【论文笔记】LLaVA-KD: A Framework of Distilling Multimodal Large Language Models
Abstract
大语言模型(Large Language Models, LLM)的成功,使得研究者为了统一视觉和语言的理解去探索多模态大预言模型(Multimodal Large Language Models, MLLM)。
但是MLLM庞大的模型和复杂的计算使其很难应用在资源受限的环境,小型MLLM(s-MLLM)的表现又远不如大型的MLLM(l-MLLM)。
基于上述提到的问题,本文提出了全新的LLaVA-KD框架,将l-MLLM的知识转移到s-MLLM。具体地,本文提出:
- 多模态蒸馏(Multimodal Distillation, MDist),减小l-MLLM和s-MLLM之间的视觉-文本输出分布的差异;
- 关系蒸馏(Relation Distillation, RDist),迁移l-MLLM对视觉特征之间相关性的建模能力。
本文还提出了三阶段训练方案,充分挖掘s-MLLM的潜力: - 预训练时蒸馏,对齐视觉文本表示;
- 有监督地微调,使模型具备多模态理解;
- 微调时蒸馏,进一步迁移l-MLLM的能力。
本文方法在不改变s-MLLM结构的情况下显著提升了其性能。
github仓库
Introduction
本文从研究各种训练策略的角度出发,在不改变模型架构的情况下,探索提高、s-MLLM的性能。
![![[Pasted image 20241123173726.png]]](https://i-blog.csdnimg.cn/direct/a16d2226395b483ba1e111094ffa2c87.png)
图1:为了训练s-MLLM,(a)已有方法遵循两步训练,包括预训练(Pre-Training, PT)和监督微调(Supervised Fine-Tuning, SFT);(b)本文的LLaVA-KD提出了三步训练,包含蒸馏预训练(Distilled Pre-Training, DPT)来对齐视觉文本表示、SFT来提升模型的多模态理解能力、蒸馏微调(Distilled Fine-Tuning, DFT)来转移l-MLLM的能力;©本文将LLaVA-KD和其他sota的MLLM在五个热门的多模态benchmark上进行比较。
如图1所示,已有的s-MLLM遵循两步训练策略,包含PT和SFT。PT阶段将视觉特征投影到文本嵌入空间;SFT阶段增强模型的理解和推离能力。
但是s-MLLM的模型容量很小,很难像l-MLLM那样捕获复杂的知识。本文将研究如何借助蒸馏提升s-MLLM的训练。
3 LLaVA-KD
![![[Pasted image 20241123184930.png]]](https://i-blog.csdnimg.cn/direct/70b39857f67a4647aadb839b10d9492c.png)
图2:LLaVA-KD的总图,包含三阶段训练。1) DPT,向l-MLLM对齐视觉和文本信息。2) SFT,为s-MLLM带来多模态理解能力。3)DFT,向s-MLLM迁移l-MLLM的能力。在DPT和DFT中应用MDist,使用RDist来使得s-MLLM捕获视觉信息的复杂关系。
3.1 Composition of Distilled MLLM Architecture
图2左侧展示了MLLM的蒸馏过程,包含l-MLLM作为教师模型,和s-MLLM作为学生模型,分别包含三个部分:
Frozen Visual Encoder:用于获得强力的视觉特征。给定输入图像 X v ∈ R H × W × 3 X_v\in\mathbb{R}^{H\times W\times 3} Xv∈RH×W×3,排序成2D patches P v ∈ R N p × S p 2 × 3 P_v\in\mathbb{R}^{N_p\times S_p^2\times 3} Pv∈RNp×Sp2×3,其中 S p S_p Sp和 N p N_p Np表示patch的大小和数量。最后的transformer层将 P v P_v Pv变成 Z v ∈ R N p × C Z_v\in\mathbb{R}^{N_p\times C} Zv∈RNp×C,其中特征维度为 C C C。教师和学生都使用相同的Frozen Visual Encoder。
Visual Projector:包含两个MLP层,带有激活函数GELU,将 Z v Z_v Zv映射到文本嵌入空间 H v ∈ R N p × D H_v\in\mathbb{R}^{N_p\times D} Hv∈RNp×D,其中 D D D是嵌入空间维度。
Large Language Model (LLM):用于实现对视觉和语言信息的统一认识。给定视觉嵌入的多模态输入 H v H_v Hv和文本嵌入 H t H_t Ht,LLM将二者的连接 H = [ H v , H t ] H=[H_v,H_t] H=[Hv,Ht]作为输入,生成输出 y = [ y p , y v , y r ] = { y t } t = 1 T y=[y_p,y_v,y_r]=\{y_t\}_{t=1}^T y=[yp,yv,yr]={yt}t=1T,其中 y p , y v , y r y_p,y_v,y_r yp,yv,yr分别代表prompt、视觉和响应tokens, T T T代表所有预测token的长度。本文将教师和学生的LLM分别称为l-LLM和s-LLM。
3.2 Training Scheme of Teacher Model L-MLLM
Pre-Training:Visual Encoder和l-LLM冻结,只有Projector被优化,用于对齐视觉和文本特征。训练过程中,使用图像-描述对,对应的目标公式表示为:
L reg = − ∑ m = 1 M log ϕ l ( y m ∣ y < m ) (1) \mathcal{L}_\text{reg}=-\sum_{m=1}^M \log\phi_l(y_m|y_{<m})\tag{1} Lreg=−m=1∑Mlogϕl(ym∣y<m)(1)
其中 M M M表示预测的响应tokens的长度, ϕ l ( y m ∣ y < m ) \phi_l(y_m|y_{<m}) ϕl(ym∣y<m)表示响应tokens y m y_m ym的分布基于先前预测 y < m y_{<m} y<m的条件。
Supervised Fine-Tuning:该阶段保持Visual Encoder的冻结,旨在联合优化Projector和l -LLM,以增强教师模型l-MLLM的理解和教学跟随能力。训练过程中,利用高质量的对话数据集,训练目标 L S F T \mathcal{L}_{SFT} LSFT如Eq.1所示。
3.3 Framework of LLaVA-KD
3.3.1 MLLM-Oriented KD Strategy
Multimodal Distillation (MDist):考虑到MLLM本质上是利用LLM进行多模态信息理解和推理,我们沿用LLM的朴素蒸馏方法,即利用KL散度(KLD)对响应预测进行蒸馏。训练目标可以定义为:
L res = ∑ m = 1 M KLD ( ϕ l ( y m ∣ y < m ) , ϕ s ( y m ∣ y < m ) ) = ∑ m = 1 M ∑ j = 1 V ϕ l ( Y j ∣ y < m ) log ( ϕ l ( Y j ∣ y < m ) ϕ s ( Y j ∣ y < m ) ) (2) \begin{aligned} \mathcal{L}_\text{res}&=\sum_{m=1}^M \text{KLD}(\phi_l(y_m|y_{<m}),\phi_s(y_m|y_{<m})) \\ &=\sum_{m=1}^M \sum_{j=1}^V \phi_l(Y_j|y_{<m})\log (\frac{\phi_l(Y_j|y_{<m})}{\phi_s(Y_j|y_{<m})})\tag{2} \end{aligned} Lres=m=1∑MKLD(ϕl(ym∣y<m),ϕs(ym∣y<m))=m=1∑Mj=1∑Vϕl(Yj∣y<m)log(ϕs(Yj∣y<m)ϕl(Yj∣y<m))(2)
其中 M M M表示响应tokens的长度, V V V表示词汇空间。 ϕ l \phi_l ϕl和 ϕ s \phi_s ϕs表示l-MLLM和s-MLLM的参数, ϕ l ( Y j ∣ y < m ) \phi_l(Y_j|y_{<m}) ϕl(Yj∣y<m)和 ϕ s ( Y j ∣ y < m ) \phi_s(Y_j|y_{<m}) ϕs(Yj∣y<m)表示由l-MLLM和s-MLLM预测的词汇 Y j Y_j Yj出现在token y m y_m ym的概率。
同时,视觉表征对于LLM的多模态理解也至关重要。因此,进一步优化教师和学生输出视觉分布之间的KLD:
L vis = ∑ k = 1 K ∑ j = 1 V ϕ l ( Y j ∣ y < k ) log ( ϕ l ( Y j ∣ y < k ) ϕ s ( Y j ∣ y < k ) ) (3) \mathcal{L}_\text{vis}=\sum_{k=1}^K \sum_{j=1}^V \phi_l(Y_j|y_{<k})\log (\frac{\phi_l(Y_j|y_{<k})}{\phi_s(Y_j|y_{<k})})\tag{3} Lvis=k=1∑Kj=1∑Vϕl(Yj∣y<k)log(ϕs(Yj∣y<k)ϕl(Yj∣y<k))(3)
其中 K K K表示视觉token的长度, ϕ l ( Y j ∣ y < k ) \phi_l(Y_j|y_{<k}) ϕl(Yj∣y<k)和 ϕ s ( Y j ∣ y < k ) \phi_s(Y_j|y_{<k}) ϕs(Yj∣y<k)分别表示由l-MLLM和s-MLLM预测的词汇 Y j Y_j Yj出现在token y k y_k yk的概率。
本文在DPT阶段用MDist来对齐s-MLLM中的视觉和语言特征,加强了s-MLLM的理解能力。
Relation Distillation (RDist):为了使学生模型能够捕获视觉信息中的复杂关系,本文从LLM输出的视觉tokens中构造自相关矩阵。通过优化矩阵之间的相似性,学生模型继承了教师模型理解视觉tokens之间错综复杂关系的能力。为了达到这个目的,首先计算自相关矩阵如下:
{ R v s = y v s ⊗ y v s ∈ R N p × N p R v t = y v t ⊗ y v t ∈ R N p × N p \begin{equation} \left\{ \begin{aligned} R_v^s &= y_v^s\otimes y_v^s\in\mathbb{R}^{N_p\times N_p} \\ R_v^t &= y_v^t\otimes y_v^t\in\mathbb{R}^{N_p\times N_p} \end{aligned} \right.\tag{4} \end{equation} {RvsRvt=yvs⊗yvs∈RNp×Np=yvt⊗yvt∈RNp×Np(4)
其中 ⊗ \otimes ⊗表示矩阵乘法, y v s y_v^s yvs和 y v t y_v^t yvt表示学生和教师的视觉logits, N p N_p Np表示视觉token的数量。目标是最大化 R v s R_v^s Rvs和 R v t R_v^t Rvt的余弦相似度:
L rel = 1 − Cos ( R v s , R v t ) = 1 − R v s ⋅ R v t ∣ ∣ R v s ∣ ∣ ∣ ∣ R v t ∣ ∣ (5) \mathcal{L}_\text{rel}=1-\text{Cos}(R_v^s,R_v^t)=1-\frac{R_v^s\cdot R_v^t}{||R_v^s||\ ||R_v^t||}\tag{5} Lrel=1−Cos(Rvs,Rvt)=1−∣∣Rvs∣∣ ∣∣Rvt∣∣Rvs⋅Rvt(5)
用RDist可以进一步提升s-MLLM在DPT和DFT阶段的视觉表达能力。
3.3.2 Three-stage Distillation Scheme
Distilled Pre-Training (DPT):该阶段的主要目的是将视觉特征投射到文本嵌入空间。在LLaVA-KD中,使用蒸馏过程来像l-MLLM一样更好地对齐视觉和文本信息。
具体地,冻结visual encoder和s-MLLM中的LLM,只优化projector。在训练过程中,通过MDist最小化学生模型和教师模型在视觉和反应的输出分布上的差异。
为了优化这个目标,可以进一步促进投影的视觉特征与文本嵌入的对齐。此外,我们利用RDist来增强视觉特征的质量,使学生模型能够借鉴教师模型处理复杂视觉信息的能力。
总的来说,除了优化自回归预测结果,还使用了MDist和RDist:
L DPT = L PT + α L res + β L vis + γ L rel (6) \mathcal{L}_\text{DPT}=\mathcal{L}_\text{PT}+\alpha\mathcal{L}_\text{res}+\beta\mathcal{L}_\text{vis}+\gamma\mathcal{L}_\text{rel}\tag{6} LDPT=LPT+αLres+βLvis+γLrel(6)
Supervised Fine-Tuning (SFT):这个阶段遵循l-MLLM训练阶段的通用SFT过程(Sec.3.2)。通过联合训练Projector和l-LLM,使模型具有推理能力和指令跟踪能力。训练目标由Eq.1定义,表示为 L SFT ′ \mathcal{L}_\text{SFT}' LSFT′。
Distilled Fine-Tuning (DFT):该阶段的主要目标是进一步增强s-MLLM的理解和推理能力。具体来说,采用了MDist和RDist相结合的蒸馏策略,冻结了Visual Encoder,优化了Projector和sLLM。通过使用MDist,可以对s-MLLM中的小规模s-LLM进行充分优化,从而更好地模拟大规模l-LLM的推理能力。和RDist可以进一步促进s-MLLM学习l-MLLM的视觉表征。
总体训练目标可以表示为:
L D F T = L reg + α ′ L res + β ′ L vis + γ ′ L rel (7) \mathcal{L}_{DFT}=\mathcal{L}_\text{reg}+\alpha'\mathcal{L}_\text{res}+\beta'\mathcal{L}_\text{vis}+\gamma'\mathcal{L}_\text{rel}\tag{7} LDFT=Lreg+α′Lres+β′Lvis+γ′Lrel(7)
其中 L reg \mathcal{L}_\text{reg} Lreg表示自回归预测loss。
相关文章:
【论文笔记】LLaVA-KD: A Framework of Distilling Multimodal Large Language Models
Abstract 大语言模型(Large Language Models, LLM)的成功,使得研究者为了统一视觉和语言的理解去探索多模态大预言模型(Multimodal Large Language Models, MLLM)。 但是MLLM庞大的模型和复杂的计算使其很难应用在资源受限的环境,小型MLLM(s-MLLM)的表现…...

M|大脑越狱
rating: 7.0 豆瓣: 7.6 上映时间: “2015” 类型: M悬疑 导演: 约瑟夫怀特 Joseph White 主演: 亚历山大欧文 Alexander Owen爱德华富兰克林 Edward Franklin 国家/地区: 英国 片长/分钟: 20分钟 M|大脑越狱 想法不错,但是逻辑比较一般。属于…...
)
数据库编程(sqlite3)
一:数据库分类 常用的数据库 大型数据库 :Oracle商业、多平台、关系型数据库功能最强大、最复杂、市场占比最高的商业数据库 中型数据库 :Server是微软开发的数据库产品,主要支持windows平台 小型数据库 : mySQL是一个小型关系型…...

【C语言】关键字详解
【C语言】关键字详解 文章目录 [TOC](文章目录) 前言一、char1.定义字符串类型2.定义字符类型 二、short三、int四、long五、signed六、unsigned七、float八、double九、struct、union、enum十、void1.void用于函数声明,没有返回值的函数,其类型为 void。…...

什么是计算机网络
什么是计算机网络? 计算机网络的定义计算机网络的分类按覆盖范围分类按拓扑结构分类按通信传输介质分类按信号频带占用方式分类 计算机网络的功能信息交换资源共享分布式处理 计算机网络的组成计算机网络的定义计算机网络的分类按覆盖范围分类按拓扑结构分类按通信传…...

【大数据学习 | Spark-Core】Spark的分区器(HashPartitioner和RangePartitioner)
之前学过的kv类型上面的算子 groupby groupByKey reduceBykey sortBy sortByKey join[cogroup left inner right] shuffle的 mapValues keys values flatMapValues 普通算子,管道形式的算子 shuffle的过程是因为数据产生了打乱重分,分组、排序、join等…...
)
CSS3_BFC(十二)
BFC MDN对BFC的解释:块格式化上下文(Block Formating Context, BFC)是web页面的可视CSS渲染的一部分,是块盒子的布局过程发生的区域,也是浮动元素与其他元素交互的区域。 1、开启BFC flow-root对内容的影响是最低的&am…...

C0032.在Clion中使用MSVC编译器编译opencv的配置方法
使用MSVC编译器编译opencv的配置方法...

微信小程序中会议列表页面的前后端实现
题外话:想通过集成腾讯IM来解决即时聊天的问题,如果含语音视频,腾讯组件一年5万起步,贵了!后面我们改为自己实现这个功能,这里只是个总结而已。 图文会诊需求 首先是个图文列表界面 同个界面可以查看具体…...

WEB攻防-通用漏洞文件上传二次渲染.htaccess变异免杀
知识点: 1、文件上传-二次渲染 2、文件上传-简单免杀变异 3、文件上传-.htaccess妙用 4、文件上传-PHP语言特性 1、上传后门时,文件内容带.就不行 这时可以上传一个转换后的ip地址,ip地址对应网站包含后门代码 转换后的int会在访问的时候…...

vue实现列表滑动下拉加载数据
一、实现效果 二、实现思路 使用滚动事件监听器来检测用户是否滚动到底部,然后加载更多数据 监听滚动事件。检测用户是否滚动到底部。加载更多数据。 三、案例代码 <div class"drawer-content"><div ref"loadMoreTrigger" class&q…...

全面解析:HTML页面的加载全过程(四)--浏览器渲染之样式计算
主线程遍历得到的 DOM 树,依次为树中的每个节点计算出它最终的样式,称之为 Computed Style。 通过前面生成的DOM 树和 CSSOM 树,遍历 DOM 树,为每一个 DOM 节点,计算它的所有 CSS 属性,最后会得到一棵带有…...

#Verilog HDL# 谈谈代码中如何跨层次引用
目录 一 先谈作用问题 二 再谈跨层次问题 2.1 向下引用 2.2 向上引用 一 先谈作用问题 大多数编程语言都有一个称为作用域(scope)的特征,它定义了代码的某些部分对于变量和方法的可见性。作用域定义了一个命名空间,以避免同一命名空间内不同对象名称之间的冲突。 V…...

LeetCode 每日一题 2024/11/18-2024/11/24
记录了初步解题思路 以及本地实现代码;并不一定为最优 也希望大家能一起探讨 一起进步 目录 11/18 661. 图片平滑器11/19 3243. 新增道路查询后的最短距离 I11/20 3244. 新增道路查询后的最短距离 II11/21 3248. 矩阵中的蛇11/22 3233. 统计不是特殊数字的数字数量1…...
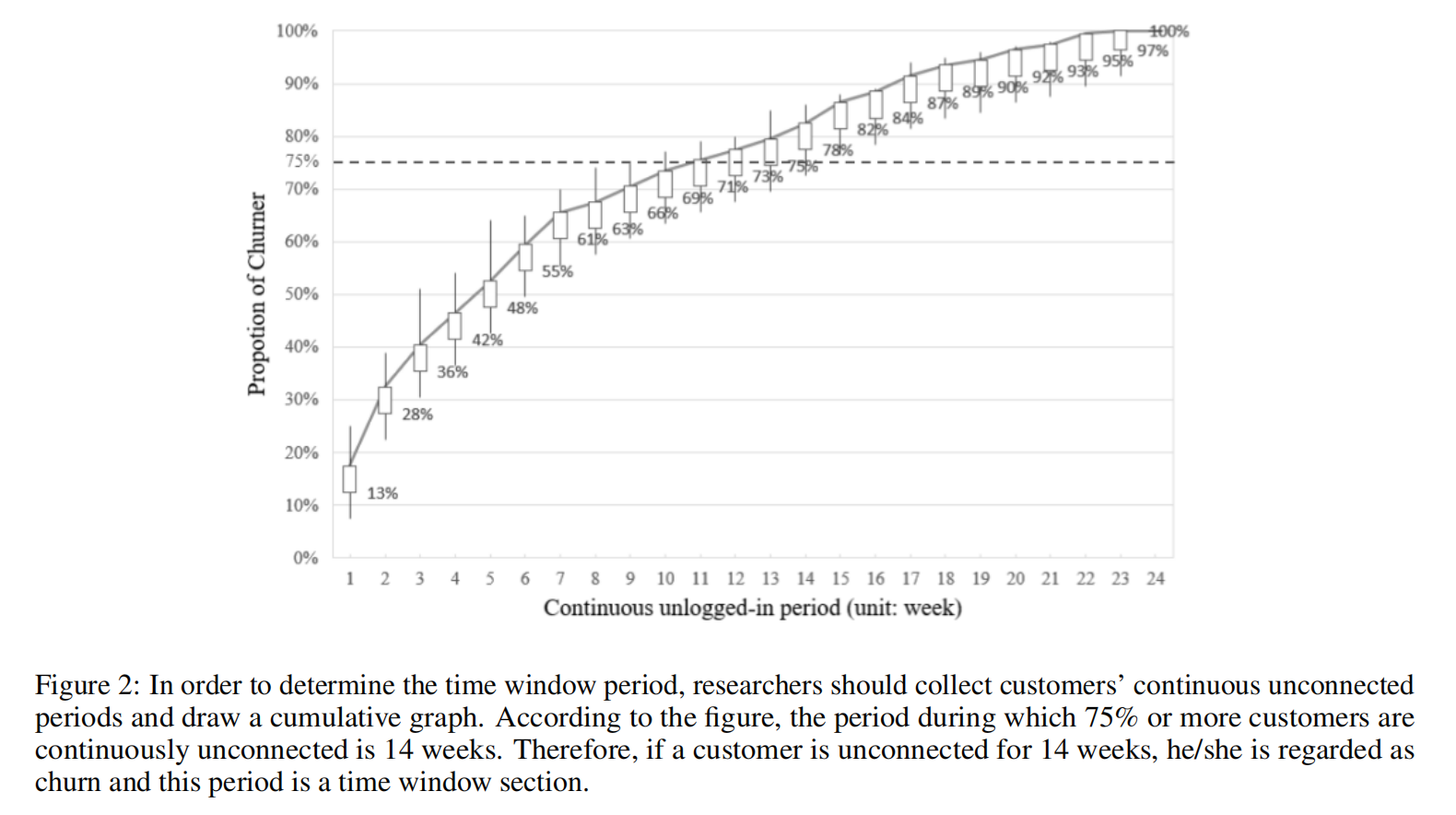
客户流失分析综述
引言 客户流失这个术语通常用来描述在特定时间或合同期内停止与公司进行业务往来的客户倾向性[1]。传统上,关于客户流失的研究始于客户关系管理(CRM)[2]。在运营服务时,防止客户流失至关重要。过去,客户获取相对于流失…...

基于51单片机的红包抽奖proteus仿真
地址: https://pan.baidu.com/s/1nYZlLb64kdZAWSydT_uHfA 提取码:1234 仿真图: 芯片/模块的特点: AT89C52/AT89C51简介: AT89C52/AT89C51是一款经典的8位单片机,是意法半导体(STMicroelectro…...

cangjie (仓颉) vscode环境搭建
sdk下载 下载中心-仓颉编程语言官网 可选择半年更新版,不用申请。目前版本:0.53.13 ,选择不同平台压缩包下载解压到任意位置即可 补充下载,vscode插件解压后,在vscode扩展中选择从vsix安装,安装后新增名为…...

阿里云私服地址
1.解压apache-maven-3.6.1-bin 2.配置本地仓库:修改conf/dettings.xml中的<localReoisitory>为一个指定目录。56行 <localRepository>D:\apache-maven-3.6.1-bin\apache-maven-3.6.1\mvn_repo</localRepository> 3.配置阿里云私服:…...

HTMLCSS:3D金字塔加载动画
效果演示 这段代码通过CSS3的3D变换和动画功能,创建了一个旋转的金字塔加载动画,每个侧面都有不同的颜色渐变,底部还有一个模糊的阴影效果,增加了视觉的立体感。 HTML <div class"pyramid-loader"><div cl…...
(3))
shell编程(2)(3)
目录 一、永久环境变量 按用户设置永久环境变量 文件路径: 示例步骤: 删除永久环境变量 二、脚本程序传递参数怎么实现 三、用编程进行数学运算 shell中利用expr进行运算 运算与变量结合 1. 变量赋值和基本运算 2. 使用expr进行运算 3. 变量…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

DLA功耗优化验证:tegrastats实战指南
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

别再把大模型当搜索框了:一文讲透 LLM 的基本原理、能力边界与局限性
写在前面很多人把大语言模型当成“会聊天的搜索引擎”,结果一上线就遇到幻觉、口径不稳、上下文丢失、成本失控。真正理解 LLM,要先抓住一句话:它是基于 Transformer 的概率生成模型,核心能力来自海量预训练、上下文学习与后训练对…...

WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件
WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸3》这…...

使用libusb-win32驱动复活老旧USB硬件:以Elektor Magic Eye为例
1. 项目概述:让老硬件在新时代焕发新生手头有一台十多年前的《Elektor》杂志上刊登的“Magic Eye EM84”复古VFD显示屏项目,想把它接到Windows 10电脑上当个酷炫的CPU占用率显示器,却发现官方提供的“AVR309”USB驱动在新系统上彻底罢工了。这…...

Linux 负载均衡的 cache_nice_tries:缓存友好的迁移尝试
简介现如今服务器、嵌入式设备、工控主板普遍采用多核、NUMA 架构 CPU,多进程多线程并发运行模式成为常态。Linux 内核依靠调度域分层负载均衡机制,分散 CPU 运行压力,避免单核心负载过高、其余核心空闲浪费硬件算力。但任务跨核心迁移是一把…...

热电效应自发电自行车灯:利用体温实现免充电照明的工程实践
1. 项目概述:从人体体温到自行车灯光你有没有想过,骑自行车时身体散发出的热量,除了让你出汗,还能干点什么?这个项目就是把我们骑车时产生的“废热”,变成照亮前路的灯光。听起来有点像科幻情节,…...

从零到远程:手把手教你用Electerm搞定Ubuntu Server的SSH连接与防火墙配置
从零到远程:手把手教你用Electerm搞定Ubuntu Server的SSH连接与防火墙配置当你第一次面对Ubuntu Server时,最迫切的需求可能就是如何安全地远程管理它。作为运维新手或开发者,掌握SSH连接和防火墙配置是进入Linux世界的第一道门槛。本文将带你…...

抖音下载器深度解析:零基础轻松批量下载无水印视频
抖音下载器深度解析:零基础轻松批量下载无水印视频 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

CANoe测试效率翻倍:手把手教你用XML Test Module搭建可复用的测试套件
CANoe测试效率翻倍:手把手教你用XML Test Module搭建可复用的测试套件在车载电子系统开发中,测试环节往往占据整个项目周期的40%以上时间。面对频繁的ECU软件迭代和多样化配置需求,传统逐个脚本执行测试的方式已经无法满足敏捷开发的要求。本…...