PyTorch 分布式并行计算
0. Abstract
使用 PyTorch 进行多卡训练, 最简单的是 DataParallel, 仅仅添加一两行代码就可以使模型在多张 GPU 上并行地计算. 但它是比较老的方法, 官方推荐使用新的 Distributed Data Parallel, 更加灵活与强大:

1. Distributed Data Parallel (DDP)
从一个简单的非分布式训练任务, 到多机器多卡训练. 跟着官方教程走, 刚开始一切都很顺利, 到最后要多机器的时候, 就老是报错: MemoryError: std::bad_alloc.
1.1 DDP 概览

特点:
- 多个 batch 的数据, 同时分别在多个 GPU 上计算;
- 需要 DistributedSampler 给各 GPU 分发数据 batch, 保证数据不重复;
- 模型在各 GPU 上都有一份副本, 分别计算梯度, 并通过
ring all-reduce算法整合梯度.
可以理解为: 为每个 GPU 启动一个进程, 这些进程执行着完全相同的代码(你的程序), 不同的地方在于:
- 吃进了不同的数据样本, 那么计算得到的 loss 和反向传播计算的参数梯度都不同;
- 各进程有自己的编号(rank), 程序中可根据编号执行一些不同的操作, 如保存 checkpoint, 日志输出等操作.
1.2 single_gpu.py
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from datautils import MyTrainDatasetclass Trainer:def __init__(self,model: torch.nn.Module,train_data: DataLoader,optimizer: torch.optim.Optimizer,gpu_id: int,save_every: int,) -> None:self.gpu_id = gpu_idself.model = model.to(gpu_id)self.train_data = train_dataself.optimizer = optimizerself.save_every = save_everydef _run_batch(self, source, targets):output = self.model(source)loss = F.cross_entropy(output, targets)self.optimizer.zero_grad()loss.backward()self.optimizer.step()def _run_epoch(self, epoch):b_sz = len(next(iter(self.train_data))[0])print(f"[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")for source, targets in self.train_data:source = source.to(self.gpu_id)targets = targets.to(self.gpu_id)self._run_batch(source, targets)def _save_checkpoint(self, epoch):ckp = self.model.state_dict()PATH = "checkpoint.pt"torch.save(ckp, PATH)print(f"Epoch {epoch} | Training checkpoint saved at {PATH}")def train(self, max_epochs: int):for epoch in range(max_epochs):self._run_epoch(epoch)if epoch % self.save_every == 0:self._save_checkpoint(epoch)def load_train_objs():train_set = MyTrainDataset(2048) # load your datasetmodel = torch.nn.Linear(20, 1) # load your modeloptimizer = torch.optim.SGD(model.parameters(), lr=1e-3)return train_set, model, optimizerdef prepare_dataloader(dataset: Dataset, batch_size: int):return DataLoader(dataset,batch_size=batch_size,pin_memory=True,shuffle=True)def main(device, total_epochs, save_every, batch_size):dataset, model, optimizer = load_train_objs()train_data = prepare_dataloader(dataset, batch_size)trainer = Trainer(model, train_data, optimizer, device, save_every)trainer.train(total_epochs)if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description='simple distributed training job')parser.add_argument('total_epochs', type=int, help='Total epochs to train the model')parser.add_argument('save_every', type=int, help='How often to save a snapshot')parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')args = parser.parse_args()device = 0 # shorthand for cuda:0main(device, args.total_epochs, args.save_every, args.batch_size)
1.3 multi_gpu.py
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from datautils import MyTrainDatasetimport torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
import osdef ddp_setup(rank, world_size):"""Args:rank: Unique identifier of each processworld_size: Total number of processes"""# MASTER 表示主节点, 负责分配任务, 启动其他进程os.environ["MASTER_ADDR"] = "localhost" # IP address of masteros.environ["MASTER_PORT"] = "12355" # Port number# This is important to prevent hangs or excessive memory utilization on GPU:0torch.cuda.set_device(rank) # sets the default GPU for each processinit_process_group(backend="nccl", rank=rank, world_size=world_size)class Trainer:def __init__(self,model: torch.nn.Module,train_data: DataLoader,optimizer: torch.optim.Optimizer,gpu_id: int,save_every: int,) -> None:self.gpu_id = gpu_idself.train_data = train_dataself.optimizer = optimizerself.save_every = save_everyself.model = DDP( # 感觉有点重复, 上面 ddp_setup 已经设置过默认 device 了model.to(gpu_id), # 这里要先将模型放到 gpu_id 号 GPU 上, 否则 DDP 会报错device_ids=[gpu_id], # 那么这里再设置 device_ids 干嘛? 是可以分布到多个 GPU 上吗?)def _run_batch(self, source, targets):output = self.model(source)loss = F.cross_entropy(output, targets)self.optimizer.zero_grad()loss.backward()self.optimizer.step()def _run_epoch(self, epoch):b_sz = len(next(iter(self.train_data))[0])# len(self.train_data)} 将会被分割为 num_device 份print(f"[GPU{self.gpu_id}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")# sampler.set_epoch(epoch) is necessary to make shuffling work properly across multiple epochs.# Otherwise, the same ordering will be used in each epoch.self.train_data.sampler.set_epoch(epoch) # 这里加了一句, 是为了保证每个 epoch 的数据是随机的for source, targets in self.train_data:source = source.to(self.gpu_id)targets = targets.to(self.gpu_id)self._run_batch(source, targets)def _save_checkpoint(self, epoch):ckp = self.model.module.state_dict() # 因为 self.model 引用的是 DDP 对象, 所以想访问模型参数, 则需要 .modulePATH = "checkpoint.pt"torch.save(ckp, PATH)print(f"Epoch {epoch} | Training checkpoint saved at {PATH}")def train(self, max_epochs: int):for epoch in range(max_epochs):self._run_epoch(epoch)if self.gpu_id == 0 and epoch % self.save_every == 0: # 主进程才保存self._save_checkpoint(epoch)def load_train_objs():train_set = MyTrainDataset(2048) # load your datasetmodel = torch.nn.Linear(20, 1) # load your modeloptimizer = torch.optim.SGD(model.parameters(), lr=1e-3)return train_set, model, optimizerdef prepare_dataloader(dataset: Dataset, batch_size: int):return DataLoader(dataset,batch_size=batch_size,pin_memory=True,shuffle=False, # 有了 DistributedSampler, 这里就不用 shuffle 了, 不过 default 已经是 Falsesampler=DistributedSampler(dataset))def main(rank: int, world_size: int, save_every: int, total_epochs: int, batch_size: int):"""rank: Unique identifier of each process, GPU ID, 也是进程的 ID, 0~world_size-1world_size: Total number of processes, 总共 GPU 数量"""ddp_setup(rank, world_size) # 先设置当前子进程dataset, model, optimizer = load_train_objs() # 之后似乎都一样, 甚至数据,模型,优化器都是各进程都创建train_data = prepare_dataloader(dataset, batch_size)trainer = Trainer(model, train_data, optimizer, rank, save_every)trainer.train(total_epochs)destroy_process_group() # 结尾销毁进程组if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description='simple distributed training job')parser.add_argument('total_epochs', type=int, help='Total epochs to train the model')parser.add_argument('save_every', type=int, help='How often to save a snapshot')parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')args = parser.parse_args()world_size = torch.cuda.device_count()# spawn processes, 自动创建进程, 并且把 rank 作为第一个参数传入 mainmp.spawn(main, args=(world_size, args.save_every, args.total_epochs, args.batch_size), nprocs=world_size)
更改代码仅仅需要几个步骤:
- 构建进程组:
init_process_group(...)&destroy_process_group()
main函数被当作子进程启动, 每个子进程启动开头由init_process_group(...)构建进程组, 结尾由destroy_process_group()销毁进程组; DistributedDataParallel包装模型
其实主要还是持有参数的模型, 至于计算部分, 不要紧, 每个子进程都在执行相同的计算过程(除非设置了if rank==...的条件), 只会是参数梯度不同, 被包装后的模型参数会自动在进程组之间同步;
注意包装前先将模型移动到 GPU 上.DistributedSampler均匀地将样本分给每个子进程
如果样本数不够整除, 则会将前几个样本补到末尾, 凑够整除, 注意是打乱后的前几个, 相当于随机补几个样本;
如果设置了batch_size=32, 那么每个进程都会得到 32 个样本, 实际的batch_size=32*num_gpus; 容易误解的地方在于, 实际batch_size增大了, 那么我求 loss 时用 mean 的话, 会不会降低梯度大小? 不会, 有些博主说要learning_rate*num_gpus, 但实际上人家的ring all-reduce算法是把各进程上的梯度相加的, 相当于执行了多次梯度更新, 只不过是在相同的参数上, 而不是像单卡更新多次, 每次梯度计算在更新之后的不同的参数上.
每个子进程中访问的 DataLoader 中 batch 数会变为原来的1/num_gpus, 而len(dataset)不会.- 每个 epoch 开始时, 调用
train_loader.sampler.set_epoch(epoch), 否则, 将在每个 epoch 中使用相同的顺序. - 设置
if rank==0为保存 checkpoint 的条件, 以保证只保存几个相同模型的其中一个.
聚合操作, 如你想整合各进程计算的不同结果并保存, 不应在 if rank == 0 内, 聚合操作需要在每个进程中执行. 原因下面会解释. spawn翻译过来就是下蛋, 意思是启动子进程, 可以看到, 相当于执行了多个main函数;
rank参数是自动传给main函数的.
BatchNorm是根据数据计算均值和标准差的, 所以每个 GPU 上计算的都不一样, 如果想合成一个完整的大 Batch, 需要SyncBatchNorm同步.
1.4 multigpu_torchrun.py
import osimport torch
import torch.nn.functional as F
from torch import distributed
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSamplerfrom datautils import MyTrainDatasetdef ddp_setup():"""都不用设置主机地址和端口号了, 直接一个 LOCAL_RANK"""torch.cuda.set_device(int(os.environ["LOCAL_RANK"]))distributed.init_process_group(backend="nccl")class Trainer:def __init__(self,model: torch.nn.Module,train_data: DataLoader,optimizer: torch.optim.Optimizer,save_every: int,snapshot_path: str,) -> None:self.gpu_id = int(os.environ["LOCAL_RANK"]) # 这里也是自动获取 LOCAL_RANKself.model = model.to(self.gpu_id)self.train_data = train_dataself.optimizer = optimizerself.save_every = save_everyself.epochs_run = 0self.snapshot_path = snapshot_pathif os.path.exists(snapshot_path):print("Loading snapshot")self._load_snapshot(snapshot_path)self.model = DDP(self.model, device_ids=[self.gpu_id])def _load_snapshot(self, snapshot_path):loc = f"cuda:{self.gpu_id}"snapshot = torch.load(snapshot_path, map_location=loc, weights_only=True) # 每个 GPU 都要加载self.model.load_state_dict(snapshot["MODEL_STATE"]) # 之所以是 model.load_state_dict, 是因为在 DDP 之前self.epochs_run = snapshot["EPOCHS_RUN"]print(f"Resuming training from snapshot at Epoch {self.epochs_run}")def _run_batch(self, source, targets):print(source.shape[0])output = self.model(source)loss = F.mse_loss(output, targets)self.optimizer.zero_grad()loss.backward()self.optimizer.step()return lossdef _run_epoch(self, epoch):b_sz = len(next(iter(self.train_data))[0])print(f"[GPU{self.gpu_id}] "f"Epoch {epoch} | "f"Batchsize: {b_sz} | "f"Steps: {len(self.train_data)} | " # data_loader 会 / num_devicesf"dsize: {len(self.train_data.dataset)}" # 而数据集大小还是原来的)self.train_data.sampler.set_epoch(epoch)loss_epoch = 0for source, targets in self.train_data:source = source.to(self.gpu_id)targets = targets.to(self.gpu_id)loss = self._run_batch(source, targets)loss_epoch += lossprint(f"[GPU{self.gpu_id}] Loss {loss_epoch.item()}")distributed.all_reduce(loss_epoch, op=distributed.ReduceOp.AVG)print(f"[GPU{self.gpu_id}] Loss {loss_epoch.item()}")def _save_snapshot(self, epoch):snapshot = {"MODEL_STATE": self.model.module.state_dict(), # 之后就要用 module 了"EPOCHS_RUN": epoch,}torch.save(snapshot, self.snapshot_path)print(f"Epoch {epoch} | Training snapshot saved at {self.snapshot_path}")def train(self, max_epochs: int):for epoch in range(self.epochs_run, max_epochs):self._run_epoch(epoch)if self.gpu_id == 0 and epoch % self.save_every == 0:self._save_snapshot(epoch)def load_train_objs():train_set = MyTrainDataset(101) # load your datasetmodel = torch.nn.Linear(20, 1) # load your modeloptimizer = torch.optim.SGD(model.parameters(), lr=1e-3)return train_set, model, optimizerdef prepare_dataloader(dataset: Dataset, batch_size: int):return DataLoader(dataset,batch_size=batch_size,pin_memory=True,shuffle=False,# 这个 DistributedSampler 会自动把数据集平均分给每个 GPU, 只是每个 DataLoader 得到的下标是 len(dataset) / num_devices 个# 原来的 len(dataloder.dataset) 还是 len(dataset)# 注意会补全, 最后每个 GPU 都会得到相同的数据, 而不是最后一个 GPU 会少得# 那补了之后, 样本数是比源数据集多一些, 测试呢, 也就有偏差, 当你有上万个测试样本时, 多出来的几个样本影响不大sampler=DistributedSampler(dataset))def main(save_every: int, total_epochs: int, batch_size: int, snapshot_path: str = "snapshot.pt"):"""不带 rank 了, 直接用 LOCAL_RANK"""ddp_setup()dataset, model, optimizer = load_train_objs()train_data = prepare_dataloader(dataset, batch_size)trainer = Trainer(model, train_data, optimizer, save_every, snapshot_path)trainer.train(total_epochs)distributed.destroy_process_group()if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description='simple distributed training job')parser.add_argument('total_epochs', type=int, help='Total epochs to train the model')parser.add_argument('save_every', type=int, help='How often to save a snapshot')parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')args = parser.parse_args()main(args.save_every, args.total_epochs, args.batch_size) # 不管 rank 和 device
执行命令:
torchrun --standalone --nproc_per_node=2 multigpu_torchrun.py 50 10
# 如果设置 --nproc_per_node=gpu, 则自动检测可用 gpu 数量, 并为每个 gpu 启动一个进程.
这里使用了不同的启动方式 torchrun, 本质还是一样的, 特点:
- 能自动重启
当训练出现意外而中断时,torchrun会自动重启, 如果保存了 checkpoint 并设置了自动加载程序, 那么就可以接着训. - 设置了环境变量 “LOCAL_RANK”
你可以在程序中使用os.environ["LOCAL_RANK"])访问当前进程的rank号了. 不过我感觉仅仅是在distributed.init_process_group(backend="nccl")之前使用, 后来的地方你可以接续这么干, 但构建进程组后有一个函数distributed.get_node_local_rank()可以获取进程号. - 单卡也可以跑, 设置
--nproc_per_node=1.
1.5 同步操作
模型参数可以通过 DDP 自动地同步, 那如果我想聚合所有子进程上计算的 loss 呢? 或者我在测试时, 想聚合测试结果? 官网的这个小教程没教. 查阅博客才得知需要用 distributed.all_reduce(...).
上面的 multigpu_torchrun.py 中, 我已经对 loss 添加了这个同步:
print(f"[GPU{self.gpu_id}] Loss {loss_epoch.item()}")
distributed.all_reduce(loss_epoch, op=distributed.ReduceOp.AVG)
print(f"[GPU{self.gpu_id}] Loss {loss_epoch.item()}")
########## output ##########
[GPU1] Loss 0.3411558270454407
[GPU0] Loss 0.29943281412124634
[GPU1] Loss 0.3202943205833435
[GPU0] Loss 0.3202943205833435
两个 GPU 计算的 loss 分别为 0.3411558270454407 和 0.29943281412124634, 经过同步, 都变为了 0.3202943205833435.
注意:
- 只可对
torch.Tensor执行同步, 其他类型的如 Python int 和 np.ndarray 都不行. - 可以选择其他聚合操作, 如
op=distributed.ReduceOp.SUM表示相加:

具体可见: Collective Functions. - 聚合操作不应在 if rank == 0 内; 聚合操作需要在每个进程中执行.

1.6 会出现模型加载错误
如果刚用 torch.save(...) 保存了模型, 立刻就使用 torch.load(...) 加载, 那么很可能会出现错误:
[rank1]: RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory
原因不明.
解决办法:
time.sleep(1)
torch.load(...)
等 1s 再加载就不出错了.
2. 总结
看起来比较复杂, 但如果构建对 Distributed Data Parallel 的认知框架, 一切都变得简单:
- DDP 为每个 GPU 启动一个子进程, 它们执行"完全相同"的代码;
distributed.init_process_group(backend="nccl")构建进程组, 程序结束时distributed.destroy_process_group()销毁进程组;DistributedSampler(dataset)为每个子进程分发不重叠的等分的 Dataset 子集, 实现数据并行;- 用 DDP 对象包装模型, 就能在进程组中同步梯度和参数; 叫
ring all-reduce算法; - 你可以用
all_reduce等操作实现进程间的张量同步; - 还可以根据进程的
rank号对不同子进程执行略有不同的操作, 如保存模型操作.
相关文章:
PyTorch 分布式并行计算
0. Abstract 使用 PyTorch 进行多卡训练, 最简单的是 DataParallel, 仅仅添加一两行代码就可以使模型在多张 GPU 上并行地计算. 但它是比较老的方法, 官方推荐使用新的 Distributed Data Parallel, 更加灵活与强大: 1. Distributed Data Parallel (DDP) 从一个简单的非分布…...
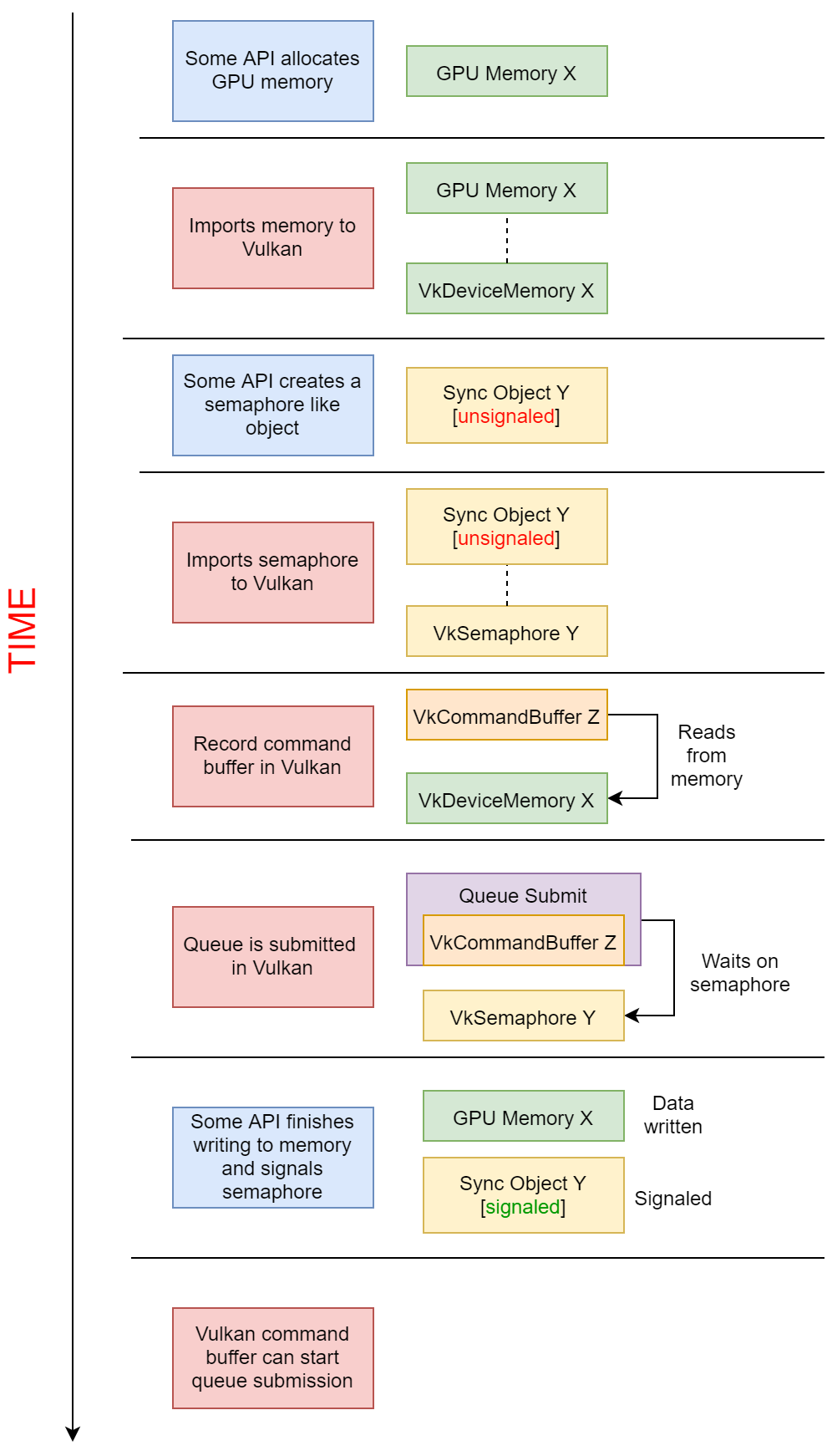
[cg] vulkan external_memory
最近在写硬件编码的代码,渲染器渲染出的RT需要给到编码器做硬编,有两种方法能做。 一是通过 map的方式,把显存里的数据读到cpu,拷贝一份cpu data给编码器,但这种方式会有内存拷贝的开销。所以,我们思考是否…...

如何使用Python代码实现给GPU预加热
如何使用Python代码实现给GPU预加热 一、引言二、使用深度学习框架进行预加热2.1 TensorFlow预加热2.2 PyTorch预加热三、使用CUDA进行预加热四、预加热的效果评估与优化五、结论与展望在高性能计算和深度学习领域,GPU(图形处理器)已经成为不可或缺的加速工具。然而,在实际…...

硬件知识 cadence16.6 原理图输出为pdf 网络名下划线偏移 (ORCAD)
1. cadence原理图输出为PDF网络名下划线偏移 生这种情况的原因 1. 设计的原理图图纸大小比正常的 A4图纸大。 2. 打印为PDF 的时候,打印机的设置有问题。 2.cadence原理图输出为 PDF网络名下划线偏移的情况 可以看到上图,网络名往上漂移。 3. 解决办法 …...

ffmpeg视频滤镜:提取缩略图-framestep
滤镜描述 官网地址 > FFmpeg Filters Documentation 这个滤镜会间隔N帧抽取一帧图片,因此这个可以用于设置视频的缩略图。总体上这个滤镜比较简单。 滤镜使用 滤镜参数 framestep AVOptions:step <int> ..FV....... set frame st…...
RecyclerView详解——(四)缓存复用机制
稍微看了下源码和部分文章,在此做个小小的总结 RecyclerView,意思为可回收的view,那么相对于listview,他的缓存复用肯定是一大优化。 具体而言,当一个列表项被移出屏幕后,RecyclerView并不会销毁其视图&a…...

进程 系统调用 中断
进程P通过执行系统调用从键盘接收一个字符的输入,已知此过程中与进程P相关的操作包括: ①将进程P插入就绪队列; ②将进程P插入阻塞队列; ③将字符从键盘控制器读入系统缓冲区; ④启动键盘中断处理程序; …...
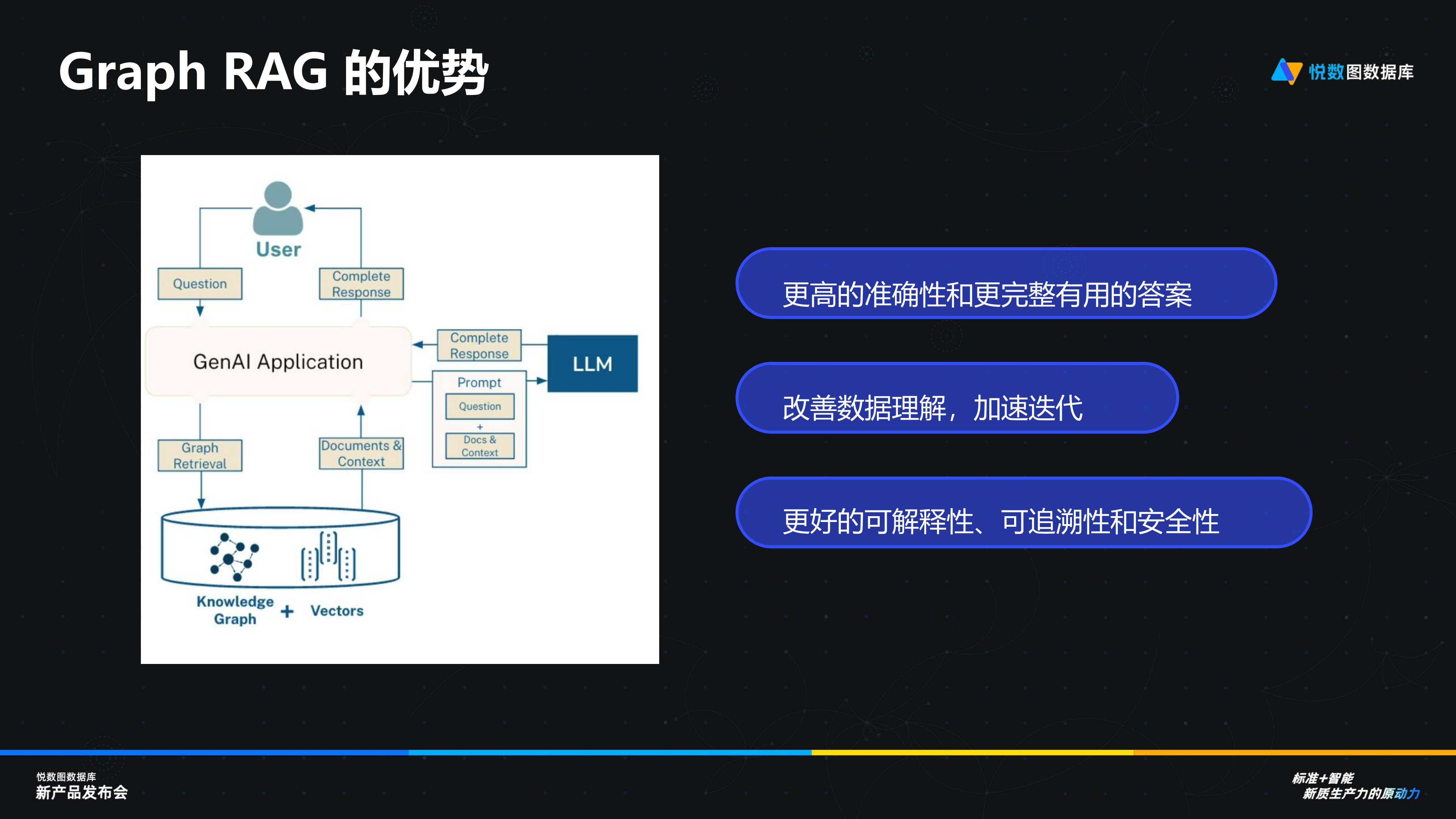
演讲回顾丨杭州悦数 CTO 叶小萌:图数据库发展新航向——拥抱 GQL,融合 HTAP,携手 AI
本文为杭州悦数 CTO 叶小萌在“标准智能:新质生产力的原动力”悦数图数据库新产品发布会上的演讲回顾,主题为:《新标准、新期待:展望图数据库发展的关键方向》 各位嘉宾、悦数图数据库的用户以及线上的观众朋友们大家好࿰…...

Java安全—JNDI注入RMI服务LDAP服务JDK绕过
前言 上次讲到JNDI注入这个玩意,但是没有细讲,现在就给它详细地讲个明白。 JNDI注入 那什么是JNDI注入呢,JNDI全称为 Java Naming and Directory Interface(Java命名和目录接口),是一组应用程序接口&…...

C++:设计模式-单例模式
单例模式(Singleton Pattern)是一种设计模式,确保一个类只有一个实例,并且提供全局访问点。实现单例模式的关键是防止类被多次实例化,且能够保证实例的唯一性。常见的实现手法包括懒汉式、饿汉式、线程安全的懒汉式等。…...

Softing工业将OPC UA信息建模集成到边缘应用和安全集成服务器中
Softing工业宣布将OPC UA(统一架构)信息建模集成到其边缘产品系列及安全集成服务器(SIS)中,这一技术进步使得在工业物联网(IIoT)应用中的数据集成、交换与控制更加无缝、有效。 (OPC…...

WPF中如何让Textbox显示为一条直线
由于Textbox直接使用是一条直线 设置如下代码 可以让Textbox变为直线输入 <Style TargetType"TextBox"x:Key"UsernameTextBoxStyle"><Setter Property"Template"><Setter.Value><ControlTemplate TargetType"{x:Typ…...

VSCode汉化教程【简洁易懂】
我们安装完成后默认是英文界面。 找到插件选项卡,搜索“Chinese”,找到简体(更具你的需要)(Microsoft提供)Install。 安装完成后选择Change Language and Restart。...

跨平台多开账号防关联:轻松管理多个账号!
对于跨境电商、独立站以及社媒营销领域,如何高效管理多个账号、确保账号安全是企业面临的重大挑战。那么如何仅用一台电脑就能实现跨平台多开账号呢? 一、为什么需要跨平台多开账号并防关联? 1. 品牌推广:不同平台拥有不同的用户…...

DICOM图像处理:深入解析DICOM彩色图像中的Planar配置及其对像素数据解析处理的实现
引言 在DICOM(Digital Imaging and Communications in Medicine)标准中,彩色图像的存储与显示涉及多个关键属性,其中**Planar Configuration(平面配置)**属性(标签 (0028,0006))尤为重要。当遇到彩色DICOM图像在浏览时被错误地分割为9张小图,而实际应显示为一…...

jupyter notebook的 markdown相关技巧
目录 1 先选择为markdown类型 2 开关技巧 2.1 运行markdown 2.2 退出markdown显示效果 2.3 注意点:一定要 先选择为markdown类型 3 一些设置技巧 3.1 数学公式 3.2 制表 3.3 目录和列表 3.4 设置各种字体效果:加粗,斜体&#x…...

Linux连接网络的三种方式
Linux 连接网络的三种常见方式如下: 桥接模式 原理:虚拟网络接口与物理网络接口或另一个虚拟接口 “桥接”,形成逻辑上的网络交换机,使所有通过该桥接设备的数据包能被转发到桥接组中的所有接口,如同在一个局域网内…...

##继承##
继承的概念 #继承是新模板基于老模板的基础上修改而成,制作新模板时不需要重新开始制作,可以在老模板的基础上进行修改.(如手机版本的换代,软件的版本更新等) #程序也可以继承 继承的格式: class 继承模块(被继承模块ÿ…...
)
2024 APMCM亚太数学建模C题 - 宠物行业及相关产业的发展分析和策略 完整参考论文(1)
摘要 近年来,中国宠物食品行业迅速增长,但面临复杂的国际形势和多变的市场环境,因此科学地分析和预测该行业的发展趋势至关重要。本研究通过构建多个机器学习与统计回归模型,量化分析中国宠物食品行业的关键驱动因素,预测未来宠物食品总产值和出口值。 在数据处理部分,…...

uni-app 修改复选框checkbox选中后背景和字体颜色
编写css(注意:这个样式必须写在App.vue里) /* 复选框 */ /* 复选框-圆角 */ checkbox.checkbox-round .wx-checkbox-input, checkbox.checkbox-round .uni-checkbox-input {border-radius: 100rpx; } /* 复选框-背景颜色 */ checkbox.checkb…...

蒙古语AI语音落地难?ElevenLabs最新v3.2模型支持率提升至98.7%,但90%开发者忽略这5个编码陷阱
更多请点击: https://intelliparadigm.com 第一章:蒙古语AI语音落地的现实困境与技术拐点 蒙古语作为中国少数民族语言中使用人口较多、语法高度黏着、音系复杂的阿尔泰语系代表,其AI语音技术长期受限于低资源特性——标准语音数据集不足50小…...

ChatGPT Plus 怎么购买?2026 开通教程
如果你还在犹豫是否有必要开通 Plus,可以先通过AI模型聚合平台 做一些基础体验,对比不同模型在写代码、改文档、做总结时的效果,再决定要不要正式升级 ChatGPT Plus。到了 2026 年,ChatGPT 已经不只是“聊天工具”,更像…...

远程会议还在发文档改来改去?我用 Rustpad 搭了个协作平台彻底解决
前言 远程会议开到一半,需要共同修订一份文档或代码提纲,这种场景估计不少人经历过。方案来来去去就那几个:发邮件等反馈、微信来回传文件、用腾讯文档但要登录账号……每种都有各自的鸡肋之处。后来我自己琢磨出一套更顺手的方案࿱…...

CANN/asc-devkit浮点ilogbf函数文档
ilogbf 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/can…...

2025_NIPS_Language Models Don‘t Always Say What They Think: Unfaithful Explanations in Chain-of-T...
文章主要内容与创新点总结 一、主要内容 该研究聚焦大语言模型(LLMs)的思维链(CoT)提示法,核心探讨CoT解释的“不忠实性”——即模型生成的分步推理过程可能无法真实反映其预测的底层逻辑,反而会系统性地误导用户。 研究背景:CoT提示法通过引导模型输出分步推理再给出…...

Internet Archive Downloader终极指南:三步永久保存数字图书馆书籍
Internet Archive Downloader终极指南:三步永久保存数字图书馆书籍 【免费下载链接】internet_archive_downloader A chrome/firefox extension that download books from Internet Archive(archive.org) and HathiTrust Digital Library (hathitrust.org) 项目地…...

告别PPT超时焦虑:PPTTimer让演讲时间管理变得如此简单
告别PPT超时焦虑:PPTTimer让演讲时间管理变得如此简单 【免费下载链接】ppttimer 一个简易的 PPT 计时器 项目地址: https://gitcode.com/gh_mirrors/pp/ppttimer 还在为PPT演示超时而烦恼吗?每次演讲都像和时间赛跑,担心讲得太快或太…...

艾络迅 × 荣耀:联合推出Meteer AI跳舞机器人玩具,智能科技重新定义儿童陪伴
在快节奏的现代生活中,每个孩子都渴望获得专属的陪伴与关注。他们对音乐和律动有着天然的热爱,期待拥有能够与之互动、共同成长的智能伙伴。然而,传统玩具的单一功能已无法满足数字原生代儿童的多元化需求。 正是洞察到这一痛点,艾…...

戴尔G15散热终极控制:开源TCC-G15高效替代方案完全指南
戴尔G15散热终极控制:开源TCC-G15高效替代方案完全指南 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 对于戴尔G15笔记本用户而言,过热…...

对比直接调用与通过 Taotoken 调用的稳定性体验差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接调用与通过 Taotoken 调用的稳定性体验差异 作为一名长期使用各类大模型 API 的开发者,我在构建和运维应用时&…...