Python 获取微博用户信息及作品(完整版)
在当今的社交媒体时代,微博作为一个热门的社交平台,蕴含着海量的用户信息和丰富多样的内容。今天,我将带大家深入了解一段 Python 代码,它能够帮助我们获取微博用户的基本信息以及下载其微博中的相关素材,比如图片等。
结果展示(文末附完整代码):

目录
结果展示(文末附完整代码):
一、代码整体介绍
二、代码准备与环境搭建
三、Weibo类的初始化方法(__init__)
1. 设置请求头(headers)
2. 设置 Cookies
四、获取用户基本信息的方法(Get和parse_user_info)
1. Get方法
2. parse_user_info方法
五、解析用户作品相关信息的方法(parse_statuses)
1. parse_statuses方法概述
2. 请求数据
3. 解析数据
六、创建文件夹路径并下载素材的方法(create_folder_path和download_video_with_requests)
1. create_folder_path方法
2. download_video_with_requests方法
七、运行代码(Run方法)
八、总结
全部代码:
注意:
一、代码整体介绍
我们先来看一下这段代码的整体结构。这段代码定义了一个名为Weibo的类,在这个类中包含了多个方法,每个方法都承担着特定的功能,共同协作实现了从获取用户信息到解析并下载相关素材的完整流程。
二、代码准备与环境搭建
在开始详细讲解代码功能之前,确保你已经安装了以下必要的库:
os:用于操作系统相关的操作,比如创建文件夹等。random:虽然在这段代码中可能没有明显体现其主要作用,但它是 Python 中常用的随机数处理库,说不定在后续扩展功能时会用到哦。re:正则表达式库,用于处理文本中的匹配等操作,不过在当前代码的主要逻辑里暂时未突出其作用。requests:这是一个非常重要的库,用于发送 HTTP 请求,我们通过它来与微博的服务器进行交互,获取数据。tqdm:用于在控制台显示进度条,让我们能直观地看到下载等操作的进度情况。
如果你还没有安装这些库,可以通过以下命令在命令行中进行安装(假设你已经安装了 Python 并且配置好了相应的环境):
pip install requests tqdm
三、Weibo类的初始化方法(__init__)
当我们创建Weibo类的实例时,首先会执行__init__方法。这个方法主要做了两件重要的事情:
1. 设置请求头(headers)
请求头是我们在向微博服务器发送请求时附带的一些信息,它告诉服务器我们的客户端相关情况,比如使用的浏览器类型、版本等。在这段代码中,设置了如下的请求头信息:
self.headers = {
'填入你的headers'
}
这些信息模仿了一个常见的浏览器请求设置,有助于我们顺利地从微博服务器获取数据,避免因为请求头设置不当而被服务器拒绝访问。
2. 设置 Cookies
Cookies 是服务器在我们访问网页时发送给客户端的一些小数据块,它可以保存一些用户相关的信息,比如登录状态等。在代码中,我们设置了如下的 Cookies 信息:
self.cookies = {'填入你的cookies'
}
这里的 Cookies 信息应该是在你之前登录微博或者通过其他合法途径获取到的,它能让服务器识别我们的身份或者提供一些特定的权限,以便获取更多的用户相关数据。
四、获取用户基本信息的方法(Get和parse_user_info)
1. Get方法
Get方法接受一个参数uid,这个参数就是微博用户的 ID。在这个方法中,我们首先构建了一个请求的 URL,用于获取用户的基本信息:
url = "https://weibo.com/ajax/profile/info"
params = {"uid": uid
}
response = requests.get(url, headers=self.headers, cookies=self.cookies, params=params).json()
self.parse_user_info(response)
这里通过requests库发送了一个 GET 请求到指定的 URL,并带上了设置好的请求头、Cookies 以及用户 ID 作为参数。获取到响应后,我们将其转换为 JSON 格式,然后调用parse_user_info方法来进一步解析这些数据。
2. parse_user_info方法
这个方法主要负责解析从服务器获取到的用户基本信息。它从响应数据中提取出了以下关键信息:
- 用户名称:通过
Weibo_name = response.get('data').get('user').get('screen_name')获取。 - 用户粉丝数量:
followers_count = response.get('data').get('user').get('followers_count')。 - 用户关注数量:
follow_count = response.get('data').get('user').get('friends_count')。 - 用户描述信息:
description = response.get('data').get('user').get('description')。 - 用户微博认证信息:
verified_reason = response.get('data').get('user').get('verified_reason')。
最后,还会将这些提取到的信息打印出来,方便我们查看:
print(Weibo_name, followers_count, follow_count, description, verified_reason)
五、解析用户作品相关信息的方法(parse_statuses)
1. parse_statuses方法概述
parse_statuses方法同样接受用户 ID 作为参数uid,它的主要目的是获取和解析用户发布的微博作品相关信息,比如微博内容、发布时间、包含的图片等。
2. 请求数据
首先,构建请求的 URL 和参数:
url = "https://weibo.com/ajax/statuses/mymblog"
params = {"uid": uid,"page": "0","feature": "0"
}
response = requests.get(url, headers=self.headers, cookies=self.cookies, params=params).json()
这里向另一个用于获取用户微博作品的 URL 发送了 GET 请求,并获取到响应数据,同样将其转换为 JSON 格式。
3. 解析数据
获取到响应后,从数据中提取出了以下重要信息:
- 微博内容(原始文本):
text_raw = statuses.get('text_raw')。 - 发布时间:
created_at = statuses.get('created_at')。 - 图片 ID 列表:
pic_ids = statuses.get('pic_ids')。 - 地区名称:
region_name = statuses.get('region_name')。
并且对于图片 ID 列表中的每一个图片 ID,还会进一步获取其最大尺寸的图片 URL:
i = []
for pic_id in pic_ids:pic_infos_urls = statuses.get('pic_infos').get(pic_id).get('largest').get('url')i.append(pic_infos_urls)
最后,会将这些提取到的信息(微博内容、发布时间、图片 URL 列表、地区名称)打印出来,并调用create_folder_path方法来处理这些信息,以便后续下载相关素材。
六、创建文件夹路径并下载素材的方法(create_folder_path和download_video_with_requests)
1. create_folder_path方法
这个方法首先根据获取到的微博用户名称创建一个以用户名为名称的主文件夹(如果不存在的话):
materials_dir = Weibo_name
if not os.path.exists(materials_dir):os.makedirs(materials_dir)
然后根据微博内容的前两个字符创建一个子文件夹,用于存放相关素材:
folder_name = str(title[:2])
folder_path = os.path.join(materials_dir, folder_name)
if not os.path.exists(folder_path):os.makedirs(folder_path)
最后,调用download_video_with_requests方法,将创建好的文件夹路径和图片 URL 列表作为参数传递过去,以便下载图片素材。
2. download_video_with_requests方法
这个方法负责实际的图片下载操作。它通过遍历图片 URL 列表,使用requests库发送请求获取图片数据,并将其保存到指定的文件夹路径下。在下载过程中,还使用了tqdm库来显示下载进度条,让我们能清楚地看到下载的进度情况。
try:j = 1for url in tqdm(i, desc="下载素材进度"):response = requests.get(url)image_name = f'{j}.{url[-3:]}' # 图片名称为数字+扩展名j += 1 # 累加计数器image_path = os.path.join(save_path, image_name)if response.status_code == 200:with open(image_path, 'wb') as f:total_size = int(response.headers.get('content-length', 0))block_size = 1024 # 每次写入的块大小progress_bar = tqdm(total=total_size, unit='iB', unit_scale=True)f.write(response.content)progress_bar.update(len(response.content))progress_bar.close()print(f"素材 {image_name} 已成功下载到 {save_path}")else:print(f"下载素材 {image_name} 失败,状态码: {response.status_code}")
except requests.exceptions.RequestException as e:print(f"下载素材时出错: {e}")
七、运行代码(Run方法)
最后,我们来看一下Run方法。这个方法是整个程序的入口点,当我们直接运行脚本时,就会执行这个方法。在这个方法中,首先会提示用户输入要获取信息的微博用户 ID:
uid = int(input('请输入你要获取信息的id:'))
然后依次调用Get方法和parse_statuses方法,来完成获取用户基本信息和解析用户作品相关信息以及下载相关素材的整个流程。
八、总结
全部代码:
# -*- coding:utf-8 -*-
import os
import random
import re
import requests
from tqdm import tqdmclass Weibo(object):def __init__(self):self.headers = {}self.cookies = {}# 传参uid输入用户id来获取数据def Get(self, uid):url = "https://weibo.com/ajax/profile/info"params = {"uid": uid}response = requests.get(url, headers=self.headers, cookies=self.cookies, params=params).json()self.parse_user_info(response)def parse_user_info(self, response):"""解析用户基本信息"""global Weibo_name# 获取用户名称Weibo_name = response.get('data').get('user').get('screen_name')# 获取用户粉丝数量followers_count = response.get('data').get('user').get('followers_count')# 获取用户关注数量follow_count = response.get('data').get('user').get('friends_count')# 获取用户描述信息description = response.get('data').get('user').get('description')# 获取用户微博认证信息verified_reason = response.get('data').get('user').get('verified_reason')# 打印数据print(Weibo_name, followers_count, follow_count, description, verified_reason)def parse_statuses(self, uid):"""解析用户作品相关信息"""url = "https://weibo.com/ajax/statuses/mymblog"params = {"uid": uid,"page": "0","feature": "0"}response = requests.get(url, headers=self.headers, cookies=self.cookies, params=params).json()statuses_list = response.get('data').get('list')since_id = response.get('data').get('since_id')print(since_id)for statuses in statuses_list:text_raw = statuses.get('text_raw')created_at = statuses.get('created_at')pic_ids = statuses.get('pic_ids')print(pic_ids)region_name = statuses.get('region_name')i = []for pic_id in pic_ids:pic_infos_urls = statuses.get('pic_infos').get(pic_id).get('largest').get('url')i.append(pic_infos_urls)print(text_raw, created_at, i, region_name)self.create_folder_path(text_raw,i)def create_folder_path(self, title,i):materials_dir = Weibo_nameif not os.path.exists(materials_dir):os.makedirs(materials_dir)folder_name = str(title[:2])folder_path = os.path.join(materials_dir, folder_name)if not os.path.exists(folder_path):os.makedirs(folder_path)self.download_video_with_requests(folder_path,i)def download_video_with_requests(self, save_path, i):try:j = 1for url in tqdm(i, desc="下载素材进度"):response = requests.get(url)image_name = f'{j}.{url[-3:]}' # 图片名称为数字+扩展名j += 1 # 累加计数器image_path = os.path.join(save_path, image_name)if response.status_code == 200:with open(image_path, 'wb') as f:total_size = int(response.headers.get('content-length', 0))block_size = 1024 # 每次写入的块大小progress_bar = tqdm(total=total_size, unit='iB', unit_scale=True)f.write(response.content)progress_bar.update(len(response.content))progress_bar.close()print(f"素材 {image_name} 已成功下载到 {save_path}")else:print(f"下载素材 {image_name} 失败,状态码: {response.status_code}")except requests.exceptions.RequestException as e:print(f"下载素材时出错: {e}")def Run(self):uid = int(input('请输入你要获取信息的id:'))self.Get(uid)self.parse_statuses(uid)if __name__ == '__main__':spider = Weibo()spider.Run()通过以上对这段 Python 代码的详细讲解,我们可以看到它能够实现从微博获取用户基本信息以及下载用户微博中相关素材的功能。当然,在实际使用过程中,你可能需要根据自己的需求对代码进行一些调整和扩展,比如处理更多类型的素材、优化错误处理等。希望这篇教程能帮助你更好地理解和运用这段代码,让你在获取微博数据方面更加得心应手。
注意:
在使用本代码获取微博数据时,请务必遵守相关法律法规以及微博平台的使用规则和服务协议。本代码仅用于学习和研究目的,不得用于任何非法的商业用途或侵犯他人隐私、权益的行为。若因不当使用本代码而导致的任何法律纠纷或不良后果,使用者需自行承担全部责任。在进行数据抓取操作之前,请确保你已经充分了解并获得了合法的授权与许可,尊重网络平台的生态环境和其他用户的合法权益。
相关文章:
Python 获取微博用户信息及作品(完整版)
在当今的社交媒体时代,微博作为一个热门的社交平台,蕴含着海量的用户信息和丰富多样的内容。今天,我将带大家深入了解一段 Python 代码,它能够帮助我们获取微博用户的基本信息以及下载其微博中的相关素材,比如图片等。…...
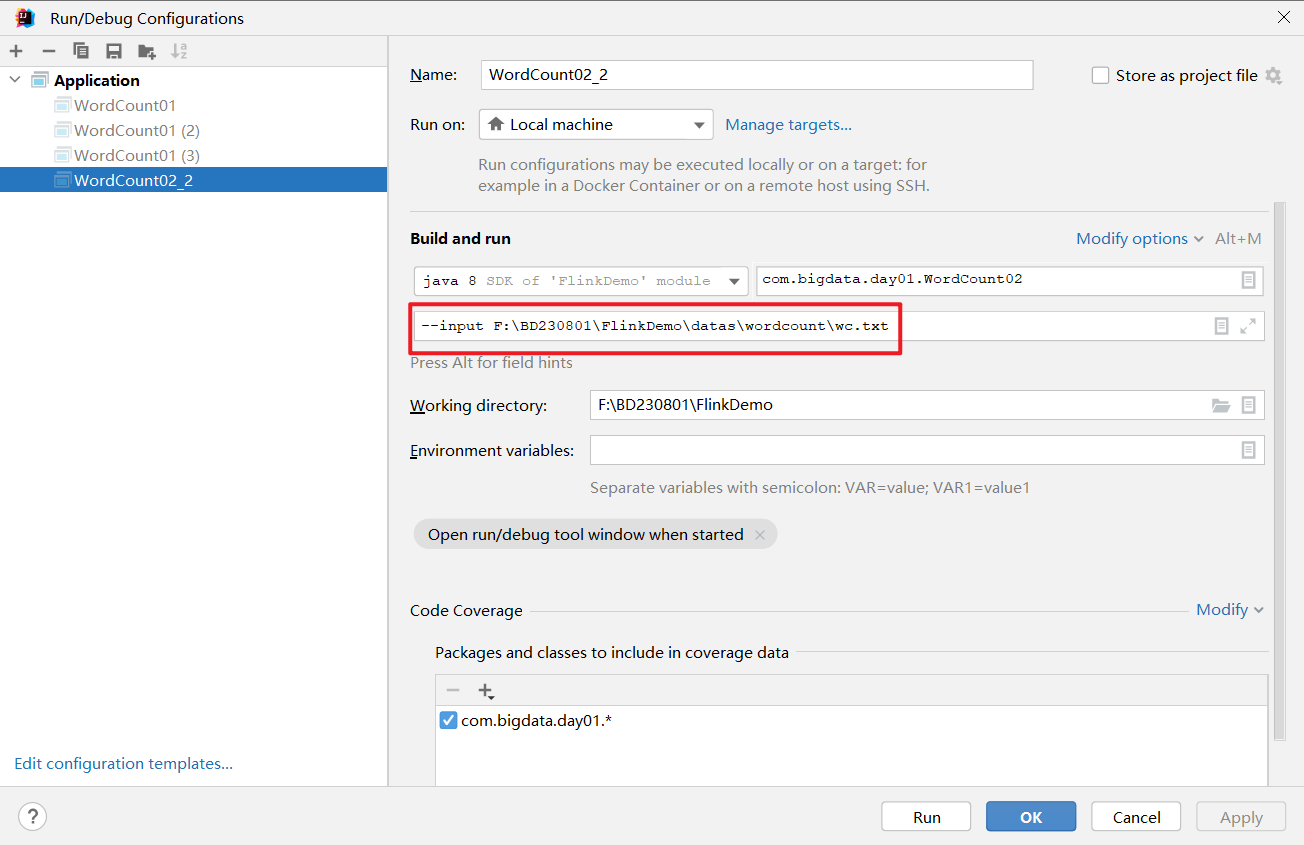
Flink学习连载第二篇-使用flink编写WordCount(多种情况演示)
使用Flink编写代码,步骤非常固定,大概分为以下几步,只要牢牢抓住步骤,基本轻松拿下: 1. env-准备环境 2. source-加载数据 3. transformation-数据处理转换 4. sink-数据输出 5. execute-执行 DataStream API开发 //n…...
是数学分析中用于解决带有约束条件的优化问题的一种重要方法,特别是SVM)
拉格朗日乘子(Lagrange Multiplier)是数学分析中用于解决带有约束条件的优化问题的一种重要方法,特别是SVM
拉格朗日乘子(Lagrange Multiplier)是数学分析中用于解决带有约束条件的优化问题的一种重要方法,也称为拉格朗日乘数法。 例如之前博文写的2月7日 SVM&线性回归&逻辑回归在支持向量机(SVM)中,为了…...

鸿蒙征文|鸿蒙心路旅程:始于杭研所集训营,升华于横店
始于杭研所 在2024年7月,我踏上了一段全新的旅程,前往风景如画的杭州,参加华为杭研所举办的鲲鹏&昇腾集训营。这是一个专门为开发者设计的培训项目,中途深入学习HarmonyOS相关技术。对于我这样一个对技术充满热情的学生来说&…...

c语言数据结构与算法--简单实现线性表(顺序表+链表)的插入与删除
老规矩,点赞评论收藏关注!!! 目录 线性表 其特点是: 算法实现: 运行结果展示 链表 插入元素: 删除元素: 算法实现 运行结果 线性表是由n个数据元素组成的有限序列ÿ…...
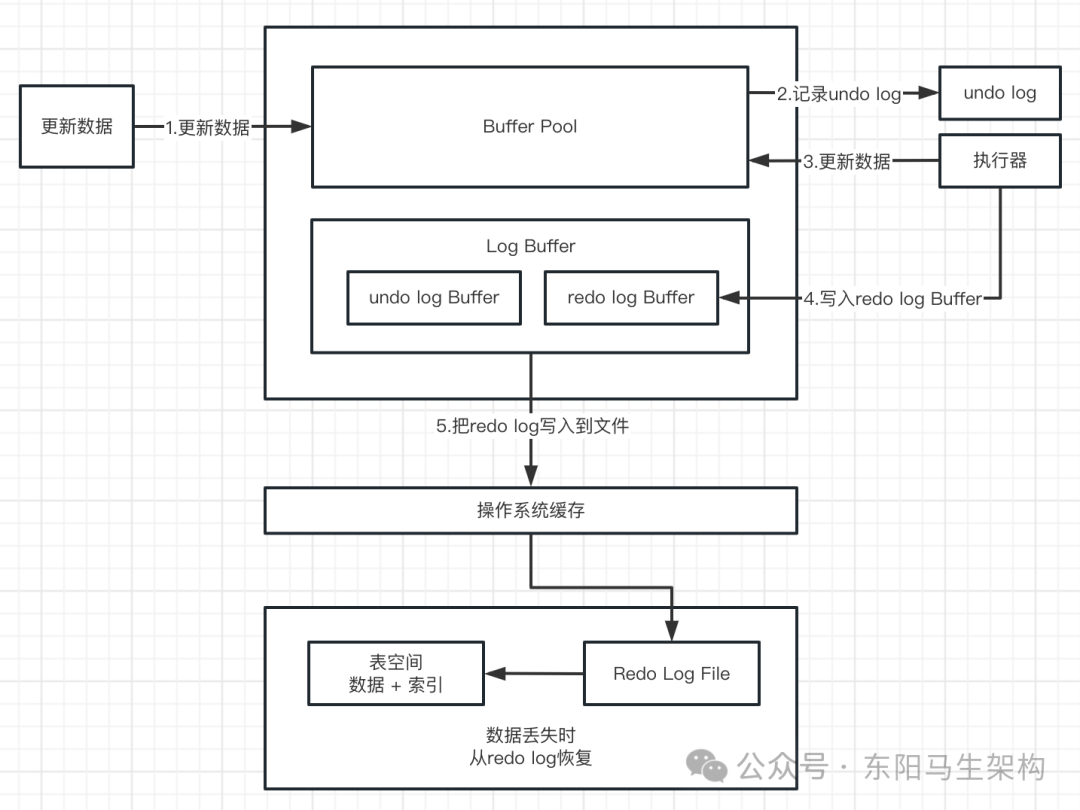
MySQL底层概述—1.InnoDB内存结构
大纲 1.InnoDB引擎架构 2.Buffer Pool 3.Page管理机制之Page页分类 4.Page管理机制之Page页管理 5.Change Buffer 6.Log Buffer 1.InnoDB引擎架构 (1)InnoDB引擎架构图 (2)InnoDB内存结构 (1)InnoDB引擎架构图 下面是InnoDB引擎架构图,主要分为内存结构和磁…...
计算两个日期天数之差)
MySQL:DATEDIFF()计算两个日期天数之差
题目需求: 计算出比前一天温度要高的日期。 select a.id from weather a, weather b where a.temperature > b.temperature and datediff(a.recordDate, b.recordDate) 1; DATEDIFF(date1, date2)函数用于计算两个日期之间的天数差。函数返回date1和date2之…...

Linux 编译Ubuntu24内核
参考来源: 编译并更新内核:https://www.cnblogs.com/smlile-you-me/p/18248433 编译报错–sub-make: https://forum.linuxfoundation.org/discussion/865005/facing-error-in-building-the-kernel 1.下载源码,执行如下命令,会在/usr/src下多…...

Android系统中init进程、zygote进程和SystemServer进程简单学习总结
Android系统中,init、zygote和SystemServer进程是系统启动和运行的关键进程,它们之间有着密切的关系,本文针对这三个进程的学习做一个简单汇总,方便后续查询。 1、init进程 Android用户空间执行的第一个程序就是它,可…...

Flask 基于wsgi源码启动流程
1. 点击 __call__ 进入到源码 2. 找到 __call__ 方法 return 执行的是 wsgi方法 3. 点击 wsgi 方法 进到 wsgi return 执行的是 response 方法 4. 点击response 方法 进到 full_dispatch_request 5. full_dispatch_request 执行finalize_request 方法 6. finalize_request …...

leetcode代码 50道答案
简单难度:两数之和 def twoSum(nums, target): for i in range(len(nums)): for j in range(i 1, len(nums)): if nums[i] nums[j] target: return [i, j] return [] 简单难度:有效的括号 def isVa…...

Centos-stream 9,10 add repo
Centos-stream repo前言 Centos-stream 9,10更换在线阿里云创建一键更换repo 自动化脚本 华为centos-stream 源 , 阿里云centos-stream 源 华为epel 源 , 阿里云epel 源vim /centos9_10_repo.sh #!/bin/bash # -*- coding: utf-8 -*- # Author: make.h...

【隐私计算大模型】联邦深度学习之拆分学习Split learning原理及安全风险、应对措施以及在大模型联合训练中的应用案例
Tips:在两方场景下,设计的安全算法,如果存在信息不对等性,那么信息获得更多的一方可以有概率对另一方实施安全性攻击。 1. 拆分学习原理 本文介绍了一种适用于隐私计算场景的深度学习实现方案——拆分学习,又称分割…...

DataWhale—PumpkinBook(TASK05决策树)
课程开源地址及相关视频链接:(当然这里也希望大家支持一下正版西瓜书和南瓜书图书,支持文睿、秦州等等致力于开源生态建设的大佬✿✿ヽ(▽)ノ✿) Datawhale-学用 AI,从此开始 【吃瓜教程】《机器学习公式详解》(南瓜…...

elasticsearch7.10.2集群部署带认证
安装elasticsearch rpm包安装 下载地址 https://mirrors.aliyun.com/elasticstack/7.x/yum/7.10.2/ 生成证书 #1.生成CA证书 # 生成CA证书,执行命令后,系统还会提示你输入密码,可以直接留空 cd /usr/share/elasticsearch/bin ./elasticsearch-certutil ca#会在/usr/share/el…...

Java基础-I/O流
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 字节流 定义 说明 InputStream与OutputStream示意图 说明 InputStream的常用方法 说明 OutputStrea…...
全面解析多种mfc140u.dll丢失的解决方法,五种方法详细解决
当你满心期待地打开某个常用软件,却突然弹出一个错误框,提示“mfc140u.dll丢失”,那一刻,你的好心情可能瞬间消失。这种情况在很多电脑用户的使用过程中都可能出现。无论是游戏玩家还是办公族,面对这个问题都可能不知所…...

详细探索xinput1_3.dll:功能、问题与xinput1_3.dll丢失的解决方案
本文旨在深入探讨xinput1_3.dll这一动态链接库文件。首先介绍其在计算机系统中的功能和作用,特别是在游戏和输入设备交互方面的重要性。然后分析在使用过程中可能出现的诸如文件丢失、版本不兼容等问题,并提出相应的解决方案,包括重新安装相关…...
)
InfluxDB时序数据库笔记(一)
InfluxDB笔记一汇总 1、时间序列数据库概述2、时间序列数据库特点3、时间序列数据库应用场景4、InfluxDB数据生命周期5、InfluxDB历史数据需要另外归档吗?6、InfluxDB历史数据如何归档?7、太麻烦了,允许的话选择设施完备的InfluxDB云产品吧8、…...

Spring Boot 3.x + OAuth 2.0:构建认证授权服务与资源服务器
Spring Boot 3.x OAuth 2.0:构建认证授权服务与资源服务器 前言 随着Spring Boot 3的发布,我们迎来了许多新特性和改进,其中包括对Spring Security和OAuth 2.0的更好支持。本文将详细介绍如何在Spring Boot 3.x版本中集成OAuth 2.0…...
)
告别调包:手把手教你用PyTorch从零复现CRNN文本识别网络(附完整代码)
从零构建CRNN文本识别引擎:PyTorch实战指南与工业级优化技巧 在计算机视觉领域,文本识别技术正经历着从传统算法到深度学习的革命性转变。当我们谈论OCR(光学字符识别)时,CRNN(卷积循环神经网络࿰…...

番茄小说下载器:一站式离线阅读与听书解决方案
番茄小说下载器:一站式离线阅读与听书解决方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 还在为网络不稳定而无法畅快阅读番茄小说烦恼吗?想要在通…...
Pixel Dream Workshop 助力前端开发:Vue.js 项目动态视觉素材生成指南
Pixel Dream Workshop 助力前端开发:Vue.js 项目动态视觉素材生成指南 1. 为什么前端开发者需要关注视觉素材生成 作为一名Vue.js开发者,你可能经常遇到这样的困扰:产品经理突然要求给新功能加个炫酷的Banner图,设计师资源紧张排…...

Scarab:重新定义空洞骑士模组管理体验
Scarab:重新定义空洞骑士模组管理体验 【免费下载链接】Scarab An installer for Hollow Knight mods written in Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 在独立游戏模组管理领域,手动复制文件、解决版本冲突和跟踪更新的…...
)
告别散斑噪声困扰:用PyTorch手把手实现DenoDet的频域去噪模块(附完整代码)
频域魔法:用PyTorch实现SAR图像去噪的工程实践 当你在处理SAR图像时,是否曾被那些恼人的散斑噪声困扰?这些像胡椒粒一样随机分布的噪声点不仅影响视觉效果,更会严重干扰目标检测的准确性。传统方法试图在空间域直接对抗噪声&#…...

惊艳!Pi0具身智能v1动作轨迹可视化:关节控制曲线清晰呈现
惊艳!Pi0具身智能v1动作轨迹可视化:关节控制曲线清晰呈现 1. 具身智能的动作可视化革命 在机器人实验室里,工程师小李正盯着屏幕上一堆杂乱的数据点发愁——这是他们最新研发的机械臂在执行抓取任务时生成的关节角度数据。理论上这些数字应…...

内核热补丁和function trace的兼容性浅析
本文代码基于linux内核4.19.195. 之前的文章简要讲解了内核热补丁的原理,也提到了热补丁是基于ftrace框架实现的。平时我们在用ftrace时,最常用的功能当属function tracer了。这天一个有趣的问题突然浮现在我的脑海里: 如果我对同一个函数&am…...

保姆级教程:在Ubuntu上复现‘easy溯源’靶场,手把手教你分析反弹Shell和内网穿透痕迹
在Ubuntu上复现‘easy溯源’靶场:从环境搭建到痕迹分析实战指南 当你第一次接触应急响应时,是否曾被各种专业术语和复杂场景搞得晕头转向?本文将带你从零开始,在Ubuntu系统上完整复现一个名为easy溯源的靶场环境。这不是简单的解题…...

PyTorch张量操作实战:从基础运算到高效数据处理
1. PyTorch张量基础:从零开始理解多维数组 第一次接触PyTorch张量时,我完全被这个看似复杂的概念搞懵了。直到有一天,我把张量想象成俄罗斯套娃,突然就豁然开朗了。最外层的套娃是最高维度,每打开一层就降一个维度&…...

深入剖析Dynamic-Datasource:迭代器模式在数据源扩展中的完整实现指南
深入剖析Dynamic-Datasource:迭代器模式在数据源扩展中的完整实现指南 【免费下载链接】dynamic-datasource dynamic datasource for springboot 多数据源 动态数据源 主从分离 读写分离 分布式事务 项目地址: https://gitcode.com/gh_mirrors/dy/dynamic-dataso…...