Flink在Linux系统上的安装与入门
一、Flink的引入
这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有Hadoop、Storm,以及后来的Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flink,也就在这个时候默默的发展着。
在国外一些社区,有很多人将大数据的计算引擎分成了4 代,当然,也有很多人不会认同。我们先姑且这么认为和讨论。
l 第1代——Hadoop MapReduce
首先第一代的计算引擎,无疑就是Hadoop 承载的 MapReduce。它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法
l 第2代——DAG框架(Tez) + MapReduce
由于这样的弊端,催生了支持DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务
l 第3代——Spark
接下来就是以Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。
l 第4代——Flink
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
批处理、流处理、SQL高层API支持自带DAG流式计算性能更高、可靠性更高
二、Flink发展史
Flink诞生背景
Flink起源于Stratosphere项目,Stratosphere是在2010~2014年由地处柏林的大学和欧洲的一些其他的大学共同进行的研究项目。
2014年4月捐赠给了Apache软件基金会
2014年12月成为Apache软件基金会的顶级项目。

2008年,Flink 的前身已经是柏林理工大学一个研究性项目,原名 StratoSphere。
2014-04-16,Flink成为 ASF(Apache Software Foundation)的顶级项目之一,从Stratosphere 0.6开始,正式更名为Flink。由Java语言编写;
2014-11-04,Flink 0.7.0发布,介绍了最重要的特性:Streaming API
2016-03-08,Flink 1.0.0,支持 Scala
2019-01-08,阿里巴巴以9000万欧元的价格收购了总部位于柏林的初创公司Data Artisans,也就是Flink的母公司。
LOGO介绍:
在德语中,Flink一词表示快速和灵巧,项目采用松鼠的彩色图案作为logo,Flink的松鼠logo尾巴的颜色与Apache软件基金会的logo颜色相呼应,也就是说,这是一只Apache风格的松鼠。
 三、 Flink官方介绍
三、 Flink官方介绍
官网:Apache Flink Documentation | Apache Flink
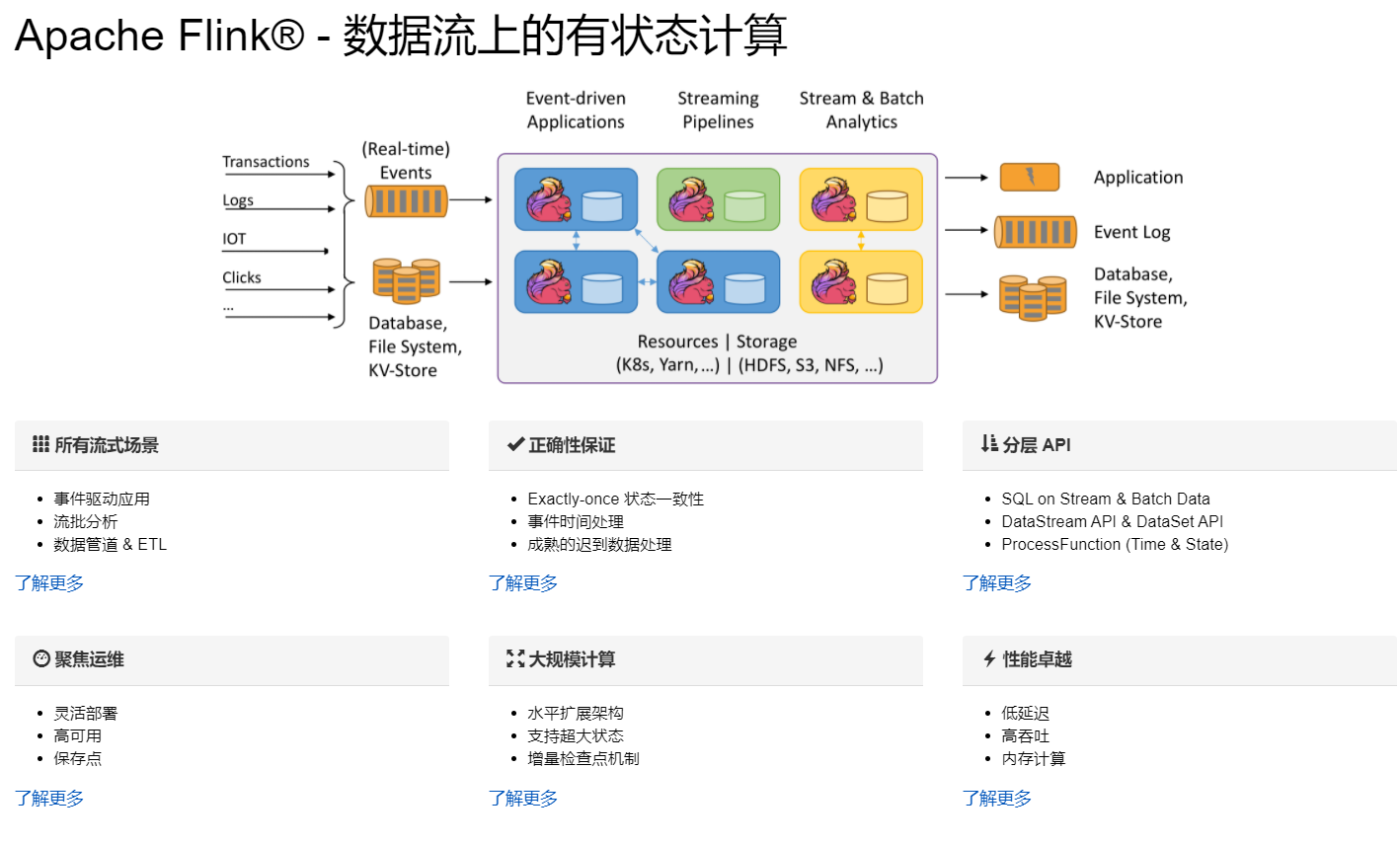
Flink主页在其顶部展示了该项目的理念:“Apache Flink是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
Flink是一款分布式的计算引擎,它可以用来做流处理;也可以用来做批处理。
四、Flink中的批和流
批处理的特点是有界、持久、大量,非常适合需要访问全部记录才能完成的计算工作,一般用于离线统计。
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统 传输的每个数据项执行操作,一般用于实时统计。
而在Flink中,一切都是由流组成的,Flink认为有界数据集是无界数据流的一种特例,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
无界流:意思很明显,只有开始没有结束。必须连续的处理无界流数据,也即是在事件注入之后立即要对其进行处理。不能等待数据到达了再去全部处理,因为数据是无界的并且永远不会结束数据注入。处理无界流数据往往要求事件注入的时候有一定的顺序性,例如可以以事件产生的顺序注入,这样会使得处理结果完整。
有界流:也即是有明确的开始和结束的定义。有界流可以等待数据全部注入完成了再开始处理。注入的顺序不是必须的了,因为对于一个静态的数据集,我们是可以对其进行排序的。有界流的处理也可以称为批处理。

五、性能比较
Spark和Flink全部都运行在Hadoop YARN上,性能为Flink > Spark > Hadoop(MR),迭代次数(数据量)越多越明显,性能上,Flink优于Spark和Hadoop最主要的原因是Flink支持增量迭代,具有对迭代自动优化的功能。
六、Standalone集群模式安装部署
1、Flink支持多种安装模式。
local(本地)——本地模式
standalone——独立模式,Flink自带集群,开发测试环境使用
standaloneHA—独立集群高可用模式,Flink自带集群,开发测试环境使用
yarn——计算资源统一由Hadoop YARN管理,生产环境测试
下载链接:
https://archive.apache.org/dist/flink/flink-1.13.1/flink-1.13.1-bin-scala_2.11.tgz
2、上传Flink安装包,解压,配置环境变量
[root@hadoop11 modules]# tar -zxf flink-1.13.6-bin-scala_2.11.tgz -C /opt/installs/
[root@hadoop11 installs]# mv flink-1.13.6/ flink
[root@hadoop11 installs]# vim /etc/profile
export FLINK_HOME=/opt/installs/flink
export PATH=$PATH:$FLINK_HOME/bin
export HADOOP_CONF_DIR=/opt/installs/hadoop/etc/hadoop记得source /etc/profile3、修改配置文件
① /opt/installs/flink/conf/flink-conf.yaml
cd /opt/installs/flink/conf/flink-conf.yamljobmanager.rpc.address: bigdata01
taskmanager.numberOfTaskSlots: 2
web.submit.enable: true#历史服务器 如果HDFS是高可用,则复制core-site.xml、hdfs-site.xml到flink的conf目录下 hadoop11:8020 -> hdfs-cluster
jobmanager.archive.fs.dir: hdfs://bigdata01:9820/flink/completed-jobs/
historyserver.web.address: bigdata01
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://bigdata01:9820/flink/completed-jobs/② /opt/installs/flink/conf/masters
cd /opt/installs/flink/conf/mastersbigdata01:8081③ /opt/installs/flink/conf/workers
cd /opt/installs/flink/conf/workersbigdata01
bigdata02
bigdata034、 上传jar包并分发
将资料下的flink-shaded-hadoop-2-uber-2.7.5-10.0.jar放到flink的lib目录下
分发:
xsync.sh /opt/installs/flink
xsync.sh /etc/profile七、启动
1、先启动集群
#启动HDFS
start-dfs.sh
#启动集群
start-cluster.sh
#启动历史服务器
historyserver.sh start假如 historyserver 无法启动,也就没有办法访问 8082 服务,原因大概是你没有上传 关于 hadoop 的 jar 包到 lib 下:


2、 观察webUI:
http://bigdata01:8081 -- Flink集群管理界面 当前有效,重启后里面跑的内容就消失了
能够访问8081是因为你的集群启动着呢
http://bigdata01:8082 -- Flink历史服务器管理界面,及时服务重启,运行过的服务都还在
能够访问8082是因为你的历史服务启动着·8081:Fink master的webUI端口,同时也是spark worker 的webUI端口。
两者的区别:
首先可以先把服务都停止

然后再重启,发现8081上已经完成的任务中是空的,而8082上的历史任务都还在,原因是8082读取了hdfs上的一些数据,而8081没有。
但是从web提供的功能来看,8081提供的功能还是比8082要丰富的多。
3、提交官方示例
flink run /opt/installs/flink/examples/batch/WordCount.jar
或者
flink run /opt/installs/flink/examples/batch/WordCount.jar --input 输入数据路径 --output 输出数据路径flink run /opt/installs/flink/examples/batch/WordCount.jar --input /home/wc.txt --output /home/result运行以上案例时,会出现有时候运行成功,有时候运行失败的问题:
Caused by: java.io.FileNotFoundException: /home/wc.txt (没有那个文件或目录)at java.io.FileInputStream.open0(Native Method)at java.io.FileInputStream.open(FileInputStream.java:195)at java.io.FileInputStream.<init>(FileInputStream.java:138)at org.apache.flink.core.fs.local.LocalDataInputStream.<init>(LocalDataInputStream.java:50)at org.apache.flink.core.fs.local.LocalFileSystem.open(LocalFileSystem.java:134)at org.apache.flink.api.common.io.FileInputFormat$InputSplitOpenThread.run(FileInputFormat.java:1053)
原因是:你的 taskManager 有三台,你的数据只在本地存放一份,所以需要将数据分发给 bigdata02 和 bigdata03
xsync.sh /home/wc.txt
相关文章:
Flink在Linux系统上的安装与入门
一、Flink的引入 这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有Hadoop、Storm,以及后来的Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计…...

微信小程序Webview与H5通信
背景 近期有个微信小程序需要用到web-view嵌套H5的场景,该应用场景需要小程序中频繁传递数据到H5进行渲染,且需要保证页面不刷新。 由于微信小程序与H5之间的通信限制比较大,显然无法满足于我的业务场景 探索 由于微信小程序与webview的环境是…...

Debezium Engine监听binlog实现缓存更新与业务解耦
飞书文档 解决缓存与数据源数据不一致的方案有很多, 各有优缺点; 1.0、旁路缓存策略, 直接同步更新 读取流程: 查询缓存。如果缓存命中,则直接返回结果。如果缓存未命中,则查询数据库。将数据库查询到的数据写入缓存,并设置一个…...

docker搭建socks5代理
准备工作 VPS安全组/策略放行相应端口如启用了防火墙,放行相应端口 实际操作 我们选用“历史悠久”的Dante socks5 代理服务器,轻量、稳定。Github也有对dante进行进一步精简的镜像,更为适宜。github项目地址如下: https://gi…...

scanf函数和printf函数的格式化输入输出
#include<stdio.h> int main() {int a;double b;char c;scanf("a%d,b%lf:c%c",&a,&b,&c); //float型输入时使用%f占位,double型使用%lf占位;输出时二者相同都是%f即可。if(a>0)printf("a%-10d,b%20.3lf,c%c",a…...

Day31 贪心算法 part05
56. 合并区间 本题也是重叠区间问题,如果昨天三道都吸收的话,本题就容易理解了。 代码随想录 class Solution {public int[][] merge(int[][] intervals) {Arrays.sort(intervals, (a,b) -> Integer.compare(a[0], b[0]));List<int[]> result …...

uniapp连接mqtt频繁断开原因和解决方法
mqtt参考文档:MQTT.js 入门教程 | EMQ、MQTT.js 入门教程 - EMQX - 博客园 uniapp引用MQTT频繁断开的问题可能由于以下几个原因导致: 网络不稳定:频繁断开可能是由于网络不稳定导致的,可以尝试优化网络连接。 心跳机制问题&…...

【数据结构-队列】力扣641. 设计循环双端队列
设计实现双端队列。 实现 MyCircularDeque 类: MyCircularDeque(int k) :构造函数,双端队列最大为 k 。 boolean insertFront():将一个元素添加到双端队列头部。 如果操作成功返回 true ,否则返回 false 。 boolean insertLast() ࿱…...

leetcode3250. 单调数组对的数目 I,仅需1s
题目: https://leetcode.cn/problems/find-the-count-of-monotonic-pairs-i/description/ 不为别的,只是记录下这个超过100%,而且比原先最快的快了一个量级 不知道咋分析,反正得出结论就是,变大不变,变小…...

安全基线检查
一、安全基线检测基础知识 安全基线的定义 安全基线检查的内容 安全基线检查的操作 二、MySQL的安全基线检查 版本加固 弱口令 不存在匿名账户 合理设置权限 合理设置文件权限 日志审核 运行账号 可信ip地址控制 连接数限制 更严格的基线要求 1、禁止远程连接数据库 2、修改…...

C#读取本地图像的方法总结
前言: 大家好,我是上位机马工,硕士毕业4年年入40万,目前在一家自动化公司担任软件经理,从事C#上位机软件开发8年以上!我们在C#开发C#程序的时候,有时候需要读取本地图像,下面进行详…...

力扣81:搜索旋转排序数组II
已知存在一个按非降序排列的整数数组 nums ,数组中的值不必互不相同。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转 ,使数组变为 [nums[k], nums[k1], ..., nums[n-1], n…...

信息系统项目管理-论文写作方法之背景二
为响应国家政务服务“一网、一门、一次”改革,打破“信息孤岛”现象,打造线上线下相融合、多级联动的政务服务一体化平台。XX市行政审批局欲整合市局及下属13镇区、500多个村居委会政务服务中心业务,梳理人社、民政、卫计委、公积金、交通等多…...

使用ffmpeg命令实现视频文件间隔提取帧图片
将视频按每隔五秒从视频中提取一张图片 使用 ffmpeg 工具,通过设置 -vf(视频过滤器)和 -vsync 选项 命令格式 ffmpeg -i input_video.mp4 -vf "fps1/5" output_%03d.png 解释: -i input_video.mp4:指定输…...

我们项目要升级到flutter架构的几点原因
一、探索 Flutter打造卓越移动应用的新时代框架 在移动应用开发的世界里,Flutter已经成为了一个炙手可热的话题。诞生于Google的怀抱,Flutter以其独特的优势和理念,正在引领一场全球范围内的应用开发 ** 。本文将深入探讨Flutter项目的特点、…...

【简单好抄保姆级教学】javascript调用本地exe程序(谷歌,edge,百度,主流浏览器都可以使用....)
javascript调用本地exe程序 详细操作步骤结果 详细操作步骤 在本地创建一个txt文件依次输入 1.指明所使用注册表编程器版本 Windows Registry Editor Version 5.00这是脚本的第一行,指明了所使用的注册表编辑器版本。这是必需的,以确保脚本能够被正确解…...

ElasticSearch为什么不能在query阶段直接返回_id,从而避免fetch?
整理自Github的一个issue,也正好解答了我的疑惑 https://github.com/elastic/elasticsearch/issues/17159 提问 是否可以避免搜索的fetch阶段并仅返回文档ID?查询阶段结束时是否有_id,这样当我只需要_id时,fetch就多余了?可以通过…...

网安瞭望台第5期 :7zip出现严重漏洞、识别网络钓鱼诈骗的方法分享
国内外要闻 7 - Zip存在高危漏洞,请立刻更新 2024 年 11 月 24 日,do son 报道了 7 - Zip 中存在的一个高严重性漏洞 CVE - 2024 - 11477。7 - Zip 是一款广受欢迎的文件压缩软件,而这个漏洞可能会让攻击者在存在漏洞的系统中执行恶意代码。…...
获 2023 年度浙江省科学技术进步奖一等奖 | 网易数智日报
11 月 22 日,加快建设创新浙江因地制宜发展新质生产力动员部署会暨全省科学技术奖励大会在杭州隆重召开。浙江大学、网易数智等单位联合研发的“大规模结构化数据智能计算平台及产业化”项目获得 2023 年度浙江省科学技术进步奖一等奖。 加快建设创新浙江因地制宜发…...

SQL基础入门 —— SQL概述
目录 1. 什么是SQL及其应用场景 SQL的应用场景 2. SQL数据库与NoSQL数据库的区别 2.1 数据模型 2.2 查询语言 2.3 扩展性 2.4 一致性与事务 2.5 使用场景 2.6 性能与扩展性 总结 3. 常见的SQL数据库管理系统(MySQL, PostgreSQL, SQLite等) 3.…...
Vit工程化应用(transformers 库)
pip install transformersfrom transformers import ViTImageProcessor, ViTForImageClassification from PIL import Image import requests# 1. 加载模型和特征提取器 model_name google/vit-base-patch16-224 processor ViTImageProcessor.from_pretrained(model_name) mo…...

TAMEn系统:触觉视觉数据采集的模块化解决方案
1. TAMEn系统概述:触觉视觉数据采集的革命性方案在机器人操作领域,接触丰富的任务(如柔性物体处理、精密装配)一直面临着数据采集的挑战。传统视觉系统难以捕捉细微的接触信号(如初始滑动、局部变形)&#…...

ARM Firmware Suite与Evaluator-7T开发板实战指南
1. ARM Firmware Suite与Evaluator-7T开发板概述在嵌入式系统开发领域,ARM架构处理器因其出色的能效比和丰富的生态系统支持,已成为工业控制、物联网设备和消费电子等领域的首选方案。ARM Firmware Suite(AFS)是ARM公司针对其处理…...

终极指南:如何用sndcpy将Android音频无损转发到电脑
终极指南:如何用sndcpy将Android音频无损转发到电脑 【免费下载链接】sndcpy Android audio forwarding PoC (scrcpy, but for audio) 项目地址: https://gitcode.com/gh_mirrors/sn/sndcpy 你是否曾经想在电脑上收听手机上的音乐、播客或游戏音频࿱…...
)
避坑指南:在CentOS 7.5上成功安装Ansys 19.2的完整流程(附字体问题终极解决方案)
CentOS 7.5与Ansys 19.2黄金组合:工业仿真环境搭建实战手册 在工程仿真领域,Ansys作为行业标准工具链的核心组件,其Linux环境部署一直是技术人员的痛点。经过长达三个月的多版本交叉测试,我们意外发现CentOS 7.5与Ansys 19.2的组合…...

别再只盯着密钥了!深入ESP32 eFuse,看懂flash加密背后的硬件安全逻辑
别再只盯着密钥了!深入ESP32 eFuse,看懂flash加密背后的硬件安全逻辑 当你在ESP32项目中使用flash加密功能时,是否曾疑惑过:为什么简单地烧录几个eFuse位就能实现固件保护?那些看似神秘的DISABLE_DL_DECRYPT、FLASH_CR…...

告别编译噩梦:在Ubuntu 22.04上为你的C++项目搞定Abseil依赖的三种方法
告别编译噩梦:在Ubuntu 22.04上为你的C项目搞定Abseil依赖的三种方法 在C项目的开发过程中,依赖管理一直是开发者面临的一大挑战。特别是对于现代C项目而言,如何高效、可靠地引入和管理第三方库,往往决定了项目的开发效率和最终质…...
搜索插入位置、搜索二维矩阵、查找数组相同的所有位置、搜索旋转排序数组、旋转升序数组的最小值)
【LeetCode 手撕算法】(二分查找)搜索插入位置、搜索二维矩阵、查找数组相同的所有位置、搜索旋转排序数组、旋转升序数组的最小值
复杂度为O(log n)且有序用二分查找35-搜索插入位置思路:二分查找,左右指针 求中间值注意:while的查询条件是>class Solution {public int searchInsert(int[] nums, int target) {int left0;int rightnums.length-1;while(left<right){…...

英雄联盟专业视频编辑器:用League Director制作电影级游戏录像的完整指南
英雄联盟专业视频编辑器:用League Director制作电影级游戏录像的完整指南 【免费下载链接】leaguedirector League Director is a tool for staging and recording videos from League of Legends replays 项目地址: https://gitcode.com/gh_mirrors/le/leaguedir…...

马斯克解散 xAI、接纳 Anthropic:亡羊补牢的无奈,与一场被 AGI 神话带偏的豪赌
马斯克解散 xAI、接纳 Anthropic:亡羊补牢的无奈,与一场被 AGI 神话带偏的豪赌 2026 年 5 月 6 日,两件事同时发生: 一、Anthropic 宣布获得 xAI Colossus 1 集群的全部算力——22 万张英伟达 GPU,300 兆瓦电力容量。 …...