多线程 相关面试集锦
- 什么是线程?
1、线程是操作系统能够进⾏运算调度的最⼩单位,它被包含在进程之中,是进程中的实际运作单位,可以使⽤多线程对
进⾏运算提速。
⽐如,如果⼀个线程完成⼀个任务要100毫秒,那么⽤⼗个线程完成改任务只需10毫秒
- 什么是线程安全和线程不安全?
1、线程安全
线程安全: 就是多线程访问时,采⽤了加锁机制,当⼀个线程访问该类的某个数据时,进⾏保护,其他线程不能进⾏
访问,直到该线程读取完,其他线程才可使⽤。不会出现数据不⼀致或者数据污染。
Vector 是⽤同步⽅法来实现线程安全的, ⽽和它相似的ArrayList不是线程安全的。
2、线程不安全
线程不安全:就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据
线程安全问题都是由全局变量及静态变量引起的。
若每个线程中对全局变量、静态变量只有读操作,⽽⽆写操作,⼀般来说,这个全局变量是线程安全的;若有多个
线程同时执⾏写操作,⼀般都需要考虑线程同步,否则的话就可能影响线程安全。
- 什么是⾃旋锁?
⾃旋锁是SMP架构中的⼀种low-level的同步机制。
1、当线程A想要获取⼀把⾃旋锁⽽该锁⼜被其它线程锁持有时,线程A会在⼀个循环中⾃旋以检测锁是不是已经可⽤了。
2、⾃选锁需要注意:
由于⾃旋时不释放CPU,因⽽持有⾃旋锁的线程应该尽快释放⾃旋锁,否则等待该⾃旋锁的线程会⼀直在那⾥⾃
旋,这就会浪费CPU时间。
持有⾃旋锁的线程在sleep之前应该释放⾃旋锁以便其它线程可以获得⾃旋锁。
3、⽬前的JVM实现⾃旋会消耗CPU,如果⻓时间不调⽤doNotify⽅法,doWait⽅法会⼀直⾃旋,CPU会消耗太⼤
4、⾃旋锁⽐较适⽤于锁使⽤者保持锁时间⽐较短的情况,这种情况⾃旋锁的效率⽐较⾼。
5、⾃旋锁是⼀种对多处理器相当有效的机制,⽽在单处理器⾮抢占式的系统中基本上没有作⽤。
- 什么是CAS?
1、CAS(compare and swap)的缩写,中⽂翻译成⽐较并交换。
2、CAS 不通过JVM,直接利⽤java本地⽅ JNI(Java Native Interface为JAVA本地调⽤),直接调⽤CPU 的cmpxchg(是
汇编指令)指令。
3、利⽤CPU的CAS指令,同时借助JNI来完成Java的⾮阻塞算法,实现原⼦操作。其它原⼦操作都是利⽤类似的特性完成
的。
4、整个java.util.concurrent都是建⽴在CAS之上的,因此对于synchronized阻塞算法,J.U.C在性能上有了很⼤的提升。
5、CAS是项乐观锁技术,当多个线程尝试使⽤CAS同时更新同⼀个变量时,只有其中⼀个线程能更新变量的值,⽽其它
线程都失败,失败的线程并不会被挂起,⽽是被告知这次竞争中失败,并可以再次尝试。
1、使⽤CAS在线程冲突严重时,会⼤幅降低程序性能;CAS只适合于线程冲突较少的情况使⽤。
2、synchronized在jdk1.6之后,已经改进优化。synchronized的底层实现主要依靠Lock-Free的队列,基本思路是⾃旋后阻塞,竞
争切换后继续竞争锁,稍微牺牲了公平性,但获得了⾼吞吐量。在线程冲突较少的情况下,可以获得和CAS类似的性能;⽽线
程冲突严重的情况下,性能远⾼于CAS。
- 什么是乐观锁和悲观锁?
1、悲观锁
Java在JDK1.5之前都是靠synchronized关键字保证同步的,这种通过使⽤⼀致的锁定协议来协调对共享状态的访
问,可以确保⽆论哪个线程持有共享变量的锁,都采⽤独占的⽅式来访问这些变量。独占锁其实就是⼀种悲观锁,所以
可以说synchronized是悲观锁。
2、乐观锁
乐观锁( Optimistic Locking)其实是⼀种思想。相对悲观锁⽽⾔,乐观锁假设认为数据⼀般情况下不会造成冲突,
所以在数据进⾏提交更新的时候,才会正式对数据的冲突与否进⾏检测,如果发现冲突了,则让返回⽤户错误的信息,
让⽤户决定如何去做。
memcached使⽤了cas乐观锁技术保证数据⼀致性。
- 什么是AQS?
1、AbstractQueuedSynchronizer简称AQS,是⼀个⽤于构建锁和同步容器的框架。事实上concurrent包内许多类都是基
于AQS构建,例如ReentrantLock,Semaphore,CountDownLatch,ReentrantReadWriteLock,FutureTask等。AQS解
决了在实现同步容器时设计的⼤量细节问题。
2、AQS使⽤⼀个FIFO的队列表示排队等待锁的线程,队列头节点称作“哨兵节点”或者“哑节点”,它不与任何线程关联。
其他的节点与等待线程关联,每个节点维护⼀个等待状态waitStatus。
- 什么是原⼦操作?在Java Concurrency API中有哪些原⼦类(atomic classes)?
1、原⼦操作是指⼀个不受其他操作影响的操作任务单元。原⼦操作是在多线程环境下避免数据不⼀致必须的⼿段。
2、int++并不是⼀个原⼦操作,所以当⼀个线程读取它的值并加1时,另外⼀个线程有可能会读到之前的值,这就会引发
错误。
3、为了解决这个问题,必须保证增加操作是原⼦的,在JDK1.5之前我们可以使⽤同步技术来做到这⼀点。
到JDK1.5,java.util.concurrent.atomic包提供了int和long类型的装类,它们可以⾃动的保证对于他们的操作是原⼦的并
且不需要使⽤同步。
- 什么是Executors框架?
Java通过Executors提供四种线程池,分别为:
1、newCachedThreadPool创建⼀个可缓存线程池,如果线程池⻓度超过处理需要,可灵活回收空闲线程,若⽆可
回收,则新建线程。
2、newFixedThreadPool 创建⼀个定⻓线程池,可控制线程最⼤并发数,超出的线程会在队列中等待。
3、newScheduledThreadPool 创建⼀个定⻓线程池,⽀持定时及周期性任务执⾏。
4、newSingleThreadExecutor 创建⼀个单线程化的线程池,它只会⽤唯⼀的⼯作线程来执⾏任务,保证所有任务
按照指定顺序(FIFO, LIFO, 优先级)执⾏。
- 什么是阻塞队列?如何使⽤阻塞队列来实现⽣产者-消费者模型?
1、JDK7提供了7个阻塞队列。(也属于并发容器)
i. ArrayBlockingQueue :⼀个由数组结构组成的有界阻塞队列。
ii. LinkedBlockingQueue :⼀个由链表结构组成的有界阻塞队列。
iii. PriorityBlockingQueue :⼀个⽀持优先级排序的⽆界阻塞队列。
iv. DelayQueue:⼀个使⽤优先级队列实现的⽆界阻塞队列。
v. SynchronousQueue:⼀个不存储元素的阻塞队列。
vi. LinkedTransferQueue:⼀个由链表结构组成的⽆界阻塞队列。
vii. LinkedBlockingDeque:⼀个由链表结构组成的双向阻塞队列。
2、概念:阻塞队列是⼀个在队列基础上⼜⽀持了两个附加操作的队列。
3、2个附加操作:
⽀持阻塞的插⼊⽅法:队列满时,队列会阻塞插⼊元素的线程,直到队列不满。
⽀持阻塞的移除⽅法:队列空时,获取元素的线程会等待队列变为⾮空。
- 什么是Callable和Future?
1、Callable 和 Future 是⽐较有趣的⼀对组合。当我们需要获取线程的执⾏结果时,就需要⽤到它们。Callable⽤于产⽣
结果,Future⽤于获取结果。
2、Callable接⼝使⽤泛型去定义它的返回类型。Executors类提供了⼀些有⽤的⽅法去在线程池中执⾏Callable内的任
务。由于Callable任务是并⾏的,必须等待它返回的结果。java.util.concurrent.Future对象解决了这个问题。
3、在线程池提交Callable任务后返回了⼀个Future对象,使⽤它可以知道Callable任务的状态和得到Callable返回的执⾏
结果。Future提供了get()⽅法,等待Callable结束并获取它的执⾏结果。
- 什么是FutureTask?
1、FutureTask可⽤于异步获取执⾏结果或取消执⾏任务的场景。通过传⼊Runnable或者Callable的任务给FutureTask,
直接调⽤其run⽅法或者放⼊线程池执⾏,之后可以在外部通过FutureTask的get⽅法异步获取执⾏结果,因此,
FutureTask⾮常适合⽤于耗时的计算,主线程可以在完成⾃⼰的任务后,再去获取结果。另外,FutureTask还可以确保即
使调⽤了多次run⽅法,它都只会执⾏⼀次Runnable或者Callable任务,或者通过cancel取消FutureTask的执⾏等。
2、futuretask可⽤于执⾏多任务、以及避免⾼并发情况下多次创建数据机锁的出现。
- 什么是同步容器和并发容器的实现?
1、同步容器
1、主要代表有Vector和Hashtable,以及Collections.synchronizedXxx等。
2、锁的粒度为当前对象整体。
3、迭代器是及时失败的,即在迭代的过程中发现被修改,就会抛出ConcurrentModificationException。
2、并发容器
1、主要代表有ConcurrentHashMap、CopyOnWriteArrayList、ConcurrentSkipListMap、ConcurrentSkipListSet。
2、锁的粒度是分散的、细粒度的,即读和写是使⽤不同的锁。
4、迭代器具有弱⼀致性,即可以容忍并发修改,不会抛出ConcurrentModificationException。
ConcurrentHashMap
采⽤分段锁技术,同步容器中,是⼀个容器⼀个锁,但在ConcurrentHashMap中,会将hash表的数组部分分成若⼲段,每段维
护⼀个锁,以达到⾼效的并发访问;
- 什么是多线程的上下⽂切换?
1、多线程:是指从软件或者硬件上实现多个线程的并发技术。
2、多线程的好处:
i. 使⽤多线程可以把程序中占据时间⻓的任务放到后台去处理,如图⽚、视屏的下载
ii. 发挥多核处理器的优势,并发执⾏让系统运⾏的更快、更流畅,⽤户体验更好
3、多线程的缺点:
1. ⼤量的线程降低代码的可读性;
2. 更多的线程需要更多的内存空间
3. 当多个线程对同⼀个资源出现争夺时候要注意线程安全的问题。
4、多线程的上下⽂切换:
CPU通过时间⽚分配算法来循环执⾏任务,当前任务执⾏⼀个时间⽚后会切换到下⼀个任务。但是,在切换前会保
存上⼀个任务的状态,以便下次切换回这个任务时,可以再次加载这个任务的状态
- ThreadLocal的设计理念与作⽤?
1、Java中的ThreadLocal类允许我们创建只能被同⼀个线程读写的变量。因此,如果⼀段代码含有⼀个ThreadLocal变量
的引⽤,即使两个线程同时执⾏这段代码,它们也⽆法访问到对⽅的ThreadLocal变量。1、概念:线程局部变量。在并发编程的时候,成员变量如果不做任何处理其实是线程不安全的,各个线程都在操作同⼀个变量,显
然是不⾏的,并且我们也知道volatile这个关键字也是不能保证线程安全的。那么在有⼀种情况之下,我们需要满⾜这样⼀个条件:变
量是同⼀个,但是每个线程都使⽤同⼀个初始值,也就是使⽤同⼀个变量的⼀个新的副本。这种情况之下ThreadLocal就⾮常适⽤,⽐
如说DAO的数据库连接,我们知道DAO是单例的,那么他的属性Connection就不是⼀个线程安全的变量。⽽我们每个线程都需要使⽤
他,并且各⾃使⽤各⾃的。这种情况,ThreadLocal就⽐较好的解决了这个问题。2、原理:从本质来讲,就是每个线程都维护了⼀个map,⽽这个map的key就是threadLocal,⽽值就是我们set的那个值,每次
线程在get的时候,都从⾃⼰的变量中取值,既然从⾃⼰的变量中取值,那肯定就不存在线程安全问题,总体来讲,ThreadLocal这个
变量的状态根本没有发⽣变化,他仅仅是充当⼀个key的⻆⾊,另外提供给每⼀个线程⼀个初始值。3、实现机制:每个Thread对象内部都维护了⼀个ThreadLocalMap这样⼀个ThreadLocal的Map,可以存放若⼲个
ThreadLocal。
1 /* ThreadLocal values pertaining to this thread. This map is maintained
2 * by the ThreadLocal class. */
3 ThreadLocal.ThreadLocalMap threadLocals = null;4、应⽤场景:当很多线程需要多次使⽤同⼀个对象,并且需要该对象具有相同初始化值的时候最适合使⽤ThreadLocal。
- ThreadPool(线程池)⽤法与优势?
1、ThreadPool 优点
1、减少了创建和销毁线程的次数,每个⼯作线程都可以被重复利⽤,可执⾏多个任务
2、可以根据系统的承受能⼒,调整线程池中⼯作线线程的数⽬,防⽌因为因为消耗过多的内存,⽽把服务器累趴下
(每个线程需要⼤约1MB内存,线程开的越多,消耗的内存也就越⼤,最后死机)
减少在创建和销毁线程上所花的时间以及系统资源的开销
如不使⽤线程池,有可能造成系统创建⼤量线程⽽导致消耗完系统内存
2、⽐较重要的⼏个类:
Java⾥⾯线程池的顶级接⼜是Executor,但是严格意义上讲Executor并不是⼀个线程池,⽽只是⼀个执⾏线程的⼯具。真正的
线程池接⼜是ExecutorService。
3、任务执⾏顺序:
类 描述
ExecutorService 真正的线程池接⼝。
ScheduledExecutorService 能和Timer/TimerTask类似,解决那些需要任务重复执⾏的问题。
ThreadPoolExecutor ExecutorService的默认实现。
ScheduledThreadPoolExecutor 继承ThreadPoolExecutor的ScheduledExecutorService接⼝实
现,周期性任务调度的类实现。
i. 当线程数⼩于corePoolSize时,创建线程执⾏任务。
ii. 当线程数⼤于等于corePoolSize并且workQueue没有满时,放⼊workQueue中
iii. 线程数⼤于等于corePoolSize并且当workQueue满时,新任务新建线程运⾏,线程总数要⼩于maximumPoolSize
iv. 当线程总数等于maximumPoolSize并且workQueue满了的时候执⾏handler的rejectedExecution。也就是拒绝策
略。
- Concurrent包⾥的其他东⻄:ArrayBlockingQueue、CountDownLatch等等。
1、ArrayBlockingQueue 数组结构组成的有界阻塞队列:
2、CountDownLatch 允许⼀个或多个线程等待其他线程完成操作;
join⽤于让当前执⾏线程等待join线程执⾏结束。其实现原理是不停检查join线程是否存活,如果join线程存活则让当前线程永
远wait
- synchronized和ReentrantLock的区别?
1、基础知识
可重⼊锁。可重⼊锁是指同⼀个线程可以多次获取同⼀把锁。ReentrantLock和synchronized都是可重⼊锁。
可中断锁。可中断锁是指线程尝试获取锁的过程中,是否可以响应中断。synchronized是不可中断锁,⽽
ReentrantLock则提供了中断功能。
公平锁与⾮公平锁。公平锁是指多个线程同时尝试获取同⼀把锁时,获取锁的顺序按照线程达到的顺序,⽽⾮公
平锁则允许线程“插队”。synchronized是⾮公平锁,⽽ReentrantLock的默认实现是⾮公平锁,但是也可以设置为公
平锁。
CAS操作(CompareAndSwap)。CAS操作简单的说就是⽐较并交换。CAS 操作包含三个操作数 —— 内存位置
(V)、预期原值(A)和新值(B)。如果内存位置的值与预期原值相匹配,那么处理器会⾃动将该位置值更新为新
值。否则,处理器不做任何操作。⽆论哪种情况,它都会在 CAS 指令之前返回该位置的值。CAS 有效地说明了“我
认为位置 V 应该包含值 A;如果包含该值,则将 B 放到这个位置;否则,不要更改该位置,只告诉我这个位置现在
的值即可。”
2、Synchronized
i. synchronized是java内置的关键字,它提供了⼀种独占的加锁⽅式。synchronized的获取和释放锁由JVM实现,⽤
户不需要显示的释放锁,⾮常⽅便。然⽽synchronized也有⼀定的局限性:
1. 当线程尝试获取锁的时候,如果获取不到锁会⼀直阻塞。
2. 如果获取锁的线程进⼊休眠或者阻塞,除⾮当前线程异常,否则其他线程尝试获取锁必须⼀直等待。
3、ReentrantLock
i. ReentrantLock它是JDK 1.5之后提供的API层⾯的互斥锁,需要lock()和unlock()⽅法配合try/finally语句块来完成。
ii. 等待可中断避免,出现死锁的情况(如果别的线程正持有锁,会等待参数给定的时间,在等待的过程中,如果获
取了锁定,就返回true,如果等待超时,返回false)
iii. 公平锁与⾮公平锁多个线程等待同⼀个锁时,必须按照申请锁的时间顺序获得锁,Synchronized锁⾮公平锁,
ReentrantLock默认的构造函数是创建的⾮公平锁,可以通过参数true设为公平锁,但公平锁表现的性能不是很好。
- Semaphore有什么作⽤?
Semaphore就是⼀个信号量,它的作⽤是限制某段代码块的并发数
- Java Concurrency API中的Lock接⼝(Lock interface)是什么?对⽐同步它有什么优势?
1、Lock接⼝⽐同步⽅法和同步块提供了更具扩展性的锁操作。他们允许更灵活的结构,可以具有完全不同的性质,并且
可以⽀持多个相关类的条件对象。
2、它的优势有:
可以使锁更公平
可以使线程在等待锁的时候响应中断
可以让线程尝试获取锁,并在⽆法获取锁的时候⽴即返回或者等待⼀段时间
可以在不同的范围,以不同的顺序获取和释放锁
- Hashtable的size()⽅法中明明只有⼀条语句”return count”,为什么还要做同步?
1、同⼀时间只能有⼀条线程执⾏固定类的同步⽅法,但是对于类的⾮同步⽅法,可以多条线程同时访问。所以,这样就
有问题了,可能线程A在执⾏Hashtable的put⽅法添加数据,线程B则可以正常调⽤size()⽅法读取Hashtable中当前元素
的个数,那读取到的值可能不是最新的,可能线程A添加了完了数据,但是没有对size++,线程B就已经读取size了,那
么对于线程B来说读取到的size⼀定是不准确的。
2、⽽给size()⽅法加了同步之后,意味着线程B调⽤size()⽅法只有在线程A调⽤put⽅法完毕之后才可以调⽤,这样就保
证了线程安全性。
- ConcurrentHashMap的并发度是什么?
1、⼯作机制(分⽚思想):它引⼊了⼀个“分段锁”的概念,具体可以理解为把⼀个⼤的Map拆分成N个⼩的segment,
根据key.hashCode()来决定把key放到哪个HashTable中。可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。
2、应⽤:当读>写时使⽤,适合做缓存,在程序启动时初始化,之后可以被多个线程访问;
3、hash冲突:1、简介:HashMap中调⽤hashCode()⽅法来计算hashCode。由于在Java中两个不同的对象可能有⼀样的
hashCode,所以不同的键可能有⼀样hashCode,从⽽导致冲突的产⽣。2、hash冲突解决:使⽤平衡树来代替链表,当同⼀hash中的元素数量超过特定的值便会由链表切换到平衡树
4、⽆锁读:ConcurrentHashMap之所以有较好的并发性是因为ConcurrentHashMap是⽆锁读和加锁写,并且利⽤了分
段锁(不是在所有的entry上加锁,⽽是在⼀部分entry上加锁);读之前会先判断count(jdk1.6),其中的count是被volatile修饰的(当变量被volatile修饰后,每次更改该变量的时候会将更
改结果写到系统主内存中,利⽤多处理器的缓存⼀致性,其他处理器会发现⾃⼰的缓存⾏对应的内存地址被修改,就会将⾃⼰处
理器的缓存⾏设置为失效,并强制从系统主内存获取最新的数据。),故可以实现⽆锁读。
5、ConcurrentHashMap的并发度就是segment的⼤⼩,默认为16,这意味着最多同时可以有16条线程操作
ConcurrentHashMap,这也是ConcurrentHashMap对Hashtable的最⼤优势。
- ReentrantReadWriteLock读写锁的使⽤?
1、读写锁:分为读锁和写锁,多个读锁不互斥,读锁与写锁互斥,这是由jvm⾃⼰控制的,你只要上好相应的锁即可。
2、如果你的代码只读数据,可以很多⼈同时读,但不能同时写,那就上读锁;
3、如果你的代码修改数据,只能有⼀个⼈在写,且不能同时读取,那就上写锁。总之,读的时候上读锁,写的时候上写
锁!
- CyclicBarrier和CountDownLatch的⽤法及区别?
CyclicBarrier和CountDownLatch 都位于java.util.concurrent 这个包下
- LockSupport⼯具?
LockSupport是JDK中⽐较底层的类,⽤来创建锁和其他同步⼯具类的基本线程阻塞。java锁和同步器框架的核⼼ AQS:
AbstractQueuedSynchronizer,就是通过调⽤ LockSupport .park()和 LockSupport .unpark()实现线程的阻塞和唤醒 的。
- Condition接⼝及其实现原理?
1. 在java.util.concurrent包中,有两个很特殊的⼯具类,Condition和ReentrantLock,使⽤过的⼈都知道,
ReentrantLock(重⼊锁)是jdk的concurrent包提供的⼀种独占锁的实现
2. 我们知道在线程的同步时可以使⼀个线程阻塞⽽等待⼀个信号,同时放弃锁使其他线程可以能竞争到锁
3. 在synchronized中我们可以使⽤Object的wait()和notify⽅法实现这种等待和唤醒
4. 但是在Lock中怎么实现这种wait和notify呢?答案是Condition,学习Condition主要是为了⽅便以后学习blockqueue和
concurrenthashmap的源码,同时也进⼀步理解ReentrantLock。
- Fork/Join框架的理解?
1、Fork就是把⼀个⼤任务切分为若⼲⼦任务并⾏的执⾏。
2、Join就是合并这些⼦任务的执⾏结果,最后得到这个⼤任务的结果。
- wait()和sleep()的区别?
1、sleep()
⽅法是线程类(Thread)的静态⽅法,让调⽤线程进⼊睡眠状态,让出执⾏机会给其他线程,等到休眠时间结束
后,线程进⼊就绪状态和其他线程⼀起竞争cpu的执⾏时间。
因为sleep() 是static静态的⽅法,他不能改变对象的机锁,当⼀个synchronized块中调⽤了sleep() ⽅法,线程虽然
进⼊休眠,但是对象的机锁没有被释放,其他线程依然⽆法访问这个对象。
2、wait()
wait()是Object类的⽅法,当⼀个线程执⾏到wait⽅法时,它就进⼊到⼀个和该对象相关的等待池,同时释放对象的
机锁,使得其他线程能够访问,可以通过notify,notifyAll⽅法来唤醒等待的线程
- 线程的五个状态(五种状态,创建、就绪、运⾏、阻塞和死亡)?
CountDownLatch CyclicBarrier
减计数⽅式 加计数⽅式
计算为0时释放所有等待的线程 计数达到指定值时释放所有等待线程
计数为0时,⽆法重置 计数达到指定值时,计数置为0重新开始
调⽤countDown()⽅法计数减⼀,调⽤await()⽅法只进⾏阻塞,
对计数没任何影响
调⽤await()⽅法计数加1,若加1后的值不等于
构造⽅法的值,则线程阻塞
不可重复利⽤ 可重复利⽤
线程通常都有五种状态,创建、就绪、运⾏、阻塞和死亡。
i. 第⼀是创建状态。在⽣成线程对象,并没有调⽤该对象的start⽅法,这是线程处于创建状态。
ii. 第⼆是就绪状态。当调⽤了线程对象的start⽅法之后,该线程就进⼊了就绪状态,但是此时线程调度程序还没有
把该线程设置为当前线程,此时处于就绪状态。在线程运⾏之后,从等待或者睡眠中回来之后,也会处于就绪状
态。
iii. 第三是运⾏状态。线程调度程序将处于就绪状态的线程设置为当前线程,此时线程就进⼊了运⾏状态,开始运⾏
run函数当中的代码。
iv. 第四是阻塞状态。线程正在运⾏的时候,被暂停,通常是为了等待某个时间的发⽣(⽐如说某项资源就绪)之后再
继续运⾏。sleep,suspend,wait等⽅法都可以导致线程阻塞。
v. 第五是死亡状态。如果⼀个线程的run⽅法执⾏结束或者调⽤stop⽅法后,该线程就会死亡。对于已经死亡的线
程,⽆法再使⽤start⽅法令其进⼊就绪。
- start()⽅法和run()⽅法的区别?
1、start()⽅法来启动⼀个线程,真正实现了多线程运⾏。
2、如果直接调⽤run(),其实就相当于是调⽤了⼀个普通函数⽽已,直接调⽤run()⽅法必须等待run()⽅法执⾏完毕才能执
⾏下⾯的代码,所以执⾏路径还是只有⼀条,根本就没有线程的特征,所以在多线程执⾏时要使⽤start()⽅法⽽不是run()⽅法。
- Runnable接⼝和Callable接⼝的区别?
1. Runnable接⼝中的run()⽅法的返回值是void,它做的事情只是纯粹地去执⾏run()⽅法中的代码⽽已;
2. Callable接⼝中的call()⽅法是有返回值的,是⼀个泛型,和Future、FutureTask配合可以⽤来获取异步执⾏的结果。
- volatile关键字的作⽤?
1. 多线程主要围绕可⻅性和原⼦性两个特性⽽展开,使⽤volatile关键字修饰的变量,保证了其在多线程之间的可⻅性,
即每次读取到volatile变量,⼀定是最新的数据。
2. 代码底层执⾏不像我们看到的⾼级语⾔—-Java程序这么简单,它的执⾏是Java代码–>字节码–>根据字节码执⾏对应
的C/C++代码–>C/C++代码被编译成汇编语⾔–>和硬件电路交互,现实中,为了获取更好的性能JVM可能会对指令进⾏
重排序,多线程下可能会出现⼀些意想不到的问题。使⽤volatile则会对禁⽌语义重排序,当然这也⼀定程度上降低了代
码执⾏效率。
- Java中如何获取到线程dump⽂件?
死循环、死锁、阻塞、⻚⾯打开慢等问题,查看线程dump是最好的解决问题的途径。所谓线程dump也就是线程堆栈,
获取到线程堆栈有两步:
1、获取到线程的pid,可以通过使⽤jps命令,在Linux环境下还可以使⽤ps -ef | grep java
2、打印线程堆栈,可以通过使⽤jstack pid命令,在Linux环境下还可以使⽤kill -3 pid
3、另外提⼀点,Thread类提供了⼀个getStackTrace()⽅法也可以⽤于获取线程堆栈。这是⼀个实例⽅法,因此此⽅法
是和具体线程实例绑定的,每次获取到的是具体某个线程当前运⾏的堆栈。
- 线程和进程有什么区别?
1. 进程是系统进⾏资源分配的基本单位,有独⽴的内存地址空间
2. 线程是CPU独⽴运⾏和独⽴调度的基本单位,没有单独地址空间,有独⽴的栈,局部变量,寄存器, 程序计数器等。
3. 创建进程的开销⼤,包括创建虚拟地址空间等需要⼤量系统资源
4. 创建线程开销⼩,基本上只有⼀个内核对象和⼀个堆栈。
5. ⼀个进程⽆法直接访问另⼀个进程的资源;同⼀进程内的多个线程共享进程的资源。
6. 进程切换开销⼤,线程切换开销⼩;进程间通信开销⼤,线程间通信开销⼩。
7. 线程属于进程,不能独⽴执⾏。每个进程⾄少要有⼀个线程,成为主线程
- 线程实现的⽅式有⼏种(四种)?
1. 继承Thread类,重写run⽅法
2. 实现Runnable接⼝,重写run⽅法,实现Runnable接⼝的实现类的实例对象作为Thread构造函数的target
3. 实现Callable接⼝通过FutureTask包装器来创建Thread线程
4. 通过线程池创建线程
1 public class ThreadDemo03 {
2 public static void main(String[] args) {
3 Callable<Object> oneCallable = new Tickets<Object>();
4 FutureTask<Object> oneTask = new FutureTask<Object>(oneCallable);
5 Thread t = new Thread(oneTask);
6 System.out.println(Thread.currentThread().getName());
7 t.start();
8 }
9 }
10
11 class Tickets<Object> implements Callable<Object>{
12 //重写call⽅法
13 @Override
14 public Object call() throws Exception {
15 // TODO Auto-generated method stub
16 System.out.println(Thread.currentThread().getName()+"-->我是通过实现Callable接⼝通过FutureTask包装器来实现的线程"
17 return null;
18 }
19 }
- ⾼并发、任务执⾏时间短的业务怎样使⽤线程池?并发不⾼、任务执⾏时间⻓的业务怎样使⽤线程池?并发⾼、
业务执⾏时间⻓的业务怎样使⽤线程池?
1. ⾼并发、任务执⾏时间短的业务:线程池线程数可以设置为CPU核数+1,减少线程上下⽂的切换。
2. 并发不⾼、任务执⾏时间⻓的业务要区分开看:
a. 假如是业务时间⻓集中在IO操作上,也就是IO密集型的任务,因为IO操作并不占⽤CPU,所以不要让所有的CPU
闲下来,可以加⼤线程池中的线程数⽬,让CPU处理更多的业务
b. 假如是业务时间⻓集中在计算操作上,也就是计算密集型任务,这个就没办法了,和(1)⼀样吧,线程池中的线
程数设置得少⼀些,减少线程上下⽂的切换
3. 并发⾼、业务执⾏时间⻓,解决这种类型任务的关键不在于线程池⽽在于整体架构的设计,看看这些业务⾥⾯某些数
据是否能做缓存是第⼀步,增加服务器是第⼆步,⾄于线程池的设置,设置参考(2)。最后,业务执⾏时间⻓的问题,
也可能需要分析⼀下,看看能不能使⽤中间件对任务进⾏拆分和解耦。
- 如果你提交任务时,线程池队列已满,这时会发⽣什么?
1、如果你使⽤的LinkedBlockingQueue,也就是⽆界队列的话,没关系,继续添加任务到阻塞队列中等待执⾏,因为
LinkedBlockingQueue可以近乎认为是⼀个⽆穷⼤的队列,可以⽆限存放任务;
2、如果你使⽤的是有界队列⽐⽅说ArrayBlockingQueue的话,任务⾸先会被添加到ArrayBlockingQueue中,
ArrayBlockingQueue满了,则会使⽤拒绝策略RejectedExecutionHandler处理满了的任务,默认是AbortPolicy。
- 锁的等级:⽅法锁、对象锁、类锁?
1. ⽅法锁(synchronized修饰⽅法时)
a. 通过在⽅法声明中加⼊ synchronized关键字来声明 synchronized ⽅法。
b. synchronized ⽅法控制对类成员变量的访问:
c. 每个类实例对应⼀把锁,每个 synchronized ⽅法都必须获得调⽤该⽅法的类实例的锁⽅能执⾏,否则所属线程阻
塞,⽅法⼀旦执⾏,就独占该锁,直到从该⽅法返回时才将锁释放,此后被阻塞的线程⽅能获得该锁,重新进⼊可
执⾏状态。这种机制确保了同⼀时刻对于每⼀个类实例,其所有声明为 synchronized 的成员函数中⾄多只有⼀个处
于可执⾏状态,从⽽有效避免了类成员变量的访问冲突。
2. 对象锁(synchronized修饰⽅法或代码块)
a. 当⼀个对象中有synchronized method或synchronized block的时候调⽤此对象的同步⽅法或进⼊其同步区域时,
就必须先获得对象锁。如果此对象的对象锁已被其他调⽤者占⽤,则需要等待此锁被释放。(⽅法锁也是对象锁)b. java的所有对象都含有1个互斥锁,这个锁由JVM⾃动获取和释放。线程进⼊synchronized⽅法的时候获取该对象
的锁,当然如果已经有线程获取了这个对象的锁,那么当前线程会等待;synchronized⽅法正常返回或者抛异常⽽
终⽌,JVM会⾃动释放对象锁。这⾥也体现了⽤synchronized来加锁的1个好处,⽅法抛异常的时候,锁仍然可以由
JVM来⾃动释放。
3. 类锁(synchronized 修饰静态的⽅法或代码块)
a. 由于⼀个class不论被实例化多少次,其中的静态⽅法和静态变量在内存中都只有⼀份。所以,⼀旦⼀个静态的⽅
法被申明为synchronized。此类所有的实例化对象在调⽤此⽅法,共⽤同⼀把锁,我们称之为类锁。
4. 对象锁是⽤来控制实例⽅法之间的同步,类锁是⽤来控制静态⽅法(或静态变量互斥体)之间的同步
- 如果同步块内的线程抛出异常会发⽣什么?
synchronized⽅法正常返回或者抛异常⽽终⽌,JVM会⾃动释放对象锁
- 并发编程(concurrency)并⾏编程(parallellism)有什么区别?
1. 解释⼀:并⾏是指两个或者多个事件在同⼀时刻发⽣;⽽并发是指两个或多个事件在同⼀时间间隔发⽣。
2. 解释⼆:并⾏是在不同实体上的多个事件,并发是在同⼀实体上的多个事件。
3. 解释三:在⼀台处理器上“同时”处理多个任务,在多台处理器上同时处理多个任务。如hadoop分布式集群
所以并发编程的⽬标是充分的利⽤处理器的每⼀个核,以达到最⾼的处理性能。
- 如何保证多线程下 i++ 结果正确?
1. volatile只能保证你数据的可⻅性,获取到的是最新的数据,不能保证原⼦性;
2. ⽤AtomicInteger保证原⼦性。
3. synchronized既能保证共享变量可⻅性,也可以保证锁内操作的原⼦性。
- ⼀个线程如果出现了运⾏时异常会怎么样?
1. 如果这个异常没有被捕获的话,这个线程就停⽌执⾏了。
2. 另外重要的⼀点是:如果这个线程持有某个对象的监视器,那么这个对象监视器会被⽴即释放.
- 如何在两个线程之间共享数据?
通过在线程之间共享对象就可以了,然后通过wait/notify/notifyAll、await/signal/signalAll进⾏唤起和等待,⽐⽅说阻塞
队列BlockingQueue就是为线程之间共享数据⽽设计的。
1. 卖票系统:
1 package 多线程共享数据;
2 public class Ticket implements Runnable{
3 private int ticket = 10;
4 public void run() {
5 while(ticket>0){
6 ticket--;
7 System.out.println("当前票数为:"+ticket);
8 }
9 }
10 }
11
12 package 多线程共享数据;
13 public class SellTicket {
14 public static void main(String[] args) {
15 Ticket t = new Ticket();
16 new Thread(t).start();
17 new Thread(t).start();
18 }
19 }
2. 银⾏存取款:
1 public class MyData {
2 private int j=0;
3 public synchronized void add(){
4 j++;
5 System.out.println("线程"+Thread.currentThread().getName()+"j为:"+j);
6 }
7 public synchronized void dec(){
8 j--;
9 System.out.println("线程"+Thread.currentThread().getName()+"j为:"+j);
10 }
11 public int getData(){
12 return j;
13 }
14 }
15
16 public class AddRunnable implements Runnable{
17 MyData data;
18 public AddRunnable(MyData data){
19 this.data= data;
20 }
21 public void run() {
22 data.add();
23 }
24 }
25
26 public class DecRunnable implements Runnable {
27 MyData data;
28 public DecRunnable(MyData data){
29 this.data = data;
30 }
31 public void run() {
32 data.dec();
33 }
34 }
35
36 public class TestOne {
37 public static void main(String[] args) {
38 MyData data = new MyData();
39 Runnable add = new AddRunnable(data);
40 Runnable dec = new DecRunnable(data);
41 for(int i=0;i<2;i++){
42 new Thread(add).start();
43 new Thread(dec).start();
44 }
45 }
- ⽣产者消费者模型的作⽤是什么?
1. 通过平衡⽣产者的⽣产能⼒和消费者的消费能⼒来提升整个系统的运⾏效率,这是⽣产者消费者模型最重要的作⽤。
2. 解耦,这是⽣产者消费者模型附带的作⽤,解耦意味着⽣产者和消费者之间的联系少,联系越少越可以独⾃发展⽽不
需要受到相互的制约。
- 怎么唤醒⼀个阻塞的线程?
1. 如果线程是因为调⽤了wait()、sleep()或者join()⽅法⽽导致的阻塞;
1、suspend与resume
Java废弃 suspend() 去挂起线程的原因,是因为 suspend() 在导致线程暂停的同时,并不会去释放任何锁资
源。其他线程都⽆法访问被它占⽤的锁。直到对应的线程执⾏ resume() ⽅法后,被挂起的线程才能继续,从⽽其它
被阻塞在这个锁的线程才可以继续执⾏。
但是,如果 resume() 操作出现在 suspend() 之前执⾏,那么线程将⼀直处于挂起状态,同时⼀直占⽤锁,这就
产⽣了死锁。⽽且,对于被挂起的线程,它的线程状态居然还是 Runnable。
2、wait与notify
wait与notify必须配合synchronized使⽤,因为调⽤之前必须持有锁,wait会⽴即释放锁,notify则是同步块执⾏
完了才释放
3、await与singal
Condition类提供,⽽Condition对象由new ReentLock().newCondition()获得,与wait和notify相同,因为使⽤
Lock锁后⽆法使⽤wait⽅法
4、park与unpark
LockSupport是⼀个⾮常⽅便实⽤的线程阻塞⼯具,它可以在线程任意位置让线程阻塞。和Thread.suspenf()相
⽐,它弥补了由于resume()在前发⽣,导致线程⽆法继续执⾏的情况。和Object.wait()相⽐,它不需要先获得某个对
象的锁,也不会抛出IException异常。可以唤醒指定线程。
2. 如果线程遇到了IO阻塞,⽆能为⼒,因为IO是操作系统实现的,Java代码并没有办法直接接触到操作系统。
- Java中⽤到的线程调度算法是什么
1. 抢占式。⼀个线程⽤完CPU之后,操作系统会根据线程优先级、线程饥饿情况等数据算出⼀个总的优先级并分配下⼀
个时间⽚给某个线程执⾏。
- 单例模式的线程安全性?
⽼⽣常谈的问题了,⾸先要说的是单例模式的线程安全意味着:某个类的实例在多线程环境下只会被创建⼀次出来。单例模式有很多种的写法,我总结⼀下:
(1)饿汉式单例模式的写法:线程安全
(2)懒汉式单例模式的写法:⾮线程安全
(3)双检锁单例模式的写法:线程安全
47. 线程类的构造⽅法、静态块是被哪个线程调⽤的?
线程类的构造⽅法、静态块是被new这个线程类所在的线程所调⽤的,⽽run⽅法⾥⾯的代码才是被线程⾃身所调⽤的。
- 同步⽅法和同步块,哪个是更好的选择?
1. 同步块是更好的选择,因为它不会锁住整个对象(当然也可以让它锁住整个对象)。同步⽅法会锁住整个对象,哪怕
这个类中有多个不相关联的同步块,这通常会导致他们停⽌执⾏并需要等待获得这个对象上的锁。
synchronized(this)以及⾮static的synchronized⽅法(⾄于static synchronized⽅法请往下看),只能防⽌多个线程同时
执⾏同⼀个对象的同步代码段。
如果要锁住多个对象⽅法,可以锁住⼀个固定的对象,或者锁住这个类的Class对象。
synchronized锁住的是括号⾥的对象,⽽不是代码。对于⾮static的synchronized⽅法,锁的就是对象本身也就是this。
2. 例如:
1 public class SynObj{
2
3 public synchronized void showA(){
4 System.out.println("showA..");
5 try {
6 Thread.sleep(3000);
7 } catch (InterruptedException e) {
8 e.printStackTrace();
9 }
10 }
11
12 public void showB(){
13 synchronized (this) {
14 System.out.println("showB..");
15 }
16 }
17 }
- 如何检测死锁?怎么预防死锁?
1. 概念:
是指两个或两个以上的进程在执⾏过程中,因争夺资源⽽造成的⼀种互相等待的现象,若⽆外⼒作⽤,它们都将⽆
法推进下去。此时称系统处于死锁;
2. 死锁的四个必要条件:
i. 互斥条件:进程对所分配到的资源不允许其他进程进⾏访问,若其他进程访问该资源,只能等待,直⾄占有该资源
的进程使⽤完成后释放该资源
ii. 请求和保持条件:进程获得⼀定的资源之后,⼜对其他资源发出请求,但是该资源可能被其他进程占有,此时请
求阻塞,但⼜对⾃⼰获得的资源保持不放
iii. 不可剥夺条件:是指进程已获得的资源,在未完成使⽤之前,不可被剥夺,只能在使⽤完后⾃⼰释放
iv. 环路等待条件:是指进程发⽣死锁后,若⼲进程之间形成⼀种头尾相接的循环等待资源关系
2. 死锁产⽣的原因:
1.因竞争资源发⽣死锁 现象:系统中供多个进程共享的资源的数⽬不⾜以满⾜全部进程的需要时,就会引起对诸资
源的竞争⽽发⽣死锁现象
2.进程推进顺序不当发⽣死锁
3. 检查死锁
i. 有两个容器,⼀个⽤于保存线程正在请求的锁,⼀个⽤于保存线程已经持有的锁。每次加锁之前都会做如下检测:
ii. 检测当前正在请求的锁是否已经被其它线程持有,如果有,则把那些线程找出来
iii. 遍历第⼀步中返回的线程,检查⾃⼰持有的锁是否正被其中任何⼀个线程请求,如果第⼆步返回真,表示出现了死
锁
4. 死锁的解除与预防:控制不要让四个必要条件成⽴。
- HashMap在多线程环境下使⽤需要注意什么?
要注意死循环的问题,HashMap的put操作引发扩容,这个动作在多线程并发下会发⽣线程死循环的问题。1、HashMap不是线程安全的;Hashtable线程安全,但效率低,因为是Hashtable是使⽤synchronized的,所有线程竞争同⼀
把锁;⽽ConcurrentHashMap不仅线程安全⽽且效率⾼,因为它包含⼀个segment数组,将数据分段存储,给每⼀段数据配⼀把锁,
也就是所谓的锁分段技术。2、HashMap为何线程不安全:1、put时key相同导致其中⼀个线程的value被覆盖;2、多个线程同时扩容,造成数据丢失;3、多线程扩容时导致Node链表形成环形结构造成.next()死循环,导致CPU利⽤率接近100%;3、ConcurrentHashMap最⾼效;
- 什么是守护线程?有什么⽤?
守护线程(即daemon thread),是个服务线程,准确地来说就是服务其他的线程,这是它的作⽤——⽽其他的线程只有
⼀种,那就是⽤户线程。所以java⾥线程分2种,
1、守护线程,⽐如垃圾回收线程,就是最典型的守护线程。
2、⽤户线程,就是应⽤程序⾥的⾃定义线程。
- 如何实现线程串⾏执⾏?
a. 为了控制线程执⾏的顺序,如ThreadA->ThreadB->ThreadC->ThreadA循环执⾏三个线程,我们需要确定唤醒、等待
的顺序。这时我们可以同时使⽤ Obj.wait()、Obj.notify()与synchronized(Obj)来实现这个⽬标。
线程中持有上⼀个线程类的对象锁以及⾃⼰的锁,由于这种依赖关系,该线程执⾏需要等待上个对象释放锁,从⽽
保证类线程执⾏的顺序。
b. 通常情况下,wait是线程在获取对象锁后,主动释放对象锁,同时本线程休眠,直到有其它线程调⽤对象的notify()唤
醒该线程,才能继续获取对象锁,并继续执⾏。⽽notify()则是对等待对象锁的线程的唤醒操作。但值得注意的是notify()
调⽤后,并不是⻢上就释放对象锁,⽽是在相应的synchronized(){}语句块执⾏结束。释放对象锁后,JVM会在执⾏
wait()等待对象锁的线程中随机选取⼀线程,赋予其对象锁,唤醒线程,继续执⾏。
1 public class ThreadSerialize {
2
3 public static void main(String[] args){
4 ThreadA threadA = new ThreadA();
5 ThreadB threadB = new ThreadB();
6 ThreadC threadC = new ThreadC();
7
8 threadA.setThreadC(threadC);
9 threadB.setThreadA(threadA);
10 threadC.setThreadB(threadB);
11
12 threadA.start();
13 threadB.start();
14 threadC.start();
15
16 while (true){
17 try {
18 Thread.currentThread().sleep(1000);
19 } catch (InterruptedException e) {
20 e.printStackTrace();
21 }
22 }
23 }
24 }
25
26 class ThreadA extends Thread{
27 private ThreadC threadC;
28 @Override
29 public void run() {
30 while (true){
31 synchronized (threadC){
32 synchronized (this){
33 System.out.println("I am ThreadA。。。");
34 this.notify();
35 }
36 try {
37 threadC.wait();
38 } catch (InterruptedException e) {
39 e.printStackTrace();
40 }
41 }
42 }
43
44 }
45
46 public void setThreadC(ThreadC threadC) {
47 this.threadC = threadC;
48 }
49 }
50 class ThreadB extends Thread{
51 private ThreadA threadA;
52 @Override
53 public void run() {
54 while (true){
55 synchronized (threadA){
56 synchronized (this){
57 System.out.println("I am ThreadB。。。");
58 this.notify();
59 }
60 try {
61 threadA.wait();
62 } catch (InterruptedException e) {
63 e.printStackTrace();
64 }
65 }
66 }
67
68 }
69
70 public void setThreadA(ThreadA threadA) {
71 this.threadA = threadA;
72 }
73 }
74 class ThreadC extends Thread{
75 private ThreadB threadB;
76 @Override
77 public void run() {
78 while (true){
79 synchronized (threadB){
80 synchronized (this){
81 System.out.println("I am ThreadC。。。");
82 this.notify();
83 }
84 try {
85 threadB.wait();
86 } catch (InterruptedException e) {
87 e.printStackTrace();
88 }
89 }
90 }
91
92 }
93
94 public void setThreadB(ThreadB threadB) {
95 this.threadB = threadB;
96 }
97 }
- 可以运⾏时kill掉⼀个线程吗?
a. 不可以,线程有5种状态,新建(new)、可运⾏(runnable)、运⾏中(running)、阻塞(block)、死亡
(dead)。
b. 只有当线程run⽅法或者主线程main⽅法结束,⼜或者抛出异常时,线程才会结束⽣命周期。
- 关于synchronized:
1. 在某个对象的所有synchronized⽅法中,在某个时刻只能有⼀个唯⼀的⼀个线程去访问这些synchronized⽅法2. 如果⼀个⽅法是synchronized⽅法,那么该synchronized关键字表示给当前对象上锁(即this)相当于
synchronized(this){}3. 如果⼀个synchronized⽅法是static的,那么该synchronized表示给当前对象所对应的class对象上锁(每个类不管⽣成
多少对象,其对应的class对象只有⼀个)
- 分步式锁,程序数据库中死锁机制及解决⽅案
基本原理:⽤⼀个状态值表示锁,对锁的占⽤和释放通过状态值来标识。1、三种分布式锁:1、Zookeeper:基于zookeeper瞬时有序节点实现的分布式锁,其主要逻辑如下。⼤致思想即为:每个客户端对某个
功能加锁时,在zookeeper上的与该功能对应的指定节点的⽬录下,⽣成⼀个唯⼀的瞬时有序节点。判断是否获取锁的⽅式很简
单,只需要判断有序节点中序号最⼩的⼀个。当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁
⽆法释放,⽽产⽣的死锁问题。2、优点锁安全性⾼,zk可持久化,且能实时监听获取锁的客户端状态。⼀旦客户端宕机,则瞬时节点随之消失,zk因
⽽能第⼀时间释放锁。这也省去了⽤分布式缓存实现锁的过程中需要加⼊超时时间判断的这⼀逻辑。3、缺点性能开销⽐较⾼。因为其需要动态产⽣、销毁瞬时节点来实现锁功能。所以不太适合直接提供给⾼并发的场景
使⽤。4、实现可以直接采⽤zookeeper第三⽅库curator即可⽅便地实现分布式锁。5、适⽤场景对可靠性要求⾮常⾼,且并发程度不⾼的场景下使⽤。如核⼼数据的定时全量/增量同步等。2、memcached:memcached带有add函数,利⽤add函数的特性即可实现分布式锁。add和set的区别在于:如果多
线程并发set,则每个set都会成功,但最后存储的值以最后的set的线程为准。⽽add的话则相反,add会添加第⼀个到达的值,并
返回true,后续的添加则都会返回false。利⽤该点即可很轻松地实现分布式锁。2、优点并发⾼效3、缺点memcached采⽤列⼊LRU置换策略,所以如果内存不够,可能导致缓存中的锁信息丢失。memcached⽆法持久化,⼀旦重启,将导致信息丢失。4、使⽤场景⾼并发场景。需要 1)加上超时时间避免死锁; 2)提供⾜够⽀撑锁服务的内存空间; 3)稳定的集群化管理。3、redis:redis分布式锁即可以结合zk分布式锁锁⾼度安全和memcached并发场景下效率很好的优点,其实现⽅式和
memcached类似,采⽤setnx即可实现。需要注意的是,这⾥的redis也需要设置超时时间,以避免死锁。可以利⽤jedis客户端
实现。
1 ICacheKey cacheKey = new ConcurrentCacheKey(key, type);
2 return RedisDao.setnx(cacheKey, "1");2、数据库死锁机制和解决⽅案:1、死锁:死锁是指两个或者两个以上的事务在执⾏过程中,因争夺锁资源⽽造成的⼀种互相等待的现象。2、处理机制:解决死锁最有⽤最简单的⽅法是不要有等待,将任何等待都转化为回滚,并且事务重新开始。但是有可能
影响并发性能。1、超时回滚,innodb_lock_wait_time设置超时时间;2、wait-for-graph⽅法:跟超时回滚⽐起来,这是⼀种更加主动的死锁检测⽅式。InnoDB引擎也采⽤这种⽅
式。
- spring单例为什么没有安全问题(ThreadLocal)
1、ThreadLocal:spring使⽤ThreadLocal解决线程安全问题;ThreadLocal会为每⼀个线程提供⼀个独⽴的变量副本,从⽽
隔离了多个线程对数据的访问冲突。因为每⼀个线程都拥有⾃⼰的变量副本,从⽽也就没有必要对该变量进⾏同步了。
ThreadLocal提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的变量封装进ThreadLocal。概括起来说,对于
多线程资源共享的问题,同步机制采⽤了“以时间换空间”的⽅式,⽽ThreadLocal采⽤了“以空间换时间”的⽅式。前者仅提供⼀份
变量,让不同的线程排队访问,⽽后者为每⼀个线程都提供了⼀份变量,因此可以同时访问⽽互不影响。在很多情况下,
ThreadLocal⽐直接使⽤synchronized同步机制解决线程安全问题更简单,更⽅便,且结果程序拥有更⾼的并发性。
2、单例:⽆状态的Bean(⽆状态就是⼀次操作,不能保存数据。⽆状态对象(Stateless Bean),就是没有实例变量的对象,不
能保存数据,是不变类,是线程安全的。)适合⽤不变模式,技术就是单例模式,这样可以共享实例,提⾼性能。
- 线程池原理:
1、使⽤场景:假设⼀个服务器完成⼀项任务所需时间为:T1-创建线程时间,T2-在线程中执⾏任务的时间,T3-销毁线程时间。
如果T1+T3远⼤于T2,则可以使⽤线程池,以提⾼服务器性能;2、组成:1、线程池管理器(ThreadPool):⽤于创建并管理线程池,包括 创建线程池,销毁线程池,添加新任务;2、⼯作线程(PoolWorker):线程池中线程,在没有任务时处于等待状态,可以循环的执⾏任务;3、任务接⼝(Task):每个任务必须实现的接⼝,以供⼯作线程调度任务的执⾏,它主要规定了任务的⼊⼝,任务执⾏完后
的收尾⼯作,任务的执⾏状态等;4、任务队列(taskQueue):⽤于存放没有处理的任务。提供⼀种缓冲机制。2、原理:线程池技术正是关注如何缩短或调整T1,T3时间的技术,从⽽提⾼服务器程序性能的。它把T1,T3分别安排在服务器程
序的启动和结束的时间段或者⼀些空闲的时间段,这样在服务器程序处理客户请求时,不会有T1,T3的开销了。 3、⼯作流程:1、线程池刚创建时,⾥⾯没有⼀个线程(也可以设置参数prestartAllCoreThreads启动预期数量主线程)。任务队列是作
为参数传进来的。不过,就算队列⾥⾯有任务,线程池也不会⻢上执⾏它们。2、当调⽤ execute() ⽅法添加⼀个任务时,线程池会做如下判断:
1. 如果正在运⾏的线程数量⼩于 corePoolSize,那么⻢上创建线程运⾏这个任务;
2. 如果正在运⾏的线程数量⼤于或等于 corePoolSize,那么将这个任务放⼊队列;
3. 如果这时候队列满了,⽽且正在运⾏的线程数量⼩于 maximumPoolSize,那么还是要创建⾮核⼼线程⽴刻运⾏这个
任务;
4. 如果队列满了,⽽且正在运⾏的线程数量⼤于或等于 maximumPoolSize,那么线程池会抛出异常
RejectExecutionException。3、当⼀个线程完成任务时,它会从队列中取下⼀个任务来执⾏。4、当⼀个线程⽆事可做,超过⼀定的时间(keepAliveTime)时,线程池会判断,如果当前运⾏的线程数⼤于
corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的⼤⼩。
- java锁多个对象:
例如: 在银⾏系统转账时,需要锁定两个账户,这个时候,顺序使⽤两个synchronized可能存在死锁的情况,在⽹上搜索到下⾯的例
⼦:
1 public class Bank {
2 final static Object obj_lock = new Object();
3
4 // Deadlock crisis 死锁
5 public void transferMoney(Account from, Account to, int number) {
6 synchronized (from) {
7 synchronized (to) {
8 from.debit();
9 to.credit();
10 }
11 }
12 }
13
14 // Thread safe
15 public void transferMoney2(final Account from, final Account to, int number) {
16 class Help {
17 void transferMoney2() {
18 from.debit();
19 to.credit();
20 }
21 }
22
23 //通过hashCode⼤⼩调整加锁顺序
24 int fromHash = from.hashCode();
25 int toHash = to.hashCode();
26
27 if (fromHash < toHash) {
28 synchronized (from) {
29 synchronized (to) {
30 new Help().transferMoney2();
31 }
32 }
33 } else if (toHash < fromHash) {
34 synchronized (to) {
35 synchronized (from) {
36 new Help().transferMoney2();
37 }
38 }
39 } else {
40 synchronized (obj_lock) {
41 synchronized (to) {
42 synchronized (from) {
43 new Help().transferMoney2();
44 }
45 }
46 }
47 }
48 }
49 }若操作账户A,B:
1. A的hashCode⼩于B, 先锁A再锁B
2. B的hashCode⼩于A, 先锁B再锁A
3. 产⽣的hashCode相等,先锁住⼀个全局静态变量,在锁A,B这样就避免了两个线程分别操作账户A,B和B,A⽽产⽣死锁的情况。需要为Account对象写⼀个好的hashCode算法,使得不同账户间产⽣的hashCode尽量不同。
- java线程如何启动:
1、继承Thread类;2、实现Runnable接⼝;3、直接在函数体内:4、⽐较:1、实现Runnable接⼝优势:1)适合多个相同的程序代码的线程去处理同⼀个资源2)可以避免java中的单继承的限制3)增加程序的健壮性,代码可以被多个线程共享,代码和数据独⽴。2、继承Thread类优势:1)可以将线程类抽象出来,当需要使⽤抽象⼯⼚模式设计时。2)多线程同步3、在函数体使⽤优势1)⽆需继承thread或者实现Runnable,缩⼩作⽤域。
- java中加锁的⽅式有哪些,如何实现怎么个写法.
1、java中有两种锁:⼀种是⽅法锁或者对象锁(在⾮静态⽅法或者代码块上加锁),第⼆种是类锁(在静态⽅法或者class上加锁);2、注意:其他线程可以访问未加锁的⽅法和代码;synchronized同时修饰静态⽅法和实例⽅法,但是运⾏结果是交替进⾏的,这证明
了类锁和对象锁是两个不⼀样的锁,控制着不同的区域,它们是互不⼲扰的。3、示例代码:1、⽅法锁和同步代码块:
1 public class TestSynchronized
2 {
3 public void test1()
4 {
5 synchronized(this)
6 {
7 int i = 5;
8 while( i-- > 0)
9 {
10 System.out.println(Thread.currentThread().getName() + " : " + i);
11 try
12 {
13 Thread.sleep(500);
14 }
15 catch (InterruptedException ie)
16 {
17 }
18 }
19 }
20 }
21
22 public synchronized void test2()
23 {
24 int i = 5;
25 while( i-- > 0)
26 {
27 System.out.println(Thread.currentThread().getName() + " : " + i);
28 try
29 {
30 Thread.sleep(500);
31 }
32 catch (InterruptedException ie)
33 {
34 }
35 }
36 }
37
38 public static void main(String[] args)
39 {
40 final TestSynchronized myt2 = new TestSynchronized();
41 Thread test1 = new Thread( new Runnable() { public void run() { myt2.test1(); } },
42 Thread test2 = new Thread( new Runnable() { public void run() { myt2.test2(); } },
43 test1.start();;
44 test2.start();
45 // TestRunnable tr=new TestRunnable();
46 // Thread test3=new Thread(tr);
47 // test3.start();
48 }
49 }2、类锁:
1 public class TestSynchronized
2 {
3 public void test1()
4 {
5 synchronized(TestSynchronized.class)
6 {
7 int i = 5;
8 while( i-- > 0)
9 {
10 System.out.println(Thread.currentThread().getName() + " : " + i);
11 try
12 {
13 Thread.sleep(500);
14 }
15 catch (InterruptedException ie)
16 {
17 }
18 }
19 }
20 }
21
22 public static synchronized void test2()
23 {
24 int i = 5;
25 while( i-- > 0)
26 {
27 System.out.println(Thread.currentThread().getName() + " : " + i);
28 try
29 {
30 Thread.sleep(500);
31 }
32 catch (InterruptedException ie)
33 {
34 }
35 }
36 }
37
38 public static void main(String[] args)
39 {
40 final TestSynchronized myt2 = new TestSynchronized();
41 Thread test1 = new Thread( new Runnable() { public void run() { myt2.test1(); } },
42 Thread test2 = new Thread( new Runnable() { public void run() { TestSynchronized.test2
43 test1.start();
44 test2.start();
45 // TestRunnable tr=new TestRunnable();
46 // Thread test3=new Thread(tr);
47 // test3.start();
48 }
49
50 }
62、如何保证数据不丢失:
1、使⽤消息队列,消息持久化;
2、添加标志位:未处理 0,处理中 1,已处理 2。定时处理。
63、ThreadLocal为什么会发⽣内存泄漏?
1、threadlocal原理图:
2、OOM实现:
1、ThreadLocal的实现是这样的:每个Thread 维护⼀个 ThreadLocalMap 映射表,这个映射表的 key 是 ThreadLocal实
例本身,value 是真正需要存储的 Object。
2、也就是说 ThreadLocal 本身并不存储值,它只是作为⼀个 key 来让线程从 ThreadLocalMap 获取 value。值得注意的
是图中的虚线,表示 ThreadLocalMap 是使⽤ ThreadLocal 的弱引⽤作为 Key 的,弱引⽤的对象在 GC 时会被回收。
3、ThreadLocalMap使⽤ThreadLocal的弱引⽤作为key,如果⼀个ThreadLocal没有外部强引⽤来引⽤它,那么系统 GC
的时候,这个ThreadLocal势必会被回收,这样⼀来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这
些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会⼀直存在⼀条强引⽤
链:Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value永远⽆法回收,造成内存泄漏。
3、预防办法:在ThreadLocal的get(),set(),remove()的时候都会清除线程ThreadLocalMap⾥所有key为null的value。
但是这些被动的预防措施并不能保证不会内存泄漏:
(1)使⽤static的ThreadLocal,延⻓了ThreadLocal的⽣命周期,可能导致内存泄漏。
(2)分配使⽤了ThreadLocal⼜不再调⽤get(),set(),remove()⽅法,那么就会导致内存泄漏,因为这块内存⼀直存在。
64、jdk8中对ConcurrentHashmap的改进
1. Java 7为实现并⾏访问,引⼊了Segment这⼀结构,实现了分段锁,理论上最⼤并发度与Segment个数相等。
2. Java 8为进⼀步提⾼并发性,摒弃了分段锁的⽅案,⽽是直接使⽤⼀个⼤的数组。同时为了提⾼哈希碰撞下的寻址性能,
Java 8在链表⻓度超过⼀定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红⿊树(寻址时间复杂度为O(long(N)))。
其数据结构如下图所示
3、源码:
1 public V put(K key, V value) {
2 return putVal(key, value, false);
3 }
4
5 /** Implementation for put and putIfAbsent */
6 final V putVal(K key, V value, boolean onlyIfAbsent) {
7 //ConcurrentHashMap 不允许插⼊null键,HashMap允许插⼊⼀个null键
8 if (key == null || value == null) throw new NullPointerException();
9 //计算key的hash值
10 int hash = spread(key.hashCode());
11 int binCount = 0;
12 //for循环的作⽤:因为更新元素是使⽤CAS机制更新,需要不断的失败重试,直到成功为⽌。
13 for (Node<K,V>[] tab = table;;) {
14 // f:链表或红⿊⼆叉树头结点,向链表中添加元素时,需要synchronized获取f的锁。
15 Node<K,V> f; int n, i, fh;
16 //判断Node[]数组是否初始化,没有则进⾏初始化操作
17 if (tab == null || (n = tab.length) == 0)
18 tab = initTable();
19 //通过hash定位Node[]数组的索引坐标,是否有Node节点,如果没有则使⽤CAS进⾏添加(链表的头结点),添加失败则进⼊下次循环。
20 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
21 if (casTabAt(tab, i, null,
22 new Node<K,V>(hash, key, value, null)))
23 break; // no lock when adding to empty bin
24 }
25 //检查到内部正在移动元素(Node[] 数组扩容)
26 else if ((fh = f.hash) == MOVED)
27 //帮助它扩容
28 tab = helpTransfer(tab, f);
29 else {
30 V oldVal = null;
31 //锁住链表或红⿊⼆叉树的头结点
32 synchronized (f) {
33 //判断f是否是链表的头结点
34 if (tabAt(tab, i) == f) {
35 //如果fh>=0 是链表节点
36 if (fh >= 0) {
37 binCount = 1;
38 //遍历链表所有节点
39 for (Node<K,V> e = f;; ++binCount) {
40 K ek;
41 //如果节点存在,则更新value
42 if (e.hash == hash &&
43 ((ek = e.key) == key ||
44 (ek != null && key.equals(ek)))) {
45 oldVal = e.val;
46 if (!onlyIfAbsent)
47 e.val = value;
48 break;
49 }
50 //不存在则在链表尾部添加新节点。
51 Node<K,V> pred = e;
52 if ((e = e.next) == null) {
53 pred.next = new Node<K,V>(hash, key,
54 value, null);
55 break;
56 }
57 }
58 }
59 //TreeBin是红⿊⼆叉树节点
60 else if (f instanceof TreeBin) {
61 Node<K,V> p;
62 binCount = 2;
63 //添加树节点
64 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
65 value)) != null) {
66 oldVal = p.val;
67 if (!onlyIfAbsent)
68 p.val = value;
69 }
70 }
71 }
72 }
73
74 if (binCount != 0) {
75 //如果链表⻓度已经达到临界值8 就需要把链表转换为树结构
76 if (binCount >= TREEIFY_THRESHOLD)
77 treeifyBin(tab, i);
78 if (oldVal != null)
79 return oldVal;
80 break;
81 }
82 }
83 }
84 //将当前ConcurrentHashMap的size数量+1
85 addCount(1L, binCount);
86 return null;
87 }
65、concurrent包下有哪些类?
ConcurrentHashMap、Future、FutureTask、AtomicInteger...
66、线程a,b,c,d运⾏任务,怎么保证当a,b,c线程执⾏完再执⾏d线程?
1、CountDownLatch类⼀个同步辅助类,常⽤于某个条件发⽣后才能执⾏后续进程。给定计数初始化CountDownLatch,调⽤countDown()⽅
法,在计数到达零之前,await⽅法⼀直受阻塞。重要⽅法为countdown()与await();
2、join⽅法将线程B加⼊到线程A的尾部,当A执⾏完后B才执⾏。
1 public static void main(String[] args) throws Exception {
2 Th t = new Th("t1");
3 Th t2 = new Th("t2");
4 t.start();
5 t.join();
6 t2.start();
7 }
3、notify、wait⽅法,Java中的唤醒与等待⽅法,关键为synchronized代码块,参数线程间应相同,也常⽤Object作为参
数。
67、⾼并发系统如何做性能优化?如何防⽌库存超卖?
1、⾼并发系统性能优化:优化程序,优化服务配置,优化系统配置1.尽量使⽤缓存,包括⽤户缓存,信息缓存等,多花点内存来做缓存,可以⼤量减少与数据库的交互,提⾼性能。2.⽤jprofiler等⼯具找出性能瓶颈,减少额外的开销。3.优化数据库查询语句,减少直接使⽤hibernate等⼯具的直接⽣成语句(仅耗时较⻓的查询做优化)。4.优化数据库结构,多做索引,提⾼查询效率。5.统计的功能尽量做缓存,或按每天⼀统计或定时统计相关报表,避免需要时进⾏统计的功能。6.能使⽤静态⻚⾯的地⽅尽量使⽤,减少容器的解析(尽量将动态内容⽣成静态html来显示)。7.解决以上问题后,使⽤服务器集群来解决单台的瓶颈问题。2、防⽌库存超卖:1、悲观锁:在更新库存期间加锁,不允许其它线程修改;1、数据库锁:select xxx for update;2、分布式锁;2、乐观锁:使⽤带版本号的更新。每个线程都可以并发修改,但在并发时,只有⼀个线程会修改成功,其它会返回失
败。1、redis watch:监视键值对,作⽤时如果事务提交exec时发现监视的监视对发⽣变化,事务将被取消。3、消息队列:通过 FIFO 队列,使修改库存的操作串⾏化。4、总结:总的来说,不能把压⼒放在数据库上,所以使⽤ "select xxx for update" 的⽅式在⾼并发的场景下是不可⾏
的。FIFO 同步队列的⽅式,可以结合库存限制队列⻓,但是在库存较多的场景下,⼜不太适⽤。所以相对来说,我会倾向于
选择:乐观锁 / 缓存锁 / 分布式锁的⽅式。
68、线程池的参数配置,为什么java官⽅提供⼯⼚⽅法给线程池?
1、线程池简介:
2、核⼼参数:
3、⼯⼚⽅法作⽤:ThreadPoolExecutor类就是Executor的实现类,但ThreadPoolExecutor在使⽤上并不是那么⽅便,在实
例化时需要传⼊很多歌参数,还要考虑线程的并发数等与线程池运⾏效率有关的参数,所以官⽅建议使⽤Executors⼯程类来
创建线程池对象。
69、说说java同步机制,java有哪些锁,每个锁的特性?
Java中的同步机制是为了保证多线程环境下的线程安全,确保多个线程在访问共享资源时能够保持数据的一致性和完整性。Java提供了多种锁机制,每种锁都有其特定的用途和特性。以下是Java中的一些主要锁类型及其特性:synchronized关键字基本锁:synchronized是Java内置的同步机制,可以用来修饰方法或者代码块。
可重入性:synchronized锁是可重入的,同一个线程可以多次获得同一个锁。
阻塞与等待:当多个线程尝试访问同一个synchronized保护的资源时,其他线程会被阻塞直到锁被释放。
锁释放:当synchronized代码块或方法执行完毕后,锁会自动释放。
ReentrantLock(可重入锁)显示锁:ReentrantLock是一个显示锁,需要用户去获取和释放。
可重入性:与synchronized一样,ReentrantLock也是可重入的。
公平性:可以指定是公平锁还是非公平锁。公平锁会按照线程等待的顺序来分配锁,非公平锁则不保证顺序。
条件变量:ReentrantLock提供了与条件变量配套的API,可以精确控制多个线程的运行。
ReadWriteLock(读写锁)读多写少场景:ReadWriteLock允许多个读操作同时进行,但写操作是独占的。
读锁和写锁:读写锁包含两个锁,一个读锁和一个写锁。读锁可以被多个读操作共享,而写锁是独占的。
锁降级:允许从写锁降级到读锁,但不允许从读锁升级到写锁。
StampedLock(乐观读锁)乐观锁:StampedLock是一种新的读写锁,它使用乐观锁机制来提高读操作的性能。
三种模式:StampedLock提供了三种模式的锁:读锁、写锁和乐观读锁。
性能优势:在读多写少的场景下,StampedLock的性能通常优于ReadWriteLock。
LockSupport工具类线程阻塞与唤醒:LockSupport提供了一系列的方法来阻塞和唤醒线程,它是基于Unsafe实现的。
无锁机制:LockSupport不提供锁的获取和释放,而是提供基本的线程阻塞和唤醒操作,可以用来实现无锁编程。
AbstractQueuedSynchronizer(AQS)锁框架:AQS是Java并发包中的一个核心组件,ReentrantLock和ReadWriteLock等锁都是基于AQS实现的。
FIFO队列:AQS内部使用一个FIFO队列来管理线程的等待状态。
CountDownLatch、CyclicBarrier、Semaphore同步辅助工具:这些类提供了线程间的协调机制,用于控制线程的执行顺序。
CountDownLatch:允许一个或多个线程等待一组操作完成。
CyclicBarrier:允许一组线程相互等待,直到所有线程都到达一个公共屏障点。
Semaphore:控制对资源的访问数量。
每种锁都有其适用场景和优缺点,选择合适的锁机制可以提高程序的性能和可靠性。在实际编程中,应根据具体需求和上下文来选择最合适的同步机制。
70、说说volatile如何保证可⻅性,从cpu层⾯分析?
volatile 是 Java 中的一个关键字,用于修饰变量,以确保该变量的可见性和禁止指令重排。从 CPU 层面来分析,volatile 保证可见性主要依赖于内存屏障(Memory Barrier)和缓存一致性协议(如 MESI 协议)。内存屏障(Memory Barrier)
内存屏障是一种 CPU 指令,它确保在屏障之前的指令执行完毕后才能执行屏障之后的指令。对于 volatile 变量的写操作,Java 内存模型会在写操作后插入一个写屏障,而在读操作前插入一个读屏障。这意味着:写操作后的写屏障:确保所有之前的写入操作(包括非 volatile 变量的写入)都完成之后,才会执行后续的写入操作。
读操作前的读屏障:确保所有之前的读取操作都完成之后,才会执行后续的读取操作,并且读取的是最新值。
缓存一致性协议(MESI)
现代多核处理器系统中,每个 CPU 核心可能都有自己的缓存(L1、L2、L3)。缓存一致性协议确保所有核心中的缓存数据是一致的。MESI 协议是其中一种缓存一致性协议,它通过以下状态来管理缓存行:M(Modified):缓存行是修改过的,数据只在此缓存中,需要同步到内存中。
E(Exclusive):缓存行是独占的,只读不写,数据是最新的。
S(Shared):缓存行是共享的,可能被多个缓存共享,数据是最新的。
I(Invalid):缓存行是无效的,需要从内存中重新加载数据。
当一个 volatile 变量被写入时,CPU 会将该变量所在的缓存行标记为 M 状态,并在写入内存后将其改为 S 状态,通知其他 CPU 核心该缓存行是共享的,并且数据在内存中是最新的。当其他 CPU 核心读取 volatile 变量时,它会从内存中重新加载最新的值,而不是从自己的缓存中读取。指令重排
volatile 还通过禁止特定类型的指令重排来保证可见性。指令重排是指编译器或 CPU 为了优化性能,可能会改变指令的执行顺序。volatile 变量的写操作和读操作不会被重排到其他非 volatile 变量的读写操作之间。总结
volatile 通过内存屏障和缓存一致性协议来确保变量的可见性,使得每次读取 volatile 变量时都能获得最新的值,并且写入对所有线程都是立即可见的。然而,volatile 并不能保证原子性,对于需要原子操作的场景,需要使用 synchronized 或 Lock 等其他同步机制。
相关文章:

多线程 相关面试集锦
什么是线程? 1、线程是操作系统能够进⾏运算调度的最⼩单位,它被包含在进程之中,是进程中的实际运作单位,可以使⽤多线程对 进⾏运算提速。 ⽐如,如果⼀个线程完成⼀个任务要100毫秒,那么⽤⼗个线程完成改…...
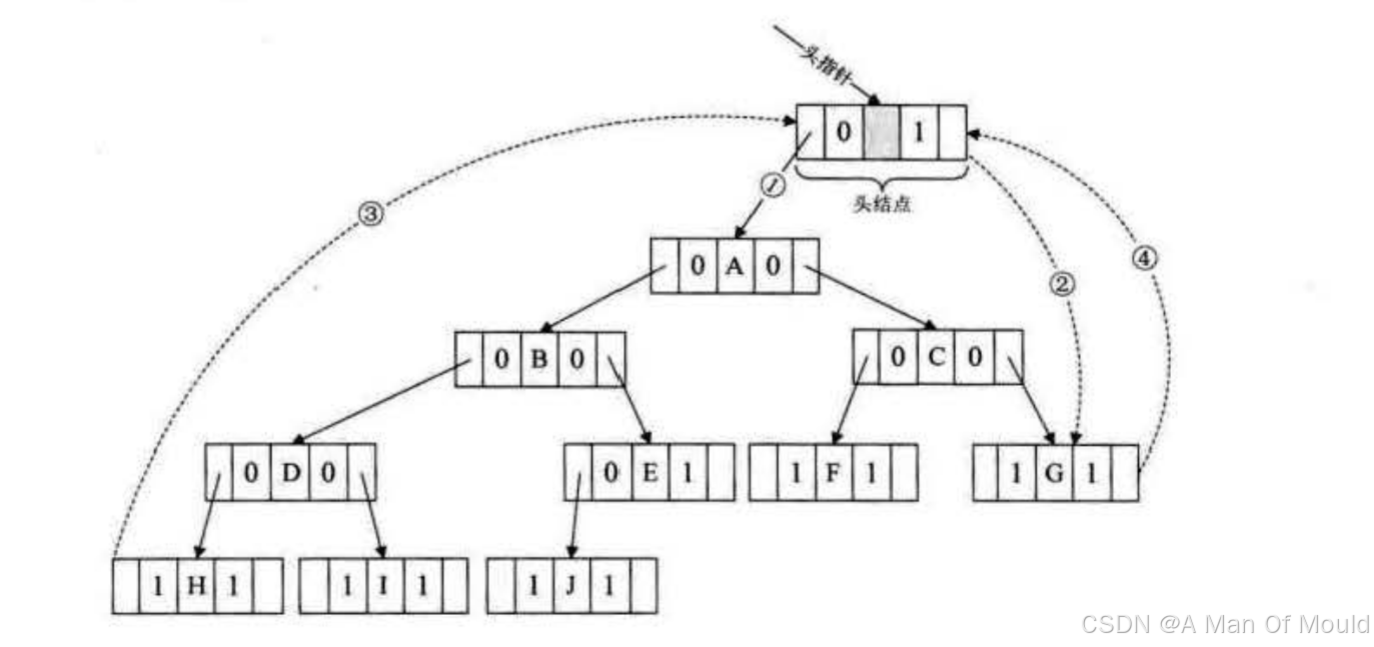
【数据结构】—— 线索二叉树
引入 我们现在提倡节约型杜会, 一切都应该节约为本。对待我们的程序当然也不例外,能不浪费的时间或空间,都应该考虑节省。我们再观察团下图的二叉树(链式存储结构),会发现指针域并不是都充分的利用了,有许…...
uni-app 发布媒介功能(自由选择媒介类型的内容) 设计
1.首先明确需求 我想做一个可以选择媒介的内容,来进行发布媒介的功能 (媒介包含:图片、文本、视频) 2.原型设计 发布-编辑界面 通过点击下方的加号,可以自由选择添加的媒介类型 但是因为预览中无法看到视频的效果&…...
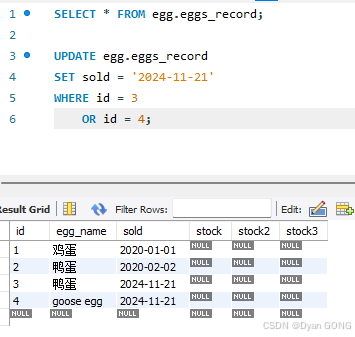
How to update the content of one column in Mysql
How to update the content of one column in Mysql by another column name? UPDATE egg.eggs_record SET sold 2024-11-21 WHERE id 3 OR id 4;UPDATE egg.eggs_record SET egg_name duck egg WHERE id 2;...
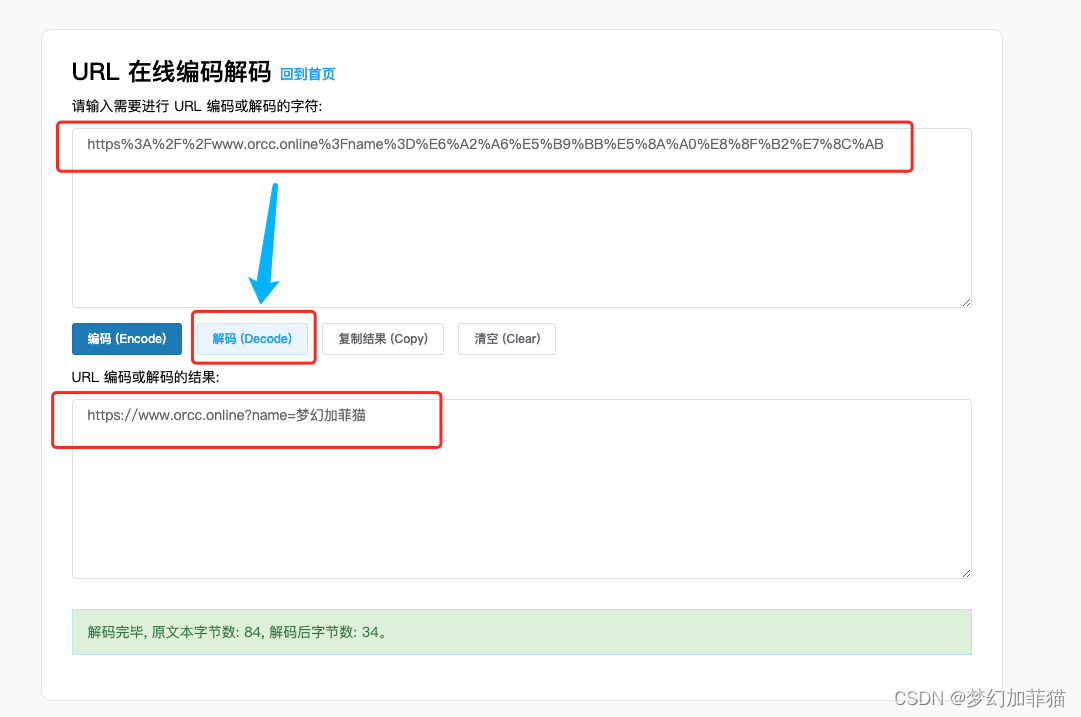
URL在线编码解码- 加菲工具
URL在线编码解码 打开网站 加菲工具 选择“URL编码解码” 输入需要编码/解码的内容,点击“编码”/“解码”按钮 编码: 解码: 复制已经编码/解码后的内容。...

Python3 爬虫 Scrapy的安装
Scrapy是基于Python的分布式爬虫框架。使用它可以非常方便地实现分布式爬虫。Scrapy高度灵活,能够实现功能的自由拓展,让爬虫可以应对各种网站情况。同时,Scrapy封装了爬虫的很多实现细节,所以可以让开发者把更多的精力放在数据的…...

QT中QString类的各种使用
大部分的QString使用可以参考:QT中QString 类的使用--获取指定字符位置、截取子字符串等_qstring 取子串-CSDN博客 补充一种QString类的分离:Qt QString切割(Split()与Mid()函数详解)_qstring split-CSDN博客 1. Trimmed和Simplified函数(去除空白) trimmed:去除了…...

linux 网络安全不完全笔记
一、安装Centos 二、Linux网络网络环境设置 a.配置linux与客户机相连通 b.配置linux上网 三、Yum详解 yum 的基本操作 a.使用 yum 安装新软件 yum install –y Software b.使用 yum 更新软件 yum update –y Software c.使用 yum 移除软件 yum remove –y Software d.使用 yum …...

uniapp将图片url转换成base64支持app和h5
uniapp将图片url转换成base64支持app和h5 imageToBase64支持app和h5, app内使用plus.io.resolveLocalFileSystemURL方法转换 h5内使用uni.request方法转换 // 图片转base64 export const imageToBase64 (path) > {// #ifdef APP-PLUSreturn new Promise((resolve, rejec…...

odoo17 档案管理之翻译2
翻译格式:#: model_terms:对象名称,arch_db:模块名.xml_id #. module: dms #: model_terms:ir.ui.view,arch_db:dms.view_dms_directory_kanban #: model_terms:ir.ui.view,arch_db:dms.view_dms_file_kanban #: model_terms:ir.ui.view,arch_db:dms.view_dms_tag_…...

风尚云网前端学习:制作一款简易的在线计算器
风尚云网前端学习:制作一款简易的在线计算器 简介 在前端开发的学习过程中,实现一个简单的在线计算器是一个常见的练习项目。它不仅能够帮助我们熟悉HTML、CSS和JavaScript的基本用法,还能够加深我们对事件处理和DOM操作的理解。今天&#…...
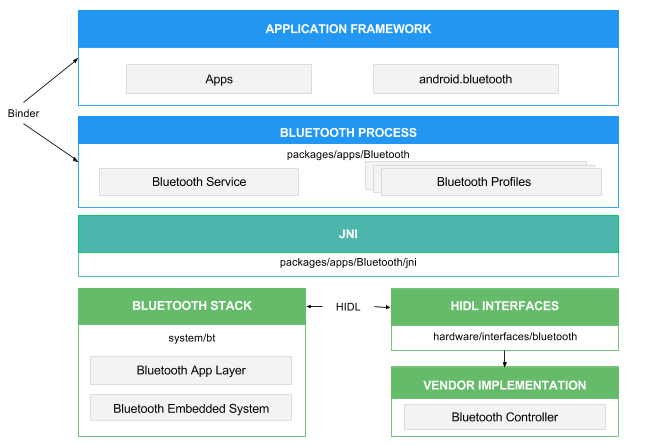
Android蓝牙架构,源文件目录/编译方式学习
Android 版本 发布时间 代号(Codename) Android 1.0 2008年9月23日 无 Android 1.1 2009年2月9日 Petit Four Android 1.5 2009年4月27日 Cupcake Android 1.6 2009年9月15日 Donut Android 2.0 2009年10月26日 Eclair Android 2.1 2…...

ubuntu中使用ffmpeg和nginx推流rtmp视频
最近在测试ffmpeg推流rtmp视频,单独安装ffmpeg是无法完成推流的,需要一个流媒体服务器,常用nginx,可以直接在ubuntu虚拟机里面测试一下。 测试过程不涉及编译ffmpeg和nginx,仅使用基本功能: 1 安装ffmpeg …...

strongswan测试流程
测试shell脚本文件testing/do-tests,测试配置文件testing/testing.conf。do-tests脚本不加参数,将依次执行testing/tests/目录下的所有测试用例。do-tests脚本有两个参数-v和-t,前者在测试中记录详细信息,后者在输出信息中增加时间…...

[CKS] CIS基准测试,修复kubelet和etcd不安全项
目前的所有题目为2024年10月后更新的最新题库,考试的k8s版本为1.31.1 专栏其他文章: [CKS] K8S Admission Set Up[CKS] CIS基准测试,修复kubelet和etcd不安全项[CKS] K8S NetworkPolicy Set Up[CKS] 利用Trivy对image进行扫描[CKS] 利用falco进行容器…...

Linux/Windows/OSX 上面应用程序重新启动运行。
1、Linux/OSX 上面重新运行程序,直接使用 execvp 函数就可以了,把main 函数传递来的 argv 二维数组(命令行参数)传进去就可以,注意不要在 fork 出来的子进程搞。 2、Windows 平台可以通过 CreateProcess 函数来创建新的…...

React拆分组件中的传值问题
在我们实际项目开发中,很多时候为为了项目后期便于维护,都会将相关的组件进行拆分,拆分过后,会将数据方法在父组件中进行编写,然后将一些逻辑拆分为组件,在这个过程中,最重要的就是数据的传递&a…...

RocketMQ的使⽤
初识MQ 1.1.同步和异步通讯 微服务间通讯有同步和异步两种⽅式: 同步通讯:就像打电话,需要实时响应。 异步通讯:就像发邮件,不需要⻢上回复。 两种⽅式各有优劣,打电话可以⽴即得到响应,但…...

Android Studio 设置不显示 build-tool 无法下载
2024版本查看build-tool版本 File -> Settings -> Languages & Frameworks -> Android SDK 或者直接打开Settings后搜索“SDK” 解决方案 将 Android Studio 升级到2022.2.1以上的版本将 C:/Windows/System32/drivers/etc/hosts 文件用管理员身份打开,…...

【Y20030007】基于java+servlet+mysql的垃圾分类网站的设计与实现(附源码 配置 文档)
网垃圾分类网站的设计与实现 1.摘要2.开发目的和意义3.系统功能设计4.系统界面截图5.源码获取 1.摘要 随着全球环境保护意识的提升,垃圾分类已成为一项紧迫且重要的任务。为了有效推动垃圾分类的实施,提升公众的环保意识和参与度,垃圾分类已…...

基于Hugging Face与Gradio的智能问答系统构建实战
1. 项目概述:从零构建一个可交互的智能问答系统 如果你对自然语言处理(NLP)感兴趣,并且一直想亲手搭建一个能“读懂”文章并回答问题的智能系统,那么这篇文章就是为你准备的。过去几年,基于Transformer架构…...

告别K-Means!用Python手撸Science上的DPC算法,搞定任意形状数据聚类
密度峰值聚类DPC:用Python突破传统K-Means的局限当面对螺旋形、环形或交叉分布的数据集时,许多数据科学从业者都有过这样的经历:反复调整K-Means参数却始终无法获得理想的聚类效果。这正是2014年发表在《Science》上的密度峰值聚类算法(DPC)要…...

不用pip install -e也能搞定Vision Mamba训练:我的CIFAR-100快速测试与whl文件安装指南
Vision Mamba极速体验指南:绕过复杂安装直接训练CIFAR-100 当最新论文《Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model》在arXiv上出现时,许多同行都迫不及待想验证这个号称"超越ViT"的架构…...

黑群晖硬盘满了别慌!手把手教你用SSH命令行扩容,Linux系统也通用
黑群晖存储扩容实战:SSH命令行全流程指南与Linux通用技巧当你发现黑群晖的存储空间亮起红灯时,那种焦虑感我深有体会。去年我的媒体服务器突然报出"存储空间不足"警告,当时存放的4TB家庭影像资料和重要工作备份几乎占满了整个磁盘。…...
)
别再手动跑Jupyter了!Lindy标准化流程强制接管你的分析工作流(仅剩最后23个企业未迁移)
更多请点击: https://codechina.net 第一章:Lindy数据分析自动化流程的演进逻辑与核心价值 Lindy效应指出,一个事物的预期剩余寿命与其当前已存在时间成正比——在数据分析领域,这一原理映射为:越经受住多轮业务迭代、…...

从电路振荡到种群竞争:常系数线性微分方程组在建模中的实战指南
从电路振荡到种群竞争:常系数线性微分方程组在建模中的实战指南微分方程是描述动态系统的数学语言,而常系数线性微分方程组则是其中最具工程实用价值的一类。不同于纯数学视角下的求解技巧,本文将带你穿越两个经典场景——电子工程中的RLC振荡…...

QMCDecode:基于Swift的QQ音乐加密格式解析与转换方案
QMCDecode:基于Swift的QQ音乐加密格式解析与转换方案 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转…...

Taotoken 的 API Key 分级管理与审计日志功能在安全合规中的应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 的 API Key 分级管理与审计日志功能在安全合规中的应用 当企业将大模型能力集成到业务流程中时,除了关注模型…...
)
从源码到发布:用.NET Reactor插件实现VS一键混淆加密(.NET 6+项目实战)
从源码到发布:用.NET Reactor插件实现VS一键混淆加密(.NET 6项目实战) 在当今快速迭代的开发环境中,代码保护已成为商业级应用不可或缺的一环。对于使用.NET 6/8的团队而言,如何在持续交付流程中无缝集成代码混淆和加密…...

为ClaudeCode配置Taotoken作为稳定后备API服务避免中断
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为ClaudeCode配置Taotoken作为稳定后备API服务避免中断 基础教程类,针对担心Claude Code服务不稳定或配额不足的用户&a…...