作为一个很好的企业级应用发布平台,尤其是提供的数据和接口,极大地为很多企业级应用提供便利,在日常中应用广泛! 最近在项目中就遇到一个与企业微信相…...
python读取.stl文件
目录 .1 文本方式读取 1.2 stl解析 1.3 stl创建 .2 把点转换为.stl .1 文本方式读取 代码如下 stl_path/home/pxing/codes/point_improve/data/003_cracker_box/0.stlpoints[] f open(stl_path) lines f.readlines() prefixvertex num3 for line in lines:#print (l…...
vue2.0项目第一部分
论坛项目后端管理系统服务器地址:http://172.16.11.18:9090swagger地址:http://172.16.11.18:9090/doc.html前端h5地址:http://172.16.11.18:9099/h5/#/前端管理系统地址:http://172.16.11.18:9099/admin/#/搭建项目vue create . …...
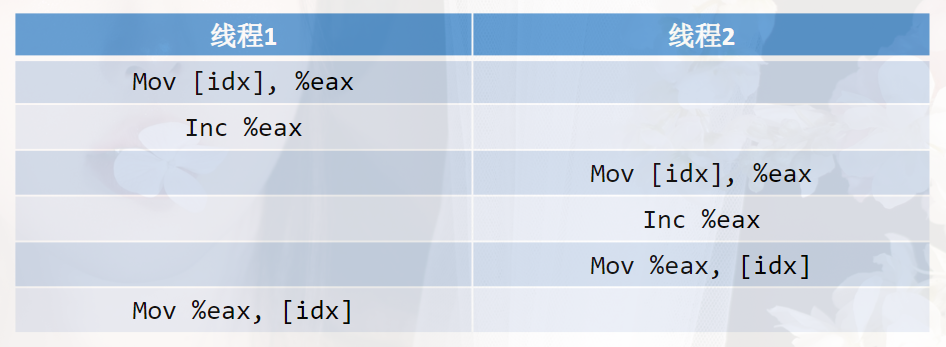
锁与原子操作
锁与原子操作 锁 以自增操作为例子: void *func(void *arg) {int *pcount (int *)arg;int i 0;//while (i < 100000) {(*pcount) ; // 并不会到达100000usleep(1);} }int main(){int i 0;for (i 0;i < THREAD_COUNT;i ) {pthread_create(&thid…...

Prometheus Pushgetway讲解与实战操作
目录 一、概述 1、Pushgateway优点: 2、Pushgateway缺点: 二、Pushgateway 架构 三、实战操作演示...
常见字符串函数的使用,你确定不进来看看吗?
👦个人主页:Weraphael ✍🏻作者简介:目前是C语言学习者 ✈️专栏:C语言航路 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞&a…...
Elasticsearch:在搜索中使用衰减函数(Gauss)
在我之前的文章 “Elasticsearch:使用 function_score 及 script_score 定制搜索结果的分数” 我有讲到 Decay 函数在搜索中的使用。在那里,我有一个例子讲述在规定的时间里,分数不进行衰减。同一的函数也可以适用于地理位置的搜索。位置搜索…...
微信小程序 Springboot英语在线学习助手系统 uniapp
四六级助手系统用户端是基于微信小程序端,管理员端是基于web端,本系统是基于java编程语言,mysql数据库,idea开发工具, 系统分为用户和管理员两个角色,其中用户可以注册登陆小程序,查看英语四六级…...

LeetCode算法题解——双指针2
LeetCode算法题解——双指针2第五题思路代码第六题思路代码第七题思路代码这里介绍双指针在数组中的第二类题型:两端夹击。 第五题 977. 有序数组的平方 题目描述: 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的…...

线性杂双功能peg化试剂——HS-PEG-COOH,Thiol-PEG-Acid
英文名称:HS-PEG-COOH,Thiol-PEG-Acid 中文名称:巯基-聚乙二醇-羧基 HS-PEG-COOH是一种含有硫醇和羧酸的线性杂双功能聚乙二醇化试剂。它是一种有用的带有PEG间隔基的交联或生物结合试剂。巯基或SH、巯基或巯基选择性地与马来酰亚胺、OPSS、…...
Linux第三讲
目录 三、 磁盘和文件管理和使用检测和维护 3.1 磁盘目录 3.2 安装软件 3.2.1 rpm命令 3.2.2 克隆虚拟机 3.2.3 yum或压缩包方式安装jdk 3.2.4 使用虚拟机运行SpringBoot项目 3.2.5 安装mysql80(57) 3.2.6 运行web项目 3.2.7 安装tomcat 三、 …...
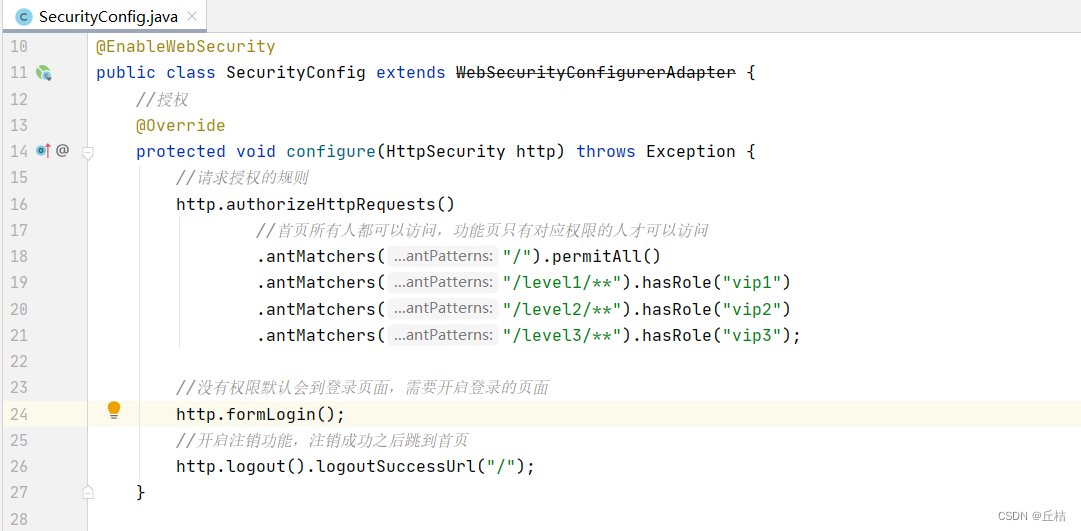
SpringBoot07:SpringSecurity
Security是什么? 是一个安全框架。可以用来做认证和授权 官网:Spring Security SpringSecurity环境搭建 1、创建一个新的project 2、导入thymeleaf依赖 <dependency><groupId>org.thymeleaf</groupId><artifactId>thymeleaf…...

C++ 浅谈之 STL Vector
C 浅谈之 STL Vector HELLO,各位博友好,我是阿呆 🙈🙈🙈 这里是 C 浅谈系列,收录在专栏 C 语言中 😜😜😜 本系列阿呆将记录一些 C 语言重要的语法特性 🏃&…...
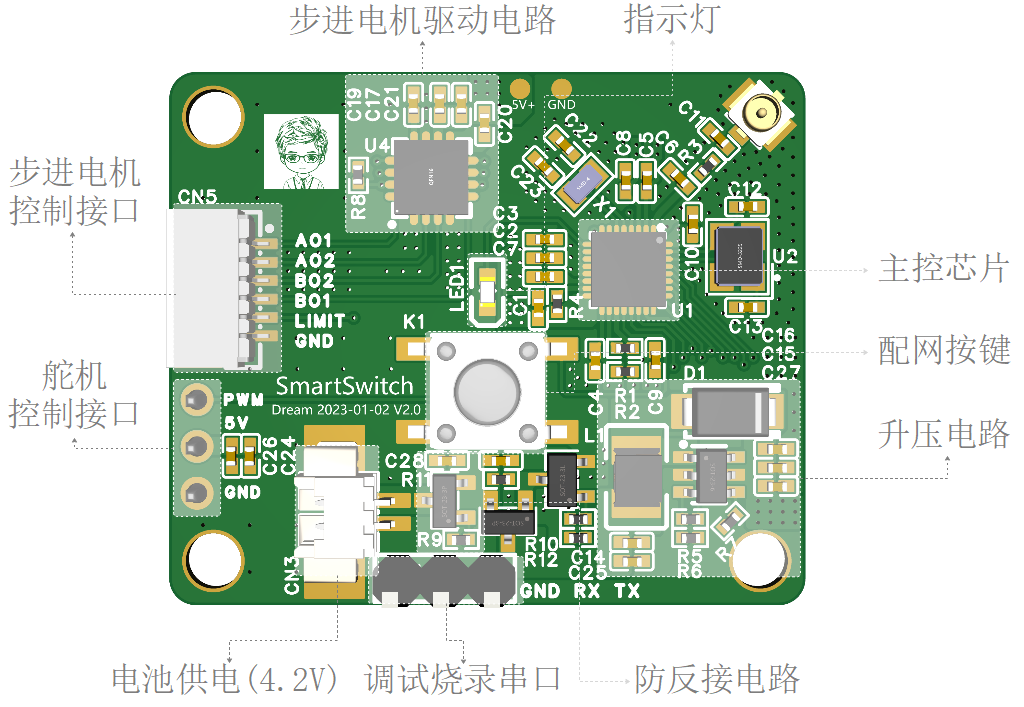
【个人作品】非侵入式智能开关
一、产品简介 一款可以通过网络实现语音、APP、小程序控制,实现模拟手动操作各种开关的非侵入式智能开关作品。 非侵入式,指的是不需要对现有的电路和开关做任何改动,只需要将此设备使用魔术无痕胶带固定在旁边即可。 以下为 ABS 材质的渲…...
数据存储技术复习(三)未完
module4智能存储系统是功能丰富且可提供高度优化的I/o处理能力的RAID阵列。请绘制智能存储系统架构,并说明其各个关键组件的主要功能。前端缓存后端物理磁盘2.智能存储系统中,使用缓存进行的写入操作与直接写入到磁盘相比,可以带来…...

ThinkPHP数据库迁移工具
安装 composer require topthink/think-migration 创建迁移工具文件 //执行命令,创建一个操作文件,一定要用大驼峰写法,如下 php think migrate:create AnyClassNameYouWant //执行完成后,会在项目根目录多一个database目录,这里面存放类库操作文件 //文件名类似/database/m…...

代理模式(Proxy Pattern)
代理模式定义: 提供了对目标对象另外的访问方式;即通过代理对象访问目标对象。举个例子:猪八戒去找高翠兰结果是孙悟空变的,可以这样理解:把高翠兰的外貌抽象出来,高翠兰和孙悟空都实现了这个接口ÿ…...

Elasticesearch内存详解
1.ES基本概念 为了更好的理解内存,我们先看一下ES的基本概念。 1.1 cluster 集群 多个节点组合在一起就形成了一个集群,在每个ES节点中,我们可以通过配置集群的名称来使各个节点组合在一起,成为一个集群。当某些节点的集群名称一样,ES会自动根据配置文件中的地址找到这些…...

基于fnos-apps框架构建智能对话应用:从技能编排到生产部署
1. 项目概述:一个为现代对话应用而生的开源工具箱最近在折腾一个基于大语言模型的客服机器人项目,在集成各种外部工具和API时,遇到了一个老生常谈的问题:每个工具都有自己的调用方式、认证逻辑和错误处理,代码里很快就…...

VisualCppRedist AIO:告别DLL错误,Windows系统必备的一体化运行库解决方案
VisualCppRedist AIO:告别DLL错误,Windows系统必备的一体化运行库解决方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打…...

AAAI‘2026 模型记错了,检索也救不了?KG+TruthfulRAG想解决这个死结
背景介绍 近年来,大语言模型(LLM)在生成与理解任务上表现突出,但其内部“参数化知识”具有静态、滞后的特点: 面对时效性知识、专业知识、隐私知识等,模型可能缺乏覆盖;即便检索增强生成&#…...

别再让专利证书变废纸!手把手教你用6步法写出能维权的权利要求书
从技术到法律:6步打造高价值专利权利要求的实战指南 刚拿到专利证书的工程师小王,在展会上发现竞争对手的产品几乎照搬了自己的发明。他信心满满地提起诉讼,却因权利要求书中"数据传输模块"的表述过于宽泛而败诉——法院认为该描述…...

崩坏星穹铁道自动化助手终极指南:三月七小助手完整使用教程
崩坏星穹铁道自动化助手终极指南:三月七小助手完整使用教程 【免费下载链接】March7thAssistant 崩坏:星穹铁道全自动 三月七小助手 项目地址: https://gitcode.com/gh_mirrors/ma/March7thAssistant 还在为《崩坏:星穹铁道》中繁琐的…...

告别本地卡顿!用Pycharm 2023.3远程连接Spark集群,5步搞定开发环境
告别本地卡顿!用Pycharm 2023.3远程连接Spark集群,5步搞定开发环境 当你的笔记本风扇开始像喷气发动机一样轰鸣,而PySpark脚本才处理到第3万条数据时,就该考虑换个战场了。去年我用一台16GB内存的MacBook Pro分析800万条电商日志&…...

CSS 混合模式完全指南
CSS 混合模式完全指南 引言 CSS 混合模式(Blend Modes)是一种强大的视觉效果工具,它允许你控制多个元素或图层如何混合在一起。本文将深入探讨各种混合模式的用法和高级技巧。 混合模式类型 基础混合模式 模式效果描述normal默认模式…...
)
壁纸引擎安卓版(wallpaper engine安卓版免费下载)
wallpaper engine安卓版是Steam上的Wallpaper Engine官方的安卓应用程序。 Wallpaper Engine Android 应用程序是免费的,支持将现有 Wallpaper Engine 壁纸合集无线传输到您的 Android 移动设备。 ————————————————————————————————…...

时间序列预测总翻车?试试用Python实现嵌套交叉验证来守住‘未来’数据
时间序列预测中的嵌套交叉验证:用Python守住数据的时间壁垒 当你在预测下周的销售额、下个月的电力负荷或明天的股价时,最可怕的不是模型不够复杂,而是它偷偷"作弊"了——通过窥探未来的数据来假装自己很聪明。这种时间序列预测中的…...

BurstGPT:大语言模型驱动高性能计算,实现自然语言科学仿真
1. 项目概述:当大语言模型遇上高性能计算最近在AI和HPC(高性能计算)的交叉领域,一个名为BurstGPT的项目引起了我的注意。乍一看这个标题,你可能会觉得有点“缝合怪”的味道——Burst通常指代计算资源的突发式使用或高性…...