过滤条件包含 OR 谓词,如何进行查询优化——OceanBase SQL 优化实践
这篇博客涉及两个点,一个是 “OR Expansion 改写”,另一个是 “基于代价的改写”。
背景
在写SQL查询时,难以避免在过滤条件中使用 OR 谓词,但其往往会导致索引利用效率下降的问题 。本文将分享如何通过查询改写的2种方式进行优化。
使用 Or 谓词的示例如下:
CREATE TABLE `t1` (`c1` varchar(255) NOT NULL,`c2` varchar(255) NOT NULL,PRIMARY KEY (`c1`),UNIQUE KEY (`c2`));explain select * from t1 where c1 = '1' or c2 = '3';
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t1 |1 |3 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2]), filter([t1.c1 = '1' OR t1.c2 = '3']), rowset=16 |
| access([t1.c1], [t1.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.c1]), range(MIN ; MAX)always true |
+------------------------------------------------------------------------------------+
11 rows in set (0.087 sec)从上述计划中不难发现,当过滤条件为 where c1 = '1' or c2 = '3' 时,尽管 c1 列和 c2 列都分别建立了索引(或主键),但由于 OR 谓词的工作原理与 AND 谓词不同,导致在实际操作中无法通过索引来避免全表扫描的开销。
如果大家一时反应不过来为何无法利用索引,那这里就再多解释几句:因为在一个 table scan 最多只能选取一个索引进行使用,假如咱们选择使用建在 c1 上的主键索引,并完成了对 where c1 = '1' 的过滤,那么后面依然要在计算 where c2 = '3' 的时候进行一次全表扫描,如果选择使用建在 c2 上的索引也会出现类似的情况。所以无论怎么建索引,怎么用索引,这次全表扫总归是逃不掉的。
基础知识
OR 语句可以被改写成一条等价的带有 UNION ALL 的 SQL,例如上面的这条 SQL,就可以改写成:
explain SELECT *
FROM t1
WHERE t1.c1 = 1UNION ALLSELECT *
FROM t1
WHERE t1.c2 = 3 and lnnvl(t1.c1 = 1);其中的 lnnvl 函数,大家可以简单的理解成是一个类似于逻辑非的操作。这个改写一般被称为 OR Expansion(OR 展开),改写的好处就是,把不能利用索引的 OR 操作,改成了等价的且可以在 union all 两侧分别利用两个索引的操作。
优化思路
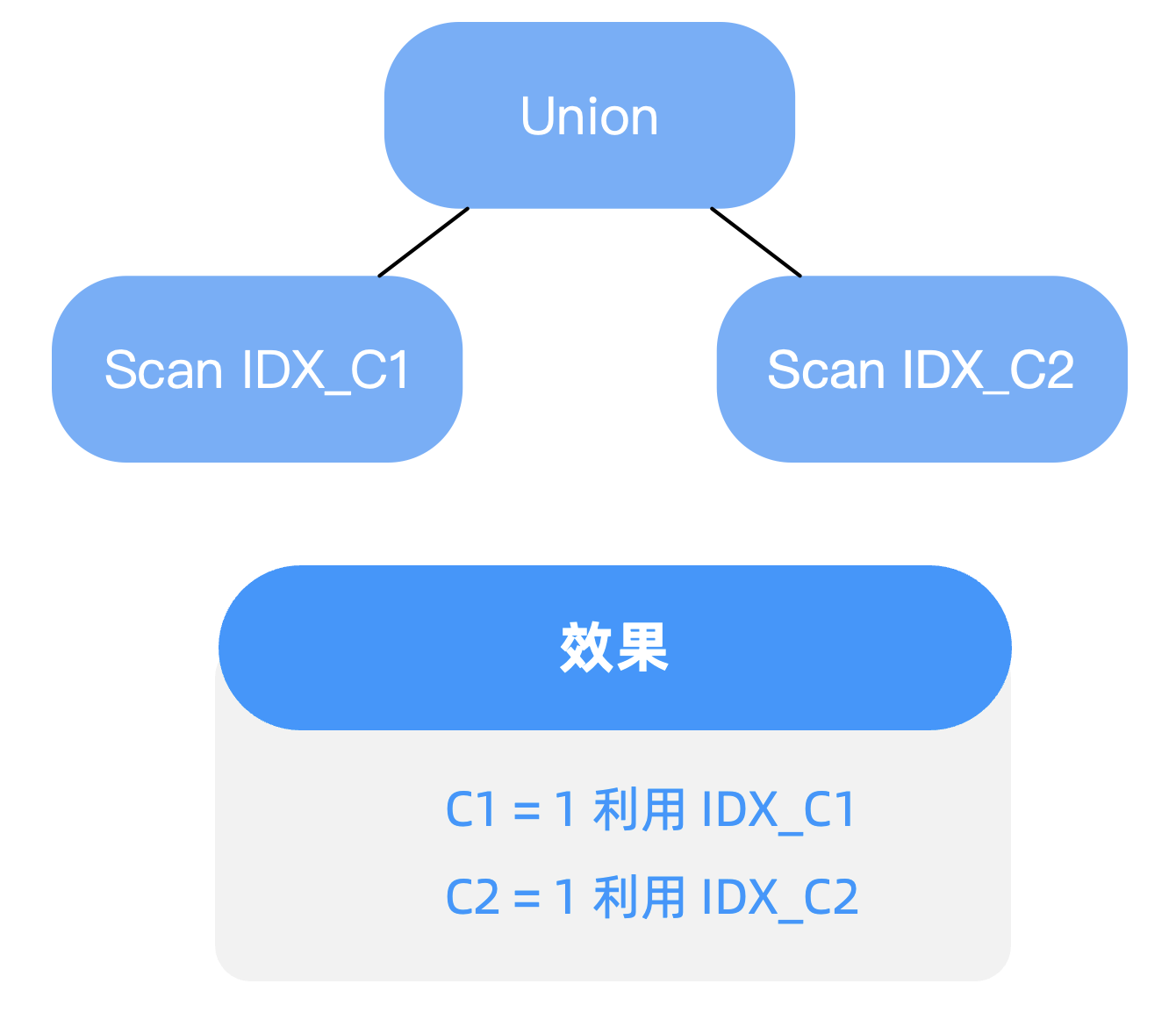
遇到这种希望利用 OR 两边的索引避免全表扫的场景时,OceanBase 支持通过 Hint /*+ use_concat */ 来强制优化器对原始 SQL 进行 OR Expansion 的改写。这样查询就会被拆分为两个部分,分别利用两个索引,在某些场景下可能可以提升查询性能。
explain select /*+ use_concat */ * from t1 where c1 = '1' or c2 = '3';
+-----------------------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------------------+
| ==================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ---------------------------------------------------- |
| |0 |UNION ALL | |1 |7 | |
| |1 |├─TABLE GET |t1 |1 |5 | |
| |2 |└─TABLE RANGE SCAN|t1(c2)|0 |3 | |
| ==================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([UNION([1])], [UNION([2])]), filter(nil), rowset=16 |
| 1 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 |
| access([t1.c1], [t1.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.c1]), range[1 ; 1], |
| range_cond([t1.c1 = '1']) |
| 2 - output([t1.c1], [t1.c2]), filter([lnnvl(cast(t1.c1 = '1', TINYINT(-1, 0)))]), rowset=16 |
| access([t1.c1], [t1.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.c2], [t1.shadow_pk_0]), range(3,MIN ; 3,MAX), |
| range_cond([t1.c2 = '3']) |
+-----------------------------------------------------------------------------------------------+
20 rows in set (0.008 sec)在上面的计划中,可以看到,使用 hint 进行改写后,union all 左边是 table get,说明走了主键,右边是 table range scan,走了 c2 列上的索引。
What's more ?
上面在介绍优化思路时,提到了一句 “在某些场景下可能可以提升查询性能”,原因是优化器的改写算法分为两类:
- 第一类叫基于规则的改写,这类改写总会有正面的效果,例如消除恒真、恒假条件。
- 第二类叫基于代价的改写,特点是某些场景下改写后能生成更好的执行计划,另一些场景下则不能。是否可以触发这类改写,优化器会根据实际的数据分布、是否有合适的索引等因素来进行判断。基于代价的算法在完成改写后需要 “询问” 优化器:“改写后的 SQL 是否能够生成执行代价更小的计划?”,如果代价的确降低了,这次改写才会被触发。
咱们上面提到的 OR Expansion,就属于第二类 “基于代价的改写”,因为 SQL 被一分为二了,所以只有当 union all 两边都有索引,并且索引的过滤性不错的情况下,才能够达到优化的目的。
Q1:
SELECT * FROM T1 WHERE C1 < 20000 OR C2 < 30 ;=>Q2:
SELECT /*SEL_1*/ * FROM T1 WHERE C1 < 20000 UNION ALL
SELECT /*SEL_2*/ * FROM T1 WHERE C2 < 30 AND LNNVL (C1 < 20000);针对上面这个 OR Expansion 的例子,简单解释下为什么有些改写需要基于代价才能触发:
- 当 T1 表上在 C1 列和 C2 列上都有索引时:Q1 无法利用这两个索引,它只能走主表扫描。
- Q2 中的
SEL_1可以利用 C1 上的索引,SEL_2可以利用 C2 上的索引。如果这两个过滤条件有强的过滤性,那么索引扫描可以大大减少读取数据的开销。此时,触发 OR Expansion 改写有利于生成更好的执行计划。 - 当 T1 表上没有任何索引时:Q1 和 Q2 都需要进行全表扫描。但是 Q2 被分拆为两个 SELECT 子句,它需要进行两次全表扫描。因此,改写后的执行代价会上升。在这种情况下,不应该触发 OR Expansion。
综上所述:在没有及时收集统计信息时(即优化器不能准备计算代价时),可以根据实际情况(两边是否都有索引,以及索引过滤性),通过 Hint /*+ use_concat */ 进行 OR Expansion 改写,达到充分利用索引的目的。当然,也可以根据实际情况,通过 Hint /* +no_expand */ 来禁用 OR Expansion 改写。
相关文章:
过滤条件包含 OR 谓词,如何进行查询优化——OceanBase SQL 优化实践
这篇博客涉及两个点,一个是 “OR Expansion 改写”,另一个是 “基于代价的改写”。 背景 在写SQL查询时,难以避免在过滤条件中使用 OR 谓词,但其往往会导致索引利用效率下降的问题 。本文将分享如何通过查询改写的2种方式进行优化…...

通过异步使用消息队列优化秒杀
通过异步使用消息队列优化秒杀 同步秒杀流程异步优化秒杀异步秒杀流程基于lua脚本保证Redis操作原子性代码实现阻塞队列的缺点 同步秒杀流程 public Result seckillVoucher(Long voucherId) throws InterruptedException {SeckillVoucher seckillVoucher iSeckillVoucherServi…...

AI产业告别“独奏”时代,“天翼云息壤杯”高校AI大赛奏响产学研“交响乐”
文 | 智能相对论 作者 | 陈泊丞 人工智能产业正在从“独奏”时代进入“大合奏”时代。 在早期的AI发展阶段,AI应用主要集中在少数几个领域,如语音识别、图像处理等。这些领域的研究和开发工作往往由少数几家公司或研究机构即可独立完成,犹…...

Hot100 - 字母异位词分组
Hot100 - 字母异位词分组 最佳思路:排序 时间复杂度: O(nmlogm),其中 n 为 strs 数组的长度,m 为每个字符串的长度。 代码: class Solution {public List<List<String>> groupAnagrams(String[] strs) …...

力扣hot100-->排序
排序 1. 56. 合并区间 中等 以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。 示例 1: 输…...

【VRChat 全身动捕】VIVE 手柄改 tracker 定位器教程,低成本光学动捕解决方案(持续更新中2024.11.26)
更新 0.0.1(2024/11/26): 1.解决了内建蓝牙无法识别、“steamVR 蓝牙不可用” 的解决方案 2.解决了 tracker 虽然建立了连接但是在 steamVR 界面上看不到的问题 3.解决了 VIVE 基站1.0 无法被蓝牙识别 && 无法被 steamVR 搜索到 &…...

【Nginx】核心概念与安装配置解释
文章目录 1. 概述2. 核心概念2.1.Http服务器2.2.反向代理2.3. 负载均衡 3. 安装与配置3.1.安装3.2.配置文件解释3.2.1.全局配置块3.2.2.HTTP 配置块3.2.3.Server 块3.2.4.Location 块3.2.5.upstream3.2.6. mine.type文件 3.3.多虚拟主机配置 4. 总结 1. 概述 Nginx是我们常用的…...

Qt界面篇:QMessageBox高级用法
1、演示效果 2、用法注意 2.1 设置图标 用于显示实际图标的pixmap取决于当前的GUI样式。也可以通过设置icon pixmap属性为图标设置自定义pixmap。 QMessageBox::Icon icon(...

【二叉树】【2.1遍历二叉树】【刷题笔记】【灵神题单】
关注二叉树的三个问题: 什么情况适合自顶向下?什么时候适合用自底向上?一般来说,DFS的递归边界是空节点,什么情况下要额外把叶子节点作为递归边界?在什么情况下,DFS需要有返回值?什…...

Mongo数据库 --- Mongo Pipeline
Mongo数据库 --- Mongo Pipeline 什么是Mongo PipelineMongo Pipeline常用的几个StageExplanation with example:MongoDB $matchMongoDB $projectMongoDB $groupMongoDB $unwindMongoDB $countMongoDB $addFields Some Query Examples在C#中使用Aggreagtion Pipeline**方法一: …...

Adobe Illustrator 2024 安装教程与下载分享
介绍一下 下载直接看文章末尾 Adobe Illustrator 是一款由Adobe Systems开发的矢量图形编辑软件。它广泛应用于创建和编辑矢量图形、插图、徽标、图标、排版和广告等领域。以下是Adobe Illustrator的一些主要特点和功能: 矢量绘图:Illustrator使用矢量…...

javax.xml.ws.soap.SOAPFaultException: ZONE_OFFSET
javax.xml.ws.soap.SOAPFaultException 表示 SOAP 调用过程中发生了错误,并且服务端返回了一个 SOAP Fault。 错误信息中提到的 ZONE_OFFSET 可能指的是时区偏移量。在日期和时间处理中,时区偏移量是指格林威治标准时间 (GMT) 的偏移量。如果服务期望特…...

常用的数据结构
队列(FIFO) 栈(LIFO) 链表 hash表 hash冲突处理 开放式寻址 线性探测 表示依次检查索引为 hash(key) + 1、hash(key) + 2 ... 的位置。i 是冲突后的探查步数。公式:hash(i) = (hash(key) + i) % TableSize二次探查 规则:冲突后探查的步长是平方递增的,例如,检查位置为 hash…...

javaweb-day01-html和css初识
html:超文本标记语言 CSS:层叠样式表 1.html实现新浪新闻页面 1.1 标题排版 效果图: 1.2 标题颜色样式 1.3 标签内颜色样式 1.4设置超链接 1.5 正文排版 1.6 页面布局–盒子 (1)盒子模型 (2)页面布局…...

C++11特性(详解)
目录 1.C11简介 2.列表初始化 3.声明 1.auto 2.decltype 3.nullptr 4.范围for循环 5.智能指针 6.STL的一些变化 7.右值引用和移动语义 1.左值引用和右值引用 2.左值引用和右值引用的比较 3.右值引用的使用场景和意义 4.右值引用引用左值及其一些更深入的使用场景分…...

基于Springboot的心灵治愈交流平台系统的设计与实现
基于Springboot的心灵治愈交流平台系统 介绍 基于Springboot的心灵治愈交流平台系统,后端框架使用Springboot和mybatis,前端框架使用Vuehrml,数据库使用mysql,使用B/S架构实现前台用户系统和后台管理员系统,和不同级别…...

初识java(2)
大家好,今天我们来讲讲java中的数据类型。 java跟我们的c语言的数据类型有一些差别,那么接下来我们就来看看。 一.字面常量,其中:199,3.14,‘a’,true都是常量将其称为字面常量。(…...

AIGC--AIGC与人机协作:新的创作模式
AIGC与人机协作:新的创作模式 引言 人工智能生成内容(AIGC)正在以惊人的速度渗透到创作的各个领域。从生成文本、音乐、到图像和视频,AIGC使得创作过程变得更加快捷和高效。然而,AIGC并非完全取代了人类的创作角色&am…...

Wonder3D本地部署到算家云搭建详细教程
Wonder3D简介 Wonder3D仅需2至3分钟即可从单视图图像中重建出高度详细的纹理网格。Wonder3D首先通过跨域扩散模型生成一致的多视图法线图与相应的彩色图像,然后利用一种新颖的法线融合方法实现快速且高质量的重建。 本文详细介绍了在算家云搭建Wonder3D的流程以及…...
】之状态模式(State Pattern))
【设计模式】【行为型模式(Behavioral Patterns)】之状态模式(State Pattern)
1. 设计模式原理说明 状态模式(State Pattern) 是一种行为设计模式,它允许对象在其内部状态发生变化时改变其行为。这个模式的核心思想是使用不同的类来表示不同的状态,每个状态类都封装了与该状态相关的特定行为。当对象的状态发…...

基于大语言模型的自动化数据标注:Autolabel实战指南
1. 项目概述:用大模型给数据打标签,这事儿到底靠不靠谱?如果你做过机器学习项目,尤其是监督学习,那你肯定对“数据标注”这四个字又爱又恨。爱的是,没有标注好的数据,模型就是无米之炊ÿ…...

如何使用pretty-ts-errors:TypeScript错误追踪与性能优化终极指南
如何使用pretty-ts-errors:TypeScript错误追踪与性能优化终极指南 【免费下载链接】pretty-ts-errors 🔵 Make TypeScript errors prettier and human-readable in VSCode 🎀 项目地址: https://gitcode.com/gh_mirrors/pr/pretty-ts-error…...

一人一书一时代:《凰标》是海棠山铁哥的东方文明宣言@凤凰标志
一人执笔,一书立世,一作定时代。 ——《凰标》题记一、破题:当网文只剩“爽点”,谁来承载文明?行业通病《凰标》回应娱乐至死以笔墨思考时代碎片叙事构建完整文明体系功利写作以文载道,以书传文明 二、个人…...

使用DSP280049的CLB做LLC硬件同步整流
一、根据epwm1a配置1pwm2a。一)搭建自己的第一部分clb结构如下:1.配置输入配置clb输入,配置输入选择epwm1a的zero与compA。input0是上升沿,input1是下降沿。2.配置计数器配置计数器,计数器重新计数配置成pwm1a上升沿。…...

ANSI转义序列封装:cursor-reset库实现终端光标精准控制
1. 项目概述与核心价值 最近在折腾一些自动化工具链,发现一个挺有意思的小项目,叫 zhitrend/cursor-reset 。乍一看名字,你可能会觉得这只是一个重置光标位置的小工具,但实际用下来,我发现它解决的痛点非常精准&…...
)
别再只装软件了!TIA Portal Openness安装后必做的用户组配置(Win10避坑指南)
别再只装软件了!TIA Portal Openness安装后必做的用户组配置(Win10避坑指南) 当你兴冲冲地安装完TIA Portal和Openness组件,准备大展拳脚时,突然弹出一个"CAx操作无法启动"的错误提示——这种挫败感…...

可视化监控大盘构建:Grafana搭配Prometheus的艺术
在软件测试领域,我们早已不满足于“功能正确”这一单一维度。性能表现、资源消耗、服务稳定性、异常预警……这些非功能质量属性正逐渐成为衡量系统成熟度的关键标尺。而要将这些隐性的、动态的指标转化为可感知、可决策的信息,一套高效、灵活的可视化监…...

PyTorch模型参数管理:从torch.nn.Parameter到高效训练实践
1. 理解torch.nn.Parameter的本质 第一次接触PyTorch的torch.nn.Parameter时,我也曾困惑它和普通Tensor的区别。直到在实际项目中踩了几个坑,才真正明白它的价值。让我们从一个简单的例子开始: import torch import torch.nn as nn# 普通Te…...

隐写术:把秘密藏在你眼皮底下
你有没有想过,秘密不一定非要“加密”,还可以“藏起来”?这就是隐写术的思想——让别人根本不知道这里藏了信息。早在公元前5世纪,一位希腊人为了把情报传回祖国,把文字写在刮去蜡的木板上,再用新蜡覆盖。收…...

DICOM文件里除了图像,还藏了哪些信息?一份给开发者的隐私与元数据解析指南
DICOM文件里除了图像,还藏了哪些信息?一份给开发者的隐私与元数据解析指南 医疗影像数据是AI模型训练和医疗信息系统开发的重要基础,但许多开发者往往只关注图像像素本身,忽略了DICOM文件中蕴含的丰富元数据。这些元数据不仅包含关…...