Elasticsearch 中的热点以及如何使用 AutoOps 解决它们
作者:来自 Elastic Sachin Frayne

探索 Elasticsearch 中的热点以及如何使用 AutoOps 解决它。
Elasticsearch 集群中出现热点的方式有很多种。有些我们可以控制,比如吵闹的邻居,有些我们控制得较差,比如 Elasticsearch 中的分片分配算法。好消息是,新的 desire_balance cluster.routing.allocation.type 算法(参见 shards-rebalancing-heuristics)在确定集群中的哪些节点应该获得新分片方面要好得多。如果存在不平衡,它会为我们找出最佳平衡。坏消息是,较旧的 Elasticsearch 集群仍在使用平衡(balanced)分配算法,该算法的计算能力较有限,在选择节点时容易出错,从而导致集群不平衡或出现热点。
在这篇博客中,我们将探讨这种旧算法,它应该如何工作以及何时不起作用,以及我们可以做些什么来解决这个问题。然后,我们将介绍新算法以及它如何解决这个问题,最后,我们将研究如何使用 AutoOps 来针对客户用例突出显示这个问题。然而,我们不会深入探讨热点的所有原因,也不会深入探讨所有具体的解决方案,因为它们太多了。
什么是 AutoOps?
平衡分配
在 Elasticsearch 8.5 及更早版本中,我们使用以下方法来确定在哪个节点放置分片,此方法主要归结为选择分片数量最少的节点:https://github.com/elastic/elasticsearch/blob/8.5/server/src/main/java/org/elasticsearch/cluster/routing/allocation/allocator/BalancedShardsAllocator.java#L242
float weight(Balancer balancer, ModelNode node, String index) {final float weightShard = node.numShards() - balancer.avgShardsPerNode();final float weightIndex = node.numShards(index) - balancer.avgShardsPerNode(index);return theta0 * weightShard + theta1 * weightIndex;
}- node.numShards():分配给集群中特定节点的分片数量
- balancer.avgShardsPerNode():集群中所有节点的分片平均值
- node.numShards(index):分配给集群中特定节点的特定索引的分片数量
- balancer.avgShardsPerNode(index):集群中所有节点的特定索引的分片平均值
- theta0:(cluster.routing.allocation.balance.shard) 分片总数的权重因子,默认为 0.45f,增加该值会增加均衡每个节点分片数量的趋势(请参阅 Shard balancing heuristics settings)
- theta1:(cluster.routing.allocation.balance.index) 每个索引分片总数的权重因子,默认为 0.55f,增加该值会增加均衡每个索引分片数量的趋势每个节点(请参阅 Shard balancing heuristics settings)
该算法在整个集群中的目标值是以这样的方式选择一个节点,使得集群中所有节点的权重回到 0 或最接近 0。
示例
让我们探讨这样一种情况:我们有 2 个节点,其中 1 个索引由 3 个主分片组成,并且假设我们在节点 1 上有 1 个分片,在节点 2 上有 2 个分片。当我们向具有 1 个分片的集群添加新索引时会发生什么?

由于新索引在集群中的其他任何地方都没有分片,因此 weightIndex 项减少到 0,我们可以在下一个计算中看到,将分片添加到节点 1 将使余额回到 0,因此我们选择节点 1。

现在让我们添加另一个包含 2 个分片的索引,由于现在已达到平衡,因此第一个分片将随机分配到其中一个节点。假设节点 1 被选为第一个分片,则第二个分片将分配到节点 2。

新的平衡最终将是:

如果集群中的所有索引/分片在采集、搜索和存储要求方面都执行大致相同的工作量,则此算法将很好地发挥作用。实际上,大多数 Elasticsearch 用例并不这么简单,并且分片之间的负载并不总是相同的,请想象以下场景。

- 索引 1,小型搜索用例,包含几千个文档,分片数量不正确;
- 索引 2,索引非常大,但未被主动写入且偶尔搜索;
- 索引 3,轻量级索引和搜索;
- 索引 4,重度摄取应用程序日志。
假设我们有 3 个节点和 4 个索引,它们只有主分片,并且故意处于不平衡状态。为了直观地了解正在发生的事情,我根据分片的繁忙程度以及繁忙的含义(写入、读取、CPU、RAM 或存储)夸大了分片的大小。即使节点 3 已经拥有最繁忙的索引,新的分片也会路由到该节点。索引生命周期管理 (ILM) 不会为我们解决这种情况,当索引滚动时,新的分片将放置在节点 3 上。我们可以手动缓解这个问题,强制 Elasticsearch 使用集群重新(cluster reroute)路由均匀分布分片,但这无法扩展,因为我们的分布式系统应该处理这个问题。尽管如此,如果没有任何重新平衡或其他干预措施,这种情况将继续存在,并可能变得更糟。此外,虽然这个例子是假的,但这种分布在具有混合用例(即搜索、日志记录、安全)的旧 Elasticsearch 集群中是不可避免的,尤其是当一个或多个用例是重度摄取时,确定何时会发生这种情况并不是一件容易的事。
虽然预测这个问题的时间范围很复杂,但在某些情况下行之有效的一个好的解决方案是保持所有索引的分片密度相同,这是通过在所有索引的分片达到预定大小(以 GB 为单位)时滚动所有索引来实现的(请参阅分片大小 - size your shards)。这并不适用于所有用例,正如我们将在下面 AutoOps 捕获的集群中看到的那样。
所期望的平衡分配
为了解决这个问题和其他一些问题,一种可以同时考虑写入负载和磁盘使用情况的新算法最初在 8.6 中发布,并在 8.7 和 8.8 版本中进行了一些微小但有意义的更改:https://github.com/elastic/elasticsearch/blob/8.8/server/src/main/java/org/elasticsearch/cluster/routing/allocation/allocator/BalancedShardsAllocator.java#L305
float weight(Balancer balancer, ModelNode node, String index) {final float weightShard = node.numShards() - balancer.avgShardsPerNode();final float weightIndex = node.numShards(index) - balancer.avgShardsPerNode(index);final float ingestLoad = (float) (node.writeLoad() - balancer.avgWriteLoadPerNode());final float diskUsage = (float) (node.diskUsageInBytes() - balancer.avgDiskUsageInBytesPerNode());return theta0 * weightShard + theta1 * weightIndex + theta2 * ingestLoad + theta3 * diskUsage;
}- node.writeLoad():特定节点的写入或索引负载
- balancer.avgWriteLoadPerNode():整个集群的平均写入负载
- node.diskUsageInBytes():特定节点的磁盘使用情况
- balancer.avgDiskUsageInBytesPerNode():整个集群的平均磁盘使用情况
- theta2:(cluster.routing.allocation.balance.write_load)写入负载的权重因子,默认为 10.0f,增加该值会增加均衡每个节点的写入负载的趋势(请参阅 Shard balancing heuristics settings)
- theta3:(cluster.routing.allocation.balance.disk_usage)磁盘使用情况的权重因子,默认为 2e-11f,增加该值会增加均衡每个节点的磁盘使用情况的趋势(请参阅 Shard balancing heuristics settings)
我不会在本博客中详细介绍此算法所做的计算,但是 Elasticsearch 用于决定分片应位于何处的数据可通过 API 获取:获取所需平衡(Get desired balance)。在调整分片大小时,遵循我们的指导仍然是最佳实践,并且仍然有充分的理由将用例分离到专用的 Elasticsearch 集群中。然而,此算法在平衡 Elasticsearch 方面要好得多,以至于它为我们的客户解决了以下平衡问题。(如果你遇到本博客中描述的问题,我建议你升级到 8.8)。
最后要注意的是,此算法没有考虑搜索负载,这很难衡量,甚至更难预测。6.1 中引入的自适应副本选择(Adaptive replica selection)对解决搜索负载大有帮助。在未来的博客中,我们将深入探讨搜索性能的主题,特别是如何使用 AutoOps 在搜索性能问题发生之前发现它们。
在 AutoOps 中检测热点
上述情况不仅难以预测,而且一旦发生也难以检测,我们需要对 Elasticsearch 有深入的内部了解,并且我们的集群需要满足非常具体的条件才能处于这种状态。
现在,使用 AutoOps 检测这个问题就轻而易举了。让我们看一个真实的例子;
在这个设置中,Elasticsearch 前面有一个排队机制,用于处理数据峰值,但是用例是近实时日志 - 持续的滞后是不可接受的。我们遇到了持续滞后的情况,必须进行故障排除。从集群视图开始,我们获取了一些有用的信息,在下图中我们了解到有 3 个主节点、8 个数据节点(以及 3 个与案例无关的其他节点)。我们还了解到集群是红色的(这可能是网络或性能问题),版本是 8.5.1,有 6355 个分片;最后这两个将在以后变得重要。

这个集群中发生了很多事情,它经常变成红色,这些都与离开集群的节点有关。节点离开集群的时间大约在我们观察到索引拒绝的时间,并且拒绝发生在索引队列过于频繁地填满后不久,黄色越深,时间块中的高索引事件越多。

转到节点视图并关注最后一个节点断开连接的时间范围,我们可以看到另一个节点(节点 9)的索引率比其他节点高得多,其次是节点 4,该节点在本月早些时候曾出现过一些断开连接的情况。你还会注意到,在同一时间范围内索引率下降幅度相当大,这实际上也与此特定集群中计算资源和存储之间的间歇性延迟有关。

默认情况下,AutoOps 只会报告断开连接时间超过 300 秒的节点,但我们知道包括节点 9 在内的其他节点经常离开集群,如下图所示,节点上的分片数量增长太快,无法移动分片,因此在节点断开连接/重新启动后,它们必须重新初始化。有了这些信息,我们可以放心地得出结论,集群正在经历性能问题,但不仅仅是热点性能问题。由于 Elasticsearch 以集群的形式工作,它只能以最慢的节点的速度运行,而且由于节点 9 被要求比其他节点做更多的工作,它无法跟上,其他节点总是在等待它,偶尔也会断开连接。

此时我们不需要更多信息,但为了进一步说明 AutoOps 的强大功能,下面是另一张图像,该图像显示了节点 9 比其他节点执行了多少工作,特别是它写入磁盘的数据量。

我们决定将所有分片从节点 9 移出,方法是将它们随机发送到集群中的其他节点;这是通过以下命令实现的。此后,整个集群的索引性能得到改善,延迟消失。
PUT /_cluster/settings
{"transient": {"cluster.routing.allocation.exclude._name": "****-data-9"}
}现在我们已经观察、确认并解决了该问题,我们需要找到一个长期的解决方案,这又让我们回到了博客开头的技术分析。我们遵循最佳实践,分片以预定的大小滚动,甚至限制每个节点特定索引的分片数量。我们遇到了算法无法处理的边缘情况,即索引繁重且频繁滚动的索引。
我们考虑过是否可以手动重新平衡集群,但对于由 6355 个分片组成的约 2000 个索引,这并非易事,更不用说,在这种级别的索引下,我们将与 ILM 竞争重新平衡。这正是新算法的设计目的,因此我们的最终建议是升级集群。
最后的想法
本博客总结了一组相当具体但复杂的情况,这些情况可能会导致 Elasticsearch 性能出现问题。你今天甚至可能会在集群中看到其中一些问题,但可能永远不会像这个用户那样严重地影响集群。这个案例强调了跟上 Elasticsearch 最新版本的重要性,以便始终利用最新的创新来更好地管理数据,它有助于展示 AutoOps 在发现/诊断问题并提醒我们注意问题方面的强大功能,以免它们成为全面生产事件。
考虑迁移到至少 8.8 版 https://www.elastic.co/guide/en/elasticsearch/reference/8.8/migrating-8.8.html
Elasticsearch 包含许多新功能,可帮助你为你的用例构建最佳搜索解决方案。深入了解我们的示例笔记本以了解更多信息,开始免费云试用,或立即在你的本地机器上试用 Elastic。
原文:Hotspots in Elasticsearch and how to resolve them with AutoOps - Search Labs
相关文章:
Elasticsearch 中的热点以及如何使用 AutoOps 解决它们
作者:来自 Elastic Sachin Frayne 探索 Elasticsearch 中的热点以及如何使用 AutoOps 解决它。 Elasticsearch 集群中出现热点的方式有很多种。有些我们可以控制,比如吵闹的邻居,有些我们控制得较差,比如 Elasticsearch 中的分片分…...

springboot基于微信小程序的食堂预约点餐系统
摘 要 基于微信小程序的食堂预约点餐系统是一种服务于学校和企事业单位食堂的智能化解决方案,旨在提高食堂就餐的效率、缓解排队压力,并优化用户的就餐体验。系统作为一种现代化的解决方案,为食堂管理和用户就餐提供了便捷高效的途径。它不仅…...

字符串学习篇-java
API:应用程序编程接口。 ctrlaltv,自动生成一个变量接收数据 字符串: 注意点 创建string对象两种方式 1.直接赋值 2.构造器来创建 详情看黑马JAVA入门学习笔记7-CSDN博客 常用方法:比较 引用数据类型,比较的是地址值。 b…...

2024亚太杯数学建模C题【Development Analyses and Strategies for Pet Industry 】思路详解
C:宠物行业及相关产业的发展分析与战略 随着人们消费观念的发展,宠物行业作为一个新兴产业,正在全球范围内逐渐积聚势头,这得益于快速的经济发展和人均收入的提高。1992年,中国小动物保护协会成立,随后1993…...

STM32串口——5个串口的使用方法
参考文档 STM32串口——5个串口的使用方法_51CTO博客_stm32串口通信的接收与发送 串口是我们常用的一个数据传输接口,STM32F103系列单片机共有5个串口,其中1-3是通用同步/异步串行接口USART(Universal Synchronous/Asynchronous Receiver/Transmitter)…...

NVR接入录像回放平台EasyCVR视频融合平台加油站监控应用场景与实际功能
在现代社会中,加油站作为重要的能源供应点,面临着安全监管与风险管理的双重挑战。为应对这些问题,安防监控平台EasyCVR推出了一套全面的加油站监控方案。该方案结合了智能分析网关V4的先进识别技术和EasyCVR视频监控平台的强大监控功能&#…...

Ubuntu24.04安装gpfs客户端
文章目录 Ubuntu24.04安装gpfs客户端拷贝软件包在客户端执行命令,提取产品包进入安装包目录,安装相关产品包编译。编译过程中会检查系统依赖接入集群(后续) Ubuntu24.04安装gpfs客户端 拷贝软件包 scp /root/Spectrum_Scale_Dat…...

Android Framework层介绍
文章目录 前言一、Android Framework 层概述二、主要组件1. 应用程序接口(API)2. 系统服务3. Binder4. 资源管理5. Content Provider6. 广播接收器(BroadcastReceiver)7. 服务(Service) 三、与 Linux Kerne…...

如何利用 Puppeteer 的 Evaluate 函数操作网页数据
介绍 在现代的爬虫技术中,Puppeteer 因其强大的功能和灵活性而备受青睐。Puppeteer 是一个用于控制 Chromium 或 Chrome 浏览器的 Node.js 库,提供了丰富的 API 接口,能够帮助开发者高效地处理动态网页数据。本文将重点讲解 Puppeteer 的 ev…...

SpringMVC接收请求参数
(5)请求参数》五种普通参数 1.普通参数 代码块 RequestMapping("/commonParam") ResponseBody public String commonParam(String name,int age){System.out.println("普通参数传递 name > "name);System.out.println("普通…...

安宝特方案 | AR助力紧急救援,科技守卫生命每一刻!
在生死时速的紧急救援战场上,每一秒都至关重要!随着科技的发展,增强现实(AR)技术正在逐步渗透到医疗健康领域,改变着传统的医疗服务模式。 安宝特AR远程协助解决方案,凭借其先进的技术支持和创新…...

蓝桥杯每日真题 - 第18天
题目:(出差) 题目描述(13届 C&C B组E题) 解题思路: 问题分析 问题实质是一个带权图的最短路径问题,但路径的权重包含两个部分: 从当前城市到下一个城市的路程时间。 当前城市的…...

HTTP 协议应用场景
一、HTTP 协议简介 HTTP(Hypertext Transfer Protocol)即超文本传输协议,是用于分布式、协作式和超媒体信息系统的应用层协议,是互联网数据通信的基础。它采用客户端 - 服务器(Client-Server)的通信模式&am…...

【Linux庖丁解牛】—Linux基本指令(下)!
目录 1、grep指令 2、zip/unzip指令 3、sz/rz指令 4、tar指令 编辑 5、scp指令 6、bc指令 7、uname –r指令 8、重要的几个热键 9、关机 10、完结撒花 1、grep指令 grep是文本过滤器,其作用是在指定的文件中过滤出包含你指定字符串的内容,…...

python: generator model using sql server 2019
設計或生成好數據庫,可以生成自己設計好的框架項目 # encoding: utf-8 # 版权所有 :2024 ©涂聚文有限公司 # 许可信息查看 :言語成了邀功盡責的功臣,還需要行爲每日來值班嗎 # 描述: : 生成实体 # Author …...

Kafka怎么发送JAVA对象并在消费者端解析出JAVA对象--示例
1、在pom.xml中加入依赖 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-stream-kafka</artifactId><version>3.1.6</version></dependency> 2、配置application.yml 加入Kafk…...
)
深度学习(1)
一、torch的安装 基于直接设备情况,选择合适的torch版本,有显卡的建议安装GPU版本,可以通过nvidia-smi命令来查看显卡驱动的版本,在官网中根据cuda版本,选择合适的版本号,下面是安装示例代码 GPUÿ…...
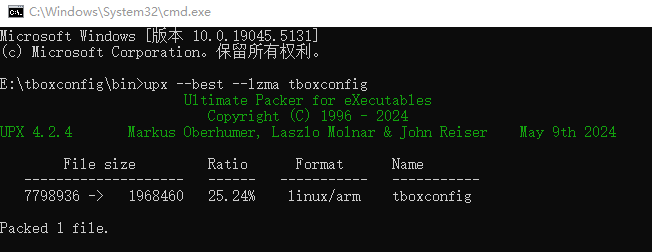
golang 嵌入式armv7l压缩编译打包
编译 Go 应用程序 go build -ldflags"-s -w" -o myapp.exe . 使用 UPX 压缩可执行文件(window下载并设置环境变量) upx --best --lzma myapp.exe 可从10M压缩到1M 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 …...

Makefile 之 join
join $(join <list1>,<list2> ) 名称:连接函数——join。 功能:把<list2>中的单词对应地加到<list1>的单词后面。如果<list1>的单词个数要比<list2>的多, 那么,<list1>中的多出…...

集合卡尔曼滤波(Ensemble Kalman Filter),用于二维滤波(模拟平面上的目标跟踪),MATLAB代码
集合卡尔曼滤波(Ensemble Kalman Filter) 文章目录 引言理论基础卡尔曼滤波集合卡尔曼滤波初始化预测步骤更新步骤卡尔曼增益更新集合 MATLAB 实现运行结果3. 应用领域结论 引言 集合卡尔曼滤波(Ensemble Kalman Filter, EnKF)是…...

python文化旅游服务系统 小程序系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述核心功能技术栈项目亮点应用场景项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->->进我个人主页-->获取博主联系方式同行可拿货,招校园代理 ,本人源头供货商 项目概述 Python文化旅游服…...

暗黑破坏神2存档编辑器完整指南:三步轻松修改D2/D2R角色与装备
暗黑破坏神2存档编辑器完整指南:三步轻松修改D2/D2R角色与装备 【免费下载链接】d2s-editor 项目地址: https://gitcode.com/gh_mirrors/d2/d2s-editor 你是否厌倦了在暗黑破坏神2中反复刷装备却一无所获?是否因为早期加点失误导致角色后期无法应…...

CANN/pypto copysign函数API文档
# pypto.copysign 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A…...

UE5 GAS中安全修改Attribute值的四种正确方式
1. 这不是简单的“赋值操作”,而是GAS系统中一次精准的属性干预在UE5的Gameplay Ability System(GAS)架构下,修改一个Attribute的值——比如让角色的生命值从100变成120,或者让法力值在施法后扣减30点——表面看只是调…...

Cardboard XR Plugin实战指南:轻量级Android VR落地方案
1. 这不是“加个插件就能跑”的VR接入——为什么Cardboard XR Plugin在2024年仍值得认真对待 很多人看到“Unity Cardboard Android VR”第一反应是:这不早淘汰了吗?毕竟Google早在2019年就停止了Cardboard官方支持,2021年彻底下架了Cardbo…...

我希望项目能像lisp那样只有少量而又足够的关键字,不希望后面再添加关键字,那样太繁琐了。 后面可以使用函数、宏等方式增加更多的功能和函数
补充一点设计需求,我希望项目能像lisp那样只有少量而又足够的关键字,不希望后面再添加关键字,那样太繁琐了。 后面可以使用函数、宏等方式增加更多的功能和函数关键在于将语法结构本身作为核心,而非定义大量特殊的关键字。这可…...

FSearch技术深度解析:如何用C语言和GTK3实现毫秒级文件搜索
FSearch技术深度解析:如何用C语言和GTK3实现毫秒级文件搜索 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 在Linux生态系统中,文件搜索一直是…...

Windows热键冲突终结者:Hotkey Detective一键定位占用程序
Windows热键冲突终结者:Hotkey Detective一键定位占用程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...

LABVIEW生成EXE
遇到的问题报错说找不到这个路径的某个VI原因在于之前手动改过文件夹名称,导致路径有变更。更关键的是有的VI还沿用以前旧的路径,因此报错。解决办法就是打开可能用到这个功能的VI,选定新路径。报错是因为要打包的vi里面不是所有的vi都能够正…...
)
跨境商城反向海淘系统开发全流程逻辑(上)
「技术、数据、接口、系统问题欢迎留言私信沟通」跨境商城开发不同于普通国内商城,核心逻辑是“合规适配功能闭环多场景兼容”,不仅要实现商品展示、下单支付等基础功能,更要兼顾不同国家的法律法规、文化差异、支付物流适配等核心痛点。本文…...