Python双向链表、循环链表、栈
一、双向链表
1.作用
双向链表也叫双面链表。
对于单向链表而言。只能通过头节点或者第一个节点出发,单向的访问后继节点,每个节点只能记录其后继节点的信息(位置),不能向前遍历。
所以引入双向链表,双向链表可以保持单向链表特点的基础上,让每个节点,既能向后访问后继节点,也可以向前访问前驱节点。
2.节点和链表类的定义
双向链表的链接域有prior记录前驱节点,next记录后继节点
#定义节点类的类型
class Node:#显性定义出构造函数def __init__(self,data):self.data = data #普通节点的数据域self.next = None #保存下一个节点的链接域self.prior = None #保存前一个节点饿链接域#定义双向链表的类的类型
class DoubleLink:#定义构造函数def __init__(self,node = None):self.head = node #头结点的head初始化为Noneself.size = 0 #链表的初始长度为03.双向链表的相关操作(判空、头插、遍历、插入、删除、查找)
#定义节点类的类型
class Node:#显性定义出构造函数def __init__(self,data):self.data = data #普通节点的数据域self.next = None #保存下一个节点的链接域self.prior = None #保存前一个节点饿链接域#定义双向链表的类的类型
class DoubleLink:#定义构造函数def __init__(self,node = None):self.head = node #头结点的head初始化为Noneself.size = 0 #链表的初始长度为0#判空def is_empty(self):return self.head == None# return self.size == 0#头插def add_head(self,data):#创建出一个新的节点node = Node(data)#判断链表是否为空 分为空和非空情况if self.is_empty():self.head = nodeelse:node.next = self.headself.head.prior = node #node.next.prior = nodeself.head = node#插入成功 链表长度自增self.size += 1#遍历def show(self):#判空if self.is_empty():print("链表为空 遍历失败")else:q = self.headwhile q:print("%d "%(q.data),end = " ")q = q.nextprint()#任意位置插入def add_index(self,idex,data):#判断插入的位置是否合理if idex<1 or idex>self.size+1:print("插入失败")else:#判断插入的位置是否是第一个位置if idex == 1:self.add_head(data)else:#创建新的节点node = Node(data)#找到要插入位置的前一个节点q = self.headi=1while i<idex-1:q = q.nexti+=1# 判断插入的位置是否是最后一个节点if q.next == None: # 如果为真 则插入的是最后一个位置q.next = nodenode.prior = qelse: # 说明插入不是最后一个node.next = q.nextnode.prior = qq.next.prior = nodeq.next = node#插入成功 链表长度自增self.size += 1#任意位置删除def del_idex(self,idex):#判空 判断位置是否合理:if self.is_empty() or idex<1 or idex>self.size:print("删除失败")else:#判断删除的是否是第一个节点if idex == 1:self.head = self.head.nextself.head.prior = Noneelse:#判断删除的是否是最后一节节点q = self.headi = 1while i<idex:q = q.nexti+=1if q.next:#删除的不是最后一个节点q.prior.next = q.nextq.next.prior = q.priorelse:#删除的是最后一个q.prior.next = None#删除成功 链表长度自减self.size -= 1#查找节点是否存在 按值def find_node(self,data):#判空if self.is_empty():print("查询失败")else:p = self.headwhile p:if p.data == data:return Truep=p.nextreturn False#测试
if __name__ == "__main__":#创建一个双向链表doubleLink = DoubleLink()#头插doubleLink.add_head(10)doubleLink.add_head(20)doubleLink.add_head(30)doubleLink.add_head(40)doubleLink.add_head(50)#遍历doubleLink.show()#任意位置插入doubleLink.add_index(1,33)doubleLink.show()doubleLink.add_index(3, 999)doubleLink.show()doubleLink.add_index(8, 1111)doubleLink.show()#任意位置删除doubleLink.del_idex(1)doubleLink.show()doubleLink.del_idex(4)doubleLink.show()doubleLink.del_idex(6)doubleLink.show()if(doubleLink.find_node(40)):print("存在")二、循环链表
1.概念
循环链表:就是首尾相连的链表,通过任意一个节点,都能将整个链表遍历一遍
分类:单向循环链表、双向循环链表
2.单向循环链表
单向循环链表也就是单向链表的最后一个节点的next域不再为None,而是第一个节点
3.单向循环链表的操作(创建、判空、尾插、遍历、删除)
#封装节点的类
class Node:def __init__(self,data):self.data = dataself.next = None#封装单向循环链表类
class LinkList:def __init__(self,node = None):self.size = 0self.head = node#判空def is_empty(self):return self.size == 0#return self.head == None#尾插def add_tail(self,data):#创建一个新的节点node = Node(data)#判空if self.is_empty():self.head = nodenode.next = nodeelse:#找到最后一个节点q = self.headwhile q.next != self.head:q = q.nextq.next = nodenode.next = self.head#链表长度自增self.size += 1#遍历def show(self):#判空if self.is_empty():print("失败")else:#两种: 长度遍历 位置遍历(循环结束 多打印一次)q = self.headwhile q.next != self.head:print("%d"%(q.data),end=" ")q = q.nextprint("%d"%(q.data),end=" ")print()#尾删def del_tail(self):#判空if self.is_empty():print("删除失败")else:#判断长度是否为1 是否只有一个节点if self.size == 1:self.head = Noneelse:q = self.headi=1while i<self.size-1:q = q.nexti+=1q.next = self.head#删除成功 链表长度自减self.size -=1
#测试
if __name__ == "__main__":#创建一个单向循环链表linkList = LinkList()#尾插linkList.add_tail(1)linkList.add_tail(2)linkList.add_tail(3)linkList.add_tail(4)linkList.add_tail(5)#显示linkList.show()#尾删linkList.del_tail()linkList.show()linkList.del_tail()linkList.show()linkList.del_tail()linkList.show()linkList.del_tail()linkList.show()linkList.del_tail()linkList.show()三、栈
1.概念
栈的概念:操作受限的线性表,对数据的插入和删除操作只能在同一端操作
栈的特点:先进后出(FILO ---->First In Last Out) 、后进先出(LIFO ---->Last In First Out)
栈顶:能够被操作的一端称为栈顶
栈底:不能被操作的一端,称为栈底
种类:顺序栈、链式栈
基本操作:创建栈、判空、入栈、出栈、获取栈顶元素、求栈的大小、遍历栈
2.顺序栈
顺序存储的栈 叫顺序栈
3.顺序栈的操作
#封装一个栈的类
class Stack:def __init__(self):self.data = [] #使用列表来完成顺序栈#判空def is_empty(self):return self.data == []#增加数据def push(self,value):self.data.insert(0,value)#遍历def show(self):for i in self.data:print(i, end=" ")print()#弹出元素 删除def pop(self):#self.data.remove(self.data[0])#self.data.pop(0)del self.data[0]#获取栈顶元素def first_value(self):return self.data[0]#返回栈的大小def size(self):return len(self.data)#测试
if __name__ == "__main__":#创建一个栈stack = Stack()#增加元素stack.push("hello")stack.push("world")stack.push("hello")stack.push("meimei")#遍历stack.show()#删除stack.pop()# 遍历stack.show()num = stack.first_value()print(num)size = stack.size()print(size)四、自行拓展双向循环链表和链式栈
1.双向循环链表
class Node:def __init__(self,data):self.data=dataself.next=Noneself.prior = Noneclass DoubleCirculateLinklist:def __init__(self):self.size = 0self.head = None# 判空def is_empty(self):return self.size==0# 尾插def add_tail(self, value):node = Node(value) # 创建新节点if self.is_empty():self.head = node # 如果链表为空,头结点指向新节点node.next = node # 新节点指向自己,形成循环node.prior = node # 新节点的前驱指向自己else:tail = self.head.prior # 找到当前尾节点tail.next = node # 当前尾节点的下一个指向新节点node.prior = tail # 新节点的前驱指向当前尾节点node.next = self.head # 新节点的后继指向头结点self.head.prior = node # 头结点的前驱指向新节点self.size += 1 # 链表长度自增#遍历def show(self):if self.is_empty():returnelse:q=self.headwhile True:print(f"{q.data}",end=" ")q=q.nextif q==self.head:breakprint()#尾删def del_tail(self):if self.is_empty():returnelif self.size==1:self.head = Noneelse:tail = self.head.prior # 找到当前尾节点tail.prior.next = self.head # 当前尾节点的前一个节点的后继指向头结点self.head.prior = tail.prior # 头结点的前驱指向当前尾节点的前一个节点self.size -= 1 # 链表长度自减if __name__=='__main__':ls=DoubleCirculateLinklist()ls.add_tail(1)ls.add_tail(2)ls.add_tail(3)ls.show()ls.del_tail()ls.del_tail()ls.show()2.链式栈
class Node:def __init__(self, data):self.data = data # 节点的数据域self.next = None # 指向下一个节点的指针class LinkedStack:def __init__(self):self.top = None # 栈顶指针self.size = 0 # 栈的大小def is_empty(self):return self.size == 0def push(self, value):new_node = Node(value) # 创建新节点new_node.next = self.top # 新节点指向当前栈顶self.top = new_node # 更新栈顶为新节点self.size += 1 # 栈的大小自增def pop(self):if self.is_empty():print("栈为空,无法出栈")return Nonetop_value = self.top.data # 获取栈顶元素self.top = self.top.next # 更新栈顶为下一个节点self.size -= 1 # 栈的大小自减return top_value # 返回出栈的元素def find_top(self):if self.is_empty():print("栈为空,无法查看栈顶元素")return Nonereturn self.top.data # 返回栈顶元素def show(self):if self.is_empty():print("栈为空")returnq = self.topwhile q:print(q.data, end=" ")q = q.nextprint() # 换行# 示例代码
if __name__ == "__main__":stack = LinkedStack()stack.push(10)stack.push(20)stack.push(30)stack.show() print("栈顶元素:", stack.find_top()) print("出栈元素:", stack.pop()) stack.show() 相关文章:

Python双向链表、循环链表、栈
一、双向链表 1.作用 双向链表也叫双面链表。 对于单向链表而言。只能通过头节点或者第一个节点出发,单向的访问后继节点,每个节点只能记录其后继节点的信息(位置),不能向前遍历。 所以引入双向链表,双…...

5G基础学习笔记
功能软件化 刚性网络:固定连接、固定功能、固化信令交互 柔性网络:网元拆解成服务模块,基于API接口调用 服务化架构(SBA) Service based Architecture (SBA): 借鉴了业界成熟的SOA、微服务架…...

Python plotly库介绍
一、引言 在数据可视化领域,Python提供了众多强大的库。其中,plotly是一个功能强大、交互式的可视化库,可以创建各种类型的图表,包括线图、散点图、柱状图、饼图、3D图表等。它不仅提供了美观的可视化效果,还支持交互式…...

go编程中yaml的inline应用
下列代码,设计 Config 和 MyConfig 是为可扩展 Config,同时 Config 作为公共部分可保持变化。采用了匿名的内嵌结构体,但又不希望 yaml 结果多出一层。如果 MyConfig 中的 Config 没有使用“yaml:",inline"”修饰,则读取…...

手机实时提取SIM卡打电话的信令声音-智能拨号器的双SIM卡切换方案
手机实时提取SIM卡打电话的信令声音 --智能拨号器app的双SIM卡切换方案 一、前言 在蓝牙电话的方案中,由于采用市场上的存量手机来做为通讯呼叫的载体,而现在市面上大部分的手机都是“双卡双待单通”手机,简称双卡双待手机。即在手机开机后…...

探索Python WebSocket新境界:picows库揭秘
文章目录 探索Python WebSocket新境界:picows库揭秘第一部分:背景介绍第二部分:picows库概述第三部分:安装picows库第四部分:简单库函数使用方法第五部分:场景应用第六部分:常见Bug及解决方案第…...

2024年11月24日Github流行趋势
项目名称:FreeCAD 项目维护者:wwmayer, yorikvanhavre, berndhahnebach, chennes, WandererFan等项目介绍:FreeCAD是一个免费且开源的多平台3D参数化建模工具。项目star数:20,875项目fork数:4,117 项目名称࿱…...

NewStar CTF week5 Crypto wp
easy_ecc ecc的模板题,稍加推理就会发现c1mc2*k因此做一个减法就行,需要注意的点是c1,c2必须放到ecc里面过一道才能出正确结果 k 86388708736702446338970388622357740462258632504448854088010402300997950626097 p 644088904089909773124499208053…...

vue3+antd注册全局v-loading指令
文章目录 1. 创建指令文件2. 全局注册3. 使用 1. 创建指令文件 src/directives 在directives中创建如下文件 src│─directives│ index.ts└─loadingindex.tsindex.vuedirectives/ index.ts export * from ./loadingdirectives/loading/index.ts import { createApp } f…...

初试无监督学习 - K均值聚类算法
文章目录 1. K均值聚类算法概述2. k均值聚类算法演示2.1 准备工作2.2 生成聚类用的样本数据集2.3 初始化KMeans模型对象,并指定类别数量2.4 用样本数据训练模型2.5 用训练好的模型生成预测结果2.6 输出预测结果2.7 可视化预测结果 3. 实战小结 1. K均值聚类算法概述…...

捉虫笔记(七)-再探谁把系统卡住了
捉虫笔记(七)-再探谁把系统卡住 1、内核调试 在实体物理机上,内核调试的第一个门槛就是如何建立调试链接。 这里我选择的建立网络连接进行内核调试。 至于如何建立网络连接后续文章再和大家分享。 2、如何分析 在上一篇文章中,我们…...

【Linux课程学习】:《简易版shell实现和原理》 《哪些命令可以让子进程执行,哪些命令让shell执行(内键命令)?为什么?》
🎁个人主页:我们的五年 🔍系列专栏:Linux课程学习 🌷追光的人,终会万丈光芒 🎉欢迎大家点赞👍评论📝收藏⭐文章 目录 打印命令行提示符(PrintCommandLin…...

2024年11月27日Github流行趋势
项目名称:screenshot-to-code 项目维护者:abi clean99 sweep-ai kachbit vagusX项目介绍:通过上传截图将其转换为整洁的代码(支持HTML/Tailwind/React/Vue)。项目star数:62,429项目fork数:7,614…...

Java中的线程池使用详解
文章目录 Java中的线程池使用详解一、引言二、线程池的创建与使用1、线程池的创建1.1、FixedThreadPool(固定大小线程池)1.2、CachedThreadPool(可缓存线程池)1.3、SingleThreadExecutor(单线程化线程池)1.…...

Redis(概念、IO模型、多路选择算法、安装和启停)
一、概念 关系型数据库是典型的行存储数据库,存在的问题是,按行存储的数据在物理层面占用的是连续存储空间,不适合海量数据存储。 Redis在生产中使用的最多的是用作数据缓存。 服务器先在缓存中查询数据,查到则返回,…...
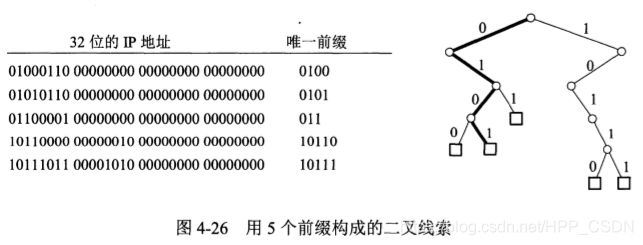
计算机网络 第4章 网络层
计算机网络 (第八版)谢希仁 第 4 章 网络层4.2.2 IP地址**无分类编址CIDR**IP地址的特点 4.2.3 IP地址与MAC地址4.2.4 ARP 地址解析协议4.2.5 IP数据报的格式题目2:IP数据报分片与重组题目:计算IP数据报的首部校验和(不正确未改) …...

Java学习笔记--继承方法的重写介绍,重写方法的注意事项,方法重写的使用场景,super和this
目录 一,方法的重写 二,重写方法的注意事项 三,方法重写的使用场景 四,super和this 1.继承中构造方法的特点 2.super和this的具体使用 super的具体使用 this的具体使用 一,方法的重写 1.概述:子类中有一个和父类…...

高级java每日一道面试题-2024年11月27日-JVM篇-JVM的永久代中会发生垃圾回收么?
如果有遗漏,评论区告诉我进行补充 面试官: JVM的永久代中会发生垃圾回收么? 我回答: 在Java虚拟机(JVM)的历史版本中,确实存在一个称为“永久代”(Permanent Generation, 或者简称PermGen)的内存区域。永久代主要用…...
Spring Boot教程之十: 使用 Spring Boot 实现从数据库动态下拉列表
使用 Spring Boot 实现从数据库动态下拉列表 动态下拉列表(或依赖下拉列表)的概念令人兴奋,但编写起来却颇具挑战性。动态下拉列表意味着一个下拉列表中的值依赖于前一个下拉列表中选择的值。一个简单的例子是三个下拉框,分别显示…...

基于混合ABC和A*算法复现
基于混合ABC和A*算法复现 一、背景介绍二、算法原理(一)A*算法原理(二)人工蜂群算法原理(三)混合ABC和A*算法策略 三、代码实现(一)数据准备(二)关键函数实现…...
)
ChatGPT生成内容同质化困局破局术:用故事化表达重构人机协作范式(仅限首批200位读者获取的叙事权重矩阵)
更多请点击: https://codechina.net 第一章:叙事权重矩阵的底层逻辑与人机协作范式跃迁 叙事权重矩阵并非传统意义上的数值张量,而是一种动态语义映射结构,它将人类叙事意图、上下文可信度、模型生成置信度及跨模态对齐信号统一编…...

告别账单惊吓,Taotoken Token Plan 如何让成本更可控
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 告别账单惊吓,Taotoken Token Plan 如何让成本更可控 对于依赖大模型 API 进行开发的团队和个人而言,项目成…...
)
AI视频生成工具“免费额度”背后的算法剥削:我们逆向拆解11家平台的Token计费黑箱(含实测换算表)
更多请点击: https://codechina.net 第一章:AI视频生成工具收费价格对比 当前主流AI视频生成工具在定价策略上呈现显著差异,涵盖免费试用、按分钟计费、订阅制及企业定制等多种模式。用户在选型时需综合考量生成质量、输出分辨率、商用授权范…...

【ChatGPT故事化表达黄金法则】:20年AI内容专家亲授3步叙事框架,让提示词转化率提升300%
更多请点击: https://intelliparadigm.com 第一章:ChatGPT故事化表达的底层认知革命 传统人机交互长期受限于指令式范式——用户需精确编码意图,系统则机械匹配关键词或规则。ChatGPT 的突破性不在于参数规模,而在于其将语言建模…...

Grafana告警规则配置实战
Grafana告警规则配置实战 一、Grafana告警概述 Grafana提供强大的告警功能,可以基于Prometheus等数据源触发告警通知。 1.1 告警流程 ┌────────────────────────────────────────────────────────────…...

如何构建企业级自动化预约系统:架构设计与工程实践
如何构建企业级自动化预约系统:架构设计与工程实践 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://git…...

深度解析sguard_limit:ACE-Guard内核级资源限制器的架构设计与性能优化
深度解析sguard_limit:ACE-Guard内核级资源限制器的架构设计与性能优化 【免费下载链接】sguard_limit 限制ACE-Guard Client EXE占用系统资源,支持各种腾讯游戏 项目地址: https://gitcode.com/gh_mirrors/sg/sguard_limit 在腾讯游戏生态中&…...
)
ssm网上订餐系统(10089)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

Chat2DB:用AI重新定义数据库操作,让SQL编写效率提升300%的终极解决方案
Chat2DB:用AI重新定义数据库操作,让SQL编写效率提升300%的终极解决方案 【免费下载链接】Chat2DB AI-driven database tool and SQL client, The hottest GUI client, supporting MySQL, Oracle, PostgreSQL, DB2, SQL Server, DB2, SQLite, H2, ClickHo…...

【太阳能】基于matlab PEM电解模拟了24小时太阳能绿色氢电厂(每小时太阳能发电量、氢气产量、用水量、储罐动态以及每公斤H₂的成本【含Matlab源码 15561期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...