因果机器学习EconML | 客户细分案例——基于机器学习的异质性处理效果估计
机器学习的最大承诺之一是在众多应用领域中实现决策自动化。在大多数数据驱动的个性化决策场景中出现的一个核心问题是对异质性处理效果的估计:作为处理样本的一组可观察特征的函数,干预对感兴趣结果的影响是什么?例如,这个问题出现在个性化定价中,其目标是根据消费者的特征来估计价格折扣对需求的影响。同样,它出现在医学试验中,其目标是根据患者特征估计药物治疗对患者临床反应的影响。在许多此类环境中,我们有大量的观察数据,其中处理是通过一些未知的策略选择的,并且运行 A/B 测试的能力是有限的。
EconML 软件包在计量经济学和机器学习的交叉点实施了文献中的最新技术,这些技术通过基于机器学习的方法解决了异构治疗效果估计的问题。这些新方法在模拟效应异质性方面提供了很大的灵活性(通过随机森林、提升、套索和神经网络等技术),同时利用因果推理和计量经济学的技术来保留对学习模型的因果解释,并且很多时候还通过构建有效的置信区间提供统计有效性。
客户细分:基于机器学习的异质性处理效果估计
背景
媒体订阅服务希望通过个性化定价计划提供有针对性的折扣。
问题
他们观察了客户的许多特征,但不确定哪些客户对较低的价格反应最强烈。
解决方案
EconML 的 DML 估算器使用现有数据中的价格变化以及一组丰富的用户特征来估计随多个客户特征而变化的异构价格敏感性。树解释器提供了关键功能的演示就绪摘要,这些功能解释了对折扣的响应能力的最大差异。
如今,业务决策者依靠估计干预措施的因果效应来回答有关战略转变的假设问题,例如以折扣促销特定产品、向网站添加新功能或增加销售团队的投资。然而,人们越来越感兴趣的是了解不同用户对这两种选择的不同反应,而不是了解是否为所有用户采取特定干预。确定对干预反应最强烈的用户的特征有助于制定规则,将未来的用户划分为不同的组。这有助于优化策略以使用最少的资源并获得最大的利润。
在本案例研究中,我们将使用个性化定价示例来解释 EconML 和 DoWhy 库如何适应这个问题并提供强大而可靠的因果解决方案。
背景
多年来,全球在线媒体市场正在快速增长。媒体公司总是有兴趣吸引更多用户进入市场并鼓励他们购买更多歌曲或成为会员。在此示例中,我们将考虑这样一个场景:一家媒体公司正在进行的一项实验是根据其当前用户的收入水平为其当前用户提供小额折扣(10%、20% 或 0),以提高他们购买的可能性。目标是了解不同收入水平的人的需求的异质价格弹性,了解哪些用户对小额折扣的反应最强烈。此外,他们的最终目标是确保在降低一些消费者的价格的同时,需求得到足够的提高以提高整体收入。
EconML 和 DoWhy 库在实施此解决方案时相辅相成。一方面,DoWhy 库可以帮助构建因果模型,识别因果效应并测试因果假设。另一方面,EconML 基于 DML 的估算器可用于获取现有数据中的折扣变化以及一组丰富的用户特征,以估计随多个客户特征而变化的异构价格敏感性。然后,SingleTreeCateInterpreter 提供了关键功能的演示就绪摘要,这些功能解释了对折扣的响应能力的最大差异,SingleTreePolicyInterpreter 建议了一个关于谁应该获得折扣以增加收入(不仅仅是需求)的策略,这可以帮助公司在未来为这些用户设置最佳价格。
``# Some imports to get us started
# Utilities
import numpy as np
import pandas as pd
from networkx.drawing.nx_pydot import to_pydot
from IPython.display import Image, display
# Generic ML imports
from sklearn.preprocessing import PolynomialFeatures
from sklearn.ensemble import GradientBoostingRegressor
# EconML imports
from econml.dml import LinearDML, CausalForestDML
from econml.cate_interpreter import SingleTreeCateInterpreter, SingleTreePolicyInterpreter
import matplotlib.pyplot as plt
import warnings
warnings.simplefilter('ignore')
%matplotlib inline
数据
该数据集*有 ~10,000 个观察结果,包括 9 个连续和分类变量,代表用户的特征和在线行为历史,例如年龄、日志收入、以前的购买、每周以前的在线时间等。
我们定义以下变量:
| Feature Name | Type | Details |
|---|---|---|
| account_age | W | user’s account age |
| age | W | user’s age |
| avg_hours | W | the average hours user was online per week in the past |
| days_visited | W | the average number of days user visited the website per week in the past |
| friend_count | W | number of friends user connected in the account |
| has_membership | W | whether the user had membership |
| is_US | W | whether the user accesses the website from the US |
| songs_purchased | W | the average songs user purchased per week in the past |
| income | X | user’s income |
| price | T | the price user was exposed during the discount season (baseline price * small discount) |
| demand | Y | songs user purchased during the discount season |
为了保护公司隐私,我们这里以模拟数据为例。数据是综合生成的,特征分布与真实分布不对应。然而,功能名称保留了它们的名称和含义。
处理和结果是使用以下函数生成的:
T = { 1 with p = 0.2 , 0.9 with p = 0.3 , if income < 1 0.8 with p = 0.5 , 1 with p = 0.7 , 0.9 with p = 0.2 , if income ≥ 1 0.8 with p = 0.1 , T = \begin{cases} 1 & \text{with } p=0.2, \\ 0.9 & \text{with } p=0.3, & \text{if income} < 1 \\ 0.8 & \text{with } p=0.5, \\ \\ 1 & \text{with } p=0.7, \\ 0.9 & \text{with } p=0.2, & \text{if income} \geq 1 \\ 0.8 & \text{with } p=0.1, \\ \end{cases} T=⎩ ⎨ ⎧10.90.810.90.8with p=0.2,with p=0.3,with p=0.5,with p=0.7,with p=0.2,with p=0.1,if income<1if income≥1
γ ( X ) = − 3 − 14 ⋅ { income < 1 } \begin{align} \gamma(X) & = -3 - 14 \cdot \{\text{income} < 1\} \end{align} γ(X)=−3−14⋅{income<1}
KaTeX parse error: Expected 'EOF', got '_' at position 54: …\cdot \text{avg_̲hours} + 5 \cdo…
Y = γ ( X ) ⋅ T + β ( X , W ) \begin{align} Y = \gamma(X) \cdot T + \beta(X, W) \end{align} Y=γ(X)⋅T+β(X,W)
# 导入样本定价数据
file_url = "https://msalicedatapublic.z5.web.core.windows.net/datasets/Pricing/pricing_sample.csv"
train_data = pd.read_csv(file_url)
# 定义估计器输入
train_data["log_demand"] = np.log(train_data["demand"])
train_data["log_price"] = np.log(train_data["price"])Y = train_data["log_demand"].values
T = train_data["log_price"].values
X = train_data[["income"]].values # features
confounder_names = ["account_age", "age", "avg_hours", "days_visited", "friends_count", "has_membership","is_US", "songs_purchased"]
W = train_data[confounder_names].values
# 获取测试数据
X_test = np.linspace(0, 5, 100).reshape(-1, 1)
X_test_data = pd.DataFrame(X_test, columns=["income"])
利用 DoWhy 创建因果模型并确定因果效应
我们用 DoWhy 来定义因果假设。例如,我们可以将我们认为是混杂因素的特征和我们认为会影响效应异质性的特征包括在内。定义了这些假设后,DoWhy 就能为我们生成因果图,并利用该图首先确定因果效应。
# 启动 EconML 类别估计器
est = LinearDML(model_y=GradientBoostingRegressor(), model_t=GradientBoostingRegressor(),featurizer=PolynomialFeatures(degree=2, include_bias=False))
# 通过 dowhy 进行拟合
est_dw = est.dowhy.fit(Y, T, X=X, W=W,outcome_names=["log_demand"], treatment_names=["log_price"], feature_names=["income"],confounder_names=confounder_names, inference="statsmodels")
# 可视化因果图
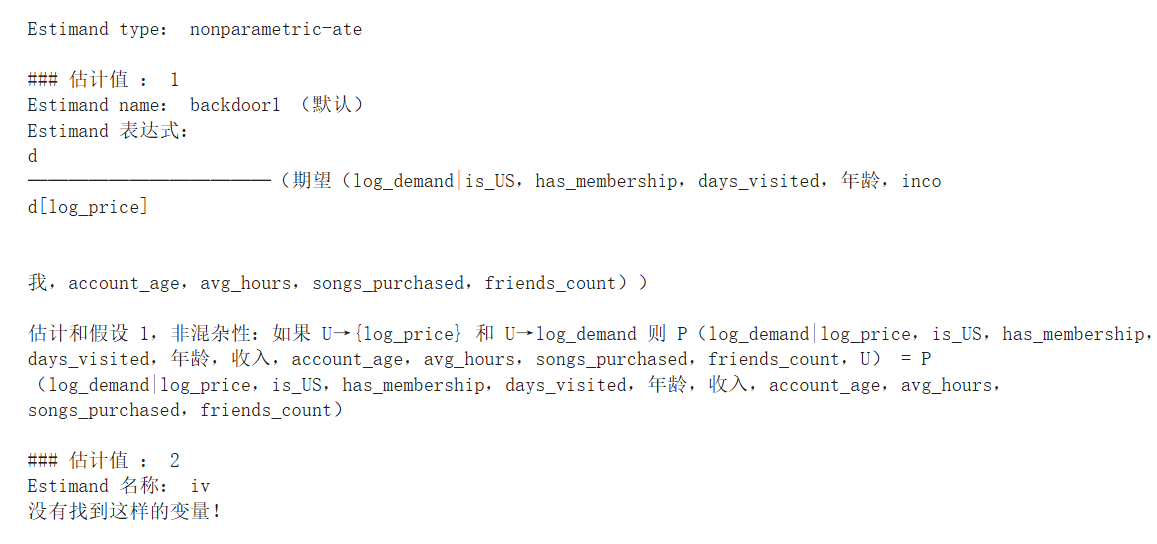
try:# 尝试漂亮地打印图表。需要 pydot 和 pygraphvizdisplay(Image(to_pydot(est_dw._graph._graph).create_png()))
except Exception:# 回到默认的图表视图est_dw.view_model(layout=None)

identified_estimand = est_dw.identified_estimand_
print(identified_estimand)
使用 EconML 获取因果效应
基于上面确定的因果效应,我们使用 EconML 按如下方式拟合模型:
l o g ( Y ) = θ ( X ) ⋅ l o g ( T ) + f ( X , W ) + ϵ l o g ( T ) = g ( X , W ) + η \begin{align} log(Y) & = \theta(X) \cdot log(T) + f(X,W) + \epsilon \\ log(T) & = g(X,W) + \eta \end{align} log(Y)log(T)=θ(X)⋅log(T)+f(X,W)+ϵ=g(X,W)+η
其中 ϵ , η \epsilon, \eta ϵ,η 是不相关的误差项。
我们在这里拟合的模型与上述数据生成函数并不完全匹配,但如果它们是一个良好的近似,就可以帮助我们制定一个有效的折扣策略。尽管模型存在误设定问题,我们仍希望看到基于 DML 的估计器能够捕捉到 θ ( X ) \theta(X) θ(X) 的正确趋势,并且推荐的策略在收入方面能优于其他基线策略(例如始终提供折扣)。由于数据生成过程和我们拟合的模型之间存在不匹配,实际上不存在唯一真实的 θ ( X ) \theta(X) θ(X)(真实的弹性不仅与 X 有关,还与 T 和 W 相关)。然而,根据上述数据生成过程,我们仍然可以计算真实 θ ( X ) \theta(X) θ(X) 的范围用于比较。
# 定义给定 DGP 的基础处理效果函数
def gamma_fn(X):return -3 - 14 * (X["income"] < 1)def beta_fn(X):return 20 + 0.5 * (X["avg_hours"]) + 5 * (X["days_visited"] > 4)def demand_fn(data, T):Y = gamma_fn(data) * T + beta_fn(data)return Ydef true_te(x, n, stats):if x < 1:subdata = train_data[train_data["income"] < 1].sample(n=n, replace=True)else:subdata = train_data[train_data["income"] >= 1].sample(n=n, replace=True)te_array = subdata["price"] * gamma_fn(subdata) / (subdata["demand"])if stats == "mean":return np.mean(te_array)elif stats == "median":return np.median(te_array)elif isinstance(stats, int):return np.percentile(te_array, stats)
# 得到真实处理效果的估计值和范围
truth_te_estimate = np.apply_along_axis(true_te, 1, X_test, 1000, "mean") # estimate
truth_te_upper = np.apply_along_axis(true_te, 1, X_test, 1000, 95) # upper level
truth_te_lower = np.apply_along_axis(true_te, 1, X_test, 1000, 5) # lower level
参数异质性
首先,我们可以尝试在假设 θ ( X ) \theta(X) θ(X) 为多项式形式的情况下,学习处理效应的线性投影。为此,我们使用了 LinearDML 估计器。由于我们对这些模型没有任何先验假设,我们使用通用的梯度提升树估计器从数据中学习预期的价格和需求。
lineardml_estimate = est_dw.estimate_
print(lineardml_estimate)

# 获取处理效果及其置信区间
te_pred = est_dw.effect(X_test).flatten()
te_pred_interval = est_dw.effect_interval(X_test)
# 比较估计值和真实值
plt.figure(figsize=(10, 6))
plt.plot(X_test.flatten(), te_pred, label="Sales Elasticity Prediction")
plt.plot(X_test.flatten(), truth_te_estimate, "--", label="True Elasticity")
plt.fill_between(X_test.flatten(),te_pred_interval[0].flatten(),te_pred_interval[1].flatten(),alpha=0.2,label="95% Confidence Interval",
)
plt.fill_between(X_test.flatten(),truth_te_lower,truth_te_upper,alpha=0.2,label="True Elasticity Range",
)
plt.xlabel("Income")
plt.ylabel("Songs Sales Elasticity")
plt.title("Songs Sales Elasticity vs Income")
plt.legend(loc="lower right")
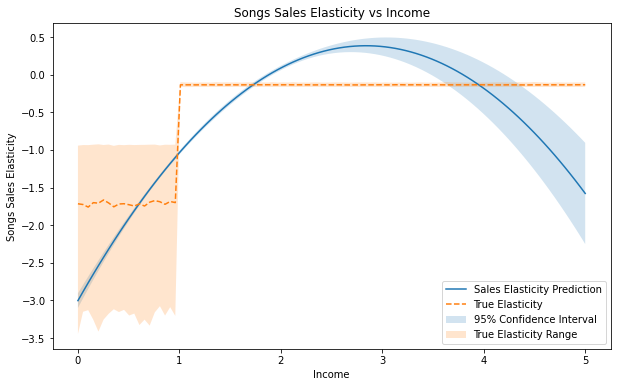
从上图可以清楚地看出,真正的处理效果是收入的非线性函数,当收入小于 1 时弹性约为 -1.75,当收入大于 1 时,弹性较小。该模型拟合二次处理效应,这不是一个很好的拟合。但它仍然抓住了总体趋势:弹性是负的,如果人们的收入更高,他们对价格变化的敏感度就会降低。
# 得到最终的系数和截距总结
est_dw.summary(feature_names=["income"])
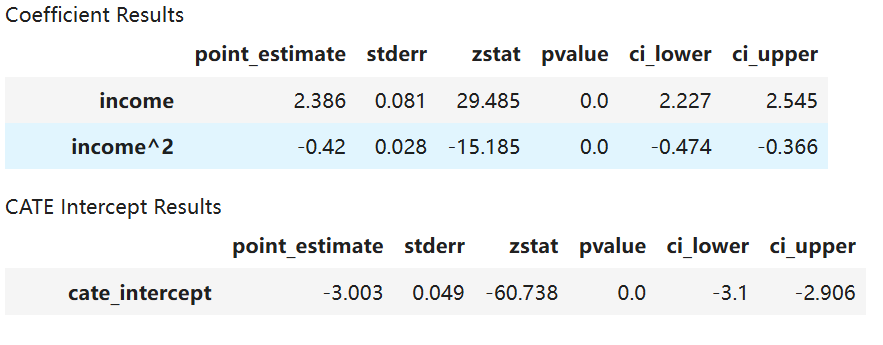
LinearDML 估计器还可以返回最终模型的系数和截距的摘要,其中包括点估计、p 值以及置信区间。从上表可以看出, i n c o m e income income 对结果具有正向影响,而 i n c o m e 2 {income}^2 income2 则具有负向影响,且这两者均在统计上显著。
非参数异质性
既然我们已经知道真正的处理效应函数是非线性的,那么让我们使用 CausalForestDML 拟合另一个模型,该模型假设处理效应的完全非参数估计。
# 启动 EconML 类别估计器
est_nonparam = CausalForestDML(model_y=GradientBoostingRegressor(), model_t=GradientBoostingRegressor())
# 通过 dowhy 进行拟合
est_nonparam_dw = est_nonparam.dowhy.fit(Y, T, X=X, W=W, outcome_names=["log_demand"], treatment_names=["log_price"],feature_names=["income"], confounder_names=confounder_names, inference="blb")
# 获取处理效果及其置信区间
te_pred = est_nonparam_dw.effect(X_test).flatten()
te_pred_interval = est_nonparam_dw.effect_interval(X_test)
# 比较估计值和真实值
plt.figure(figsize=(10, 6))
plt.plot(X_test.flatten(), te_pred, label="Sales Elasticity Prediction")
plt.plot(X_test.flatten(), truth_te_estimate, "--", label="True Elasticity")
plt.fill_between(X_test.flatten(),te_pred_interval[0].flatten(),te_pred_interval[1].flatten(),alpha=0.2,label="95% Confidence Interval",
)
plt.fill_between(X_test.flatten(),truth_te_lower,truth_te_upper,alpha=0.2,label="True Elasticity Range",
)
plt.xlabel("Income")
plt.ylabel("Songs Sales Elasticity")
plt.title("Songs Sales Elasticity vs Income")
plt.legend(loc="lower right")
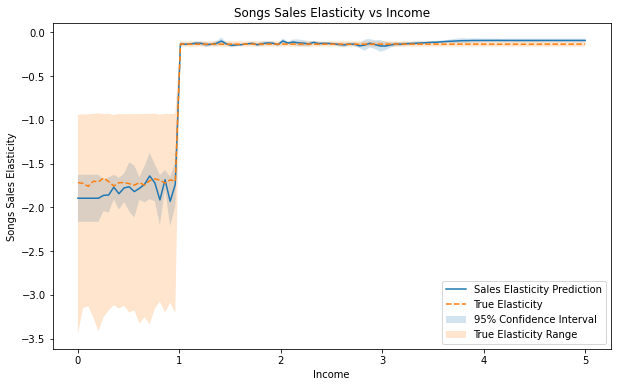
我们注意到该模型比 LinearDML 拟合得更好,95% 置信区间正确地涵盖了真实的处理效果估计值,并捕获了收入约为 1 时的变化。总体而言,该模型显示,低收入人群比高收入人群对价格变化更敏感。
使用 DoWhy 检验估计稳健性
添加随机常见原因
我们的估计值对增加另一个混杂因素有多稳健?我们使用 DoWhy 来测试这个!
res_random = est_nonparam_dw.refute_estimate(method_name="random_common_cause", num_simulations=5)
print(res_random)

添加未观察到的常见原因
我们对未观察到的混杂因素的估计有多稳健?由于我们假设模型处于非混杂性下,因此添加未观察到的混杂因素可能会使估计值产生偏差。我们使用 DoWhy 来测试这个!
res_unobserved = est_nonparam_dw.refute_estimate(method_name="add_unobserved_common_cause",confounders_effect_on_treatment="linear",confounders_effect_on_outcome="linear",effect_strength_on_treatment=0.1,effect_strength_on_outcome=0.1,
)
print(res_unobserved)

用随机(安慰剂)变量替换处理
如果我们用噪声替换处理变量,我们的估计值会发生什么变化?理想情况下,平均效果将与我们最初的估计大相径庭。我们使用 DoWhy 来调查!
res_placebo = est_nonparam_dw.refute_estimate(method_name="placebo_treatment_refuter", placebo_type="permute",num_simulations=3
)
print(res_placebo)
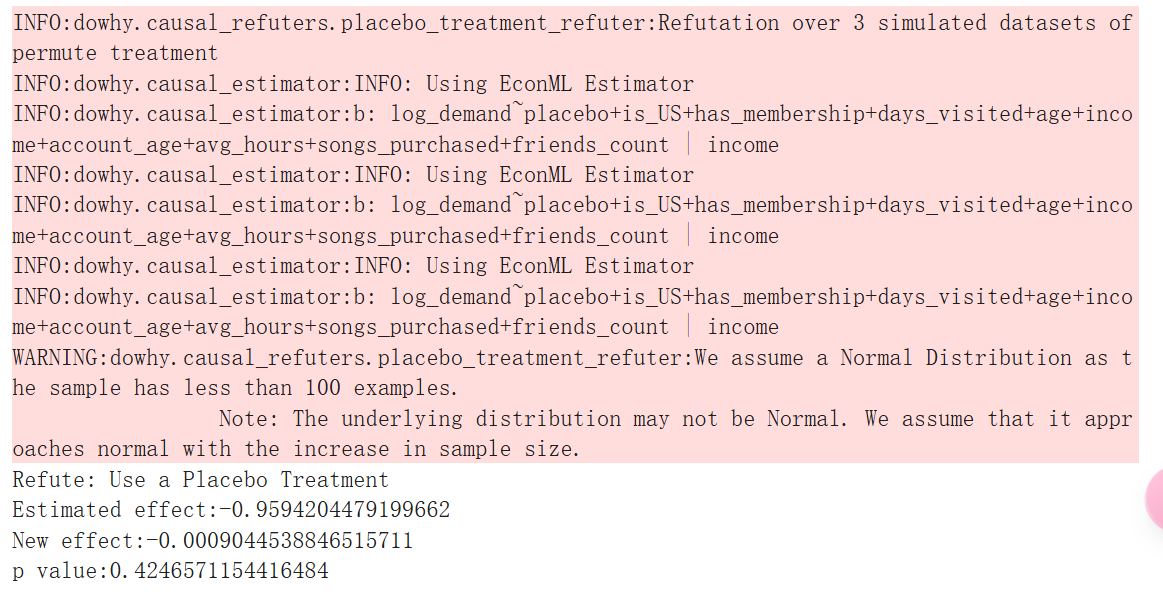
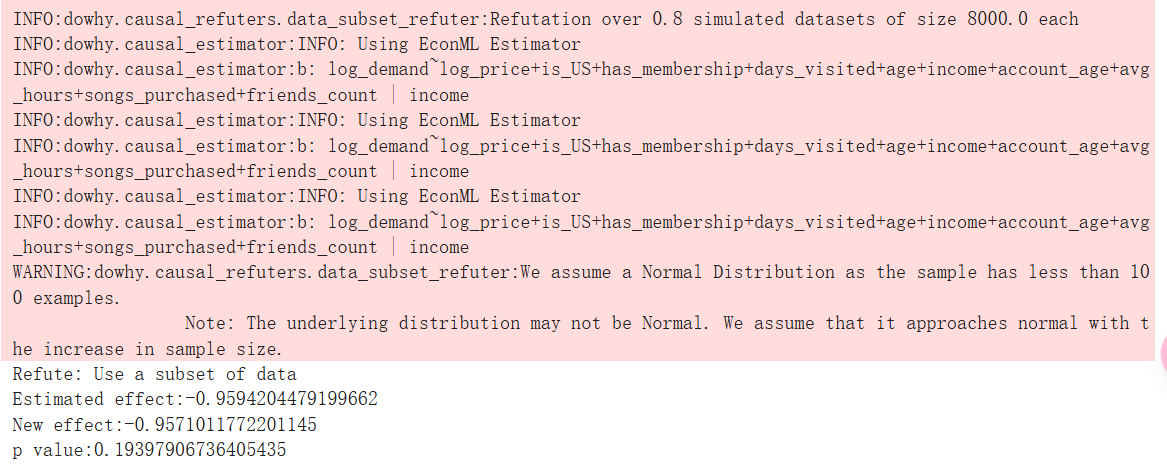
删除数据的随机子集
我们是否可以恢复数据子集的类似估计值?这说明了我们选择的估计器能够很好地泛化。我们使用 DoWhy 来调查这个问题!
res_subset = est_nonparam_dw.refute_estimate(method_name="data_subset_refuter", subset_fraction=0.8,num_simulations=3)
print(res_subset)
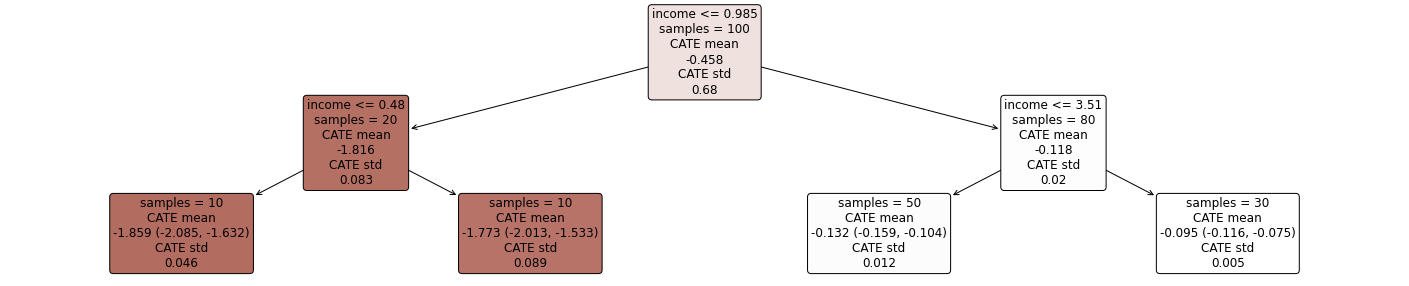
了解 EconML 的处理效果
EconML 包括可解释性工具,以更好地了解治疗效果。处理效果可能很复杂,但通常我们感兴趣的是简单的规则,这些规则可以区分积极响应的用户、保持中立的用户和对提议的更改做出消极响应的用户。
EconML 的 SingleTreeCateInterpreter 通过对任何 EconML 估计器输出的治疗效果训练单个决策树来提供可遍历性。在下图中,我们可以看到深红色用户对折扣的反应强烈,而白色用户对折扣的反应较轻。
intrp = SingleTreeCateInterpreter(include_model_uncertainty=True, max_depth=2, min_samples_leaf=10)
intrp.interpret(est_nonparam_dw, X_test)
plt.figure(figsize=(25, 5))
intrp.plot(feature_names=["income"], fontsize=12)
使用 EconML 做出策略决策
我们希望做出政策决策,以实现收入而不是需求最大化。在此方案中,
R e v = Y ⋅ T = exp l o g ( Y ) ⋅ T = exp ( θ ( X ) ⋅ l o g ( T ) + f ( X , W ) + ϵ ) ⋅ T = exp ( f ( X , W ) + ϵ ) ⋅ T ( θ ( X ) + 1 ) \begin{align} Rev & = Y \cdot T \\ & = \exp^{log(Y)} \cdot T\\ & = \exp^{(\theta(X) \cdot log(T) + f(X,W) + \epsilon)} \cdot T \\ & = \exp^{(f(X,W) + \epsilon)} \cdot T^{(\theta(X)+1)} \end{align} Rev=Y⋅T=explog(Y)⋅T=exp(θ(X)⋅log(T)+f(X,W)+ϵ)⋅T=exp(f(X,W)+ϵ)⋅T(θ(X)+1)
随着价格的下降,只有当 θ ( X ) + 1 < 0 \theta(X)+1<0 θ(X)+1<0 时,收入才会增加。因此,这里设置 sample_treatment_cast=-1 来学习应该为哪些客户提供小额折扣以最大化收入。
EconML 库包含诸如 SingleTreePolicyInterpreter 的策略可解释性工具,该工具结合了处理成本和处理效应,用于学习关于哪些客户可以获利目标的简单规则。在下图中可以看到,模型建议对收入低于 0.985 0.985 0.985 的人给予折扣,而对其他人则维持原价。
intrp = SingleTreePolicyInterpreter(risk_level=0.05, max_depth=2, min_samples_leaf=1, min_impurity_decrease=0.001)
intrp.interpret(est_nonparam_dw, X_test, sample_treatment_costs=-1)
plt.figure(figsize=(25, 5))
intrp.plot(feature_names=["income"], treatment_names=["Discount", "No-Discount"], fontsize=12)

现在,让我们将我们的策略与其他基线策略进行比较!我们的模型会向哪些客户提供小额折扣,对于此实验,我们将为这些用户设置 10% 的折扣水平。由于模型指定有误,因此我们不会期望具有较大折扣的良好结果。在这里,由于我们知道基本事实,因此我们可以评估此策略的价值。
# 定义函数来计算收入
def revenue_fn(data, discount_level1, discount_level2, baseline_T, policy):policy_price = baseline_T * (1 - discount_level1) * policy + baseline_T * (1 - discount_level2) * (1 - policy)demand = demand_fn(data, policy_price)rev = demand * policy_pricereturn rev
policy_dic = {}
# 我们的政策
policy = intrp.treat(X)
policy_dic["Our Policy"] = np.mean(revenue_fn(train_data, 0, 0.1, 1, policy))
## 之前的策略
policy_dic["Previous Strategy"] = np.mean(train_data["price"] * train_data["demand"])
##给大家折扣
policy_dic["Give Everyone Discount"] = np.mean(revenue_fn(train_data, 0.1, 0, 1, np.ones(len(X))))
## 不给折扣
policy_dic["Give No One Discount"] = np.mean(revenue_fn(train_data, 0, 0.1, 1, np.ones(len(X))))
## 遵循我们的政策,但团体给予-10%折扣,不建议给予折扣
policy_dic["Our Policy + Give Negative Discount for No-Discount Group"] = np.mean(revenue_fn(train_data,-0.1, 0.1, 1, policy))
## 给每个人-10% 的折扣
policy_dic["Give Everyone Negative Discount"] = np.mean(revenue_fn(train_data, -0.1, 0, 1, np.ones(len(X))))
# 获取策略汇总表
res = pd.DataFrame.from_dict(policy_dic, orient="index", columns=["Revenue"])
res["Rank"] = res["Revenue"].rank(ascending=False)
res

我们击败了基准政策!我们的政策获得的收入最高,除了提高 No-Discount 组的价格的政策。这意味着我们目前的基准价格很低,但我们细分用户的方式确实有助于增加收入!
结论
在项目中,我们演示了使用 EconML 和 DoWhy 的强大功能:
- 即使模型指定错误,也能正确估计处理效果
- 测试因果假设并调查结果估计的稳健性
- 解释由此产生的个体水平治疗效果
- 使策略决策击败先前和基线策略
相关文章:
因果机器学习EconML | 客户细分案例——基于机器学习的异质性处理效果估计
机器学习的最大承诺之一是在众多应用领域中实现决策自动化。在大多数数据驱动的个性化决策场景中出现的一个核心问题是对异质性处理效果的估计:作为处理样本的一组可观察特征的函数,干预对感兴趣结果的影响是什么?例如,这个问题出…...

找到最大“葫芦”组合
文章目录 问题描述解题思路分析1. 数据预处理2. 特殊情况处理3. 普通情况计算4. 结果输出 Java代码实现复杂度分析与优化 在经典德州扑克中,“葫芦”是一种较强的牌型。它由五张牌组成,其中三张牌面值相同,另外两张牌面值也相同。本文将探讨一…...

shell(9)完结
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...

【计算机网络】多路转接之select
系统提供select()来实现多路转接 IO 等 拷贝 -> select()只负责等待,可以一次等待多个fd select()本身没有数据拷贝的能力,拷贝要read()/write()来完成 一、select的使用 int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exc…...

数据库-基础理论
文章目录 前言一、ORM框架二、ACID原则三、事务Transaction四、N1问题五、Normalization三范式六、FMEA方法论(Failure Mode and Effects Analysis)七、Profiling和PerformanceSchema查询分析 前言 基础理论 ORM框架、ACID原则、事务Transaction、N1问…...

Linux——1_系统的延迟任务及定时任务
系统的延迟任务及定时任务 在系统中我们的维护工作大多数时在服务器行对闲置时进行 我们需要用延迟任务来解决自动进行的一次性的维护 延迟任务时一次性的,不会重复执行 当延迟任务产生输出后,这些输出会以邮件的形式发送给延迟任务发起者 在RHEL9中…...

C++ 矩阵旋转
【问题描述】 编写一个程序,读入一个矩阵,输出该矩阵以第一行第一列数字为中心,顺时针旋转90度后的新矩阵,例如: 输入的矩阵为: 1 2 3 4 5 6 顺时针旋转90度后输出的矩阵为: 4 1 5 2 6 3 【输入…...

Docker学习笔记整理
这周不知道写点啥内容做个分享,但还是秉持学会分享的精神,粗略放一些Docker相关的问题和解答吧,后面有机会再补补再深挖深挖o(>﹏<)o 1. 容器VS虚拟机 虚拟机是一种带环境安装的解决方案(资源完全隔离),有以下缺…...
计算机组成原理期末试题三(含答案)
本科生期末试卷 三 一.选择题(每小题1分,共10分) 1.冯诺依曼机工作的基本方式的特点是______。 A 多指令流单数据流 B 按地址访问并顺序执行指令 C 堆栈操作 D 存贮器按内容选择地址 2.在机器数______中&a…...

django+boostrap实现注册
一、django介绍 Django 是一个高级的 Python 网络框架,可以快速开发安全和可维护的网站。由经验丰富的开发者构建,Django 负责处理网站开发中麻烦的部分,因此你可以专注于编写应用程序,而无需重新开发。 它是免费和开源的&#x…...

C++初阶——类和对象(下)
目录 1、再探构造函数——初始化列表 2、类型转换 3、static成员 4、友元 5、内部类 6、匿名对象 7、对象拷贝时编译器的优化(了解) 1、再探构造函数——初始化列表 1. 构造函数初始化除了使用函数体内赋值,还有一种方式——初始化列表, 初始化列…...
趋势洞察|AI 能否带动裸金属 K8s 强势崛起?
随着容器技术的不断成熟,不少企业在开展私有化容器平台建设时,首要考虑的问题就是容器的部署环境——是采用虚拟机还是物理机运行容器?在往期“虚拟化 vs. 裸金属*”系列文章中,我们分别对比了容器部署在虚拟化平台和物理机上的架…...

idea初始化设置
下载idea: https://www.jetbrains.com/idea/ 安装idea 安装插件: Rainbow BracketsLombokMybatisXSonarLintMaven HelperCodeGeeX(国内AI插件可用) 设置idea注释模板: 设置代码注释模板: https://blo…...

LINUX系统编程之——环境变量
目录 环境变量 1、基本概念 2、查看环境变量的方法 三、查看PATH环境变量的內容 1)不带路径也能运行的自己的程序 a、将自己的程序直接添加到PATH指定的路径下 b、将程序所在的路径添加到PATH环境中 四、环境变量与本地变量 1、本地变量创建 2、环境变量创…...

健康老龄化:适合老年人的播客
什么是播客 什么是播客?好问题。对于那些还不熟悉这个术语的人来说,播客有点像在线广播或电视节目。这是一个可下载、可流式传输的程序,定期发布剧集,时长从几分钟到一个多小时不等。您可以在计算机、智能手机或平板电脑上…...

家庭智慧工程师:如何通过科技提升家居生活质量
在今天的数字化时代,家居生活已经不再只是简单的“住”的地方。随着物联网(IoT)、人工智能(AI)以及自动化技术的快速发展,越来越多的家庭开始拥抱智慧家居技术,将他们的家变得更加智能化、便捷和…...

Milvus概念
非结构化数据、嵌入和 Milvus 非结构化数据(如文本、图像、音频)格式多样,蕴含丰富的语义信息,使其分析变得复杂。为了管理这种复杂性,嵌入技术被用来将非结构化数据转换为数值向量,这些向量能够捕捉数据的…...

为什么调用 setState 而不是直接改变 state
在React中,调用setState方法而不是直接改变state的原因涉及多个方面,包括性能优化、状态管理的可预测性、React的设计理念等。以下是对这些原因的详细解释: 1. 性能优化 异步更新与批量处理:setState是异步执行的,Rea…...

【Python爬虫五十个小案例】爬取豆瓣电影Top250
博客主页:小馒头学python 本文专栏: Python爬虫五十个小案例 专栏简介:分享五十个Python爬虫小案例 🪲前言 在这篇博客中,我们将学习如何使用Python爬取豆瓣电影Top250的数据。我们将使用requests库来发送HTTP请求,…...

cocos creator 3.8 物理碰撞器Collider+刚体RigidBody 8
遇到一个朋友,你来就行的朋友,我过去了,管吃管住,这样的朋友真的很难求。 最近离职了,很难想象,一份策划书一天能给你改n次,一周能郁闷,上一个功能没搞完,让你搞下一个功…...

GetQzonehistory:永久保存QQ空间记忆的终极免费解决方案
GetQzonehistory:永久保存QQ空间记忆的终极免费解决方案 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字时代,我们的青春记忆大多存储在QQ空间里。那些深夜…...

DeepSeek免费额度到底能跑几个大模型?揭秘2024最新配额规则与5个隐藏续费技巧
更多请点击: https://codechina.net 第一章:DeepSeek免费额度到底能跑几个大模型? DeepSeek 官方为新注册用户提供 100 万 Token 的免费调用额度(截至 2024 年底政策),但不同模型的 Token 消耗差异显著——…...

如何高效使用健康提醒工具:完整配置指南
如何高效使用健康提醒工具:完整配置指南 【免费下载链接】stretchly The break time reminder app 项目地址: https://gitcode.com/gh_mirrors/st/stretchly 在数字时代,我们每天花费大量时间盯着电脑屏幕,眼睛疲劳和身体僵硬已成为现…...

为Nodejs后端服务配置Taotoken多模型聚合API调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Nodejs后端服务配置Taotoken多模型聚合API调用 基础教程类,指导Nodejs开发者将Taotoken服务集成到现有后端项目中&am…...

【稻米计数】形态学稻米计数【含Matlab源码 15562期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab领域博客之家💞&…...

网络性能周报 - {日期范围}
网络性能周报 - {日期范围} 【免费下载链接】iperf3-win-builds iperf3 binaries for Windows. Benchmark your network limits. 项目地址: https://gitcode.com/gh_mirrors/ip/iperf3-win-builds 执行摘要 平均带宽:{bandwidth} Mbps ({变化率}%)最大延迟&…...

使用curl命令直接测试Taotoken聊天补全接口的完整指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令直接测试Taotoken聊天补全接口的完整指南 在开发或调试大模型应用时,有时我们希望在无需依赖特定编程语言…...

从0到1构建DeepSeek企业级隔离体系:4类租户场景×3种SLA等级×2套审计回溯机制
更多请点击: https://intelliparadigm.com 第一章:DeepSeek资源隔离方案的总体架构设计 DeepSeek资源隔离方案以“多租户安全边界 动态资源契约”为核心设计理念,构建覆盖计算、内存、存储与网络四维资源的统一隔离层。该架构采用分层解耦结…...
,已交付27家头部客户验证)
从原始日志到业务洞察只要1次SQL:DeepSeek日志分析方案支持自然语言查询(“查上周支付失败且含Redis超时的订单”),已交付27家头部客户验证
更多请点击: https://intelliparadigm.com 第一章:DeepSeek日志分析方案的核心价值与落地成效 DeepSeek日志分析方案并非通用日志管道的简单复刻,而是面向大模型训练与推理场景深度定制的可观测性基础设施。其核心价值体现在对高吞吐、多模态…...

Legacy iOS Kit:让旧款iPhone/iPad重获新生的终极指南
Legacy iOS Kit:让旧款iPhone/iPad重获新生的终极指南 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...