深度学习:ResNet每一层的输出形状
 其中
其中
/**在输出通道数为64、步幅为2的7 × 7卷积层后,接步幅为2的3 × 3的最大汇聚层,与GoogLeNet区别是每个卷积层后增加了批量规范层**/
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))/**ResNet在后面接了由4个残差块组成的模块,每个模块使用若干个同样输出通道数的残差块,本例每个模块使用2个残差块
**/
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5,nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(), nn.Linear(512, 10))
##模块的构成
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels,use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))return blk##残差块的构成(详细解释在下面)
class Residual(nn.Module):def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)
残差块里首先有2个有相同输出通道数的3 × 3卷积层。每个卷积层后接一个批量规范化层和ReLU激活函数。然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。如果想改变通道数,就需要引入一个额外的1 × 1卷积层来将输入变换成需要的形状后再做相加运算。
接下来通过一个实例来展示下ResNet的每一层的输出形状
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:X = layer(X)print(layer.__class__.__name__, 'output shape:\t', X.shape)
输出结果为
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
解释每一层的输出形状
-
b1
输入形状:torch.Size([1, 1, 224, 224])输出形状:torch.Size([1, 64, 56, 56])
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3):将输入的 1 个通道扩展为 64 个通道,特征图的尺寸从 224x224 变为 112x112。
卷积层的输出特征图的尺寸可以通过以下公式计算: Output Size=(Input Size−Kernel
Size+2×Padding)/Stride+1 本例即Output Size=(224−7+2×3)/2+1 = 112nn.BatchNorm2d(64):对 64 个通道进行批量归一化。
nn.ReLU():应用 ReLU 激活函数。
nn.MaxPool2d(kernel_size=3, stride=2, padding=1):最大池化层将特征图的尺寸从 112x112 变为 56x56。最大池化的输出特征图的尺寸可以通过以下公式计算: Output Size=(Input Size−Kernel
Size+2×Padding)/2Stride+1 本例即Output Size=(112−3+2×1)/2+1=56 -
b2:
输入形状:torch.Size([1, 64, 56, 56])
输出形状:torch.Size([1, 64, 56, 56])
解释:resnet_block(64, 64, 2, first_block=True):包含两个残差块,输入和输出通道数均为 64,特征图的尺寸保持不变(56x56)。
-
b3:
输入形状:torch.Size([1, 64, 56, 56])
输出形状:torch.Size([1, 128, 28, 28])
解释:resnet_block(64, 128, 2):包含两个残差块,输入通道数为 64,输出通道数为 128,特征图的尺寸减半(56x56 -> 28x28)。
是通过在第一个残差块中使用步幅为 2 的卷积操作来实现的。特征图尺寸减半的原因是为了在增加网络深度的同时,减小特征图的尺寸,从而减少计算量和参数数量,同时增加感受野,提高网络的性能和效率。
-
b4:
输入形状:torch.Size([1, 128, 28, 28])
输出形状:torch.Size([1, 256, 14, 14])
解释:resnet_block(128, 256, 2):包含两个残差块,输入通道数为 128,输出通道数为 256,特征图的尺寸减半(28x28 -> 14x14)。
-
b5:
输入形状:torch.Size([1, 256, 14, 14])
输出形状:torch.Size([1, 512, 7, 7])
解释:resnet_block(256, 512, 2):包含两个残差块,输入通道数为 256,输出通道数为 512,特征图的尺寸减半(14x14 -> 7x7)。
-
AdaptiveAvgPool2d:
输入形状:torch.Size([1, 512, 7, 7])
输出形状:torch.Size([1, 512, 1, 1])
解释:自适应平均池化层将特征图的尺寸调整为 1x1,通道数保持不变。
-
Flatten:
输入形状:torch.Size([1, 512, 1, 1])
输出形状:torch.Size([1, 512])
解释:展平层将多维特征图展平成一维向量,总元素数为 512。
-
Linear:
输入形状:torch.Size([1, 512])
输出形状:torch.Size([1, 10])
解释:全连接层将输入的 512 个元素映射到 10 个元素,输出 10 个类别的概率分布。
相关文章:
深度学习:ResNet每一层的输出形状
其中 /**在输出通道数为64、步幅为2的7 7卷积层后,接步幅为2的3 3的最大汇聚层,与GoogLeNet区别是每个卷积层后增加了批量规范层**/ b1 nn.Sequential(nn.Conv2d(1, 64, kernel_size7, stride2, padding3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_s…...

国内几大网络安全公司介绍 - 网络安全
Posted by zhaol under 安全 , 电信 , 评论 , 中国 中国国内的安全市场进入“战国时期”,启明星辰、绿盟、天融信、安氏、亿阳、联想网御、华为等战国七雄拥有雄厚的客户资源和资金基础,帐前皆有勇猛善战之士,渐渐开始统领国内安全市场的潮流…...

修改Android Studio项目配置JDK路径和项目Gradle路径的GUI工具
概述 本工具提供了一个基于Python Tkinter的图形用户界面(GUI),用于帮助用户搜索并更新Android Studio项目中的config.properties文件里的java.home路径,以及workspace.xml文件中的last_opened_file_path路径。该工具旨在简化手动…...
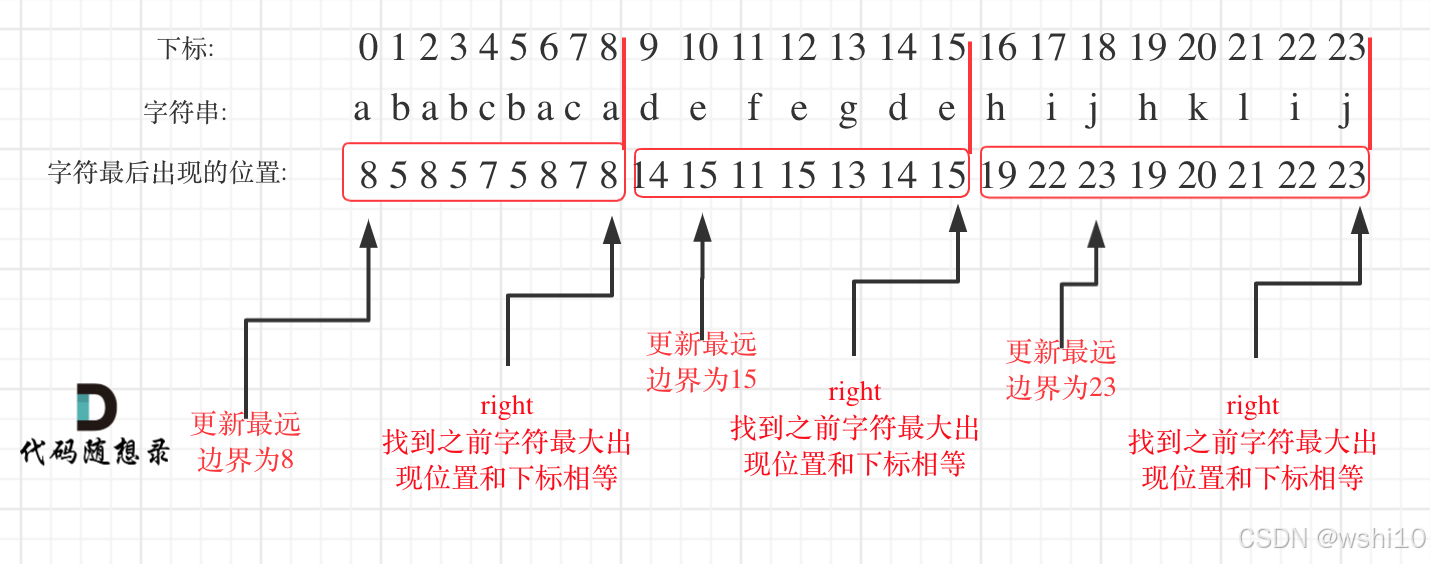
✅DAY30 贪心算法 | 452. 用最少数量的箭引爆气球 | 435. 无重叠区间 | 763.划分字母区间
452. 用最少数量的箭引爆气球 解题思路:首先把原数组按左边界进行排序。然后比较[i-1]的右边界和[i]的左边界是否重叠,如果重叠,更新当前右边界为最小右边界和[i1]的左边界判断是重叠。 class Solution:def findMinArrowShots(self, points:…...

关于Redis单线程模型以及IO多路复用的理解
IO多路复用 -> redis主线程 -> 事件队列 -> 事件处理器 1.IO多路复用机制的作用: 操作系统的多路复用机制(如 epoll、select)负责监听多个文件描述符(如客户端连接)上的事件。 当某个文件描述符上的事件就绪…...

学习ASP.NET Core的身份认证(基于Cookie的身份认证1)
B/S架构程序可通过Cookie、Session、JWT、证书等多种方式认证用户身份,虽然之前测试过用户登录代码,也学习过开源项目中的登录认证,但其实还是对身份认证疑惑甚多,就比如登录验证后用户信息如何保存、客户端下次连接时如何获取用户…...

奇门遁甲中看债务时用神该怎么取?
奇门遁甲中看债务的用神 一、值符 值符在债务关系中可代表债权人(放贷人)。例如在预测放贷时,以值符为放贷人,如果值符克天乙(借贷人)或者天乙生值符,这种情况下可以放贷;反之&#…...

Redis 集群主要有以下几种类型
Redis 集群主要有以下几种类型: 主从复制模式: 这种模式包含一个主数据库实例(master)与一个或多个从数据库实例(slave)。客户端可以对主数据库进行读写操作,对从数据库进行读操作,主…...

使用 Axios 拦截器优化 HTTP 请求与响应的实践
目录 前言1. Axios 简介与拦截器概念1.1 Axios 的特点1.2 什么是拦截器 2. 请求拦截器的应用与实践2.1 请求拦截器的作用2.2 请求拦截器实现 3. 响应拦截器的应用与实践3.1 响应拦截器的作用3.2 响应拦截器实现 4. 综合实例:一个完整的 Axios 配置5. 使用拦截器的好…...
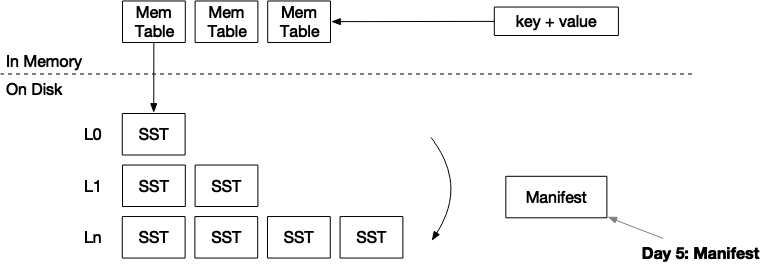
mini-lsm通关笔记Week2Day5
项目地址:https://github.com/skyzh/mini-lsm 个人实现地址:https://gitee.com/cnyuyang/mini-lsm Summary 在本章中,您将: 实现manifest文件的编解码。系统重启时从manifest文件中恢复。 要将测试用例复制到启动器代码中并运行…...

mybatis的动态sql用法之排序
概括 在最近的开发任务中,涉及到了一些页面的排序,其中最为常见的就是时间的降序和升序。这个有的前端控件就可以完成,但是对于一些无法用前端控件的,只能通过后端来进行解决。 后端的解决方法就是使用mybatis的动态sql拼接。 …...

OneToMany 和 ManyToOne
在使用 ORM(如 TypeORM)进行实体关系设计时,OneToMany 和 ManyToOne 是非常重要的注解,常用来表示两个实体之间的一对多关系。下面通过例子详细说明它们的使用场景和工作方式。 OneToMany 和 ManyToOne 的基本概念 ManyToOne 表示…...

《生成式 AI》课程 第3講 CODE TASK 任务3:自定义任务的机器人
课程 《生成式 AI》课程 第3講:訓練不了人工智慧嗎?你可以訓練你自己-CSDN博客 我们希望你创建一个定制的服务机器人。 您可以想出任何您希望机器人执行的任务,例如,一个可以解决简单的数学问题的机器人0 一个机器人,…...

反转链表、链表内指定区间反转
反转链表 给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。 如当输入链表{1,2,3}时,经反转后,原链表变…...

Debezium系列之:Debezium3版本使用快照过程中的指标
Debezium系列之:Debezium3版本使用快照过程中的指标 一、背景二、技术原理三、增量快照四、阻塞快照指标一、背景 使用快照技术的过程中可以观察指标,从而确定快照的进度二、技术原理 Debezium系列之:Debezium 中的增量快照Debezium系列之:Incremental snapshotting设计原理…...

第一讲,Opencv计算机视觉基础之计算机视觉概述
深度剖析计算机视觉:定义、任务及未来发展趋势 引言 计算机视觉(Computer Vision)是人工智能的重要分支之一,旨在让机器通过视觉感知和理解环境。随着深度学习的快速发展,计算机视觉在自动驾驶、安防监控、医疗影像等…...

数据结构(双向链表——c语言实现)
双向链表相比于单向链表的优势: 1. 双向遍历的灵活性 双向链表:由于每个节点都包含指向前一个节点和下一个节点的指针,因此可以从头节点遍历到尾节点,也可以从尾节点遍历到头节点。这种双向遍历的灵活性使得在某些算法和操作中&a…...

【新人系列】Python 入门(十一):控制结构
✍ 个人博客:https://blog.csdn.net/Newin2020?typeblog 📝 专栏地址:https://blog.csdn.net/newin2020/category_12801353.html 📣 专栏定位:为 0 基础刚入门 Python 的小伙伴提供详细的讲解,也欢迎大佬们…...

群核科技首次公开“双核技术引擎”,发布多模态CAD大模型
11月20日,群核科技在杭州举办了第九届酷科技峰会。现场,群核科技首次正式介绍其技术底层核心:基于GPU高性能计算的物理世界模拟器。并对外公开了两大技术引擎:群核启真(渲染)引擎和群核矩阵(CAD…...

【AI大模型引领变革】探索AI如何重塑软件开发流程与未来趋势
文章目录 每日一句正能量前言流程与模式介绍【传统软件开发 VS AI参与的软件开发】一、传统软件开发流程与模式二、AI参与的软件开发流程与模式三、AI带来的不同之处 结论 AI在软件开发流程中的优势、挑战及应对策略AI在软件开发流程中的优势面临的挑战及应对策略 结论 后记 每…...

终极免费风扇控制软件:FanControl完整配置与优化指南
终极免费风扇控制软件:FanControl完整配置与优化指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/…...

如何3分钟解放你的B站缓存视频?m4s-converter终极转换指南
如何3分钟解放你的B站缓存视频?m4s-converter终极转换指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是不是也遇到过这样的烦…...

CTFshow F5杯 逆向与隐写实战解析 超详细
1. CTFshow F5杯逆向与隐写技术全景解析 去年参加F5杯时,我对着那道LSB隐写题折腾到凌晨三点。当终于从图片噪点中提取出flag那一刻,突然理解了什么叫做"数字世界的考古学"。逆向工程和隐写术就像侦探破案,需要同时具备技术功底和发…...

DDrawCompat完整教程:Windows 11上经典游戏DirectDraw兼容性修复终极指南
DDrawCompat完整教程:Windows 11上经典游戏DirectDraw兼容性修复终极指南 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh…...

英雄联盟免费专业录像编辑器:League Director完整使用终极指南
英雄联盟免费专业录像编辑器:League Director完整使用终极指南 【免费下载链接】leaguedirector League Director is a tool for staging and recording videos from League of Legends replays 项目地址: https://gitcode.com/gh_mirrors/le/leaguedirector …...

CSS Flexbox 布局高级技巧完全指南
CSS Flexbox 布局高级技巧完全指南 引言 Flexbox 是现代 CSS 布局的核心技术之一,它提供了一种一维布局方式,让开发者能够轻松实现灵活的响应式布局。本文将深入探讨 Flexbox 的高级特性和实用技巧。 Flexbox 基础回顾 在深入高级技巧之前,让…...

掌握显卡性能调优:NVIDIA Profile Inspector 7个实用技巧
掌握显卡性能调优:NVIDIA Profile Inspector 7个实用技巧 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款强大的显卡配置工具,能够深度修改NVIDI…...

Docker Maven Plugin 最佳实践:企业级Docker化部署的完整解决方案 [特殊字符]
Docker Maven Plugin 最佳实践:企业级Docker化部署的完整解决方案 🚀 【免费下载链接】docker-maven-plugin Maven plugin for running and creating Docker images 项目地址: https://gitcode.com/gh_mirrors/doc/docker-maven-plugin 想要快速实…...

GitHub Actions 工作流中的输出处理
在现代软件开发中,CI/CD(持续集成和持续交付)是确保代码质量和自动化部署的关键环节。GitHub Actions 作为 GitHub 提供的 CI/CD 工具,支持通过工作流文件定义自动化任务。本文将结合一个实际的 GitHub Actions 工作流实例,探讨如何处理 Python 脚本的输出,并根据该输出决…...

简单学习 --> 数据加密
加密/加盐存储在数据库里的数据都是明文的, 如果数据库被盗, 数据就被泄露了;所以要进行加密密码算法对称密码算法: 加密和解密的算法用同一个; x明文,y密文 , f() 加密算法 > y f(x) , x f(y) ; 常见: AES , DES非对称密码算法: 公钥和私钥 ; > 使用公钥进行加密 , 使…...