hhdb数据库介绍(9-24)
计算节点参数说明
failoverAutoresetslave
参数说明:
| Property | Value |
|---|---|
| 参数值 | failoverAutoresetslave |
| 是否可见 | 是 |
| 参数说明 | 故障切换时,是否自动重置主从复制关系 |
| 默认值 | false |
| Reload是否生效 | 否 |
参数设置:
<property name="failoverAutoresetslave">false</property><!-- 故障切换时,是否自动重置主从复制关系 -->
参数作用:
此参数用于保障存储节点发生故障切换后的数据正确性。开启参数,故障切换后,会暂停原主从之间IO线程,等原主库恢复正常后,检测原从库(现主库)是否仍存在未接收的事务,若存在,则自动重置主从复制关系。
frontConnectionTrxIsoLevel
参数说明:
| Property | Value |
|---|---|
| 参数值 | frontConnectionTrxIsoLevel |
| 是否可见 | 否 |
| 参数说明 | 前端连接默认隔离级别 |
| 默认值 | 2 |
| Reload是否生效 | 是 |
参数设置:
<property name="frontConnectionTrxIsoLevel">2</property>
参数作用:
用于设置计算节点的前端连接的默认初始时的隔离级别,五种隔离级别选择:
0=read-uncommitted; 1=read-committed; 2=repeatable-read; 3=serializable;4=read-semi-committed
frontWriteBlockTimeout
参数说明:
| Property | Value |
|---|---|
| 参数值 | frontWriteBlockTimeout |
| 是否可见 | 是 |
| 参数说明 | 前端连接写阻塞超时时间 |
| 默认值 | 10000ms |
| 最小值 | 2000ms |
| 最大值 | 600000ms |
| Reload是否生效 | Y |
参数作用:
在计算节点到客户端存在网络延迟过大或者网络不可达,客户端接收数据慢等情况下,可能会出现前端写阻塞。
前端连接写阻塞超时时,会关闭前端连接,然后输出对应的日志提示" closed, due to write block timeout",如下:
2018-06-14 13:46:48.355 [INFO] [] [TimerExecutor1] FrontendConnection(695) -- [thread=TimerExecutori,id=9,user=cara,host=192.168.200.82,port=8883,localport=61893,schema=TEST_LGG] closed, due to write block timeout, executing SQL: select * from customer_auto_1
forwardFunction
参数说明:
| Property | Value |
|---|---|
| 参数值 | forwardFunction |
| 是否可见 | 否 |
| 参数说明 | 非单库逻辑库,开启后可下发函数DDL |
| 默认值 | false |
| Reload是否生效 | 是 |
参数设置:
<property name="forwardFunction">false</property><!-- 下发函数DDL(forward function operation to datasource) -->
参数作用:
forwardFunction参数开启后支持非单库函数DDL语句下发。 参数为false时,非单库的逻辑库,禁止执行函数DDL(CREATE\ALTER\DROP):

参数为true时,非单库的逻辑库,可以执行函数DDL(CREATE\ALTER\DROP)

generatePrefetchCostRatio
参数说明:
| Property | Value |
|---|---|
| 参数值 | generatePrefetchCostRatio |
| 是否可见 | 否 |
| 参数说明 | 触发提前预取的已消耗比例 |
| 默认值 | 90 |
| 最小值 | 50 |
| 最大值 | 100 |
| Reload是否生效 | 是 |
参数设置:
<property name="generatePrefetchCostRatio">70</property>
参数作用:
隐藏参数,配置批次已消耗比例,已消耗比例是指当前自增值占当前批次大小的比例,例如当前自增值为89,当前批次大小为100,则已消耗比例为89%。
若批次使用率达到已消耗比例,则会触发提前预取新的批次。例如参数设置为70,若批次使用率达到70%,则开始预取下一批次。
globalUniqueConstraint
参数说明:
| Property | Value |
|---|---|
| 参数值 | globalUniqueConstraint |
| 是否可见 | 否 |
| 参数说明 | 新增表是否默认开启全局唯一约束 |
| 默认值 | false |
| Reload是否生效 | 是 |
参数设置:
server.xml中globalUniqueConstraint参数配置 如下配置:
<property name="globalUniqueConstraint">false</property><!--新增表是否默认开启全局唯一约束-->
参数作用:
新增表是否默认开启全局唯一约束,修改为true后可默认为添加的表开启全局唯一约束。
开启全局唯一约束保证有唯一约束(UNIQUE、PRIMARY KEY)的列在所有数据节点上唯一。注意:开启该功能后,可能对SQL语句INSERT、UPDATE、DELETE执行效率有较大影响,可能导致SQL操作延迟增大;还可能导致锁等待和死锁的情况增加。
haMode
参数说明:
| Property | Value |
|---|---|
| 参数值 | haMode |
| 是否可见 | 是 |
| 参数说明 | 高可用模式, 0:HA, 1:集群, 2:HA模式中心机房, 3:HA模式容灾机房,4:集群模式中心机房,5:集群模式容灾机房 |
| 默认值 | 0 |
| Reload是否生效 | 是 |
参数设置:
server.xml中haMode参数配置 如下配置:
<property name="haMode">0</property><!-- 高可用模式, 0:HA, 1:集群, 2:HA模式中心机房, 3:HA模式容灾机房,4:集群模式中心机房,5:集群模式容灾机房 -->
参数作用:
haMode可设置为0,1,2,3,4,5。对于单机房模式下的计算节点集群,与低版本的使用方法相同,将haMode设置为0或1,表示单机房模式下的单节点、高可用以及集群模式。对于容灾模式下的计算节点集群,在中心机房将此参数设置为2,在容灾机房将此参数设置为3,表示容灾模式下的单节点或高可用模式。容灾模式的计算节点集群不支持集群模式。其中4为开启容灾模式后,计算节点为多计算节点集群模式的中心机房;5为开启容灾模式后,计算节点为多计算节点集群模式的容灾机房。
haState & haNodeHost
参数说明:
| Property | Value |
|---|---|
| 参数值 | haState |
| 是否可见 | 是 |
| 参数说明 | 计算节点高可用模式下的主备角色配置,主计算节点配置为:master,备计算节点配置为:backup(集群模式下,此项无效) |
| 默认值 | master |
| Reload是否生效 | 否 |
| Property | Value |
|---|---|
| 参数值 | haNodeHost |
| 是否可见 | 是 |
| 参数说明 | 计算节点高可用模式下需配置当前主计算节点管理端口连接信息;集群模式下,需配置所有成员的集群通信端口连接信息(集群在同一网段且集群端口相同时,可以不配置该参数) |
| 默认值 | (空) |
| Reload是否生效 | 否 |
参数设置:
server.xml中haMode参数配置,如下配置:
<property name="haState">master</property>!-- 计算节点高可用模式下的主备角色配置,主计算节点配置为:master,备计算节点配置为:backup(集群模式下,此项无效) -->
<property name="haNodeHost"></property><!-- 计算节点高可用模式下需配置当前主计算节点管理端口连接信息;集群模式下,需配置所有成员的集群通信端口连接信息,且集群模式下,只有当集群内所有计算节点在同一网段且集群端口相同时,可以不配置该参数,否则必须配置所有成员的集群通信信息。例:192.168.220.1:3326,192.168.200.1:3327,192.168.200.1:3328 -->
参数作用:
haState与haNodeHost属于配套参数。
当计算节点为高可用模式时,haState为主节点(master)角色,haNodeHost配置为空;haState为备节点(backup)角色,haNodeHost可配置为对端当前主计算节点管理端连接信息,即IP:PORT,此处PORT为管理端口;当backup角色的计算节点被keepalived触发启动(online)时,会主动往haNodeHost上的原master服务发送offline命令以尽可能减少多活场景的出现。例如192.168.200.51:3325与192.168.200.52:3325属于计算节点高可用的环境,该组参数是用户使用计算节点高可用关系的关键配置,主计算节点haState角色为master, 备计算节点haState角色为backup , 并且haNodeHost需要指定配置与之关联的主服务的IP和管理端口。
当计算节点为多节点集群模式时,haState无实际意义,但haNodeHost需要注意:只有当集群内所有计算节点在同一网段且集群端口相同时,可以不配置该参数(此时需要正确配置clusterNetwork参数),否则必须配置所有成员的集群通信信息。例如:192.168.220.1:3326,192.168.200.1:3327,192.168.200.1:3328属于多计算节点,需要指定配置该集群的所有计算节点的IP和通信端口。
单计算节点服务可忽略该参数。
高可用模式主节点示例:
<property name="haState">master</property><!-- 计算节点高可用模式下的主备角色配置,主计算节点配置为:master,备计算节点配置为:backup(集群模式下,此项无效) -->
<property name="haNodeHost"/><!-- 当前主计算节点节点连接信息,IP:PORT (主备模式下使用,PORT表示管理端口,例:192.168.200.2:3325)-->
高可用模式备节点示例:
<property name="haState">backup</property><!-- 计算节点高可用模式下的主备角色配置,主计算节点配置为:master,备计算节点配置为:backup(集群模式下,此项无效) -->
<property name="haNodeHost"/>192.168.200.51:3325<!-- HA角色,其他节点IP:PORT (主备模式下使用,PORT表示管理端口,例:192.168.200.2:3325)-->
集群模式实例:
<property name="haState">backup</property><!-- 集群模式下,此项无实际意义-->
<property name="haNodeHost"/>192.168.220.1:3326,192.168.220.1:3327,192.168.200.1:3328<! 集群模式下,若集群所有成员在同一网段且集群端口相同时,可以不配置该参数,否则必须配置所有成员的连接信息,IP:PORT 逗号间隔,此处PORT为监听端口-->
highCostSqlConcurrency
参数说明:
| Property | Value |
|---|---|
| 参数值 | highCostSqlConcurrency |
| 是否可见 | 否 |
| 参数说明 | 高消耗语句的并发数 |
| 默认值 | 32 |
| 最小值 | 1 |
| 最大值 | 2048 |
| Reload是否生效 | Y |
参数作用:
此参数为计算节点过载保护相关参数,用于控制高消耗语句的并发数(包括跨库join、union、update/delete…limit等),当前端执行并发数超过设置时,相关连接会被hold住,等待前面执行完后,才能执行下一批。
Show processlist中的flow control为lock状态,等待下一批执行。
可从管理端口中查看当前剩余可用的并发数。
+-----+----------------------+----------------------+----------+---------+------+--------------+-----------------------------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+-----+----------------------+----------------------+----------+---------+------+--------------+-----------------------------------------------------------------------+
| 150 | _HotDB_Cluster_USER_| 192.168.210.31:51428 | TEST_LGG | Query | 0 | Sending data | select a.*,b.x from customer_auto_1 a join customer_auto_2 on ...省略 |
| 126 | _HotDB_Cluster_USER_| 192.168.210.31:51412 | TEST_LGG | Query | 0 | Flow control | select a.*,b.x from customer_auto_1 a join customer_auto_2 on ...省略 |
| 222 | _HotDB_Cluster_USER_| 192.168.210.32:16636 | TEST_LGG | Query | 0 | optimizing | select a.*,b.x from customer_auto_1 a join customer_auto_2 on ...省略 |
| 174 | _HotDB_Cluster_USER_| 192.168.210.32:16604 | TEST_LGG | Query | 0 | Sending data | select a.*,b.x from customer_auto_1 a join customer_auto_2 on ...省略 |
| 129 | _HotDB_Cluster_USER_| 192.168.210.31:51414 | TEST_LGG | Query | 0 | Flow control | select a.*,b.x from customer_auto_1 a join customer_auto_2 on ...省略 |
...省略更多...mysql> show @@debug;
+------------+------------+
| join_limit | committing |
+------------+------------+
| 32 | 0 |
+------------+------------+
1 row in set (0.00 sec)
highCostSqlThreshold
参数说明:
| Property | Value |
|---|---|
| 参数值 | highCostSqlThreshold |
| 是否可见 | 是 |
| 参数说明 | 触发高内存消耗SQL流控的缓存行数阈值 |
| 默认值 | 100000 |
| 最小值 | 0 |
| 最大值 | 100000000 |
| Reload是否生效 | 是 |
参数设置:
<property name="highCostSqlThreshold">0</property><!-- 触发高内存消耗SQL流控的缓存行数阈值,默认100000, 0为不触发流控(Threshold of cached lines that trigger flow control of high memory cost SQL. The default value is 100000, and 0 means that all queries will not trigger flow control) -->
参数作用:
触发高内存消耗SQL流控的缓存行数阈值,当SQL消耗的缓存行数超过该值,将会触发流控。默认100000,0表示不触发流控。
holdCommitTimeout
参数说明:
| Property | Value |
|---|---|
| 参数值 | holdCommitTimeout |
| 是否可见 | 否 |
| 参数说明 | Hold Commit操作超时(秒) |
| 默认值 | 60 |
| 最小值 | 5 |
| 最大值 | 300 |
| Reload是否生效 | 是 |
参数设置:
<property name="holdCommitTimeout">5</property><!-- Hold Commit操作超时(秒)(Timeout(second) for hold commit command) -->
参数作用:
管理端执行hold commit命令,执行时间超过参数设置的时间时会报错。 设置计算节点与存储节点的网络延迟为7000ms,设置该参数的超时时间为5秒。手动开启一个事务,执行commit时,在管理端执行 hold commit命令,命令执行超过5秒超时失败


相关文章:
hhdb数据库介绍(9-24)
计算节点参数说明 failoverAutoresetslave 参数说明: PropertyValue参数值failoverAutoresetslave是否可见是参数说明故障切换时,是否自动重置主从复制关系默认值falseReload是否生效否 参数设置: <property name"failoverAutor…...

HDMI数据传输三种使用场景
视频和音频的传输 在HDMI传输音频中有3种方式进行传输,第一种将音频和视频信号被嵌入到同一数据流中,通过一个TMDS(Transition Minimized Differential Signaling)通道传输。第二种ARC。第三张种eARC。这三种音频的传输在HDMI线中…...

unigui 登陆界面
新建项目,因为我的Main页面做了其他的东西,所以我在这里新建一个form File -> New -> From(Unigui) -> 登录窗体 添加组件:FDConnection,FDQuery,DataSource,Unipanel和几个uniedit,…...

无人机 PX4飞控 | CUAV 7-Nano 飞行控制器介绍与使用
无人机 PX4飞控 | CUAV 7-Nano 飞行控制器介绍与使用 7-Nano简介硬件参数接口定义模块连接供电部分遥控器电机 固件安装 7-Nano简介 7-Nano是一款针对小型化无人系统设备研发的微型自动驾驶仪。它由雷迅创新自主研发和生产,其创新性的采用叠层设计,在极…...

安装spark
spark依赖java和scale。所以先安装java,再安装scale,再是spark。 总体教程跟着这个链接 我跟着这个教程走安装java链接,但是有一些不同,原教程有一些错误,在环境变量设置的地方。 java 首先下载jdk。 先看自己的环境…...

佛山三水戴尔R740服务器黄灯故障处理
1:佛山三水某某大型商场用户反馈一台DELL PowerEdge R740服务器近期出现了黄灯警告故障,需要冠峰工程师协助检查故障灯原因。 2:工程师协助该用户通过笔记本网线直连到服务器尾部的IDRAC管理端口,默认ip 192.168.0.120 密码一般在…...

大学课程项目中的记忆深刻 Bug —— 一次意外的数组越界
开头 在编程的世界里,每一行代码都像是一个小小的宇宙,承载着开发者的心血与智慧。然而,即便是最精心编写的代码,也难免会遇到那些突如其来的 bug,它们就像是潜伏在暗处的小怪兽,时不时跳出来捣乱。 在我…...

html数据类型
数据类型是字面含义,表示各种数据的类型。在任何语言中都存在数据类型,因为数据是各式各样。 1.数值类型 number let a 1; let num 1.1; // 整数小数都是数字值 // 数字肯定有个范围 正无穷大和负无穷大 // Infinity 正无穷大 // -Infinity 负…...

Kotlin Multiplatform 未来将采用基于 JetBrains Fleet 定制的独立 IDE
近期 Jetbrains 可以说是动作不断,我们刚介绍了 IntelliJ IDEA 2024.3 K2 模式发布了稳定版支持 ,而在官方最近刚调整过的 Kotlin Multiplatform Roadmap 优先关键事项里,可以看到其中就包含了「独立的 Kotlin Multiplatform IDE,…...
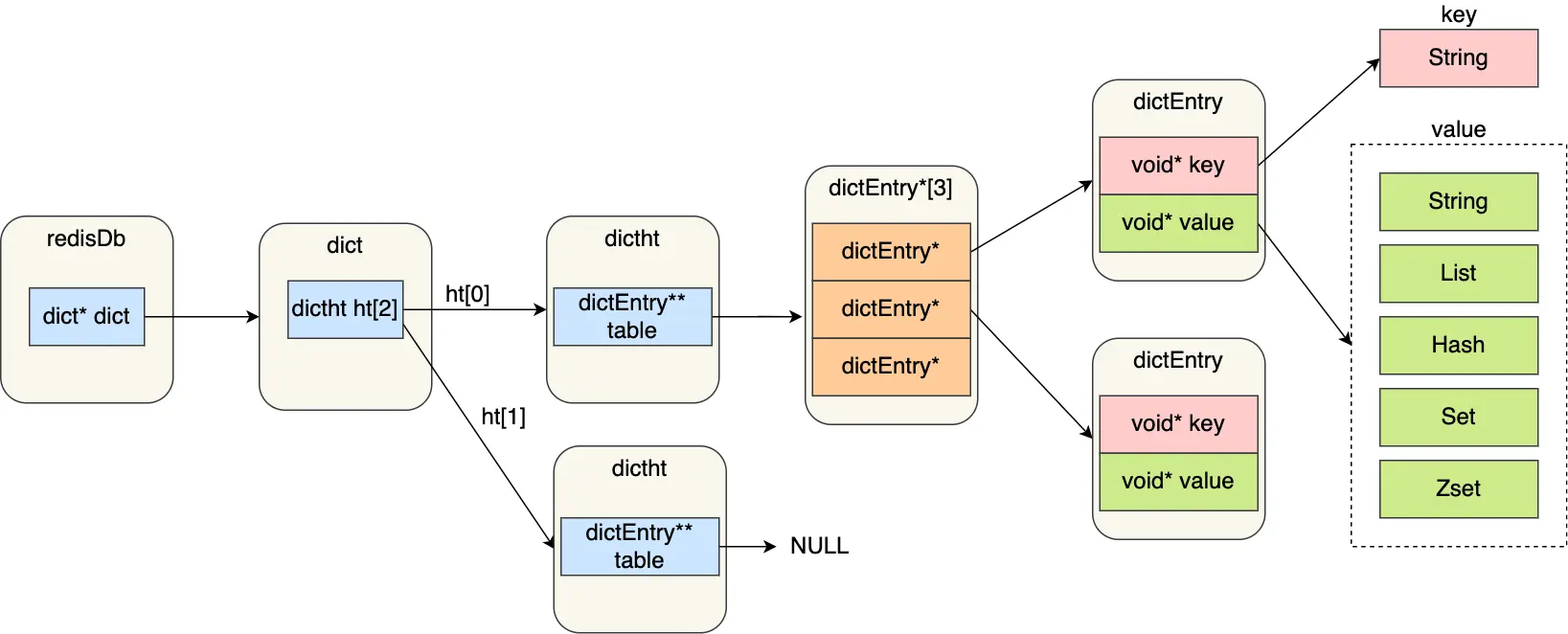
Redis中常见的数据类型及其应用场景
五种常见数据类型 Redis中的数据类型指的是 value存储的数据类型,key都是以String类型存储的,value根据场景需要,可以以String、List等类型进行存储。 各数据类型介绍: Redis数据类型对应的底层数据结构 String 类型的应用场景 常…...

代理IP在后端开发中的应用与后端工程师的角色
目录 引言 代理IP的基本概念和工作原理 代理IP在后端开发中的应用 网络爬虫与数据采集 负载均衡与性能优化 安全防护与隐私保护 后端工程师在使用代理IP时面临的挑战 结论 引言 在数字化时代,网络技术的飞速发展极大地推动了各行各业的发展。其中ÿ…...

工作流和流程引擎有什么区别?
在企业的数字化转型中,如何提升效率、优化业务流程是每个管理者都在思考的问题。而在这个过程中,工作流(Workflow)和流程引擎(Process Engine)这两个术语频频出现,成为企业流程自动化和智能化的…...

【SpringBoot】27 拦截器
Gitee仓库 https://gitee.com/Lin_DH/system 介绍 拦截器:拦截器是 Spring 框架提供的核心功能之一,主要用来拦截用户请求,在指定方法前后,根据业务需要执行预先设定的代码。 拦截器允许开发人员提前预定义一些逻辑,…...

AI对开发者的影响,以及传统软件开发 与 AI参与的软件开发区别
AI 大模型,尤其是像 GPT-4、BERT 这样的语言模型,正以深远的影响改变着软件开发流程。传统的软件开发流程通常依赖开发人员进行代码编写、测试、调试等工作,但随着 AI 技术的进步,AI 可以承担越来越多的任务,自动化和优…...

HBase Java基础操作
Apache HBase 是一个开源的、分布式的、可扩展的大数据存储系统,它基于 Google 的 Bigtable 模型。使用 Java 操作 HBase 通常需要借助 HBase 提供的 Java API。以下是一个基本的示例,展示了如何在 Java 中连接到 HBase 并执行一些基本的操作,…...

关于一次开源java spring快速开发平台项目RuoYi部署的记录
关于一次开源java spring快速开发平台项目RuoYi部署的记录 本次因为需要一些练习环境,想要快速搭建一个javaweb 项目作为练习环境,经过查询和实验找到一个文档详细,搭建简单,架构也相对比较新的开源项目RuoYi。 项目介绍…...

【AI编程实战】安装Cursor并3分钟实现Chrome插件(保姆级)
Cursor介绍 https://www.cursor.com/ 一句话介绍:AI代码编辑器,当前最火的AI编程器 软件下载与安装 下载 打开Cursor官网下载,会根据操作系统的差别进行选择 https://www.cursor.com/ 这里下载的内容很小,是个安装器&#x…...

【Chatgpt】如何通过分层Prompt生成更加细致的图文内容
如何通过分层Prompt生成更加细致的图文内容 利用ChatGPT和类似的生成式AI模型,通过分层Prompt设计可以生成更具层次感和细节的图文内容。分层Prompt的核心在于将需求分解成多层次的指令,从宏观到微观逐步细化,最终形成高质量的内容输出。 一…...

中间件--laravel进阶篇
laravel版本11.31,这中间件只有3种,分别是全局中间件,路由中间件,控制器中间件。相比thinkphp8,少了一个应用中间件。 一、创建中间件 laravel创建中间件可以使用命令的方式创建,非常方便。比如php artisan make:middleware EnsureTokenIsValid。EnsureTokenIsValid是中间…...

【vue】vue中.sync修饰符如何使用--详细代码对比
.sync修饰符作用 .sync修饰符是一个语法糖,可以简化父子组件通信操作,当子组件想改变父组件数值时,父组件只需要使用.sync修饰符,子组件使用props接收属性,再使用this.$emit(update:属性, 值);就可以实现子组件更新父…...

3步实现电脑风扇智能控制:FanControl.HWInfo插件终极指南
3步实现电脑风扇智能控制:FanControl.HWInfo插件终极指南 【免费下载链接】FanControl.HWInfo FanControl plugin to import HWInfo sensors. 项目地址: https://gitcode.com/gh_mirrors/fa/FanControl.HWInfo 还在为电脑风扇的噪音烦恼吗?或者担…...
)
Vit工程化应用(timm 库)
pip install timm import timm import torch from PIL import Image import requests from io import BytesIO# 1. 加载模型 (ViT Base版本,16x16图块,在ImageNet-1k上预训练) # 设置 pretrainedTrue 自动下载权重 model timm.create_model(vit_base_pa…...

对比直接使用厂商API,Taotoken在路由容灾上的体验差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API,Taotoken在路由容灾上的体验差异 1. 引言:服务稳定性的现实挑战 在将大模型能力集成…...

网盘直链下载助手:解锁九大网盘下载速度的终极方案
网盘直链下载助手:解锁九大网盘下载速度的终极方案 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

FastAPI项目实战:从零构建现代化Python Web API的完整指南
1. 从零到一:一个完整的 FastAPI 项目实战复盘最近在社区里看到一个挺有意思的葡萄牙语开源教程项目,叫“FastAPI do Zero”。虽然页面是葡萄牙语,但技术栈和路径对我们来说再熟悉不过了:FastAPI、Pydantic、SQLAlchemy、Alembic&…...
)
别再折腾Windows了!用Mac或Linux搞定ACM LaTeX模板的字体难题(附保姆级配置流程)
跨平台LaTeX写作:为什么macOS和Linux是ACM模板的最佳选择 第一次接触ACM LaTeX模板的研究人员,往往会在字体兼容性问题上耗费大量时间——特别是Windows用户。当你反复尝试安装Libertine字体、解决各种编译错误时,是否想过问题可能出在操作系…...

从图文到视频:用 Python 打造公众号文章自动化转视频号的爆款流水线
摘要:本文详解一套完全基于开源工具(Python + edge-tts + ffmpeg)的自动化系统,可将任意微信公众号文章一键转换为横屏/竖屏视频,直接用于视频号分发。全程无需剪辑软件、无需出镜、无需复杂配置,5 分钟部署,1 条命令生成专业级视频。 🔥 为什么你需要这个? 在 AIGC…...

Claude Code与Cursor CLI集成:AI辅助编程工作流优化实践
1. 项目概述:Claude Code与Cursor CLI的桥梁如果你和我一样,日常开发中同时使用Claude Code和Cursor,并且对Composer 2的执行速度印象深刻,那么你很可能也面临过这样的困境:Claude Code在规划、分析和代码审查方面表现…...

从云原生到边原生:AI营销一体机如何重构企业的“数字孪生”基础设施?
摘要: 随着大模型参数量的激增,传统的“端-管-云”架构在处理高频营销任务时遭遇了带宽与延迟的瓶颈。本文将探讨“边原生(Edge-Native)”架构的崛起,并以卡特加特AI营销一体机为例,解析如何利用本地化超…...

如何快速掌握SRWE:Windows窗口分辨率自定义完整教程
如何快速掌握SRWE:Windows窗口分辨率自定义完整教程 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾遇到过游戏窗口大小不合适、截图分辨率不够高,或者想要为特定应用程序设置独…...