跳表 | 基本概念 | 代码实现
文章目录
- 1.跳表的基本概念
- 2.跳表的结构
- 3.跳表的增删改查
- 4.完整代码
1.跳表的基本概念
跳表的本质是一种查找结构,一般查找问题的解法分为两个大类:一个是基于各种平衡树,一个是基于哈希表,跳表比较的特殊,它独成一派。跳表是基于有序链表的基础上发展而来的,普通链表查找只能一个一个往下跳,而跳表能一次跳过好几个结点,这就是它查找效率高的原因。 例如:
如果只有一层那么查找就是逐个遍历,效率就是O(n)

如果为两个相邻结点添加第二层指向

甚至是添加第三层的指向

每层的结点个数呈现2:1的对应关系,查找就是从最高层开始,依次往下查找,这个过程类型二分查找,效率可以来到O(log n)。但是如果严格维持这种2:1的对应关系,插入删除节点都需要重新调整,插入删除效率直接就降到O(n)。所以跳表采用随机化结点的层数,来控制查找插入删除的时间复杂度近似为O(log n)。怎么计算可以参考博客。
2.跳表的结构
跳表的结点有多层,通过vector<SkiplistNode*> 来存储下一个结点的指针。初始化跳表时是带头结点的,它的层数要求是最高的,它开始只有它自己,默认给一层,后面插入的时候如果有结点的层数高于它,需要调整。
struct SkiplistNode
{ int _data;vector<SkiplistNode*> _nextV;SkiplistNode(int data,int level):_data(data),_nextV(level,nullptr){}
};class Skiplist
{typedef SkiplistNode Node;
private:Node* _head;int _maxLevel = 32;double _p = 0.25;public:Skiplist(){_head = new Node(-1,1);}
};int main()
{Skiplist list; return 0;
}
3.跳表的增删改查
看看自己的代码有没有问题可以在leetcode上提交代码:题目链接
1)跳表的查找: 跳表中的元素是有序的,在理解跳表查找前先来看一下一个有序的单链表是如何查找元素的。

查找有序单链表,cur表示当前结点,如果cur的值data等于待查找的值target说明找到了。可如果cur 的下一个结点的值data大于target,说明target目标值不在链表中,或者是链表遍历到结尾还是找不到也说明target目标值不在链表中,这就是有序单链表的查找过程。
有了有序单链表的查找的基础,来看跳表的查找就简单了。

1、cur表示当前结点、next表示下一个结点、data表示结点的数据。
2、要从最高层找起,直到遍历到最低的那一层。
3、如果target 等于 cur的 data说明找到了。
4、如果target 大于 next 的 data,向右找。但是要保证next 不能为NULL。如找19而当前cur 的data是7,它的next 是NULL。不代表找不到,而是要到下一层找。
5、如果next的date 大于target 说明target可能在cur 和 next之间,往下一层找。
bool search(int target)
{Node* cur = _head;int level = cur->_nextV.size() -1;while(level >= 0){if(cur->_nextV[level] && cur->_nextV[level]->_data < target){cur = cur->_nextV[level];}else if(cur->_nextV[level] == nullptr || cur->_nextV[level]->_data > target){level--;}else {return true;}}return false;
}
2)跳表的插入: 类比单链表的从中间的某个位置插入。需要找到前一个位置prev。跳表要找的是prevV,前结点指针列表。

1、找到prevV
2、创建一个结点newNode,先让newNode->_nextV[i] 逐个指向 prevV[i]->_nextV[i]指向的结点。再让prevV[i]->_nextV[i]指向newNode。
3、这里创建newNode层数是随机的,需要根据概率计算。这里参照radis中给定的概率和最大层数。
4、如果插入节点的层数高于头结点,需要调整头结点的层数。
vector<Node*> findPervV(int num)
{Node* cur = _head;int level = _head->_nextV.size() -1;vector<Node*> prevV(level + 1,nullptr);while(level >= 0){ if(cur->_nextV[level] != nullptr && cur->_nextV[level]->_data < num){cur = cur->_nextV[level];}else if(cur->_nextV[level] == nullptr || cur->_nextV[level]->_data >= num){prevV[level] = cur;level--;}}return prevV;
}void add(int num)
{int n = randomLevel();int level = _head->_nextV.size() -1;vector<Node*> prevV = findPervV(num);// 调整头结点的层数if(n > _head->_nextV.size()){_head->_nextV.resize(n,nullptr);prevV.resize(n,_head);}Node* newNode = new Node(num,n); for(int i = 0;i < n;i++){ newNode->_nextV[i] = prevV[i]->_nextV[i];prevV[i]->_nextV[i] = newNode;}
}int randomLevel()
{Node* cur = _head;srand(time(NULL));int level= 1;// rand的区间范围为[0,RAND_MAX]while(rand() <= RAND_MAX*_p && level < _maxLevel) { level++;}return level;
}
3)跳表的删除:
1、要到前结点列表prevV
2、根据当前结点的层数,循环指向prevV[i]->_nextV[i] = del->_nextV[i]
bool erase(int num)
{vector<Node*> prevV = findPervV(num);if(prevV[0]->_nextV[0] == nullptr || prevV[0]->_nextV[0]->_data != num){return false;}else{Node* del = prevV[0]->_nextV[0];// 当前节点的层数for(int i = 0;i < del->_nextV.size();i++){prevV[i]->_nextV[i] = del->_nextV[i];}delete del;int index = _head->_nextV.size() -1;// _head->_nextV[index] == nullptr说明最高结点删除了,调整头结点while (index >= 0) {if(_head->_nextV[index] == nullptr) {index--;}else {break;} }return true;}
}
4)跳表的打印: 这里按照单链表的思路打印,如果只看第一层那么跳表就像是有序的单链表。注意跳表是带头指针的,所以直接从_head->nextV[0]开始。
void print()
{Node* cur = _head->_nextV[0];while(cur != nullptr){ cout << cur->_data << "->"; cur = cur->_nextV[0];}cout << "NULL" << endl;
}
4.完整代码
#include <vector>
#include <iostream>
#include <time.h>
#include <stdlib.h>using namespace std;struct SkiplistNode
{ int _data;vector<SkiplistNode*> _nextV;SkiplistNode(int data,int level):_data(data),_nextV(level,nullptr){}
};class Skiplist
{typedef SkiplistNode Node;
private:Node* _head;int _maxLevel = 32;double _p = 0.25;public:Skiplist(){_head = new Node(-1,1);}bool search(int target){Node* cur = _head;int level = cur->_nextV.size() -1;while(level >= 0){if(cur->_nextV[level] && cur->_nextV[level]->_data < target){cur = cur->_nextV[level];}else if(cur->_nextV[level] == nullptr || cur->_nextV[level]->_data > target){level--;}else {return true;}}return false;}vector<Node*> findPervV(int num){Node* cur = _head;int level = _head->_nextV.size() -1;vector<Node*> prevV(level + 1,nullptr);while(level >= 0){ if(cur->_nextV[level] != nullptr && cur->_nextV[level]->_data < num){cur = cur->_nextV[level];}else if(cur->_nextV[level] == nullptr || cur->_nextV[level]->_data >= num){prevV[level] = cur;level--;}}return prevV; }void add(int num){int n = randomLevel();int level = _head->_nextV.size() -1;vector<Node*> prevV = findPervV(num);if(n > _head->_nextV.size()){_head->_nextV.resize(n,nullptr);prevV.resize(n,_head);}Node* newNode = new Node(num,n); for(int i = 0;i < n;i++){ newNode->_nextV[i] = prevV[i]->_nextV[i];prevV[i]->_nextV[i] = newNode;}}int randomLevel(){Node* cur = _head;srand(time(NULL));int level= 1;while(rand() <= RAND_MAX*_p && level < _maxLevel) { level++;}return level;}bool erase(int num){vector<Node*> prevV = findPervV(num);if(prevV[0]->_nextV[0] == nullptr || prevV[0]->_nextV[0]->_data != num){return false;}else{Node* del = prevV[0]->_nextV[0];for(int i = 0;i < del->_nextV.size();i++){prevV[i]->_nextV[i] = del->_nextV[i];}delete del;int index = _head->_nextV.size() -1;while (index >= 0) {if(_head->_nextV[index] == nullptr) {index--;}else {break;} }return true;}}void print(){Node* cur = _head->_nextV[0];while(cur != nullptr){ cout << cur->_data << "->"; cur = cur->_nextV[0];}cout << "NULL" << endl;}};int main()
{Skiplist list; list.add(1);list.add(3);list.add(6);cout << list.search(6) << endl;list.erase(9);list.erase(6);cout << list.search(6) << endl;list.print();return 0;
}
相关文章:
跳表 | 基本概念 | 代码实现
文章目录 1.跳表的基本概念2.跳表的结构3.跳表的增删改查4.完整代码 1.跳表的基本概念 跳表的本质是一种查找结构,一般查找问题的解法分为两个大类:一个是基于各种平衡树,一个是基于哈希表,跳表比较的特殊,它独成一派…...

分数加减
#include <stdio.h> #include <stdlib.h>// 求最大公因数 int gcd(int a, int b) {return b 0? a : gcd(b, a % b); }// 化简分数 void simplify(int *num, int *den) {int g gcd(*num, *den);*num / g;*den / g;if (*den < 0) {*num * -1;*den * -1;} }//…...

基于卷积神经网络的皮肤病识别系统(pytorch框架,python源码,GUI界面,前端界面)
更多图像分类、图像识别、目标检测等项目可从主页查看 功能演示: 皮肤病识别系统 vgg16 resnet50 卷积神经网络 GUI界面 前端界面(pytorch框架 python源码)_哔哩哔哩_bilibili (一)简介 基于卷积神经网络的皮肤病识…...

QT与嵌入式——获取网络实时时间
目录 1、使用QT通过网络API接口获取网络实时时间 1.1、首先在网上找一个获取实时时间的API接口 1.2、 根据第一步获取的链接来发送请求 1.3、通过connect链接信号与槽 注意的点: 2、为什么需要网络实时时间 3、获取本机的实时时间 4、顺带提一句 1、使用QT通过…...

优化装配,提升品质:虚拟装配在汽车制造中的关键作用
汽车是各种零部件的有机结合体,因此汽车的装配工艺水平和装配质量直接影响着汽车的质量与性能。在汽车装配过程中,经常会发生零部件间干涉或装配顺序不合理等现象,且许多零部件制造阶段产生的质量隐患要等到实际装配阶段才能显现出来…...

Bug的严重等级和优先级别与分类
目录 前言 1. Bug的严重等级定义 2.Bug的优先等级 3.一般 BUG 的正规的处理流程 4.BUG严重等级划分 5.BUG紧急程度定义 前言 Bug是指在软件开发或者系统运行过程中出现的错误、缺陷或者异常情况。它可能导致系统无法正常工作、功能不完整、数据错误或者界面异常等问题。 …...

游戏引擎学习第13天
视频参考:https://www.bilibili.com/video/BV1QQUaYMEEz/ 改代码的地方尽量一张图说清楚吧,懒得浪费时间 game.h #pragma once #include <cmath> #include <cstdint> #include <malloc.h>#define internal static // 用于定义内翻译单元内部函数 #…...
结束后不能再次加载)
bind返回失败(ctrl+c)结束后不能再次加载
问题现象(VxWorks): 在测试的时候发现使用ctrlc打断程序后再次调用bind绑定失败 错误返回 0x30 问题分析: 1、程序没有开启端口复用。 2、程序在使用ctrlc打断后 vxWorks的打断和linux不相同,并没有清除底层的端口&a…...

菜鸟驿站二维码/一维码 取件识别功能
特别注意需要引入 库文 ZXing 可跳转: 记录【WinForm】C#学习使用ZXing.Net生成条码过程_c# zxing-CSDN博客 using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using static System.Net.…...

23种设计模式-备忘录(Memento)设计模式
文章目录 一.什么是备忘录设计模式?二.备忘录模式的特点三.备忘录模式的结构四.备忘录模式的优缺点五.备忘录模式的 C 实现六.备忘录模式的 Java 实现七.总结 类图: 备忘录设计模式类图 一.什么是备忘录设计模式? 备忘录设计模式(…...

搜维尔科技:Manus遥操作五指机械手专用手套惯性高精度虚拟现实
Manus遥操作五指机械手专用手套惯性高精度虚拟现实 搜维尔科技:Manus遥操作五指机械手专用手套惯性高精度虚拟现实...

MySql面试题.运维面试题之五
《(全国)MySQL数据库DBA测试题-第1套》 卷面总分 题号 单选题 多选题 判断题 100 题分 42 40 18 得分 一、单选题(每题3分,共计42分;得分____) 1. 二进制rpm包安装的mysql数据库,默认的数据文件存放在如下哪个目录里? A、/usr/local/mysql B、/tmp/ C、/var/lib/my…...

小程序-基于java+SpringBoot+Vue的小区服务管理系统设计与实现
项目运行 1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。 2.IDE环境:IDEA,Eclipse,Myeclipse都可以。推荐IDEA; 3.tomcat环境:Tomcat 7.x,8.x,9.x版本均可 4.硬件环境:…...

JWT 过期后 自动刷新方案
JWT(JSON Web Token)广泛应用于现代 Web 开发中的认证与授权,它以无状态、灵活和高效的特点深受开发者欢迎。然而,JWT 的一个核心问题是 Token 过期后如何处理。本文将总结常见的解决方案,分析其优缺点,并帮…...

react-amap海量点优化
前言:高版本的react-amap 支持MassMarkers 组件用于一次性添加大量的标记点。本次优化的海量点是在低版本react-amap的基础上。官方推荐使用聚合useCluster属性来优化海量点的渲染。 直接附上代码: import React, { Component } from "react"…...

GRU(门控循环单元)详解
1️⃣ GRU介绍 前面介绍的LSTM可以有效缓解RNN的梯度消失问题,但是其内部结构比较复杂,因此衍生出了更加简化的GRU。GRU把输入门和遗忘门整合成一个更新门,并且合并了细胞状态和隐藏状态。于2014年被提出 2️⃣ 原理介绍 GRU的结构和最简单…...

【代码随想录|回溯算法排列问题】
491.非减子序列 题目链接. - 力扣(LeetCode) 这里和子集问题||很像,但是这里要的是非递减的子序列,要按照给的数组的顺序来进行排序,就是如果我给定的数组是[4,4,3,2,1],如果用子集||的做法先进行排序得到…...

Azure Kubernetes Service (AKS)资源优化策略
针对Azure Kubernetes Service (AKS)的资源优化策略,可以从多个维度进行考虑和实施,以提升集群的性能、效率和资源利用率。以下是一些关键的优化策略: 一、 Pod资源请求和限制 设置Pod请求和限制:在YAML清单中为所有Pod设置CPU和…...

R语言 | 宽数据变成一列,保留对应的行名和列名
对应稀疏矩阵 转为 宽数据框,见 数据格式转换 | 稀疏矩阵3列还原为原始矩阵/数据框,自定义函数 df3toMatrix() 目的:比如查看鸢尾花整体的指标分布,4个指标分开,画到一个图中。每个品种画一个图。 1.数据整理&#…...
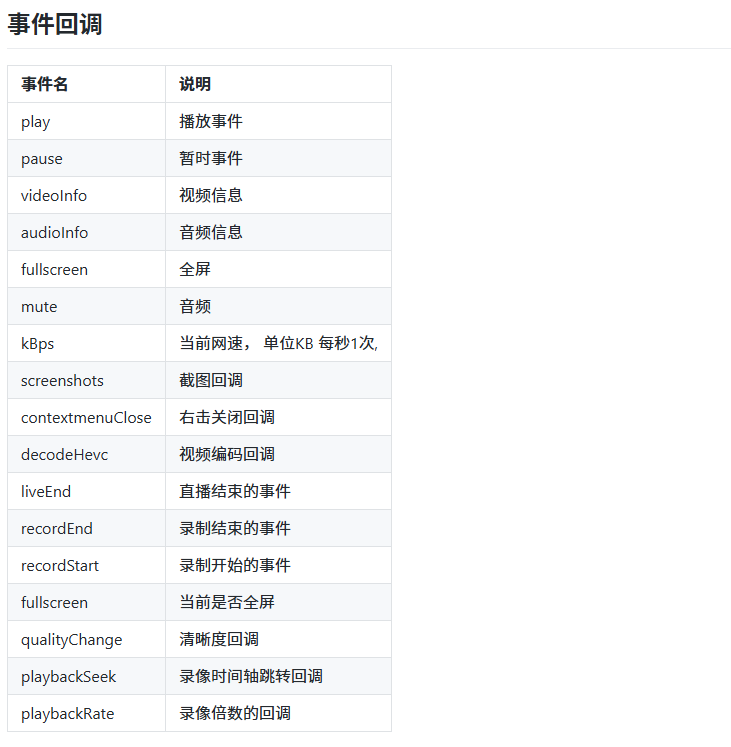
RTSP播放器EasyPlayer.js播放器在webview环境下,PC和安卓能够正常播放,IOS环境下播放器会黑屏无法播放
流媒体技术分为顺序流式传输和实时流式传输两种。顺序流式传输允许用户在下载的同时观看,而实时流式传输则允许用户实时观看内容。 流媒体播放器负责解码和呈现内容,常见的播放器包括VLC和HTML5播放器等。流媒体技术的应用场景广泛,包括娱乐…...

Windows 10/11终极指南:如何快速解决PL2303驱动兼容性问题
Windows 10/11终极指南:如何快速解决PL2303驱动兼容性问题 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 还在为Windows 10/11系统上的PL2303串口设备无法…...

阴阳师百鬼夜行自动化脚本终极指南:3种智能模式解放你的双手
阴阳师百鬼夜行自动化脚本终极指南:3种智能模式解放你的双手 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 你是否曾在深夜为刷百鬼夜行而手指酸痛?是否…...

基于Nuxt 4与Shadcn/ui的现代全栈仪表板开发实战
1. 项目概述:一个现代全栈仪表板的技术栈选择 最近在做一个内部管理后台,需要快速搭建一个既美观又功能齐全的仪表板。我的核心需求很明确:开发要快、代码质量要高、用户体验要好,并且要能轻松应对多语言场景。在评估了市面上各种…...

3个关键策略:qmcdump如何高效解密QQ音乐加密音频文件
3个关键策略:qmcdump如何高效解密QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否…...
)
基于 DWT 的盲数字水印实现(嵌入与提取)
一、原理 盲数字水印(Blind Watermarking)指提取水印时无需原始载体图像,仅依靠含水印图像和密钥即可完成。 DWT(离散小波变换) 将图像分解为: LL:低频近似分量(能量集中,…...

基于MCP协议与向量检索,为AI编程助手构建跨会话持久记忆
1. 项目概述:为AI编程助手构建持久记忆如果你和我一样,日常重度依赖Cursor、Claude Code、Windsurf这类AI编程助手,那你一定遇到过这个让人头疼的场景:昨天在Cursor里花了半小时跟AI解释清楚了一个复杂模块的业务逻辑和设计思路&a…...

医疗AI数据偏见:从耳镜图像分类看模型泛化陷阱与实战避坑指南
1. 项目概述与核心挑战作为一名在医疗AI领域摸爬滚打了十多年的从业者,我见过太多“实验室里天花乱坠,临床上寸步难行”的模型。最近,我和团队深入剖析了一项关于利用人工智能(AI)进行中耳炎耳镜图像分类的研究&#x…...

Go-ldap-admin权限系统解析:基于Casbin的RBAC实现完整指南
Go-ldap-admin权限系统解析:基于Casbin的RBAC实现完整指南 【免费下载链接】go-ldap-admin 🌉 基于GoVue实现的openLDAP后台管理项目 项目地址: https://gitcode.com/gh_mirrors/go/go-ldap-admin Go-ldap-admin作为一款基于GoVue实现的现代化Ope…...

Kubescape终极跨平台安装指南:Windows/Linux/macOS一键部署与实用技巧
Kubescape终极跨平台安装指南:Windows/Linux/macOS一键部署与实用技巧 Kubescape是一款开源的Kubernetes安全平台,专为IDE、CI/CD管道和集群设计,提供风险分析、安全合规检查和错误配置扫描功能,帮助Kubernetes用户和管理员节省宝…...

【ElevenLabs API接入黄金手册】:20年AI语音工程师亲授5大避坑要点与3小时极速上线实战路径
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs API接入黄金手册:开篇导论与核心价值定位 ElevenLabs 以行业领先的语音自然度、情感表现力与多语言支持能力,成为生成式AI语音服务的事实标准。其API并非仅提供TTS基…...