新型大语言模型的预训练与后训练范式,阿里Qwen

前言:大型语言模型(LLMs)的发展历程可以说是非常长,从早期的GPT模型一路走到了今天这些复杂的、公开权重的大型语言模型。最初,LLM的训练过程只关注预训练,但后来逐步扩展到了包括预训练和后训练在内的完整流程。后训练通常涵盖监督指导微调和对齐过程,而这些在ChatGPT的推广下变得广为人知。
自ChatGPT首次发布以来,训练方法学也在不断进化。在这几期的文章中,我将回顾近1年中在预训练和后训练方法学上的最新进展。
关于LLM开发与训练流程的概览,特别关注本文中讨论的新型预训练与后训练方法
每个月都有数百篇关于LLM的新论文提出各种新技术和新方法。然而,要真正了解哪些方法在实践中效果更好,一个非常有效的方式就是看看最近最先进模型的预训练和后训练流程。幸运的是,在近1年中,已经有四个重要的新型LLM发布,并且都附带了相对详细的技术报告。
在本文中,我将重点介绍以下模型中的Qwen 2预训练和后训练流程:
• 阿里巴巴的 Qwen 2
• 苹果的 智能基础语言模型
• 谷歌的 Gemma 2
• Meta AI 的 Llama 3.1
我会完整的介绍列表中的全部模型,但介绍顺序是基于它们各自的技术论文在arXiv.org上的发表日期,这也巧合地与它们的字母顺序一致。
1. 阿里的 Qwen 2
我们先来说说 Qwen 2,这是一个非常强大的 LLM 模型家族,与其他主流的大型语言模型具有竞争力。不过,不知为何,它的知名度不如 Meta AI、微软和谷歌那些公开权重的模型那么高。
1.1 Qwen 2 概览
在深入探讨 Qwen 2 技术报告中提到的预训练和后训练方法之前,我们先简单总结一下它的一些核心规格。
Qwen 2 系列模型共有 5 种版本,包括 4 个常规(密集型)的 LLM,分别为 5 亿、15 亿、70 亿和 720 亿参数。此外,还有一个专家混合模型(Mixture-of-Experts),参数量为 570 亿,但每次仅激活 140 亿参数。(由于这次不重点讨论模型架构细节,我就不深入讲解专家混合模型了,不过简单来说,它与 Mistral AI 的 Mixtral 模型类似,但激活的专家更多。如果想了解更高层次的概述,可以参考这一篇知识《模型融合、专家混合与更小型 LLM 的未来》中的 Mixtral 架构部分。)
Qwen 2 模型的一大亮点是它在 30 种语言中的出色多语言能力。此外,它的词汇量非常大,达到 151,642 个 token。(相比之下,Llama 2 的词汇量为 32k,而 Llama 3.1 则为 128k)。根据经验法则,词汇量增加一倍,输入 token 数量会减少一半,因此 LLM 可以在相同输入中容纳更多 token。这种大词汇量特别适用于多语言数据和编程场景,因为它能覆盖标准英语词汇之外的单词。
下面是与其他 LLM 在 MMLU 基准测试中的简要对比。(需要注意的是,MMLU 是一个多选基准测试,因此有其局限性,但仍是评估 LLM 性能的最受欢迎方法之一。)

MMLU基准测试得分,针对最新的开源权重模型(分数越高越好)。这个图中的得分是从每个模型的官方研究论文中收集的。
1.2 Qwen 2 预训练
Qwen 2 团队对参数规模为 15 亿、70 亿和 720 亿的模型进行了训练,使用了 7 万亿个训练 token,这是一个合理的规模。作为对比,Llama 2 模型使用了 2 万亿个 token,Llama 3.1 模型使用了 15 万亿个 token。
有趣的是,参数规模为 5 亿的模型使用了 12 万亿个 token 进行训练。然而,研究人员并没有用这个更大的 12 万亿 token 数据集来训练其他模型,因为在训练过程中并未观察到性能提升,同时额外的计算成本也难以合理化。
他们的一个重点是改进数据过滤流程,以去除低质量数据,同时增强数据混合,从而提升数据的多样性——这一点我们在分析其他模型时会再次提到。
有趣的是,他们还使用了 Qwen 模型(尽管没有明确说明细节,我猜是指前一代的 Qwen 模型)来生成额外的预训练数据。而且,预训练包含了“多任务指令数据……以增强模型的上下文学习能力和指令遵循能力。”
此外,他们的训练分为两个阶段:常规预训练和长上下文预训练。在预训练的最后阶段,他们使用了“高质量、长文本数据”将上下文长度从 4,096 token 增加到 32,768 token。

Qwen 2 预训练技术总结。‘持续预训练’指的是两阶段预训练,研究人员先进行了常规预训练,然后接着进行长上下文的持续预训练。
(遗憾的是,这些技术报告的另一个特点是关于数据集的细节较少,因此如果总结看起来不够详细,是因为公开的信息有限。)
1.3 Qwen 2 后训练
Qwen 2 团队采用了流行的两阶段后训练方法,首先进行监督式指令微调(SFT),在 50 万个示例上进行了 2 个 epoch 的训练。这一阶段的目标是提高模型在预设场景下的响应准确性。

典型的大语言模型开发流程
在完成 SFT 之后,他们使用直接偏好优化(DPO)来将大语言模型(LLM)与人类偏好对齐。(有趣的是,他们的术语将其称为基于人类反馈的强化学习,RLHF。)正如我几周前在《LLM预训练和奖励模型评估技巧》文章中所讨论的,由于相比其他方法(例如结合 PPO 的 RLHF)更加简单易用,SFT+DPO 方法似乎是当前最流行的偏好调优策略。
对齐阶段本身也分为两个步骤。第一步是在现有数据集上使用 DPO(离线阶段);第二步是利用奖励模型形成偏好对,并进入“在线”优化阶段。在这里,模型在训练中会生成多个响应,奖励模型会选择优化步骤中更符合偏好的响应,这种方法也常被称为“拒绝采样”。
在数据集构建方面,他们使用了现有语料库,并通过人工标注来确定 SFT 的目标响应,以及识别偏好和被拒绝的响应(这是 DPO 的关键)。研究人员还合成了人工注释数据。
此外,团队还使用 LLM 生成了专门针对“高质量文学数据”的指令-响应对,以创建用于训练的高质量问答对。

Qwen2后训练技术汇总
1.4 结论
Qwen 2 是一个相对能力较强的模型,与早期的 Qwen 系列类似。在 2023 年 12 月的 NeurIPS LLM 效率挑战赛中,我记得大部分获胜方案都涉及 Qwen 模型。
关于 Qwen 2 的训练流程,值得注意的一点是,合成数据被用于预训练和后训练阶段。同时,将重点放在数据集过滤(而不是尽可能多地收集数据)也是 LLM 训练中的一个显著趋势。在我看来,数据确实是越多越好,但前提是要满足一定的质量标准。
从零实现直接偏好优化(DPO)对齐 LLM
直接偏好优化(DPO)已经成为将 LLM 更好地与用户偏好对齐的首选方法之一。这篇文章中你会多次看到这个概念。如果你想学习它是如何工作的,Sebastian Raschka博士有一篇很好的文章,即:《从零实现直接偏好优化(DPO)用于 LLM 对齐》,你可以看看它。在介绍完本文列表中的模型扣会根据它用中文语言为大家重新编写一篇发布出来。

利用DPO技术实现人工智能大语言模型与人类对齐流程概览
相关文章:
新型大语言模型的预训练与后训练范式,阿里Qwen
前言:大型语言模型(LLMs)的发展历程可以说是非常长,从早期的GPT模型一路走到了今天这些复杂的、公开权重的大型语言模型。最初,LLM的训练过程只关注预训练,但后来逐步扩展到了包括预训练和后训练在内的完整…...

深入理解 Dubbo 如何动态感知服务下线
在现代分布式系统中,服务的上下线管理是非常重要的功能,尤其是服务动态扩展与缩减的需求日益频繁。在这种环境中,如何确保消费者能够实时感知到服务的状态变化,减少因服务失效导致的调用失败,直接影响系统的可用性和用…...

VSCode 下载 安装
VSCode【下载】【安装】【汉化】【配置C环境(超快)】(Windows环境)-CSDN博客 Download Visual Studio Code - Mac, Linux, Windowshttps://code.visualstudio.com/Downloadhttps://code.visualstudio.com/Download 注意࿰…...

局域网的网络安全
网络安全 局域网基本上都采用以广播为技术基础的以太网,任何两个节点之间的通信数据包,不仅为这两个节点的网卡所接收,也同时为处在同一以太网上的任何一个节点的网卡所截取。因此,黑客只要接入以太网上的任一节点进行侦听&#…...

VMware ubuntu创建共享文件夹与Windows互传文件
1.如图1所示,点击虚拟机,点击设置; 图1 2.如图2所示,点击选项,点击共享文件夹,如图3所示,点击总是启用,点击添加; 图2 图3 3.如图4所示,出现命名共享文件夹…...
)
TCP/IP网络编程-C++(上)
TCP/IP网络编程-C (上) 一、基于TCP的服务端/客户端1、server端代码2、client端代码3、socket() 函数3.1、函数原型3.2、参数解析3.2.1、协议族(domain参数)3.2.2、套接字类型(type参数)3.2.3、最终使用的协…...

React Hooks中use的细节
文档 useState useState如果是以函数作为参数,那要求是一个纯函数,不接受任何参数,同时需要一个任意类型的返回值作为初始值。 useState可以传入任何类型的参数作为初始值,当以一个函数作为参数进行传入的时候需要注意ÿ…...

通信网络安全分层及关键技术解决
要实现信息化,就必须重视信息网络安全。信息网络安全绝不仅是IT行业的问题,而是一个社会问题,是一个包括多学科的系统安全工程问题,并直接关系到国家安全。因此,知名安全专家沈昌祥院士呼吁,要像重视两弹一…...

C++ 面向对象包含哪些设计原则
设计模式是由设计原则迭代出来的 开闭原则:一个类应该对扩展开放,对修改关闭 稳定的部分稳定住,变化的部分扩展 扩展可以通过继承和组合 相关原则:单一职责原则、里氏替换原则、接口隔离原则 单一职责原则:一个类应该…...

微信小程序首页搜索框的实现教程
微信小程序首页搜索框的实现教程 前言 在现代移动应用中,搜索功能是用户获取信息的主要方式之一。对于购物小程序而言,提供一个美观且高效的搜索框,可以显著提升用户体验,帮助用户快速找到他们想要的商品。本文将详细介绍如何在微信小程序中实现一个样式优美的搜索框,包…...

android集成FFmpeg步骤以及常用命令,踩坑经历
1、入坑第一步:首先集成的库必须正确。最好是有ndk的,FFmpeg有许多个版本,我才开始接触的时候随便选了一个,一般的 方法没有问题。但是涉及到需要使用libx264等条件进行编码时,老是报错,网上搜索资料也没有…...

Go错误与日志处理—推荐实践
错误的分类 在 Go 语言中,错误是通过实现 error 接口的类型表示的,但不同场景下的错误可以按性质和用途进行分类。以下是 Go 语言错误的常见分类,以及每类错误的解释和示例: 标准错误类型 标准库中定义了许多常见的错误类型&…...

Android 13 Aosp Settings Android Studio版本
Android 13 Aosp Settings Android Studio版本 Settings相关源码 Settings https://android.googlesource.com/platform/packages/apps/Settings/+/refs/heads/android13-release SettingsIntelligence https://android.googlesource.com/platform/packages/apps/SettingsIn…...

Jedis存储一个以byte[]的形式的对象到Redis
1.1 准备一个User实体类 import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor;import java.io.Serializable; import java.util.Date;Data NoArgsConstructor AllArgsConstructor public class User implements Serializable {private In…...

updatexml报错注入原理分析
《网络安全自学教程》 SQL注入时,经常利用updatexml()的报错特性来脱库。 updatexml报错原理 1、updatexml语法参数2、报错原理分析3、使用updatexml()脱库4、分割显示结果 updatexml() 的作用是修改xml文件的内容。 1、updatexml语法参数 updatexml(参数1&#x…...

蓝桥杯c++算法秒杀【6】之动态规划【上】(数字三角形、砝码称重(背包问题)、括号序列、组合数问题:::非常典型的必刷例题!!!)
下将以括号序列、组合数问题超级吧难的题为例子讲解动态规划 别忘了请点个赞收藏关注支持一下博主喵!!!! ! ! ! ! 关注博主,更多蓝桥杯nice题目静待更新:) 动态规划 一、数字三角形 【问题描述】 上图给出了…...

【Qt】重写QComboBox下拉展示多列数据
需求 点击QComboBox时,下拉列表以多行多列的表格展示出来。 实现 直接上代码: #include <QComboBox> #include <QTableWidget> #include <QVBoxLayout> #include <QWidget> #include <QEvent> #include <QMouseEve…...
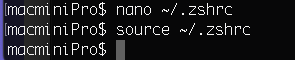
【mac】终端左边太长处理,自定义显示名称(terminal路径显示特别长)
1、打开终端 2、步骤 (1)修改~/.zshrc文件 nano ~/.zshrc(2)添加或修改PS1,我是自定义了名字为“macminiPro” export PS1"macminiPro$ "(3)使用 nano: Ctrl o (字母…...

基于Springboot的流浪宠物管理系统
基于javaweb的流浪宠物管理系统 介绍 基于javaweb的流浪宠物管理系统的设计与实现,后端框架使用Springbootmybatis,前端框架使用Vuehrml,数据库使用mysql,使用B/S架构实现前台用户系统和后台管理员系统,和不同权限级别…...

web博客系统的自动化测试
目录 前言测试用例编写自动化脚本测试准备博客登录页相关测试用例登陆成功登录失败 博客首页相关测试用例登陆成功登录失败 博客详情页相关测试用例登录成功登录失败 博客编辑页相关测试用例登陆成功登录失败 编写测试文档测试类型内容 前言 本次测试是运用个人写的一个博客系…...

后端架构技术01-「10万并发压垮线程池?Project Loom虚拟线程:一个线程几KB,轻松扛住流量洪峰」
Java虚拟线程革命:从线程池地狱到10万并发自由CSDN标签:Java, 虚拟线程, Project Loom, 高并发, 性能优化, 后端开发, 微服务开篇黄金100字你的线程池又OOM了? 每次大促前,你是不是也在疯狂调整corePoolSize和maximumPoolSize&…...

卖电子元器件怎么找客户?下游工厂在哪里
卖电子元器件找客户,本质是找用这些元器件的下游工厂——即需要采购连接器、继电器、电容、电阻、变压器等被动及结构件的整机或 PCBA 生产企业。核心难点不是"不知道哪些行业用",而是无法把这些下游工厂的名单、规模和采购联系人系统地整理出…...

[特殊字符] Lucky从零到一的系统搭建里程碑 | 写给后人的初心与使命
🌱 从零到一的足迹 写给未来的你们: 这不是炫耀,不是宣传。 这是一个普通人,一个退伍军人,一个什么都不懂的人,和AI一起创造的故事。 如果这个系统让你们受益,请记住:初心、根、使命…...

从 ROI 看:什么时候只用单 Agent 更优
从 ROI 看:什么时候只用单 Agent 更优一、 引言 (Introduction) 1.1 钩子 (The Hook) 你有没有见过这样的项目场景? 场景1:创业公司MVP阶段 小团队只有2个算法工程师、1个全栈,预算只有30万/月的云服务和人力折算(算法…...

2026年AI论文平台实测排行,哪款真正适合毕业定稿?
2026 年学术 AI 论文工具已形成全流程、理工 / 社科、英文 / 中文、免费 / 付费的清晰分化。综合实测排行与场景适配,千笔AI 是中文全能首选,DeepSeek 学术版是理工开源首选,毕业之家是国内毕业专属首选。 一、2026 年实测排行 TOP5…...

为什么92%的DeepSeek部署失败?揭秘量化校准中被忽略的3个KL散度阈值临界点
更多请点击: https://intelliparadigm.com 第一章:为什么92%的DeepSeek部署失败?揭秘量化校准中被忽略的3个KL散度阈值临界点 在真实生产环境中,DeepSeek-R1/Distill系列模型的INT4量化部署失败率高达92%,核心症结并非…...

Windows上的安卓应用安装神器:APK-Installer完全指南
Windows上的安卓应用安装神器:APK-Installer完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上轻松安装安卓应用,又不想…...
)
DeepSeek负载均衡方案竟被90%团队忽略的3个致命盲区:长连接保活、gRPC流式重试、Token级会话粘滞(附Checklist)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek负载均衡方案的演进与核心挑战 DeepSeek作为高性能开源大语言模型推理框架,其负载均衡方案经历了从静态路由到动态感知、从单层代理到多级协同的持续演进。早期版本依赖Nginx反向代…...

AI率总超标?2026年AI论文平台排行榜权威发布,一次过审不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...

如何快速实现Windows硬件ID伪装:EASY-HWID-SPOOFER终极指南
如何快速实现Windows硬件ID伪装:EASY-HWID-SPOOFER终极指南 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在当今数字隐私日益重要的时代,硬件指纹追踪已成…...