实时数仓Kappa架构:从入门到实战
引言
随着大数据技术的不断发展,企业对实时数据处理和分析的需求日益增长。实时数仓(Real-Time Data Warehouse, RTDW)应运而生,其中Kappa架构作为一种简化的数据处理架构,通过统一的流处理框架,解决了传统Lambda架构中批处理和实时处理的复杂性。本文将深入探讨Kappa架构的历史背景、业务场景、功能点、优缺点、解决的问题以及底层原理,并详细介绍如何使用Java语言快速搭建一套实时数仓。
一、Kappa架构的历史背景
1.1 Lambda架构的局限性
Lambda架构由Nathan Marz提出,旨在通过批处理层和速度层的结合,同时满足实时数据分析和历史数据分析的需求。然而,Lambda架构存在以下局限性:
- 系统复杂性高:需要维护两套系统(批处理层和速度层),增加了开发和维护的难度。
- 数据一致性延迟:由于批处理层和速度层的数据处理存在时间差,可能导致数据一致性问题。
1.2 Kappa架构的提出
Kappa架构由LinkedIn的前首席工程师杰伊·克雷普斯(Jay Kreps)提出,作为Lambda架构的改进方案。Kappa架构通过删除批处理层,仅保留流处理层,实现了实时和批量数据的统一处理,从而简化了系统架构。
二、Kappa架构的业务场景
Kappa架构广泛应用于需要实时处理和分析数据的场景,包括但不限于:
- 金融服务:实时交易监控、欺诈检测和风险管理。
- 电子商务:实时推荐系统、库存管理和客户行为分析。
- 物联网(IoT):设备监控、预测性维护和实时数据流分析。
- 社交媒体:实时内容分析、趋势分析和用户互动监控。
- 电信:实时网络监控、流量分析和故障检测。
三、Kappa架构的功能点
3.1 数据流处理
Kappa架构所有数据都是以事件流的形式处理的,没有批处理的概念。数据流是连续的、实时的,不需要区分历史数据和实时数据。
3.2 简化架构
通过统一的流处理框架,Kappa架构简化了数据处理流程,避免了Lambda架构中批处理层和速度层的分离,降低了系统复杂性和维护成本。
3.3 流处理框架
Kappa架构使用流处理引擎(如Apache Kafka、Apache Flink、Apache Storm)来处理数据流。数据在流处理引擎中进行过滤、转换、聚合等处理操作,实时生成结果。
3.4 数据存储与查询
处理后的数据存储在低延迟、高吞吐量的存储系统中(如Apache Kafka、Cassandra、HBase、Elasticsearch等),支持快速写入和查询,以满足实时数据分析的需求。
四、Kappa架构的优缺点
4.1 优点
- 简化架构:通过统一的流处理引擎,简化了数据处理流程,降低了系统复杂性和维护成本。
- 实时处理:所有数据都以事件流的形式实时处理,提供实时的数据分析和决策支持。
- 一致性:由于没有批处理和实时处理的分离,数据的一致性和完整性更容易保证。
- 灵活性:支持各种实时数据源和数据类型,具有较高的灵活性和可扩展性。
4.2 缺点
- 流处理复杂性:设计和实现高效的流处理逻辑需要专业的技术和经验,处理复杂的业务逻辑和数据操作。
- 故障恢复:实时数据处理对系统的稳定性和容错性要求高,需要有效的故障恢复机制。
- 数据存储和查询:实时数据存储系统需要支持高吞吐量和低延迟的写入和查询,确保实时分析的性能。
- 成本:实时处理和存储系统的成本较高,需要投入更多的资源和技术支持。
五、Kappa架构解决的问题
Kappa架构通过统一的流处理框架,解决了传统Lambda架构中批处理和实时处理的复杂性,实现了实时和批量数据的统一处理。这解决了以下问题:
- 数据一致性延迟:通过流处理框架,实时处理和批量处理的数据保持一致,避免了数据一致性延迟问题。
- 系统复杂性:简化了系统架构,降低了开发和维护的难度。
- 资源利用率:提高了资源利用率,避免了批处理层和速度层的资源重复投入。
六、Kappa架构的底层原理
6.1 数据流
在Kappa架构中,数据流是连续的、实时的,从各种数据源(如传感器、日志、交易系统等)产生,并通过消息队列(如Apache Kafka)传输到流处理引擎。
6.2 流处理引擎
流处理引擎(如Apache Flink)接收数据流,执行过滤、转换、聚合等操作,并实时生成处理结果。流处理引擎能够处理复杂的计算逻辑,支持窗口函数、状态管理等高级功能。
6.3 数据存储
处理后的数据存储在高性能的存储系统中(如Apache Kafka、Cassandra等),这些存储系统支持快速写入和查询,以满足实时数据分析的需求。同时,存储系统还可以保留数据的完整历史记录,以便进行历史数据分析和重放。
6.4 查询与分析
用户可以通过查询引擎和BI工具实时访问和分析存储的数据。数据可视化工具提供实时的数据展示和报告生成,帮助用户快速获取数据洞察并做出决策。
七、使用Java快速搭建实时数仓示例
7.1 环境准备
首先,确保你已经安装了以下软件和工具:
- Java Development Kit (JDK):用于Java程序的开发和编译。
- Apache Kafka:用于消息队列和数据流传输。
- Apache Flink:用于流处理。
- MySQL:用于模拟数据源。
- Maven:用于项目管理和依赖管理。
7.2 项目结构
创建一个Maven项目,项目结构如下:
复制代码 realtime-dw ├── pom.xml ├── src │ ├── main │ │ ├── java │ │ │ └── com │ │ │ └── example │ │ │ ├── KafkaProducer.java │ │ │ ├── FlinkJob.java │ │ │ └── Main.java │ │ └── resources │ │ └── application.properties
7.3 添加依赖
在pom.xml文件中添加必要的依赖:
xml复制代码
<dependencies>
<!-- Kafka Client -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.8.0</version>
</dependency>
<!-- Flink Dependencies -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.13.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.13.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.13.2</version>
</dependency>
<!-- MySQL JDBC Driver -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
</dependencies>7.4 模拟数据源
使用MySQL数据库模拟数据源,创建一个简单的表并插入一些数据:
sql复制代码
CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(50),age INT,created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO users (id, name, age) VALUES (1, 'Alice', 30), (2, 'Bob', 25), (3, 'Charlie', 35);7.5 Kafka生产者
编写一个Kafka生产者,将数据从MySQL数据库读取并发送到Kafka主题:
java复制代码
package com.example;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.Properties;
public class KafkaProducer {
private static final String KAFKA_TOPIC = "user_topic";
private static final String KAFKA_BOOTSTRAP_SERVERS = "localhost:9092";
public static void main(String[] args) {
Properties props = new Properties();props.put("bootstrap.servers", KAFKA_BOOTSTRAP_SERVERS);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");KafkaProducer<String, String> producer = new KafkaProducer<>(props);
try (Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb", "username", "password");
Statement statement = connection.createStatement()) {
ResultSet resultSet = statement.executeQuery("SELECT * FROM users");
while (resultSet.next()) {
String key = resultSet.getString("id");
String value = resultSet.getString("name") + "," + resultSet.getInt("age") + "," + resultSet.getTimestamp("created_at");ProducerRecord<String, String> record = new ProducerRecord<>(KAFKA_TOPIC, key, value);producer.send(record);}} catch (Exception e) {e.printStackTrace();} finally {producer.close();}}
}7.6 Flink作业
编写一个Flink作业,从Kafka主题读取数据并进行实时处理:
java复制代码
package com.example;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
public class FlinkJob {
private static final String KAFKA_TOPIC = "user_topic";
private static final String KAFKA_BOOTSTRAP_SERVERS = "localhost:9092";
private static final String GROUP_ID = "flink-group";
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(KAFKA_TOPIC, new SimpleStringSchema(), props);consumer.setGroupId(GROUP_ID);DataStream<String> stream = env.addSource(consumer);DataStream<String> processedStream = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {String[] parts = value.split(",");
return "User ID: " + parts[0] + ", Name: " + parts[1] + ", Age: " + parts[2] + ", Created At: " + parts[3];}});processedStream.print();env.execute("Real-Time Data Warehouse with Flink");}
private static Properties getKafkaProperties() {
Properties props = new Properties();props.setProperty("bootstrap.servers", KAFKA_BOOTSTRAP_SERVERS);props.setProperty("group.id", GROUP_ID);
return props;}
}7.7 启动程序
- 启动Kafka和Zookeeper。
- 启动MySQL数据库,并确保
users表中有数据。 - 运行
KafkaProducer类,将数据发送到Kafka主题。 - 运行
FlinkJob类,从Kafka主题读取数据并进行实时处理。
7.8 结果展示
在控制台中,你将看到Flink作业实时处理并输出数据:
复制代码 User ID: 1, Name: Alice, Age: 30, Created At: 2023-10-01 12:00:00 User ID: 2, Name: Bob, Age: 25, Created At: 2023-10-01 12:00:01 User ID: 3, Name: Charlie, Age: 35, Created At: 2023-10-01 12:00:02
八、总结
Kappa架构作为一种简化的数据处理架构,通过统一的流处理框架,解决了传统Lambda架构中批处理和实时处理的复杂性,提供了强大的实时数据处理和分析能力。本文详细介绍了Kappa架构的历史背景、业务场景、功能点、优缺点、解决的问题以及底层原理,并给出了使用Java语言快速搭建实时数仓的示例。通过本文的学习,读者可以深入了解Kappa架构的原理和实现方法,并能够在实际项目中应用这一技术。
相关文章:

实时数仓Kappa架构:从入门到实战
引言 随着大数据技术的不断发展,企业对实时数据处理和分析的需求日益增长。实时数仓(Real-Time Data Warehouse, RTDW)应运而生,其中Kappa架构作为一种简化的数据处理架构,通过统一的流处理框架,解决了传统…...

【老白学 Java】Warship v2.0(四)
Warship v2.0(四) 文章来源:《Head First Java》修炼感悟。 上一篇文章中,老白仔细分析了 v2.0 的设计思路以及实现手段,如果大家有好的设计方案也可以自行尝试。 本篇文章的主要内容是对 Warship 类进行最后的修改&a…...

LLM之学习笔记(一)
前言 记录一下自己的学习历程,也怕自己忘掉了某些知识点 Prefix LM 和 Causal LM区别是什么? Prefix LM (前缀语⾔模型)和 Causal LM(因果语言模型)是两者不同类型的语言模型,它们的区别在于生…...

C# 反射详解
反射是C#中的一个强大特性,允许程序在运行时检查和操作类型和对象的信息。 通过反射,你可以获取类型的属性、方法、构造函数等信息,并可以动态创建对象、调用方法或访问属性,甚至可以实现某些框架或库的核心功能。 反射的基本概念…...

pgadmin安装后运行不能启动界面的问题
在本人机器上安装了pgsql10后,自带的pgadmin安装后运行时能打开edge并显示数据库server和数据库的,后来又安装了pgsql17,结果安装后想打开pgadmin,结果一直在等待最后,爆出类似于下面的错误。 pgAdmin Runtime Enviro…...
)
跳表(Skip List)
跳表(Skip List) 跳表是一种用于快速查找、插入和删除的概率型数据结构,通常用于替代平衡二叉搜索树(如 AVL 树或红黑树)。跳表通过在有序链表的基础上增加多层索引,使得查找操作的平均时间复杂度降低&…...

前端实现把整个页面转成PDF保存到本地(DOM转PDF)
一、问题 遇到一个需求,就是要把整个看板页面导出成PDF用在汇报,也就是要把整个DOM生成一个PDF保存到本地。 二、解决方法 1、解决思路:使用插件 jspdf 和 html2canvas,我用的版本如下图 2、代码实现 import { jsPDF } from …...
)
Vue 3 学习文档(一)
最近打算做一个项目,涉及到一些前端的知识,因上一次接触前端已经是三四年前了,所以捡一些简单的功能做一下复习。 响应式函数:reactive 和 ref属性绑定:v-bind 和简写语法事件监听:v-on 和简写语法 双向绑…...

【适配】屏幕拖拽-滑动手感在不同分辨率下的机型适配
接到一个需求是类似下图的3D多房间视角,需要拖拽屏幕 问题 在做这种屏幕拖拽的时候发现,需要拖拽起来有跟手的感觉,会存在不同分辨率机型的适配问题。 即:美术调整好了机型1的手感,能做到手指按下顶层地板上下挪动&…...

牛客周赛 Round 69(A~E)
文章目录 A 构造C的歪思路code B 不要三句号的歪思路code C 仰望水面的歪思路code D 小心火烛的歪思路code E 喜欢切数组的红思路code 牛客周赛 Round 69 A 构造C的歪 思路 签到题,求出公差d,让最大的数加上公差d即可 code int a,b;cin >> a &…...

Spring Boot 实战:分别基于 MyBatis 与 JdbcTemplate 的数据库操作方法实现与差异分析
1. 数据库新建表 CREATE TABLE table_emp(id INT AUTO_INCREMENT,emp_name CHAR(100),age INT,emp_salary DOUBLE(10,5),PRIMARY KEY(id) );INSERT INTO table_emp(emp_name,age,emp_salary) VALUES("tom",18,200.33); INSERT INTO table_emp(emp_name,age,emp_sala…...
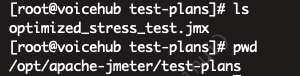
【jmeter】服务器使用jmeter压力测试(从安装到简单压测示例)
一、服务器上安装jmeter 1、官方下载地址,https://jmeter.apache.org/download_jmeter.cgi 2、服务器上用wget下载 # 更新系统 sudo yum update -y# 安装 wget 以便下载 JMeter sudo yum install wget -y# 下载 JMeter 压缩包(使用 JMeter 官方网站的最…...

使用Python实现自动化邮件通知:当长时程序运行结束时
使用Python实现自动化邮件通知:当长时程序运行结束时 前提声明 本代码仅供学习和研究使用,不得用于商业用途。请确保在合法合规的前提下使用本代码。 目录 引言项目背景项目设置代码分析 导入所需模块定义邮件发送函数发送邮件 实现步骤结语全部代码…...

框架学习07 - SpringMVC 其他功能实现
一. 拦截器实现HandlerInterceptor 接⼝ SpringMVC 中的 Interceptor 拦截器也是相当重要和相当有⽤的,它的主要作⽤是拦截⽤户的请求并进⾏相应的处理。⽐如通过它来进⾏权限验证,或者是来判断⽤户是否登陆等操作。对于 SpringMVC 拦截器的定义⽅式有两…...

NAT:连接私有与公共网络的关键技术(4/10)
一、NAT 的工作原理 NAT 技术的核心功能是将私有 IP 地址转换为公有 IP 地址,使得内部网络中的设备能够与外部互联网通信。其工作原理主要包括私有 IP 地址到公有 IP 地址的转换、端口号映射以及会话表维护这几个步骤。 私有 IP 地址到公有 IP 地址的转换࿱…...

RabbitMQ2:介绍、安装、快速入门、数据隔离
欢迎来到“雪碧聊技术”CSDN博客! 在这里,您将踏入一个专注于Java开发技术的知识殿堂。无论您是Java编程的初学者,还是具有一定经验的开发者,相信我的博客都能为您提供宝贵的学习资源和实用技巧。作为您的技术向导,我将…...

衡山派D133EBS 开发环境安装及SDK编译烧写镜像烧录
1.创建新文件夹,用来存放SDK包(其实本质就是路径要对就ok了),右键鼠标通过Open Git Bash here来打开git 输入命令 git clone --depth1 https://gitee.com/lcsc/luban-lite.git 来拉取,如下所示:࿰…...

【Spring MVC】如何获取cookie/session以及响应@RestController的理解,Header的设置
前言 🌟🌟本期讲解关于SpringMVC的编程之参数传递~~~ 🌈感兴趣的小伙伴看一看小编主页:GGBondlctrl-CSDN博客 🔥 你的点赞就是小编不断更新的最大动力 🎆那么废…...

C++设计模式行为模式———策略模式
文章目录 一、引言二、策略模式三、总结 一、引言 策略模式是一种行为设计模式, 它能让你定义一系列算法, 并将每种算法分别放入独立的类中, 以使算法的对象能够相互替换。与模板方法模式类似,都是以扩展的方式来支持未来的变化。…...

Spring Cloud 中 bootstrap.yml 配置文件详解
Spring Cloud 中 bootstrap.yml 配置文件详解 1. 什么是 bootstrap.yml? bootstrap.yml 是 Spring Cloud 提供的一个特殊配置文件,主要用于初始化 Spring Cloud 应用程序的环境。与常见的 application.yml 不同,bootstrap.yml 在 Spring 应用…...

ThinkPad开机嘀嘀响或报2100/2110错误?可能是硬盘松了!自己动手检测与修复指南
ThinkPad开机嘀嘀响或报2100/2110错误?三步排查硬盘接触不良问题ThinkPad用户对那个标志性的开机"嘀嘀"声再熟悉不过——正常情况下它意味着系统自检通过。但当这个声音变成急促的报警音,伴随屏幕上出现"2100 Detection error"或&qu…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

ARMv8 HFGITR_EL2寄存器解析与虚拟化指令陷阱控制
1. AArch64 HFGITR_EL2寄存器架构解析HFGITR_EL2(Hypervisor Fine-Grained Instruction Trap Register)是ARMv8架构中专门用于指令级陷阱控制的系统寄存器,属于虚拟化扩展的重要组成部分。这个64位寄存器通过位映射机制实现对特定AArch64指令…...

13456
12356...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...

机器学习与SHAP在教育公平研究中的应用:精准定位学业困境根源
1. 项目概述:当机器学习遇见教育公平,我们如何精准定位学业困境的根源?在拉丁美洲的教育研究领域,一个长期困扰政策制定者和研究者的核心问题是:究竟是什么因素,在复杂的社会经济背景下,系统性地…...

基于ESP32与MQTT的家庭环境监测系统:从传感器选型到数据可视化实战
1. 项目概述与核心价值最近几年,我身边越来越多的朋友开始关注家里的空气质量、温湿度这些看不见摸不着,但又实实在在影响生活舒适度和健康的环境指标。从新装修的房子担心甲醛,到有老人小孩的家庭在意PM2.5和二氧化碳浓度,再到南…...

Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案
Performance-Fish:让你的《环世界》后期游戏帧率提升400%的终极优化方案 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish 你是否曾在《环世界》游戏后期,面对庞大…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...