【Pytest+Yaml+Allure】实现接口自动化测试框架
一、框架思想
requests+yaml+pytest+allure实现接口自动化框架。结合数据驱动和分层思想,将代码与数据分离,易维护,易上手。使用yaml编写编写测试用例,利用requests库发送请求,使用pytest管理用例,allure生成测试报告,后续可能加上CI 持续集成(Jenkins)。
数据驱动是整个框架的核心
什么是数据驱动?
在接口测试中,测试用例可能有上百条,如果将用例全部写在代码中,一旦需要修改,将会消耗大量的时间,不容易维护。所以,我们就要测试数据,或者测试用例存储到文件中,用代码读取文件获取数据,实现数据驱动。
数据驱动分为两种:
1、参数的数据驱动
2、用例的数据驱动
| json | 格式完备,格式死板,不能写注释 |
| yaml | 格式完备,格式简单,可注释 |
| csv | 可以使用excel编辑,文本格式方便管理 |
| xml | 格式完备,冗长复杂 |
二、yaml基本语法
大小写敏感
使用缩进表示层级关系
缩进时不允许使用Tab键,只允许使用空格。
缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
yaml支持三种数据结构:
对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
纯量(scalars):单个的、不可再分的值
数组:
- Cat
- Dog
- Goldfish也可写成:列表嵌套列表
-- Cat- Dog- Goldfish字典与列表嵌套:-id:login_02三、读取yaml
yaml.load和safe_load()
两者区别:
safe_load()可以解析简单的数据结构,而且比较安全,load可以解析比较复杂的数据结构,通常一般使用的最多的还是load()
四、测试用例数据驱动
-id: login_01title: 登录成功url: member/loginmethod: POSTrequest_data: {"mobile_phone": "17866554324","pwd":"188888"}expect: {"code":0,"msg":"OK"}#读取yamldef read_yaml(self):with open(self.filename, encoding='utf-8') as fs:# 避免报警告:yaml.FullLoaderdata = yaml.load(fs, Loader=yaml.FullLoader)return data
五、参数化数据驱动
将测试用例部分数据进行参数化,比如用户名密码之类的数据。 然后将数据放入配置文件中
[case_data]
mobile_phone = 11111111111
pwd = 123456789
六.使用正在表达式替换参数化数据
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式的大致匹配过程是: 1.依次拿出表达式和文本中的字符比较, 2.如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。 3.如果表达式中有量词或边界,这个过程会稍微有一些不同。 正则表达式贪婪模式:尽可能多的匹配 非贪婪模式:尽可能少的匹配
引入模块
import re
方法:
1.compile(pattern[,flag]):对正则表达式pattern进行编译,编译后比直接查找速度快
2.match(patter,string[,flag]):从字符串string的开始就匹配,若匹配成功,则返回匹配对象,否则返回None(None对象没有group()和groups()方法,不判断直接调用这两个方法,则会出现异常)
3.search(pattern,string[,flag]):从字符串中查找,若匹配成功,则返回匹配对象,否则返回None
4.findall(pattern,string[,flag]):在字符串 string 中查找正则表达式模式 pattern 的所有(非重复)出现;返回一个匹配对象的列表
5.finditer(pattern,string[, flags])b 和 findall()相同,但返回的不是列表而是迭代器;对于每个匹配,该迭代器返回一个匹配对象
6.split(pattern,string, max=0) 根据正则表达式 pattern 中的分隔符把字符 string 分割为一个列表,返回成功匹配的列表,最多分割 max 次(默认是分割所有匹配的地方)
7.sub(pattern, repl, string, max=0) 把字符串 string 中所有匹配正则表达式 pattern 的地方替换成字符串 repl,如果 max 的值没有给出, 则对所有匹配的地方进行替换
代码如下(示例):res=re.findall("#(.*?)#",data)
七、发送请求
使用第三方库requests 请求方式:get/post/put/delete
代码如下(示例):
def send_request(method,url,data,header):if method=="POST":res=requests.post(url,json=data,headers=header)elif method=="GET":res = requests.post(url, params=data, headers=header)elif method=="PUT":'''封装put方法,uri是访问路由,params是put请求需要传递的参数,如果没有参数这里为空:param uri: 访问路由:param params: 传递参数,string类型,默认为None:return: 此次访问的response'''if data is not None:# 如果有参数,那么通过put方式访问对应的url,并将参数赋值给requests.put默认参数data# 返回request的Response结果,类型为requests的Response类型res=requests.put(url,json=data,headers=header)else:# 如果无参数,访问方式如下# 返回request的Response结果,类型为requests的Response类型res = requests.put(url)elif method=="DELETE":'''封装delete方法,uri是访问路由,params是delete请求需要传递的参数,如果没有参数这里为空:param uri: 访问路由:param params: 传递参数,string类型,默认为None:return: 此次访问的response'''if data is not None:# 如果有参数,那么通过put方式访问对应的url,并将参数赋值给requests.put默认参数data# 返回request的Response结果,类型为requests的Response类型res=requests.delete(url,data=data,headers=header)else:# 如果无参数,访问方式如下# 返回request的Response结果,类型为requests的Response类型res = requests.delete(url,headers=header)else:logger.info("无效的请求方式,get/post/put/delete,请查找原因!!!")return reslogger.info("响应数据为{}".format(res.json))
八、pytest管理用例
为什么选择pytest,不选择unittest?
pytest特点:
简单灵活,容易上手;支持参数化; 测试用例的skip和xfail 处理;
能够支持简单的单元测试和复杂的功能测试,还可以用来做 selenium/appium等自动化测试、接口自动化测试 (pytest+requests);
pytest具有很多第三方插件,并且可以自定义扩展, 比较好 用的如 pytest-allure(完美html测试报告生成) pytest-xdist (多CPU分发)等;
可以很好的和jenkins集成;**
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
pytest框架结构:
Import pytest 类似的setup,teardown同样更灵活
模块级 (setup_module/teardown_module)
全局的,整个.py模块开始前和结束后调用一次
函数级 (setup_function/teardown_function)
只对函数用例生效(不在类内),每个函数级用例开始和结束时调用一次
类级 (setup_class/teardown_class)
只在类前后运行一次(在类中)。
方法级 (setup_method/teardown_methond)
运行在类中方法始末
类里面的(setup/teardown):运行在调用方法的前后
类中运行顺序:setup_class>setup_method>setup>用例>teardown>teardown_method>teardown_class
pytest执行方式:
Pytest –v (最高级别信息—verbose)
pytest -v -s filename 3.Pytest-q (静默)
(输出打印)
多种执行方式
1.pytest将在当前目录及其子目录中运行test _ * .py或* test.py形 式的所有文件。
2.以test_开头的函数,以Test开头的类,以test_开头的方法。所有包 package都要有__init_.py文件。
3.Pytest可以执行unittest框架写的用例和方法
可以在pytest.ini文件中自定义要运行的测试路径、文件名、类名和方法名等。
pytest断言
mark中skip的使用:
1、不想运行部分用例
2、标记无法运行的测试用例
3、当前外部资源不可用
4、在某些版本中跳过
mark中xfail的使用
1、功能尚未实施或尚未修复,使用@pytest.mark.xfail标记,会是一个xpass,在测试报告中
自定义的标记,可以只执行部分用例
1、当回归测试,只需要执行部分用例时。
pytest中的fixture
在pytest中可以灵活使用fixture,不需要每一个用例都写fixture,写好一个只需要调用就可以
@pytest.fixture(scope="class")
def init():logger.info("=========================开始执行测试项目=========================")yieldlogger.info("=========================测试项目执行完毕=========================")1.机制:与测试用例同级,或者是测试用例的父级,创建一个conftest.py文件。
2.conftest.py文件里:放所有的前置和后置。 不需要用例.py文件主动引入conftest文件。
3.定义一个函数:包含前置操作+后置操作。
4.把函数声明为fixture :在函数前面加上 @pytest.fixture(作用级别=默认为function)
5.fixture的定义。
如果有返回值,那么写在yield后面。(yield的作用就相当于return)
在测试用例当中,调用有返回值的fixture函数时,函数名称就是代表返回值。
在测试用例当中,函数名称作为用例的参数即可。
@pytest.mark.sign
@allure.epic("测试项目")
@allure.feature("登录模块")
@pytest.mark.usefixtures("init")
class Test_Login:@pytest.mark.parametrize("case",cases)def test_login(self,case):res=send_request(case["method"],case["url"],json.loads(case["request_data"]))expect=json.loads(case["expect"])logger.info("期望结果为{}".format(expect))logger.info("响应结果为:{}".format(res.json()))if expect:try:assert res.json()["code"]==expect["code"]except Exception as e:logger.info("断言失败")raisereturn res进阶方法:conftest中定义多个fixture,一个fixture可以是另一个fixture的前后置,期间还是用yield隔开前后置
参数化与数据驱动框架实现
使用@pytest.mark.parametrize(“case”,cases)实现参数化
当每个测试用例需要不同的测试数据是,可以直接获取
调整测试用例的执行顺序
比如:添加功能模块的用例要先执行,删除功能模块的用例要后执行,可以使用第三方插件
pip install pytest-ordering
在测试方法上加上装饰器:@pytest.mark.last (—最后一个执行) @pytest.mark.run(order=1) (第几个执行)
多线程并行与分布式执行
当用例数量太多时,可以考虑多线程并行,分布式执行
插件:pip3 install pytest-xdist
多个cpu执行,pytest -n 3
import pytest
import time@pytest.mark.parametrize('x',list(range(10)))
def test_somethins(x):time.sleep(1)pytest -v -s -n 5 test_xsdist.py ----一次执行5个 九、allure测试报告
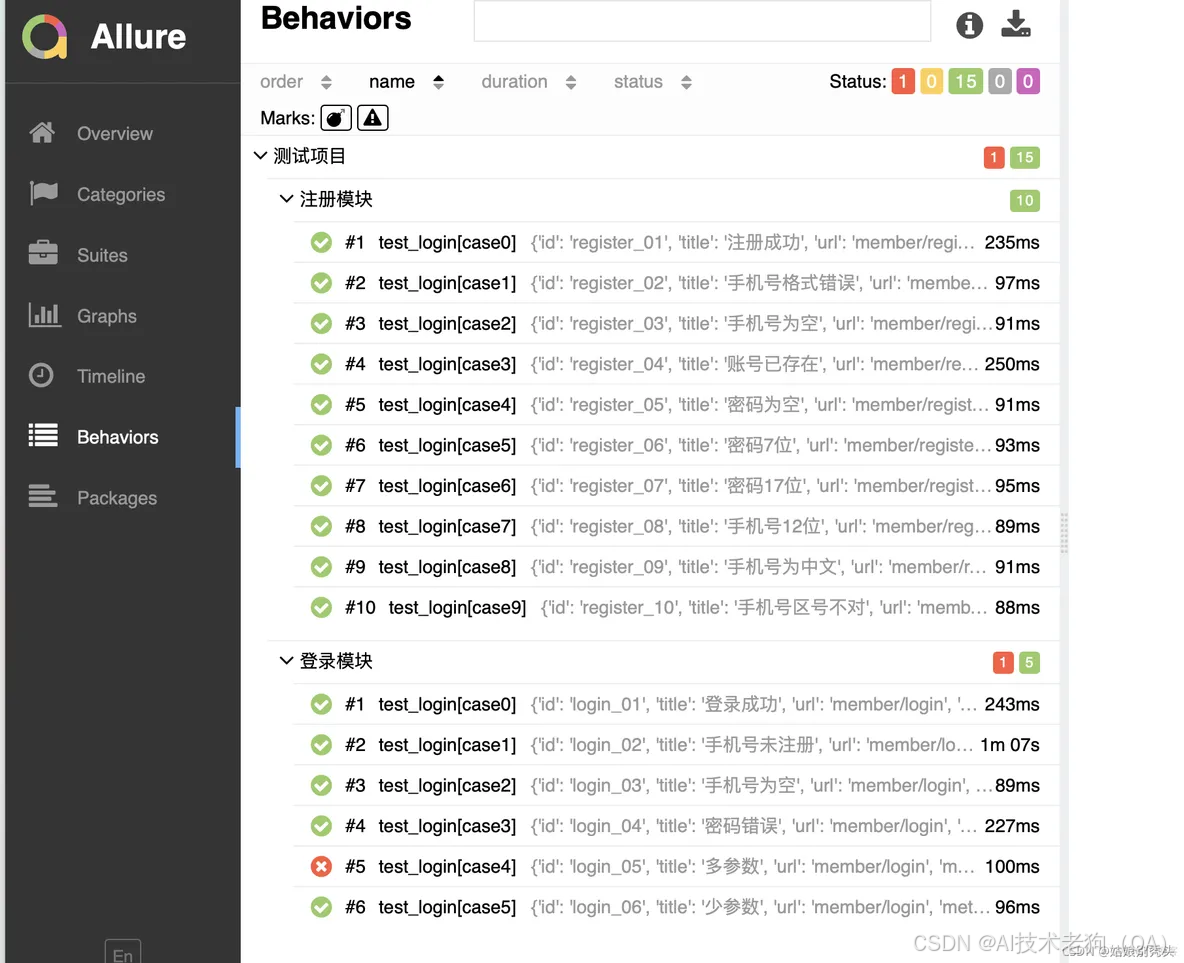
定制化测试报告
Feature: 标注主要功能模块
Story: 标注Features功能模块下的分支功能
Severity: 标注测试用例的重要级别
Step: 标注测试用例的重要步骤
Issue和TestCase: 标注Issue、Case,可加入URL
上述组合框架可以快速简单的实现相应的接口测试,简单上手快,同学们可以亲手实验一下。
相关文章:
【Pytest+Yaml+Allure】实现接口自动化测试框架
一、框架思想 requestsyamlpytestallure实现接口自动化框架。结合数据驱动和分层思想,将代码与数据分离,易维护,易上手。使用yaml编写编写测试用例,利用requests库发送请求,使用pytest管理用例,allure生成…...

el-input绑定点击回车事件意外触发页面刷新
小伙伴们在项目中应该还是比较常用键盘指定按键事件的,尤其是一些筛选条件的通过点击键盘回车按键去触发搜索 例如: <el-form><el-form-item label条件title><el-input v-modelformData.searchKey keydown.entersearch></el-input…...

Golang的语言特性与鸭子类型
Golang的语言特性与鸭子类型 前言 什么是鸭子类型? Suppose you see a bird walking around in a farm yard. This bird has no label that says ‘duck’. But the bird certainly looks like a duck. Also, he goes to the pond and you notice that he swims l…...

如何在Linux系统中排查GPU上运行的程序
如何在Linux系统中排查GPU上运行的程序 在Linux系统中,随着深度学习和高性能计算的普及,GPU资源的管理和监控变得越来越重要。当您遇到GPU资源不足或性能下降的问题时,需要能够快速定位并解决这些问题。本文将介绍几种常用的方法来帮助您排查…...

VSCode 新建 Python 包/模块 Pylance 无法解析
问题描述: 利用 VSCode 写代码,在项目里新建一个 Python 包或者模块,然后在其他文件里正常导入这个包或者模块时出现: Import “xxxx” could not be resolved Pylance (reportMissingImports) 也就是说 Pylance 此时无法解析我们…...

Unet++改进44:添加MogaBlock(2024最新改进模块)|在纯基于卷积神经网络的模型中进行判别视觉表示学习,具有良好的复杂性和性能权衡。
本文内容:添加MogaBlock 目录 论文简介 1.步骤一 2.步骤二 3.步骤三 4.步骤四 论文简介 通过将内核尽可能全局化,现代卷积神经网络在计算机视觉任务中显示出巨大的潜力。然而,最近在深度神经网络(dnn)内的多阶博弈论相互作用方面的进展揭示了现代卷积神经网络的表示瓶…...

计算机网络(14)ip地址超详解
先看图: 注意看第三列蓝色标注的点不会改变,A类地址第一个比特只会是0,B类是10,C类是110,D类是1110,E类是1111. IPv4地址根据其用途和网络规模的不同,分为五个主要类别(A、B、C、D、…...

【C语言】野指针问题详解及防范方法
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: C语言 文章目录 💯前言💯什么是野指针?💯未初始化的指针代码示例问题分析解决方法 💯指针越界访问代码示例问题分析解决方法 💯指向已释放内存的…...

【SVN和GIT】版本控制系统详细下载使用教程
文章目录 ** 参考文章一、什么是SVN和GIT二、软件使用介绍1 SVN安装1.1 服务端SVN下载地址1.2 客户端SVN下载地址2 SVN使用2.1 服务端SVN基础使用2.1.1 创建存储库和用户成员2.1.2 为存储库添加访问人员2.2 客户端SVN基础使用2.2.1 在本地下载库中的内容2.2.2 版本文件操作--更…...

【Vue】Vue3.0(二十六)Vue3.0中的作用域插槽
上篇文章 【Vue】Vue3.0(二十五)Vue3.0中的具名插槽 的概念和使用场景 🏡作者主页:点击! 🤖Vue专栏:点击! ⏰️创作时间:2024年11月20日17点30分 文章目录 概念使用场景示…...
神经网络(系统性学习二):单层神经网络(感知机)
此前篇章: 神经网络中常用的激活函数 神经网络(系统性学习一):入门篇 单层神经网络(又叫感知机) 单层网络是最简单的全连接神经网络,它仅有输入层和输出层,没有隐藏层。即&#x…...
)
CTF之密码学(BF与Ook)
BrainFuck(通常也被称为Brainfuck或BF)和Ook是两种非常特殊且有趣的编程语言。以下是对这两种语言的详细介绍: 一、BrainFuck 简介: BrainFuck是一种极小化的计算机语言,由Urban Mller在1993年创建。由于“fuck”在英…...

【TEST】Apache JMeter + Influxdb + Grafana
介绍 使用Jmeter发起测试,测试结果存入Influxdb,Grafana展示你的测试结果。 环境 windows 10docker desktopJDK17 安装 Apache JMeter 访问官网(Apache JMeter - Apache JMeter™)下载JMeter(目前最新版本5.6.3&a…...

SpringBoot集成多个rabbitmq
1、pom文件 <!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-amqp --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId><versio…...
)
从零开始学习数据库 day0(基础)
在当今的信息时代,数据已经成为了企业和组织最重要的资产之一。无论是电子商务平台,社交媒体,还是科研机构,几乎每个地方都离不开数据库。今天,我们将一起走进数据库的世界,学习它的基础知识,帮…...

MongoDB相关问题
视频教程 【GeekHour】20分钟掌握MongoDB Complete MongoDB Tutorial by Net Ninja MongoDB开机后调用缓慢的原因及解决方法 问题分析: MongoDB开机后调用缓慢,通常是由于以下原因导致: 索引重建: MongoDB在启动时会重建索引…...
)
linux基本命令(1)
1. 文件和目录操作 ls — 列出目录内容 ls # 显示当前目录的文件和目录 ls -l # 显示详细的文件信息(权限、大小、修改时间等) ls -a # 显示所有文件(包括隐藏文件) ls -lh # 显示详细信息并以易读的方式显示文件大小 cd — 改…...

【机器学习】超简明Python基础教程
Python是一种简单易学、功能强大的编程语言,适用于数据分析、人工智能、Web开发、自动化脚本等多个领域。本教程面向零基础学习者,逐步讲解Python的基本概念、语法和操作。 1. 安装与运行 安装Python 从官网 Welcome to Python.org 下载适合自己系统的…...

基于信创环境的信息化系统运行监控及运维需求及策略
随着信息技术的快速发展和国家对信息安全的日益重视,信创环境(信息技术应用创新环境)的建设已成为行业发展的重要趋势。本指南旨在为运维团队在基于信创环境的系统建设及运维过程中提供参考,确保项目顺利实施并满足各项技术指标和…...

【Mysql】视图--介绍和作用 视图的创建
1、介绍 (1)视图(view)是一个虚拟表,非真实存在,其本质是根据SQL语句获取动态的数据集,并为其命名,用户使用时只需使用视图名称既可获取结果集,并可以将其当作表来使用。…...

告别重装!用Systemback在Ubuntu 20.04上打造你的专属系统‘时光机’
用Systemback为Ubuntu打造专属系统时光机每次系统崩溃都要重装?开发环境配置浪费半天时间?实验室电脑和个人笔记本环境不一致?这些问题对于频繁折腾系统的开发者来说简直是噩梦。Systemback就像给Ubuntu系统装上了"时光机"…...

# 软考软件设计师 · 考前2天轻松复习与终极必背手册
软考软件设计师 考前2天轻松复习与终极必背手册📅 2026年5月21日 | 距考试仅剩2天 | D-2 轻松复习日 ⚠️ 今天的核心任务:翻看错题本 快速过一遍速记口诀 确认考场路线 心态放松 ❌ 不要学新内容!不要做难题!今天的任务只有一…...

# 软考软件设计师 · 考前3天终极实战全攻略
软考软件设计师 考前3天终极实战全攻略📅 2026年5月20日 | 距考试仅剩3天 | D-3 最终准备日 ⚠️ 今天起停止大量刷题,核心任务:熟悉机考系统 梳理答题策略 调整心态 考前物质准备📌 今日重点概览模块内容目的🖥️…...

Unity实现CS级FPS手感的四大底层契约与枪械物理精调
1. 这不是又一个“FPS入门教程”,而是一份被反复验证过的实战路线图很多人点开“Unity FPS教程”时,心里想的是:抄几段代码、拖几个预制体、跑通一个能走能跳的场景,就算交差了。我试过不下二十个标着“完整”“从零开始”的FPS项…...

8051单片机PDATA与XDATA存储访问优化解析
1. PDATA与XDATA变量生成的指令解析在8051单片机开发中,外部数据存储器的访问方式直接影响程序效率和硬件设计。作为从业十余年的嵌入式工程师,我经常需要针对不同存储区域优化代码。PDATA和XDATA作为两种常见的外部数据存储模式,其指令生成机…...

从线性智能到多维能力光谱:重新理解AI的“陌生性”与工程实践
1. 项目概述:重新审视智能的“陌生性”在人工智能领域,我们似乎总在追逐一个幽灵般的“通用智能”(AGI)——一个能在所有认知任务上媲美甚至超越人类的系统。这种想象往往基于一个根深蒂固的线性模型:智能是一个单一的…...

3步解锁Windows远程桌面多人连接:RDP Wrapper Library完整指南
3步解锁Windows远程桌面多人连接:RDP Wrapper Library完整指南 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 你是否曾因Windows家庭版无法支持多人远程桌面连接而感到困扰?当团队成员需要…...

【应用实战】基于Dify与多Agent的凭证与档案管理
一、智能文档处理:基于Dify与多Agent的凭证与档案管理革新 在金融行业,文档处理贯穿业务始终。传统的纯人工方式不仅耗时费力,而且极易出错。智能文档处理(Intelligent Document Processing, IDP)融合了OCR、自然语言处…...

【限时解密】Claude 3.5 Sonnet专属编程模式:仅开放给前500家企业的上下文感知补全协议
更多请点击: https://kaifayun.com 第一章:Claude 3.5 Sonnet编程辅助的核心能力边界与适用场景 Claude 3.5 Sonnet 在编程辅助领域展现出显著的推理深度与上下文理解能力,但其本质仍是基于大规模语言模型的生成式系统,不具备实时…...

WxJava 微信开发包 - 新手入门指南
WxJava 微信开发包 - 新手入门指南项目概览项目名称Binary Wang/WxJavaStarsGVP ⭐⭐⭐⭐⭐组织Binary Wang语言Java标签GVP, Java, 微信开发, 微信公众号, 微信支付项目简介WxJava 是一个基于 Java 的微信开发工具包,支持微信公众号、微信支付、小程序、企业微信等…...