Unifying Top-down and Bottom-up Scanpath Prediction Using Transformers
Abstract
大多数视觉注意力模型旨在预测自上而下或自下而上的控制,这些控制通过不同的视觉搜索和自由观看任务进行研究。本文提出了人类注意力变换器(Human Attention Transformer,HAT),这是一个能够预测两种形式注意力控制的单一模型。HAT采用了一种新型的基于变换器的架构和简化的视网膜模型,这些共同构建了一种类似于人类动态视觉工作记忆的时空意识。HAT不仅在预测目标呈现和目标缺失视觉搜索中的注视扫描路径以及“无任务”自由观看中表现出色,成为新一代最先进的技术,还使人类注视行为变得可解释。与依赖粗略网格的注视单元并由于注视离散化而导致信息丢失的先前方法不同,HAT采用了顺序密集预测架构,并为每个注视点输出密集热图,从而避免了注视离散化。HAT设定了计算注意力的新标准,强调了其有效性、通用性和可解释性。HAT的广泛适用性和应用范围有望激发新型注意力模型的开发,这些模型能够更好地预测人类在各种需求注意力的场景中的行为。代码可在 GitHub - cvlab-stonybrook/HAT: CVPR 2024 "Unifying Top-down and Bottom-up Scanpath Prediction Using Transformers"
Introduction
注意力是一个认知过程,使人类能够将有限的认知资源选择性地分配到视觉世界的特定区域,这在人体感知系统中发挥着至关重要的作用。理解和预测人类(视觉)注意力将带来许多应用,例如:能够预测个人需求和意图的辅助技术,能够优先处理人类关注区域的感知系统,提升各种视觉任务(如物体检测)的准确性和速度,以及图像/视频压缩技术,能够将更多资源分配给编码和传输高关注区域,从而优化带宽的使用。
人类注意力控制可以分为两种广泛的形式。一种是自下而上的注意力,这意味着注意力显著性信号是从视觉输入中计算出来的,并用于优先考虑注意力的转移。因此,相同的视觉输入应导致相同的自下而上的注意力转移。第二种注意力是自上而下的,这意味着任务或目标用于控制注意力。以厨房场景为例,搜索钟表或微波炉时,人们的注视点会有所不同。这两种类型的注意力控制产生了两种不同的注视点预测文献,一种使用自由观察任务研究自下而上的注意力,另一种使用目标导向任务(通常是视觉搜索)研究自上而下的注意力控制。因此,大多数模型旨在解决自下而上或自上而下的注意力,而不是两者兼顾。一个模型架构能否预测这两种注意力控制?

图1。给定图像,所提出的HAT能够在目标存在预测扫描路径;目标不存在扫描路径;自由观看。重要的是,HAT 在三个设置中在多个数据集上优于以前的最先进的扫描路径预测方法:目标存在、目标缺失视觉搜索和自由观看,分别进行了研究。
我们对这个问题的回答是HAT(人类注意力变换器),它能够预测注视路径,即可以应用于自上而下的视觉搜索和自下而上的自由观察任务(图一)。设计一个能够预测自下而上和自上而下注意力控制的统一模型架构并非易事:1)预测人类注视路径需要模型对注视图像内容及其与外部目标的关系具有时空理解;2)预测自上而下和自下而上的注意力需要模型捕捉输入图像的低级特征和高级语义。HAT通过采用一种新型变换器设计和简化的中心凹视网膜来解决这些问题。结合这两个组件,形成了一种新的范式,构成一种动态更新的视觉工作记忆。传统方法依赖循环神经网络(RNN)来维持动态更新的隐藏向量,从而在注视之间传递信息。然而,这些方法存在缺陷:RNN牺牲了解释性,而多分辨率模拟在捕捉对注视路径预测至关重要的时间和空间信息方面表现不佳。
为了解决这些挑战,我们利用计算注意力机制动态地将每次注视获取的空间、时间和视觉信息整合到工作记忆中。这使得HAT能够辨别一组特定任务的注意力权重,以整合工作记忆中的信息并预测人类的注意力控制。这一创新机制揭示了人类注意力与工作记忆之间复杂的关系,使HAT不仅在认知上合理,而且确保了其预测的可解释性。此外,与之前的方法相比,HAT将注视路径预测视为一系列密集预测任务,采用每像素监督,成功避免了注视离散化的需求。这提高了该方法在高分辨率图像场景中的有效性。为了展示HAT的通用性,我们在三种设置下预测注视路径:目标存在(TP)、目标缺失(TA)视觉搜索和自由观察(FV),涵盖了自上而下和自下而上的注意力。在之前的工作中,预测搜索路径时,为TP和TA设置分别训练了不同的模型。而HAT是一个单一模型,在TP和TA搜索路径预测中都建立了新的最先进的水平。当用FV路径训练时,HAT相对于基准模型也取得了顶尖表现。在COCO-Search18数据集和COCO-FreeView数据集上,HAT在TP、TA和FV设置下的cNSS(注意力神经信号)分别提高了95%、94%和104%。
我们的贡献可以总结如下:
- 我们提出了HAT,一种新型的变换器架构,通过整合两种不同偏心度的视觉信息(近似视网膜中心凹)来预测人类注意力的空间和时间分配。
- 我们将扫描路径预测问题形式化为一个顺序密集预测任务,避免了注视离散化,使得HAT可以应用于高分辨率输入。
- HAT架构可以广泛应用于不同的注意力控制任务,且在视觉搜索和自由观看任务中的扫描路径预测达到了最先进水平。
- HAT的注意力预测具有很高的可解释性,适用于研究注视行为。
Related Work
注意力显著性预测:预测和理解人类注视控制在心理学中已经是一个关注了数十年的主题,但最近才引起计算机视觉领域研究者的关注。特别是Itti的开创性工作引发了计算机视觉社区对人类注意力建模的广泛兴趣,并推动了许多研究,识别和建模图像的显著视觉特征(即显著性预测)。然而,这些研究通常狭隘地集中在无特定视觉任务的自然眼动预测(即自由观看),忽视了另一种重要的注意力控制形式——目标导向注意力。此外,显著性模型仅建模注视的空间分布,而不预测注视之间的时间顺序。扫描路径预测是一个更具挑战性的问题,因为它不仅需要预测注视的位置,还需要预测注视的时间。
扫描路径预测:许多现有的扫描路径预测深度神经网络主要集中于预测自由观看的扫描路径,这主要是由于其与显著性建模的紧密联系。然而,这些模型在捕捉人类注意力控制的完整谱系方面受到限制,尤其是目标导向注意力——一种基础的认知过程,支持日常视觉任务,如导航和运动控制。尽管目标导向人类注意力在认知科学中研究已久(主要是在视觉搜索的背景下),但针对目标导向扫描路径预测的深度神经网络的发展滞后于自由观看任务模型,部分原因是缺乏数据。为了解决这一问题,Chen等人创建了第一个大型目标导向注视数据集COCO-Search18。在相关研究中,一种逆强化学习模型在COCO-Search18上展示了对目标存在扫描路径的优秀预测性能。随后,Chen等人展示了一种直接优化扫描路径相似度指标的强化学习模型,可以预测视觉问答(VQA)扫描路径以及目标存在的搜索扫描路径。最近,Gazeformer,一个基于变换器的扫描路径预测模型,进一步提升了COCO-Search18上目标存在搜索扫描路径的预测性能。然而,这些研究都未能展示对三种设置(即目标存在、目标不存在和自由观看)的普遍性。在本工作中,我们设计了一种通用的扫描路径模型,能够推广到自由观看和视觉搜索任务。
扫描路径变换器:变换器的变革性影响在自然语言处理及其他领域被广泛认可。在计算机视觉中,变换器在图像识别、目标检测和图像分割等任务中表现出色。Mondal等人介绍了Gazeformer,一个专门设计用于零-shot视觉搜索扫描路径预测的变换器模型。相比之下,我们提出的模型是通用的,能够预测视觉搜索和自由观看的扫描路径。此外,我们的模型与其他基于变换器的架构不同,受到人类视觉系统的启发,包含一个新颖的视网膜模块,模拟简化的中央凹视网膜,从而建立一个动态视觉工作记忆,以增强扫描路径预测。
Human Attention Transformer
在本节中,我们首先将扫描路径预测公式化为一系列密集预测任务,使用行为克隆的方法。然后,我们介绍我们提出的基于变换器的模型 HAT,用于扫描路径预测。最后,我们描述如何训练 HAT 以及如何进行快速推断
Preliminaries
为了避免先前注视预测方法中由于网格离散化导致的精度损失 [10, 62, 63, 66],我们将扫描路径预测公式化为像素坐标的序列预测。给定一个 H×W 的图像和一个可选的初始注视点 f0(通常设为图像的中心),扫描路径预测模型预测一系列类似人类的注视位置 f1, ···, fn,其中每个注视点 fi 是图像中的一个像素位置。需要注意的是,n 是可变的,对于不同的人类受试者,由于终止标准不同,可能会有不同的值。
为了建模人类注意力分配的不确定性,现有方法 [10, 62, 63, 66] 通常在每一步预测一个粗糙网格上注视位置的概率分布。HAT 采用相同的思路,但输出一个密集的注视热图。具体来说,HAT 输出一个热图 Yi ∈ [0, 1]H×W,每个像素值表示下一个注视中该像素被注视的概率。此外,HAT 还输出一个终止概率 τi ∈ [0, 1],表示模型在当前步骤 i 终止扫描路径的可能性。为了采样一个注视点,我们对 Yi 应用 L1 归一化。以下内容中,我们为了简洁起见省略下标 i。
Network Architecture
图2. HAT概述。
1. 特征提取编码器-解码器 CNNs:使用这种结构来提取图像的特征图。特征图 P1 和 P4:分别代表不同的空间分辨率。P4:通常是高分辨率特征图,捕捉图像的细节信息。P1:较低分辨率特征图,提供更广泛的背景信息。
2. 工作记忆工作记忆容量:设计为 λ 个标记(tokens),模拟人类的短期记忆,能够存储与当前视觉任务相关的信息。信息结合:来自 P1 的特征向量:更广泛的背景信息。来自 P4 的特征向量:源自之前注视的位置。中央注视点与周边视野:通过结合这两类信息,模型能够更好地理解当前场景的上下文。
3. 动态更新机制变换器编码器:每当新的注视点出现时,模型使用变换器编码器来动态更新工作记忆。这意味着模型可以根据视觉输入的变化迅速调整其对环境的理解。
4. 任务特定查询生成 N 个查询:针对不同的任务(例如,寻找时钟或鼠标),模型生成多个查询。查询的维度 C:表示每个任务特定的特征。聚合任务特定信息:每个查询会从共享的工作记忆中提取与其任务相关的信息,从而更准确地预测相应的注视点。
5. 热图生成卷积处理:更新后的查询与 P4 进行卷积操作,以生成注视热图。多层感知器(MLP)层:经过 MLP 层处理后,热图显示了可能的注视点位置。终止概率的投影:热图进一步被转换为终止概率,表示在特定位置停止注视的可能性。
6. 适用范围视觉搜索与自由观看:虽然该图主要展示了视觉搜索的情况,但 HAT 模型同样适用于自由观看任务。这种灵活性表明模型能够适应多种视觉任务,展现出广泛的应用潜力。



Training and Inference



Experiments
数据集:我们使用四个数据集来训练和评估 HAT:COCO-Search18、COCO-FreeView、MIT1003 和 OSIE。COCO-Search18 是一个大规模视觉搜索数据集,包含人类在搜索 18 种不同物体目标时的扫描路径,并分为目标存在和目标缺失两部分。COCO-Search18 总共有 3101 张目标存在图像和 3101 张目标缺失图像,每张图像由 10 位被试观看。我们将 COCO-Search18 的目标存在部分和目标缺失部分视为两个独立的数据集,分别训练模型。
COCO-FreeView 是 COCO-Search18 的“兄弟”数据集,包含自由观看的扫描路径。COCO-FreeView 包含与 COCO-Search18 相同的图像,每张图像同样由 10 位被试在自由观看的环境下观看。
MIT1003 是一个广泛使用的自由观看数据集,包含 1003 张自然图像。
OSIE 是一个自由观看的注视数据集,具有丰富的语义级注释,包含 700 张自然室内和室外图像。MIT1003 和 OSIE 中的每张图像由 15 位被试观看。
评估指标:为了测量性能,我们主要从两个方面分析扫描路径预测模型:
1) 预测的扫描路径与人类扫描路径的相似程度;
2) 模型在给定所有先前注视的情况下预测下一个注视的准确性。我们使用常用的度量指标,序列得分(SS)及其变体语义序列得分(SemSS)来衡量扫描路径的相似性。SS 将扫描路径转换为注视聚类 ID 的序列,并使用字符串匹配算法进行比较。与 SS 不同,SemSS 将扫描路径转换为注视像素的语义标签字符串。
对于下一个注视预测,我们遵循文献中的方法,报告条件显著性指标 cIG、cNSS 和 cAUC,这些指标衡量模型预测的注视概率图在提供扫描路径的注视历史时,如何有效地预测真实的下一个注视。为了公平比较,我们遵循文献的做法,逐步选择最可能的注视位置作为下一个注视,并为每张测试图像预测一个扫描路径。
基线模型:我们首先将我们的模型与几个启发式基线进行比较。根据前人的研究,使用一个观察者的扫描路径来预测另一个观察者的扫描路径的人类一致性被报告为黄金标准模型。其次,我们将其与一个注视启发式方法进行比较——一个训练用来预测人类注视密度图的卷积网络,从中我们按顺序选择注视点,并实施返回抑制。
对于视觉搜索扫描路径,我们还包括一个检测器基线,该基线类似于注视启发式,但训练于 COCO-Search18 的目标存在图像,以预测目标检测概率图。对于注视启发式和检测器基线,我们使用赢家通吃策略生成扫描路径。此外,我们将 HAT 与之前的最先进的扫描路径预测模型进行比较,包括 IVSN、PathGAN、IRL、Chen 等人、DeepGaze III、FFMs 和 GazeFormer。注意,IVSN 仅适用于视觉搜索任务,且与其他方法不同,IVSN 被设计用于零-shot 搜索扫描路径预测,因此未使用任何注视数据进行训练。DeepGaze III 仅适用于自由观看扫描路径,并使用 SALICON 数据集和 MIT1003 进行训练。
实现细节:我们使用 ResNet-50 作为像素编码器,使用 MSDeformAttn 作为像素解码器。对于聚焦模块,变压器编码器有三层。聚合模块中的变压器解码器有六层(即 L=6)。HAT 中所有变压器编码器和解码器层都有 4 个注意力头。注视预测模块中的多层感知器(MLP)有两个线性层,隐藏维度为 512,使用 ReLU 激活函数。我们使用 AdamW 优化器,学习率为 0.0001,训练 HAT 30 个周期,批量大小为 128。所有图像在训练和推理期间被调整为 320×512,以提高计算效率。按照前人的研究,我们将每个预测扫描路径的最大长度设置为 6(针对目标存在)和 10(针对目标缺失),自由观看的最大扫描路径长度设置为 20。有关更多实现细节,请参见补充材料。
Main Results
我们在目标存在(TP)设置下,使用 COCO-Search18 数据集的目标存在部分对 HAT 与之前的扫描路径预测模型进行了比较,结果见表 1。HAT 在几乎所有指标上都持续超越了其他预测方法,能够更准确地预测 TP 人类扫描路径。简单的启发式基线(即检测器和注视启发式)在 TP 扫描路径预测中表现相当不错,因为在 COCO-Search18 的 60% TP 试验中,人类能够在 2 次注视内找到目标。

在 COCO-Search18 的目标存在测试集上进行的比较。我们将最佳结果加粗显示。
然而,它们在显著性指标(即 cIG、cNSS 和 cAUC)上得分较低,因为它们忽略了注视点之间的相互依赖性。与 FFMs [63] 和 Chen 等人 [10] 相比,它们在显著性得分上较高,HAT 在所有指标上都显著提高了性能。特别是,HAT 在 cNSS 上比排名第二的 Chen 等人 [10] 高出 95%。HAT 在 SS 上略逊于最近的 GazeFormer [42],但在 semSS 上明显更好。我们还在补充材料中展示了 HAT 从多个受试者那里学习了整个扫描路径分布,而 GazeFormer 过度拟合于“平均人”并且无法预测来自不同受试者的扫描路径。此外,HAT 在 semSS 上超过了人类一致性,这表明 HAT 很好地捕捉了注视背后的语义。
目标缺失(Target-absent, TA)搜索。对于目标缺失的扫描路径预测,我们在 COCO-Search18 数据集的 TA 测试集上将 HAT 与不同方法进行了对比,结果如表 2 所示。与表 1 中目标存在(TP)搜索结果不同的是,我们在表 2 中发现,启发式方法与人类一致性之间的差距在 TA 搜索中显著更大,这表明 TA 搜索的扫描路径预测比 TP 搜索更具挑战性。实际上,在 TP 搜索中对人类注意力的主要影响因素(即目标)在 TA 搜索中已经不存在【12】,因此锚定物体提供的空间线索【4】、来自全局场景理解的上下文线索【52】以及物体共现性【40】等其他因素变得更加突出。辨别这些因素需要对输入图像进行稳健的语义理解。表 2 显示,HAT 在所有指标上都创下了新的最先进水平(state-of-the-art),cNSS 分数比之前的最佳方法(Chen 等人【10】)提高了 94%。更重要的是,HAT 首次在序列得分上超过了人类一致性。这些结果表明,与其他方法相比,HAT 能更好地捕捉图像的语义,并学习物体与目标之间的关系。

在 COCO-Search18 的目标缺失测试集上进行的比较。我们将最佳结果加粗显示。
Qualitative Analysis
扫描路径可视化。在本节中,我们定性地比较了不同方法预测的扫描路径与真实人类扫描路径在目标存在(TP)、目标缺失(TA)和自由观看(FV)设置下的表现。如图 4 所示,在 TP 设置中寻找瓶子时,HAT 不仅准确预测了被严重遮挡的目标的终点注视点,还像人类一样对所有与目标相似的干扰物进行了预测。其他方法要么遗漏了干扰物,要么未能找到目标。同样,在寻找停车标志的 TA 设置中,HAT 是唯一一个像人类一样查看道路两侧的模型,展示了使用语义和上下文线索来引导注意力的能力。在 FV 设置中,HAT 还在(1)注视位置(哪里)、(2)语义(是什么)和(3)注视顺序(何时)方面预测了最接近人类的扫描路径。更多的扫描路径可视化可以在补充材料中找到。

图 4. 真实人类扫描路径与不同方法预测的扫描路径可视化(列)。从上到下显示了三种不同的设置:目标存在的瓶子搜索、目标缺失的停车标志搜索和自由观看。每条扫描路径的最终注视点用红色圆圈突出显示。对于没有终止预测的方法,如 IRL、检测器和注视启发式方法,我们可视化了视觉搜索的前 6 次注视和自由观看的前 15 次注视。最右侧一列显示了启发式方法(视觉搜索的检测器 630 和自由观看的注视启发式)的预测扫描路径。
模型可解释性。HAT 的一个显著特点在于其可解释性,这得益于其计算注意力机制和中央凹模块设计。HAT 可以定量衡量周边视野(peripheral)和中央凹(foveal)特征对注视分配的贡献。特征的贡献通过 HAT 聚合模块中最后一个交叉注意力层的注意力权重计算得出。通过计算每个周边特征的归一化贡献,我们生成了一张周边贡献图,这为理解人类注视行为提供了新的见解。我们进一步分析了周边贡献图在一系列注视中的演化过程。

图 7 展示了 HAT 在 TP 笔记本搜索任务中的预测扫描路径、周边贡献图和预测注视热图。我们发现,编码的周边特征不仅与下一次注视的位置一致(例如,当被遮挡的笔记本在左下方周边被编码时,模型将注视移动到目标并终止搜索),还提供了目标可能位于某些位置的上下文线索(例如,通常在键盘和显示器附近可能找到笔记本)。我们在 TA 场景中也观察到了类似的模式(详见补充材料)。此外,在补充材料中,我们还系统分析了周边和中央凹特征在预测人类注意力控制中的综合贡献,结果表明周边视野在不同场景下扮演着不同的角色。
这些研究表明,HAT 能够进行高度可解释的预测。
相关文章:
Unifying Top-down and Bottom-up Scanpath Prediction Using Transformers
Abstract 大多数视觉注意力模型旨在预测自上而下或自下而上的控制,这些控制通过不同的视觉搜索和自由观看任务进行研究。本文提出了人类注意力变换器(Human Attention Transformer,HAT),这是一个能够预测两种形式注意力…...

JavaSE(十四)——文件操作和IO
文章目录 文件操作和IO文件相关概念Java操作文件文件系统操作文件内容操作字节流FileOutputStreamFileInputStream代码演示 字符流FileWriterFileReader代码演示 缓冲流转换流 案例练习 文件操作和IO 文件相关概念 文件 通常指的是包含用户数据的文件,如文本文件、…...

【视觉SLAM】4b-特征点法估计相机运动之PnP 3D-2D
文章目录 0. 前言1. PnP求解1.1 直接线性变换DLT1.2 P3P1.3 光束平差法BA2. 实现0. 前言 透视n点(Perspective-n-Point,PnP)问题是计算机视觉领域的经典问题,用于求解3D-2D的点运动。换句话说,当知道 N N N个世界坐标系中3D空间点的坐标以及它们在图像上的投影点像素坐标…...
Asan 内存检测工具)
android 性能分析工具(04)Asan 内存检测工具
1 Asan工具简介 1.1 Asan工具历史背景 AddressSanitizer(ASan)最初由Google开发,并作为LLVM项目的一部分。ASan的设计目的是帮助开发者检测并修复内存错误,如堆栈和全局缓冲区溢出、使用已释放的内存等,这些问题可能…...

html中select标签的选项携带多个值
搜索参考资料:SELECT标签中的选项可以携带多个值吗? 【摘抄】: 它可能有一个select选项中的多个值,如下所示。 <select id"ddlEmployee" class"form-control"> <option value"">-- S…...

Lambda表达式如何进行调试
一、概述 Java8提供了lambda表达式,方便我们对数据集合进行操作,我们使用lambda表达式的时候,是不是有这样的疑问,如何对执行过程中的中间数据进行调试呢? 二、例子 在下面的例子中,我们实现随机最多生成…...

C++ —— 剑斩旧我 破茧成蝶—C++11
江河入海,知识涌动,这是我参与江海计划的第2篇。 目录 1. C11的发展历史 2. 列表初始化 2.1 C98传统的{} 2.2 C11中的{} 2.3 C11中的std::initializer_list 3. 右值引用和移动语义 3.1 左值和右值 3.2 左值引用和右值引用 3.3 引用延长生命周期…...

HTML5好看的音乐播放器多种风格(附源码)
文章目录 1.设计来源1.1 音乐播放器风格1效果1.2 音乐播放器风格2效果1.3 音乐播放器风格3效果1.4 音乐播放器风格4效果1.5 音乐播放器风格5效果 2.效果和源码2.1 动态效果2.2 源代码 源码下载万套模板,程序开发,在线开发,在线沟通 作者&…...

C++设计模式行为模式———迭代器模式中介者模式
文章目录 一、引言二、中介者模式三、总结 一、引言 中介者模式是一种行为设计模式, 能让你减少对象之间混乱无序的依赖关系。 该模式会限制对象之间的直接交互, 迫使它们通过一个中介者对象进行合作。 中介者模式可以减少对象之间混乱无序的依赖关系&…...

FFmpeg 4.3 音视频-多路H265监控录放C++开发十五,解码相关,将h264文件进行帧分隔变成avpacket
前提 前面我们学习了 将YUV数据读取到AVFrame,然后将AVFrame通过 h264编码器变成 AVPacket后,然后将avpacket直接存储到了本地就变成了h264文件。 这一节课,学习解码的一部分。我们需要将 本地存储的h264文件进行帧分隔,也就是变…...

力扣 LeetCode 104. 二叉树的最大深度(Day7:二叉树)
解题思路: 采用后序遍历 首先要区别好什么是高度,什么是深度 最大深度实际上就是根节点的高度 高度的求法是从下往上传,从下往上传实际上就是左右中(后序遍历) 深度的求法是从上往下去寻找 所以采用从下往上 本…...
如何高效实现汤臣倍健营销云数据集成到SQLServer
新版订单同步-(Life-Space)江油泰熙:汤臣倍健营销云数据集成到SQL Server 在企业信息化建设中,数据的高效集成和管理是提升业务运营效率的关键。本文将分享一个实际案例——如何通过新版订单同步方案,将汤臣倍健营销云…...

Vue3中使用:deep修改element-plus的样式无效怎么办?
前言:当我们用 vue3 :deep() 处理 elementui 中 el-dialog_body和el-dislog__header 的时候样式一直无法生效,遇到这种情况怎么办? 解决办法: 1.直接在 dialog 上面增加class 我试过,也不起作用,最后用这种…...

具身智能之Isaac Gym使用
0. 简介 Isaac Gym 是由 NVIDIA 提供的一个高性能仿真平台,专门用于大规模的机器人学习和强化学习(RL)任务。它结合了物理仿真、GPU加速、深度学习框架互操作性等特点,使得研究人员和开发者可以快速进行复杂的机器人仿真和训练。…...

【大数据学习 | Spark】spark-shell开发
spark的代码分为两种 本地代码在driver端直接解析执行没有后续 集群代码,会在driver端进行解析,然后让多个机器进行集群形式的执行计算 spark-shell --master spark://nn1:7077 --executor-cores 2 --executor-memory 2G sc.textFile("/home/ha…...

《Python制作动态爱心粒子特效》
一、实现思路 粒子效果: – 使用Pygame模拟粒子运动,粒子会以爱心的轨迹分布并运动。爱心公式: 爱心的数学公式: x16sin 3 (t),y13cos(t)−5cos(2t)−2cos(3t)−cos(4t) 参数 t t 的范围决定爱心形状。 动态效果: 粒子…...
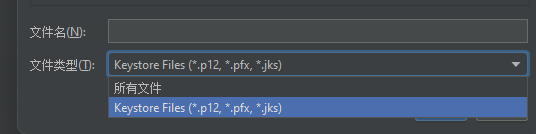
Jmeter 如何导入证书并调用https请求
Jmeter 如何导入证书并调用https请求 通过SSL管理器添加证书文件 支持添加的文件为.p12,.pfx,.jks 如何将pem文件转换为pfx文件? 在公司内部通常会提供3个pem文件。 ca.pem:可以理解为是根证书,用于验证颁发的证…...

Python程序15个提速优化方法
目录 Python程序15个提速优化方法1. 引言2. 方法一:使用内建函数代码示例:解释: 3. 方法二:避免使用全局变量代码示例:解释: 4. 方法三:使用局部变量代码示例:解释: 5. 方…...

足球虚拟越位线技术FIFA OT(二)
足球虚拟越位线技术FIFA OT(二) 在FIFA认证测试过程中,留给VAR系统绘制越位线的时间只有90秒(在比赛中时间可能更短),那么90秒内要做什么事呢,首先场地上球员做出踢球动作,然后VAR要…...

centos7.9单机版安装K8s
1.安装docker [rootlocalhost ~]# hostnamectl set-hostname master [rootlocalhost ~]# bash [rootmaster ~]# mv /etc/yum.repos.d/* /home [rootmaster ~]# curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo [rootmaster ~]# cu…...

73:L的程序安全:蓝队的规范防御
作者: HOS(安全风信子) 日期: 2026-03-26 主要来源平台: GitHub 摘要: 程序安全是防御的基石,通过规范的流程、自动化执行和可追溯设计构建可靠的安全防御体系。本文分享程序安全的核心价值、L的程序安全策略、技术实现…...

MedGemma 1.5新手必看:从安装到问诊,完整使用流程详解
MedGemma 1.5新手必看:从安装到问诊,完整使用流程详解 你是否曾面对一份复杂的化验单,需要快速理解其临床意义?是否在深夜值班时,想快速确认某个药物的相互作用?或者,作为一名医学生࿰…...

Qwen3-TTS作品分享:听AI朗读你的日记、诗歌和故事
Qwen3-TTS作品分享:听AI朗读你的日记、诗歌和故事 1. 为什么你需要一个会"读心"的语音合成工具 想象一下这样的场景:深夜写完日记,点击播放键,听到一个温暖的声音将你的文字娓娓道来;创作完一首诗…...

终极PDF批量处理指南:如何用PDF Arranger自动化文档操作
终极PDF批量处理指南:如何用PDF Arranger自动化文档操作 【免费下载链接】pdfarranger Small python-gtk application, which helps the user to merge or split PDF documents and rotate, crop and rearrange their pages using an interactive and intuitive gra…...

Ubuntu系统磁盘管理
要在Ubuntu系统中开机自动挂载AWS EBS卷(设备名为/dev/xvdd),需通过**/etc/fstab文件**配置自动挂载规则。以下是完整步骤(含前提条件、命令和验证): 一、前提条件 确认磁盘状态:/dev/xvdd需已…...
)
UniApp跨平台开发入门:用现有Vue代码快速生成小程序/App(2023最新版)
UniApp跨平台开发实战:2023年Vue代码高效迁移指南 移动互联网时代,开发者常面临一个核心挑战:如何用最小成本将Web应用扩展到移动端。如果你手头已有成熟的Vue项目,UniApp可能是最经济的跨平台解决方案——它允许你复用80%以上的现…...
)
Isaac Sim 4.1.0 国内网络环境下的三种下载与安装提速方案(含离线包处理)
Isaac Sim 4.1.0 国内网络环境下的高效安装指南 对于国内开发者而言,安装NVIDIA Isaac Sim往往面临下载速度缓慢、连接不稳定等问题。本文将提供三种经过验证的解决方案,帮助您快速完成安装。 1. 直链下载加速方案 通过分析Omniverse Launcher的日志文件…...

深度解析Cassandra:分布式数据库的王者之路
深度解析Cassandra:分布式数据库的王者之路一篇让你彻底搞懂Cassandra的适用场景、优势劣势与应用实践前言 在大数据时代,传统的关系型数据库已经无法满足所有场景的需求。随着互联网应用的爆发式增长,高可用性、线性扩展、海量数据存储成为了…...

jsontop.cn使用全攻略:免费无广告的在线工具站,电脑手机通用
你是否经常遇到这些问题: 拿到一堆杂乱 JSON 看不懂,想格式化却不会?需要转 Base64、算 MD5、转时间戳,却要装复杂软件?想测试正则、预览 HTML,还要搭环境、找插件?网上工具全是广告࿰…...

Winhance:重塑Windows体验的系统优化与个性化解决方案
Winhance:重塑Windows体验的系统优化与个性化解决方案 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. PowerShell GUI application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi…...