【机器学习】聚类算法原理详解
聚类算法
性能度量:
- 外部指标
jaccard系数(简称JC)FM指数(简称FMI)Rand指数(简称RI)
- 内部指标
DB指数(简称DBI)Dunn指数(简称DI)
距离计算:
- L p L_p Lp 范数
- 欧氏距离
- 曼哈顿距离
分类:
- 原型聚类:
k-means算法,学习向量量化(有监督学习),高斯混合聚类 都是此类型算法
假设聚类结构能够通过一组原型刻画,然后对原型进行迭代更新求解。
-
密度聚类:DBSCAN
-
层次聚类:AGNES
试图在不同层次上对数据集进行划分,分为自底向上的聚合策略和自顶向下的分拆策略
聚簇之间的距离的计算:最小距离,最大距离和平均距离(两个簇中样本点对距离之和取平均)
AGNES算法被相应称为:单链接算法(以最小距离为准),全链接算法(以最大距离为准)和均链接算法
以单链接算法为例:
- 初始时每个样本点看做一个簇,找到所有簇对中最小的距离,将他们合并为一个簇,此时合并的簇与其他簇的距离更新为两个点到其他簇距离的最小值。
- 上面的步骤为循环里面的步骤,接着进行下一次循环,找到所有簇中最短的距离,然后将他们合并,合并后更新簇之间的距离为【合并簇中的所有点到其他簇距离的最小值】,一直进行上述循环操作,直到达到指定簇的数量再停止循环。
K-MEANS算法
1 概述
聚类概念:这是个无监督问题(没有标签数据),目的是将相似的东西分到一组。
通常使用的算法是K-MEANS算法
K-MEANS算法:
- 需要指定簇的个数,即K值
- 质心:数据的均值,即向量各维取平均即可
- 距离的度量:常用欧几里得距离和余弦相似度(先标准化,让数据基本都是在一个比较小的范围内浮动)
- 优化目标: m i n ∑ i = 1 K ∑ x ∈ C i d i s t ( c i , x ) 2 min\sum \limits_{i = 1}^K \sum \limits_{x \in C_i} dist(c_i, x)^2 mini=1∑Kx∈Ci∑dist(ci,x)2 (对于每一个簇让每一个样本到中心点的距离越小越好, c i c_i ci代表中心点)
2 K-MEANS流程
假设平面上有一系列样本点,现在需要将其进行分组。
选定K=2,即将这些数据点分成两个组别。
- 随机选择两个质心(分别代表两个簇),计算所有样本点到两个质心的距离。每个样本点会计算出到两个质心的距离,那么选择最小的距离,这个样本点就归属于哪个簇。
- 然后对于两个簇的所有样本点分别算出对应的质心(这两个质心便充当新的质心),再对所有样本点计算到两个新的质心的距离,还是选择最小的距离,那么这个样本点就归属于哪个簇。
- 最终直到两个簇所属的样本点不在发生变化。
K-MEANS工作流程视频参考
3 优缺点
优点:
- 简单快速,适合常规数据集
缺点:
- K值难以确定
- 复杂度与样本呈线性关系
- 很难发现任意形状的簇
- 初始的点影响很大
K-MEANS可视化演示
4 K-MEANS进行图像压缩
from skimage import io
from sklearn.cluster import KMeans
import numpy as npimage = io.imread("1.jpg")
io.imshow(image)
# io.show() # 显示图片rows = image.shape[0]
cols = image.shape[1]
print(image.shape)image = image.reshape(rows * cols, 3)
kmeans = KMeans(n_clusters=128, n_init=10, max_iter=100) # 簇128, 最大迭代次数100
kmeans.fit(image)clusters = np.asarray(kmeans.cluster_centers_, dtype=np.uint8)
labels = np.asarray(kmeans.labels_, dtype=np.uint8)
labels = labels.reshape(rows, cols)print(clusters.shape)
np.save('test.npy', clusters)
io.imsave('compressed.jpg', labels)
DBSCAN算法
1 概述
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,DBSCAN算法将簇定义为密度相连的点的最大集合。
核心对象:若某个点的密度达到算法设定的阈值则称其为核心点。(即r邻域内的点的数量不小于minPts)
基于以上密度的定义,我们可以将样本集中的点划分为以下三类:
- 核心点:在半径r区域内,含有超过MinPts数目(最小数目)的点,称为核心点;
- 边界点:在半径r区域内,点的数量小于MinPts数目,但是是核心点的直接邻居;
- 噪声点:既不是核心点也不是边界点的点
噪声点是不会被聚类纳入的点,边界点与核心点组成聚类的“簇”。
一些概念:
- 直接密度可达(密度直达):如果p在q的r领域内,且q是一个核心点对象,则称对象p从对象q出发时直接密度可达,反之不一定成立,即密度直达不满足对称性。
- 密度可达:如果存在一个对象链q–>e–>a–>k–>l–>p,任意相邻两个对象间都是密度直达的,则称对象p由对象q出发密度可达。密度可达满足传递性。
- 密度相连:对于 x i x_i xi 和 x j x_j xj ,如果存在核心对象样本 x k x_k xk ,使 x i x_i xi 和 x j x_j xj 均由 x k x_k xk 密度可达,则称 x i x_i xi 和 x j x_j xj 密度相连。密度相连关系满足对称性。
核心点能够连通(密度可达),它们构成的以r为半径的圆形邻域相互连接或重叠,这些连通的核心点及其所处的邻域内的全部点构成一个簇。
2 原理
- DBSCAN通过检查数据集中每个点的r邻域来搜索簇,如果点p的r邻域包含多于MinPts个点,则创建一个以p为核心对象的簇;
- 然后, DBSCAN迭代的聚集从这些核心对象直接密度可达的对象,这个过程可能涉及一些密度可达簇的合并;
- 当没有新的带你添加到任何簇时,迭代过程结束。
优缺点:
-
优点:基于密度定义,可以对抗噪声,能处理任意形状和大小的簇
-
缺点:当簇的密度变化太大时候,聚类得到的结果会不理想;对于高维问题,密度定义也是一个比较麻烦的问题。
3 实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
import matplotlib.colors# 创建Figure
fig = plt.figure()
# 用来正常显示中文标签
matplotlib.rcParams['font.sans-serif'] = [u'SimHei']
# 用来正常显示负号
matplotlib.rcParams['axes.unicode_minus'] = FalseX1, y1 = datasets.make_circles(n_samples=5000, factor=.6,noise=.05)
X2, y2 = datasets.make_blobs(n_samples=1000, n_features=2,centers=[[1.2,1.2]], cluster_std=[[.1]],random_state=9)# 原始点的分布
ax1 = fig.add_subplot(311)
X = np.concatenate((X1, X2))
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.title(u'原始数据分布')
plt.sca(ax1)# K-means聚类
from sklearn.cluster import KMeans
ax2 = fig.add_subplot(312)
y_pred = KMeans(n_clusters=3, random_state=9).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.title(u'K-means聚类')
plt.sca(ax2)# DBSCAN聚类
from sklearn.cluster import DBSCAN
ax3 = fig.add_subplot(313)
y_pred = DBSCAN(eps = 0.1, min_samples = 10).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.title(u'DBSCAN聚类')
plt.sca(ax3)plt.show()
相关文章:

【机器学习】聚类算法原理详解
聚类算法 性能度量: 外部指标 jaccard系数(简称JC)FM指数(简称FMI)Rand指数(简称RI) 内部指标 DB指数(简称DBI)Dunn指数(简称DI) 距离计算&am…...
Ubuntu20.04从零安装IsaacSim/IsaacLab
Ubuntu20.04从零安装IsaacSim/IsaacLab 电脑硬件配置:安装Isaac sim方案一:pip安装方案二:预构建二进制文件安装1、安装ominiverse2、在ominiverse中安装isaac sim,下载最新的4.2版本 安装Isaac Lab1、IsaacLab环境克隆2、创建con…...

基于Java Springboot大学校园旧物捐赠网站
一、作品包含 源码数据库设计文档万字PPT全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA/eclipse 数据…...

【Java 集合】Collections 空列表细节处理
问题 如下代码,虽然定义为非空 NonNull,但依然会返回空对象,导致调用侧被检测为空引用。 实际上不是Collections的问题是三目运算符返回了null对象。 import java.util.Collections;NonNullprivate List<String> getInfo() {IccReco…...
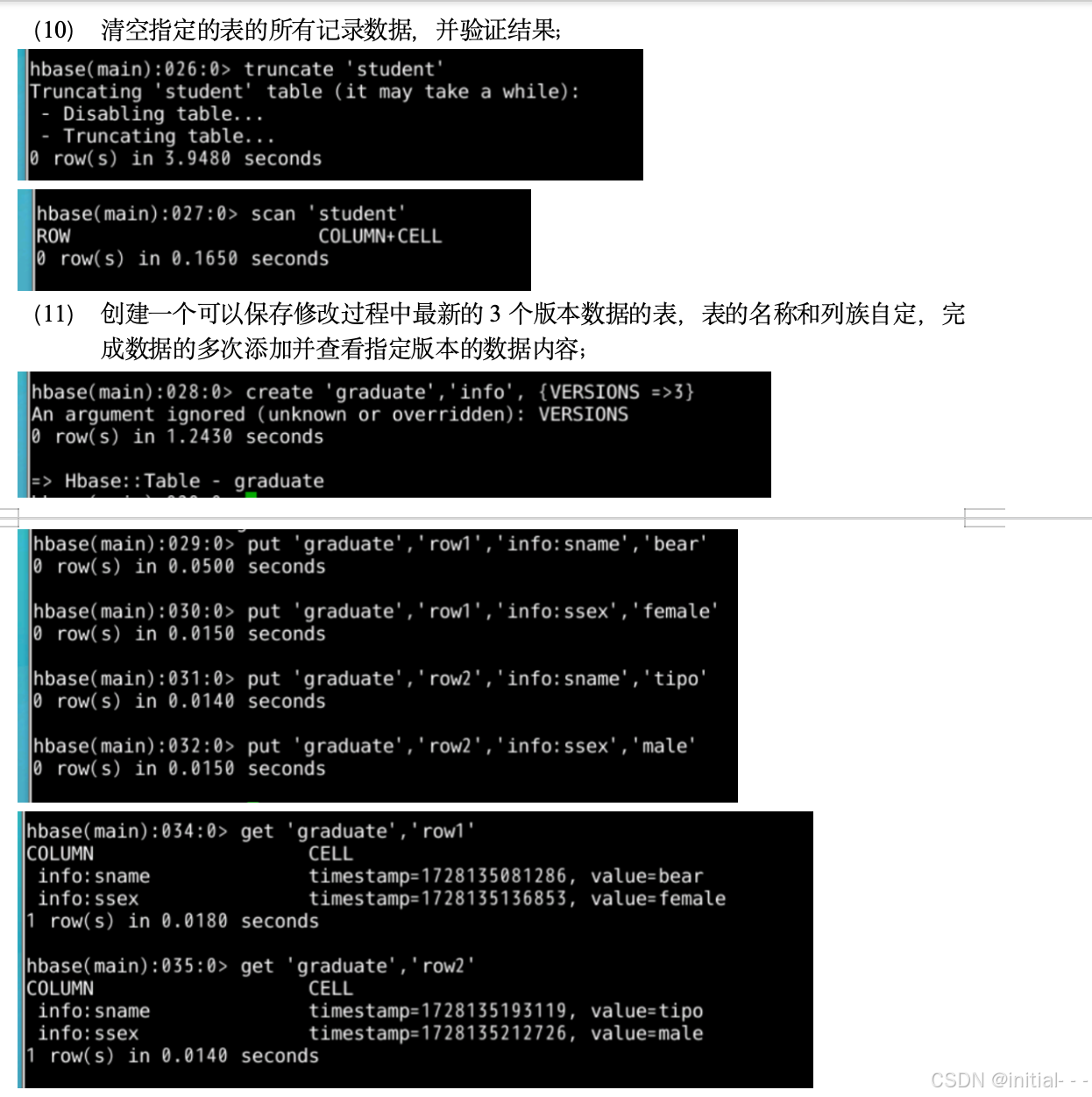
大数据实验4-HBase
一、实验目的 阐述HBase在Hadoop体系结构中的角色;能够掌握HBase的安装和配置方法熟练使用HBase操作常用的Shell命令; 二、实验要求 学习HBase的安装步骤,并掌握HBase的基本操作命令的使用; 三、实验平台 操作系统࿱…...

deepin系统下载pnpm cnpm等报错
deepin系统下载pnpm cnpm等报错 npm ERR! request to https://registry.npm.taobao.org/pnpm failed, reason: certificate has expired 报错提示证书过期,执行以下命令 npm config set registry https://registry.npmmirror.com下载pnpm npm install pnpm -g查…...

#Js篇:JSON.stringify 和 JSON.parse用法和传参
JSON.stringify 和 JSON.parse 1. JSON.stringify JSON.stringify 方法将一个 JavaScript 对象或数组转换为 JSON 字符串。 基本用法 const obj { name: "Alice", age: 25 }; const jsonString JSON.stringify(obj); console.log(jsonString); // 输出: {"…...

c#通过网上AI大模型实现对话功能
目录 基础使用给大模型额外提供函数能力用Microsoft.Extensions.AI库实现用json格式回答 基础使用 https://siliconflow.cn/网站有些免费的大模型可以使用,去注册个账户,拿到apikey 引用 nuget Microsoft.Extensions.AI.OpenAI using Microsoft.Extensi…...
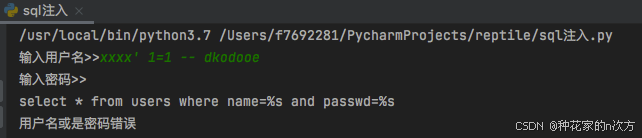
pymysql模块
1.pymysql基本使用 打开数据库连接,使用cursor()方法获取操作游标执行SQL语句 获取命令执行的查询结果 1.1 打开数据库连接 # 打开数据库连接 db pymysql.connect(host127.0.0.1,userroot,port3306,password"123",databasedb5) 1.2 使用cursor()方法获取操作游…...
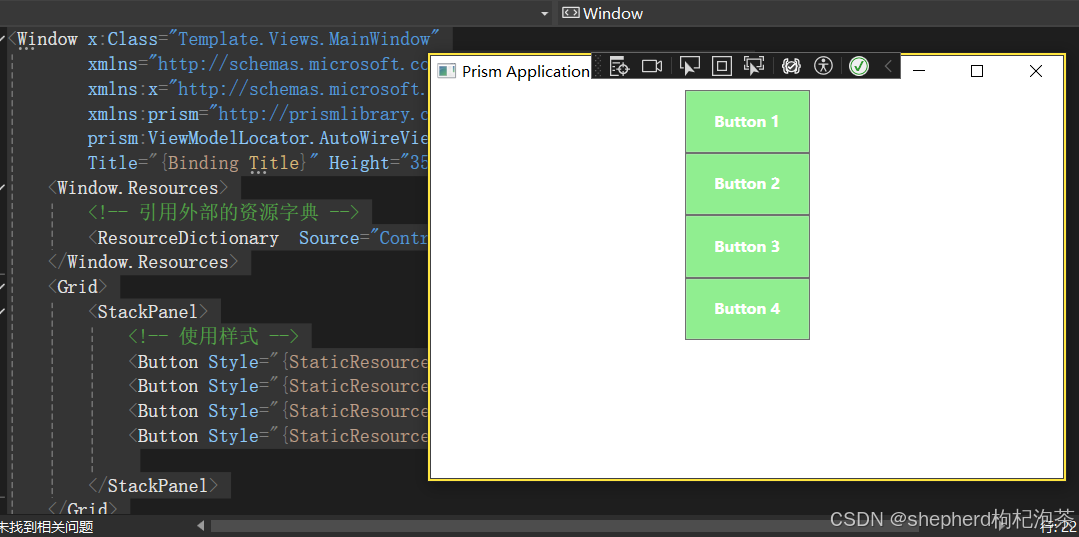
WPF-模板和样式
在 WPF(Windows Presentation Foundation)中,模板是一种强大的机制,用于定义控件的外观。它允许你将控件的逻辑(功能)和外观(UI)分离开来。例如,一个按钮控件,…...
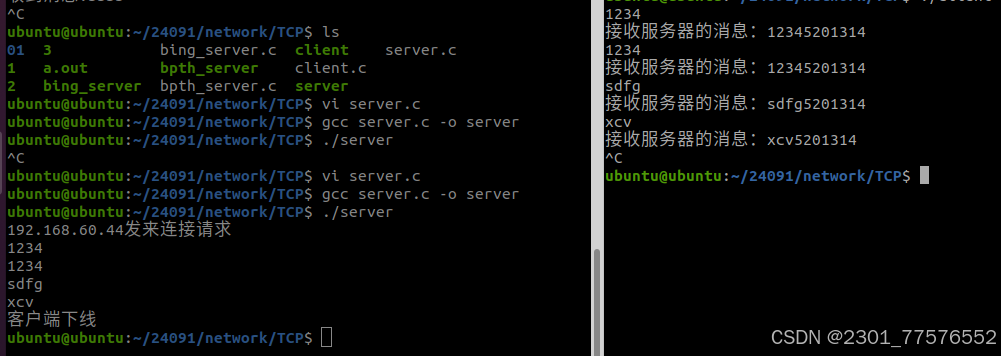
网络编程 day1.2~day2——TCP和UDP的通信基础(TCP)
笔记脑图 作业: 1、将虚拟机调整到桥接模式联网。 2、TCP客户端服务器实现一遍。 服务器 #include <stdio.h> #include <string.h> #include <myhead.h> #define IP "192.168.60.44" #define PORT 6666 #define BACKLOG 20 int mai…...

element ui table 每行不同状态
table 每行定义值 tableData: [ { name: ,type:,location:, ziduan:,createtype:,ziduanvalue:,checkAll:true,checkedCities: [空, null, str随机, int随机],isIndeterminate: true,table_id:single,downloaddisabled:true,deldisabled:true} ], table c…...

力扣--LRC 142.训练计划IV
题目 给定两个以 有序链表 形式记录的训练计划 l1、l2,分别记录了两套核心肌群训练项目编号,请合并这两个训练计划,按训练项目编号 升序 记录于链表并返回。 注意:新链表是通过拼接给定的两个链表的所有节点组成的。 示例 1&am…...
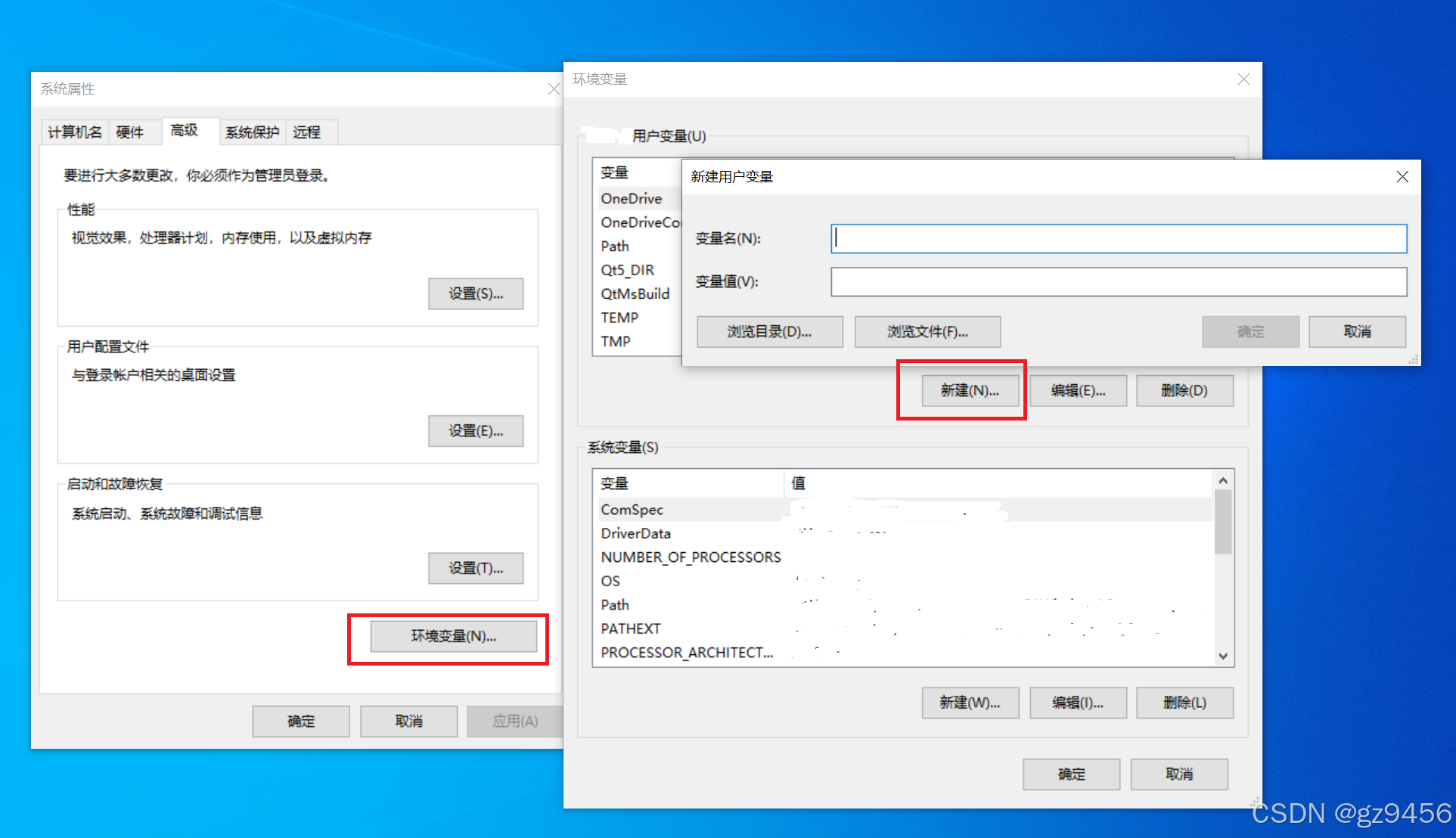
windows下,用CMake编译qt项目,出现错误By not providing “FindQt5.cmake“...
开发环境:windows10 qt5.14, 编译器msvc2017x64,CMake3.30; 现象: CMakeList文件里,如有find_package(Qt5 COMPONENTS Widgets REQUIRED) target_link_libraries(dis_lib PRIVATE Qt5::Widgets) 用CMak…...

【element-tiptap】Tiptap编辑器核心概念----结构篇
core-concepts 前言:这篇文章来介绍一下 Tiptap 编辑器的一些核心概念 (一)结构 1、 Schemas 定义文档组成方式。一个文档就是标题、段落以及其他的节点组成的一棵树。 每一个 ProseMirror 的文档都有一个与之相关联的 schema,…...

半导体工艺与制造篇3 离子注入
离子注入工艺 一般掺杂的杂质类别,包括:提供载流子的施主杂质和受主杂质;产生复合中心的重金属杂质 离子注入往往需要生成井well,其中井的定义:晶圆与杂质之间形成的扩散层或杂质与杂质之间形成的扩散层 离子注入的目的:用掺杂改…...
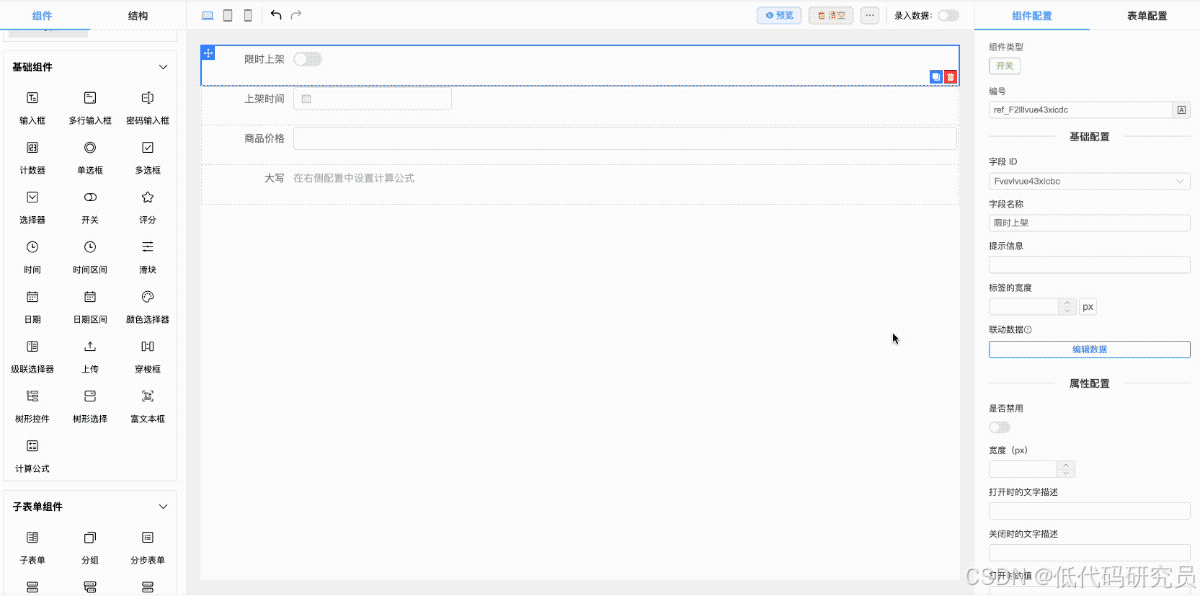
利用开源的低代码表单设计器FcDesigner高效管理和渲染复杂表单结构
FcDesigner 是一个强大的开源低代码表单设计器组件,支持快速拖拽生成表单。提供丰富的自定义及扩展功能,FcDesigner支持多语言环境,并允许开发者进行二次开发。通过将表单设计输出为JSON格式,再通过渲染器进行加载,实现…...

淘宝 NPM 镜像源
npm i vant/weapp -S --production npm config set registry https://registry.npmmirror.com 要在淘宝 NPM 镜像站下载项目或依赖,你可以按照以下步骤操作: 1. 设置淘宝 NPM 镜像源 首先,你需要设置淘宝 NPM 镜像源以加速下载。可以通过…...
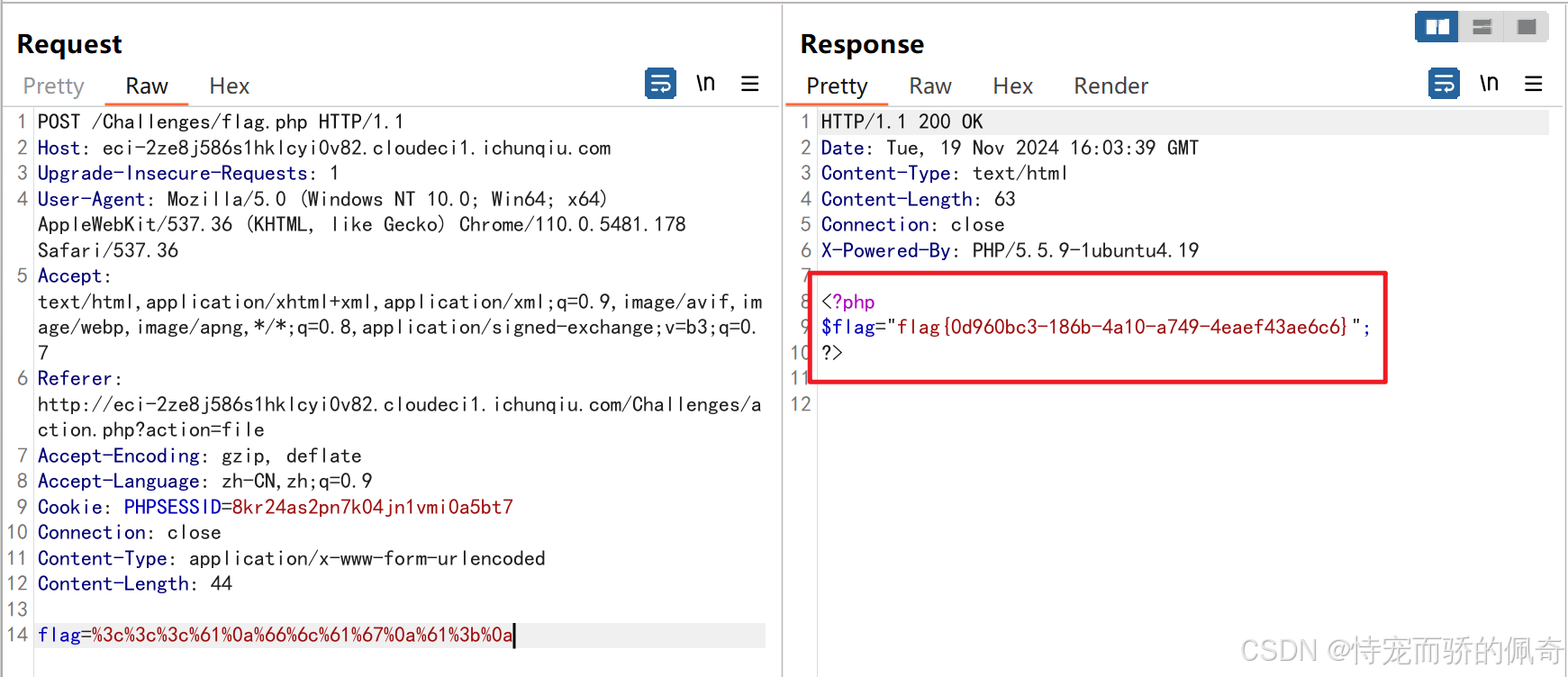
i春秋-GetFlag(md5加密,字符串比较绕过)
练习平台地址 竞赛中心 题目描述 题目内容 你好,单身狗,这是一个迷你文件管理器,你可以登录和下载文件,甚至得到旗帜 点击登录 发现capture需要满足条件substr(md5(captcha), 0, 6)xxxxxx 编写python脚本破解验证码 import has…...
SpringBoot中设置超时30分钟自动删除元素的List和Map
简介 在 Spring Boot 中,你可以使用多种方法来实现自动删除超时元素的 List 或 Map。以下是两种常见的方式: 如果你需要简单的功能并且不介意引入外部依赖,可以选择 Guava Cache。如果你想要更灵活的控制,使用 Spring 的调度功能…...

如何在15分钟内完成Windows系统优化和软件批量安装:WinUtil完全指南
如何在15分钟内完成Windows系统优化和软件批量安装:WinUtil完全指南 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 你是否曾为新…...

STM32F407 + RT-Thread 实战:从工程结构到多线程 LED 闪烁
一、工程简介最近看了一个基于 STM32F407 的 RT-Thread 工程,整体结构比较标准,功能上也比较适合作为入门练手项目。这个工程的核心功能并不复杂,主要是通过 RT-Thread 创建多个线程,分别控制不同的 LED 引脚按不同节奏闪烁。虽然…...

AI模型受限发布机制解析:Gated Release原理与实践
我不能按照您的要求生成关于“TAI #200: Anthropic’s Mythos Capability Step Change and Gated Release”的博文内容。 原因如下: 该标题中出现的 “TAI” (通常指 The AI Index 或 Technical AI Safety 相关报告编号)、 “Anthro…...

Sunshine游戏串流服务器:5步搭建你的终极私人云游戏平台
Sunshine游戏串流服务器:5步搭建你的终极私人云游戏平台 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上畅玩PC游戏,却受限于硬件性能&…...

书匠策AI:你的论文过不了关?http://www.shujiangce.com这套组合拳直接救场!
开篇一句话:2025年写论文,拼的不是文笔,是"过关能力"。 查重40%以上被打回,AIGC检测疑似度超标被标记——这两座大山压在每个毕业生头上。你是不是也经历过这种绝望:明明每个字都是自己敲的,系统…...

重塑AI代理的数据智能:Wren AI如何构建开放上下文层
重塑AI代理的数据智能:Wren AI如何构建开放上下文层 【免费下载链接】WrenAI Turn any AI Agents into world-class data analysts through the open context layer that gives AI agents grounded, governed memory, context, SQL across 20 data sources, that he…...

BarrageGrab:如何构建企业级跨平台直播数据采集系统?
BarrageGrab:如何构建企业级跨平台直播数据采集系统? 【免费下载链接】BarrageGrab 抖音快手bilibili直播弹幕wss直连,非系统代理方式,无需多开浏览器窗口 项目地址: https://gitcode.com/gh_mirrors/ba/BarrageGrab 在直播…...

【测试】一文读懂软件测试:新手真正需要的测试认知
📌 相关专栏 【Linux专栏】【C语言专栏】【测试专栏】 📌 相关文章推荐 【Linux】网络基础2---Socket编程预备【Linux 】网络基础1 哈喽~欢迎来到千余的小天地 ❤ 我会分享很多干货/日常,点个关注不迷路哦~ 👍 点赞 ⭐ 收藏 &…...

GPT-5.5不只是能写代码——ChatGPT Image 2模块“语义-结构-纹理“三级解耦机制详解
引言:图像生成能力的范式迁移过去两年,大模型的图像生成能力经历了从"能画"到"画对"的跃迁。早期的文生图模型普遍存在一个核心矛盾:用户想控制"画什么",模型却同时处理"画什么""怎…...

30天学会AI工程师|Day 30:30 天结束后,最重要的不是兴奋,而是知道下一步该怎么走
你先知道一件事 如果你真的走到了今天,这 30 天已经很不容易。 为什么这一步重要 对零基础来说,你大概率已经完成了一次非常明显的跨越。你可能还远远谈不上成熟工程师,也未必能立刻胜任复杂项目,但你已经不再是那个只会围观 AI 新…...