【自动化Selenium】Python 网页自动化测试脚本(上)
目录
1、Selenium介绍
2、Selenium环境安装
3、创建浏览器、设置、打开
4、打开网页、关闭网页、浏览器
5、浏览器最大化、最小化
6、浏览器的打开位置、尺寸
7、浏览器截图、网页刷新
8、元素定位
9、元素交互操作
10、元素定位
(1)ID定位
(2)NAME定位
(3)CLASS_NAME定位
(4)TAG_NAME定位
(5)LINK_TEXT定位
(6)PARTIAL_LINK_TEXT定位
(7)CSS_SELECTOR定位
(8)XPATH定位
1、Selenium介绍
(1)自动化:自动化是指使用技术手段模拟人工。执行重复性任务,准确率100%,高于人工。
(2)自动化应用场景:自动化测试;自动化运维;自动化办公;自动化游戏
(3)Selenium:是web自动化中的知名开源库,通过浏览器驱动控制浏览器,通过元素定位模拟人工交换;支持多种浏览器;跨平台、兼容性高;以实现web自动化(无焦点状态依然执行)
2、Selenium环境安装
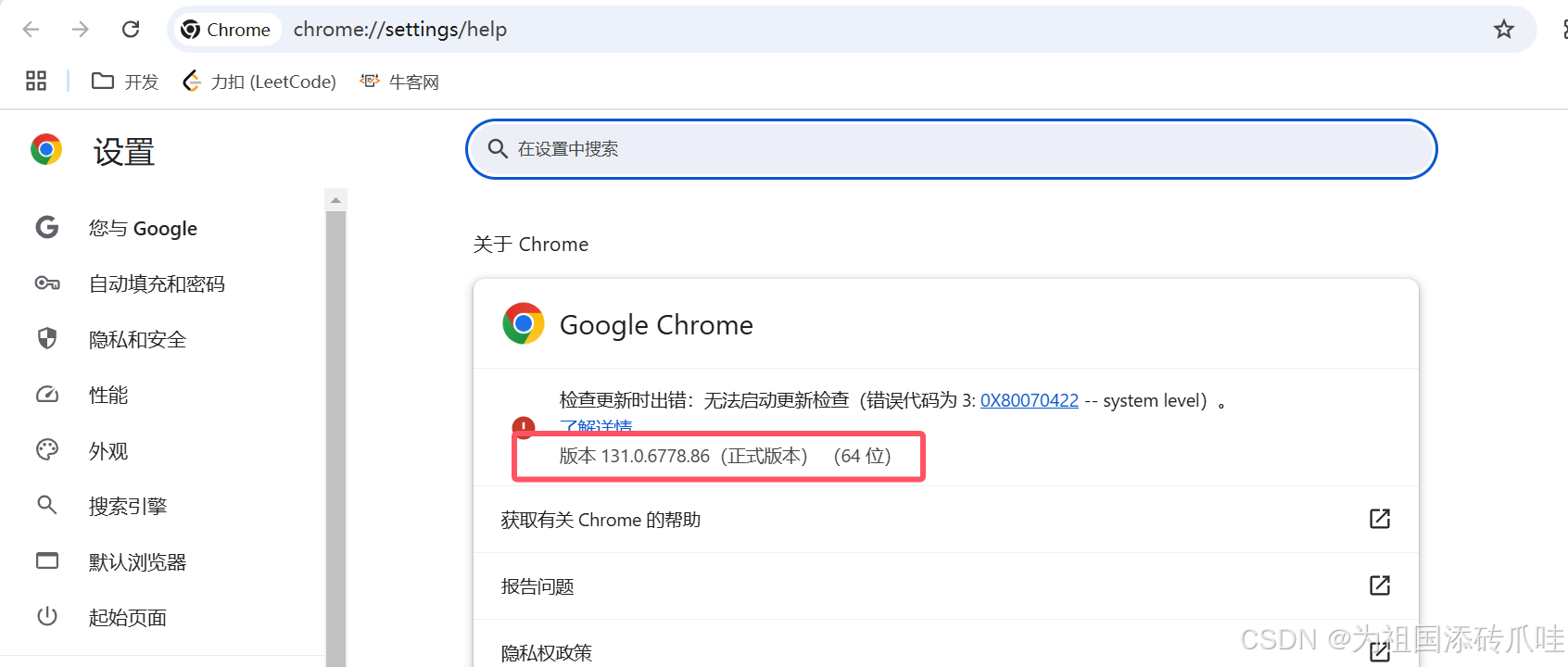
(1)浏览器的安装
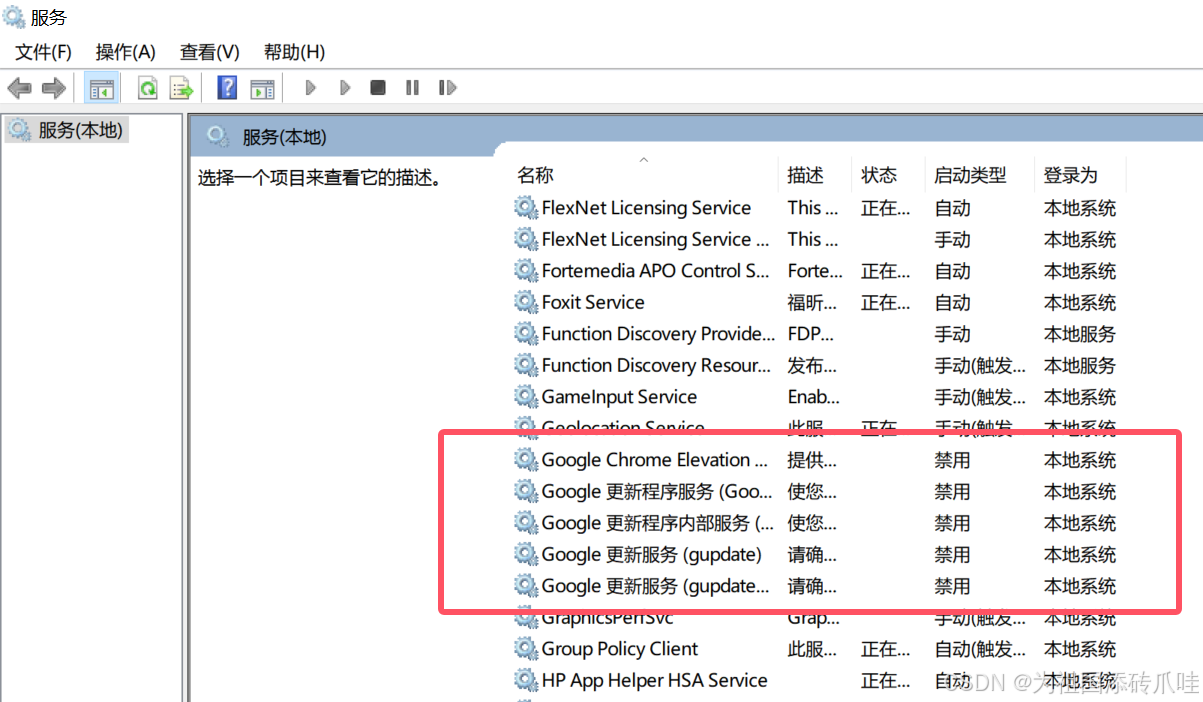
安装好了看版本右上角三个点->[帮助]->[关于Google Chrome ],然后关闭Chrome浏览器自动更新服务[开始搜索‘服务’,关于Chrome的都可以禁用]!!!
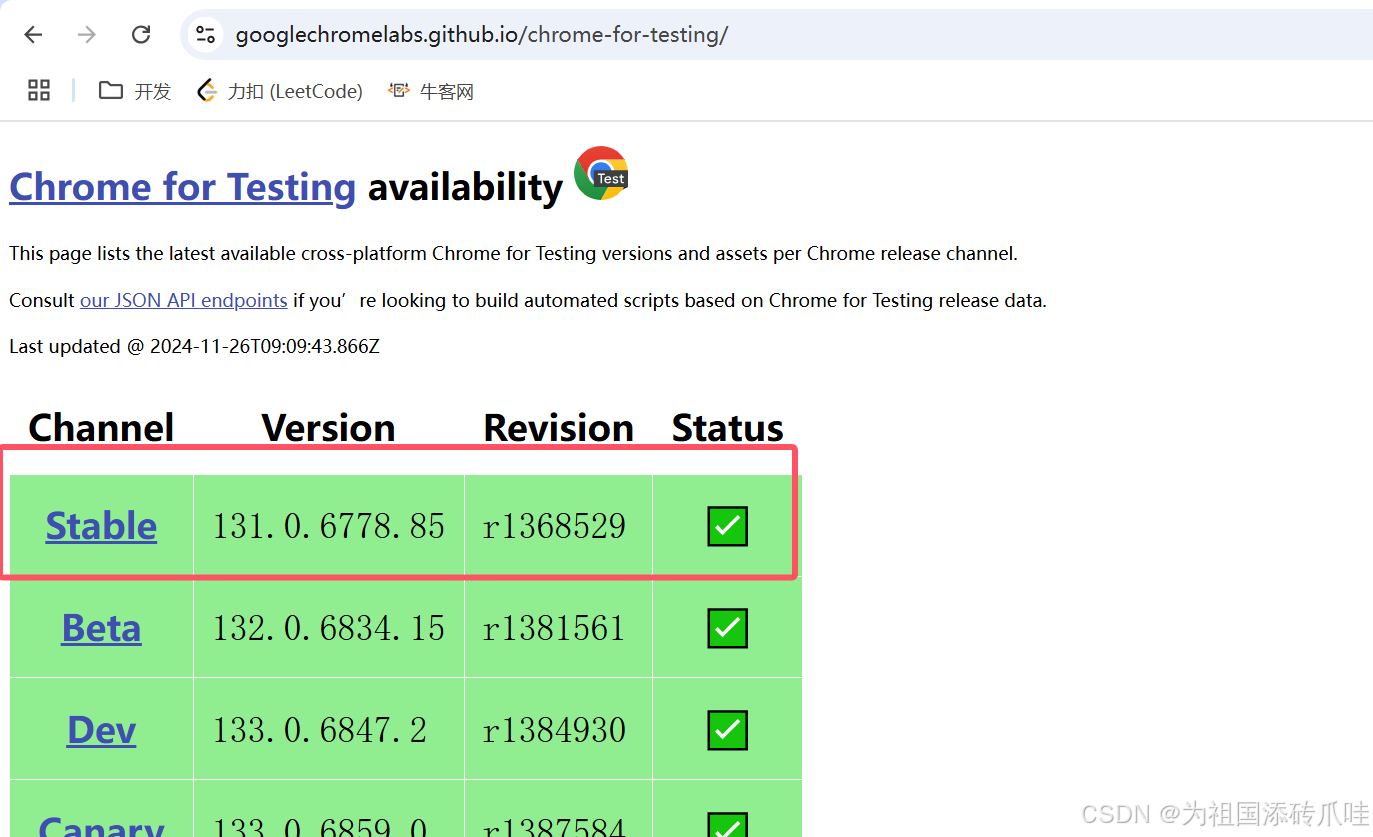
(2)浏览器驱动的安装
Chrome for Testing availability
保证浏览器与驱动大版本一致
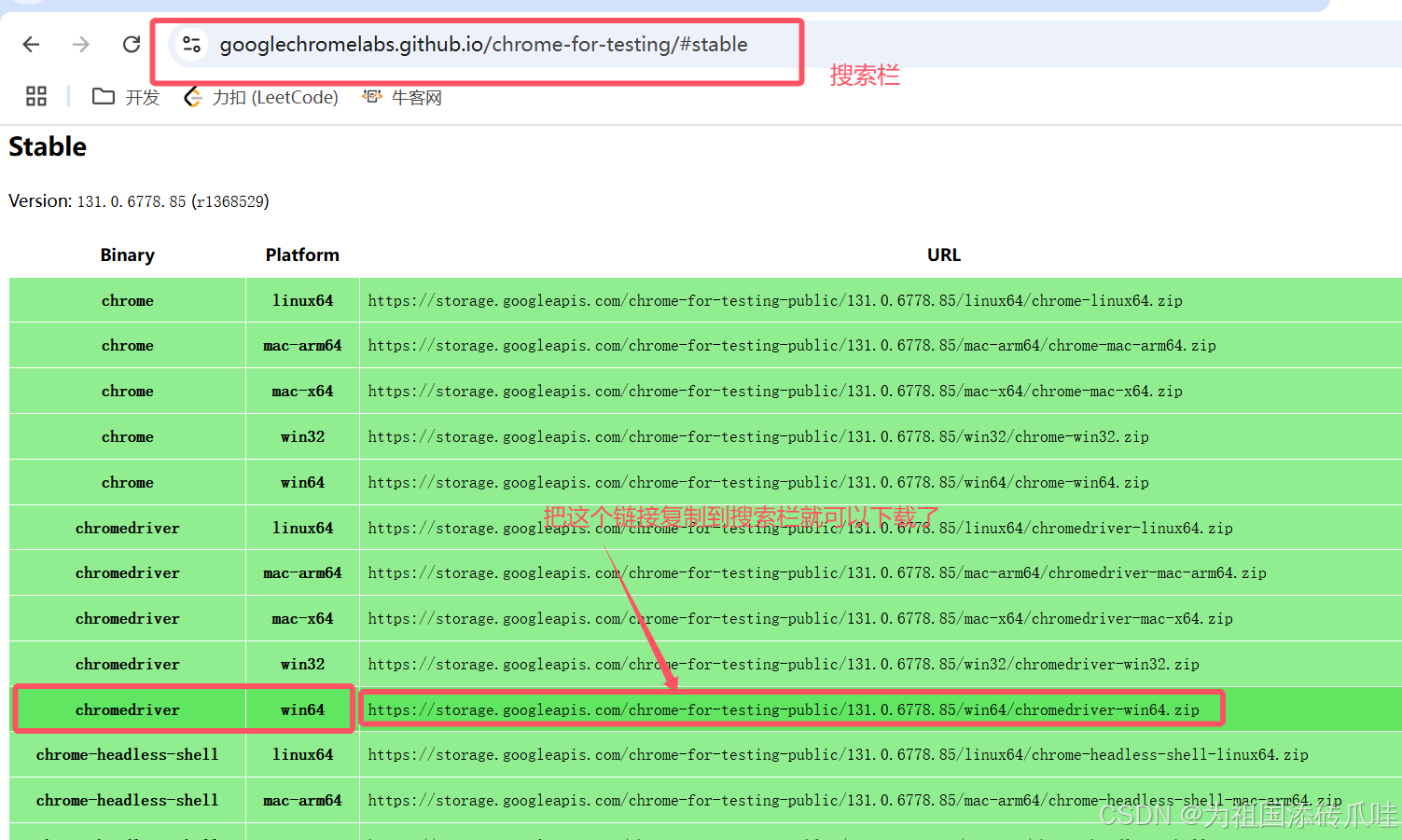
下载后就可以拖到工程项目中了
3、创建浏览器、设置、打开
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动#创建设置浏览器对象
q1=Options()#禁用沙盒模式
q1.add_argument('--no-sandbox')#保持浏览器打开状态(默认是代码执行完毕后自动关闭)
q1.add_experimental_option('detach',True)#创建并启动浏览器
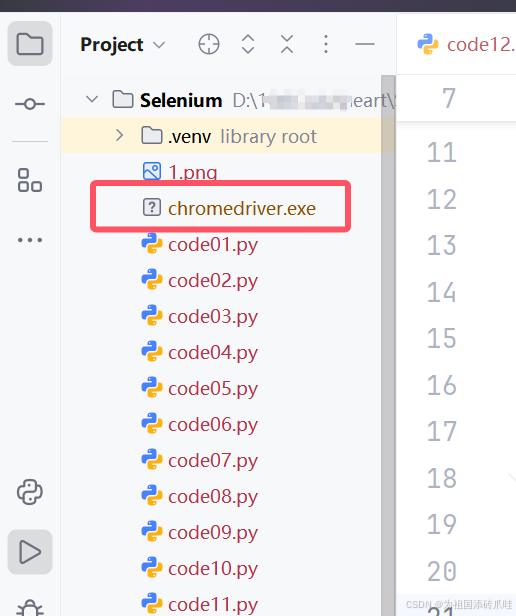
a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)点击运行就会打开Chrome浏览器
注意:沙盒模式在有些电脑必须设置的,因为存在某些冲突,所以必须设置,但是大多数电脑时可以不用添加的!
4、打开网页、关闭网页、浏览器
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(3)
#关闭当前标签页[只会关闭一个标签页;当只有一个标签页时,就相当于关闭浏览器]
a1.close()
time.sleep(3)
#退出浏览器
a1.quit()
页面的渲染是需要花费时间的,所以大家酌情添加time.sleep(second)
5、浏览器最大化、最小化
from os import times_resultfrom selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)
#浏览器的最大化
a1.maximize_window()
time.sleep(2)
#浏览器的最小化
a1.minimize_window()
6、浏览器的打开位置、尺寸
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)
#浏览器的打开位置
a1.set_window_position(0,0)
#浏览器打开尺寸
a1.set_window_size(600,600)7、浏览器截图、网页刷新
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)
#浏览器截图
a1.get_screenshot_as_file('1.png')
time.sleep(2)
#刷新当前网页
a1.refresh()8、元素定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)
#定位一个元素[找到的话返回结果,找不到的话就会返回空列表]
a2=a1.find_element(By.ID,'kw')
print(a2)#定位多个元素[找到的话返回列表,找不到的话直接报错]
a3=a1.find_elements(By.ID,'kw')
print(a3)9、元素交互操作
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)
a2=a1.find_element(By.ID,'kw');
#元素输入
a2.send_keys('自动化测试')
time.sleep(2)
#元素清空
a2.clear()
time.sleep(2)
#元素输入
a2.send_keys('测试')
#元素点击
a1.find_element(By.ID, 'su').click()10、元素定位
(1)ID定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——ID
#1、一般通过ID定位元素使比较准确的
#2、并不是所有的网页或者元素都有ID值
a1.find_element(By.ID,'kw').send_keys('自动化测试')(2)NAME定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——NAME
#1、一般通过name定位元素是比较准确的
#2、并不是所有的网页或者元素都有name值
a1.find_element(By.NAME,'wd').send_keys('自动化测试')(3)CLASS_NAME定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——CLASS_NAME
#1、class值不能有空格,否则报错
#2、class值会有重复的,所以需要切片处理
#3、class值有的网站是随机的,这时候就不得不用别的定位方式哦
a1.find_elements(By.CLASS_NAME,'c-font-normal')[1].click()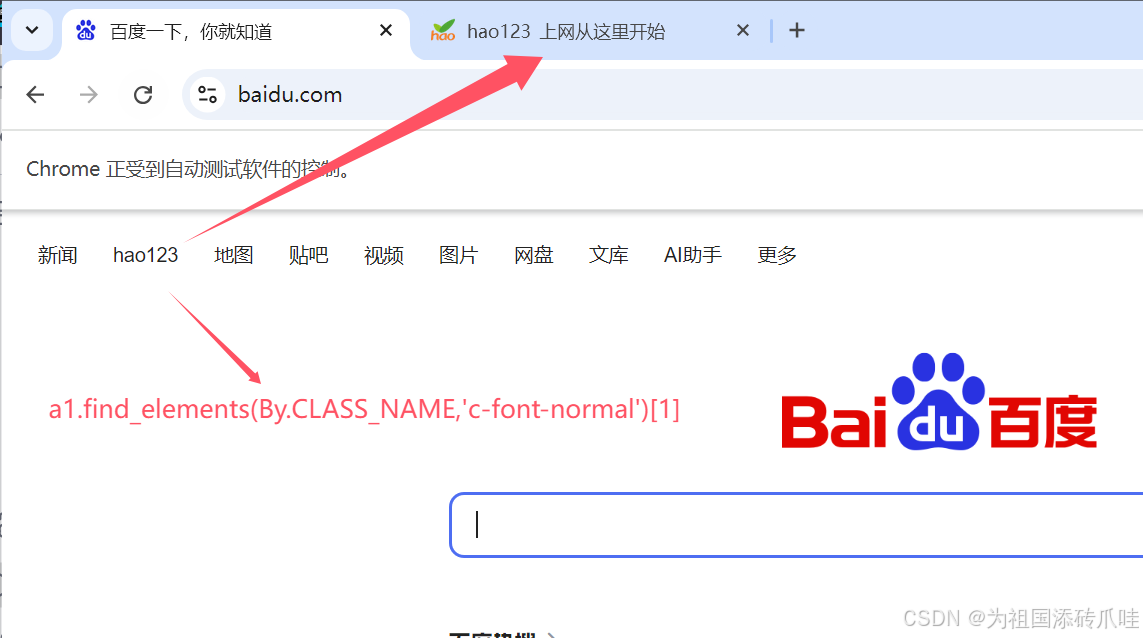
(4)TAG_NAME定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
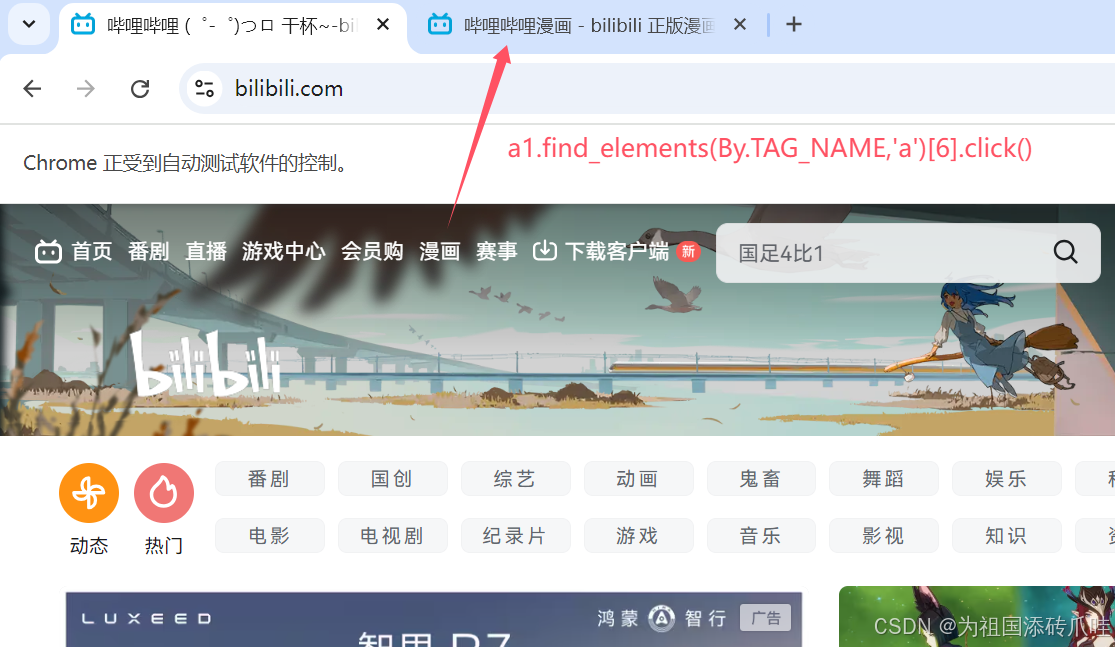
a1.get('http:/bilibili.com/')
time.sleep(2)#元素定位——TAG_NAME
#找出<开头便签名字>
a1.find_elements(By.TAG_NAME,'a')[6].click()
(5)LINK_TEXT定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——LINK_TEXT
#通过精准链接文本找到标签a的元素[精准文本]
#有重复的文本,需要切片
a1.find_element(By.LINK_TEXT,'新闻').click()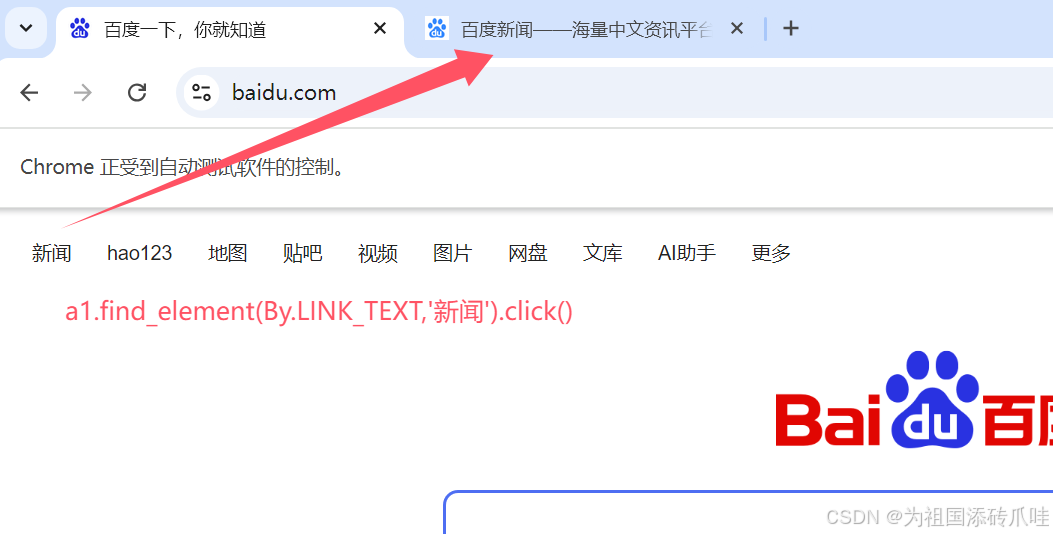
(6)PARTIAL_LINK_TEXT定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/bilibili.com/')
time.sleep(2)#元素定位——PARTIAL_LINK_TEXT
#通过模糊链接文本找到标签a的元素[模糊文本]
#有重复的文本,需要切片
a1.find_element(By.PARTIAL_LINK_TEXT,'音').click()(7)CSS_SELECTOR定位

from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——CSS_SELECTOR
#1、通过id定位——#id
#2、通过class值定位——.class
#3、通过标签头定位——标签头
#4、通过任意类型定位:"[类型='精准值']"
#5、通过任意类型定位:"[类型*='模糊值']"
#6、通过任意类型定位:"[类型^='开头值']"
#7、通过任意类型定位:"[类型$'结尾值']"
a1.find_element(By.CSS_SELECTOR,'#kw').send_keys('hello')(8)XPATH定位
Copy XPath:通过属性+路径定位,属性如果是随机的就定位不到
Copy full XPath:完整路径(缺点是定位值比较长,优点是基本100%正确)

from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——XPath
a1.find_element(By.XPATH,'//*[@id="kw"]').send_keys('hello')
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——XPath
a1.find_element(By.XPATH,'/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input').send_keys('hello')相关文章:
【自动化Selenium】Python 网页自动化测试脚本(上)
目录 1、Selenium介绍 2、Selenium环境安装 3、创建浏览器、设置、打开 4、打开网页、关闭网页、浏览器 5、浏览器最大化、最小化 6、浏览器的打开位置、尺寸 7、浏览器截图、网页刷新 8、元素定位 9、元素交互操作 10、元素定位 (1)ID定位 &…...

什么是MyBatis?
MyBatis简介 MyBatis是一款优秀的持久层框架,用于简化Java应用程序对数据库的操作。它曾是Apache的一个开源项目,名为iBatis,2010年迁移到Google Code并改名为MyBatis,2013年11月又迁移到了GitHub。 一、MyBatis的作用 在JavaE…...

TortoiseGit 将本地已有仓库推送到远程
TortoiseGit 将本地已有仓库推送到远程 一、创建线上仓库二、创建本地仓库三、提交内容到本地仓库四、添加远程仓库地址补充 一、创建线上仓库 在gitlab管理面页面按这前讲过的步骤创建一个空仓库。(通常我们把服务器上这个仓库叫远程仓库,把我们自己电…...
腾讯云OCR车牌识别实践:从图片上传到车牌识别
在当今智能化和自动化的浪潮中,车牌识别(LPR)技术已经广泛应用于交通管理、智能停车、自动收费等多个场景。腾讯云OCR车牌识别服务凭借其高效、精准的识别能力,为开发者提供了强大的技术支持。本文将介绍如何利用腾讯云OCR车牌识别…...

TailwindCss 总结
目录 一、简介 二、盒子模型相关 三、将样式类写到一个类里面apply 四、一款TailWind CSS的UI库 一、简介 官方文档:Width - TailwindCSS中文文档 | TailwindCSS中文网 Tailwind CSS 的工作原理是扫描所有 HTML 文件、JavaScript 组件以及任何 模板中的 CSS 类…...

Java与C#
Java和C#(C Sharp)是两种流行的面向对象编程语言,它们在很多方面非常相似,因为它们都受到了类似的编程范式和语言设计理念的影响。然而,它们之间也存在一些重要的区别。 平台依赖性: Java:Java是…...

leetcode:222完全二叉树的节点个数
给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。 完全二叉树 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最…...

[STM32]从零开始的STM32 FreeRTOS移植教程
一、前言 如果能看到这个教程的话,说明大家已经学习嵌入式有一段时间了。还记得嵌入式在大多数时候指的是什么吗?是的,我们所说的学习嵌入式大部分时候都是在学习嵌入式操作系统。从简单的一些任务状态机再到复杂一些的RTOS,再到最…...

java——Tomcat连接池配置NIO、BIO、APR
Tomcat连接池的配置涉及不同的IO模型,包括NIO(Non-blocking IO,非阻塞IO)、APR(Apache Portable Runtime,Apache可移植运行库)和BIO(Blocking IO,阻塞IO)。以…...

跨域相关的一些问题 ✅
当网页从一个源(https://baidu.com)请求另一个源(如 https://taobao/api)的资源时,就发生了跨域。由于安全原因(防止恶意网站通过脚本访问用户在其他网站上的数据),浏览器对跨域请求…...

RPC学习
一、什么是 RPC RPC(Remote Procedure Call),即远程过程调用,是一种计算机通信协议,它允许运行在一台计算机上的程序调用另一台计算机上的子程序或函数,就好像调用本地程序中的函数一样,无需程序…...
)
coe文件转mif(c语言)
1 mif文件格式 DEPTH=1024; --The size of data in bits WIDTH=16; --The size of memory in words ADDRESS_RADIX = DEC; --The radix for address values DATA_RADIX = UNS...

【leetcode】动态规划
31. 873. 最长的斐波那契子序列的长度 题目: 如果序列 X_1, X_2, ..., X_n 满足下列条件,就说它是 斐波那契式 的: n > 3对于所有 i 2 < n,都有 X_i X_{i1} X_{i2} 给定一个严格递增的正整数数组形成序列 arr ࿰…...
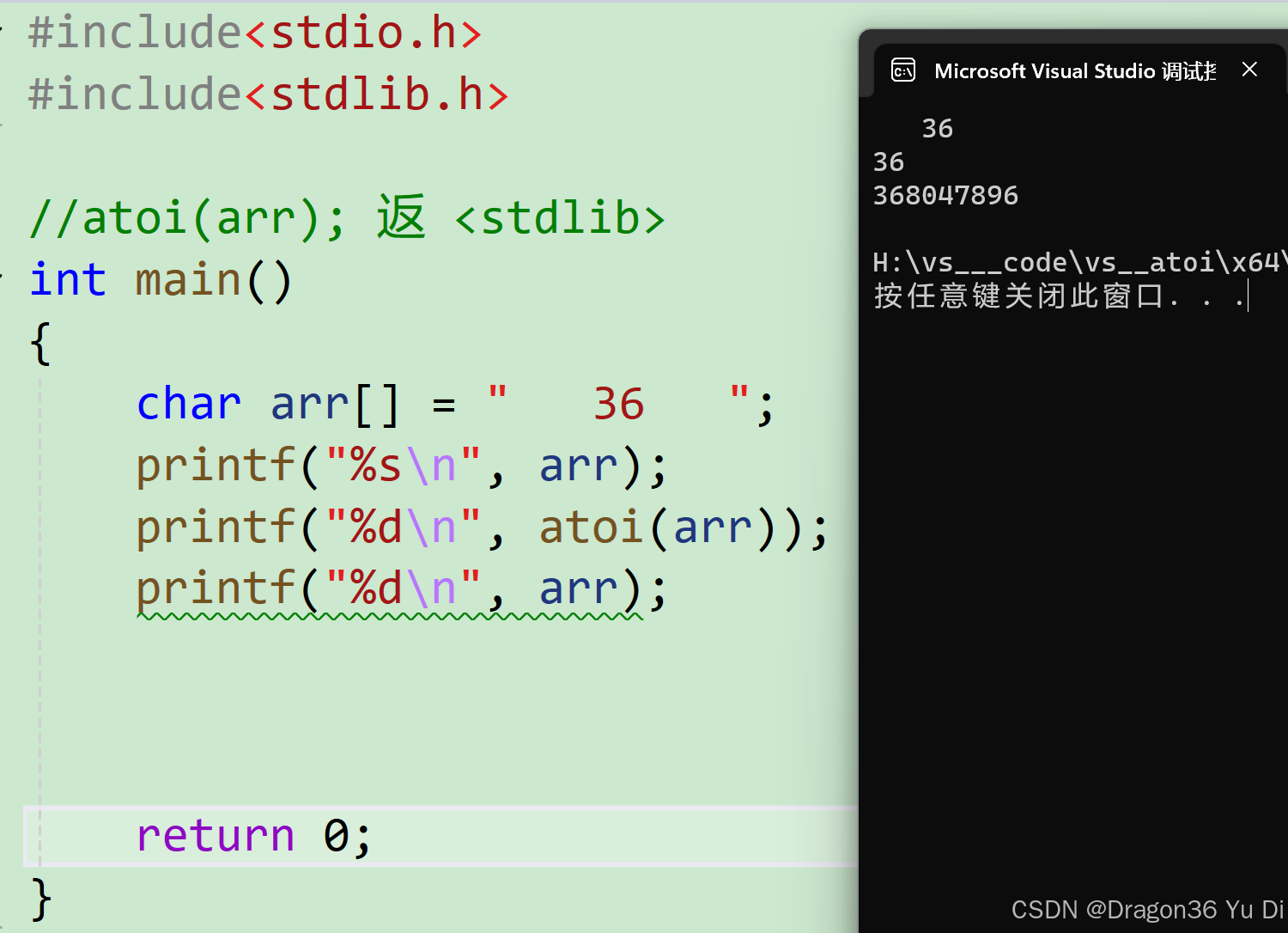
介绍一下atoi(arr);(c基础)
hi , I am 36 适合对象c语言初学者 atoi(arr);是返回整数(int型),整数是arr数组中字符中数字 格式 #include<stdio.h> atoi(arr); 返回值arr数组中的数字 未改变arr数组 #include<stdlib.h>//atoi(arr); 返 <stdlib> int main(…...

docker入门学习笔记
docker的定义 docker是一个用于构建、运行、传送 应用程序的平台。 为什么要使用docker ? 在开发测试库环境中测试成功后,打包成集装箱,到生产环境也是能够成功的。而传统的安装方式不仅繁琐,并且在测试环境安装后,到…...

使用Python和Pybind11调用C++程序(CMake编译)
目录 一、前言二、安装 pybind11三、编写C示例代码四、结合Pybind11和CMake编译C工程五、Python调用动态库六、参考 一、前言 跨语言调用能对不同计算机语言进行互补,本博客主要介绍如何实现Python调用C语言编写的函数。 实验环境: Linux gnuPython3.10…...
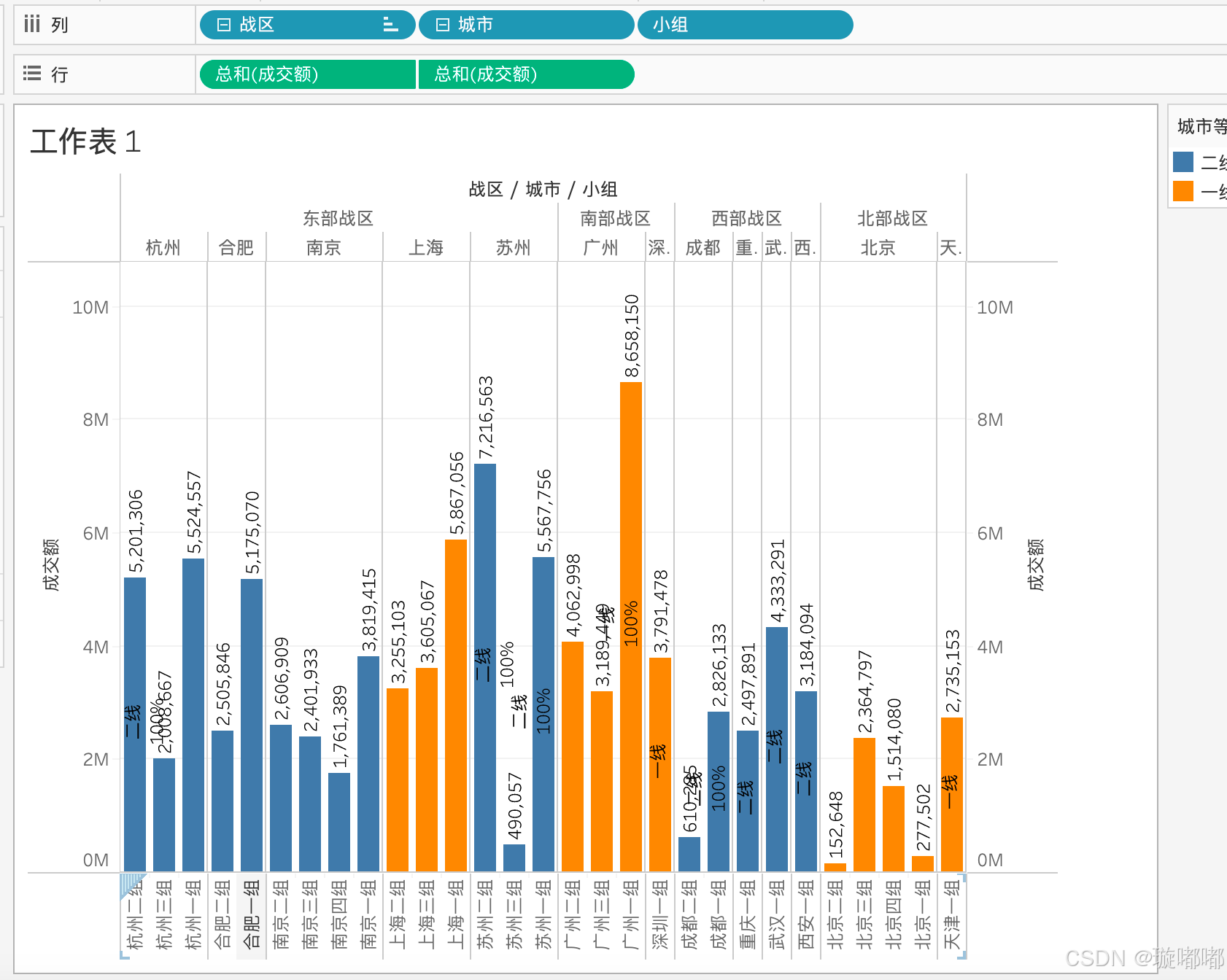
tableau-制作30个图表
制作条形图 步骤: 1、横轴是数值,对应了某一个度量值,纵轴是一个标签 战区的成交额,条形图横轴是战区,纵轴是成交额 下钻条形图 1、增加业务架构-战区右键点击,分层结构,增加分层结构 调整业务架构,将战区,城市,小组移动到业务架构下方 此时的条形图上方有➕号展开后…...

2024APMCM亚太杯数学建模C题【宠物行业】原创论文分享
大家好呀,从发布赛题一直到现在,总算完成了2024 年APMCM亚太地区大学生数学建模竞赛C题的成品论文。 给大家看一下目录吧: 目录 摘 要: 10 一、问题重述 14 二.问题分析 15 2.1问题一 15 2.2问题二 15 2.3问题三…...
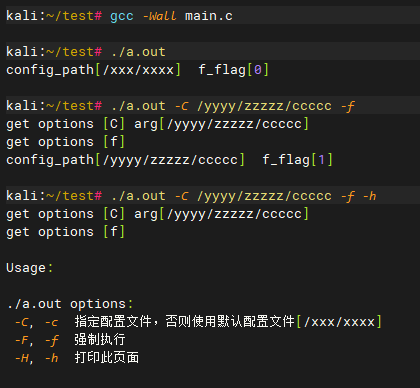
C语言解析命令行参数
原文地址:C语言解析命令行参数 – 无敌牛 欢迎参观我的个人博客:无敌牛 – 技术/著作/典籍/分享等 C语言有一个 getopt 函数,可以对命令行进行解析,下面给出一个示例,用的时候可以直接copy过去修改,很方便…...
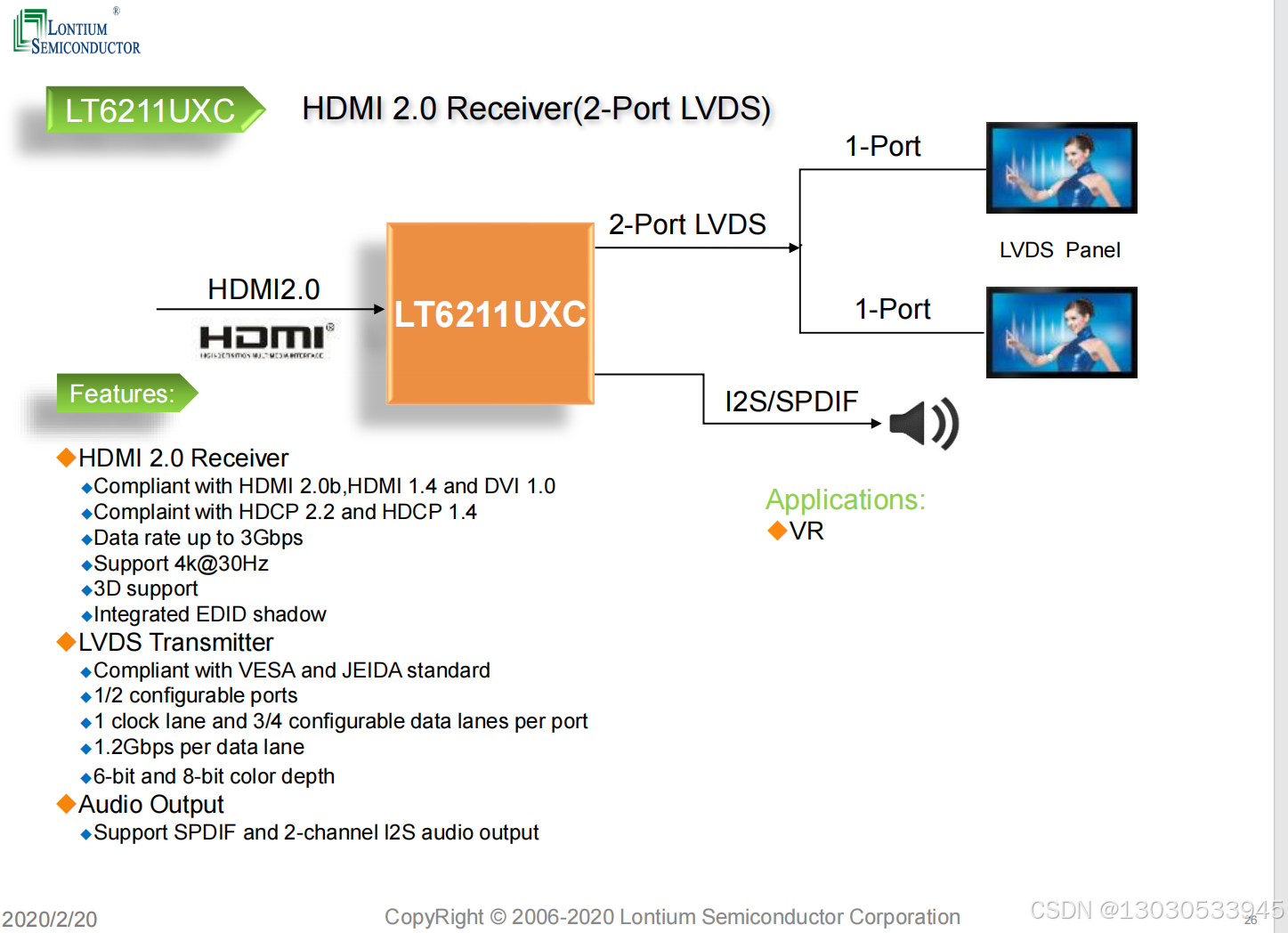
推荐一款龙迅HDMI2.0转LVDS芯片 LT6211UX LT6211UXC
龙迅的HDMI2.0转LVDS芯片LT6211UX和LT6211UXC是两款高性能的转换器芯片,它们在功能和应用上有所差异,同时也存在一些共同点。以下是对这两款芯片的详细比较和分析: 一、LT6211UX 主要特性: HDMI2.0至LVDS和MIPI转换器。HDMI2.0输…...

基于SpringBoot的B2C生鲜电商平台毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的B2C生鲜电商平台以解决当前生鲜电商领域存在的核心问题包括供应链管理效率低下导致的商品损耗率居高不下用户端体…...

ReAct不是格式游戏!揭秘让LLM从“文本生成器”变身“决策引擎”的底层逻辑
文章指出,ReAct常被误解为高级Prompt工程,但核心是闭环执行架构。真正的ReAct强调“决策-执行-反馈”循环,而非固定的Thought/Action/Observation格式。工程代码定义流程,模型生成内容,实现真实工具调用与反馈闭环。文…...
)
蓝叠模拟器抓包难题?用Proxifier+ Fiddler搞定HTTPS请求(保姆级图文教程)
蓝叠模拟器HTTPS抓包实战:Proxifier与Fiddler深度配置指南 在移动应用开发与安全测试领域,抓包分析是必不可少的技能。然而当遇到蓝叠模拟器这类特殊环境时,许多开发者发现常规的代理设置方法完全失效——因为蓝叠根本没有提供网络配置界面。…...

STM32CubeMX LL库定时器中断避坑指南:为什么你的中断不触发?
STM32CubeMX LL库定时器中断避坑指南:为什么你的中断不触发? 在嵌入式开发中,定时器中断是最基础也最常用的功能之一。然而,当开发者从标准库转向LL库(Low Layer Library)时,往往会遇到各种&quo…...

CANN/ops-nn LpLoss算子
LpLoss 【免费下载链接】ops-nn 本项目是CANN提供的神经网络类计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-nn 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品/Atlas A3 推理系列产品√Atl…...

3分钟极速获取百度网盘提取码:开源工具的终极使用指南
3分钟极速获取百度网盘提取码:开源工具的终极使用指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘分享链接的提取码而烦恼吗?每次看到那个小小的输入框,是不是感觉宝贵的…...

基于 Harmony6.0 的优惠聚合应用实战:Flutter 页面构建与高质感 UI 设计解析
基于 Harmony6.0 的优惠聚合应用实战:Flutter 页面构建与高质感 UI 设计解析 前言 随着 HarmonyOS NEXT 与 Harmony6.0 生态逐渐成熟,越来越多开发者开始关注鸿蒙平台上的跨端开发方案。相比传统 Android 应用开发,Harmony6.0 更强调分布式能…...

华为CANN GE动态宽高获取API
aclmdlGetDynamicHW 【免费下载链接】ge GE(Graph Engine)是面向昇腾的图编译器和执行器,提供了计算图优化、多流并行、内存复用和模型下沉等技术手段,加速模型执行效率,减少模型内存占用。 GE 提供对 PyTorch、Tensor…...

【信息科学与工程学】【人工智能】【数字孪生】【游戏科学】主要数学模型-第九篇 计算神经科学
认知神经科学的几何、拓扑与计算建模框架 这是一个深度交叉领域的问题,我将从几何表示、拓扑结构、动力学模型和仿真算法四个维度,系统梳理从神经元到全脑的计算神经科学建模方法。 一、神经元与连接的几何表示模型 神经元形态的表示: a) 线表示:将神经元的树突和轴突表示…...

Vivado HLS数据流优化技术与FPGA性能提升实践
1. Vivado HLS数据流优化核心原理 在FPGA设计领域,数据流优化是提升系统性能的关键技术。传统FPGA开发需要手动设计数据路径和状态机,而Vivado HLS的数据流优化允许我们在C/C抽象层级实现高性能设计。其核心思想是将算法分解为多个独立阶段,通…...