Hive离线数仓结构分析
Hive离线数仓结构

首先,在数据源部分,包括源业务库、用户日志、爬虫数据和系统日志,这些都是数据的源头。这些数据通过Sqoop、DataX或 Flume 工具进行提取和导入操作。这些工具负责将不同来源的数据传输到基于 Hive 的离线数据仓库中。
在离线数据仓库中,数据会依次经过多个处理层。最开始是 ODS(操作数据存储)层,这里存储的是从数据源导入的原始数据。接着数据流向 DWD(数据仓库明细)层,在此层对原始数据进行清洗和预处理,确保数据质量。之后是 DWM(数据仓库中间)层,在这一层进行数据的聚合和整合,生成中间结果。然后是 DWS(数据仓库服务)层,该层主要是为数据分析和应用提供数据服务。最后是DM(数据集市)层,针对特定业务需求进行数据定制和汇总。
在数据仓库处理过程中,分布式离线计算起到了关键作用。图中展示了几种常用的分布式计算框架,包括MapReduce、Hive SQL、Impala和 Spark SQL。这些框架用于处理和分析数据仓库中的数据,确保数据处理的高效性和准确性。
数仓分层
为什么分层?
作为一名数据的规划者,我们肯定希望自己的数据能够有秩序地流转,数据的整个生命周期能够清晰明确被设计者和使用者感知到。直观来讲就是如图这般层次清晰、依赖关系直观。但是,大多数情况下,我们完成的数据体系却是依赖复杂、层级混乱的。在不知不觉的情况下,我们可能会做出一套表依赖结构混乱,甚至出现循环依赖的数据体系。
因此,我们需要一套行之有效的数据组织和管理方法来让我们的数据体系更有序,这就是谈到的数据分层。数据分层并不能解决所有的数据问题,但是,数据分层却可以给我们带来如下的好处:
-
清晰数据结构:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解。
-
复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题。
-
便于维护:当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
-
减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少重复开发的工作量。
-
高性能:数据仓库的构建将大大缩短获取信息的时间,数据仓库作为数据的集合,所有的信息都可以从数据仓库直接获取,尤其对于海量数据的关联查询和复杂查询,所以数据仓库分层有利于实现复杂的统计需求,提高数据统计的效率。

ODS层(操作数据层,Operational Data Store)
数据来源与特点
数据来源广泛:直接从各个业务系统的数据库中抽取而来,如企业的ERP系统、CRM系统、电商平台的交易数据库等。这些数据基本保持了业务系统中原始数据的原貌,包括数据的格式、精度、编码等。
数据实时性强:能够快速获取业务系统中的最新数据,通常是按照一定的时间周期(如每小时、每天)进行增量抽取,以保证数据仓库中的数据与业务系统数据的同步性在可接受范围内。
功能作用
数据集成:将不同业务系统、不同类型的数据整合到一起,解决了数据分散在多个系统中的问题,为后续的数据处理提供了统一的数据基础。
数据缓冲:作为业务数据进入数据仓库的第一层,起到了缓冲的作用,避免了直接对业务系统数据库的频繁查询和读取,减轻了业务系统的压力。
支持快速查询:可以满足一些对实时性要求较高、查询相对简单的业务需求,如实时监控业务数据的变化、快速获取当天的业务订单数量等。
DIM层(维度层,Dimension)
数据构成与特性
维度数据丰富:主要包含了描述业务事实的各种维度信息,如时间维度(年、月、日、时等)、地理维度(国家、地区、城市等)、产品维度(产品类别、品牌、型号等)、客户维度(客户类型、年龄、性别等)。
数据相对稳定:维度数据一旦确定,通常不会频繁更改,具有较高的稳定性。例如,产品的类别和品牌一般不会经常变动。
功能作用
提供分析维度:为数据分析和决策支持提供了丰富的维度视角,通过与其他层的数据进行关联,可以从不同的维度对业务事实进行分析和挖掘。
数据标准化:对维度数据进行统一的编码、分类和标准化处理,确保在整个数据仓库中维度信息的一致性和准确性,便于进行跨部门、跨业务的数据分析和比较。
支持数据钻取:方便用户在数据分析过程中进行维度的上卷和下钻操作,例如从年维度钻取到月维度,或者从产品类别维度下钻到具体的产品型号维度,以满足不同层次的分析需求。
DWD层(明细数据层,Data Warehouse Detail)
数据处理与特征
数据清洗与转换:对从ODS层抽取上来的数据进行清洗,去除噪声数据、重复数据,处理缺失值等,并根据业务规则进行数据转换,如数据类型的统一、字段的拆分和合并等。
明细数据存储:以业务过程为单位,存储经过清洗和转换后的详细业务数据,这些数据能够完整地反映每个业务过程的细节信息,如每一笔订单的详细信息、每一次客户访问的记录等。
功能作用
数据质量提升:通过清洗和转换操作,提高了数据的质量,为后续的数据分析和应用提供了准确、可靠的数据基础。
支持明细查询:能够满足对业务数据进行详细查询和分析的需求,例如查询某一订单的具体交易信息、某一客户在特定时间段内的所有访问记录等。
为数据聚合做准备:作为数据聚合的基础层,为DWS层和ADS层提供了详细的数据支持,便于进行各种维度的汇总和统计分析。
DWM 层(数据仓库中间层,Data Warehouse Middle)
数据处理方式与特点
轻度汇总处理:对 DWD 层的明细数据进行轻度汇总操作。这种汇总操作介于明细数据和高度汇总数据之间,例如按小时对用户登录次数进行汇总,或按天对商品点击量进行汇总。
数据整合与转换:将来自多个不同数据源的 DWD 层数据进行整合,并进行必要的数据转换。比如将不同格式的日期数据统一转换为标准格式,或者将不同编码的产品类别进行统一编码。
关联分析处理:对存在关联关系的数据进行处理,挖掘数据间的潜在联系。例如将用户的浏览行为数据和购买行为数据进行关联,分析用户的购买决策过程。
功能作用
数据优化与预处理:通过轻度汇总、转换和关联处理,优化数据结构,为后续更复杂的数据分析和处理提供更便捷的数据基础,减少数据处理复杂性。
支持实时分析需求:能够快速地为一些实时性较强的数据分析需求提供数据支持,如实时监控某产品在当天的销售趋势,通过 DWM 层已处理的数据可以快速获取相关信息。
辅助数据挖掘工作:为数据挖掘任务提供经过初步处理的数据,提高数据挖掘的效率和准确性。例如在进行用户细分的数据挖掘项目时,DWM 层处理的数据可以帮助更准确地识别不同用户群体的特征。
DWS层(汇总数据层,Data Warehouse Summary)
数据汇总方式与特点
基于维度汇总:根据预先定义的业务规则和分析需求,按照一定的维度对DWD层的明细数据进行汇总,如按天、周、月等时间维度对订单金额进行汇总,或者按地区、产品类别等维度对销售量进行汇总。
轻度汇总数据:汇总的程度相对较轻,一般保留了关键的维度信息和汇总指标,既能满足一定的分析需求,又不至于丢失过多的细节信息,具有较好的灵活性和扩展性。
功能作用
提高查询效率:通过预先的汇总计算,大大减少了查询时需要处理的数据量,提高了数据分析的效率,能够快速响应用户的分析请求,如快速获取某个月的销售总额、某个地区的客户活跃度等。
支持综合分析:为企业的综合数据分析和决策支持提供了有力的数据支持,能够从多个维度对业务数据进行综合分析,发现业务的趋势、规律和问题。
数据共享与复用:作为企业内部分享和复用的数据层,不同的业务部门和分析团队可以基于DWS层的数据进行各自的分析和应用开发,减少了重复的数据处理工作。
ADS层(应用数据层,Application Data Store)
数据应用导向与特性
面向应用场景:根据具体的业务应用需求和决策场景而构建,数据具有很强的针对性和实用性,如为营销活动提供目标客户名单、为财务报表提供数据支持、为运营监控提供关键指标数据等。
数据形式多样:可以是报表、仪表盘、数据接口等多种形式,以满足不同用户和业务场景的需求。
功能作用
支持业务决策:直接为企业的业务决策提供数据支持,通过对数据的分析和展示,帮助决策者快速了解业务现状、发现问题、制定决策方案。
数据交付与输出:作为数据仓库与业务应用的接口层,将经过处理和分析的数据以合适的形式交付给业务用户,实现了数据仓库与业务应用的有效衔接,促进了数据的价值转化和应用落地。
相关文章:
Hive离线数仓结构分析
Hive离线数仓结构 首先,在数据源部分,包括源业务库、用户日志、爬虫数据和系统日志,这些都是数据的源头。这些数据通过Sqoop、DataX或 Flume 工具进行提取和导入操作。这些工具负责将不同来源的数据传输到基于 Hive 的离线数据仓库中。 在离线…...

鱼眼相机模型-MEI
参考文献: Single View Point Omnidirectional Camera Calibration from Planar Grids 1. 相机模型如下: // 相机坐标系下的点投影到畸变图像// 输入:相机坐标系点坐标cam 输出: 畸变图像素点坐标disPtvoid FisheyeCamAdapter::…...

GPT系列文章
GPT系列文章 GPT1 GPT1是由OpenAI公司发表在2018年要早于我们之前介绍的所熟知的BERT系列文章。总结:GPT 是一种半监督学习,采用两阶段任务模型,通过使用无监督的 Pre-training 和有监督的 Fine-tuning 来实现强大的自然语言理解。在 Pre-t…...
微软Ignite 2024:建立一个Agentic世界!
在今年的Microsoft Ignite 2024上,AI Agent无疑成为本次大会的重点,已经有十万家企业通过Copilot Studio创建智能体了。微软更是宣布:企业可以在智能体中,使用Azure目录中1800个LLM中的任何一个模型了! 建立一个Agent…...

windows C#-属性
属性提供了一种将元数据或声明性信息与代码(程序集、类型、方法、属性等)关联的强大方法。将属性与程序实体关联后,可以使用称为反射的技术在运行时查询该属性。 属性具有以下属性: 属性将元数据添加到您的程序中。元数据是有关程序中定义的类型的信息…...

深入浅出:JVM 的架构与运行机制
一、什么是JVM 1、什么是JDK、JRE、JVM JDK是 Java语言的软件开发工具包,也是整个java开发的核心,它包含了JRE和开发工具包JRE,Java运行环境,包含了JVM和Java的核心类库(Java API)JVM,Java虚拟…...
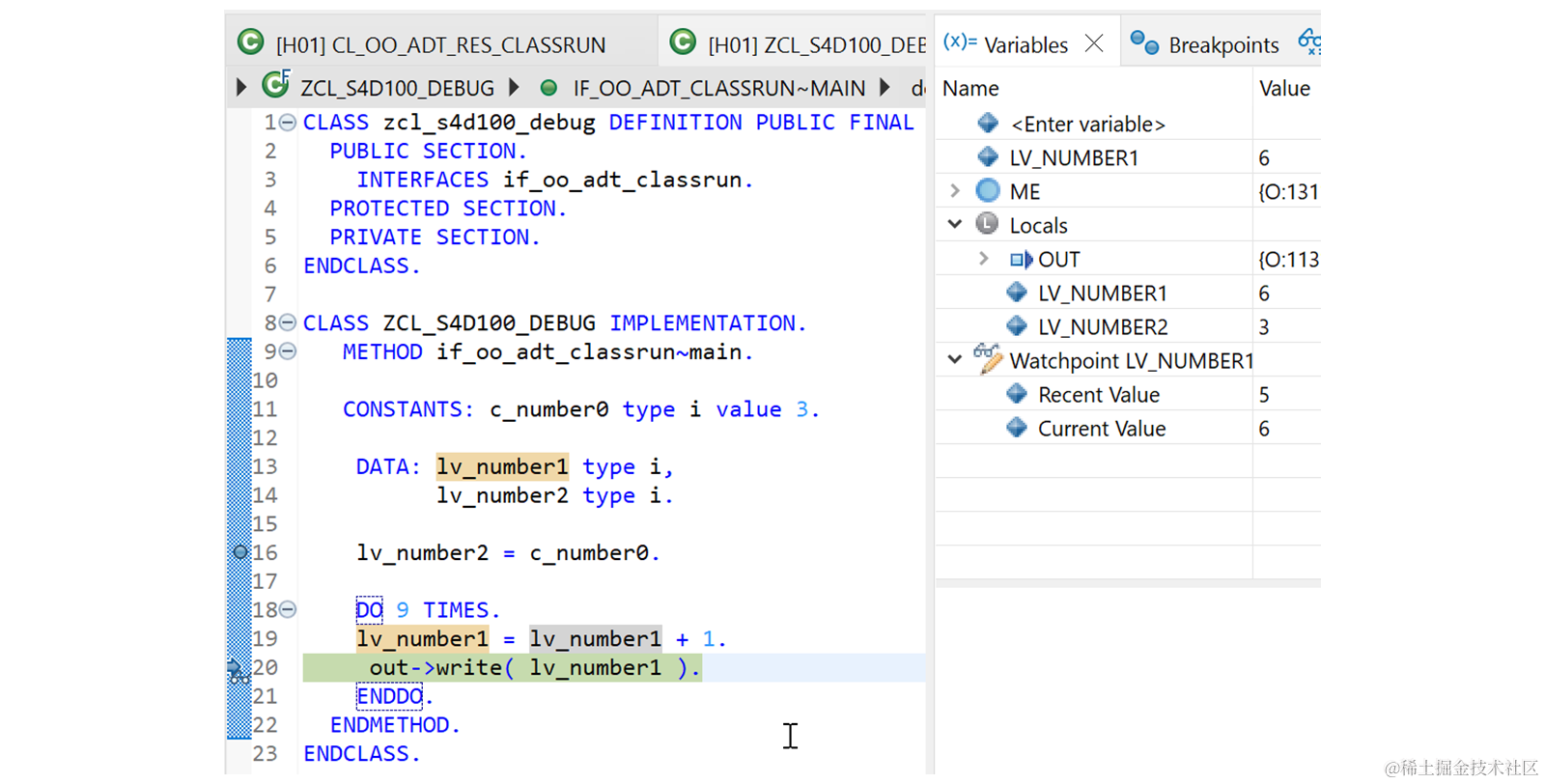
如何在 Eclipse 中调试ABAP程序
原文链接:Debugging an ABAP Program ADT 中的调试器是一个重要的诊断工具,可用于分析 ABAP 应用程序。 使用调试器,您可以通过在运行时 Debug 单步执行(F5)程序来确定程序无法正常工作的原因。这使您可以看到正在执…...

websocket是什么?
一、定义 Websocket是一种在单个TCP连接上进行全双工通信的协议,它允许服务器主动向客户端推送数据,而不需要客户端不断的轮询服务器来获取数据 与http协议不同,http是一种无状态的,请求,响应模式的协议(单向通信)&a…...

Java项目实战II基于微信小程序的图书馆自习室座位预约平台(开发文档+数据库+源码)
目录 一、前言 二、技术介绍 三、系统实现 四、文档参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。 一、前言 在知识爆炸的时代,图书馆和…...
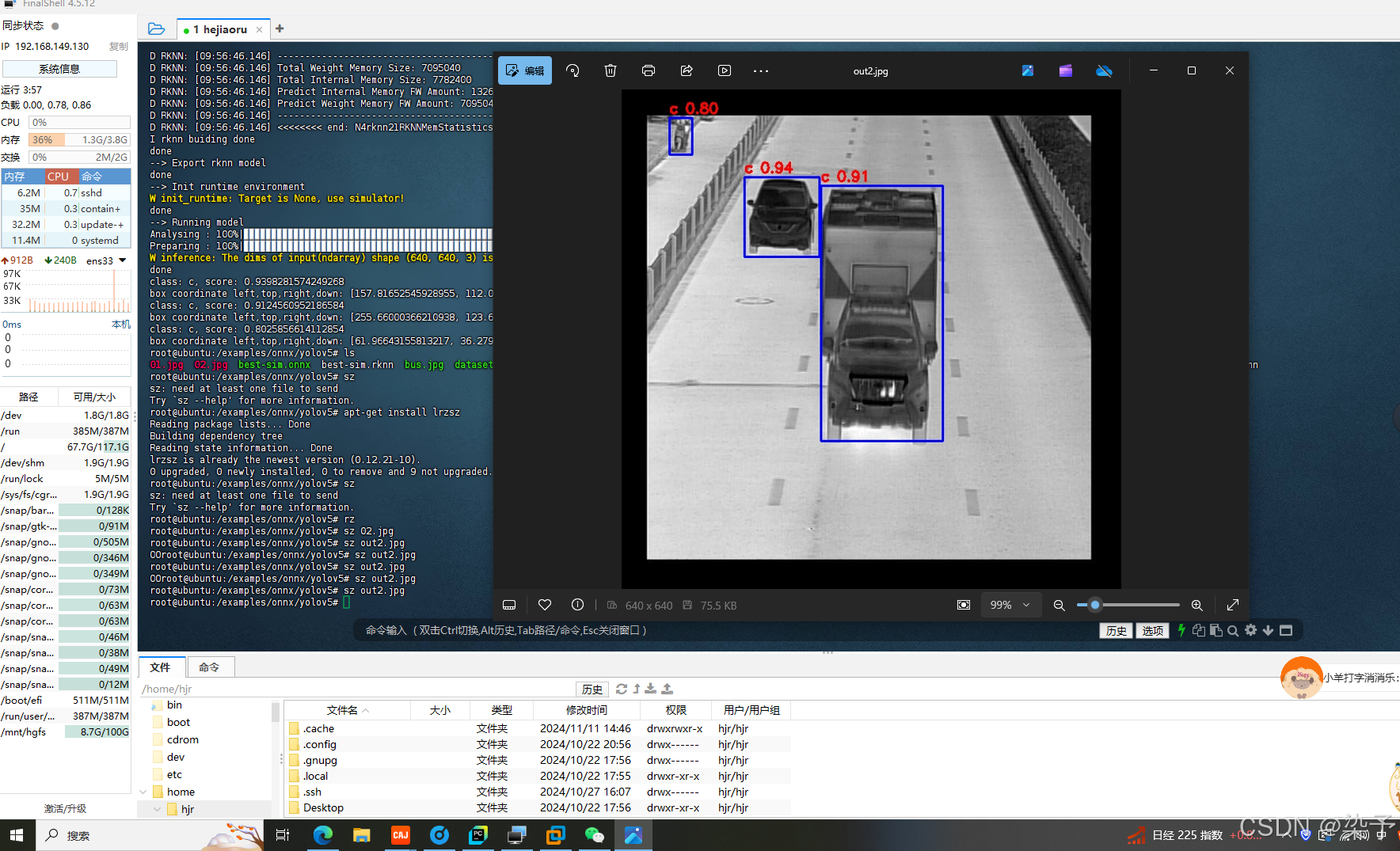
5.算法移植第六篇YOLOV5 /onnx模型转换成rknn
上两篇文章讲述了pytorch模型下best.pt转换成onnx模型,以及将onnx进行简化成为best-sim.onnx, 接下来这篇文章讲述如何将onnx模型转换成rknn模型,转换成该模型是为了在rk3568上运行 1.创建share文件夹 文件夹包含以下文件best-sim.onnx,rknn-tookit2-…...

微知-DOCA SDK中如何编译一个sample?如何运行?(meson /tmp/xxx; meson compile -C /tmp/xxx)
文章目录 快速回忆背景前期准备DOCA SDK中的例子情况编译编译request编译responser 执行测试启动响应端启动请求端查看响应端 综述参考 快速回忆 # 生成编译目录和相关文件 cd /opt/mellanox/doca/samples/doca_rdma/rdma_write_requester meson /tmp/req #将编译目录指定到/t…...
)
【Leetcode 每日一题】146. LRU 缓存(c++)
146. LRU 缓存 请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。 实现 LRUCache 类: LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值&#x…...
lnq(x)还是q(x)lnq(x)?)
【机器学习】近似分布的熵到底是p(x)lnq(x)还是q(x)lnq(x)?
【1】通信的定义 信息量(Information Content)是信息论中的一个核心概念,用于定量描述一个事件发生时所提供的“信息”的多少。它通常用随机变量 𝑥的概率分布来定义。事件 𝑥发生所携带的信息量由公式给出࿱…...

网络安全,文明上网(6)网安相关法律
列举 1. 《中华人民共和国网络安全法》: - 这是中国网络安全的基本法律,于2017年6月1日开始实施。该法律明确了网络运营者的安全保护义务,包括采取数据分类、重要数据备份和加密等措施。 2. 《中华人民共和国数据安全法》: …...
)
网络安全学习74天(记录)
11.21日,今天学习了 app抓包(需要的工具charles(激活),夜神模拟器,postern,) 思路:首先charles需要抓取的app的包,需要的是装证书,将charles的证…...

Spring Boot 实战:基于 Validation 注解实现分层数据校验与校验异常拦截器统一返回处理
1. 概述 本文介绍了在spring boot框架下,使用validation数据校验注解,针对不同请求链接的前端传参数据,进行分层视图对象的校验,并通过配置全局异常处理器捕获传参校验失败异常,自动返回校验出错的异常数据。 2. 依赖…...

20241125复盘日记
昨日最票: 南京化纤 滨海能源 广博股份 日播时尚 众源新材 返利科技 六国化工 丰华股份 威领股份 凯撒旅业 华扬联众 泰坦股份 高乐股份高均线选股: 理邦仪器高乐股份日播时尚领湃科技威领股份资金最多的票: 资金攻击最多的票: …...

【Excel】拆分多个sheet,为单一表格
Private Sub 分拆工作表() Application.ScreenUpdating True 让屏幕显示操作过程, Dim sht As Worksheet Dim MyBook As Workbook Set MyBook ActiveWorkbook For Each sht In MyBook.Sheets If sht.Visible True Then 隐藏的sheet跳过,否则会报1004无…...

类和对象plus版
一.类的定义 1.1类定义的格式 图中class为关键字,Stack为类的名字,用{}框住类的主体,类定义完后;不能省略。 为了区分成员变量,一般习惯在成员变量前面或后面加一个特殊标识,_或者m_ 1.2访问限定符 c采用…...

shell练习
开篇小贴士:为创建的sh(当然可以是任何一个文件)文件添加开头的注释 1、进入到家目录,然后通过 ls -a 查看全部文件 2、找到并编辑一个名为 .vimrc (Vim编辑器的核心配置文件)的配置文件,下图…...
)
从机器学习转做DFT计算?手把手教你用Python ASE库搞定VASP输入文件(含VC++14安装避坑)
从机器学习转做DFT计算?用Python ASE库高效构建VASP输入文件全指南 当机器学习背景的研究者首次接触第一性原理计算时,往往会被VASP等传统软件的复杂输入文件格式所困扰。POSCAR、INCAR、KPOINTS这些文件的手动编写不仅耗时,还容易出错。本文…...
)
别再死记硬背公式了!用C++ STL的next_permutation玩转排列组合(附LeetCode刷题实战)
用C STL的next_permutation玩转排列组合:LeetCode实战指南 在算法面试和编程竞赛中,排列组合问题几乎无处不在。从全排列到子集生成,这类问题看似基础,却能让不少开发者陷入递归的泥潭。但你知道吗?C标准库中早已藏着一…...

搜极星破局:拆解企业 “看不见、控不住、比不过” 困局
引言:AI 时代,企业陷入三重信息绝境2026 年,生成式 AI 全面主导用户决策链路,品牌竞争从搜索排名转向 AI 认知权重。但多数企业正深陷看不见、控不住、比不过的三重困局:看不见自身在 AI 平台的真实曝光状态࿰…...

OpenClaw微信公众号插件wemp v2:双Agent路由与混合知识库实战
1. 项目概述:一个为OpenClaw设计的微信公众号插件如果你正在寻找一个能够将你的AI助手能力无缝接入微信公众号,实现自动化客服、智能问答甚至更复杂交互的解决方案,那么你找对地方了。wemp(WeChat MP Plugin)正是这样一…...

【2025最新】基于SpringBoot+Vue的夕阳红公寓管理系统管理系统源码+MyBatis+MySQL
💡实话实说:有自己的项目库存,不需要找别人拿货再加价,所以能给到超低价格。摘要 随着人口老龄化趋势加剧,养老服务需求日益增长,传统的养老机构管理模式已难以满足高效、智能化的运营需求。夕阳红公寓管理…...

Awesome List Creator:基于规则引擎的自动化资源清单生成工具
1. 项目概述:一个清单的“引擎”在信息过载的时代,无论是开发者寻找工具库,还是学习者梳理知识体系,一份结构清晰、内容精选的“Awesome List”(优质资源清单)都堪称无价之宝。然而,维护一份高质…...

SyntaxUI:基于Tailwind CSS与Framer Motion的React组件库实战指南
1. 项目概述:SyntaxUI,一个为现代Web开发者提速的组件库如果你和我一样,常年奋战在React、Next.js项目的一线,那你一定对“重复造轮子”这件事深恶痛绝。每次新项目启动,从零开始搭建按钮、卡片、模态框、导航栏&#…...

AI图像编辑中的性别擦除现象与视觉公平性测试
1. 项目概述:当AI“擦除”男性面孔时,我们到底在测试什么?“AI Erases Men Too: A Visual Test of Bias Across Four Leading Tools”——这个标题乍看像一则科技媒体的警示快讯,但背后是一次扎实、可复现、有明确方法论支撑的视觉…...

分布式缓存策略:提升应用性能和可扩展性
分布式缓存策略:提升应用性能和可扩展性 一、分布式缓存概述 1.1 分布式缓存的定义 分布式缓存是一种将数据存储在多个节点上的缓存系统,它通过在内存中存储常用数据,减少对后端数据库的访问,从而提高应用性能和可扩展性。 1.…...

十分钟速通:GO、KEGG、COG注释与富集分析的实战指南
1. 从测序数据到功能注释的快速通道 刚拿到高通量测序数据的同学,面对海量基因序列时总会陷入迷茫:这些基因到底有什么功能?它们参与了哪些生物过程?这时候GO、KEGG和COG三大注释工具就是你的"基因翻译官"。我处理过上百…...