Python 爬虫从入门到(不)入狱学习笔记
爬虫的流程:从入门到入狱
- 1 获取网页内容
- 1.1 发送 HTTP 请求
- 1.2 Python 的 Requests 库
- 1.2 实战:豆瓣电影 scrape_douban.py
- 2 解析网页内容
- 2.1 HTML 网页结构
- 2.2 Python 的 Beautiful Soup 库
- 3 存储或分析数据(略)
一般爬虫的基本流程:获取网页内容、解析网页内容、存储或分析数据。
1 获取网页内容
1.1 发送 HTTP 请求
网课链接
(1)定义
HTTP(超文本传输协议)请求是客户端(如网页浏览器)和服务器之间进行通信的一种方式。
(2)方法
- GET方法:获取数据
- POST方法:创建数据
(3)HTTP请求例子

(4)HTTP响应例子

1.2 Python 的 Requests 库
网课链接
(1)加载所需的包
conda instal python
pip install requests

(2) 引用和使用 Requests 库
import requestsresponse = requests.get("http://books.toscrape.com/") # 使用 GET 请求, 参数传入完整的包含协议名的 URL
print(response)
print(response.status_code) # HTTP 状态码# 如果等于 200, 则表示请求成功;# 如果等于 404, 则表示请求失败
状态码 4 开头表示 ”请求失败,客户端错误“
(3)根据状态码判断成不成功获取网页内容
http://books.toscrape.com/:专门给练习爬虫的网站
## 方法一
if response.status_code >= 200 and response.status_code < 400:print(response.text) # 获取响应体内容
elif response.status_code >= 400 and response.status_code < 500:print("请求失败,客户端错误")
elif response.status_code >= 500:print("请求失败,服务器错误")## 方法二(推荐)
if response.ok:print(response.text) # 获取响应体内容
else:print("请求失败")
(4)如果想指定某些信息进行更改,可传入 headers 参数
作用:把爬虫程序伪装成正常浏览器
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"}
response = requests.get("http://books.toscrape.com/", headers=head)
if response.ok:print(response.text) # 获取响应体内容
else:print("请求失败")
1.2 实战:豆瓣电影 scrape_douban.py
网课链接
(1)要爬取的网站:https://movie.douban.com/top250
import requestsresponse = requests.get("https://movie.douban.com/top250")
print(response)
print(response.status_code) # 直接查看返回的状态码
(2)通过定义请求头,把服务器伪装成浏览器
先去网站抄作业获取 User-Agent

headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.status_code)
print(response.text)
2 解析网页内容
2.1 HTML 网页结构
网课链接
(1)网页的三大技术要素
- HTML:定义网页的结构和信息
- CSS: 定义网页的样式
- JavaScript:定义用户和网页的交互逻辑
(2)最简单的 HTML
<!DOCTYPE HTML> # 告知浏览器,文件类型是 HTML
<html> # 起始标签,表示开始<body> # body 表示文档的主体内容<h1>这是一个标题</h1> # h1 表示最大字号的标题<p>这是一段文字这是一段文字这是一段文字</p> # p 表示文本段落</body>
</html> # 闭合标签,表示结束
网课链接
(3)HTML 的常用标签类型
- 标题标签

- 文本段落标签

- 换行标签

- 加粗标签

- 斜体标签

- 下划线

- 图片标签

- 链接标签

- 容器标签

- 有序列表标签

- 列表元素标签

- 无序列表标签

- 表格标签
<table border="1"> # table 为表格标签; border 为边框标签<thead> # 表示表格的头部,一般为表格第一行<tr> # table row, 定义表格行<td>表头1</td><td>表头2</td></tr></thead><tbody> # 表示表格的主体<tr><td>111</td> # table data, 表示单元格内的数据<td>222</td></tr><tr><td>333</td><td>444</td></tr></tbody>
</table>

- class 属性标签:定义元素类的名称

(4)HTML 常见标签练习:demo.py
<!DOCTYPE html> <!--声明文件类型--><html> <!--整个文档的根--><head> <!--文档的头部--><title>这是一个标题</title> <!--定义展示在浏览器选项卡上的标题--></head><body><div style="background-color:red;"> <!--style 是 CSS 的内容,可以不用管--><h1>我是一个一级标题</h1><h2>我是一个二级标题</h2><h6>我是一个六级标题</h6><h7>我是一个七级标题</h7> <!--其实七级标题不存在,所以不显示--><p>这是一个<b>文本段落</b>这是一个<i>文本段落</i>这是一个文本段落这是一个<u>文本段落</u>这是一个文本段落这是一个文本段落这是一个文本段落</p></div><p>这是一个<span style="background-color:aqua;">文本段落</span>这是一个<span style="background-color:plum;">文本段落</span>这是一个文本<br>段落这是一个文本段落这是一个文本段落</p><img src="https://t7.baidu.com/it/u=1415984692,3889465312&fm=193&f=GIF" with="500px"><a href="https://www.baidu.com" target="_blank">百度链接</a>" <!--添加超链接,href 参数是 URL,target 参数是打开方式--><ol> <!--定义有序列表--><li>我是第一项</li><li>我是第二项</li></ol><ul> <!--定义无序列表--><li>我是一项</li><li>我是另一项</li></ul><table border="'2" class="data-table"> <!--定义表格--><thead><tr><td>头部1</td><td>头部2</td><td>头部3</td></tr></thead><tbody><tr><td>111</td><td>222</td><td>333</td></tr><tr><td>444</td><td>555</td><td>666</td></tr><tr><td>777</td><td>888</td></tr></tbody></table></body></html>
2.2 Python 的 Beautiful Soup 库
网课链接
(1)下载 Beautiful Soup 库
pip install bs4
(2)导入 Beautiful Soup 并使用
from bs4 import BeautifulSoup
import requestscontent = requests.get("http://www.example.com/").text
soup = BeautifulSoup(content, "html.parser") # 第2个参数是解析器,默认是lxml
print(soup.p)
Beautiful Soup 可以解析 HTML 结构,让搜索和修改 HTML 结构变得更加容易

(3) 浏览器辅助检查标签
实例网站:http://books.toscrape.com/

(4)实例:导出所有价格
from bs4 import BeautifulSoup
import requestscontent = requests.get("http://books.toscrape.com/").text
soup = BeautifulSoup(content, "html.parser") # 第2个参数是解析器,默认是lxml
all_prices = soup.findAll("p", attrs={"class":"price_color"}) # 查找所有p标签,传入可选参数 attrs 来选择想要的内容
for price in all_prices:print(price.string[2:])
(5)实例:导出所有书名
all_titles = soup.findAll("h3")
for title in all_titles:all_links = title.findAll("a")for link in all_links:print(link.string)
(6)实例:导出豆瓣 top250 的所有标题
import requests
from bs4 import BeautifulSoupheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
}for start_num in range(0,250,25):response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers=headers)html = response.textsoup = BeautifulSoup(html, "html.parser") # html: 待解析的HTML文本# "html.parser": 解析器all_titles = soup.findAll("span",attrs={"class":"title"})for title in all_titles:title_string = title.stringif "/" not in title_string:print(title_string)
3 存储或分析数据(略)
相关文章:
Python 爬虫从入门到(不)入狱学习笔记
爬虫的流程:从入门到入狱 1 获取网页内容1.1 发送 HTTP 请求1.2 Python 的 Requests 库1.2 实战:豆瓣电影 scrape_douban.py 2 解析网页内容2.1 HTML 网页结构2.2 Python 的 Beautiful Soup 库 3 存储或分析数据(略) 一般爬虫的基…...
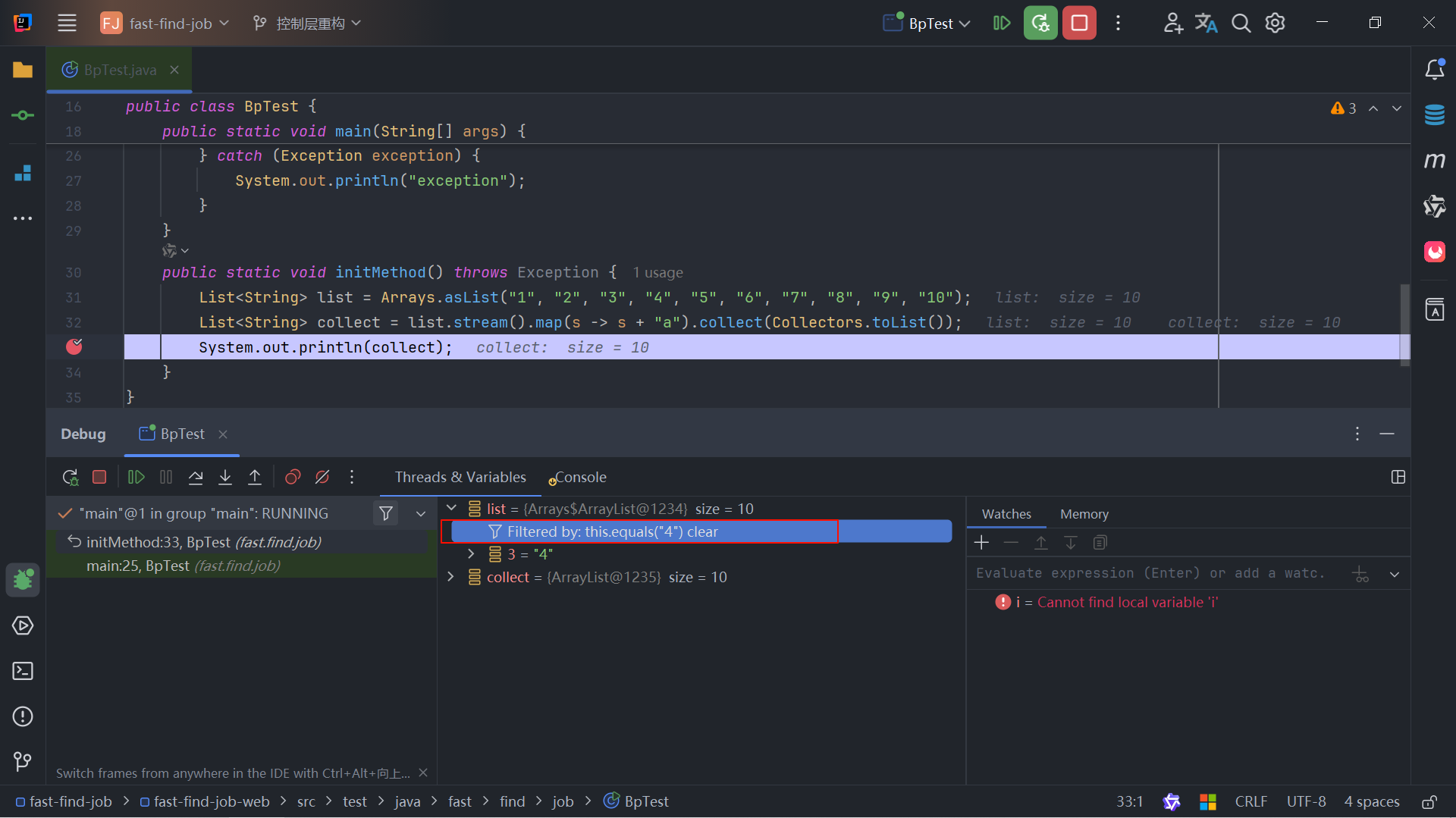
IDEA优雅debug
目录 引言一、断点分类🎄1.1 行断点1.2 方法断点1.3 属性断点1.4 异常断点1.5 条件断点1.6 源断点1.7 多线程断点1.8 Stream断点 二、调试动作✨三、Debug高级技巧🎉3.1 watch3.2 设置变量3.3 异常抛出3.4 监控JVM堆大小3.5 数组过滤和筛选 引言 使用ID…...

wp the_posts_pagination 与分类页面搭配使用
<ul> <?php while( have_posts() ) : the_post(); <li > <a href"<?php the_permalink(); ?>"> <?php xizhitbu_get_thumbnail(thumb-pro); ?> </a> <p > <a href&q…...

大数据-231 离线数仓 - DWS 层、ADS 层的创建 Hive 执行脚本
点一下关注吧!!!非常感谢!!持续更新!!! Java篇开始了! 目前开始更新 MyBatis,一起深入浅出! 目前已经更新到了: Hadoop࿰…...

【Python】分割秘籍!掌握split()方法,让你的字符串处理轻松无敌!
在Python开发中,字符串处理是最常见也是最基础的任务之一。而在众多字符串操作方法中,split()函数无疑是最为重要和常用的一个。无论你是Python新手,还是经验丰富的开发者,深入理解并熟练运用split()方法,都将大大提升…...

免费实用在线AI工具集合 - 加菲工具
免费在线工具-加菲工具 https://orcc.online/ 在线录屏 https://orcc.online/recorder 时间戳转换 https://orcc.online/timestamp Base64 编码解码 https://orcc.online/base64 URL 编码解码 https://orcc.online/url Hash(MD5/SHA1/SHA256…) 计算 https://orcc.online/h…...

正则表达式灾难:重新认识“KISS原则”的意义
RSS Feed 文章标题整理 微积分在生活中的应用与思维启发 捕鹿到瞬时速度的趣味探索 微积分是一扇通往更广阔世界的门,从生活中学习思维的工具。 数据库才是最强架构 你还在被“复杂架构”误导吗? 把业务逻辑写入数据库,重新定义简单与效率。…...
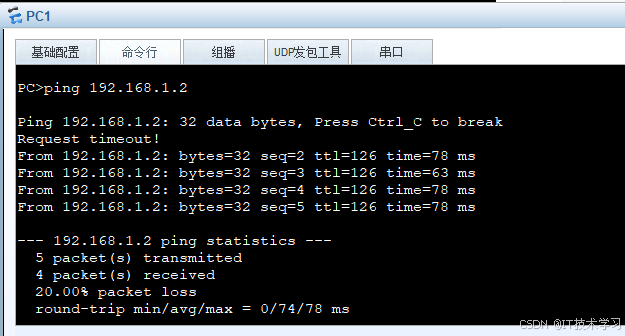
eNSP-缺省路由配置
缺省路由是一种特殊的静态路由,其目的地址为0.0.0.0,子网掩码为0.0.0.0。 1.拓扑图搭建 2.配置路由器 AR2 <Huawei>sys #进入系统视图 [Huawei]ip route-static 0.0.0.0 0.0.0.0 192.168.3.2 #设置缺省路由 [Huawei]q #返回上一层 <Huawe…...

solr 远程命令执行 (CVE-2019-17558)
漏洞描述 Apache Velocity是一个基于Java的模板引擎,它提供了一个模板语言去引用由Java代码定义的对象。Velocity是Apache基金会旗下的一个开源软件项目,旨在确保Web应用程序在表示层和业务逻辑层之间的隔离(即MVC设计模式)。 Apa…...

STM32端口模拟编码器输入
文章目录 前言一、正交编码器是什么?二、使用步骤2.1开启时钟2.2配置编码器引脚 TIM3 CH1(PA6) CH2 (PA7)上拉输入2.3.初始化编码器时基2.4 初始化编码器输入2.5 配置编码器接口2.6 开启定时器2.7获取编码器数据 三、参考程序四、测试结果4.1测试方法4.2串口输出结果…...

Centos 8, add repo
Centos repo前言 Centos 8更换在线阿里云创建一键更换repo 自动化脚本 华为Centos 源 , 阿里云Centos 源 华为epel 源 , 阿里云epel 源vim /centos8_repo.sh #!/bin/bash # -*- coding: utf-8 -*- # Author: make.han...
)
MYSQL- 查看存储过程调式信息语句(二十七)
13.7.5.27 SHOW PROCEDURE CODE 语句 SHOW PROCEDURE CODE proc_name此语句是MySQL扩展,仅适用于已构建有调试支持的服务器。它显示了命名存储过程的内部实现的表示。类似的语句SHOW FUNCTION CODE显示有关存储函数的信息(见第13.7.5.19节“SHOW FUNTIO…...

C#基础上机练习题
21.计算500-800区间内素数的个数cn,并按所求素数的值从大到小的顺序排列,再计算其间隔加、减之和,即第1个素数-第2个素数第3个素数-第4个素数第5个素数……的值sum。请编写函数实现程序的要求,把结果cn和sum输出。 22.在三位整数…...

5.5 W5500 TCP服务端与客户端
文章目录 1、TCP介绍2、W5500简介2.1 关键函数socketlistensendgetSn_RX_RSRrecv自动心跳包检测getSn_SR 1、TCP介绍 TCP 服务端: 创建套接字[socket]:服务器首先创建一个套接字,这是网络通信的端点。绑定套接字[bind]:服务器将…...

一区北方苍鹰算法优化+创新改进Transformer!NGO-Transformer-LSTM多变量回归预测
一区北方苍鹰算法优化创新改进Transformer!NGO-Transformer-LSTM多变量回归预测 目录 一区北方苍鹰算法优化创新改进Transformer!NGO-Transformer-LSTM多变量回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab NGO-Transformer-LST…...

深入理解 MyBatis 的缓存机制:一级缓存与二级缓存
MyBatis 是目前 Java 开发中常用的一种 ORM(对象关系映射)框架,它不仅简化了 SQL 语句的编写和管理,还提供了强大的缓存机制,用以提高数据库访问的性能。MyBatis 的缓存分为一级缓存和二级缓存,分别应用于不…...

移远通信推出全新5G RedCap模组RG255AA系列,以更高性价比加速5G轻量化大规模商用
11月20,全球领先的物联网整体解决方案供应商移远通信宣布,正式推出其全新5G RedCap模组RG255AA系列。该系列模组支持5G NR独立组网(SA)和LTE Cat 4双模通信,具有高性能高集成度、低功耗、小尺寸、高性价比等优势&#…...

架构-微服务-环境搭建
文章目录 前言一、案例准备1. 技术选型2. 模块设计3. 微服务调用 二、创建父工程三、创建基础模块四、创建用户微服务五、创建商品微服务六、创建订单微服务 前言 微服务环境搭建 使用的电商项目中的商品、订单、用户为案例进行讲解。 一、案例准备 1. 技术选型 maven&a…...

conda下载与pip下载的区别
一、conda下载与pip下载的区别 最重要是依赖关系: pip安装包时,尽管也对当前包的依赖做检查,但是并不保证当前环境的所有包的所有依赖关系都同时满足。 当某个环境所安装的包越来越多,产生冲突的可能性就越来越大。conda会检查当…...

MySQL获取数据库内所有表格数据总数
在 MySQL 中,要获取数据库内所有表格的数据总数,可以编写一个查询脚本来遍历每个表并计算其行数。你可以使用 INFORMATION_SCHEMA 数据库,它包含了关于数据库元数据的表格,如 TABLES 和 COLUMNS。 以下是一个示例脚本,…...

从‘不好用的CE’到‘好用的OD’:一次逆向实战中的工具选择与思路转换
逆向工程实战:从工具局限到思维跃迁的破解之道 当那个MFC程序弹出第一个窗口时,我习惯性地打开了Cheat Engine——这个在游戏修改领域堪称神器的工具。但十分钟后,面对毫无进展的扫描结果和不断跳出的错误提示,我突然意识到&#…...

Awesome-Robotics-3D:机器人3D视觉资源精选与高效利用指南
1. 项目概述:一个机器人学3D视觉的“藏宝图” 如果你正在机器人、自动驾驶或者三维感知领域摸爬滚打,并且时常为了找一个靠谱的开源实现、一篇奠基性的论文,或者一个高质量的数据集而翻遍GitHub、arXiv和各大实验室主页,那么你很可…...

《深入浅出通信原理》连载101-105
连载101:正弦信号的傅立叶变换连载102:直流信号的傅立叶变换连载103:复指数信号傅立叶变换的另外一种求法连载104:非周期信号的傅立叶变换连载105:傅立叶变换的对称性(一)...

从纸质手册到智能助手:技术会议应用如何重塑信息获取与时间管理
1. 从混乱到有序:技术会议体验的痛点与变革契机如果你参加过像国际电子器件会议(IEDM)或国际固态电路会议(ISSCC)这样的大型学术盛会,你肯定对那种“甜蜜的烦恼”深有体会。面对五六个并行进行的专题分会场…...

基于Twilio与ChatGPT构建AI电话助手:架构设计与实战指南
1. 项目概述:当ChatGPT遇上实体电话最近在折腾一个挺有意思的玩意儿,叫“ChatGPT-phone”。这名字听起来有点科幻,但说白了,它的核心目标就是让一个AI语音助手,比如ChatGPT,能够像真人一样接听和拨打电话。…...

AI驱动的网络安全:深度学习与LLM在威胁检测与教育中的应用
1. 项目概述:AI赋能的网络安全新范式在网络安全领域,我们正面临着一个日益严峻的悖论:一方面,攻击手段正变得前所未有的复杂和自动化;另一方面,74%的安全事件仍然源于人为因素。这种技术与人的双重挑战催生…...

MCP协议专用Linter:mcp-lint工具的设计、规则与集成实践
1. 项目概述:一个为MCP协议量身定制的代码质量守护者 最近在折腾MCP(Model Context Protocol)相关的开发,发现一个挺有意思的项目: robert19001-cmyk/mcp-lint 。光看名字,你大概能猜到它是个代码检查工具…...

苹果W1芯片如何通过低功耗无线技术重塑TWS耳机体验
1. 无线音频的功耗困局与苹果的破局思路 2016年9月,当苹果在发布会上首次亮出那对剪掉线缆的AirPods时,整个消费电子行业都在问同一个问题:它是怎么做到的?更具体地说,它如何解决了无线耳机领域最核心、也最令人头疼的…...

【波导仿真】基于矢量有限元法分析均匀波导附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。 🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室 👇 关注我领取海量matlab电子书和数学建模资料 &#x…...

35岁程序员的AI转型之路:年薪翻倍,收藏这份从零到架构师的详细指南
本文分享了作者作为35岁Java程序员的AI转型经历,从初期的焦虑与迷茫,到通过学习ChatGPT、Prompt Engineering和大模型技术,最终成功转型为AI架构师的故事。文章详细描述了学习路径、关键决策、遇到的坑以及成功因素,并给其他程序员…...