NLP任务四大范式的进阶历程:从传统TF-IDF到Prompt-Tuning(提示词微调)
引言:从TF-IDF到Prompt-Tuning(提示词微调),NLP的四次变革
自然语言处理(NLP)技术从最早的手工特征设计到如今的Prompt-Tuning,经历了四个重要阶段。随着技术的不断发展,我们的目标从“更高精度”逐渐转向“更少监督”甚至“无监督”。本篇文章将带你全面解析NLP任务的四大范式,并剖析Fine-Tuning和Prompt-Tuning的核心原理。
1. NLP四种范式的进阶历程

1.1 第一范式:传统机器学习模型的起点
• 核心特征:
• 基于手工设计特征(如TF-IDF、n-gram),并结合朴素贝叶斯、支持向量机等经典算法完成任务。
• 案例:
假设要解决文本分类任务(如垃圾邮件识别),可以用TF-IDF提取邮件关键词特征,结合朴素贝叶斯判断一封邮件是否为垃圾邮件。
• 优点:
• 简单高效,适合小规模数据集。
• 计算成本低,模型易解释。
• 缺点:
• 特征工程依赖人工设计,难以扩展到复杂任务。
• 无法捕获上下文语义信息,模型精度有限。
1.2 第二范式:深度学习模型的崛起
• 核心特征:
• 使用分布式词表示(如word2vec、GloVe)将单词编码为语义向量。
• 借助LSTM、GRU等深度学习模型,捕获上下文依赖关系。
• 案例:
在情感分析任务中,用word2vec将“我今天很开心”转化为向量后,使用LSTM网络提取句子特征,再预测句子情感。
• 优点:
• 自动学习特征,无需复杂的手工设计。
• 能捕获一定的上下文语义关系。
• 缺点:
• 依赖大规模标注数据集,成本高昂。
• 模型复杂度提升,对硬件资源要求高。
1.3 第三范式:预训练模型与微调的黄金时代

Fine-Tuning(微调)属于一种迁移学习方式,在自然语言处理(NLP)中,Fine-Tuning(微调)是用于将预训练的语言模型适应于特定任务或领域。Fine-Tuning(微调)的基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它.
经典的Fine-Tuning(微调)方法包括将预训练模型与少量特定任务数据一起继续训练。在这个过程中,预训练模型的权重被更新,以更好地适应任务。所需的Fine-Tuning(微调)量取决于预训练语料库和任务特定语料库之间的相似性。如果两者相似,可能只需要少量的Fine-Tuning(微调),如果两者不相似,则可能需要更多的Fine-Tuning(微调).
但是,在大多数下游任务微调时,下游任务的目标和预训练的目标差距过大导致提升效果不明显(过拟合),微调过程中需要依赖大量的监督语料等等。至此,以GPT3、PET等为首的模型提出一种基于预训练语言模型的新的微调范式--Prompt-Tuning.该方法的目的是通过添加模板的方法来避免引入额外的参数,从而让模型可以在小样本(few-shot)或者零样本(zero-shot)场景下达到理想的效果。
• 核心特征:
• 使用大规模预训练模型(如BERT、GPT)学习通用语言表示,通过Fine-Tuning(微调)完成特定任务。
• 案例:
在命名实体识别任务中,加载预训练好的BERT模型,微调后即可高效完成“识别句子中的地名、人名”等任务。
• 优点:
• 小数据集即可实现高精度。
• 模型捕获了丰富的语言知识,表现优于传统方法。
• 缺点:
• 模型体积庞大,对计算资源要求高。
• 不同任务需要单独微调,效率较低。
1.4 第四范式:Prompt-Tuning的崭新未来

在大多数下游任务微调时,下游任务的目标和预训练的目标差距过大导致提升效果不明显(过拟合),微调过程中需要依赖大量的监督语料等等。至此,以GPT3、PET等为首的模型提出一种基于预训练语言模型的新的微调范式--Prompt-Tuning(提示微调).该方法的目的是通过添加模板的方法来避免引入额外的参数,从而让模型可以在小样本(few-shot)或者零样本(zero-shot)场景下达到理想的效果。
Prompt-Tuning(提示微调)主要解决传统Fine-Tuning方式的两个痛点:
- 降低语义偏差:预训练任务主要以MLM为主,而下游任务则重新引入新的训练参数,因此两个阶段目标差异较大。因此需要解决Pre-Training(预训练)和Fine-Tuning(微调)之间的Gap(gap就是差距的意思)。
- 避免过拟合:由于Fine-Tuning阶段需要引入新的参数适配相应任务,因此在样本数量有限的情况下容易发生过拟合,降低模型泛化能力。因此需要解决预训练模型的过拟合能力。
prompt顾名思义就是“提示”的意思,应该有人玩过你画我猜这个游戏吧,对方根据一个词语画一幅画,我们来猜他画的是什么,因为有太多灵魂画手了,画风清奇,或者你们没有心有灵犀,根本就不好猜啊!这时候屏幕上会出现一些提示词比如3个字,水果,那岂不是好猜一点了嘛,毕竟3个字的水果也不多呀。看到了吧,这就是prompt的魅力.
基于Fine-Tuning的方法是让预训练模型去迁就下游任务,而基于Prompt-Tuning(提示微调)的方法可以让下游任务去迁就预训练模型, 其目的是将Fine-tuning的下游任务目标转换为Pre-Training(预训练)的任务。那么具体如何工作呢?我们以一个二分类的情感分析为例子,进行简单理解:
- eg: 定一个句子
[CLS] I like the Disney films very much. [SEP] - 传统的Fine-tuning方法: 将其通过BERT的Transformer获得
[CLS]表征之后再喂入新增加的MLP分类器进行二分类,预测该句子是积极的(positive)还是消极的(negative),因此需要一定量的训练数据来训练。 - Prompt-Tuning执行步骤:
- 1.构建模板(Template Construction): 通过人工定义、自动搜索、文本生成等方法,生成与给定句子相关的一个含有
[MASK]标记的模板。例如It was [MASK].,并拼接到原始的文本中,获得Prompt-Tuning的输入:[CLS] I like the Disney films very much. [SEP] It was [MASK]. [SEP]。将其喂入BERT模型中,并复用预训练好的MLM分类器(在huggingface中为BertForMaskedLM),即可直接得到[MASK]预测的各个token的概率分布。 - 2.标签词映射(Label Word Verbalizer) :因为
[MASK]部分我们只对部分词感兴趣,因此需要建立一个映射关系。例如如果[MASK]预测的词是“great”,则认为是positive类,如果是“terrible”,则认为是negative类。 - 3.训练:根据Verbalizer,则可以获得指定label word的预测概率分布,并采用交叉信息熵进行训练。此时因为只对预训练好的MLM head进行微调,所以避免了过拟合问题。
- 1.构建模板(Template Construction): 通过人工定义、自动搜索、文本生成等方法,生成与给定句子相关的一个含有
注意思考:不同的句子应该有不同的template和label word,没错,因为每个句子可能期望预测出来的label word都不同,因此如何最大化的寻找当前任务更加合适的template和label word是Prompt-tuning非常重要的挑战。
其实我们可以理解,引入的模板和标签词本质上属于一种数据增强,通过添加提示的方式引入先验知识。
• 核心特征:
• 借助Prompt将任务转化为语言模型擅长的填空或问答问题。
• 案例:
对于情感分析任务,用“这句话的情感是[MASK]”形式提示模型,BERT通过填空即可直接预测“积极”或“消极”。
• 优点:
• 无需微调整个模型,仅需优化Prompt模板。
• 极大减少标注数据需求,适合少样本甚至零样本学习。
• 缺点:
• 设计高质量Prompt模板需要领域知识。
• 对复杂任务的适配能力有待提升。
1.5 Prompt-Tuning(提示微调)技术发展历程

Prompt-Tuning自GPT-3被提出以来,从传统的离散、连续的Prompt构建、走向面向超大规模模型的In-Context Learning、Instruction-tuning和Chain_of_Thought.
2. Fine-Tuning模型微调的核心原理
2.1 什么是Fine-Tuning?
• 定义:
基于预训练模型,通过有监督微调适配特定任务。Fine-Tuning是第三范式的核心技术。
• 训练流程:
1. 预训练阶段: 在大规模通用语料库(如Wikipedia)上无监督训练,学习通用语言表示。
2. 微调阶段: 在下游任务数据上有监督微调,调整模型参数适配任务需求。
2.2 Fine-Tuning优缺点
• 优点:
• 小数据集即可达高精度,显著降低标注成本。
• 能适配多种任务,如文本分类、翻译、问答等。
• 缺点:
• 每个任务需要单独微调一个模型,适配效率低。
• 模型训练成本高,对硬件资源要求大。
3. Prompt-Tuning模型微调原理揭秘
3.1 什么是Prompt-Tuning?
• 定义:
Prompt-Tuning通过设计提示词将下游任务转化为语言模型擅长的生成任务。例如,“这句话的情感是[MASK]”将情感分析转化为填空任务。
3.2 Prompt-Tuning的实现流程
1. 任务转化:
• 将任务转化为填空、问答等语言生成问题。
• 示例:“今天的天气如何?它是[MASK]”。
2. 模板优化:
• 优化Prompt模板提升任务适配性,可以手动设计或自动优化。
3. 轻量训练:
• 仅优化少量Prompt相关参数,而非整个模型。
3.3 优缺点
• 优点:
• 训练效率高,适合少样本甚至零样本任务。
• 极大降低对计算资源的需求。
• 缺点:
• 设计Prompt模板需要领域知识,复杂任务适配性不足。
4. 未来展望:从少监督到无监督,NLP的未来趋势
• 更少监督,更多迁移:
Prompt-Tuning极大减少了对标注数据和计算资源的需求,将引领未来NLP的发展。
• 从少样本到零样本:
NLP模型的泛化能力将持续提升,通过高效Prompt设计,模型在无标注数据情况下即可完成任务。
• 跨领域应用扩展:
未来的预训练模型将结合更多领域数据,适配更广泛的任务场景。
总结
• NLP的四大范式从传统机器学习到Prompt-Tuning,展现了技术从高监督到少监督甚至无监督的进化路径。
• Fine-Tuning是第三范式的核心技术,为小数据集带来高精度,但效率较低。
• Prompt-Tuning作为第四范式的代表,通过减少训练需求,实现了轻量化适配,展现了NLP的未来趋势。
当前大模型阶段,提示词工程已经很主流了,下一篇文章我们将会详细的讲解 Prompt-Tuning,敬请关注!
你是否尝试过Prompt-Tuning?它在你的任务中表现如何?欢迎在评论区留言分享你的看法!
相关文章:
NLP任务四大范式的进阶历程:从传统TF-IDF到Prompt-Tuning(提示词微调)
引言:从TF-IDF到Prompt-Tuning(提示词微调),NLP的四次变革 自然语言处理(NLP)技术从最早的手工特征设计到如今的Prompt-Tuning,经历了四个重要阶段。随着技术的不断发展,我们的目标…...

GAMES101:现代计算机图形学入门-笔记-09
久违的101图形学回归咯 今天的话题应该是比较轻松的:聊一聊在渲染中比较先进的topics Advanced Light Transport 首先是介绍一系列比较先进的光线传播方法,有无偏的如BDPT(双向路径追踪),MLT(梅特罗波利斯…...

【Db First】.NET开源 ORM 框架 SqlSugar 系列
.NET开源 ORM 框架 SqlSugar 系列 【开篇】.NET开源 ORM 框架 SqlSugar 系列【入门必看】.NET开源 ORM 框架 SqlSugar 系列【实体配置】.NET开源 ORM 框架 SqlSugar 系列【Db First】.NET开源 ORM 框架 SqlSugar 系列【Code First】.NET开源 ORM 框架 SqlSugar 系列 …...

MySQL聚合查询分组查询联合查询
#对应代码练习 -- 创建考试成绩表 DROP TABLE IF EXISTS exam; CREATE TABLE exam ( id bigint, name VARCHAR(20), chinese DECIMAL(3,1), math DECIMAL(3,1), english DECIMAL(3,1) ); -- 插入测试数据 INSERT INTO exam (id,name, chinese, math, engli…...
告别照相馆!使用AI证件照工具HivisionIDPhotos打造在线证件照制作软件
文章目录 前言1. 安装Docker2. 本地部署HivisionIDPhotos3. 简单使用介绍4. 公网远程访问制作照片4.1 内网穿透工具安装4.2 创建远程连接公网地址 5. 配置固定公网地址 前言 本文主要介绍如何在Linux系统使用Docker快速部署一个AI证件照工具HivisionIDPhotos,并结合…...

通信原理第三次实验
实验目的与内容 实验操作与结果 5.1 刚开始先不加入白噪声,系统设计如下: 正弦波参数设置如下: FM设计如下: 延迟设计如下: 两个滤波器设计参数如下: 输出信号频谱为(未加入噪声)&a…...

【halcon】Metrology工具系列之 get_metrology_object_result_contour
get_metrology_object_result_contour (操作员) 名称 get_metrology_object_result_contour — 查询测量对象的结果轮廓。 签名 get_metrology_object_result_contour( : Contour : MetrologyHandle, Index, Instance, Resolution : ) 描述 get_metrology_object_result_…...

A052-基于SpringBoot的酒店管理系统
🙊作者简介:在校研究生,拥有计算机专业的研究生开发团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 赠送计算机毕业设计600…...

NLP信息抽取大总结:三大任务(带Prompt模板)
信息抽取大总结 1.NLP的信息抽取的本质?2.信息抽取三大任务?3.开放域VS限定域4.信息抽取三大范式?范式一:基于自定义规则抽取(2018年前)范式二:基于Bert下游任务建模抽取(2018年后&a…...
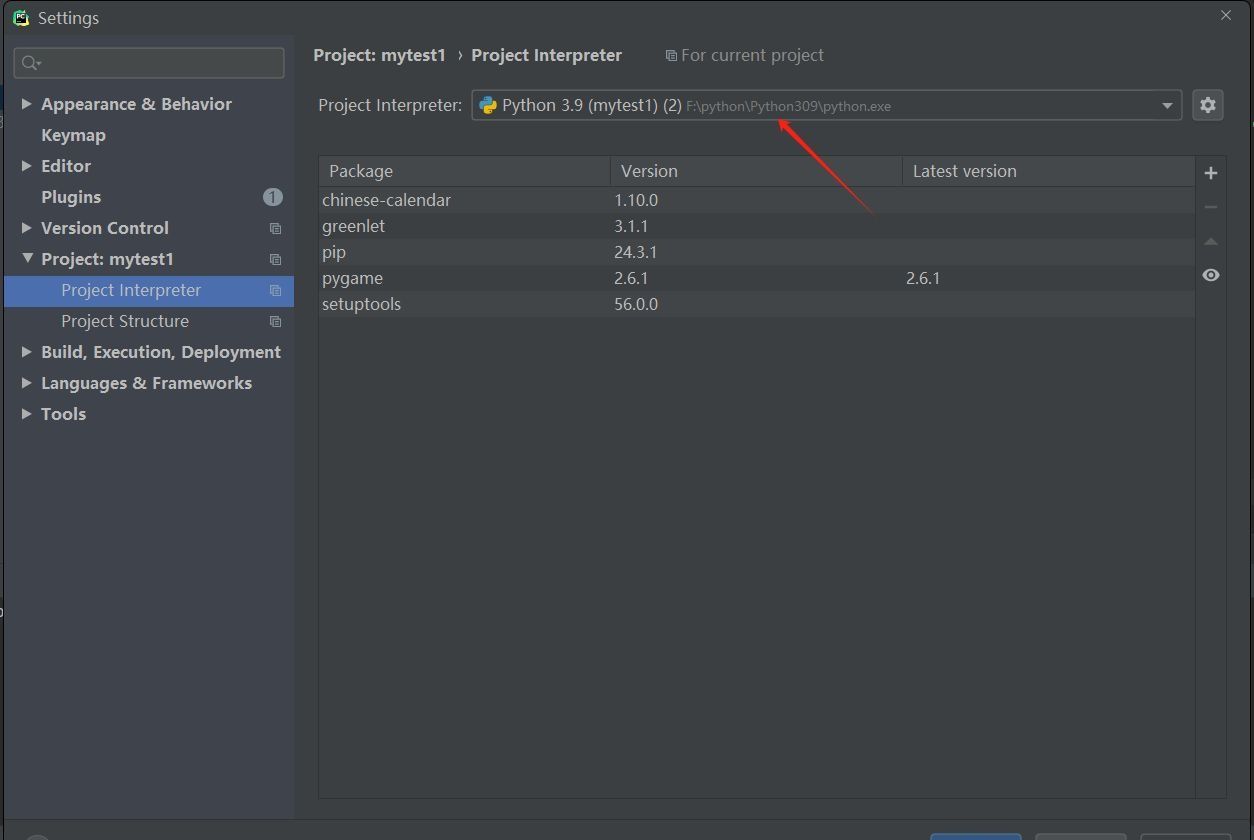
python常见问题-pycharm无法导入三方库
1.运行环境 python版本:Python 3.9.6 需导入的greenlet版本:greenlet 3.1.1 2.当前的问题 由于需要使用到greenlet三方库,所以进行了导入,以下是我个人导入时的全过程 ①首先尝试了第1种导入方式:使用pycharm进行…...

迅为RK3588开发板Android系统开发笔记-使用ADB工具
1 使用 ADB 工具 ADB 英文名叫 Android debug bridge ,是 Android SDK 里面的一个工具,用这个工具可以操作管理 Android 模拟器或者真实的 Android 设备,主要的功能如下所示: 在 Android 设备上运行 shell 终端,用命…...

什么是分布式数据库?
随着现代互联网应用和大数据时代的到来,分布式数据库成为了解决大规模数据存储和高并发处理的核心技术之一。本文将通过深入浅出的方式,带你全面理解分布式数据库的概念、工作原理以及底层实现技术。无论你是刚刚接触分布式数据库的开发者,还…...

Leetcode 3363. Find the Maximum Number of Fruits Collected
Leetcode 3363. Find the Maximum Number of Fruits Collected 1. 解题思路2. 代码实现 题目链接:3363. Find the Maximum Number of Fruits Collected 1. 解题思路 这一题是一道陷阱题…… 乍一眼看过去,由于三人的路线完全可能重叠,因此…...

【数据仓库 | Data Warehouse】数据仓库的四大特性
1. 前言 数据仓库是用于支持管理和决策的数据集合,它汇集了来自不同数据源的历史数据,以便进行多维度的分析和报告。数据仓库的四大特点是:主题性,集成性,稳定性,时变性。 2. 主题性(Subject-Oriented) …...

springboot配置多数据源mysql+TDengine保姆级教程
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pom文件二、yamlDataSourceConfigServiceMapper.xml测试总结 前言 Mybatis-plus管理多数据源,数据库为mysql和TDengine。 一、pom文件 <de…...

dns实验2:反向解析
启动服务: 给虚拟机网卡添加IP地址: 查看有几个IP地址: 打开配置文件: 重启服务,该宽松模式,关闭防火墙: 本机测试: windows测试:(本地shell)...

ZooKeeper 基础知识总结
先赞后看,Java进阶一大半 ZooKeeper 官网这样介绍道:ZooKeeper 是一种集中式服务,用于维护配置信息、命名、提供分布式同步和提供组服务。 各位hao,我是南哥,相信对你通关面试、拿下Offer有所帮助。 ⭐⭐⭐一份南哥编写…...

npm库xss依赖的使用方法和vue3 中Web富文本编辑器 wangeditor 使用xss库解决 XSS 攻击的方法
npm库xss依赖的使用方法和vue3 中Web富文本编辑器 wangeditor 使用xss库解决 XSS 攻击的方法 1. npm库xss依赖的使用方法1.1 xss库定义1.2 xss库功能 2. vue3 中 wangeditor 使用xss库解决 XSS 攻击的方法和示例2.1 在终端执行如下命令安装 xss 依赖2.2 在使用 wangeditor 的地…...

微信小程序蓝牙writeBLECharacteristicValue写入数据返回成功后,实际硬件内信息查询未存储?
问题:连接蓝牙后,调用小程序writeBLECharacteristicValue,返回传输数据成功,查询硬件响应发现没有存储进去? 解决:一直以为是这个write方法的问题,找了很多相关贴,后续进行硬件日志…...

5G NR:带宽与采样率的计算
100M 带宽是122.88Mhz sampling rate这是我们都知道的,那它是怎么来的呢? 采样率 子载波间隔 * 采样长度 38.211中对于Tc的定义, 在LTE是定义了Ts,在NR也就是5G定义了Tc。 定义这个单位会对我们以后工作中的计算至关重要。 就是在…...

BetterRTX终极教程:5分钟免费提升Minecraft画质的完整方案
BetterRTX终极教程:5分钟免费提升Minecraft画质的完整方案 【免费下载链接】BetterRTX-Installer The Powershell Installer for BetterRTX! BetterRTX is a Ray-Tracing mod for Minecraft Bedrock. 项目地址: https://gitcode.com/gh_mirrors/be/BetterRTX-Inst…...

OpenClaw Mattermost插件:为团队协作平台注入AI智能的轻量集成方案
1. 项目概述:为团队协作平台注入AI灵魂如果你所在的技术团队正在使用 Mattermost 这类自托管、注重数据隐私的团队协作工具,同时又希望引入一个能处理工单、回答疑问、甚至自动执行任务的智能助手,那么你很可能已经厌倦了那些需要复杂 API 调…...

终极指南:3分钟免费配置PotPlayer百度翻译插件,实现实时字幕翻译
终极指南:3分钟免费配置PotPlayer百度翻译插件,实现实时字幕翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu …...

高效Kolmogorov-Arnold网络:PyTorch实现终极指南 [特殊字符]
高效Kolmogorov-Arnold网络:PyTorch实现终极指南 🚀 【免费下载链接】efficient-kan An efficient pure-PyTorch implementation of Kolmogorov-Arnold Network (KAN). 项目地址: https://gitcode.com/GitHub_Trending/ef/efficient-kan Kolmogor…...

告别远程桌面‘失忆症’:一招锁定xrdp端口,让你的XFCE会话永不丢失
告别远程桌面‘失忆症’:一招锁定xrdp端口,让你的XFCE会话永不丢失 远程办公和跨平台协作已成为现代开发者的日常,但当你正沉浸于代码世界时,突然的网络波动或客户端切换却让整个工作环境"人间蒸发"——这种经历恐怕每…...

【AI原生产品规划终极指南】:2026奇点大会PM必修的7大认知跃迁与3个落地陷阱规避法
AI原生产品规划:2026奇点智能技术大会产品经理必修课 更多请点击: https://intelliparadigm.com 第一章:从AI赋能到AI原生:一场范式革命的底层认知重构 传统AI赋能模式将模型作为工具嵌入既有系统——例如在CRM中调用NLP接口分析…...

DeepSeek V4的突破:探索未来AI意识的可能性
引言 DeepSeek V4的发布,再次刷新了人们对大语言模型的认知:更强的代码生成、更复杂的逻辑推理、更精准的长文本理解……几乎所有技术评测都在告诉我们:AI又向前迈进了一大步。社交媒体上,关于“AI是否快要拥有意识”的讨论也随之…...

AI插件系统开发指南:从架构设计到生态构建
1. 项目概述:一个为TrapicAI生态注入活力的插件系统最近在折腾AI应用开发,特别是围绕一些开源大模型框架做二次开发时,总感觉缺了点什么。很多框架功能强大,但“开箱即用”的体验和针对特定场景的深度定制能力之间,往往…...

灵魂面甲修改器 2026最新版42项功能
下载地址:https://pan.quark.cn/s/81c8f13901b3 毒盘 支持最新版本,风灵月影42项功能拉满,支持最新版本,Steam/EPIC/学习版全适配! 【5月9日的最新版本不会闪退!全网最新版本!】 ✅ 非软件丨无…...

从零到一:基于iSYSTEM winIDEA与IC5000的嵌入式程序烧写与调试实战指南
1. 环境准备:搭建你的嵌入式开发工作台 第一次接触iSYSTEM工具链时,我完全被各种专业术语搞懵了。后来才发现,只要把环境搭好,后面的操作就像拼乐高一样简单。这里我会手把手带你配置好winIDEA和IC5000调试器,避开那些…...