大数据-231 离线数仓 - DWS 层、ADS 层的创建 Hive 执行脚本
点一下关注吧!!!非常感谢!!持续更新!!!
Java篇开始了!
目前开始更新 MyBatis,一起深入浅出!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(正在更新…)
章节内容
上节我们完成了如下的内容:
- ODS层的构建 Hive处理
- UDF 处理
- SerDe 处理
- 当前总结

活跃会员
- 活跃会员:打开应用的会员即为活跃会员
- 新增会员:第一次使用英勇的会员,定义为新增会员
- 留存会员:某段时间新增会员,经过一段时间后,仍继续使用应用认为是留存会员
- 活跃会员的指标需求:每日、每周、每月的活跃会员数
DWD:会员的每日启动信息明细(会员都是活跃会员,某个会员可能会出现多次)
DWS:每日活跃会员信息(关键)、每周活跃会员信息、每月活跃会员信息
每日活跃会员信息 => 每周活跃会员信息
每日活跃会员信息 => 每月活跃会员信息
ADS:每日、每周、每月活跃会员数(输出)
ADS表结构:daycnt weekcnt monthcnt dt
备注:周、月为自然周、自然月
处理过程:
- 建表(每日、每周、每月活跃会员信息)
- 每日启动明细 => 每日活跃会员
- 每日活跃会员 => 每周活跃会员;每日活跃会员 => 每月活跃会员
- 汇总生成ADS层的数据
创建DWS层表
DWS作用
统一数据模型
将原始数据(ODS层)按照一定的逻辑模型进行整合、清洗、加工,形成标准化的数据结构。
支持对数据的多维度、多粒度分析。
支持业务场景
满足企业对历史数据的查询和分析需求。
支持 OLAP(在线分析处理)操作,如聚合查询、钻取和切片。
数据细化与分类
将数据按照主题域(如销售、财务、库存等)分类,便于管理和查询。
通常保持较高的细节粒度,便于灵活扩展。
数据准确性与一致性
经过处理的数据经过校验,确保逻辑关系正确,能够为下游提供准确的一致性数据。
编写脚本
启动Hive,进行执行:
use dws;
drop table if exists dws.dws_member_start_day;
create table dws.dws_member_start_day
(`device_id` string,`uid` string,`app_v` string,`os_type` string,`language` string,`channel` string,`area` string,`brand` string
) COMMENT '会员日启动汇总'
partitioned by(dt string)
stored as parquet;
drop table if exists dws.dws_member_start_week;
create table dws.dws_member_start_week(`device_id` string,`uid` string,`app_v` string,`os_type` string,`language` string,`channel` string,`area` string,`brand` string,`week` string
) COMMENT '会员周启动汇总'
PARTITIONED BY (`dt` string)
stored as parquet;
drop table if exists dws.dws_member_start_month;
create table dws.dws_member_start_month(`device_id` string,`uid` string,`app_v` string,`os_type` string,`language` string,`channel` string,`area` string,`brand` string,`month` string
) COMMENT '会员月启动汇总'
PARTITIONED BY (`dt` string)
stored as parquet;
执行结果如下图所示:

加载DWS层数据
vim /opt/wzk/hive/dws_load_member_start.sh
写入的内容如下所示:
#!/bin/bash
source /etc/profile
# 可以输入日期;如果未输入日期取昨天的时间
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
# 定义要执行的SQL
# 汇总得到每日活跃会员信息;每日数据汇总得到每周、每月数据
sql="
insert overwrite table dws.dws_member_start_day
partition(dt='$do_date')
select device_id,
concat_ws('|', collect_set(uid)),
concat_ws('|', collect_set(app_v)),
concat_ws('|', collect_set(os_type)),
concat_ws('|', collect_set(language)),
concat_ws('|', collect_set(channel)),
concat_ws('|', collect_set(area)),
concat_ws('|', collect_set(brand))
from dwd.dwd_start_log
where dt='$do_date'
group by device_id;
-- 汇总得到每周活跃会员
insert overwrite table dws.dws_member_start_week
partition(dt='$do_date')
select device_id,
concat_ws('|', collect_set(uid)),
concat_ws('|', collect_set(app_v)),
concat_ws('|', collect_set(os_type)),
concat_ws('|', collect_set(language)),
concat_ws('|', collect_set(channel)),
concat_ws('|', collect_set(area)),
concat_ws('|', collect_set(brand)),
date_add(next_day('$do_date', 'mo'), -7)
from dws.dws_member_start_day
where dt >= date_add(next_day('$do_date', 'mo'), -7)
and dt <= '$do_date'
group by device_id;
-- 汇总得到每月活跃会员
insert overwrite table dws.dws_member_start_month
partition(dt='$do_date')
select device_id,
concat_ws('|', collect_set(uid)),
concat_ws('|', collect_set(app_v)),
concat_ws('|', collect_set(os_type)),
concat_ws('|', collect_set(language)),
concat_ws('|', collect_set(channel)),
concat_ws('|', collect_set(area)),
concat_ws('|', collect_set(brand)),
date_format('$do_date', 'yyyy-MM')
from dws.dws_member_start_day
where dt >= date_format('$do_date', 'yyyy-MM-01')
and dt <= '$do_date'
group by device_id;
"
hive -e "$sql"
注意Shell的引号。
写入的内容如下图所示:

ODS => DWD => DWS(每日、每周、每月活跃会员的汇总表)
创建ADS层表
ADS 作用
聚合和简化数据
将 DWS 层中多表、多主题域的数据聚合成简单易用的表或视图。
直接输出满足业务需求的数据结果。
面向业务应用
通过设计宽表或高性能视图,直接支持具体的业务场景和报表需求。
响应快速查询需求,如实时数据的展示。
数据分发与集成
为前端的 BI 工具、报表系统或 API 服务提供高效的查询接口。
能够通过缓存机制或物化视图加速查询性能。
轻量化与高性能
尽量减少数据量,保留业务最关心的关键指标。
采用预聚合、预计算等技术提升查询效率。
计算当天、当周、当月活跃会员数量
drop table if exists ads.ads_member_active_count;
create table ads.ads_member_active_count(`day_count` int COMMENT '当日会员数量',`week_count` int COMMENT '当周会员数量',`month_count` int COMMENT '当月会员数量'
) COMMENT '活跃会员数'
partitioned by(dt string)
row format delimited fields terminated by ',';
执行结果如下图所示:

加载ADS层数据
vim /opt/wzk/hive/ads_load_memeber_active.sh
写入的内容如下:
#!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
with tmp as(select 'day' datelabel, count(*) cnt, dtfrom dws.dws_member_start_daywhere dt='$do_date'group by dtunion allselect 'week' datelabel, count(*) cnt, dtfrom dws.dws_member_start_weekwhere dt='$do_date'group by dtunion allselect 'month' datelabel, count(*) cnt, dtfrom dws.dws_member_start_monthwhere dt='$do_date'group by dt
)
insert overwrite table ads.ads_member_active_count
partition(dt='$do_date')
select sum(case when datelabel='day' then cnt end) as
day_count,
sum(case when datelabel='week' then cnt end) as
week_count,
sum(case when datelabel='month' then cnt end) as
month_count
from tmp
group by dt;
"
hive -e "$sql"
写入内容如下图所示:

这里有一个同样功能的脚本,可以参考对比以下:
vim /opt/wzk/hive/ads_load_memeber_active2.sh
写入内容如下:
#!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table ads.ads_member_active_count
partition(dt='$do_date')
select daycnt, weekcnt, monthcnt
from (select dt, count(*) daycntfrom dws.dws_member_start_daywhere dt='$do_date'group by dt) day join
(select dt, count(*) weekcntfrom dws.dws_member_start_weekwhere dt='$do_date'group by dt
) week on day.dt=week.dt
join
(select dt, count(*) monthcntfrom dws.dws_member_start_monthwhere dt='$do_date'group by dt
) month on day.dt=month.dt;
"
hive -e "$sql"
写入内容如下图所示:

- 第一个脚本:通过构建临时表(WITH tmp AS (…))将不同维度的数据(天、周、月)汇总到一个临时表中,再通过 SUM 计算出最终的统计结果。这种方式的灵活性较高,便于扩展。
- 第二个脚本:直接通过 JOIN 不同的子查询,将天、周、月三个维度的数据联结在一起,最后插入目标表。这种方式在性能上可能更高效,但扩展性稍差。
相关文章:
大数据-231 离线数仓 - DWS 层、ADS 层的创建 Hive 执行脚本
点一下关注吧!!!非常感谢!!持续更新!!! Java篇开始了! 目前开始更新 MyBatis,一起深入浅出! 目前已经更新到了: Hadoop࿰…...

【Python】分割秘籍!掌握split()方法,让你的字符串处理轻松无敌!
在Python开发中,字符串处理是最常见也是最基础的任务之一。而在众多字符串操作方法中,split()函数无疑是最为重要和常用的一个。无论你是Python新手,还是经验丰富的开发者,深入理解并熟练运用split()方法,都将大大提升…...

免费实用在线AI工具集合 - 加菲工具
免费在线工具-加菲工具 https://orcc.online/ 在线录屏 https://orcc.online/recorder 时间戳转换 https://orcc.online/timestamp Base64 编码解码 https://orcc.online/base64 URL 编码解码 https://orcc.online/url Hash(MD5/SHA1/SHA256…) 计算 https://orcc.online/h…...

正则表达式灾难:重新认识“KISS原则”的意义
RSS Feed 文章标题整理 微积分在生活中的应用与思维启发 捕鹿到瞬时速度的趣味探索 微积分是一扇通往更广阔世界的门,从生活中学习思维的工具。 数据库才是最强架构 你还在被“复杂架构”误导吗? 把业务逻辑写入数据库,重新定义简单与效率。…...
eNSP-缺省路由配置
缺省路由是一种特殊的静态路由,其目的地址为0.0.0.0,子网掩码为0.0.0.0。 1.拓扑图搭建 2.配置路由器 AR2 <Huawei>sys #进入系统视图 [Huawei]ip route-static 0.0.0.0 0.0.0.0 192.168.3.2 #设置缺省路由 [Huawei]q #返回上一层 <Huawe…...

solr 远程命令执行 (CVE-2019-17558)
漏洞描述 Apache Velocity是一个基于Java的模板引擎,它提供了一个模板语言去引用由Java代码定义的对象。Velocity是Apache基金会旗下的一个开源软件项目,旨在确保Web应用程序在表示层和业务逻辑层之间的隔离(即MVC设计模式)。 Apa…...

STM32端口模拟编码器输入
文章目录 前言一、正交编码器是什么?二、使用步骤2.1开启时钟2.2配置编码器引脚 TIM3 CH1(PA6) CH2 (PA7)上拉输入2.3.初始化编码器时基2.4 初始化编码器输入2.5 配置编码器接口2.6 开启定时器2.7获取编码器数据 三、参考程序四、测试结果4.1测试方法4.2串口输出结果…...

Centos 8, add repo
Centos repo前言 Centos 8更换在线阿里云创建一键更换repo 自动化脚本 华为Centos 源 , 阿里云Centos 源 华为epel 源 , 阿里云epel 源vim /centos8_repo.sh #!/bin/bash # -*- coding: utf-8 -*- # Author: make.han...
)
MYSQL- 查看存储过程调式信息语句(二十七)
13.7.5.27 SHOW PROCEDURE CODE 语句 SHOW PROCEDURE CODE proc_name此语句是MySQL扩展,仅适用于已构建有调试支持的服务器。它显示了命名存储过程的内部实现的表示。类似的语句SHOW FUNCTION CODE显示有关存储函数的信息(见第13.7.5.19节“SHOW FUNTIO…...

C#基础上机练习题
21.计算500-800区间内素数的个数cn,并按所求素数的值从大到小的顺序排列,再计算其间隔加、减之和,即第1个素数-第2个素数第3个素数-第4个素数第5个素数……的值sum。请编写函数实现程序的要求,把结果cn和sum输出。 22.在三位整数…...

5.5 W5500 TCP服务端与客户端
文章目录 1、TCP介绍2、W5500简介2.1 关键函数socketlistensendgetSn_RX_RSRrecv自动心跳包检测getSn_SR 1、TCP介绍 TCP 服务端: 创建套接字[socket]:服务器首先创建一个套接字,这是网络通信的端点。绑定套接字[bind]:服务器将…...

一区北方苍鹰算法优化+创新改进Transformer!NGO-Transformer-LSTM多变量回归预测
一区北方苍鹰算法优化创新改进Transformer!NGO-Transformer-LSTM多变量回归预测 目录 一区北方苍鹰算法优化创新改进Transformer!NGO-Transformer-LSTM多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab NGO-Transformer-LST…...

深入理解 MyBatis 的缓存机制:一级缓存与二级缓存
MyBatis 是目前 Java 开发中常用的一种 ORM(对象关系映射)框架,它不仅简化了 SQL 语句的编写和管理,还提供了强大的缓存机制,用以提高数据库访问的性能。MyBatis 的缓存分为一级缓存和二级缓存,分别应用于不…...

移远通信推出全新5G RedCap模组RG255AA系列,以更高性价比加速5G轻量化大规模商用
11月20,全球领先的物联网整体解决方案供应商移远通信宣布,正式推出其全新5G RedCap模组RG255AA系列。该系列模组支持5G NR独立组网(SA)和LTE Cat 4双模通信,具有高性能高集成度、低功耗、小尺寸、高性价比等优势&#…...

架构-微服务-环境搭建
文章目录 前言一、案例准备1. 技术选型2. 模块设计3. 微服务调用 二、创建父工程三、创建基础模块四、创建用户微服务五、创建商品微服务六、创建订单微服务 前言 微服务环境搭建 使用的电商项目中的商品、订单、用户为案例进行讲解。 一、案例准备 1. 技术选型 maven&a…...

conda下载与pip下载的区别
一、conda下载与pip下载的区别 最重要是依赖关系: pip安装包时,尽管也对当前包的依赖做检查,但是并不保证当前环境的所有包的所有依赖关系都同时满足。 当某个环境所安装的包越来越多,产生冲突的可能性就越来越大。conda会检查当…...

MySQL获取数据库内所有表格数据总数
在 MySQL 中,要获取数据库内所有表格的数据总数,可以编写一个查询脚本来遍历每个表并计算其行数。你可以使用 INFORMATION_SCHEMA 数据库,它包含了关于数据库元数据的表格,如 TABLES 和 COLUMNS。 以下是一个示例脚本,…...
Matlab 深度学习工具箱 案例学习与测试————求二阶微分方程
clc clear% 定义输入变量 x linspace(0,2,10000);% 定义网络的层参数 inputSize 1; layers [featureInputLayer(inputSize,Normalization"none")fullyConnectedLayer(10)sigmoidLayerfullyConnectedLayer(1)sigmoidLayer]; % 创建网络 net dlnetwork(layers);% 训…...

django authentication 登录注册
文章目录 前言一、django配置二、后端实现1.新建app2.编写view3.配置路由 三、前端编写1、index.html2、register.html3、 login.html 总结 前言 之前,写了django制作简易登录系统,这次利用django内置的authentication功能实现注册、登录 提示ÿ…...
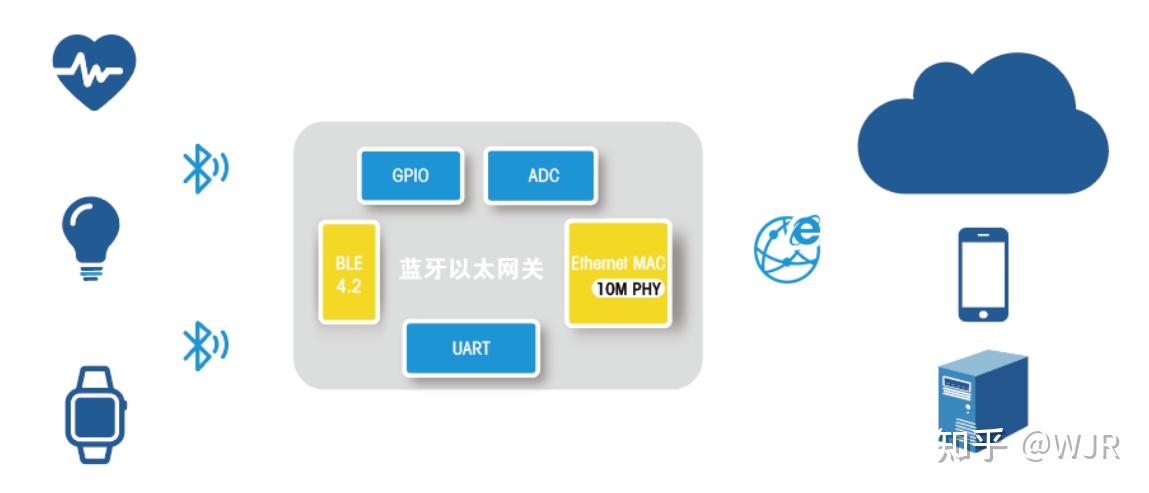
三种蓝牙架构实现方案
一、蓝牙架构方案 1、hostcontroller双芯片标准架构 手机里面包含很多SoC或者模块,每颗SoC或者模块都有自己独有的功能,比如手机应用跑在AP芯片上,显示屏,3G/4G通信,WiFi/蓝牙等都有自己专门的SoC或者模块࿰…...

AI系统可观测性:从数据漂移到模型性能的全面监控实践
1. 项目概述:为什么AI系统需要独立的可观测性体系?最近几年,我参与和主导了不下十个所谓的“AI驱动”或“智能”系统的构建与运维。从最初的兴奋到后来的头疼,一个深刻的体会是:传统的监控和日志体系,在AI系…...

大模型幻觉:为何AI会“一本正经地胡说八道”?
大模型的“幻觉”是指其生成看似合理却错误的回答。这主要源于训练数据中的错误信息、模型仅学习语言分布而非事实、以及激励机制倾向于猜测而非承认未知。减轻幻觉的方法包括引入RAG技术连接外部知识库,以及优化训练激励机制,奖励诚实地表达不确定性。 …...

360安全浏览器-很恶心,经常自己绑定安装,有没有什么方法可以阻止安装?
360安全浏览器-很恶心,经常自己绑定安装,有没有什么方法可以阻止安装? 可以阻止360安全浏览器的自动安装,主要通过关闭其推荐功能、彻底卸载关联组件、禁用后台服务及使用系统策略拦截来实现。 一、关闭360软件的推荐安装设置 若已安装360安全卫士或360极速浏览器,需先…...

Python Redis 缓存策略实战:提升应用性能的最佳实践
Python Redis 缓存策略实战:提升应用性能的最佳实践 引言 在后端开发中,缓存是提升系统性能的关键技术。作为一名从Rust转向Python的开发者,我深刻认识到缓存策略在高并发场景下的重要性。Redis作为一款高性能的内存数据库,已成为…...

从音频处理到IoT数据:用scipy.signal.resample_poly搞定实际项目中的采样率转换
从音频处理到IoT数据:用scipy.signal.resample_poly搞定实际项目中的采样率转换 采样率转换是数字信号处理中的常见需求,无论是音频处理、传感器数据分析还是通信系统仿真,都会遇到不同采样率设备间的数据交互问题。想象一下,当你…...

Windows Cleaner:彻底告别C盘爆红的免费开源解决方案
Windows Cleaner:彻底告别C盘爆红的免费开源解决方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 面对Windows系统使用过程中C盘空间不断告急的困扰…...

Windows安全组件深度解析与优化:2025专业版系统性能调优完整指南
Windows安全组件深度解析与优化:2025专业版系统性能调优完整指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_m…...
终极配置指南:5步打造专业级网络视频传输系统)
DistroAV(原OBS-NDI)终极配置指南:5步打造专业级网络视频传输系统
DistroAV(原OBS-NDI)终极配置指南:5步打造专业级网络视频传输系统 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 你是否曾为OBS Stud…...

为AI编码助手集成aislop-skill:实时代码质量检测与修复
1. 项目概述:为AI编码助手装上“质检员”如果你和我一样,日常重度依赖Cursor、Windsurf这类AI驱动的IDE,或者频繁使用Claude Code、Gemini CLI等代码生成工具,那你一定遇到过这样的场景:AI助手生成的代码,功…...

别再只盯着密钥了!深入ESP32 eFuse,看懂flash加密背后的硬件安全逻辑
别再只盯着密钥了!深入ESP32 eFuse,看懂flash加密背后的硬件安全逻辑 当你在ESP32项目中使用flash加密功能时,是否曾疑惑过:为什么简单地烧录几个eFuse位就能实现固件保护?那些看似神秘的DISABLE_DL_DECRYPT、FLASH_CR…...