ElasticSearch学习篇18_《检索技术核心20讲》LevelDB设计思想
目录
一些常见的设计思想以及基于LSM树的LevelDB是如何利用这些设计思想优化存储、检索效率的。
- 几种常见的设计思想
- 索引和数据分离
- 减少磁盘IO
- 读写分离
- 分层思想
- LevelDB的设计思想
- 读写分离设计
- 分层设计与延迟合并
- LRU缓存加速检索
几种常见设计思想
索引与数据分离
索引和数据分离设计理念可以让索引保持简洁和高效,来帮助我们聚焦在索引的优化技术上。
比如对于无法完全加载到内存的数据,进行索引和数据分离之后就可以把索引加载进内存,进行高性能的访问,例如B+树、BKD树就是基于这一设计思想。
如果索引和数据能够完全加载到内存中了,还需要进行索引和和数据分离吗?需要根据实际情况考虑,比如像ES的索引设计,根据关键词创建的倒排索引,存储的是docId,一般在多关键词、条件检索的时候,需要对docId取交集,最终的docId确定之后,然后在根据docId去正排索引找对应的文档数据。若是索引和数据不分离,
- 那么会增加额外的存储开销,不需要在posting list中重复记录文档所有数据。
- 不能减少检索过程的数据复制代价,如果存储不只是docId,每次都需要复制数据,然后单独取出docId进行运算。
- 不能保持索引的简洁高效,比如只存储docId的posting list可以使用位图bitmap进行检索加速,并且压缩存储空间,或者优化的Roaring Bitmap结构,关于Roaring Bitmap参考往期博客:ElasticSearch学习篇12_《检索技术核心20讲》基础篇_elasticsearch位运算-CSDN博客。
若是数据和索引分离,同样会带来些问题,比如数据的不一致,比如数据已经被修改或者删除了,但是索引还没来得及更新,就会有问题,对于这种情况的容忍程度,需要结合具体的业务情况判断,比如一些不重要的场景可以容忍临时性数据不一致,但是对于一些金钱转账的场景,就要求强一致,不能容忍,这时候就得加锁,为了锁的粒度更小,就适合索引和数据不分离。
举例如MySQL的MyISAM就是索引和数据分离的,InnoDB就是聚集索引和数据不分离的,因此InnoDB不需要加全局表锁来保证数据一致性,他只需要支持行级的锁就可以了。
减少磁盘IO
对于数据无法全部存在内存只中的情况,必然会涉及磁盘的读写操作,在这种情况下应该尽可能减少磁盘IO。
一种常见的是将频繁访问的数据加载进内存,比如前面索引和数据分离之后,可以把索引加载进内存,对于内存无法装下的索引,可以使用占用内存较小的数据索引结构,如具有压缩性质的前缀树这类数据结构来压缩索引,前缀树替换跳表、哈希表这种就是以性能换空间思路。最典型的例子就是 lucene 中用 FST(Finite State Transducer,中文:有限状态转换器)来存索引字典。参考:关于Lucene的词典FST深入剖析 - 苍青浪 - 博客园
另外一个就是尽量保证磁盘顺序IO,可以通过预写日志以及利用磁盘的局部性原理来加快随机IO的效率。比如基于LSM树的Hbase、Kafka都是利用这些设计思想。
关于SSD磁盘和内存IO效率仍然会有1-2个数量集的差距,并且SSD的顺序IO效率仍然是快于随机IO的,让我们先来了解一下 SSD 的工作原理。对于 SSD 而言,它以页(Page,一个 Page 为 4K-16K)为读写单位,以块(Block,256 个 Page 为一个 Block)为垃圾回收单位。由于 SSD 不支持原地更新的方式修改一个页,因此当我们写数据到页中时,SSD 需要将原有的页标记为失效,并将原来该页的数据和新写入的数据一起,写入到一个新的页中。那被标记为无效的页,会被垃圾回收机制处理,而垃圾回收又是一个很慢的操作过程。因此,随机写会造成大量的垃圾块,从而导致系统性能下降。所以,对于 SSD 而言,批量顺序写的性能依然会大幅高于随机写。
读写分离
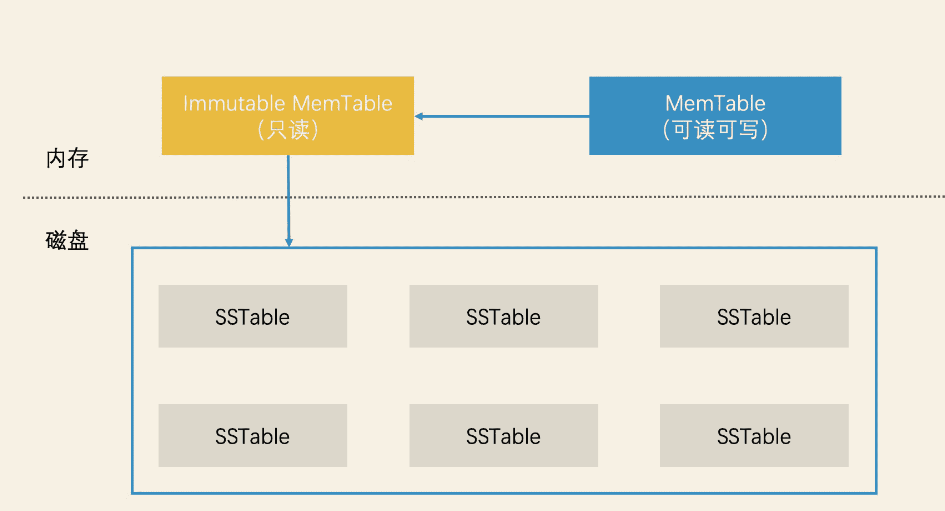
在高并发场景下,为了避免对数据的加锁导致系统性能降低,而读写分离给数据创建一个读副本、写副本,可以避免数据读写不安全。举例MySQL的master-slave结构,主接受写数据,定期同步数据到从,然后请求读从节点数据。包括在LevelDB中,MemTable - Immutable MemTable 的设计,其实也是读写分离的一个具体案例。
分层处理
在大规模检索系统中,不同数据的价值是不一样的,如果都用同样的处理方式可能会造成资源的浪费,因此将数据分层处理是一种思想。
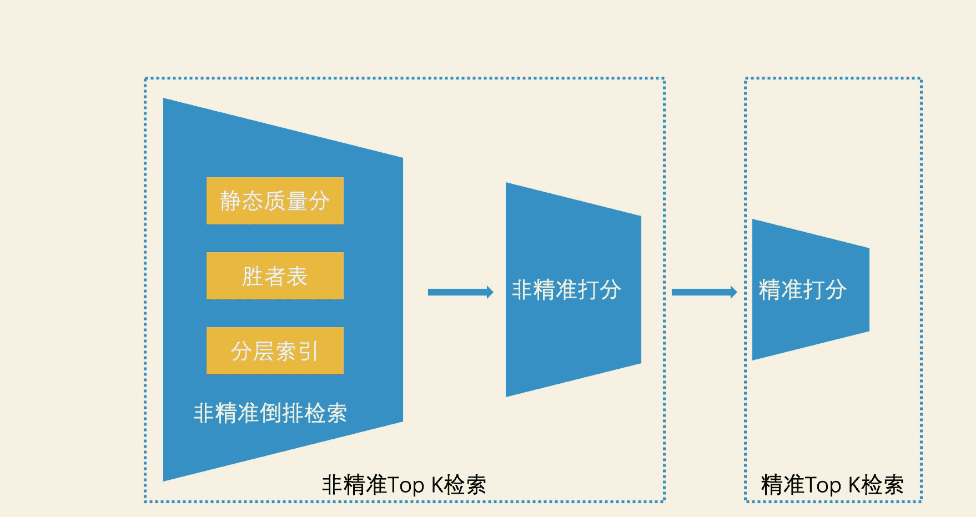
比如非精确TopK的检索结果才进行计算打分,然后作为精确TopK检索结果。比如上面的将索引、数据分离也是一种分层思想,比如LSM树吧最近频繁访问的数据放入内存,然后把其他数据放入磁盘也是分层思想,甚至CPU的一二级缓存同样也是。
LevelDB的设计思想
LevelDB 是基于 LSM 树优化而来的存储系统。关于LSM树可参考往期博客:
ElasticSearch学习篇13_《检索技术核心20讲》进阶篇之LSM树_elasticsearch lsm-CSDN博客。
LSM 树会将索引分为内存和磁盘两部分,并在内存达到阈值时启动树合并。但是,这里面存在着大量的细节问题。比如说
- 数据在内存中如何高效检索?
- 数据是如何高效地从内存转移到磁盘的?
- 以及我们如何在磁盘中对数据进行组织管理?
- 有数据是如何从磁盘中高效地检索出来的?
先大概总结一下
- 首先,在内存中检索数据的环节,LevelDB 使用跳表代替 B+ 树,提高了内存检索效率。
- 其次,在将数据从内存写入磁盘的环节,LevelDB 先是使用了读写分离的设计,增加了一个只读的 Immutable MemTable 结构,避免了给内存索引加锁。
- 然后,LevelDB 又采用了延迟合并设计来优化归并。具体来说就是,它先快速将 C0 树落盘生成 SSTable 文件,再使用其他异步进程对这些 SSTable 文件合并处理。而在管理多个 SSTable 文件的环节,LevelDB 使用分层和滚动合并的设计来组织多个 SSTable 文件,避免了 C0 树和 C1 树的合并带来的大量数据被复制的问题。
- 最后,在磁盘中检索数据的环节,因为 SSTable 文件是有序的,所以我们通过多层二分查找的方式,就能快速定位到需要查询的 SSTable 文件。
- 接着,在 SSTable 文件内查找元素时,LevelDB 先是使用索引与数据分离的设计,减少磁盘 IO,又使用 BloomFilter 和二分查找来完成检索加速。
- 加速检索的过程中,LevelDB 又使用缓存技术,将会被反复读取的数据缓存在内存中,从而避免了磁盘开销。
读写分离设计
对于LSM的内存树C0,LevelDB第一个对LSM的改进就是使用跳表代替B+树,因为跳表对于增删的效率是优于B+树的。
归并时候的内存一致性问题:对于LSM的内存树C0数据满之后,需要合并到磁盘树C1 , 该过程是滚动Rolling Merge(按照分页块一次读取磁盘树的多个连续块数据到清空块,然后把内存和磁盘归并完成数据块写入新的块,待会顺序写入磁盘新位置),若在此过程遇到数据修改,即需要修改内存树C0,如何保证数据的一致性?
避免加锁
对于归并时候的内存数据一致性问题,LevelDB第二个改进就是使用读写分离的设计思想,避免加锁影响数据检索效率,具体的做法就是它将内存中的数据分为两块,一块叫作 MemTable,它是可读可写的。另一块叫作 Immutable MemTable,它是只读的。这两块数据的数据结构完全一样,都是跳表,如何避免加锁保证数据一致性?
- 当MemTable满了之后,把它切换为 Immutable MemTable,接受读请求。
- 另外准备一块新的 New MemTable来接受写请求。
此时Immutable MemTable和磁盘树C1进行归并,因为是只读的,不用在归并期间加锁,另外就是新的修改数据,写入了新的MemTable,读请求的时候会读依次内存中的 新的MemTable 、Immutable MemTabe 以及磁盘中的数据,保证读数据的实效性是最新的。
分层设计与延迟合并
延迟合并
LevelDB对于归并过程的优化,并不是直接在内存中拿着C0和C1进行归并再写入磁盘,因为这样会有一些问题
- 合并代价很高:因为C1树很大,C0树很小,尽管有Rolling Merging,还是会发生大量测磁盘IO
- 合并频率很频繁:因为因为C1树很大,C0树很小,会频繁的进行合并
因此LevelDB采用一种延迟合并的设计,具体来说就是,先将 Immutable MemTable 顺序快速写入磁盘,直接变成一个个 SSTable(Sorted String Table)文件,之后再对这些 SSTable 文件进行合并。这样就避免了 C0 树和 C1 树昂贵的合并代价,进而磁盘树C1就被多个小的SSTable代替了。
延迟合并多个SSTable会带来检索方面的问题,LevelDB使用分层设计思想解决检索效率问题。
分层设计
单个SSTable的数据来自Immutable MemTable,所以单个SSTable内数据的key是有序的,查找的时候可比较高效,但是SSTable之间的数据范围可能是交叉的,因此这样情况下,查找的时候并不能定位出该去哪个SSTable中查找执行的数据,最差的情况需要遍历查找全部的SSTable,磁盘IO开销影响检索效率。
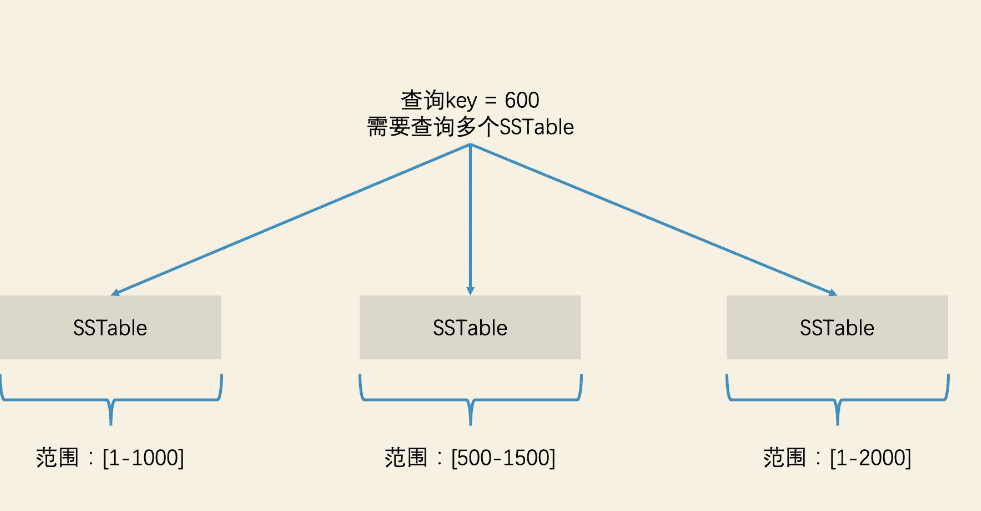
解决的思路就是需要整理SSTable文件数据进行重新划分,让每个SSTable的存储的数据范围不交叉,以便进行如二分等快速检索。
如何保证SSTable存储数据范围不是交叉的?当系统生成超过SSTable的时候,这个时候就要整理,首先计算新的SSTable的数据范围,之后使用多路归并的方式生成新1个或者多个SSTable文件(可能会涉及SSTable数据节点的分裂),并且保证已生成的SSTable之间是排序的,同时LevelDB控制每个SSTable的大小(比如2M),太大的话检索效率也会降低。
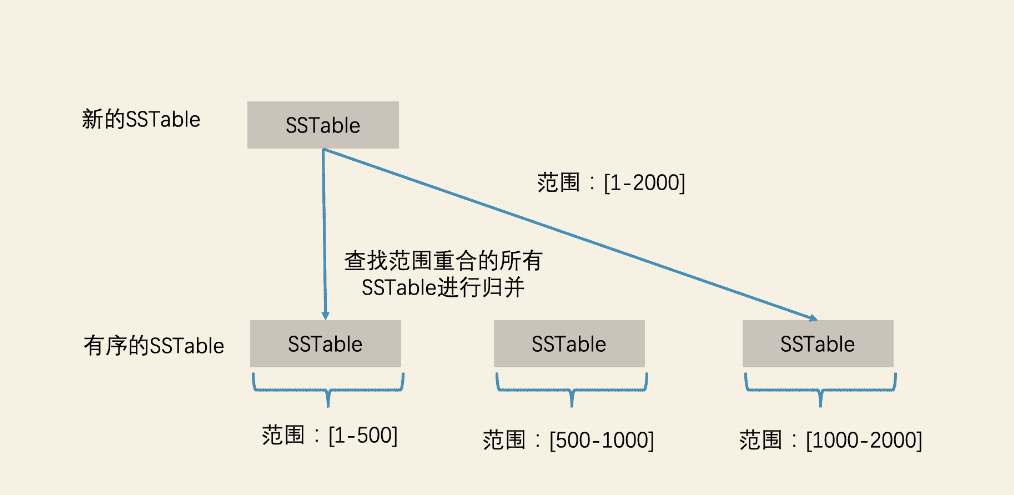
归并的时候,如果SSTable数量太多也会影响效率,最差的就是一个新的SSTable数据范围太广,需要归并到所有已有的SSTable中,LevelDB基于分层思想使用滚动合并来避免大量数据的无效复制,具体的就是将SSTable分层管理,然后逐层合并,这就是LevelDB的分层思想。
为了防止SSTable的数量不断增加,合并策略很关键,主要介绍两种基本策略:size-tiered和leveled
- size-tiered 策略:size-tiered策略保证每层SSTable的大小相近,同时限制每一层SSTable的数量。如上图,每层限制SSTable为N,当每层SSTable达到N后,则触发Compact操作合并这些SSTable,并将合并后的结果写入到下一层成为一个更大的sstable。由此可以看出,当层数达到一定数量时,最底层的单个SSTable的大小会变得非常大。并且size-tiered策略会导致空间放大比较严重**。**即使对于同一层的SSTable,每个key的记录是可能存在多份的,只有当该层的SSTable执行compact操作才会消除这些key的冗余记录。
- leveled策略:限制每一层的SSTable总文件大小。
LevelDB使用的是leveled策略,当从Immutable MemTable 转成的SSTable会被放在Level 0层,Level 0层最多可以放四个SSTable,当level0 层满了之后,需要进行多路归并生成新的多个SSTable,作为level 1层,接下来如果level 0层又来了4个新的SSTable,那么就要和level 1层相关的SSTable进行多路归并合并,如果Level1层的SSTable数量太多,效率就会比较低,因此使用leveled策略,限制level1层的总文件大小(默认为10M)。
当 Level 1 层的 SSTable 文件总容量达到了上限之后,我们就需要选择一个 SSTable 的文件,将它并入下一层(为保证一层中每个 SSTable 文件都有机会并入下一层,我们选择 SSTable 文件的逻辑是轮流选择。也就是说第一次我们选择了文件 A,下一次就选择文件 A 后的一个文件)。下一层会将容量上限翻 10 倍,这样就能容纳更多的 SSTable 了。依此类推,如果下一层也存满了,我们就在该层中选择一个 SSTable,继续并入下一层。这就是 LevelDB 的分层设计了。

尽管限制了每层的文件总容量大小,能保证开销上限,但是随着层数的增加,底层的SSTable会越来越多,合并的时候数量太多有大量磁盘IO,LevelDB通过加入一个限制,就是当新生成第N层的新的SSTable之后,需要判断又再加数据会不会导致范围过广,及时止损,如果判断和N+1层的SSTable范围交叉了10个,那么就不在往这个SSTable加数据,结束这个SSTable的继续生成,继续生成一个新的SSTable,直到所有需要合并的数据都完成合并为止。这种设计可以有效限制每次合并操作需要处理的数据量,避免过度的IO操作,提高性能。
举个例子,假设我们有一个LevelDB数据库,其中:
- 第n层(Level n)有几个SSTable文件,我们称之为A, B, C。
- 第n+1层(Level n+1)有一系列SSTable文件,称之为1, 2, 3, …, 15。
合并的过程如下:
- 开始合并: 我们从第n层选择一个SSTable文件,比如A,尝试与第n+1层的文件进行合并。
- 检查重合覆盖度: 假设在这个过程中,我们发现要合并A和第n+1层文件时,与文件1到文件12都有键区间重合。这时重合覆盖度是12。
- 达到限制: 因为重合覆盖度超过了预设限制10,LevelDB决定不合并与文件12及后续的文件。
- 生成当前SSTable文件: 不继续合并A和第12个及其后续的文件,而是生成一个新的SSTable文件作为合并A和文件1到文件11的结果。
- 继续合并: 由于合并过程被分段处理,接下来LevelDB并没有停下来,而是继续从第n层的剩余数据开始(假如是A中未处理完的部分),尝试进行与第n+1层文件12及后续文件的新的合并。这会创建下一批SSTable文件。
这样,LevelDB在合并过程中通过分段合并和限制单个合并操作的范围,可以有效管理磁盘IO,提高合并效率,避免单次合并处理过多数据导致的性能问题,避免**无限制合并:** 系统试图将第n层的一个大SSTable文件与第n+1层的所有重叠的SSTable文件进行合并。假如在第n+1层有20个SSTable文件,这意味着一次合并可能涉及大量的文件操作。
检索的时候也是分层的,先从多个SSTbale找目标SSTable,
- 首先检索level 0 层的4个SSTable,需要全部遍历
- 接着按照二分检索level1层之后的SSTable,定位到指定SSTable接着查找。
然后在利用SSTable内部索引和数据分离的设计加速检索,下面是SSTable的数据结构
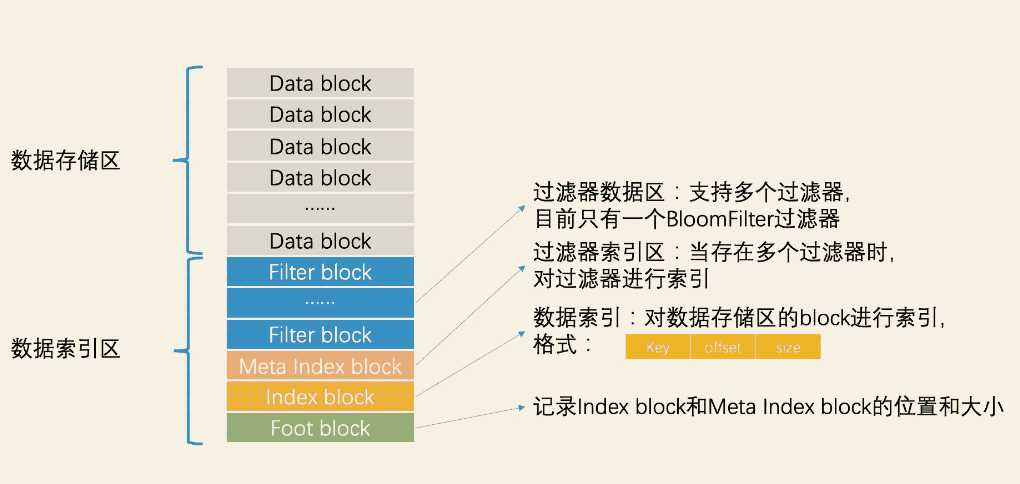
在读取SSTable文件的时候,不需要全部读进内存,只需要读取索引到内存,
- 快速判断元素是否存在当前SSTable:首先根据过滤器索引MetaIndex block读取如BloomFilter过滤器,快速判断元素是否存在。
- 精确查找元素:如果元素存在,根据数据区索引 Index block读取 每个data block 的最小分隔key(便于计算key范围)、起始位置、block的大小(类似Redis的压缩结构ziplist),根据index和data的指针关系,直接二分查找key,然后再去data block数据区取数据。
举个精确查找例子,假设有一个包含多个键值对的SSTable文件,数据分布在多个Data Block中,而Index Block保存了这些Data Block的偏移信息。
- 查找某个键: 假设需要查找键“K123”。
- 加载Index Block: 首先,系统会加载SSTable文件的Index Block到内存中。Index Block中保存了每个Data Block的键范围和偏移位置。
- 二分查找索引: 在Index Block中,通过二分查找快速定位哪个Data Block可能包含键“K123”。假如找到Data Block B,其键范围覆盖了“K123”。
- **加载Data Block:**然后,系统使用Index Block中提供的信息,从磁盘中读取Data Block B到内存中。
- 查找键值对: 在内存中对已加载的Data Block B进行二分查找以找到确切的键“K123”及其对应的值。
性能考量
- 减少磁盘IO: 通过Index Block来减少需要访问的Data Block数量,避免将整个SSTable加载到内存中。
- 提高查找速度: 二分查找加上Index Block的使用能大幅提高查找速度,因为它减少了磁盘访问次数、提高了数据访问的效率。
虽然每次查找都需要加载Index Block和相应的Data Block,这种分段的读取还是比线性扫描整个文件高效得多。此外,常用的索引块可能会被缓存到内存中,某种程度上减少了重复的磁盘读取,从而进一步加快查找速度。
LRU缓存加速检索
上面说SSTable内的精确检索,每次二分的期间会需要将Index Block以及对应的Data Block加载到内存,有时候还可能会导致需要将多个Data block加载到内存,可能会涉及多次IO。
在查询特定键的过程中,通常不需要多次加载多个Data Block到内存,理想情况下只需加载一个Data Block即可。不过,这也取决于数据的分布和访问的具体情况。以下是详细解释:
- 单个Data Block加载:
- 在典型情况下,如果索引块很好地组织和设计,查找某个键时,通过Index Block的二分查找可以确定目标键所处的单个Data Block。
- 然后,从磁盘中加载这个Data Block到内存,进行进一步的查找以获取具体的键值对。
- 多次加载Data Block的情况:
- 在某些情况下,如果数据查询模式导致多个查询在彼此非常接近的位置,并且横跨了多个Data Block,可能会连续加载多个Data Block。例如:
- 如果查找的键正好位于Data Block的边界附近,且索引不够精确,可能需要访问两个Data Block。
- 一次操作需要访问多个连续键(例如范围查询),而这些键跨越了多个Data Block。
优化措施
为了减少多次加载Data Block的需求,系统可能:
- 索引缓存:缓存索引信息,避免每次查找都访问磁盘上的索引块。
- 数据块缓存:使用内存缓存来存储常用的Data Block,减轻磁盘IO。
- 预读取和分片:在可能的情况下,系统可以预先将相邻的块读入内存,以减少后续的磁盘访问。
总的来说,通过合理使用索引和缓存机制,可以有效减少多次加载多个Data Block的需要,优化查找效率并提高系统性能。
因此LevelDB使用LRU缓存来优化减少磁盘IO的次数,针对这两次读磁盘操作,LevelDB 分别设计了 table cache 和 block cache 两个缓存。其中,这两个缓存都使用 LRU 机制进行替换管理。
- block cache 是配置可选的,它是将最近使用的 Data Block 加载在内存中。
- table cache 则是将最近使用的 SSTable 的 Index Block 加载在内存中。
相关文章:
ElasticSearch学习篇18_《检索技术核心20讲》LevelDB设计思想
目录 一些常见的设计思想以及基于LSM树的LevelDB是如何利用这些设计思想优化存储、检索效率的。 几种常见的设计思想 索引和数据分离减少磁盘IO读写分离分层思想 LevelDB的设计思想 读写分离设计分层设计与延迟合并LRU缓存加速检索 几种常见设计思想 索引与数据分离 索引…...

使用 FFmpeg 提取音频的详细指南
FFmpeg 是一个开源的多媒体处理工具,支持视频、音频的编码、解码、转换等多种功能。通过 FFmpeg,提取视频中的音频并保存为各种格式非常简单和高效。这在音视频剪辑、媒体处理、转码等场景中具有广泛的应用。 本文将详细讲解如何使用 FFmpeg 提取音频&a…...

中国省级新质生产力发展指数数据(任宇新版本)2010-2023年
一、测算方式:参考C刊《财经理论与实践》任宇新(2024)老师的研究,新质生产力以劳动者劳动资料劳动对象及其优化组合的质变为 基本内涵,借 鉴 王 珏 和 王 荣 基 的 做 法构建新质生产力发展水平评价指标体系如下所示&a…...
 房屋建造案例)
C++设计模式:建造者模式(Builder) 房屋建造案例
什么是建造者模式? 建造者模式是一种创建型设计模式,它用于一步步地构建一个复杂对象,同时将对象的构建过程与它的表示分离开。简单来说: 它将复杂对象的“建造步骤”分成多部分,让我们可以灵活地控制这些步骤。通过…...

Python 快速入门(上篇)❖ Python基础知识
Python 基础知识 Python安装**运行第一个程序:基本数据类型算术运算符变量赋值操作符转义符获取用户输入综合案例:简单计算器实现Python安装** Linux安装: yum install python36 -y或者编译安装指定版本:https://www.python.org/downloads/source/ wget https://www.pyt…...

string接口的模拟实现
文章目录 一. string底层逻辑演示声明和定义分开 二. size()三. operator[]四. 迭代器四. const迭代器五. 预留空间(reserve)六. 尾插一个字符push_back七. 尾插一个字符串append八. operator九. operator 一. string底层逻辑 (1)为了和库里面…...

sed使用扩展正则表达式时, -i 要写在 -r 或 -E 的后面
sed使用扩展正则表达式时, -i 要写在 -r 或 -E 的后面 前言 -r 等效 -E , 启用扩展正则表达式 -E是新叫法,更统一,能增强可移植性 , 但老系统,比如 CentOS-7 的 sed 只能用 -r ### Ubuntu24.04-E, -r, --regexp-extendeduse extended regular expressions in the script(fo…...

Verilog HDL可综合与不可综合语句
目录 什么是逻辑综合 可综合语句 不可综合语句 逻辑综合建模建议 综合流程 什么是逻辑综合 所谓逻辑综合就是在标准单元库和特定的设计约束的基础上,把设计的高层次描述转换成优化的门级网表的过程。 标准单元库(工艺库)可以包含简单的…...
tomcat 后台部署 war 包 getshell
1. tomcat 后台部署 war 包 getshell 首先进入该漏洞的文件目录 使用docker启动靶场环境 查看端口的开放情况 访问靶场:192.168.187.135:8080 访问靶机地址 http://192.168.187.135:8080/manager/html Tomcat 默认页面登录管理就在 manager/html 下,…...

网络云计算】2024第47周-每日【2024/11/21】周考-实操题-RAID6实操解析1
文章目录 1、RAID6配置指南(大致步骤)2、注意事项3、截图和视频 网络云计算】2024第47周-每日【2024/11/21】周考-实操题-RAID6实操 RAID6是一种在存储系统中实现数据冗余和容错的技术,其最多可以容忍两块磁盘同时损坏而不造成数据丢失。RAID…...

前端面试题大汇总:React 篇
基础知识 1. 什么是 React?它的主要特点是什么? React 是一个用于构建用户界面的 JavaScript 库,由 Facebook 开发并维护。它主要用于构建单页应用程序(SPA)和复杂的用户界面。React 的主要特点包括: 组件…...

【prism】遇到一个坑,分享!
背景 我通用prism的方式写了一个弹窗,弹窗绑定一个 Loaded 事件,但是Loaded事件一直不触发!!! 具体过程 我的loaded事件也是通过命令的方式绑定的: <i:Interaction.Triggers><i:EventTrigger EventName="Loaded...

Python+Selenium+Pytest+Allure+ Jenkins webUI自动化框架
Python+Selenium+Pytest+Allure+ Jenkins webUI自动化框架 WebUI接口框架使用的工具...

智象未来(HiDream.ai)技术赋能,开启AR眼镜消费时代
Rokid Jungle 2024合作伙伴暨新品发布会于近日隆重举行,标志着AR眼镜跑步进入消费时代,更预示着ARAI技术融合的新篇章。智象未来(HiDream.ai),作为多模态生成式人工智能技术的领跑者,与Rokid的深度合作&…...

element dialog 2层弹窗数据同步问题
注意:本帖为公开技术贴,不得用做任何商业用途 element dialog 2层弹窗数据同步问题 如果嵌套dialog,也就是多层dialog嵌套 2个input,key用同样的值 会导致内外2层dialog,用相同key值的input会数据同步 原因如下&a…...

向量数据库FAISS之五:原理(LSH、PQ、HNSW、IVF)
1.Locality Sensitive Hashing (LSH) 使用 Shingling MinHashing 进行查找 左侧是字典,右侧是 LSH。目的是把足够相似的索引放在同一个桶内。 LSH 有很多的版本,很灵活,这里先介绍第一个版本,也是原始版本 Shingling one-hot …...

要素市场与收入分配
生产要素与家庭收入 生产要素:企业用于生产产品或劳务的最初投入,主要分为三类: 劳动:工人的时间和技能 土地:代指自然资源 资本:指的是货币形式的资本,可以供企业用来购置厂房、设备等资本品…...

Web3的核心技术:区块链如何确保信息安全与共享
在互联网不断迭代的进程中,Web3被视为下一代互联网的核心发展方向,其目标是构建更加开放、安全、去中心化的数字生态。在这一过程中,区块链作为核心技术,为信息安全与共享提供了全新解决方案。本文将深入探讨区块链如何在Web3中实…...

2025蓝桥杯(单片机)备赛--扩展外设之UART1的原理与应用(十二)
一、串口1的实现原理 a.查看STC15F2K60S2数据手册: 串口一在590页,此款单片机有两个串口。 串口1相关寄存器: SCON:串行控制寄存器(可位寻址) SCON寄存器说明: 需要PCON寄存器的SMOD0/PCON.6为0,使SM0和SM1一起指定工作模式,这里选择工作模式1,REN位置1,允许接受, …...

Js中的常见全局函数
文章目录 1、encodeURI、decodeURI2、encodeURIComponent、decodeURIComponent3、parseInt4、parseFloat5、String6、Number7、Boolean8、isNaN、Number.isNaN()9、JSON10、toString Js内置了一些函数和变量,全局都可以获取使用(本文归纳非构造函数作用的…...

虚幻5细节面板消失的真相与四步唤醒方案
1. 这不是Bug,是虚幻5蓝图编辑器的“细节面板隐身术”在作祟2025年用虚幻引擎5做项目,突然发现蓝图编辑器右侧的细节面板(Details Panel)怎么点都不出来——节点选中了没反应,右键菜单里找不到“显示细节”,…...

STM32 SysTick中断:嵌入式系统时间管理的核心原理与实战应用
1. 项目概述:为什么SysTick中断是STM32开发的基石在STM32的嵌入式开发世界里,无论你是刚入门的新手,还是已经做过几个项目的熟手,有一个功能你几乎无法绕开,那就是SysTick——系统滴答定时器。你可能在HAL库的初始化代…...

Netlify CLI 部署完全指南:从零到生产环境的10个步骤
Netlify CLI 部署完全指南:从零到生产环境的10个步骤 【免费下载链接】cli Netlify Command Line Interface 项目地址: https://gitcode.com/gh_mirrors/cli16/cli Netlify CLI 是一款功能强大的命令行工具,能帮助开发者轻松实现从本地开发到生产…...

手写NumPy版RBM:从能量函数到吉布斯采样的可调试实现
1. 项目概述:这不是又一个“RBM扫盲帖”,而是一次亲手拆解神经网络祖师爷级模型的实操复盘Restricted Boltzmann Machine(受限玻尔兹曼机),简称RBM,不是教科书里那个被反复引用却没人真去跑通的抽象符号&am…...

深度解析:光引擎、光模块、光器件之间的关系和区别?
随着AI大模型加速迭代,算力集群正从“千卡”向“万卡”“十万卡”规模迈进,光通信作为连接算力的“血管”,其内部层级关系变得愈发关键。然而,光器件、光模块、光引擎这三者并非同一概念,而是产业链中层层递进的“铁三…...

干翻特斯拉?雷军说输给特斯拉不丢人
一周前的晚上,雷军和马斯克合照上了热搜。一周后的晚上,“雷军说输给特斯拉不丢人”又上了热搜。①5 月 21 日晚间小米有个发布会,雷军期间自问:“Model Y 是全球纯电车型的销冠,每年都有很多车型站出来要挑战 Model Y…...

Unity TMP InputField光标稳定方案:字体、渲染与输入法深度适配
1. 为什么InputField光标会“消失”、错位、卡死——不是Bug,是渲染管线的底层博弈 你有没有在Unity项目里遇到过这样的场景:UI界面一切正常,唯独InputField的光标不显示;或者光标明明在文字末尾,点击却跳到中间&#…...

工具调用优化:减少API延迟对Agent性能的影响
《工具调用优化全指南:彻底解决API延迟拖累大模型Agent性能的痛点》 副标题:从原理到落地,覆盖缓存、并行、调度、轻量化改造全链路可复现方案 第一部分:引言与基础 1.1 摘要/引言 你有没有遇到过这种场景:辛辛苦苦开发的智能Agent功能非常强大,能查订单、搜资料、算数…...

98的堂邀请码色花的堂邀请码
兑换不易,可以联系邮箱sht98sht163.com,出邀请。...

卡梅德生物技术快报|噬菌体随机肽库筛选实战:花生过敏原 Ara h 5 模拟表位鉴定全流程
摘要本文面向生物研发、体外诊断、蛋白质工程开发者,系统讲解噬菌体随机肽库筛选过敏原模拟表位完整工程化流程:从问题分析、实验设计、关键参数到结果验证,提供可复现技术方案,基于真实研究数据,聚焦高可靠性表位筛选…...